文章目录
- 1.Spark任务阶段划分
-
- [1.1 job,stage与task](#1.1 job,stage与task)
- [1.2 job划分](#1.2 job划分)
- [1.3 stage和task划分](#1.3 stage和task划分)
- 2.任务执行时机
- 3.task内部数据存储与流动
- 4.根据sparkUI了解Spark执行计划
-
- 4.1查看job和stage
- [4.2 查看DAG图](#4.2 查看DAG图)
- 4.3查看task
1.Spark任务阶段划分
1.1 job,stage与task
- 首先根据action()操作顺序将应用划分为作业job。
- 根据每个job的逻辑处理流程中的ShuffleDependency依赖关系,将job划分为执行阶段stage。
- 在每个stage中,根据最后生成的RDD的分区个数生成多个计算任务task。
1.2 job划分
举一个简单的例子,在下面这段代码中:
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum, count, col
# 初始化SparkSession
spark = SparkSession.builder.appName("MultiJobStageTaskExample").getOrCreate()
# 读取数据(Transformation,不触发Job)
orders = spark.read.csv(
"orders.csv",
header=True,
inferSchema=True
).select("用户ID", "订单金额", "支付方式")
users = spark.read.csv(
"users.csv",
header=True,
inferSchema=True
).select("用户ID", "所在城市")
# 缓存重复使用的数据集(优化性能)
orders.cache()
users.cache()
# --------------------------
# Job 1:计算不同支付方式的订单数和总金额
# --------------------------
payment_analysis = orders.groupBy("支付方式") \
