简介
在前面的章节中,我们介绍了一系列图像处理算法。这些图像处理算法能够帮助我们从图像中提取所需的信息,为后续的计算机视觉任务打下了基础。从本章开始,我们将进入计算机视觉领域中视觉识别的部分。视觉识别的目标是希望计算机对图像的识别结果与人类对图像的识别结果一致。因此视觉识别通常需要一个(机器)学习的过程。自2012年深度学习崛起,视觉识别领域的任务绝大部分是基于深度学习的方法来完成的。因此在视觉识别这一部分,我们将主要介绍基于深度学习的视觉识别算法。

**图像分类(image classification)**是视觉识别的最基本的问题之一,对这个问题的研究也是研究其他视觉识别问题的基础。图像分类,顾名思义,就是根据一定的分类规则,将图像划分到预定义的类别中。如图10-1所示,简单的图像分类就是分别给这些图像打上"猫""骆驼""老虎"等标签。用数学语言来描述图像分类问题,猫骆驼老虎图10-1图像分类示例传统的图像分类流程如图10-2所示。先从用于训练的图像中提取图像表征(image representation),并结合对应的标签信息训练一个图像分类的模型(分类器)。对于每一幅测试图像,采用同样的表征提取过程得到其表征,并利用训练得到的分类器预测其所属类别。
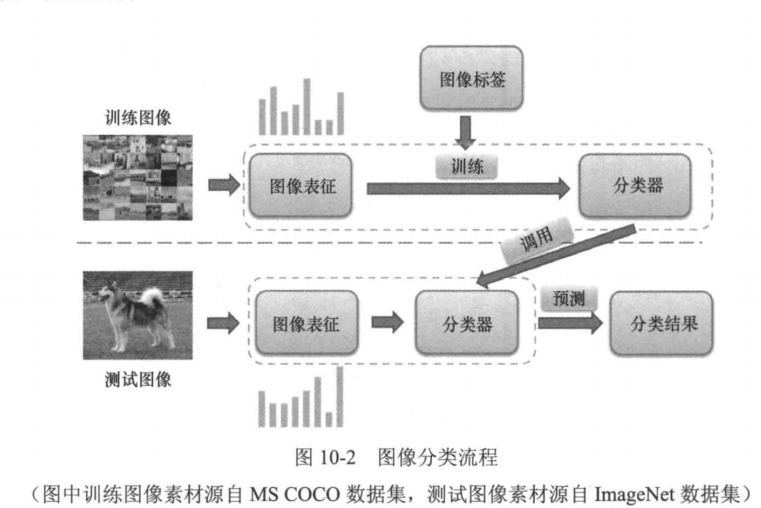 图像表征 的提取是图像分类中关键的一步。机器学习中不同分类器的性能差别不大,因此图像表征的好坏直接决定了图像分类性能的高低。传统图像表征提取算法主要基于手工设计的图像特征向量,如第7章介绍的SFT特征就是一种最典型的手工设计的图像特征向量。传统图像表征中的集大成者是视觉词袋模型(bag of features,.BoF)l-4,由Andrew Zisserman等人受文本检索领域的词袋模型(bag of words model)启发而提出。该表征模型先从图像中检测并提取出多个特征点,之后利用聚类算法对这些特征点的特征向量进行聚类得到"词典",在此基础上通过构建好的词典对每幅图像中的特征向量进行编码,从而构建每幅图像的表征,即视觉词袋模型表征。传统的图像分类过程可以基于视觉词袋模型表征训练图像分类器。可以看到,传统的图像表征提取与图像分类器的训练是分开进行的(如图10-2所示),手工设计的图像表征往往会过早地丢失有用的信息,而分类的结果又无法反馈给图像表征的提取阶段,因此分类性能会受一定的限制。
图像表征 的提取是图像分类中关键的一步。机器学习中不同分类器的性能差别不大,因此图像表征的好坏直接决定了图像分类性能的高低。传统图像表征提取算法主要基于手工设计的图像特征向量,如第7章介绍的SFT特征就是一种最典型的手工设计的图像特征向量。传统图像表征中的集大成者是视觉词袋模型(bag of features,.BoF)l-4,由Andrew Zisserman等人受文本检索领域的词袋模型(bag of words model)启发而提出。该表征模型先从图像中检测并提取出多个特征点,之后利用聚类算法对这些特征点的特征向量进行聚类得到"词典",在此基础上通过构建好的词典对每幅图像中的特征向量进行编码,从而构建每幅图像的表征,即视觉词袋模型表征。传统的图像分类过程可以基于视觉词袋模型表征训练图像分类器。可以看到,传统的图像表征提取与图像分类器的训练是分开进行的(如图10-2所示),手工设计的图像表征往往会过早地丢失有用的信息,而分类的结果又无法反馈给图像表征的提取阶段,因此分类性能会受一定的限制。
