文章目录
- 一、R-CNN
- 二、评价指标
- [三、Fast R-CNN](#三、Fast R-CNN)
- [四、Faster R-CNN](#四、Faster R-CNN)
- 四、总结
- [五、Mask R-CNN](#五、Mask R-CNN)
- [六、Cascade R-CNN](#六、Cascade R-CNN)
一、R-CNN
整体的流程分为三步:
- 1、图片候选框生成与特征提取
- 2、确定框内是否有物体以及物体是什么
- 3、修正框的位置
(1) 预训练与微调

预训练是指在一个大规模通用数据集上,先训练一个基础 CNN 模型,让模型学习到通用的视觉特征。
大规模分类数据集(如 I m a g e N e t ) + C N N 模型(如 A l e x N e t ) = 预训练好的 C N N 模型 大规模分类数据集(如 ImageNet)+ CNN模型(如 AlexNet)= 预训练好的 CNN 模型 大规模分类数据集(如ImageNet)+CNN模型(如AlexNet)=预训练好的CNN模型
微调是指将预训练好的 CNN 模型,在新的特定任务数据集上进行二次训练,调整网络参数。
目标检测数据集(如 P A S C A L V O C ) + 预训练好的 C N N = 适配检测任务的 C N N 目标检测数据集(如 PASCAL VOC)+ 预训练好的 CNN =适配检测任务的CNN 目标检测数据集(如PASCALVOC)+预训练好的CNN=适配检测任务的CNN
生成候选区域(Region Proposal):对数据集中的每张图像,用选择性搜索(Selective Search)生成约 2000 个大小、比例不同候选区域(矩形框)。定义 "正样本"(IoU≥0.5)和 "负样本"(IoU<0.5)。- Step1:初始分割:使用 Felzenszwalb 算法进行超像素分割(superpixel segmentation),把将像素按颜色、纹理相似度聚成数百个初始小区域。每个区域都有自己的颜色直方图、纹理直方图、大小、位置等特征。
- Step2: 区域相似性计算:
- 颜色相似性 S color S_\text{color} Scolor :HSV 颜色空间中每个通道的直方图。交集的总和。
- 纹理相似性 S texture S_\text{texture} Stexture :用高斯导数提取每个区域的纹理特征,生成纹理直方图。交集的总和。
- 大小相似性 S size S_\text{size} Ssize :两个区域的大小接近程度
- 空间邻近性 S fill S_\text{fill} Sfill :两个区域在空间上是否紧密相邻
- Step3: 区域合并:计算所有相邻区域间的综合相似度(赋权或等权)。每次合并相似度最高的两个区域,形成新的区域。重新计算新区域与周边区域的相似度(更新颜色、纹理直方图等特征)。直到所有区域合并为一个整体。在合并过程中每一步生成的区域都作为候选区域保留。
