目录
[2.1 kafka社团为啥执行这么高效,这个组织到底隐藏的什么秘密?](#2.1 kafka社团为啥执行这么高效,这个组织到底隐藏的什么秘密?)
[2.1.1 顺序手抄小册的智慧(无敌快只在小册最后记录)](#2.1.1 顺序手抄小册的智慧(无敌快只在小册最后记录))
[2.1.2 页缓存(PageCache)与异步刷盘:社团文件管理](#2.1.2 页缓存(PageCache)与异步刷盘:社团文件管理)
[1. 页缓存的基本原理:减少仓库访问](#1. 页缓存的基本原理:减少仓库访问)
[2. 写入数据与脏页的产生](#2. 写入数据与脏页的产生)
[3. 异步刷新:管理员定期同步仓库](#3. 异步刷新:管理员定期同步仓库)
[4. Kafka的应用:社团的高效消息处理](#4. Kafka的应用:社团的高效消息处理)
[2.1.3 零拷贝-社团的高效通知系统(包括 sendfile 和 mmap 两种实现方式)](#2.1.3 零拷贝-社团的高效通知系统(包括 sendfile 和 mmap 两种实现方式))
[1. mmap 的优点:索引加速](#1. mmap 的优点:索引加速)
[2. sendfile 的优点:网络数据传输](#2. sendfile 的优点:网络数据传输)
[2.1.4 批量发送](#2.1.4 批量发送)
[2.1.5 压缩技术](#2.1.5 压缩技术)
[2.1.6 数据分区](#2.1.6 数据分区)
一、简单回顾
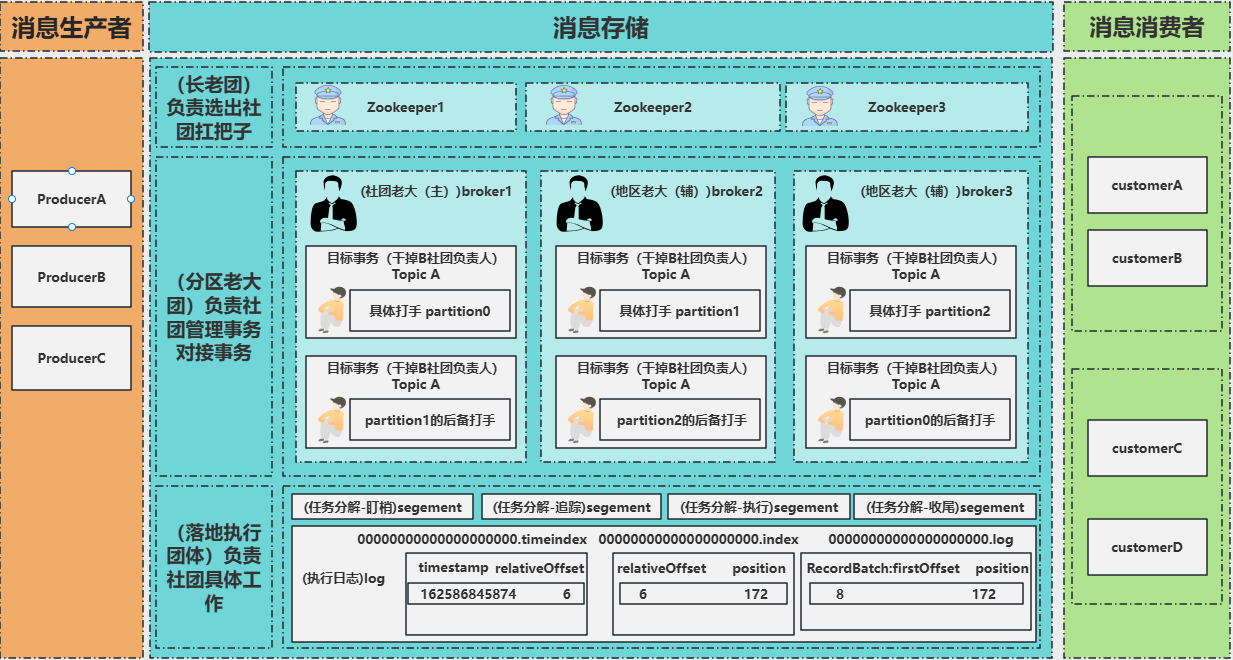
在之前的讨论中,我们用社团比喻解释了Kafka的核心架构:长老团(Zookeeper)负责协调,小弟(broker)处理任务(partition),社团(集群)高效执行消息传递。那么大家肯定有疑问,这个庞大的社团如何高效有序的运转?下面我讲针对每一个文件进行展开。
二、kafka社团运转揭秘
2.1 kafka社团为啥执行这么高效,这个组织到底隐藏的什么秘密?
