视频链接
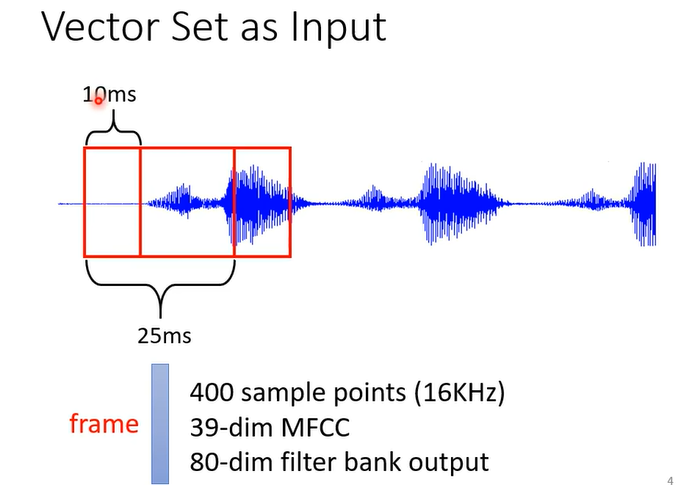
Input:一组有意义的向量
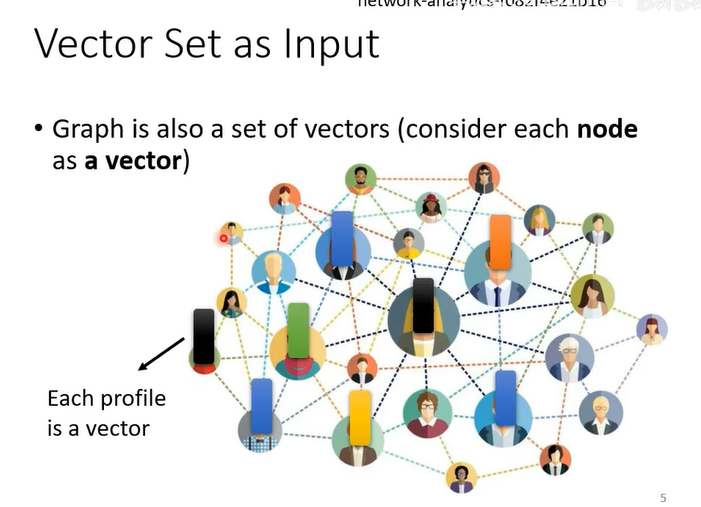
一个社交网络也可以看作一组向量
一个分子也能当做向量
output有三种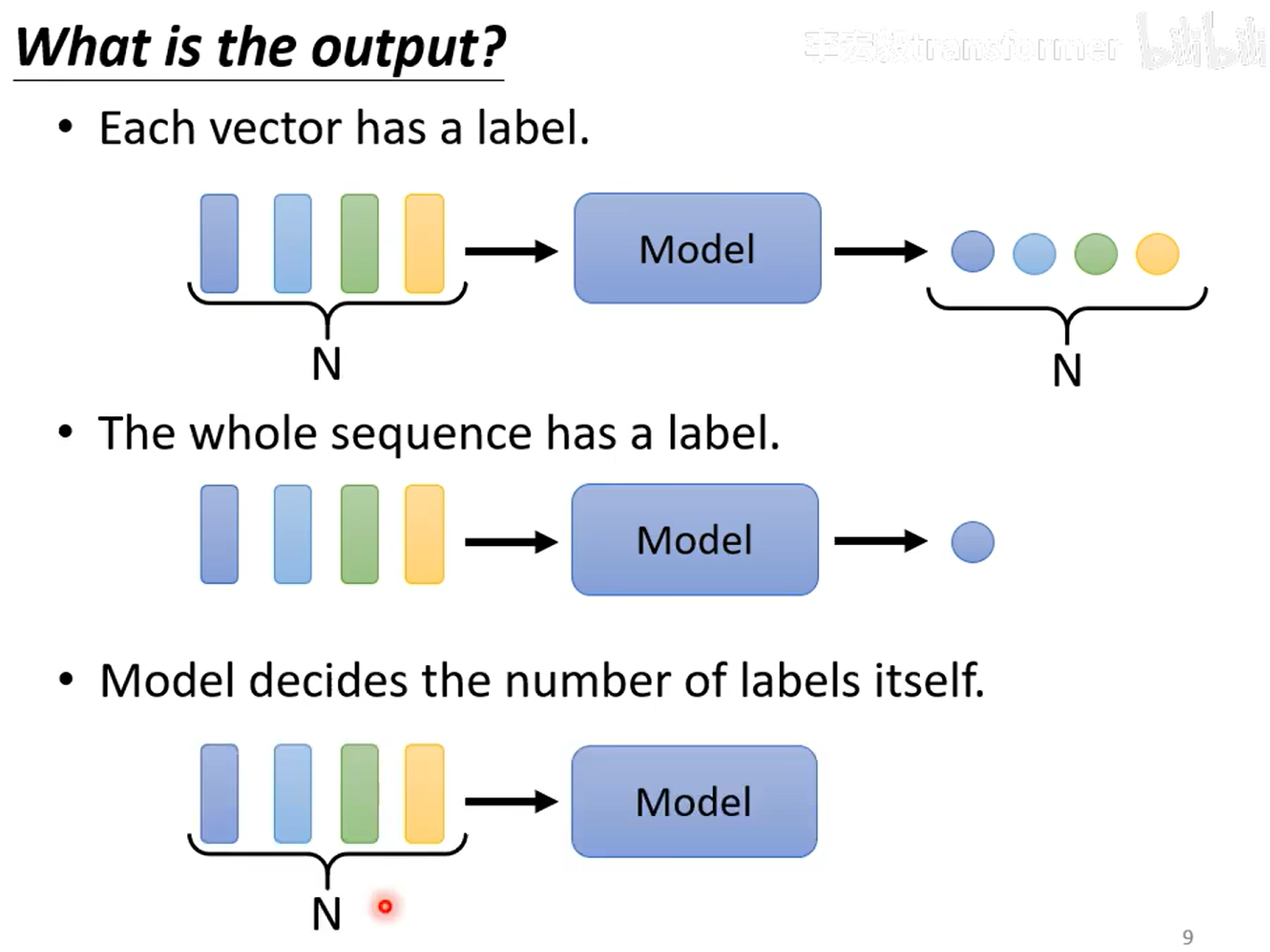
1、每个向量一个label
比如
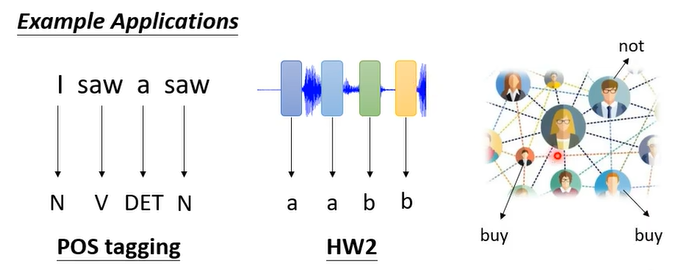
图1:一个句子的每个单词是什么类型(名词、动词)
图2:一串声音讯号里面每一段是哪一个音标
图3:每个结点有什么特性,是否会买商品
2、整个序列一个label
比如
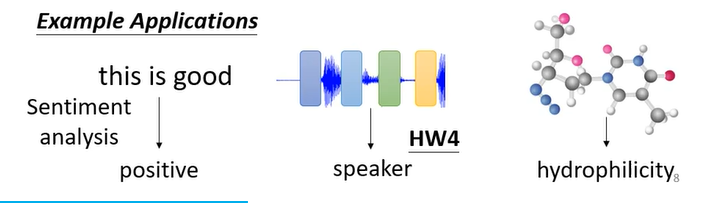
图1:判断该评价是正面还是负面
图2:根据语音判断语者
图3:给一个分子预测这个分子的亲水性怎么样
3、不知道应该输出多少label,机器自己决定(seq2seq)
比如翻译就是
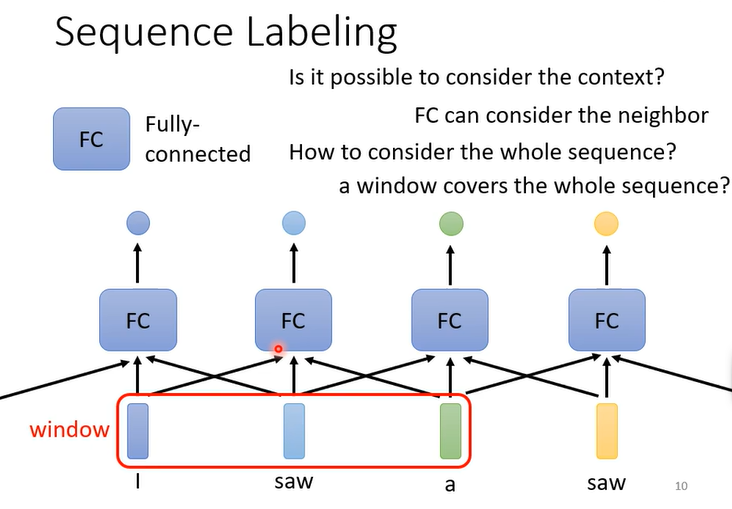
Sequence Labeling(output中的第一种)
单一的输入一个单词输出一个label会使两个saw输出同样的结果,所以为了使效果更好还要输入上一个单词和下一个单词
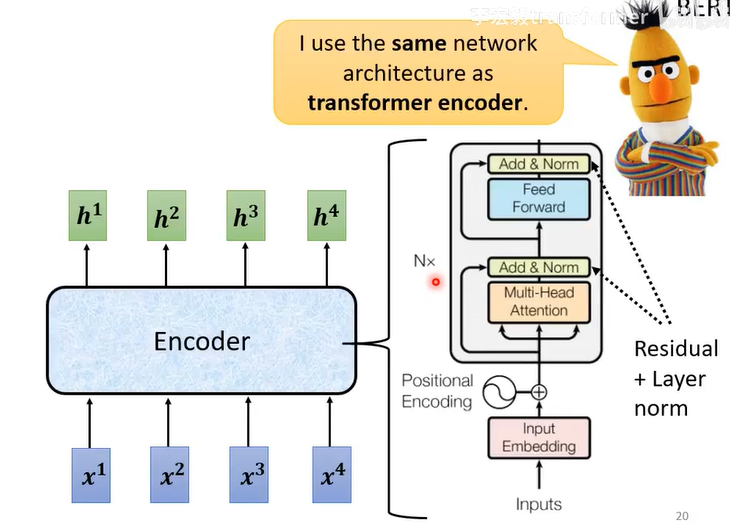
FC是全连接神经网络(Fully Connected Neural Network)
Self-attention
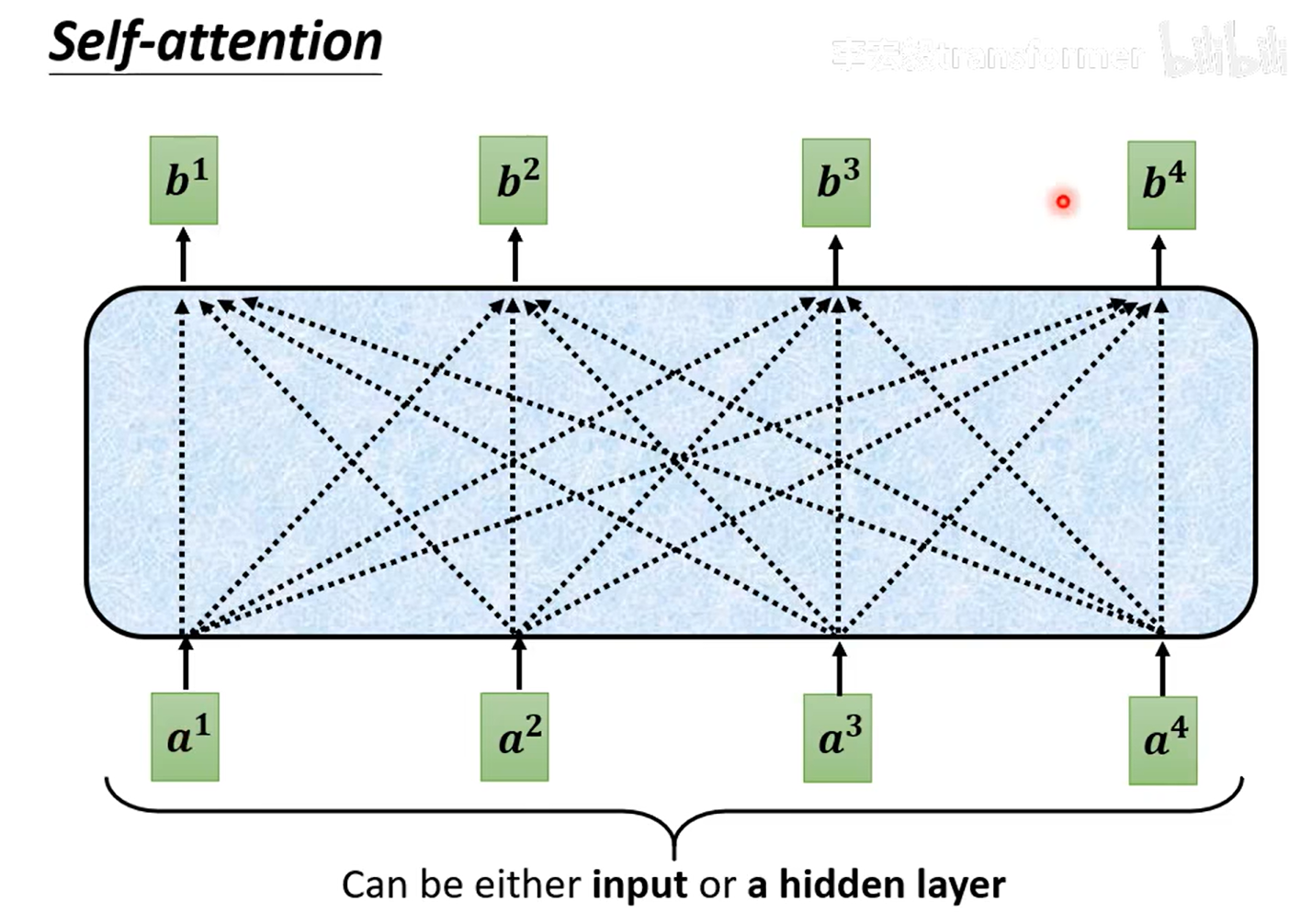
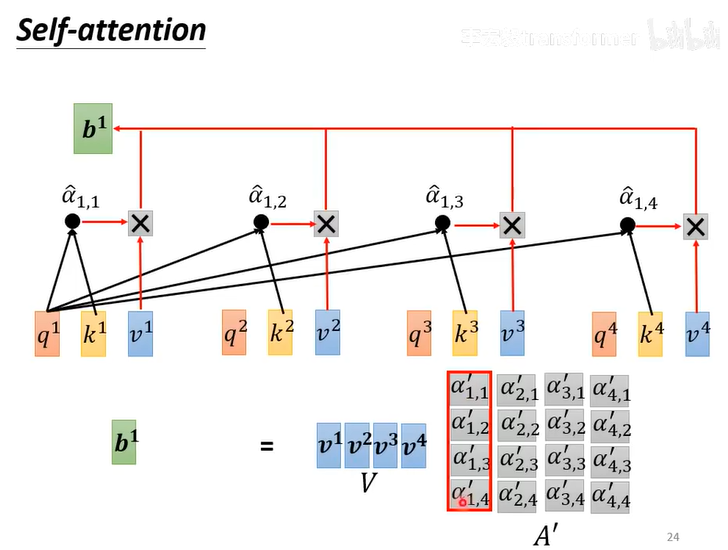
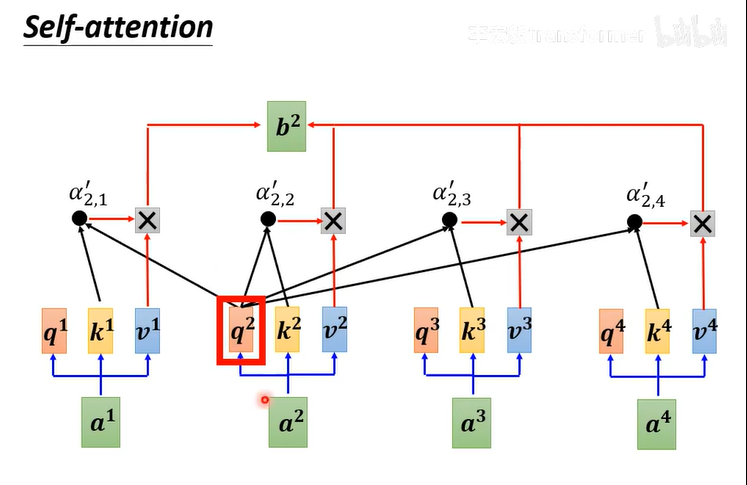
怎么从a1,a2,a3...得到b1,b2,b3...