- Step4: 后处理:合并过程会产生大量重叠的候选区域,通过非极大值抑制(NMS) 或阈值筛选,保留约 2000 个高质量候选区域(去除高度重叠的冗余框)。
区域归一化(Warping):选择性搜索生成的是候选框的坐标(x1, y1, x2, y2,即左上角和右下角坐标)。
程序会根据这些坐标,从原始图像中裁剪出对应的区域,再缩放 / 拉伸到 CNN 要求的固定尺寸(如 227×227 像素)。【CNN 的输入需要固定尺寸】
归一化候选区域图像块 + 预训练后的 C N N = 每个候选区域对应的高维特征向量 归一化候选区域图像块 + 预训练后的CNN=每个候选区域对应的高维特征向量 归一化候选区域图像块+预训练后的CNN=每个候选区域对应的高维特征向量
(2) 分类(Classification):
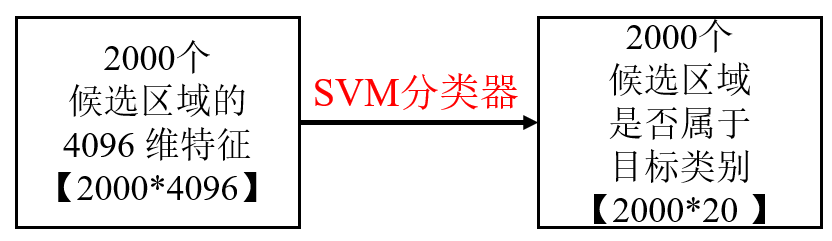
- 输入:微调后的 CNN 提取的每个候选区域的 4096 维特征。
- 标注:每个特征向量会根据IoU分别被标注为该 GT 的类别(如 "person" / "car")或"background" 类别。
正例:IoU ≥ 0.5(与真实框高重叠,含目标);
负例:IoU < 0.1(与真实框低重叠,为背景); - 为每个类别训练一个 SVM(如 VOC 的 20 类对应 20 个 SVM)
- 输出:判断该区域是否属于某一目标类别或背景。(1或-1)
- 非极大值抑制(NMS):同一目标可能被多个候选区域覆盖,通过 NMS 移除重叠度高的冗余框(保留置信度最高的框)
(3) 边框回归(Bounding Box Regression):
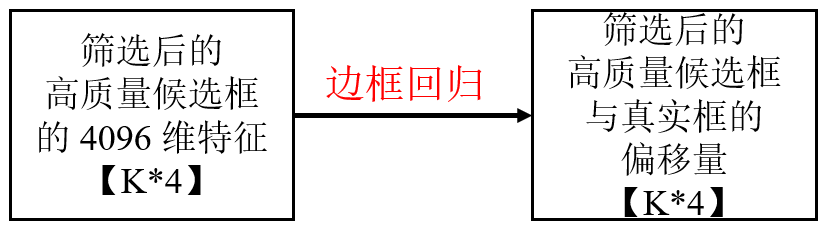
- 输入:微调后的 CNN 提取的每个候选区域的 4096 维特征。仅选择重叠度较高的候选区域(如 IoU≥0.6)作为训练样本(先通过 SVM 分类过滤掉背景类别,只保留被判定为目标的区域)。+ 候选框的坐标( 𝑥 𝑎 𝑥_𝑎 xa, 𝑦 𝑎 𝑦_𝑎 ya, 𝑤 𝑎 𝑤_𝑎 wa, h 𝑎 ℎ_𝑎 ha)。
- 标注:候选框与真实框的偏移量。
- 训练线性回归模型,输出:候选框与真实框的偏移量 tx, ty, tw, th
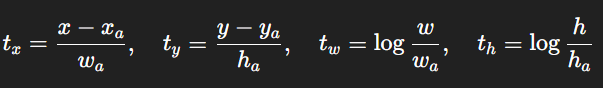
其中 ( 𝑥 𝑎 𝑥_𝑎 xa, 𝑦 𝑎 𝑦_𝑎 ya, 𝑤 𝑎 𝑤_𝑎 wa, h 𝑎 ℎ_𝑎 ha)是候选框,(𝑥,𝑦,𝑤,ℎ)是真实框。
R-CNN的优点:
- 提出
候选区域 + 特征提取 + 分类的模块化框架 - 引入
边框回归提高定位精度。 - 首次将深度学习引入目标检测,在 R-CNN 之前,目标检测主要依赖手工设计的特征(如 HOG、SIFT)和传统分类器(如 SVM),精度受限。
二、评价指标
| 预测出了目标 | 没有预测出目标 | |
|---|---|---|