2.1.1 顺序手抄小册的智慧(无敌快只在小册最后记录)
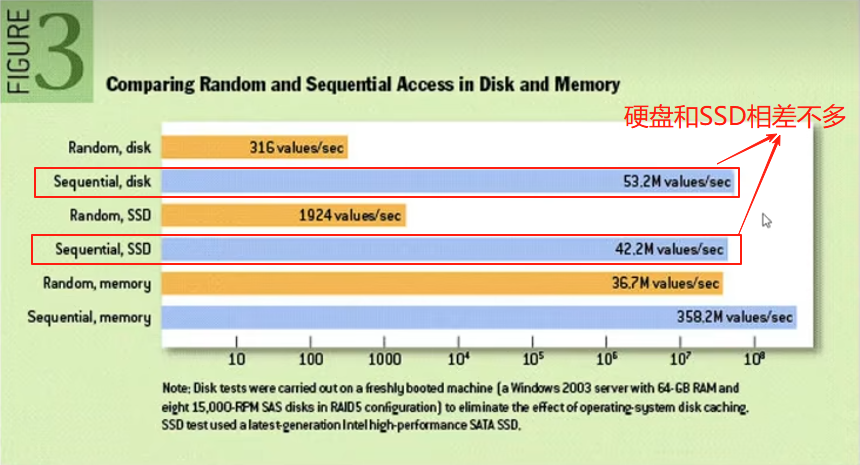
(上图是谋篇论文中的验证结果,充分说明了顺序读写比随机读写的优势)
想象一下,有一个名为"数据记录部"的社团部门,他们负责记录社团里发生的所有重要事件。社团有一本"专有手抄小册",这本小册子就是他们的核心记录工具。规则很简单:
-
只能顺序追加:社员们不能在册子中间随意插入或修改记录,只能在册子的末尾(尾部)添加新的事件描述。这就像写日记一样,只能一页页往后写,不能回头涂改。
-
依赖固定位置:小册子存放在社团的固定书桌上(相当于磁盘),书桌虽然看起来普通,但设计得井井有条。
在社团运作中,社员们(相当于Kafka的生产者)不断收到新事件消息。他们快速跑到书桌前,翻开小册子的最后一页,用流畅的笔迹(顺序写入)添加新内容。由于册子是按顺序摆放的,社员不需要翻来覆去查找位置,直接"刷刷刷"地写完。测试显示,这种顺序追加方式,速度能达到惊人的600MB/s,(相当于每分钟抄写600页),效率极高。
为什么顺序写如此高效?对比随机写的困境
现在,如果社团改变规则,允许社员在册子中间随机插入或修改记录(相当于随机写入),情况就大不同了。社员得先花时间翻到指定页数,找到空隙,再小心修改。这个过程不仅慢,还容易出错。实际测试中,随机写入的速度只有100KB/s(相当于每分钟只抄写1页),比顺序写慢了整整6000倍!
- 性能差异的直观比喻:顺序写像开着跑车在高速公路上飞驰600MB/s,而随机写像推着蜗牛在迷宫里转悠100KB/s。速度差6000倍,意味着如果顺序写1小时能处理完一年的社团事件,随机写可能需要大半年!
在Kafka中,这种"只能追加尾部、不修改旧消息"的设计,正是利用了磁盘的顺序写入优势。社团的书桌(磁盘)虽然不如内存快,但通过顺序操作,它能轻松处理海量事件(高吞吐量),比如每秒处理数百万条消息。
所以,Kafka就像这个"数据记录部",通过坚持顺序手抄小册的智慧,即使使用普通的书桌(磁盘),也能实现惊人的性能。这不仅避免了随机写的瓶颈,还确保了记录的可靠性和一致性。社团的例子生动地说明:有时候,最简单的规则(顺序追加)反而能带来最大的效率提升!
