- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
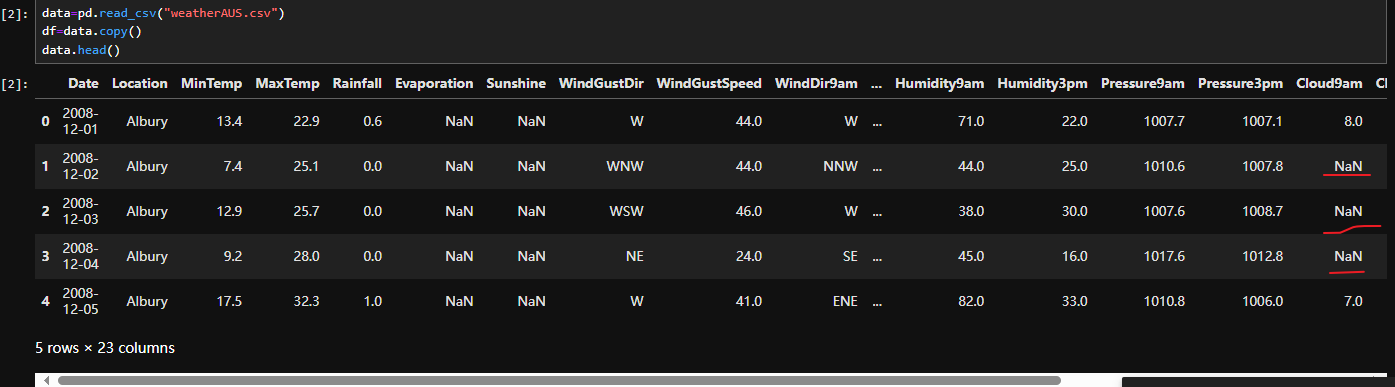
一、导入数据
1. 导入需要的库
其中,Seaborn是基于matplotlib的Python可视化库。它提供了一个高级界面来绘制有吸引力的统计图形,在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致。
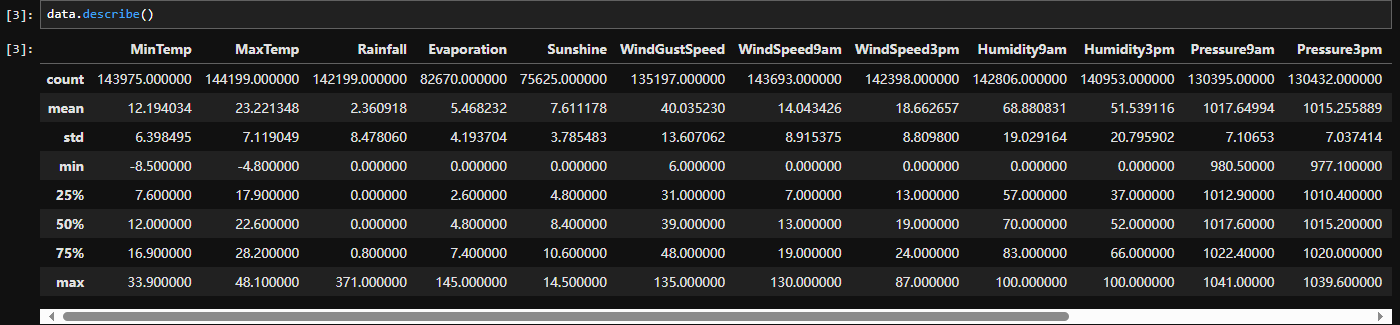
Pandas 库中 DataFrame 对象的一个方法,用于计算每个数值列的基本描述统计信息。
.describe() 是Pandas 库中 DataFrame 对象的一个方法,用于计算每个数值列的基本描述统计信息,可以将数据集的各个统计量以表格形式展示出来,其中包括:
count:非缺失值的数量。
mean:平均值。
std:标准差。