发现序列的相关性
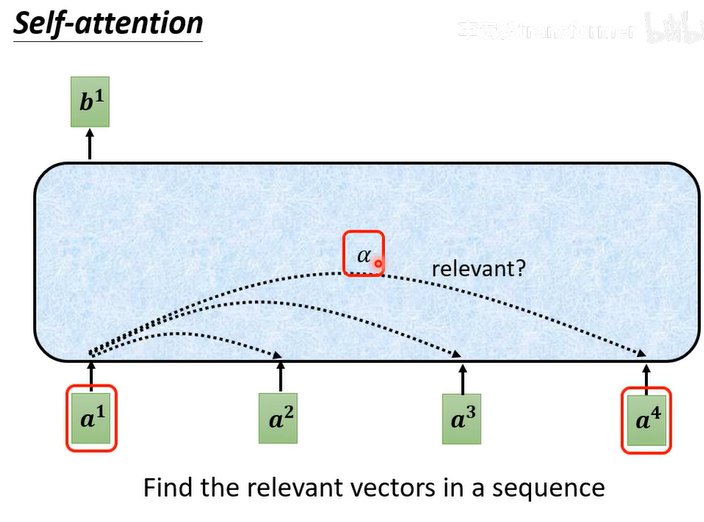
计算来确定相关性:两种方法dot-product(常用),addictive
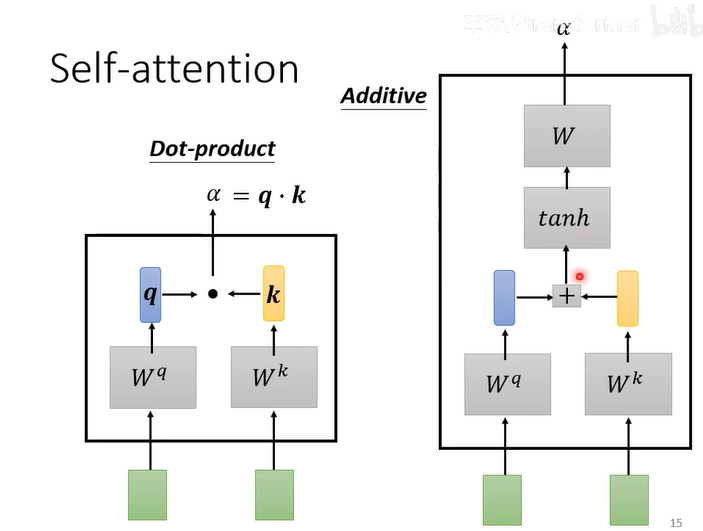
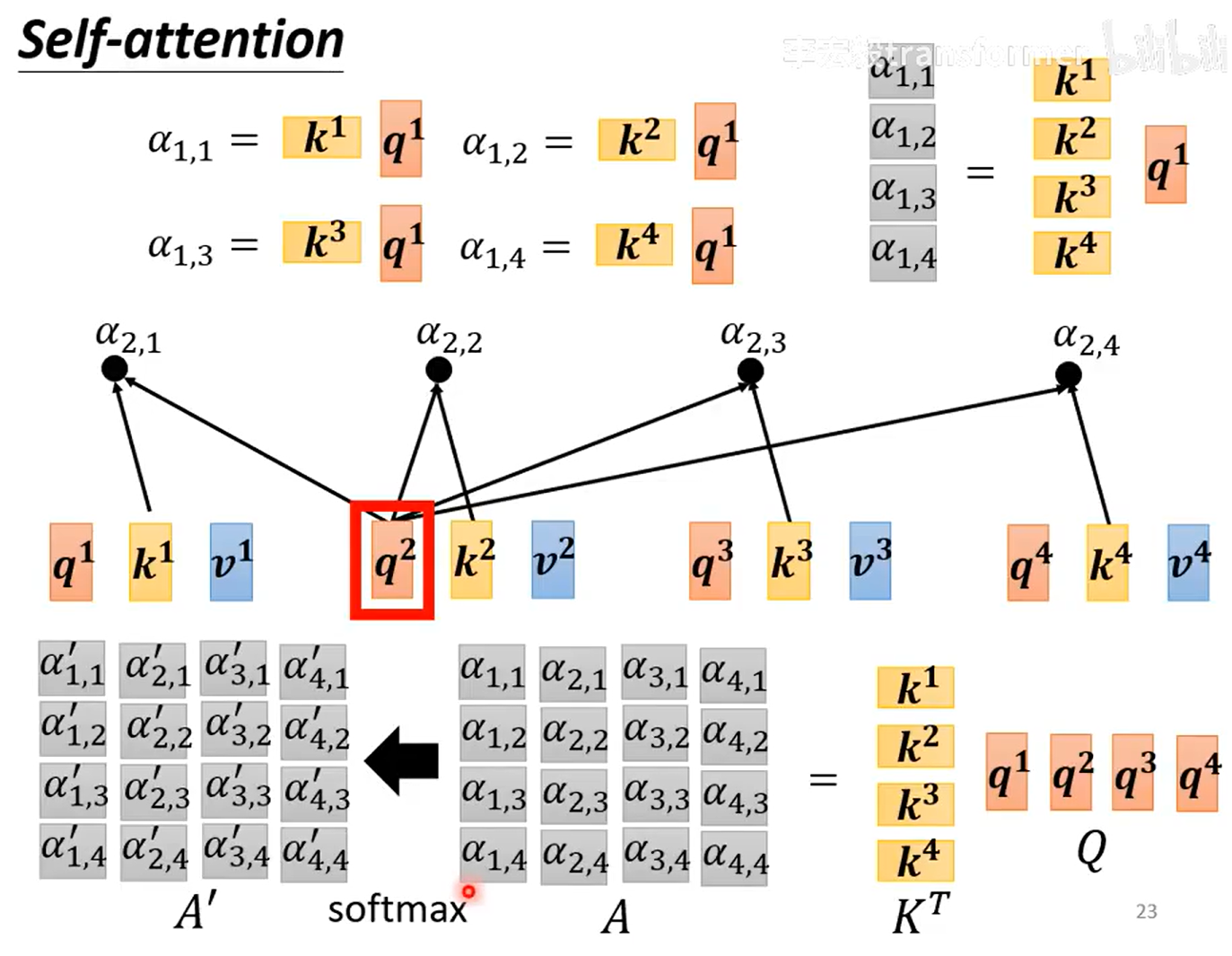
第一步:计算

第二步:计算softmax/ReLU
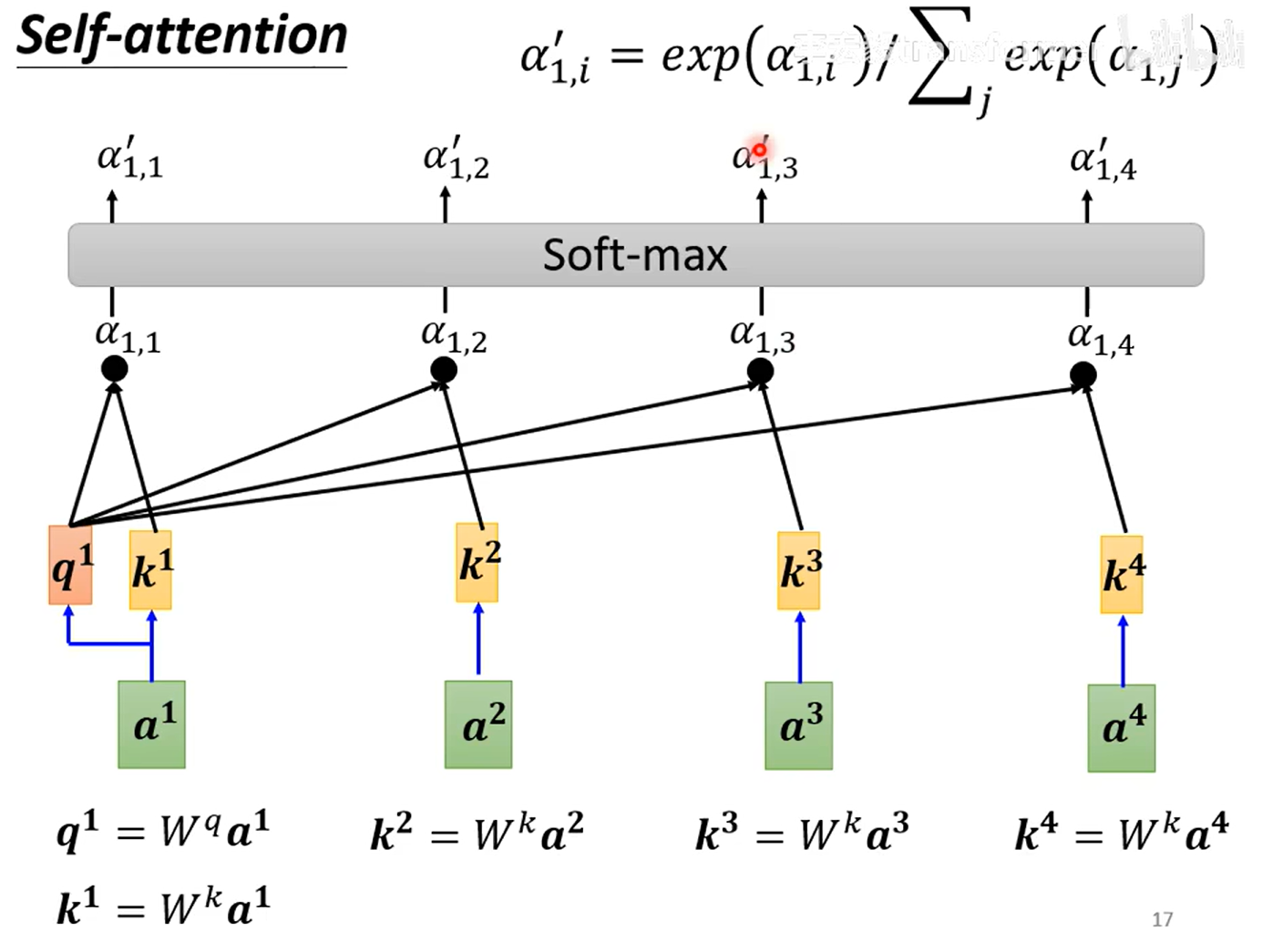
第三步:根据关联性提取sequence信息
将=
...