.agg(
count("用户ID").alias("订单数"), # 聚合操作(宽依赖,触发Shuffle)
sum("订单金额").alias("总金额")
)
# Action操作:触发Job 1
payment_result = payment_analysis.collect() # Job 1
print("支付方式分析结果:", payment_result)
# --------------------------
# Job 2:计算每个城市的平均订单金额
# --------------------------
city_analysis = orders.join(users, on="用户ID", how="inner") \ # join是宽依赖(Shuffle)
.groupBy("所在城市") \ # 再次宽依赖(Shuffle)
.agg(
sum("订单金额").alias("城市总金额"),
count("用户ID").alias("城市订单数")
) \
.withColumn("平均订单金额", col("城市总金额") / col("城市订单数"))
# Action操作:触发Job 2
city_analysis.write.csv("city_avg_order") # Job 2
# --------------------------
# Job 3:统计高消费用户(订单总金额>10000)的分布
# --------------------------
high_value_users = orders.groupBy("用户ID") \ # 宽依赖(Shuffle)
.agg(sum("订单金额").alias("用户总消费")) \
.filter(col("用户总消费") > 10000) \ # 过滤(窄依赖)
.join(users, on="用户ID", how="inner") # 宽依赖(Shuffle)
# Action操作:触发Job 3
high_value_count = high_value_users.count() # Job 3
print("高消费用户数量:", high_value_count)
