文章目录
- [1 概述](#1 概述)
- [2 基础结构](#2 基础结构)
- [3 多层结构](#3 多层结构)
- [4 双向结构](#4 双向结构)
- [5 多层 + 双向结构](#5 多层 + 双向结构)
- [6 API 使用](#6 API 使用)
-
- [6.1 参数说明](#6.1 参数说明)
- [6.2 输入输出](#6.2 输入输出)
-
- [6.2.1 示例代码](#6.2.1 示例代码)
- [6.2.2 输入输出内容](#6.2.2 输入输出内容)
- [6.2.3 输入输出形状](#6.2.3 输入输出形状)
- [7 案例实操------智能输入法](#7 案例实操——智能输入法)
-
- [7.1 需求说明](#7.1 需求说明)
- [7.2 需求分析](#7.2 需求分析)
-
- [7.2.1 数据集处理](#7.2.1 数据集处理)
- [7.2.2 模型结构设计](#7.2.2 模型结构设计)
- [7.2.3 训练方案](#7.2.3 训练方案)
1 概述
虽然词向量能够表示词语的语义,但它本身并不包含词语之间的顺序信息。为了解决这一问题,研究者提出RNN(Recurrent Neural Network,循环神经网络)。
RNN 会逐个读取句子中的词语,并在每一步结合当前词和前面的上下文信息,不断更新对句子的理解。通过这种机制,RNN 能够持续建模上下文,从而更准确地把握句子的整体语义。因此RNN曾是序列建模领域的主流模型,被广泛应用于各类NLP任务。
2 基础结构
RNN(循环神经网络)的核心结构是一个具有循环连接的隐藏层,它以时间步(time step)为单位,依次处理输入序列中的每个 token。
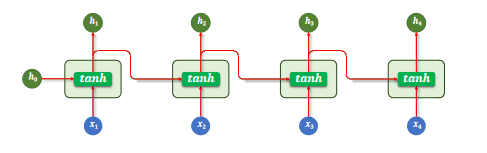
在每个时间步,RNN 接收当前 token 的向量和上一个时间步的隐藏状态(即隐藏层的输出),计算并生成新的隐藏状态,并将其传递到下一时间步。
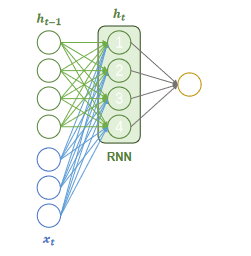
隐藏层的计算公式为: h t = tanh ( x t W x + h t − 1 W h + b ) h_t = \tanh(x_t W_x + h_{t-1} W_h + b) ht=tanh(xtWx+ht−1Wh+b)
3 多层结构
为了让模型捕捉更复杂的语言特征,可以将多个 RNN 层按层次堆叠起来,使不同层学习不同层次的语义信息。
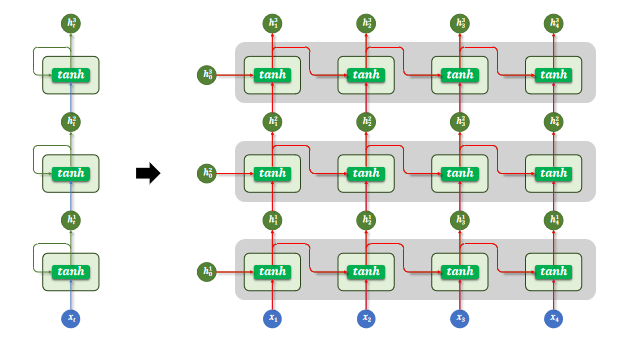
这种设计的核心假设是:底层网络更容易捕捉局部模式(如词组、短语),而高层网络则能学习更抽象的语义信息(如句子主题或语境)。
多层 RNN 结构中,每一层的输出序列会作为下一层的输入序列,最底层 RNN 接收原始输入序列,顶层 RNN 的输出作为最终结果用于后续任务。