2.1.2 页缓存(PageCache)与异步刷盘:社团文件管理
**注:****PageCache是OS对文件的缓存,用于加速对文件的读写(与Mysql如出一辙)。**Kafka为什么不自己管理缓存,而非要用PageCache?原因有如下三点:
1.JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
2.如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
3.一旦程序崩溃,自己管理的缓存数据会全部丢失。
社团文件处,负责处理各种文档(如活动计划、成员名单)。社团有一个仓库(代表磁盘)存放所有文件,但直接访问仓库很慢。为了提高效率,社团设置了一个前台缓存区(代表页缓存),用于快速访问常用文件。社团成员(代表进程)需要读取或修改文件,管理员(代表操作系统)负责协调文件存储和同步。
1. 页缓存的基本原理:减少仓库访问
- 社团场景 :仓库是社团的长期存储地,存放所有文件(如纸质文档)。前台缓存区是一个小桌子,上面放着最近使用的文件副本。成员想读取文件时,先检查缓存区:
- 命中:如果文件在缓存区(例如,成员想查"本周活动计划",缓存区刚好有),成员直接拿走文件,无需去仓库。
- 未命中:如果文件不在缓存区(例如,成员想查"年度预算报告",缓存区没有),管理员必须去仓库取文件,放入缓存区,再给成员。之后,这份文件会保留在缓存区一段时间,方便下次访问。
- 类比页缓存:仓库是磁盘,缓存区是内存中的页缓存。命中时避免仓库访问(磁盘I/O),未命中时从仓库加载数据到缓存区,减少物理操作的开销。
2. 写入数据与脏页的产生
- 社团场景 :成员想修改文件(如更新"成员名单")。先检查缓存区:
- 如果文件在缓存区,成员直接在副本上修改(例如,添加新成员名字)。
- 如果文件不在缓存区,管理员先添加文件副本到缓存区,成员再修改。
- 修改后,这份副本变成了"脏文件"(内容与仓库版本不一致)。
- 类比脏页:脏文件代表页缓存中的脏页(修改过的数据页)。在操作系统中,数据写入时先修改缓存页,使其成为脏页,而不是立即写回磁盘。
3. 异步刷新:管理员定期同步仓库
- 社团场景 :管理员不会立即处理所有脏文件,因为频繁跑仓库会耽误成员工作(影响性能)。管理员在空闲时(如每天下班前)批量检查缓存区:
- 将脏文件放回仓库更新原版(例如,把修改过的"成员名单"副本覆盖仓库旧版)。
- 完成后,缓存区文件不再是脏文件。
- 如果成员要求紧急同步(如"马上保存,以防断电"),管理员会立即处理,但这会短暂阻塞成员操作。
- 类比异步刷盘:管理员代表操作系统,在后台异步将脏页写入磁盘(如定期刷盘)。这保持了数据一致性,同时避免频繁I/O拖慢系统。紧急同步类似于强制刷盘(fsync),但代价更高。
4. Kafka的应用:社团的高效消息处理
- 社团场景扩展 :假设社团负责传递消息(如活动通知)。成员发送消息时,先写入缓存区(页缓存),管理员异步刷新到仓库。这大大提高了处理速度(高吞吐),因为成员不必等待仓库操作。
- 参数控制 :管理员可以设置规则,比如"每收到10条消息或每5分钟强制刷新一次"(类比Kafka的
log.flush.interval.messages和log.flush.interval.ms)。这确保在异常(如突然停电)时,消息不会丢失在缓存区。 - 同步刷盘选项:如果消息很重要(如"紧急会议通知"),成员可以要求管理员立即刷新(同步刷盘),牺牲速度换取可靠性。但大多数情况下,异步刷新更高效。
- 参数控制 :管理员可以设置规则,比如"每收到10条消息或每5分钟强制刷新一次"(类比Kafka的
- Kafka的优化:就像社团依赖缓存区减少仓库访问,Kafka利用页缓存实现高吞吐。消息先写入内存缓存,由操作系统异步刷盘;Kafka的参数允许在需要时强制同步,防止数据丢失(如机器掉电)。
2.1.3 零拷贝-社团的高效通知系统(包括 sendfile 和 mmap 两种实现方式)
1. mmap 的优点:索引加速
在技术层面,mmap(内存映射文件)通过将文件直接映射到内存中,避免了数据从内核缓冲区到用户缓冲区的额外拷贝。这减少了上下文切换次数(从4次减少到更少),并最小化CPU拷贝(仅1次),从而提升访问速度。在Kafka中,这用于索引文件(如查找消息的位置),使搜索更高效。