min:最小值。
25%:第一四分位数。
50%:中位数(第二四分位数)。
75%:第三四分位数。
max:最大值。
默认情况下,.describe() 只会计算数值特征的描述性统计量,如果需要包括所有特征,可以使用 include='all' 参数。还可以使用 exclude 参数排除某些特征的统计量
二、探索式数据分析(EDA)
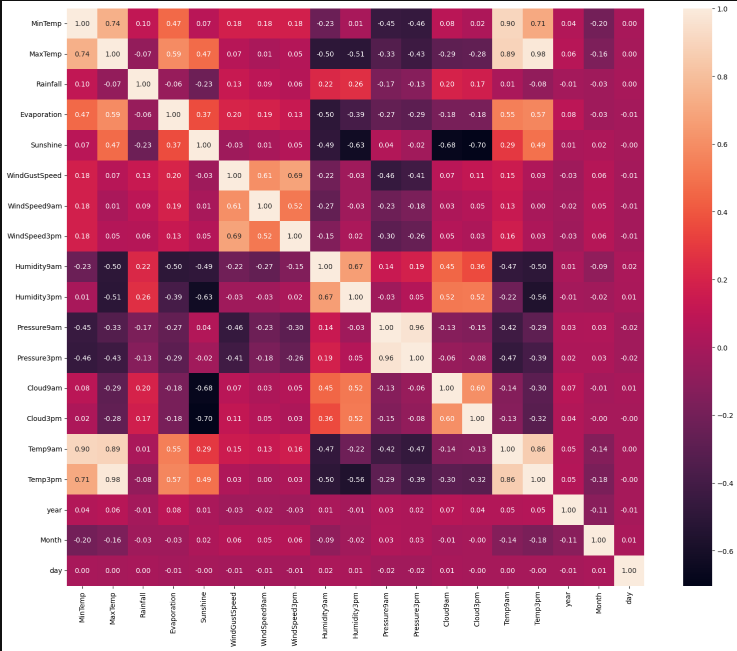
2.1数据相关性探索
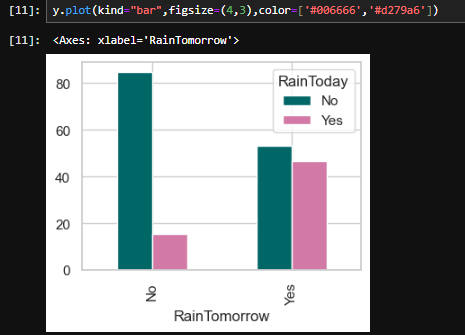
2.2是否会下雨
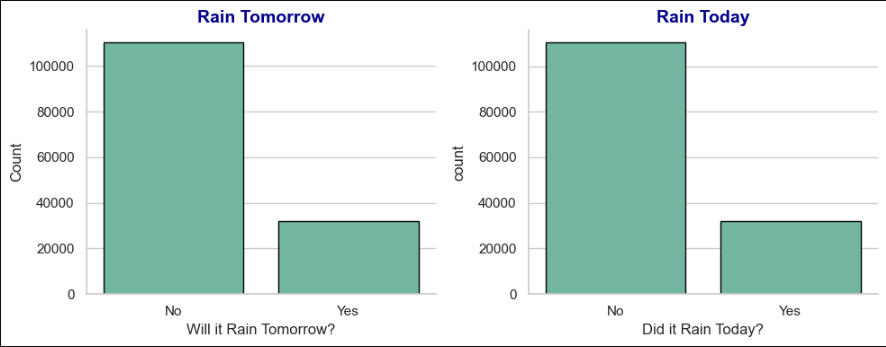
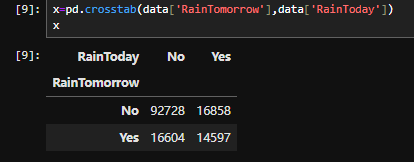
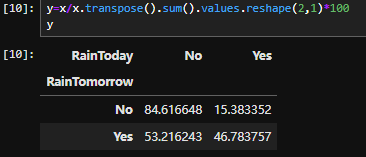
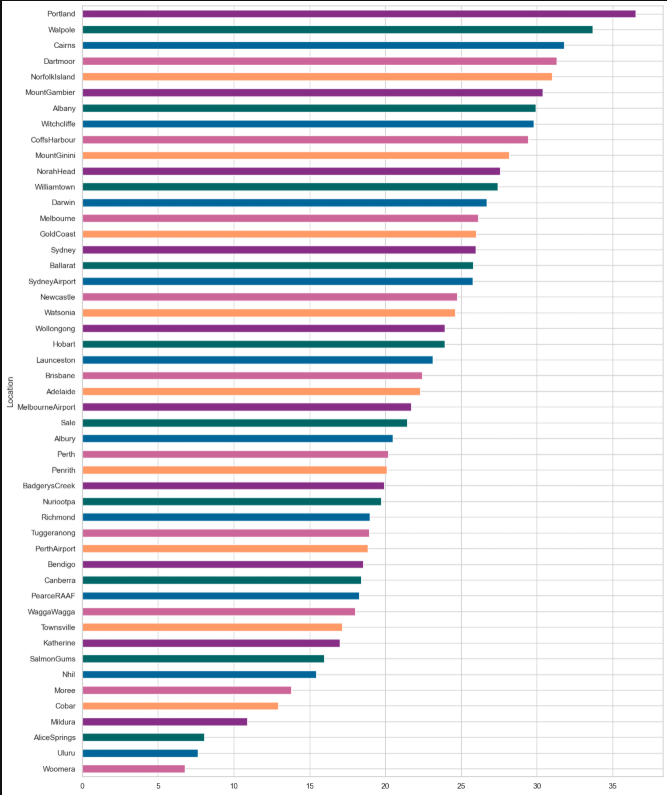