| 确实存在目标 | True Positive(正确) | False Negative(漏检) |
| 不存在目标 | False Positive(误检) | True Negative |
-
Precision(精确率):反映预测的准确性,越低说明误检越多
P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP -
Recall(召回率):反映预测的完整性,越低说明漏检越多
R = T P T P + F N R = \frac{TP}{TP + FN} R=TP+FNTP -
PR 曲线:以召回率 recall 为横轴、精确率 precision 为纵轴绘制的曲线,反映不同置信度阈值下模型的精度 - 召回权衡。 -
AP(平均精度):单个类别的 PR 曲线下的面积,衡量该类别的检测精度。 -
mAP(mean Average Precision,平均精度均值)所有类别AP的平均值,是目标检测中最核心的评价指标。 -
IoU(Intersection over Union,交并比):预测框与真实框的交集面积除以并集面积。判断预测框是否有效。
I o U = A r e a ( 预测框 ∩ 真实框 ) A r e a ( 预测框 ∪ 真实框 ) IoU = \frac{Area(预测框 \cap 真实框)}{Area(预测框 \cup 真实框)} IoU=Area(预测框∪真实框)Area(预测框∩真实框) -
AP@0.5:IoU ≥ 0.5 就算对。AP@0.75:IoU ≥ 0.75 才算对 -
mAP@0.5:0.95= 在 IoU=0.5 到 0.95(步长0.05)10个阈值下的平均 mAP -
推理时间(Inference Time)模型处理单张图像并输出检测结果的时间(单位:毫秒 ms 或秒 s)。
-
参数量(Parameters):模型中可学习参数的总量(单位:百万 M)。
-
计算量(FLOPs,Floating Point Operations)模型推理过程中所需的浮点运算次数(单位:十亿 G)。
三、Fast R-CNN
R-CNN 的缺点:
- 速度慢:对每张图像的 2000 个候选区域,需单独输入到CNN 提取特征,导致卷积层重复计算
- 训练复杂:训练流程不端到端,步骤繁琐。
- 存储需求大:需要对每个候选框提取特征并存储到硬盘再训练 SVM → 硬盘 I/O 成瓶颈。
- 候选框依赖外部算法:使用 Selective Search 提供候选区域 → 速度慢且受候选框质量限制。
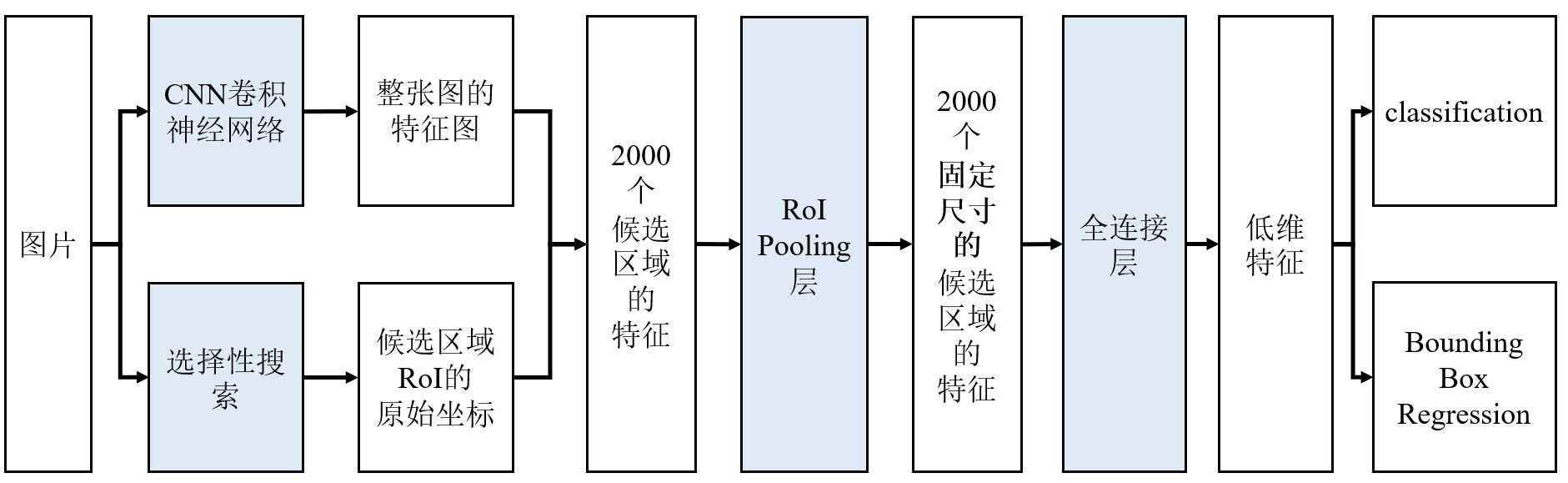
改进1: 特征共享
- 先对整幅图像一次性运行
卷积网络,得到全图的卷积特征图(Feature Map) - 用
选择性搜索生成候选区域(RoI,Region of Interest) - 将其从原始图像坐标映射到特征图坐标,从特征图中直接裁剪出每个候选区域对应的特征。