spark.stop()根据payment_analysis.collect(),city_analysis.write.csv("city_avg_order")和high_value_count = high_value_users.count(),这段代码被划分成了三个job。
1.3 stage和task划分
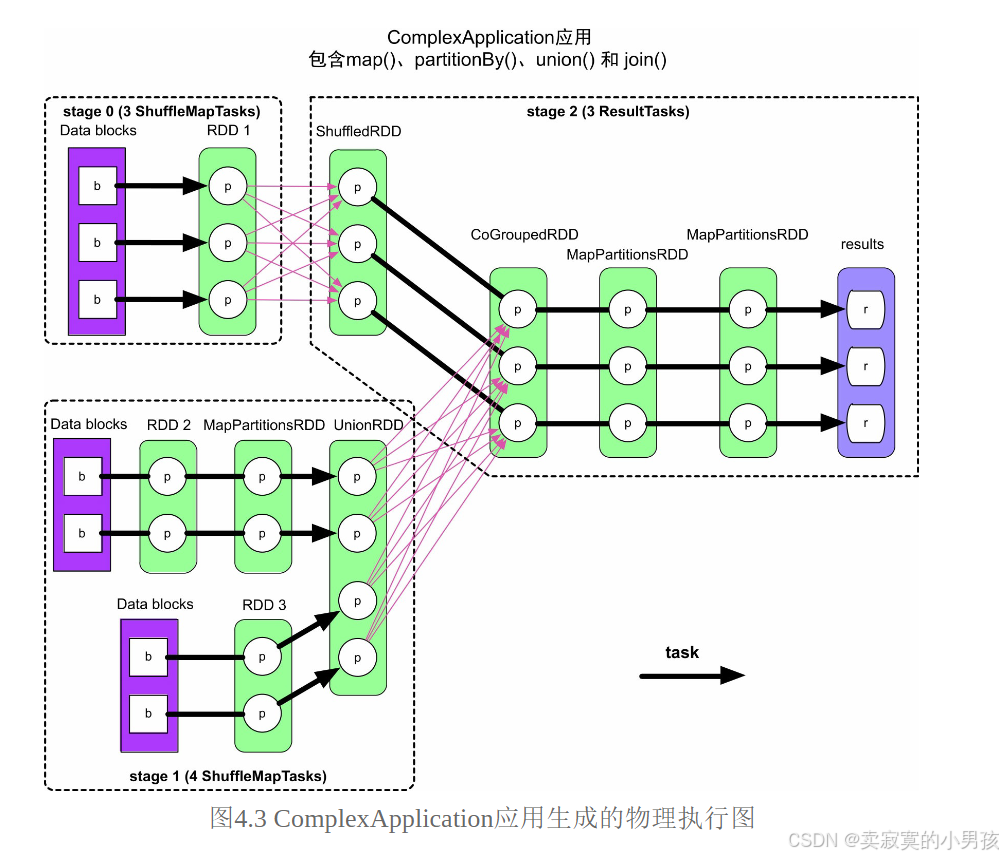
如下图所示,在一个job中,出现了shuffle操作,就会划分一个stage。再根据每个stage中的分区数量划分task数量。
2.任务执行时机
- job的提交时间与action()被调用的时间有关,当应用程序执行到rdd.action()时,就会立即将rdd.action()形成的job提交给Spark。这其实也就是为什么有的时候写完代码没有运行的原因,因为没写action()操作,job不会被提交到Spark。
- 仅当上游的stage都执行完成后,再执行下游的stage。如果stage之间没有依赖,则并行执行,例如stage1和stage0是并行执行,当且仅当两者执行后,stage2才开始执行。
- stage中每个task因为是独立而且同构的,可以并行运行没有先后之分。
3.task内部数据存储与流动
task是根据分区来划分的,而一个分区中有很多个record,根据不同record之间的关系,存储的方式也不同:
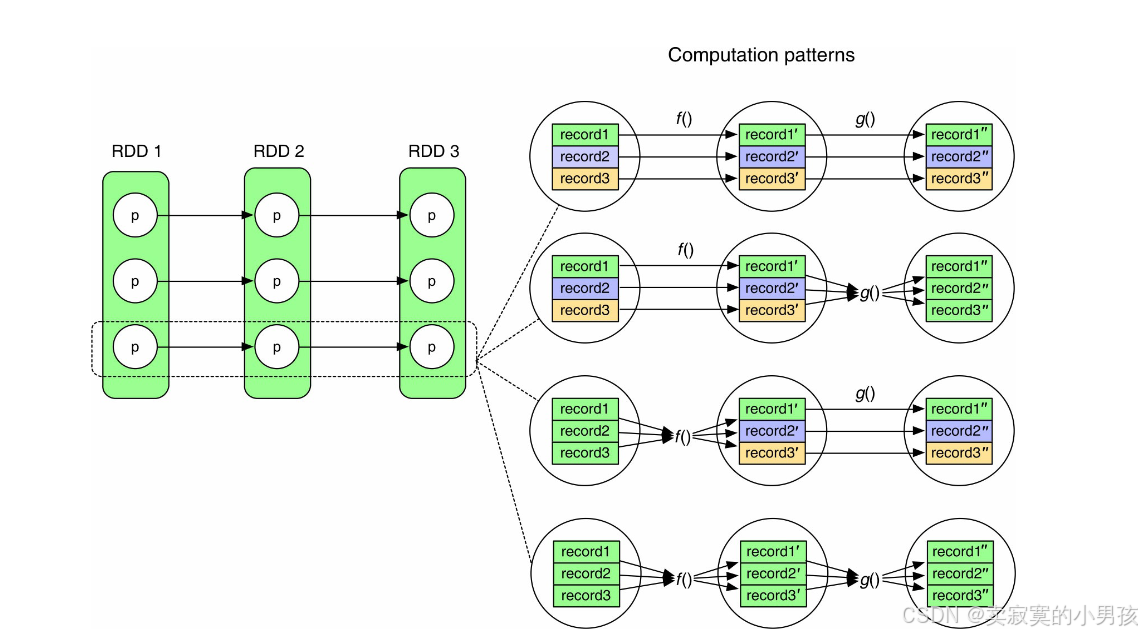
这是一个task的执行流程的几种不同的情况:
- 第一个流程:record之间并没有相互依赖,因此可以进行流式处理,即record1处理成record1'之后就可以将record1从内存中删掉,而不用关心record2和record3处理到哪里了。
- 第二个流程:f()流程无相互依赖,但是g()流程有相互依赖,也就是说record1在处理成record1''后,record1''会被保存到内存中,直到record2''和record3''被处理完成。
- 第三个流程:同理,在record1,record2和record3都被算出之后,才能执行f(),而在执行g()时,record1',record2'和record3'才不会相互依赖。