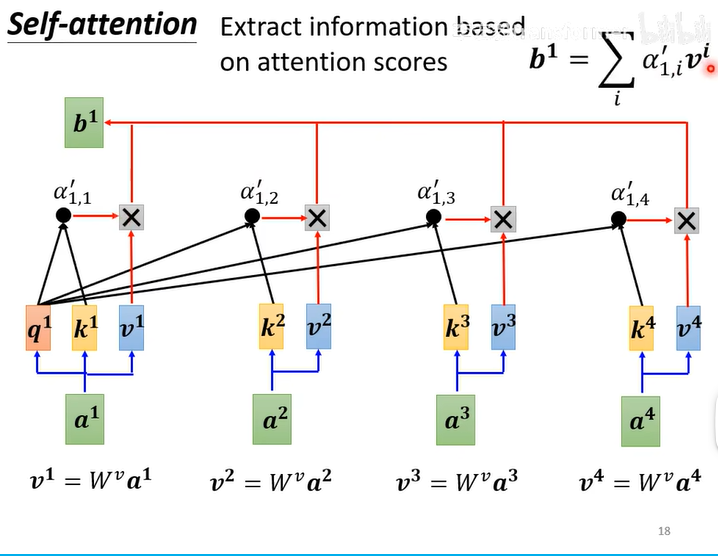
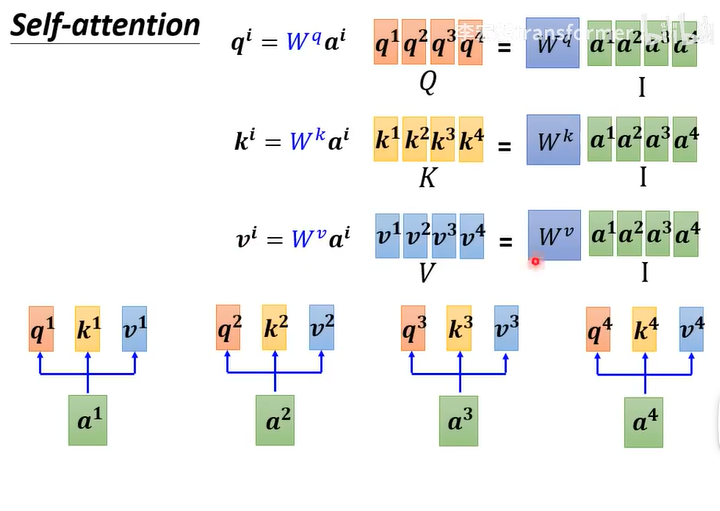
推广到每一个
先计算q,k,v
再计算
再计算b
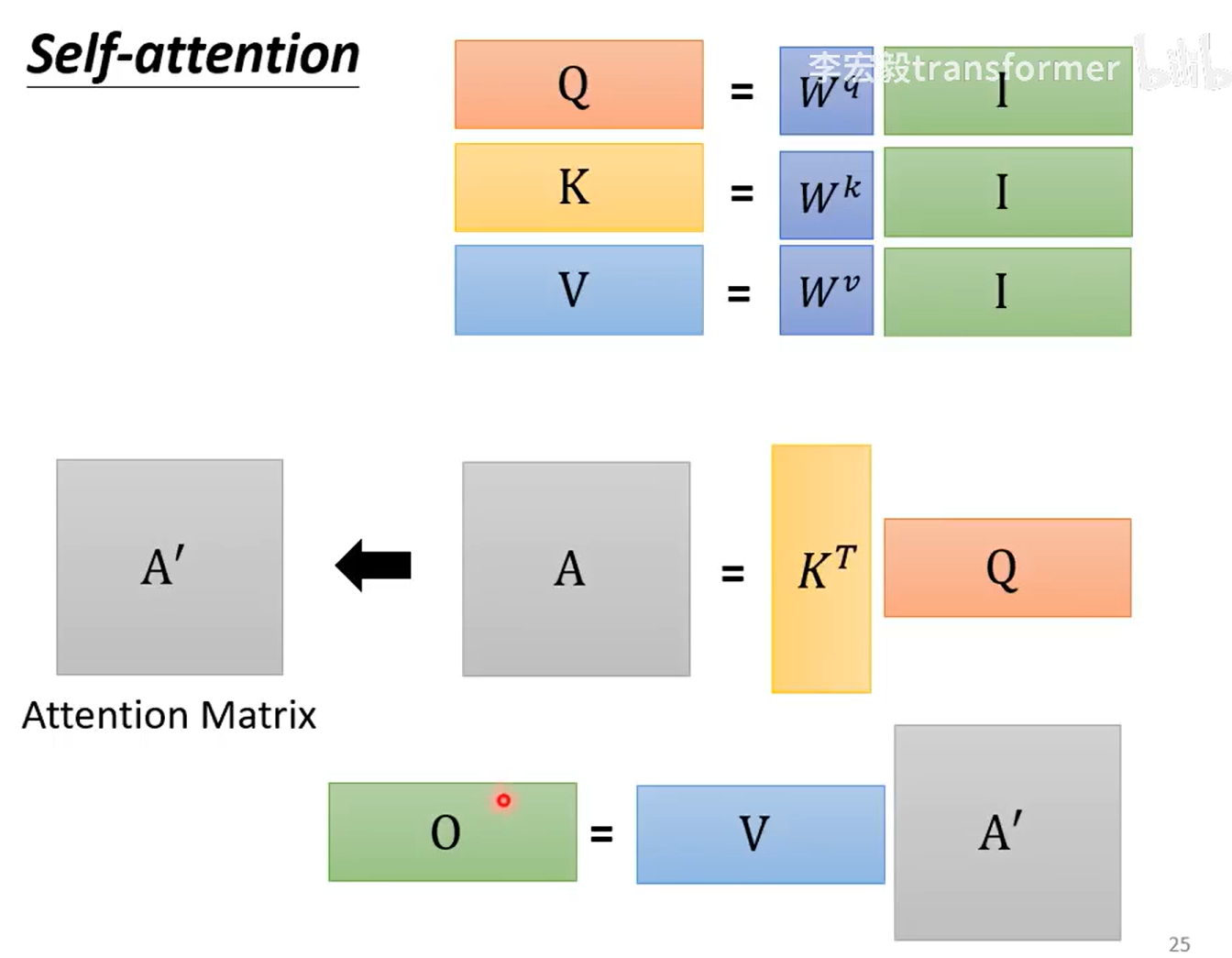
I:输入,O:输出,A:上面的b,又称注意力矩阵,,
,
是通过学习得来的
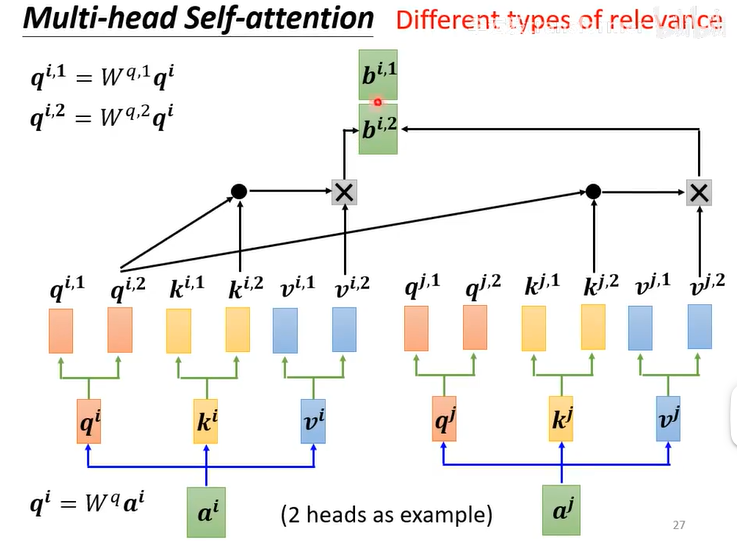
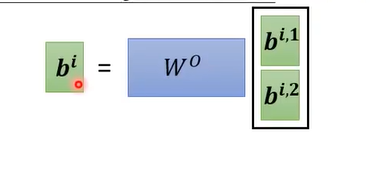
多头注意力机制------Multi-head Self-attention
位置编码Positional Encoding
self-attention没有位置资讯
每一个位置有一个独特的位置向量e
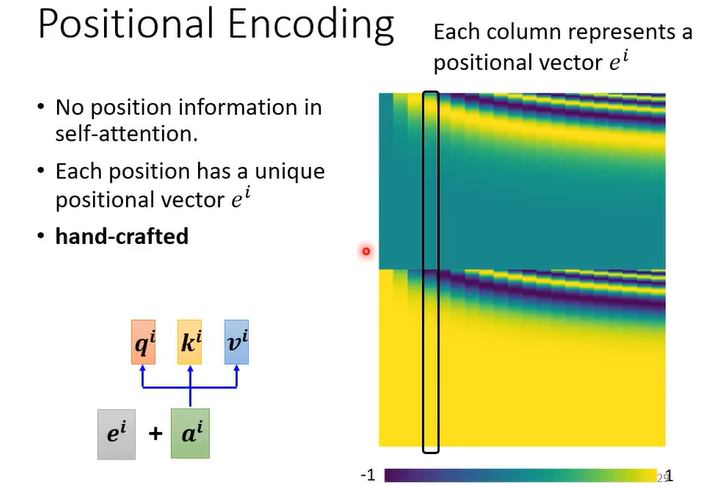
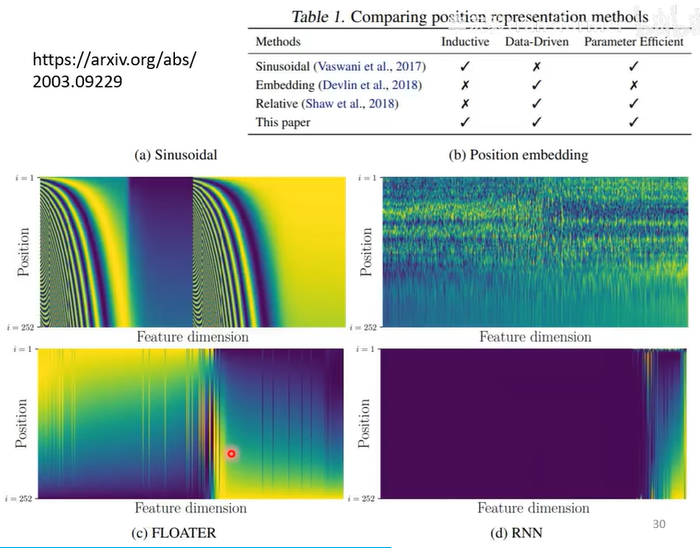
几种常见的产生方式
(a)Sinusoidal (b)Position embedding (c)FLOATER (d)RNN
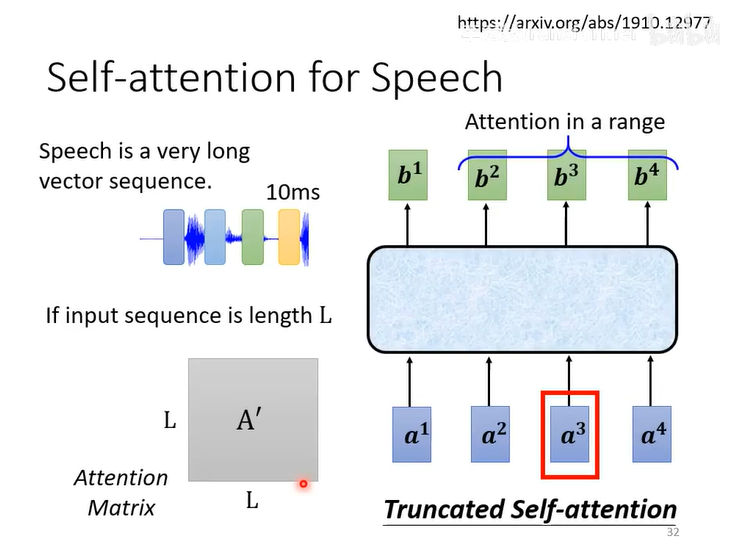
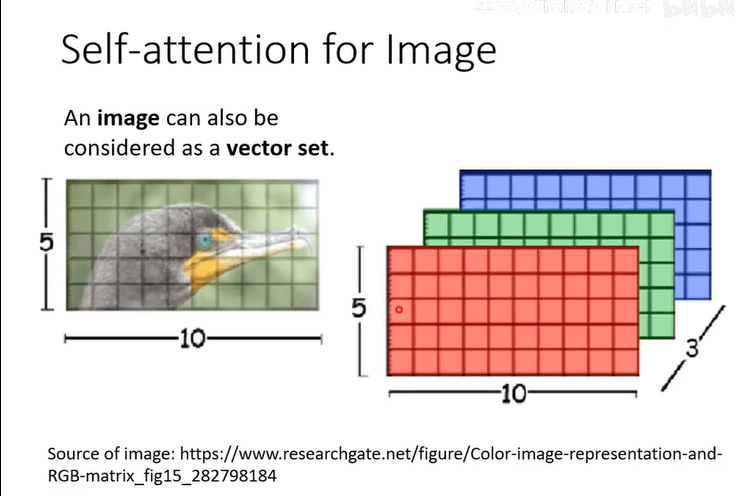
应用
nlp上:比如transformer,BERT

语音上:Truncated Self-attention
图像上,因为图像也能看作vector