4 双向结构
基础的 RNN 在每个时间步只输出一个隐藏状态,该状态仅包含来自上文的信息,而无法利用当前词之后的下文。
对于一些任务而言,这是一个明显的限制。比如在序列标注任务中,模型需要为每个 token 预测一个标签,如果只能参考前文信息,往往难以做出准确判断。
而使用双向 RNN(Bidirectional RNN),模型可以在每个时间步同时利用前文和后文的信息,从而获得更全面的上下文表示,有助于提升序列标注等任务的预测效果。
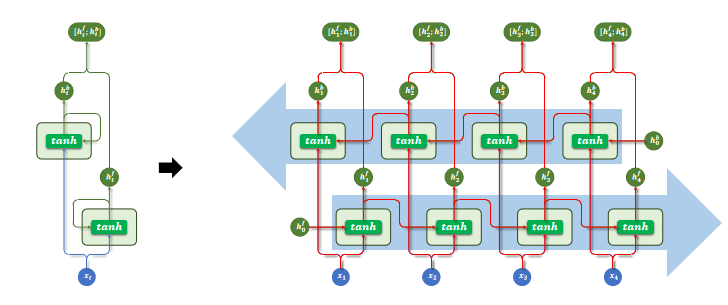
双向 RNN 同时使用两层 RNN:
- 正向 RNN:按照时间顺序(从前到后)处理序列;
- 反向 RNN:按照逆时间顺序(从后到前)处理序列。
每个时间步的输出,是正向和反向隐藏状态的组合(例如拼接或求和)。
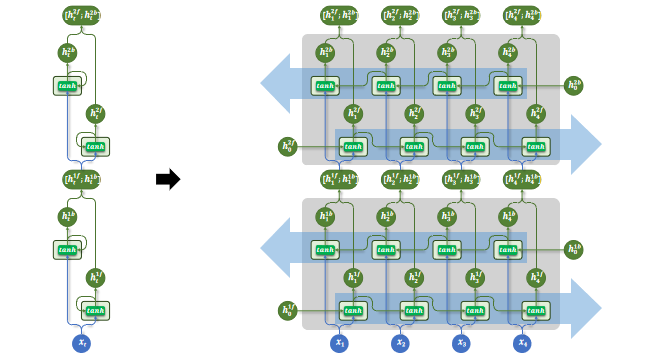
5 多层 + 双向结构
多层结构和双向结构还可组合使用,每层都是一个双向RNN。
6 API 使用
PyTorch 提供了torch.nn.RNN模块用于构建循环神经网络(Recurrent Neural Network, RNN)。该模块支持单层或多层结构,也可通过设置参数启用双向 RNN(bidirectional),适用于处理序列建模相关任务。
6.1 参数说明
构造RNN层所需的参数如下:
python
torch.nn.RNN(
input_size, # 词向量维度
hidden_size, # 隐藏状态维度
num_layers=1, # RNN层数
nonlinearity="tanh", # 激活函数
bias=True, # 是否使用偏置项
batch_first=False, # 输入张量是否是(batch, seq, feature)
dropout=0.0, # 除最后一层外,其余层之间的 dropout 概率
bidirectional=False, # 是否为双向
device=None, # 模块的初始化设备
dtype=None, # 模块式初始化时的默认数据类型
)6.2 输入输出
6.2.1 示例代码
python
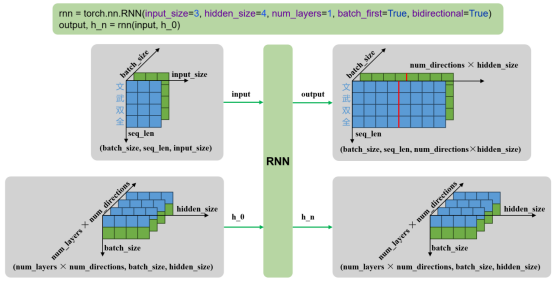
rnn = torch.nn.RNN()
output, h_n = rnn(input, h_0)6.2.2 输入输出内容
-
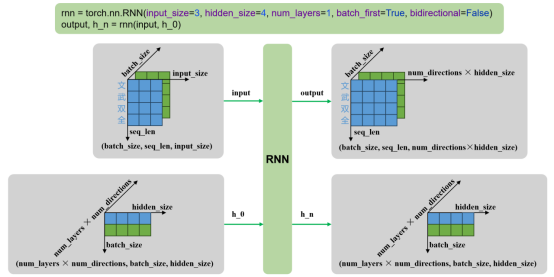
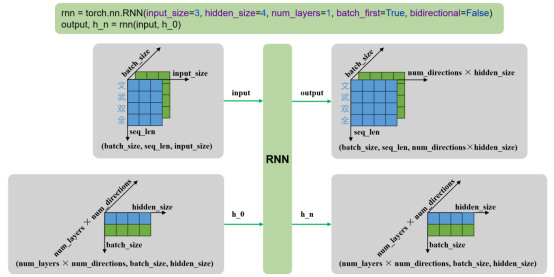
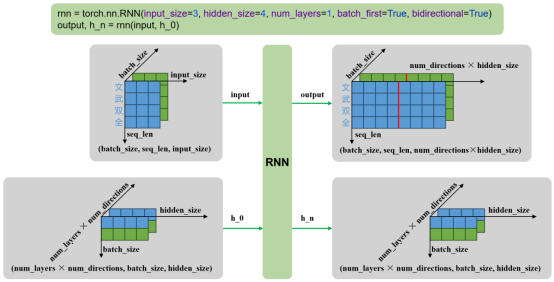
输入