随着深度学习的崛起,通过深度卷积神经网络(deepconvolutionalneuralnetwork,DCNN) 联合图像表征学习和分类器学习逐渐成为主流,因为通过联合学习可以使分类的结果与图像表征的提取相互影响,从而大幅提升图像分类的性能。第一个深度卷积神经网络由YannLeCun于1989年提出,用于手写字符的识别。随后在1998年,他改进了这个网络。改进后的网络被称为LeNet-5,已具有所有现代卷积神经网络的元素。2012年,GeoffreyHinton带领他的学生构建了AlexNet7模型。AlexNet是一个8层的卷积神经网络,在ImageNet图像分类比赛中取得冠军,从此开启了图像分类的深度学习时代。2015年,微软亚洲研究院的研究员何恺明等人提出了ResNet。ResNet是一种可以堆叠上千层的卷积神经网络,它刷新了ImageNet图像分类比赛的最好成绩,从此深度学习开始统治整个视觉识别领域。在本章中,我们将分别介绍基于传统的视觉词袋模型的图像分类算法 和基于深度卷积网络 ResNet的图像分类算法。
在介绍算法之前,我们需要先了解一些图像分类常用的数据集及度量(metric)。
数据集及度量(metric)
在图像分类任务中,我们通常会选择以下几种数据集进行模型的训练与测试。
(1)MNIST:MNIST是一个手写数字的数据集,每个样本都是一幅黑白图像,对应的标签为数字0~9中的一个。它包含了60000幅训练图像和10000幅测试图像。
(2)Caltech-101:Caltech-101由李飞飞等于2003年发布。该数据集包含102个类别(101个目标类别和1个背景类别),9144幅图像用于训练和测试。
(3)CFAR-l0:CFAR-l0是由Geoffrey Hinton和他的学生Alex Krizhevsky、Ilya Sutskever整理的一个用于识别常见类别的小型数据集,它包含10个类别,50000幅训练图像和 10000幅测试图像。(4)ImageNet:ImageNet是一个大规模图像识别数据集,由李飞飞团队从2007年开始通过各种方式收集而成。ImageNet数据集包含了2万多个类别,超过1400万幅图像。
本章使用Caltech-101作为实验的数据集,随机选择60%的数据作为训练样本,在剩下的数据中,随机选择50%作为验证样本、另外50%作为测试样本。在图像分类中,通常以top-k错误率作为模型的度量指标之一。对于n幅测试图像样本,若模型预测的前k个类别中包含真实类别的测试图像的数量为m,设真实标签为( y ),模型预测的前k个类别为,则top-k错误率为:
基于视觉词袋模型的图像分类算法
视觉词袋模型(BoVW)概述
视觉词袋模型(Bag of Visual Words, BoVW)通过模拟文本处理中的词袋模型,将图像表示为局部特征的集合。核心思想是将图像中的局部特征(如SIFT、SURF)量化为"视觉单词",通过统计单词频率生成全局特征向量,用于分类任务。
算法原理
特征提取
使用SIFT或SURF等算法检测图像关键点并提取局部描述符(128维向量)。每张图像生成数百至数千个描述符,构成原始特征空间。
词典构建(聚类)
通过K-means对所有训练图像的描述符进行聚类,生成包含K个聚类中心的视觉词典。每个聚类中心代表一个"视觉单词",词典大小K通常为500-10000。