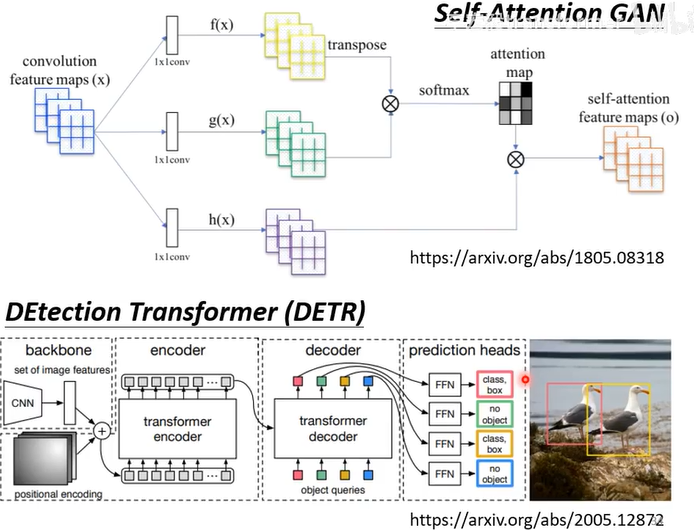
Self-attention v.s. CNN
1、CNN是简化版的self-attention
self-attention是带有自学习rceptive field的CNN
2、CNN需要的数据更少
相关论文:
On the Relationship between Self-Attention and Convolutional Layers文章链接


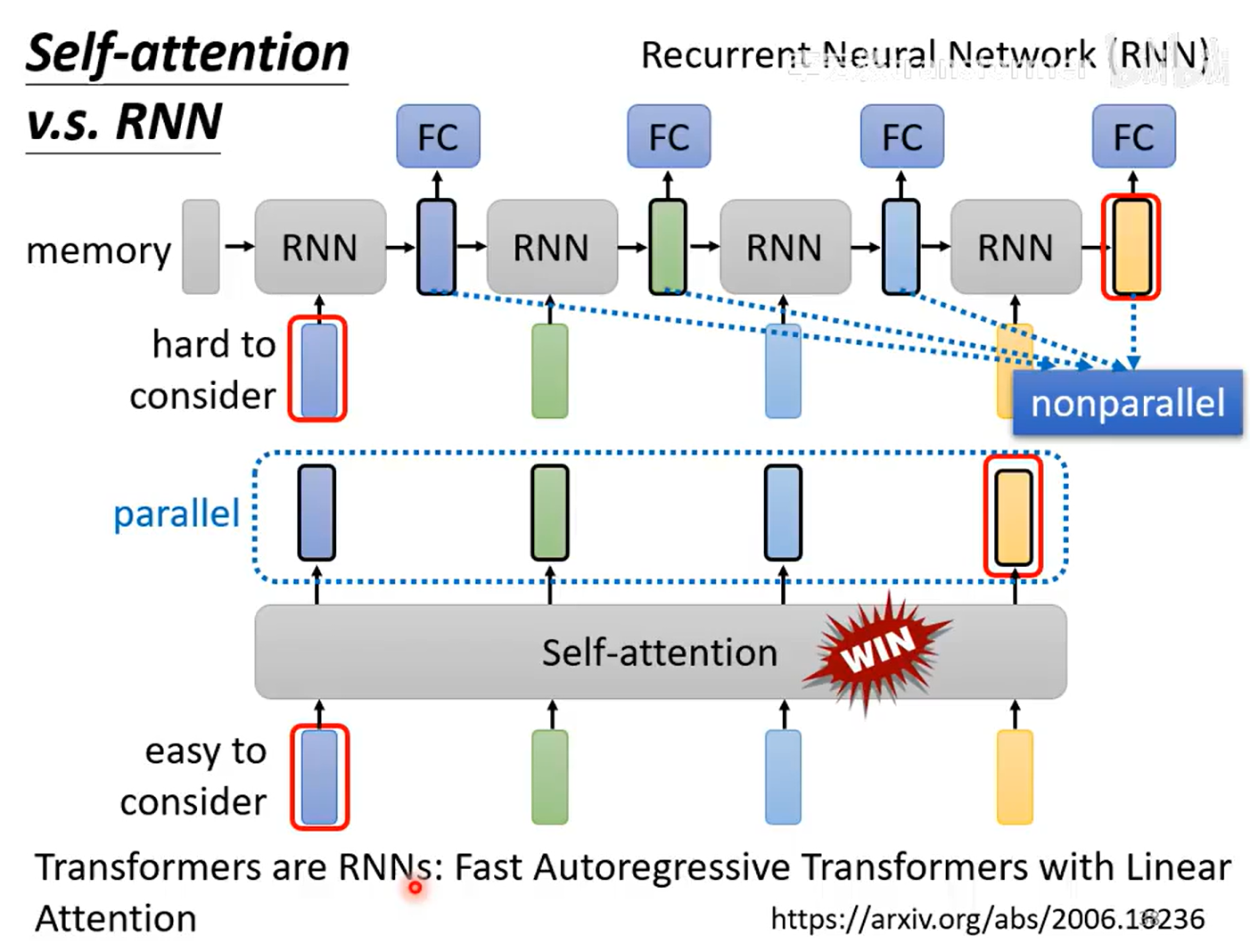
Self-attention和RNN
| 区域 | 含义 |
|---|---|
| RNN | 每一时间步的隐藏状态 h_t 必须等 h_{t-1} 算完才能继续 → 无法并行(nonparallel) |
| Self-attention | 所有位置一次性看到全局 → 可并行(parallel) |
| 优势 | Self-attention 胜出:既能像 RNN 一样"考虑历史"(memory),又能并行训练 |
| 论文 | 给出理论支撑:把 softmax 注意力换成 线性核函数 后,Transformer 的每一步输出可以写成 只依赖前一步隐藏状态的递归形式 ,即"Fast Autoregressive Transformer with Linear Attention "------它 形式上就是 RNN,却可并行预计算 |
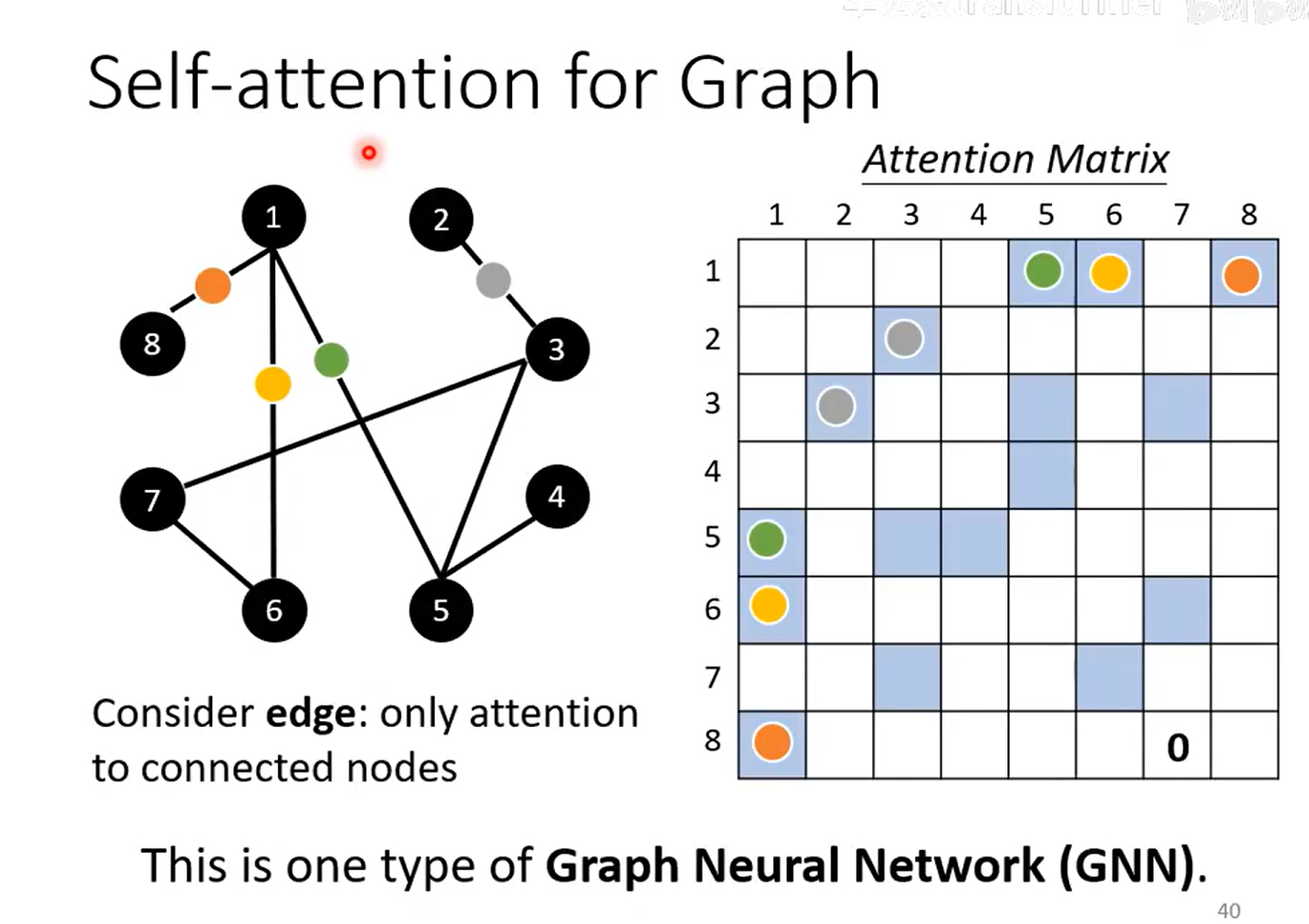
self-attention for Graph:GNN?