2.3地理位置与下雨的关系
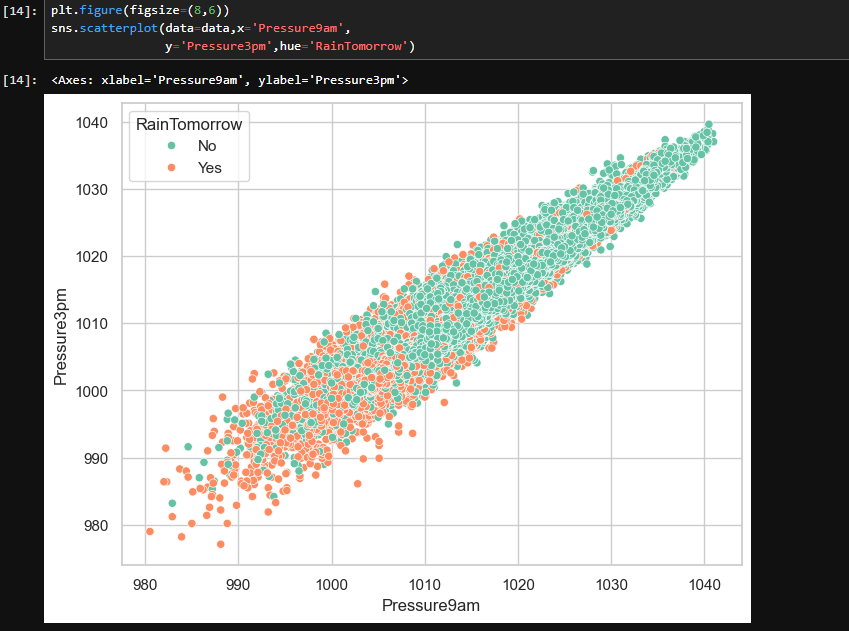
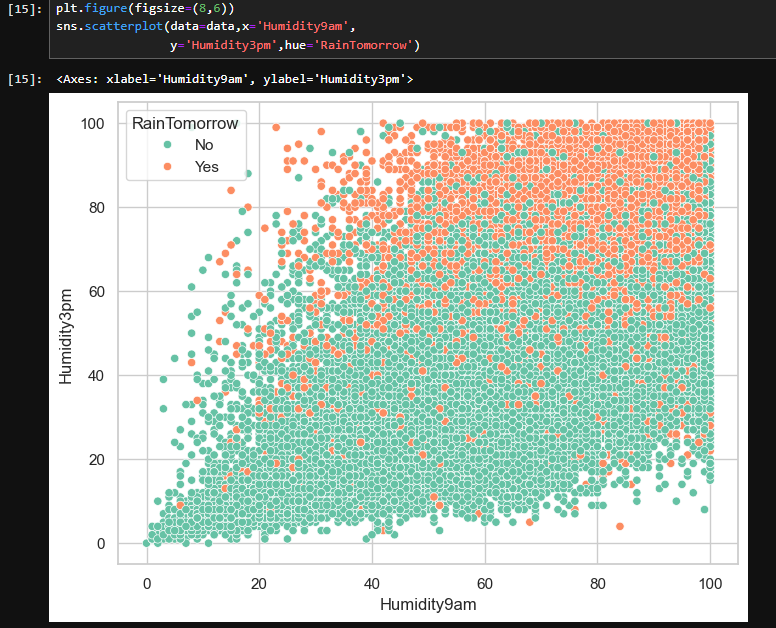
2.4湿度和压力对下雨的影响
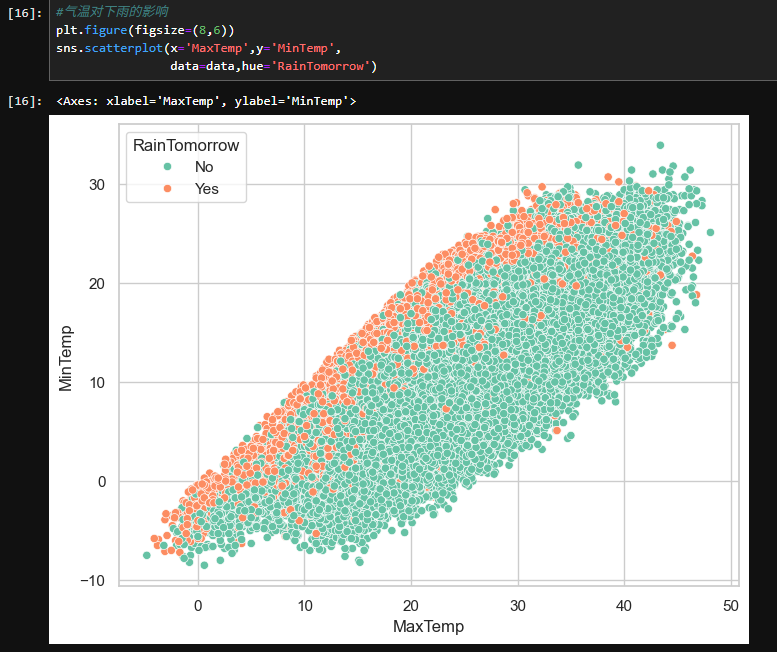
2.5气温对下雨的影响
三、数据预处理
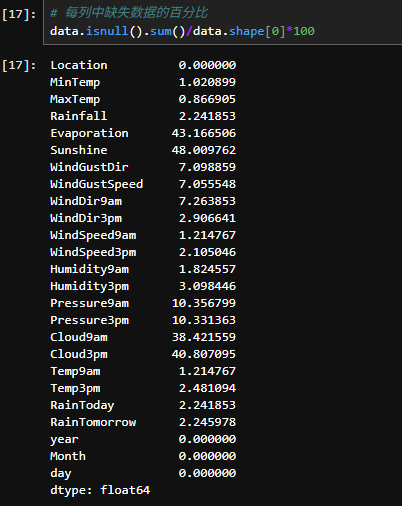
3.1处理缺损值
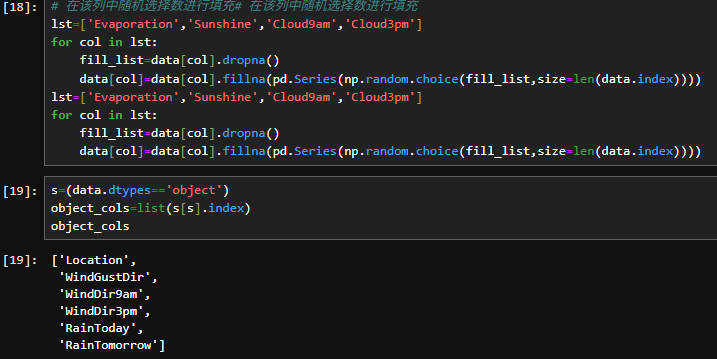
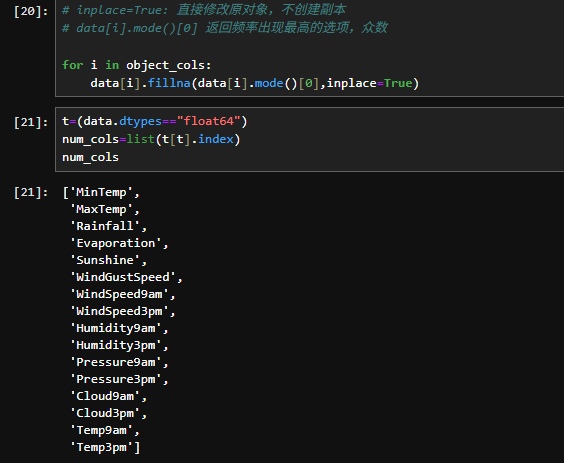
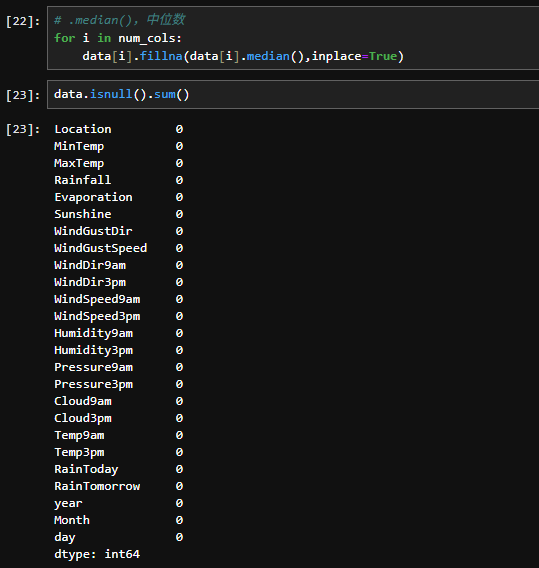
3.2构建数据集
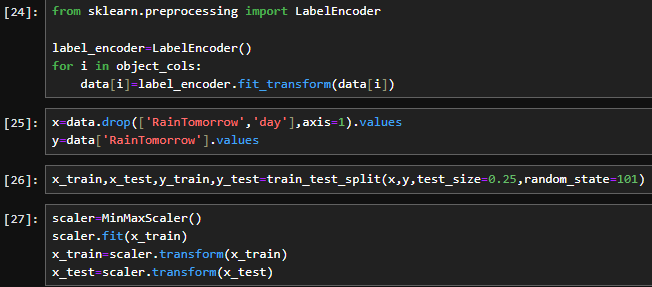
四、预测是否下雨
4.1搭建神经网络
python