特征编码
将每张图像的描述符映射到最近的视觉单词,统计每个单词出现的频率,生成K维直方图(即词频向量)。可选改进方法:
- Soft-assignment:根据距离加权分配单词
- TF-IDF:降低高频但低区分度单词的权重
分类器训练
使用词频向量作为输入,训练SVM、随机森林等分类器。常见核函数选择:
- 线性核:适用于大规模数据
- 卡方核:针对直方图特征优化
实现步骤(Python示例)
依赖库
python
import cv2
import numpy as np
from sklearn.cluster import KMeans
from sklearn.svm import SVC1. 特征提取
python
def extract_features(image_paths):
sift = cv2.SIFT_create()
descriptors = []
for path in image_paths:
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
_, des = sift.detectAndCompute(img, None)
if des is not None:
descriptors.append(des)
return np.vstack(descriptors) # 合并所有描述符2. 构建视觉词典
python
def build_vocabulary(features, k=1000):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(features)
return kmeans.cluster_centers_ # 视觉单词3. 生成词频向量
python
def bow_histogram(vocab, descriptors):
k = vocab.shape[0]
hist = np.zeros(k)
if descriptors is not None:
distances = np.linalg.norm(descriptors[:, np.newaxis] - vocab, axis=2)
nearest_words = np.argmin(distances, axis=1)
for word in nearest_words:
hist[word] += 1
return hist / (np.sum(hist) + 1e-6) # 归一化4. 训练与预测
python
# 训练阶段
train_features = extract_features(train_images)
vocab = build_vocabulary(train_features, k=500)
train_vectors = [bow_histogram(vocab, des) for des in train_descriptors]
svm = SVC(kernel='linear').fit(train_vectors, train_labels)
# 测试阶段
test_img_des = extract_features([test_image_path])
test_vector = bow_histogram(vocab, test_img_des)