序列到序列Seq2seq
例子
语音->语言
机器翻译(一种语言->另一种语言)
一种语音->另一种语言
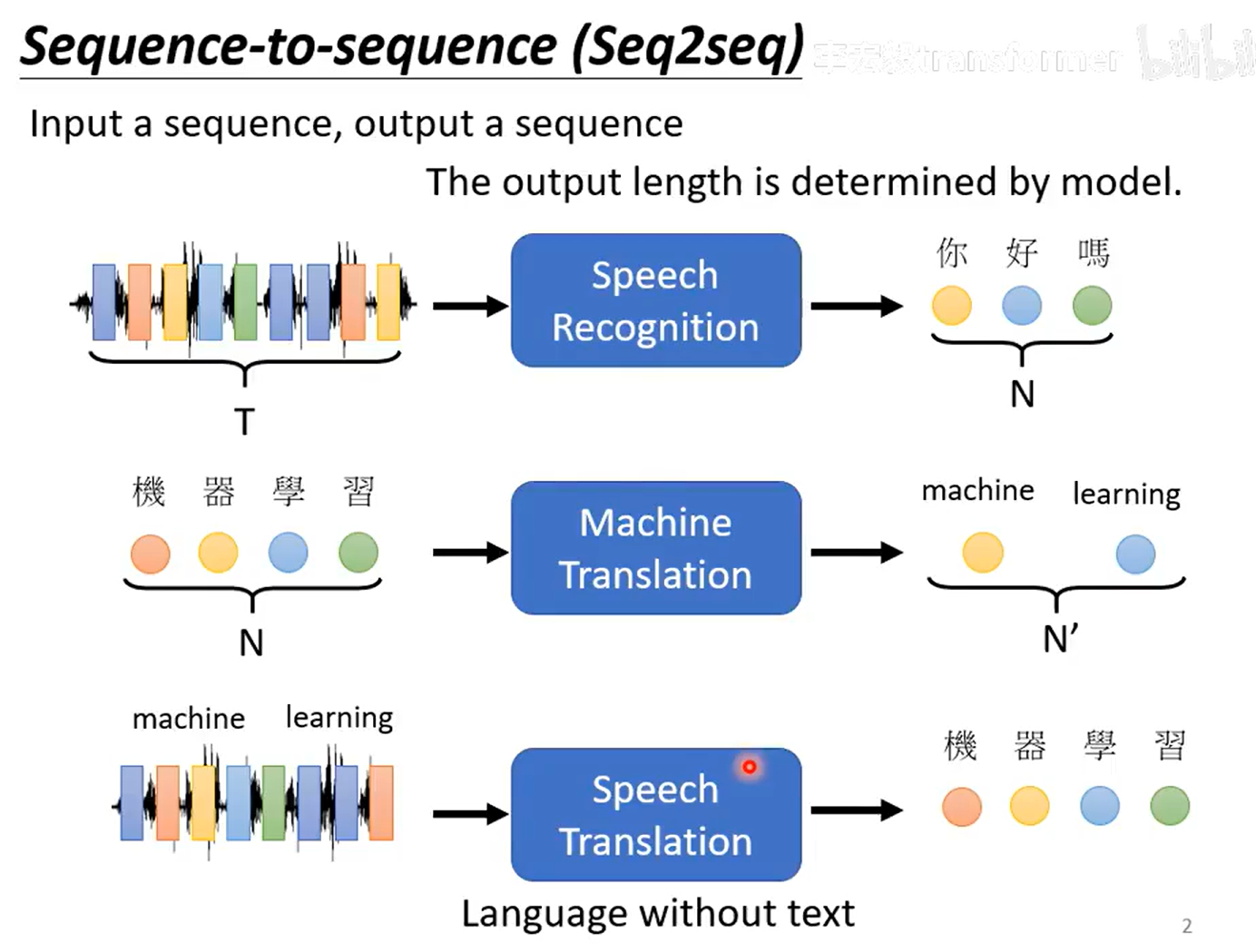
Seq2seq for 文法剖析
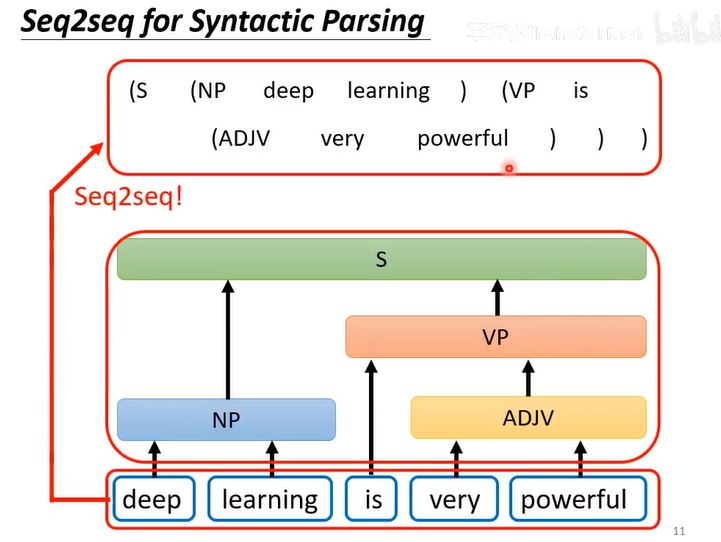
Seq2seq for 多标签分类
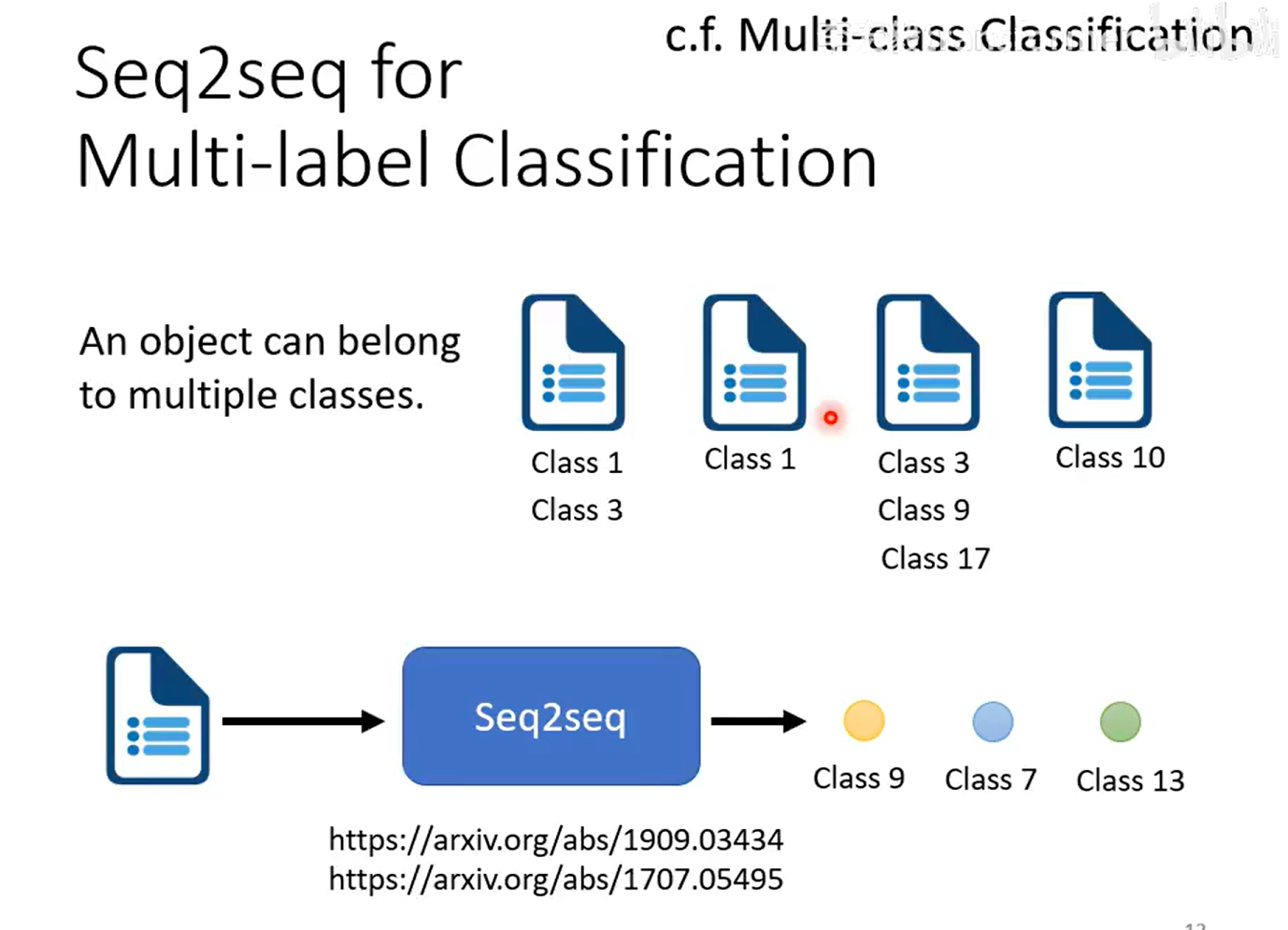
Seq2seq for 目标识别
如何实现seq2seq
主要是Encoder和Decoder
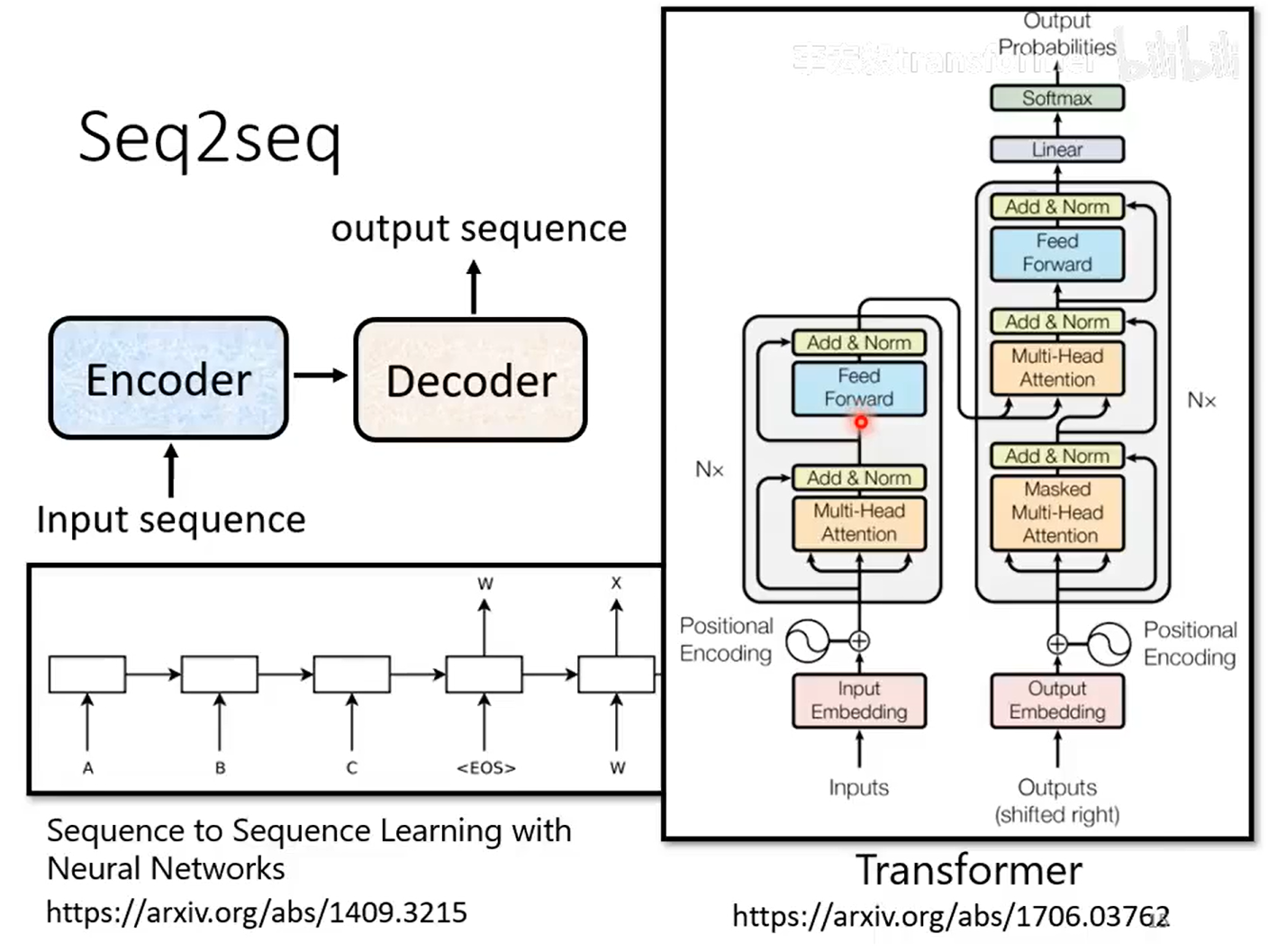
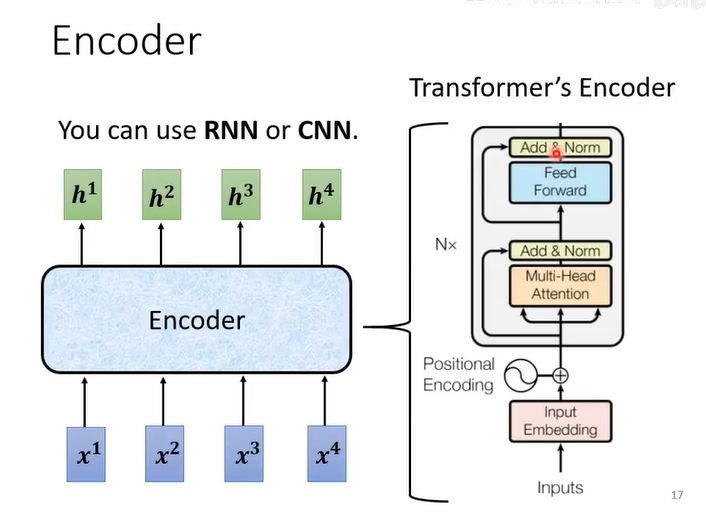
Encoder:
self-attention和CNN、RNN都可以
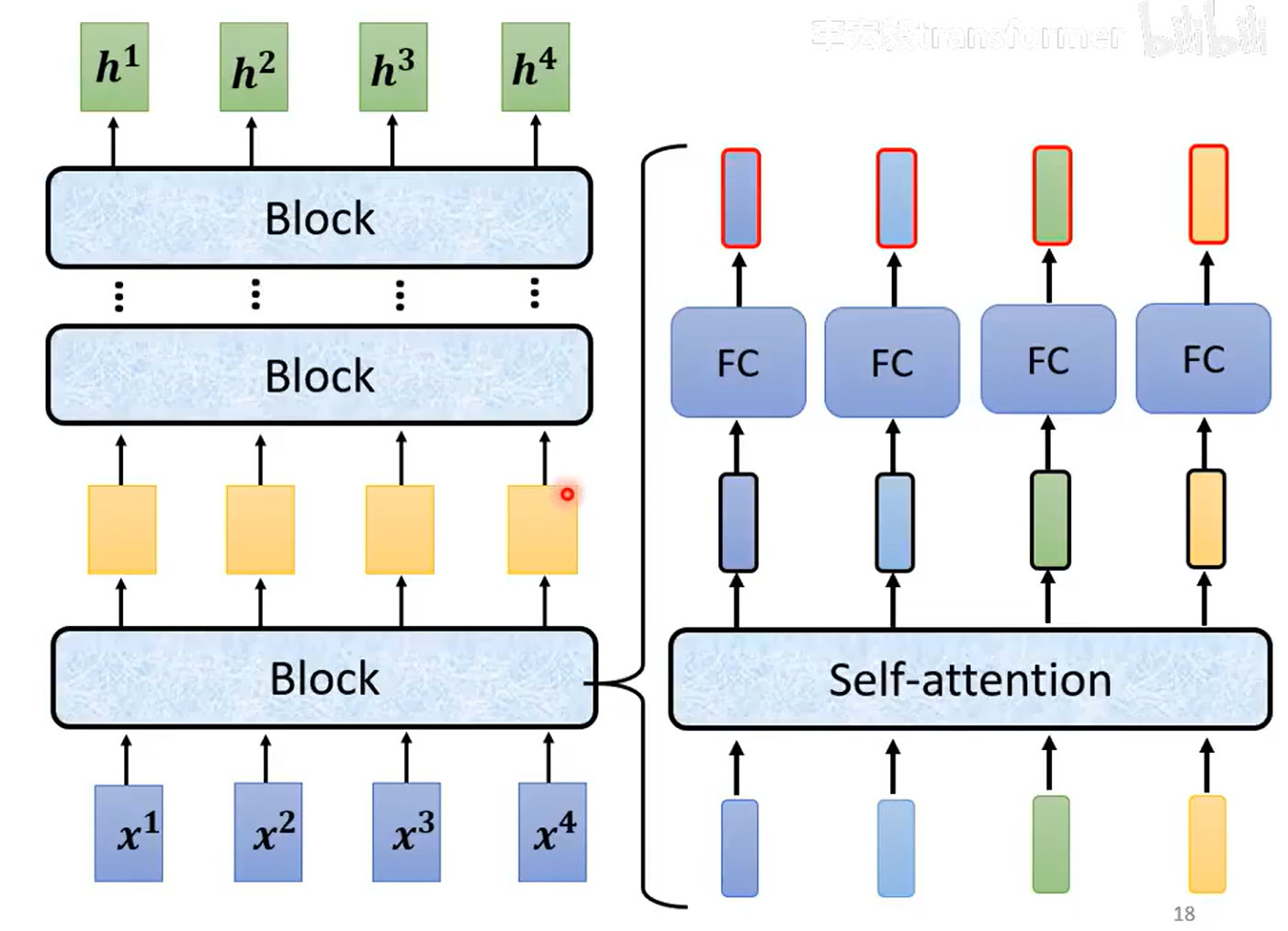
有好多块
每一块:self-attention+FFN
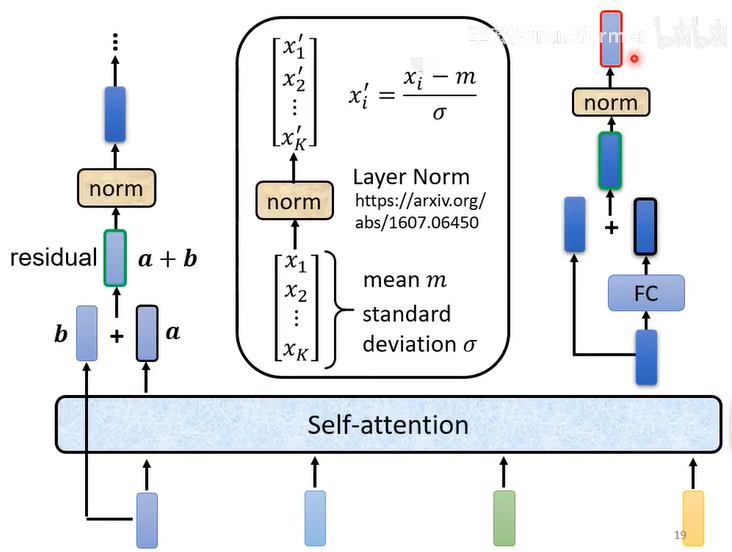
1、self-attetion
2、残差连接(residual):input和output加起来
3、layer Normalization:对同一个feature里面不同的dimenstion计算均值mean和standard deviation
4、FFN
5、FFN的输入和FFN的输出残差连接
6、normalization
5和6即Add&Norm
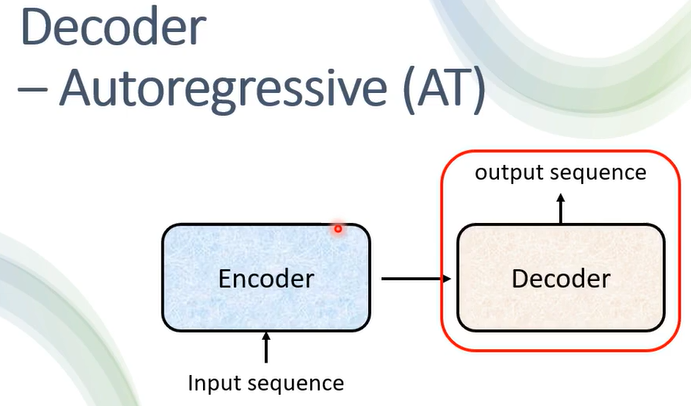
Decoder:
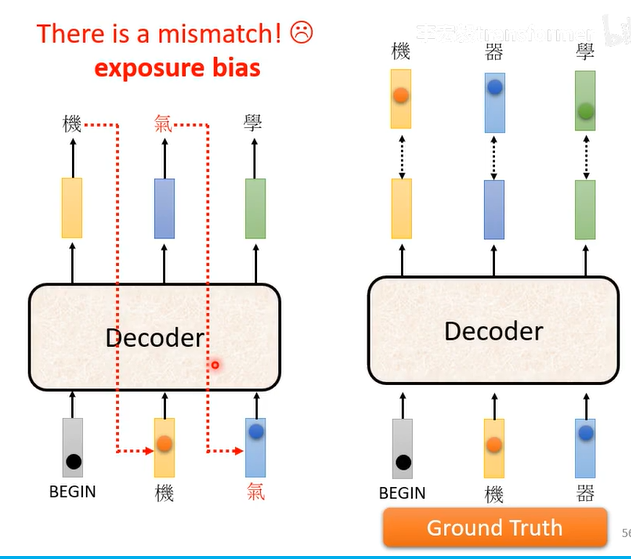
输出当输入容易产生Error Propagation 误差传播,一步错、步步错
masked self-attention:未来的位置不能用
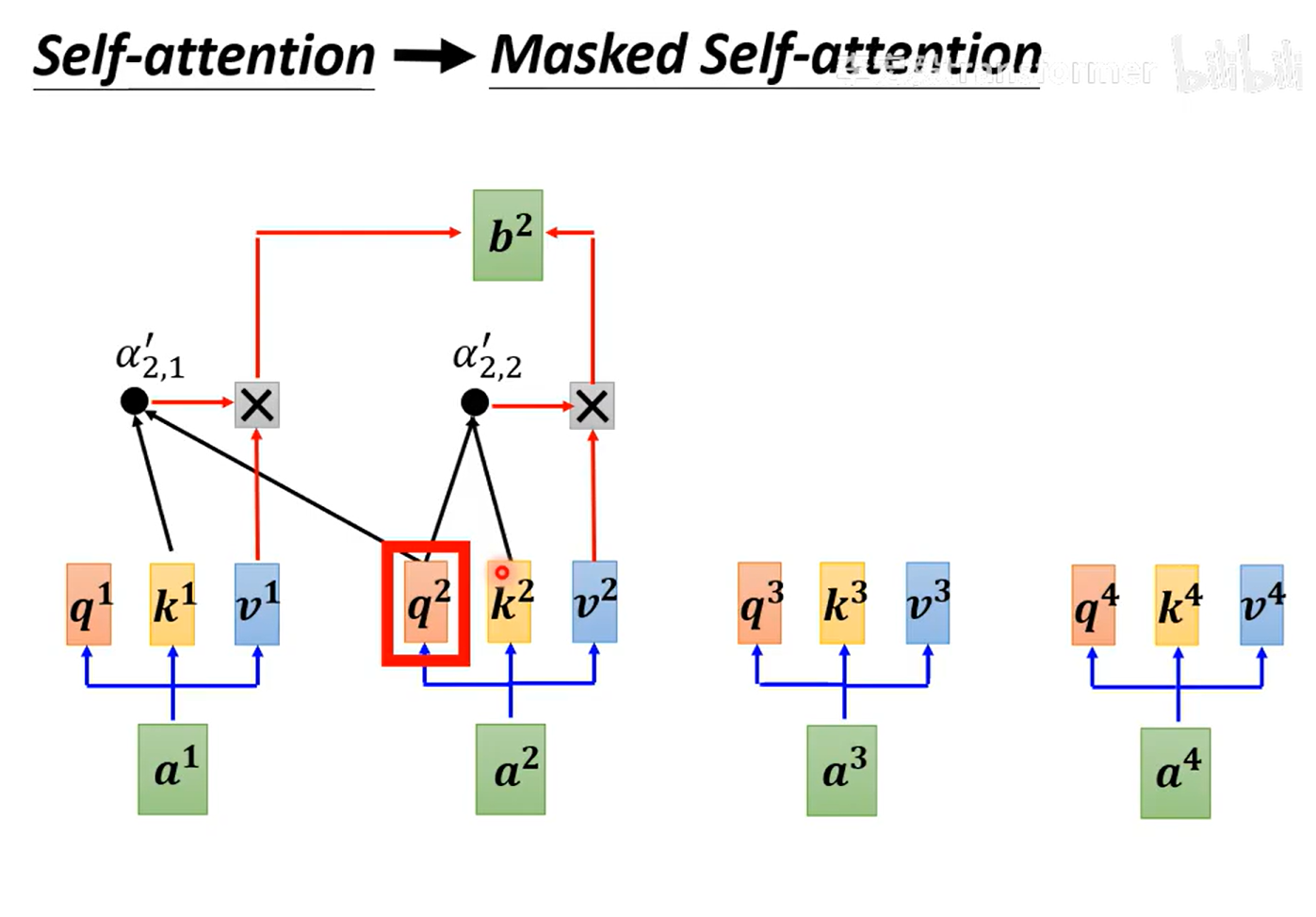

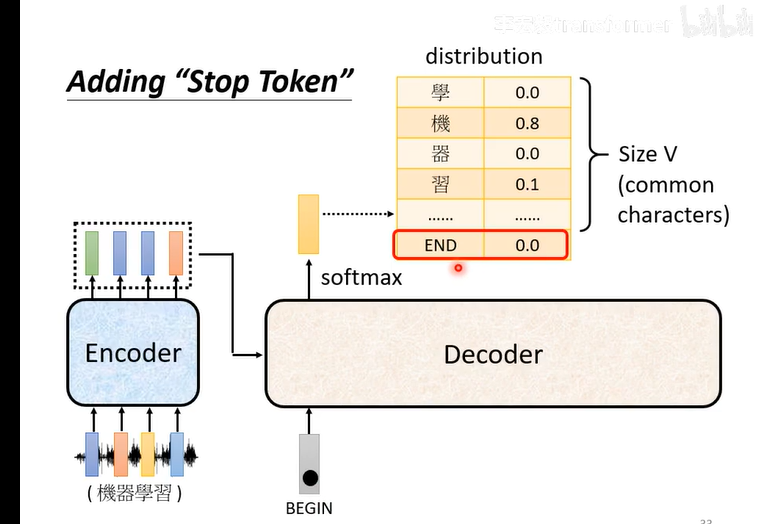
问题:不知道输出的长度?所以输出需要能产生end符号
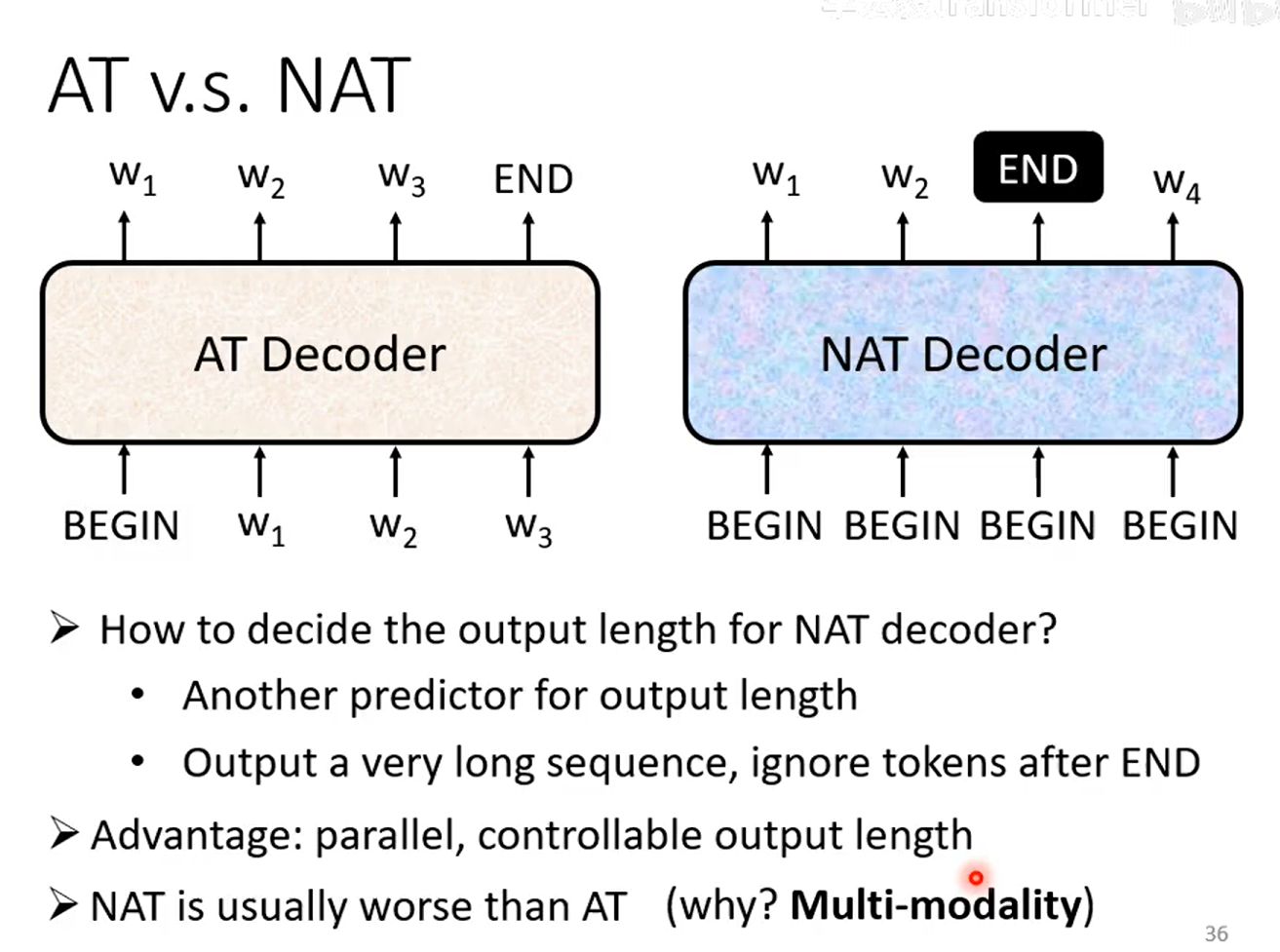
AT VS NAT
AT是串行产生的
NAT是并行产生的
AT的输入有上一个输出,有的是BEGIN
NAT全是BEGIN
NAT的end是另一个预测得出的输出长度,是可控的
encoder的输出如何变成decoder的输入(又称cross attention)