社团类比:管理会员名册 想象一个社团需要频繁查询会员名册(索引文件)。传统方式就像:
- 名册存放在档案室(磁盘)。
- 每次查询时,管理员(用户空间)需要:
- 去档案室取名册(上下文切换)。
- 复印名册到办公室(数据拷贝到用户缓冲区)。
- 在办公室查找信息(处理数据)。
- 归还名册(上下文切换)。 这过程涉及多次跑腿(上下文切换)和复印(数据拷贝),效率低且耗时。
使用mmap后:
- 管理员在档案室墙上安装一个透明窗口(内存映射),名册直接透过窗口可见。
- 查询时,管理员只需走到窗口前(少量上下文切换),直接查看名册(无需复印),快速找到信息。
- 优点:减少了跑腿次数(上下文切换)和复印工作(数据拷贝),查询速度更快,管理员能专注于其他任务(如组织活动)。
在这个类比中,mmap相当于"直接映射窗口",让数据访问更直接,减少了不必要的中间步骤,从而加速索引操作。
2. sendfile 的优点:网络数据传输
在技术层面,sendfile通过零拷贝机制,允许数据直接从文件系统发送到网络,无需经过用户空间。这减少了数据拷贝次数(从4次减少到2次内核拷贝),并大幅减少上下文切换(从4次减少到2次)。在Kafka中,这用于Consumer从Broker读取数据,提升传输效率。
社团类比:发送活动通知 假设社团要发送活动通知(数据)给所有会员(网络接收方)。传统方式就像:
- 通知草稿存放在档案室(文件系统)。
- 管理员(用户空间)需要:
- 去档案室取草稿(上下文切换)。
- 复印草稿到办公室(数据拷贝到用户缓冲区)。
- 在办公室打包通知(处理数据)。
- 叫快递员发送(上下文切换和数据拷贝到网络)。 这过程涉及多次跑腿和复印,效率低下。
使用sendfile后:
- 管理员直接告诉快递员(操作系统):"档案室有通知草稿,请直接从这里发送给会员"。
- 快递员直接从档案室取草稿(内核缓冲区),并立即发送(网络),无需管理员复印或中转。
- 优点:减少了跑腿次数(上下文切换)和复印工作(CPU拷贝),通知发送更快,管理员能腾出时间处理其他社团事务(如策划活动)。
在这个类比中,sendfile相当于"快递直达服务",消除了中间环节,让数据传输更高效。
总结优点
Kafka采用了两种零拷贝技术, 主要有两个大的场景:其中网络数据持久化磁盘主要用 mmap 技术,网络数据传输环节主要使用 sendfile 技术
-
社团老大读取文件:Broker 读写index 文件,用了 mmap零复制(索引加速)
-
社团老大发送消息:Broker 向Consumer发消息,用了 sendfile传到socket 零复制(网络数据传输)
2.1.4 批量发送
批量发送就不用展开了在发送者那章已经说过,相当于任务需要打包,考虑任务数量和时间。
-
batch.size:控制批量发送消息的大小,默认值为 16KB,可适当增加 batch.size 参数值提升吞吐。但是,需要注意的是,如果批量发送的大小设置得过大,可能会导致消息发送的延迟增加,因此需要根据实际情况进行调整。
-
linger.ms:控制消息在批量发送前的等待时间,默认值为 0。当 linger.ms 大于 0 时,如果有消息发送,Kafka 会等待指定的时间,如果等待时间到达或者批量大小达到 batch.size,就会将消息打包成一个批次进行发送。可适当增加 linger.ms 参数值提升吞吐,比如 10 ~ 100。
2.1.5 压缩技术
吞吐量:LZ4>Snappy>zstd 和 GZIP
压缩比:zstd>LZ4>GZIP>Snappy。
在 Kafka 中,压缩技术是通过以下两个参数来控制的:
- compression.type:控制压缩算法的类型,默认值为 none,表示不进行压缩。
- compression.level:控制压缩的级别,取值范围为 0-9,默认值为-1。当值为-1 时,表示使用默认的压缩级别。
2.1.6 数据分区
Kafka 集群包含多个 broker。一个 topic 下通常有多个 partition,partition 分布在不同的 Broker 上,用于存储 topic 的消息,这使 Kafka 可以在多台机器上处理、存储消息,给 kafka 提供给了并行的消息处理能力和横向扩容能力。
OK 今天就讲到这里,实在不想打字了。