from tensorflow.keras.optimizers import Adam
model=Sequential()
model.add(Dense(units=24,activation='tanh'))
model.add(Dense(units=18,activation='tanh'))
model.add(Dense(units=23,activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(units=12,activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=1,activation='sigmoid'))
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics="accuracy")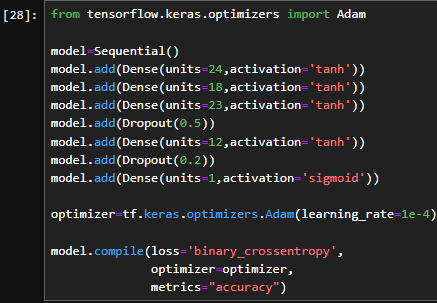
4.2模型训练
4.3结果可视化
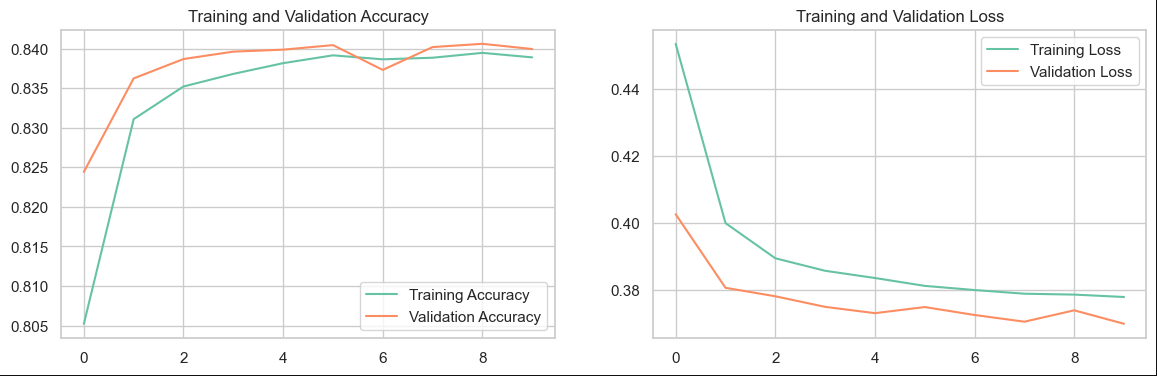
五、总结
对使用 LSTM 模型进行天气预测任务的优缺点总结,并结合 Seaborn 可视化分析时常见的观察点进行说明:
一、LSTM 在天气预测中的优点
捕捉长期依赖关系,天气数据(如温度、湿度序列)具有强时间依赖性(如季节周期、连续数天的趋势)。LSTM 的门控机制(遗忘门、输入门、输出门)能有效学习长期模式。
可视化验证:使用 Seaborn 的 lineplot()绘制真实值 vs 预测值,可观察到模型对趋势拐点(如寒潮来临)的跟踪能力。
通过 lag_plot()分析残差自相关性,若滞后效应弱(点分布无模式),说明模型已捕捉长期依赖。
处理多元时间序列。天气预测需整合多变量(温度、气压、风速等)。LSTM 天然支持多输入特征,能建模变量间复杂相互作用。
二、LSTM 在天气预测中的缺点
2.1计算复杂度高
劣势:LSTM 参数量大,需大量数据和计算资源训练。
可视化验证:训练损失曲线(Seaborn lineplot())收敛缓慢,需更多 epoch。
资源监控显示 GPU/CUP 占用率高且耗时长。
2.2超参数调优敏感
劣势:层数、隐藏单元数、学习率等显著影响结果。
可视化验证:
使用 boxplot()对比不同超参数组合的 RMSE 分布,可观察到性能波动大。
学习率扫描图(lineplot()损失 vs 学习率)显示最优区间狭窄。
2.3短期突变预测困难
劣势:对突发天气事件(如雷暴)响应滞后,因依赖历史模式。
可视化验证:
在突变时间点放大预测曲线(lineplot()),可见明显预测延迟。
误差时间序列图(lineplot())在突变时段出现尖峰。
2.4长期预测误差累积
劣势:递归预测时误差逐步放大,尤其超过 7 天。
可视化验证:多步预测图中,随着时间步增加,预测区间(用 fill_between()绘制)显著变宽。
RMSE 随预测步长增长的曲线(lineplot())呈上升趋势。