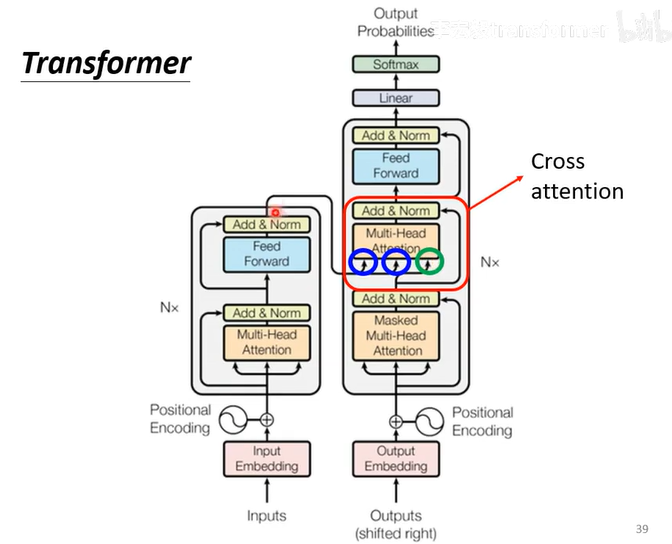
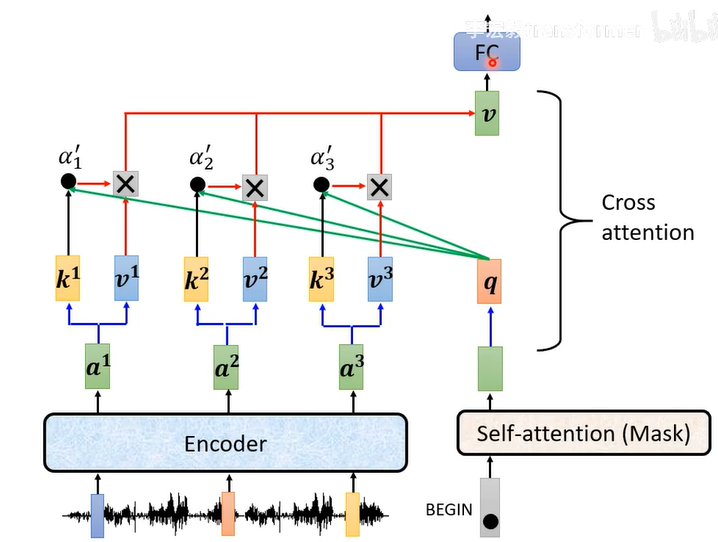
encoder输出的a1,a2,a3...产生k1,v1,k2,v2,k3,v4,self-attention对应的q,k1q点积产生1,
1*v1...产生最后的v
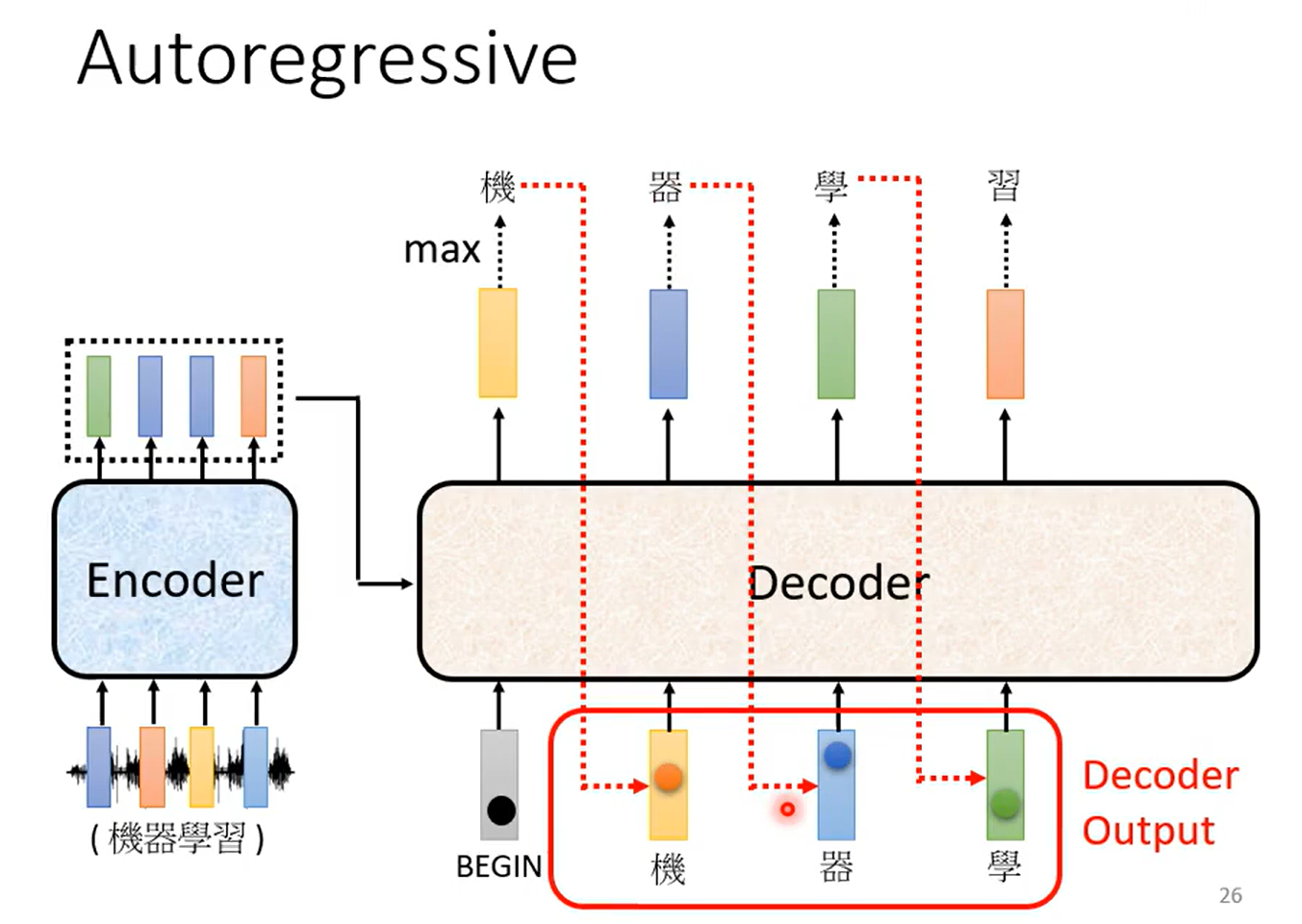
1、输入begin
2、输入机
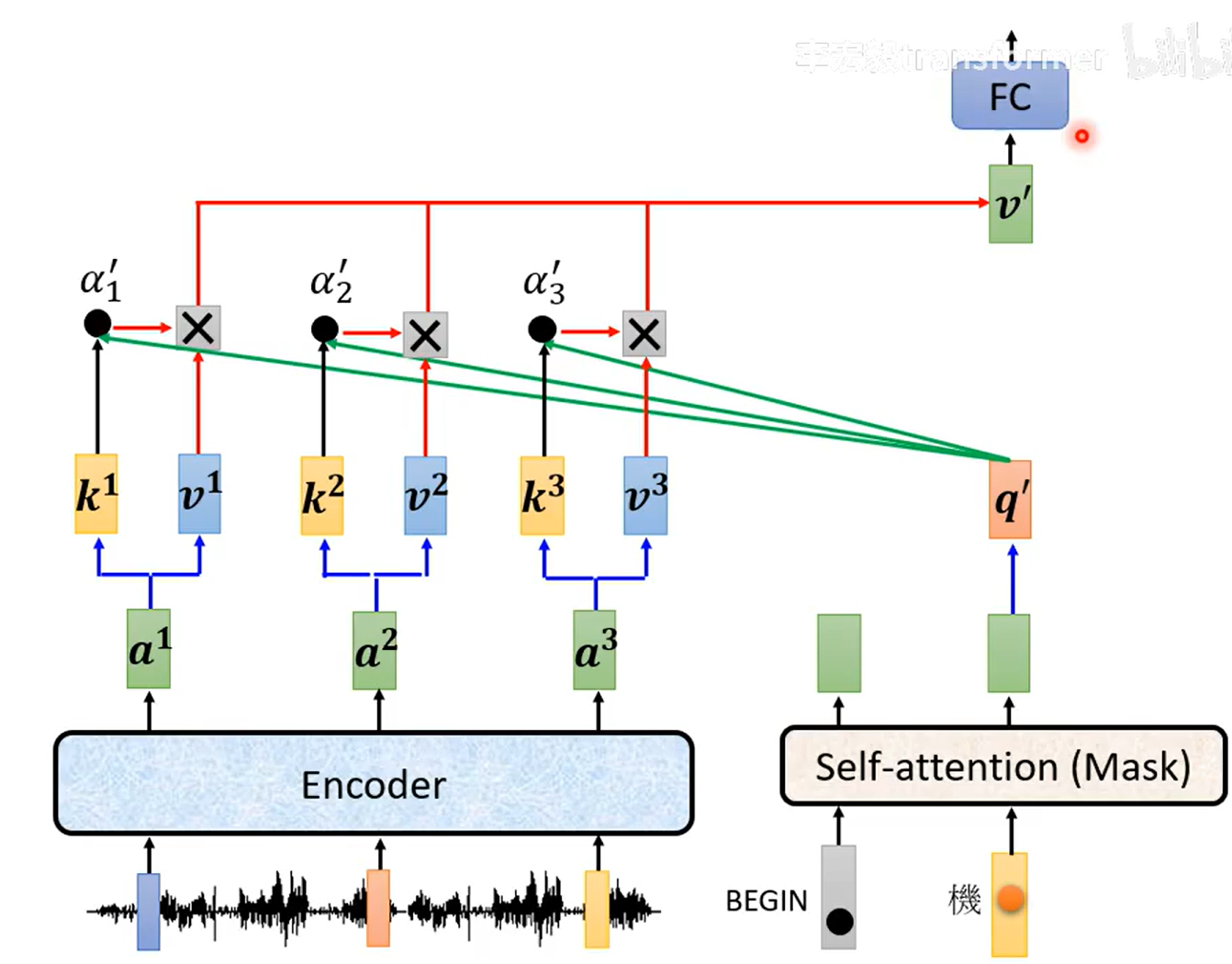
encoder有很多层,decoder也有很多层,不用一定每一层decoder的输入都是最后一层decoder的输出
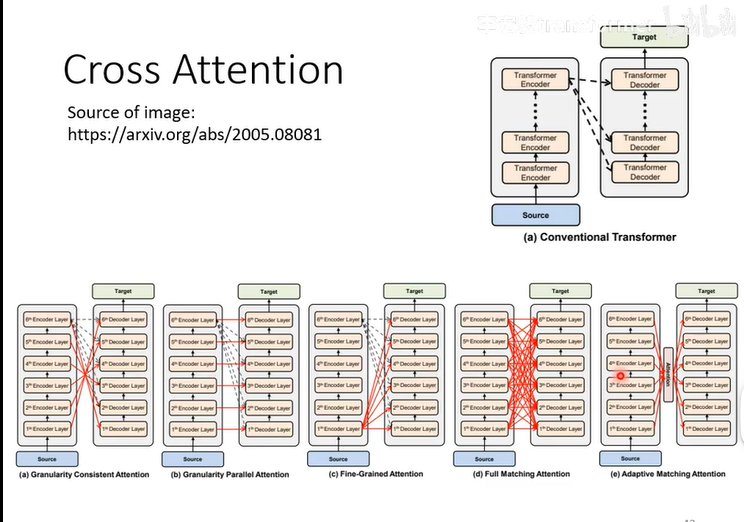
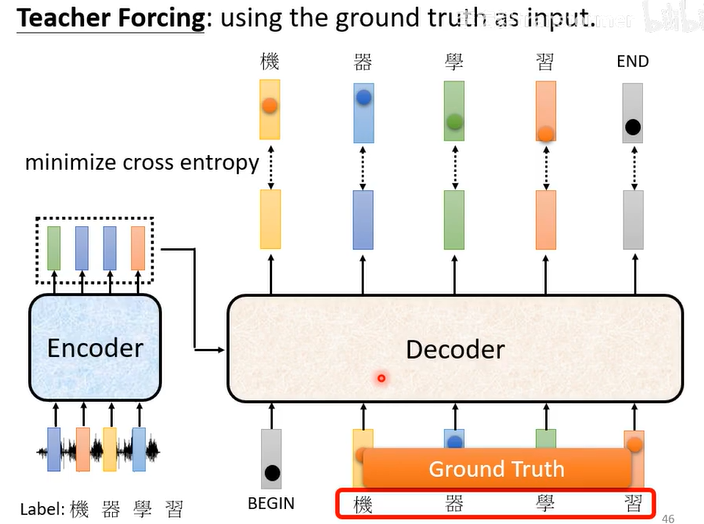
训练training
训练时会知道正确答案,用正确答案计算cross entropy(交叉熵)
而且Decoder输入的时候不是输入自己产生的输出,而是正确的答案
机器需要复制的能力

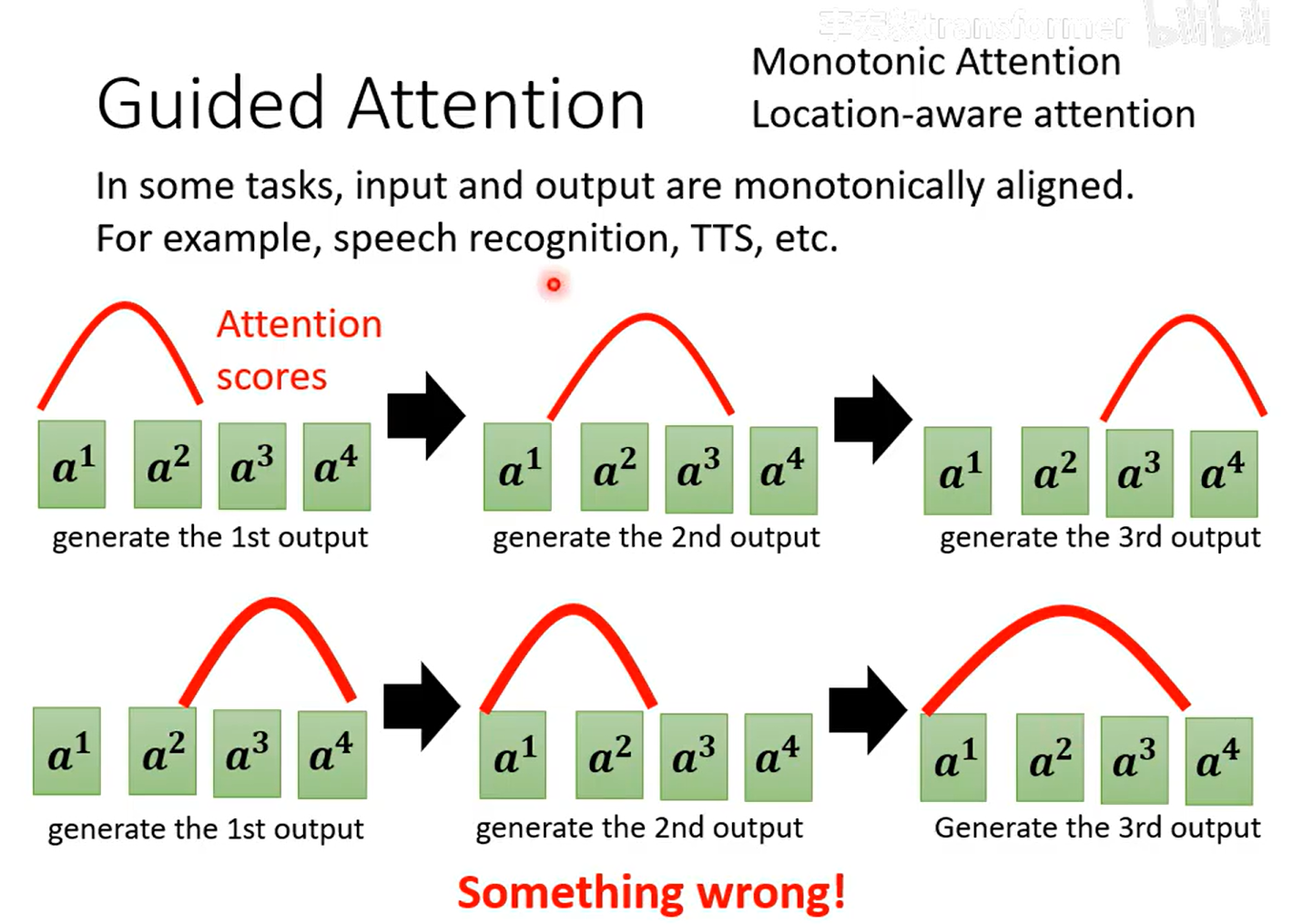
guided attention(引导注意力)
Guided Attention(引导注意力)是一类"训练辅助"技巧,核心思想是:
在训练阶段用外部知识或先验分布去"告诉"模型的注意力矩阵应该长成什么样,从而加快收敛、提升鲁棒性,或让模型学到人类可解释的对齐方式。
1. 为什么需要它
标准注意力完全由数据驱动,可能出现
-
收敛慢、需要大量数据才能学到合理的对齐;
-
对齐杂乱,解释性差;
-
在超长序列或稀有样本上把注意力放到无关区域。
Guided Attention 通过额外损失或掩码把"先验"注入注意力,让模型少走弯路。
2. 典型先验与具体做法
| 场景 | 先验形状 | 实现方式 | 代表文献 |
|---|---|---|---|
| TTS、G2P、语音识别 | 对角带状 | 对远离对角线的注意力权重加惩罚,loss∝ ∑ᵢⱼ wᵢⱼ·(i−j)² | SpeechBrain 的 GuidedAttentionLoss |
| 上下文偏置 ASR | 短语-帧/Token 对齐 | 额外 GA-loss 迫使 cross-attn 把偏置短语与对应帧对齐,提升稀有词识别 | 2024 年 ASR 研究 |
| 语码切换 ASR | 语言身份 | 先挑出"表达语言身份"的头,再约束这些头只关注对应语言区域 | Attention-Guided Adaptation |