- 第四个流程:无法进行流水线处理,每处理完一个操作,才能回收该操作的输入结果。
4.根据sparkUI了解Spark执行计划
4.1查看job和stage
在spark的首界面可以看到当前正在执行的job:

点击job的链接,可以看到当前job中的stage数量:

其中stage 0包含3个task,共Shuffle Write了376.0B,stage 1包含4个task,共Shuffle Write了988.0B,而stage 2包含3个task,一共Shuffle Read了1364.0B=376.0B+988.0B。
4.2 查看DAG图
将Job链接中界面上的DAG Visualization展开,可以看到正在执行的DAG图:
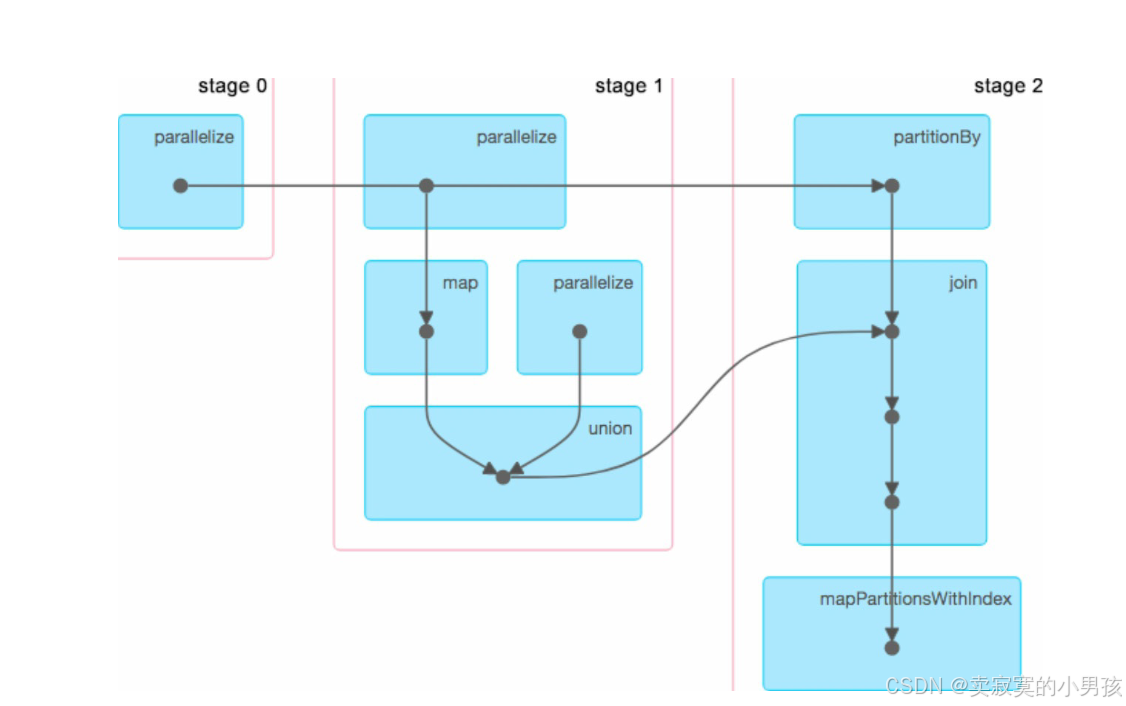
每个黑色实心圆圈代表一个RDD,但这个图稍显混乱,stage 0中parallelize操作生成的RDD应该是被stage 2中的partitionBy处理的,与stage 1中的parallelize无关,也就是stage 0到stage 2的横箭头并没有在stage1中作停留生成一个RDD。
如果想进一步了解黑色实心圆圈代表哪些RDD,则可以进入stage的UI界面:
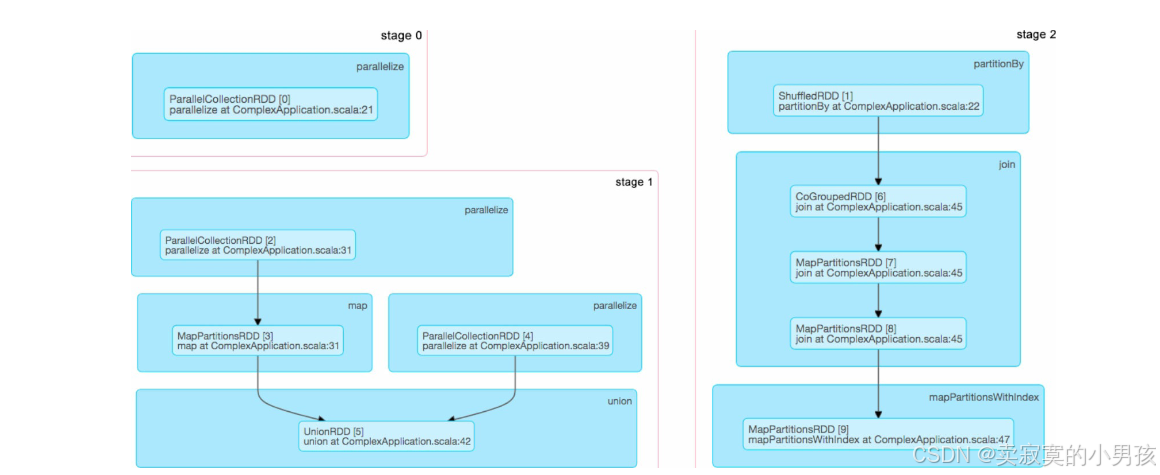
这张图展示了每个操作会生成哪些RDD(如join()操作生成了CoGroupedRDD及两个MapPartitionsRDD),但没有展示stage之间的连接关系。但是没有展示Stage的连接关系。
4.3查看task
在某个stage界面,可以看到该stage的task信息:

stage 0包含3个task,每个task都进行了Shuffle Write,写入了2~3个record,也就是说Spark UI中也会统计Shuffle Write/Read的record数目。

stage 1包含4个task,每个task都进行了ShuffleWrite,写入了2个record。

stage 2包含3个task,每个task从上游的stage 0/1那里Shuffle Read了5~6个record。