predicted_label = svm.predict([test_vector])改进方向
空间金字塔匹配(SPM)
将图像分块并在每个区域统计词频,增强空间信息表达能力。
深度特征替代
使用CNN的卷积层输出(如VGG的conv5特征)替代传统手工特征,提升判别力。
Fisher Vector编码
通过高斯混合模型(GMM)建模特征分布,捕获更丰富的统计信息。
Top-1Error:0.3001640240568617
可以发现,利用词袋模型在Caltech-101数据集上进行图像分类,top-1错误率约为30%。当然,也可以通过其他的方式在现有基础上降低模型的top-l错误率,可以使用Dense SIFT34替换SIFT从图像中提取特征。Dense SIFT算法是对SFT算法的改进版本,它先对输入图像分块处理,再对每一块进行SFT运算并提取特征。
不过这些改进效果提升不大,现在我们介绍基于深度卷积神经网络算法的图像分类算法在top1 error上面实现了大幅下降,重点
基于深度卷积神经网络的图像分类算法
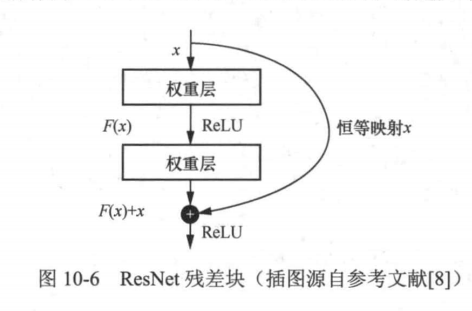
2012年,随着A1exNet的横空出世,基于深度卷积神经网络的方法逐渐成为计算机视觉领域的主流方法。对于图像分类任务,利用深度卷积神经网络可以实现从图像到分类标签的端到端预测,不再需要分阶段的表征提取与分类器训练。 ResNet网络是20l5年由微软亚洲研究院研究员何恺明等人提出的,斩获了当年ImageNet大规模视觉识别竞赛的图像分类任务和目标检测任务两个第一名。在ResNet提出之前,所有的神经网络都是由卷积层和池化层的叠加组成的(关于神经网络的相关知识,可参阅《动手学深度学习》)。人们认为卷积层和池化层的层数越多,获取的图像表征信息越强,学习效果就越好。但在实际的实验中研究人员发现,随着卷积层和池化层的叠加,不但没有出现学习效果越来越好的情况,反而出现了梯度消失和梯度爆炸,以及退化问题。在神经网络的反向传播中,每向前传播一层,都要乘以每一层的误差梯度,若误差梯度是一个小于1的数,当网络层数越来越多时,梯度会越来越小,出现梯度消失;若误差梯度是一个大于1的数,当网络层数越来越多时,梯度会越来越大,出现梯度爆炸。通过数据的预处理及在网络中使用批量标准化(batch normalization,BN)层可以解决梯度消失或梯度爆炸问题。退化问题是指层数更多的网络在训练集和测试集上的表现不如层数少的网络。针对退化问题,ResNet引入了残差块(如图10-6所示),增加了恒等映射作为短路连接(shortcut connection),跨越几个层,将输入添加到输出。
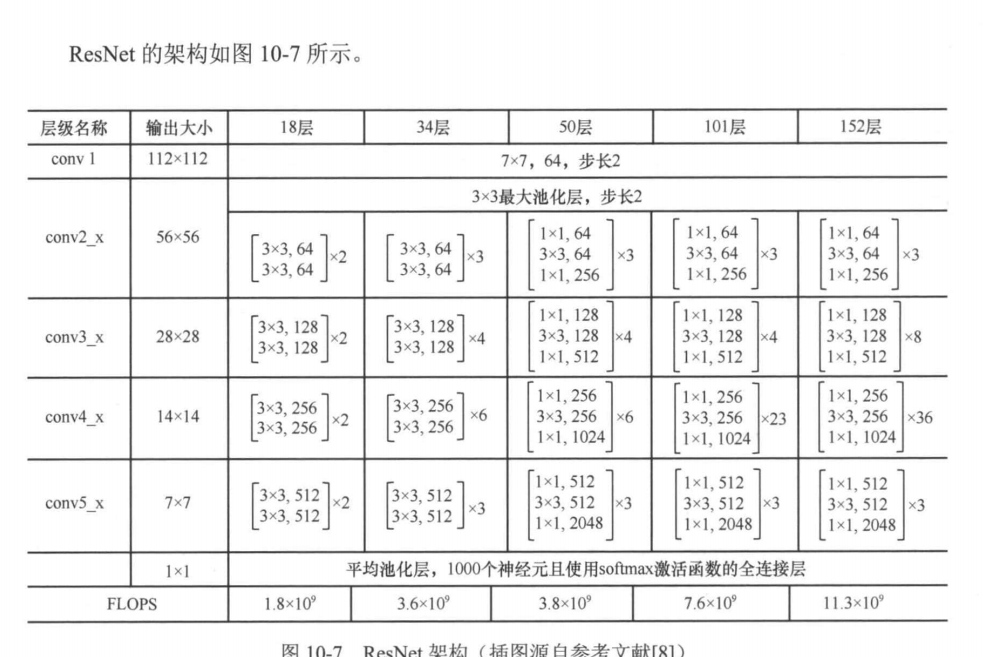
我们可以根据架构图很轻松的复现resnet这一经典的网络
我们以使用ResNet18进行图像分类为例进一步说明ResNet的架构。将一幅分辨率为224像素×224像素的RGB图像输入ResNet,.ResNet通过conv1层网络对其进行卷积,得到一个空间分辨率为112像素×112像素、通道数为64的特征图。回顾在第2章中介绍的二维卷积,可以知道,由于cov1层中卷积的步长设置为2,因此得到的特征图的空间分辨率只有输入图像的1/4。通道数为64的特征图是怎么来的?