| 心电图分类 | 医学波形位置 | 用 R 峰检测自动产生"应关注区间"的 soft-mask,再与空间注意力做加权 KL 惩罚 | 2025 年 ECG 论文 |
| 通用 NLP | 人工标注或规则热度图 | 把外部热度图作为 teacher,用 MSE/KL 约束 student 的注意力分布 | GAM 方法 |
3. 数学抽象
设模型产生的注意力矩阵为 A∈ℝ^(T×S),先验mask或目标分布为 G,则常用辅助损失:
-
**L1** = ∑ᵢⱼ wᵢⱼ·Aᵢⱼ ,远离期望区域权重越大 wᵢⱼ 越大;
-
**L2** = KL(A‖G) 或 MSE(A,G),直接把 A 拉向先验分布;
总损失 = 原任务损失 + λ·L_guided,λ 随训练逐步减小(退火)。
4. 效果与优势
-
训练速度↑:GAM 报道 NLP 任务训练时间缩短 5--9% 。
-
识别精度↑:ASR 上下文偏置在 LibriSpeech 稀有词 WER 再降 19.2% 。
-
解释性↑:ECG 模型可直观看到注意力是否聚焦在 P、T 波等医学关键段 。
-
零额外参数:多数方法只改损失,不影响推断结构 。
5. 与相关概念区分
-
Attention Constraint / Mask:硬遮罩,推理期也生效;Guided Attention 多为软约束,只在训练期影响梯度。
-
Knowledge Distillation:用另一个模型当 teacher;Guided Attention 用的是人工规则或领域知识当 teacher。
-
Self-Supervised Pretext:设计前置任务学对齐;Guided Attention 直接把"理想对齐"作为监督信号。
一句话总结
Guided Attention = 先验地图 + 辅助损失,让注意力矩阵在训练时就"走对方向",从而学得更快、更准、更易解释。
红色曲线代表attention的分数,越高代表值越大,代表越关注
第一行是想象中attention的分数
第二行是不理想的attention,先看后面,再看前面...
Beam Search束搜索
红色路线是利用贪心算法,一直选当前最好的
绿色才是我们期望的
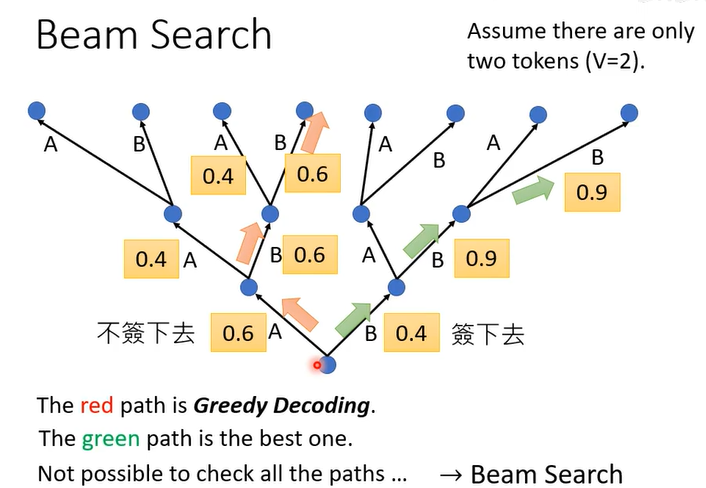
Beam Search(集束搜索)是一种**"受限的贪心解码"** 方法,用来在生成模型 (如机器翻译、语音识别、TTS、对话系统)里快速找一条(或几条)近似最优的输出序列 ,而不是一口气搜完所有可能(指数爆炸)。
1. 核心思想一句话
"每一步只保留最好的 k 个候选,其余剪掉"