- input:输入序列,形状为 (seq_len, batch_size, input_size),如果 batch_first=True,则为 (batch_size, seq_len, input_size)
- h_0:可选,初始隐藏状态,形状为 (num_layers × num_directions, batch_size, hidden_size)
-
输出
- output:RNN层的输出,包含最后一层每个时间步的隐藏状态,形状为 (seq_len, batch_size, num_directions × hidden_size ),如果如果 batch_first=True,则为(batch_size, seq_len, num_directions × hidden_size )
- h_n:最后一个时间步的隐藏状态,包含每一层的每个方向,形状为 (num_layers × num_directions, batch_size, hidden_size)
6.2.3 输入输出形状
-
单层单向
-
多层单向
-
单层双向
-
多层双向
7 案例实操------智能输入法
7.1 需求说明
本案例旨在实现一个用于手机输入法的智能词语联想模型。
具体需求为:根据用户当前已输入的文本内容,预测下一个可能输入的词语,要求返回概率最高的 5 个候选词供用户选择。
例如:向模型输入"自然语言",模型输出"处理"、"理解"、"的"、"描述"、"生成"。
7.2 需求分析
7.2.1 数据集处理
在本任务中,模型需要根据用户已输入的文本预测下一个可能输入的词语,因此训练数据应具备自然语言上下文连续性和贴近真实使用场景的特点。
可选数据来源包括:
- 用户真实输入内容:如聊天记录、搜索历史、输入法日志等。这类数据最能反映真实输入场景,有助于模型学习用户输入习惯和上下文联想模式。
- 开放领域对话语料:如论坛回复、社交平台评论、闲聊对话等。这类语料具有较强的口语化特征,能够提升模型在真实输入场景中的泛化能力。
为了构造适用于"下一词预测"任务的训练样本,首先需要对原始语料进行分词。随后,采用滑动窗口的方式,从分词后的序列中提取连续的上下文片段,并以每个窗口的下一个词作为预测目标,构成输入-输出对。
7.2.2 模型结构设计
本任务采用基于循环神经网络(RNN)的语言模型结构来实现"下一词预测"功能。模型整体由以下3个主要部分组成:
- 嵌入层(Embedding):将输入的词或字索引映射为稠密向量表示,便于后续神经网络处理。
- 循环神经网络层(RNN):用于建模输入序列的上下文信息,输出最后一个时间步的隐藏状态作为上下文表示。
- 输出层(Linear):将隐藏状态映射到词表大小的维度,生成对下一个词的概率预测。
7.2.3 训练方案
- 损失函数:下一个词的预测本质为多分类问题,所以损失函数采用 CrossEntropyLoss,其结合了softmax和交叉熵计算。
- 优化器:使用 Adam 优化器,具有较强的收敛能力和稳定性。