我们在第2章中介绍了用一个k×k卷积核对输入图像做卷积,会得到一个通道数为1的特征图。那么,通道数为64的特征图就是用64个k×k卷积核对输入图像做卷积,然后将得到的64个通道数为1的特征图沿特征维度拼接得到的。注意,特征图也可以看成一幅图像,所以,我们可以通过卷积来改变特征图的通道数,即特征维度。一般来说,对一个通道数为t、空间分辨率为H×W的特征图,使用、个卷积核同时对该特征图进行卷积,便可输出一个通道数为s的特征图。由此可见,通过卷积可以完成对特征图特征维度的升维和降维,这个性质非常有用。
在conv1层之后,ResNet依次通过4个模块,每个模块都将特征图的空间分辨率缩小1/4,最终conv5x的输出是一个512通道的7像素×7像素的特征图。在此之后,将特征图依次输入全局平均池化层和一个具有1000个神经元且使用softmax激活函数的全连接层。全连接层将一个任意通道数的特征图映射到一个维度为类别数目的向量,该向量表示模型预测的类别的概率分布。最终,可以根据这一概率分布,预测图像的类别。为了更深入地了解ResNet,我们动手编写ResNet34网络。
ResNet34代码实现
首先我们创建model.py文件,其实也没必要可以通过
model = torchvision.models.resnet34(pretrained='imagenet')调用
但是为了学习可以进行参考具体实现方法
python
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)编写基于ResNet-34的图像分类任务
先下载Caltech101数据集Caltech 101
然后解压
bash
unzip caltech-101.zip
tar -xvf Annotations.tar
tar -xzvf 101_ObjectCategories.tar.gz 创建main.py
python
# 图像分类
import torch.optim as optim
import torch.nn as nn
import torch
import torchvision
import torchvision.transforms as transforms
import torch.utils.data as data
from sklearn.model_selection import train_test_split
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
from imutils import paths
from PIL import Image
import torchvision.datasets as datasets
from torch.utils.data import DataLoader,Dataset
# 进行训练集数据增强
train_transformer = transforms.Compose([
transforms.ToPILImage(), # 将numpy数组转换为PIL格式
# transforms.ColorJitter(brightness=0.2, contrast=0.2), # 新增颜色增强
# transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.RandomResizedCrop(size=224, scale=(0.8, 1.0)), # 随机缩放并裁剪到 224x224
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]), # 归一化
])
# 验证集通常不包含数据增强操作(如随机裁剪、翻转等)但是要保持相同的图像大小(224x224)和归一化参数
val_transformer = transforms.Compose([
transforms.ToPILImage(), # 将numpy数组转换为PIL格式
transforms.Resize((224, 224)), # 调整图像大小(与训练集相同)
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]), # 归一化
])
# 图像数据
data=[]
# 标签数据
labels=[]