k 叫 beam size(集束宽度),通常 3~10。
2. 工作流程(以机器翻译为例)
输入:我爱你
目标:I love you
| 步骤 | 当前 k 个候选(部分序列) | 打分(log-prob) |
|---|---|---|
| 1 | I | -0.8 |
| You | -1.2 | |
| We | -1.5 | |
| 2 | I love | -1.5 |
| I like | -1.7 | |
| You | -1.2 → 被剪 | |
| 3 | I love you | -2.1 |
| I like you | -2.4 |
3. 关键概念
-
score :一般用累积对数概率(加上长度惩罚,防止过短)。
-
beam size = 1 时 退化成贪心搜索(greedy)。
-
beam size = ∞ 时 退化成穷举搜索(不可行)。
-
剪枝:每步只扩 k×V 个节点 → 保留 top-k,其余扔掉(V 是词表大小)
4. 优点 vs 缺点
比较需要创造力的如语音合成时beam search就没有优势

| 优点 | 缺点 |
|---|---|
| 比贪心更准,比穷举快 | 内存随 k 线性增长 |
| 容易实现,可并行 | 可能漏掉全局最优(早剪错支) |
| 可输出多条候选(k best)供重排序 | 重复、覆盖问题需额外处理(如 coverage 惩罚) |
5. 一段极简伪代码
beam = [(<s>, 0)] # (序列, 累积log-prob)
for t in range(max_len):
next_beam = []
for seq, score in beam:
for w in vocab:
new_seq = seq + [w]
new_score = score + logP(w | new_seq, encoder_ctx)
next_beam.append((new_seq, new_score))
next_beam.sort(key=lambda x: x[1], reverse=True)
beam = next_beam[:k] # 只留 top-k
return beam[0] # 最优序列评估
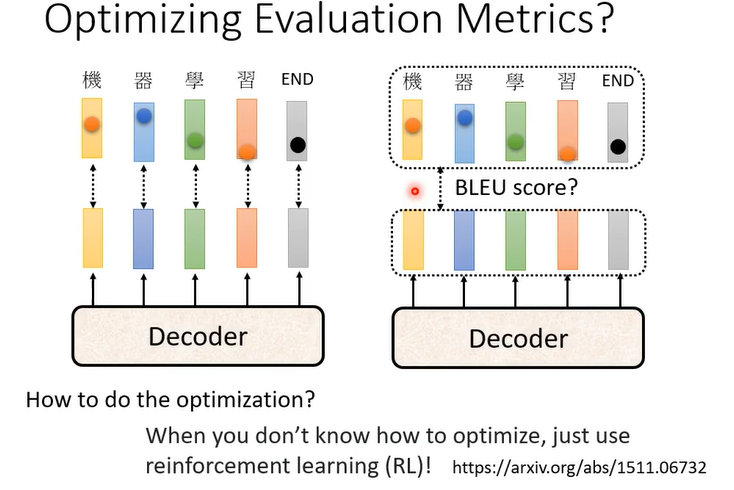
训练的时候是minimize cross entropy
但是评估是maximize BLEU score
测试的时候会产生一步错、步步错
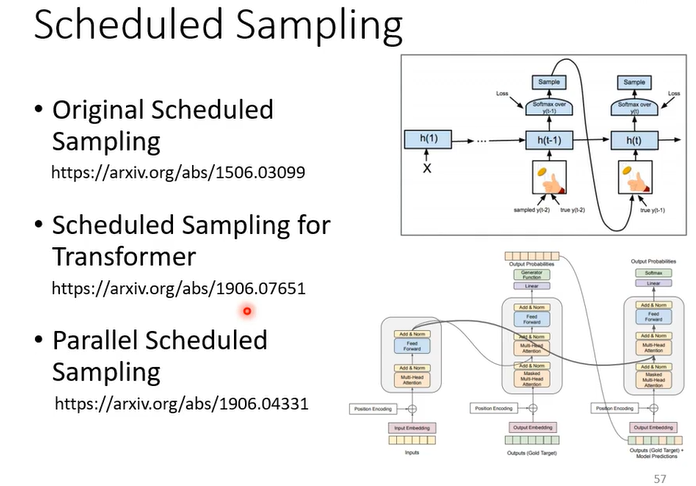
解决方法:Scheduled Sampling