RoI Pooling:将任意尺寸的候选区域特征转换为固定尺寸。- 假设 RoI 在特征图上是 30×20 的区域。我们希望输出 7×7 的特征图。
- 就把这 30×20 的区域划分为 7×7 个小格,每个格子大约 4×3 的大小。
- 在每个小格内做 max pooling(最大池化)。这样无论原来的 RoI 大小是多少,最终都会得到 7×7 的固定大小特征。结果送入全连接层。
改进2: 端到端训练
- R-CNN分三步训练:CNN 特征提取 → SVM 分类器 → 边框回归器
- Fast R-CNN :图像------卷积------ROI Pooling------全连接层------softmax分类层+边框回归层(修订坐标)
- 用 Softmax 替代 SVM,实现多分类统一输出。R-CNN输出的是 "是否属于该类" 的决策,Fast R-CNN使用 Softmax 层实现多分类,直接输出所有类别(包括背景)的概率分布。
用一个统一的损失函数同时优化分类和回归任务:
-
分类损失:采用交叉熵损失,针对每个候选区域(RoI)计算其预测类别概率与真实类别的差异
L cls ( p , u ) = − l o g p u L _\text{cls} (p,u)=−log p _u Lcls(p,u)=−logpu- u u u:真实类别标签(若为背景, u = 0 u=0 u=0;若为第k类目标, u = k u=k u=k)。21 类:20 类目标 + 1 类背景
- p p p:Softmax 输出的概率分布, p u p_u pu是预测为真实类别 u u u的概率)。
-
边框回归损失(Bounding Box Regression Loss):采用平滑 L1 损失(Smooth L1 Loss),仅对 "非背景" 的候选区域计算预测偏移量与真实偏移量的差异
L reg ( t , t ∗ ) = ∑ i = 1 4 s m o o t h L 1 ( t i − t i ∗ ) L_\text{reg} (t,t^*)=\sum_{i=1}^{4} smooth L1 (t_i−t^*_i) Lreg(t,t∗)=i=1∑4smoothL1(ti−ti∗)- t:回归分支输出的预测偏移量(dx, dy, dw, dh)。
- t ∗ t^* t∗:根据候选框与真实框计算的真实偏移量(作为标签)
-
总损失函数:将分类损失和回归损失加权求和,作为网络的总优化目标
L o s s = L cls + λ u ≠ 0 L r e g Loss=L_\text{cls}+\lambda u \\neq 0 L_{reg} Loss=Lcls+λu=0Lreg
四、Faster R-CNN
R-CNN / Fast R-CNN 的瓶颈:依赖传统的选择性搜索生成候选区域,该过程完全独立于神经网络,速度慢。
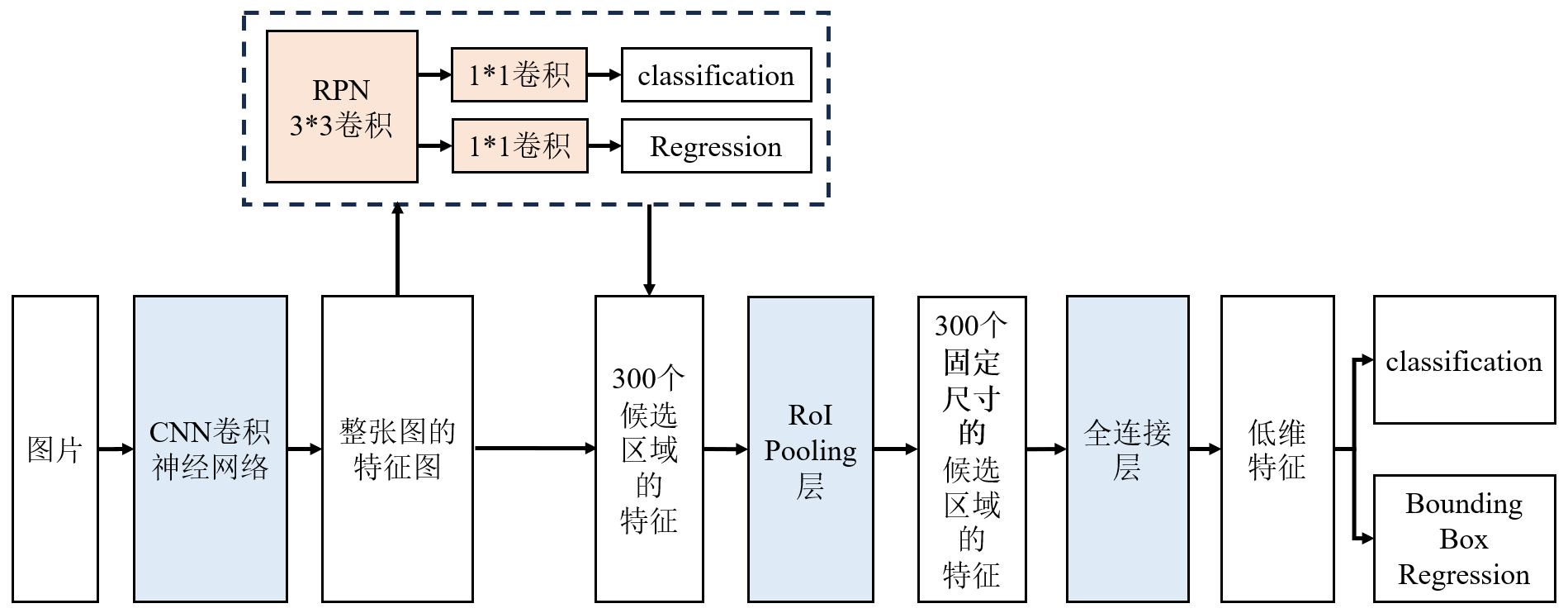
改进:区域提议网络(Region Proposal Network):用 CNN 自己学习生成候选区域,彻底替代了选择性搜索。