# 储存标签的临时变量
labels_tep=[]
# 获取caltech101文件夹下的全部图片的列表
image_paths=list(paths.list_images('./caltech-101/'))
# ./caltech-101/101_ObjectCategories/elephant/image_0001.jpg
# ./caltech-101/101_ObjectCategories/elephant/image_0057.jpg
step=0
for image_path in image_paths:
# 获取倒数第二个'/'前的文本也就是label elephant
label=image_path.split(os.path.sep)[-2]
# 读取
image=cv2.imread(image_path)
# 将图像从BGR转向RGB OpenCV默认使用BGR格式读取图像,而大多数深度学习框架(如TensorFlow/PyTorch)使用RGB格式
image=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
# 统一输入图像尺寸 使用INTER_AREA插值方法,适合缩小图像时保持清晰度
image=cv2.resize(image,(224,224),interpolation=cv2.INTER_AREA)
data.append(image)
labels_tep.append(label)
# 构建标签映射
unique_labels = sorted(set(labels_tep))
name2label = {label: idx for idx, label in enumerate(unique_labels)}
# print(name2label)
# 生成数字标签
labels = [name2label[label] for label in labels_tep]
# print(labels)
# 转成numpy数组
data=np.array(data)
labels=np.array(labels)
# 将数据划分成训练集和验证集和测试集
# X_train和y_train:60%的训练数据 其他数据用于验证和测试40%
X_train,X,y_train,Y=train_test_split(data,labels,test_size=0.4,random_state=42)
# X_val和y_val:20%的验证数据 另外20%用于测试
X_val,X_test,y_val,y_test=train_test_split(X,Y,test_size=0.5,random_state=42)
# (5486, 224, 224, 3) (1829, 224, 224, 3) (1829, 224, 224, 3)
print(X_train.shape,X_val.shape,X_test.shape)
# 把caltech101数据集封装成Dataset类
class Caltech101Dataset(Dataset):
def __init__(self, image,label=None,transform=None):
self.image = image
self.label = label
self.transform = transform
def __len__(self):
return len(self.image)
def __getitem__(self, index):
img = self.image[index]
if self.transform is not None:
img = self.transform(img)
if self.label is not None:
label = self.label[index]
return img,label
else:
return img
# 生成不同类用于训练和验证和测试
train_dataset =Caltech101Dataset(X_train,y_train,transform=train_transformer)
val_dataset =Caltech101Dataset(X_val,y_val,transform=val_transformer)
test_dataset =Caltech101Dataset(X_test,y_test,transform=val_transformer)
# # 冻结参数(可选),冻结后训练速度更快,但是准确率会下降
# # for param in model.parameters():
# # param.requires_grad = False
# 加载ResNet34模型
model = torchvision.models.resnet34(pretrained='imagenet')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 把模型转移到GPU上
model.to(device)
# 定义训练函数
def fit(model, dataloader, optimizer, criterion):
model.train()
running_loss = 0.0
running_top1_error = 0
for i, data in enumerate(dataloader):
x, y = data[0].to(device), data[1].to(device)
# 梯度清零
optimizer.zero_grad()
outputs = model(x)
# 计算损失
loss = criterion(outputs, y)
running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
running_top1_error += torch.sum(preds != y).item()
loss.backward()
optimizer.step()
loss = running_loss / len(dataloader.dataset)
top1_error = running_top1_error / len(dataloader.dataset)
print(f"Train Loss: {loss:.4f}, Train Top-1 Error: {top1_error:.4f}")
return loss, top1_error
# 定义验证函数
def validate(model, dataloader, criterion):
model.eval()
running_loss = 0.0
running_top1_error = 0
with torch.no_grad():
for i, data in enumerate(dataloader):
x, y = data[0].to(device), data[1].to(device)
outputs = model(x)
loss = criterion(outputs, y)
running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
running_top1_error += torch.sum(preds != y).item()
loss = running_loss / len(dataloader.dataset)
top1_error = running_top1_error / len(dataloader.dataset)
print(f'Val Loss: {loss:.4f}, Val Top-1 Error: {top1_error:.4f}')
return loss, top1_error
# 定义测试函数
def test(model, dataloader):
top1_error = 0
total = 0
with torch.no_grad():
for data in dataloader:
x, y = data[0].to(device), data[1].to(device)
outputs = model(x)
_, predicted = torch.max(outputs.data, 1)
total += y.size(0)
top1_error += torch.sum(predicted != y).item()
return top1_error, total
# 主训练流程
def main():
# 每次传入批次大小,不建议太大
BATCH_SIZE = 64
# 训练轮数
epochs = 25
trainloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valloader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
testloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 模型和优化器初始化
model = torchvision.models.resnet34(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(unique_labels))
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
train_loss, train_top1_error = [], []
val_loss, val_top1_error = [], []
print(f"Training on {len(train_dataset)} examples, validating on {len(val_dataset)} examples...")
for epoch in range(epochs):
print(f"\nEpoch {epoch+1} of {epochs}")
train_epoch_loss, train_epoch_top1_error = fit(model, trainloader, optimizer, criterion)
val_epoch_loss, val_epoch_top1_error = validate(model, valloader, criterion)
train_loss.append(train_epoch_loss)
train_top1_error.append(train_epoch_top1_error)
val_loss.append(val_epoch_loss)
val_top1_error.append(val_epoch_top1_error)
torch.save(model.state_dict(), "model.pth")
# 绘制曲线
plt.figure(figsize=(10, 7))
plt.plot(train_top1_error, label='train top-1 error')
plt.plot(val_top1_error, label='validation top-1 error')
plt.xlabel('Epoch')
plt.ylabel('top-1 Error')
plt.legend()
plt.show()
plt.figure(figsize=(10, 7))
plt.plot(train_loss, label='train loss')
plt.plot(val_loss, label='validation loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
top1_error, total = test(model, testloader)
print(f'Top-1 Error of the network on test images: {100 * top1_error / total:.3f}%')
if __name__ == "__main__":
main()训练结果如下,可以训练更多轮,或者调大批次比如64->2048
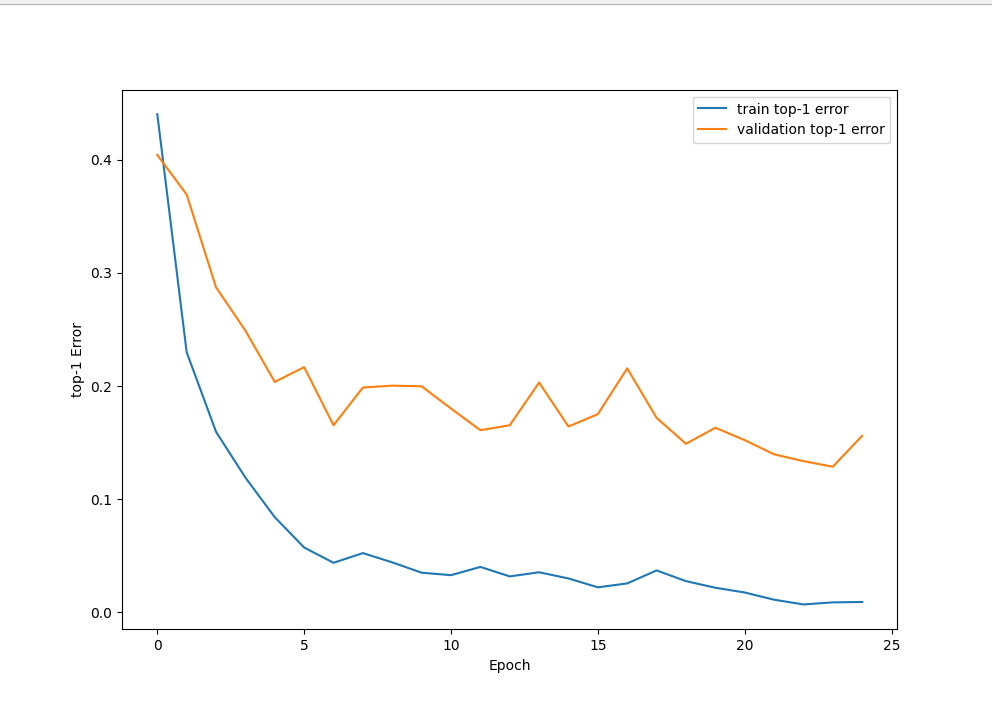
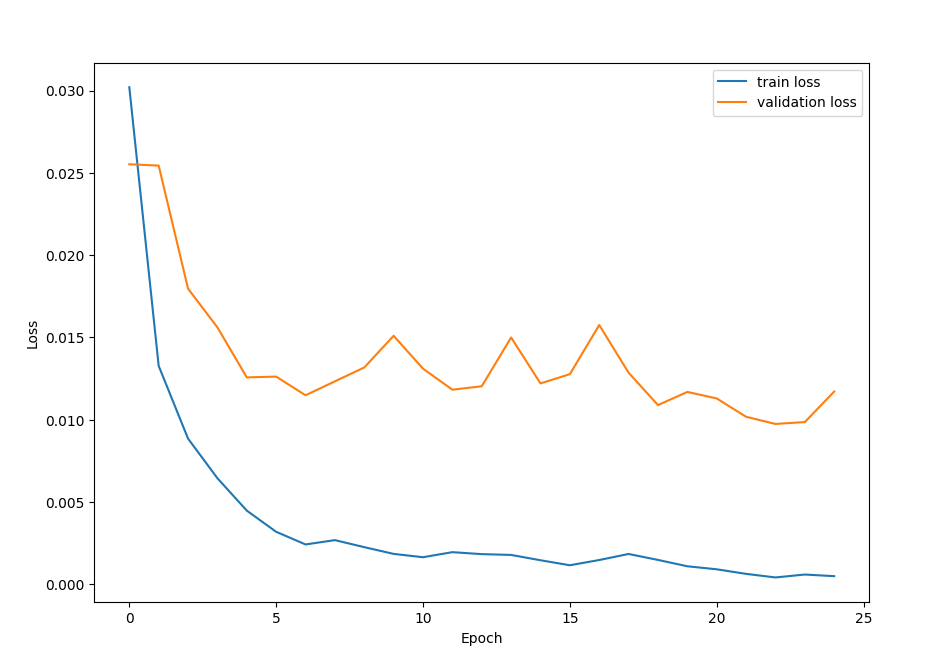
Top-1 Error of the network on test images: 15.090%
调大批次为2048训练25轮结果是
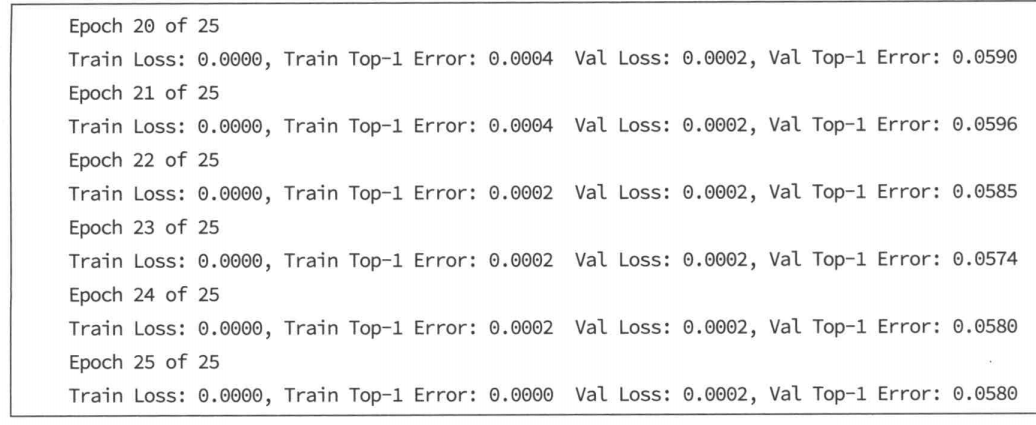
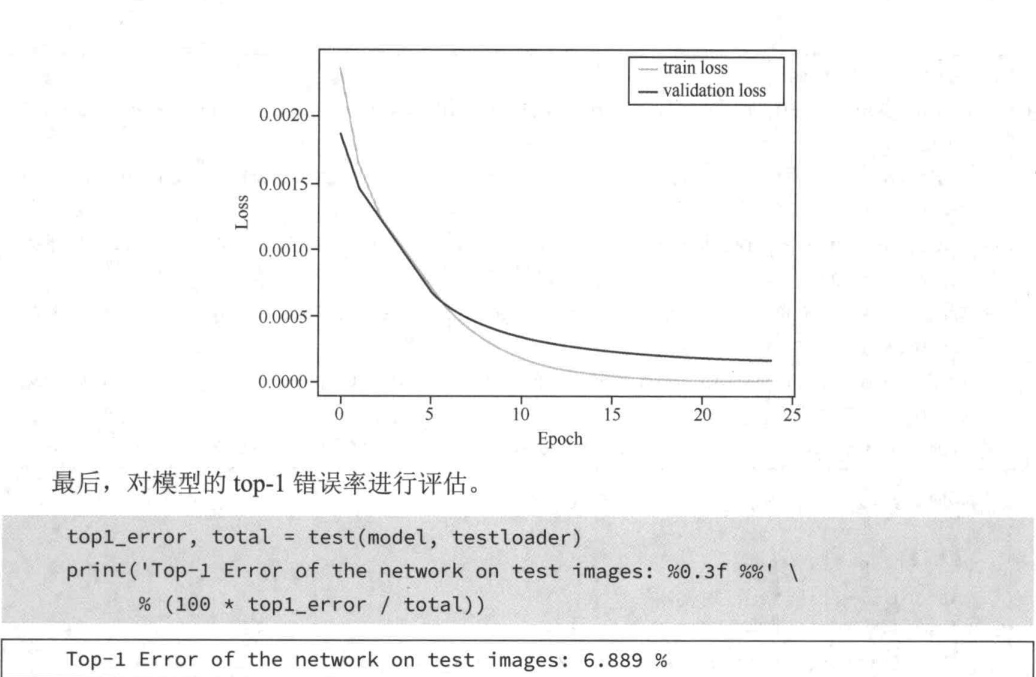
小结
本章介绍了视觉识别中最基本的问题之一图像分类 。本章先后讲解了基于手工设计图像表
正(视觉词袋模型)的图像分类算法和基于深度卷积神经网络的图像分类算法。在后续的章节中,
我们将介绍如何把基于深度卷积神经网络的图像分类算法推广到其他的视觉识别问题中。