- 输入:整图卷积特征图
Anchor Box锚框:在特征图上滑动一个小网络(3×3 卷积),每个滑动窗口位置预设k个锚框(通常k=9),涵盖 3 种尺度(128×128、256×256、512×512)和 3 种长宽比(1:1、1:2、2:1),适配不同大小和形状的目标。为特征图上的每个位置生成多个候选框。- 对每个锚框,RPN 输出两个结果:
- 二分类分数:判断锚框是否包含目标("前景" 或 "背景")。
- 边框回归偏移量:修正锚框坐标,使其更接近真实目标。NMS去除冗余候选框
- 输出:RPN 先通过前景概率阈值过滤掉明显是背景的锚框;对保留的锚框用边框回归修正坐标;NMS去除高度重叠的候选框,最终保留约 300 个高质量的候选区域(坐标对应原始图像)。
四步交替训练:
- Step 1: 训练 RPN使用 ImageNet 预训练的 CNN(比如 VGG16、ResNet)初始化。输入图像,训练 RPN 来生成候选区域(anchors 的分类 + 回归)。得到初步的候选框。
- Step 2: 训练 Fast R-CNN:用 Step1 的候选框作为训练样本。共享同样的 CNN 特征层,Fast R-CNN 训练分类器和边框回归器。
- Step 3: 固定 Fast R-CNN,微调 RPN:把 Fast R-CNN 的卷积层固定住。重新训练 RPN,让它和 Fast R-CNN 更加匹配。
- Step 4: 固定 RPN,微调 Fast R-CNN:最后再微调 Fast R-CNN 的参数,使得两个网络达到一致。
四、总结
| 特性 | R-CNN | Fast R-CNN | Faster R-CNN |
|---|---|---|---|
| 候选框 | Selective Search | Selective Search | RPN(网络生成) |
| 特征提取 | 每个 RoI 单独 | 整图共享 CNN | 整图共享 CNN |
| ROI 特征 | Warp 到固定大小 | ROI Pooling | ROI Pooling |
| 分类/回归 | SVM + Linear Regressor | 端到端多任务 | 端到端多任务 |
| 训练 | 三阶段 | 端到端联合训练 | 端到端联合训练 |
| 速度 | 很慢 | 快 | 更快(≈5 FPS 以上) |
R-CNN模型都两阶段(Two-Stage)检测器把任务拆成两步:
- 候选区域生成(Region Proposals):找出"可能有目标"的若干候选框;
- 分类 + 回归(Detection Head):对每个候选框判别类别并精修边界框。
SSD、YOLO等算法都是one-Stage算法
五、Mask R-CNN
Mask R-CNN 是在 Faster R-CNN 基础上扩展:
- 它不仅能完成目标检测(定位 + 分类)
- 在 Faster R-CNN 的基础上增加了一个掩码分支,对每个目标进行像素级的分割。
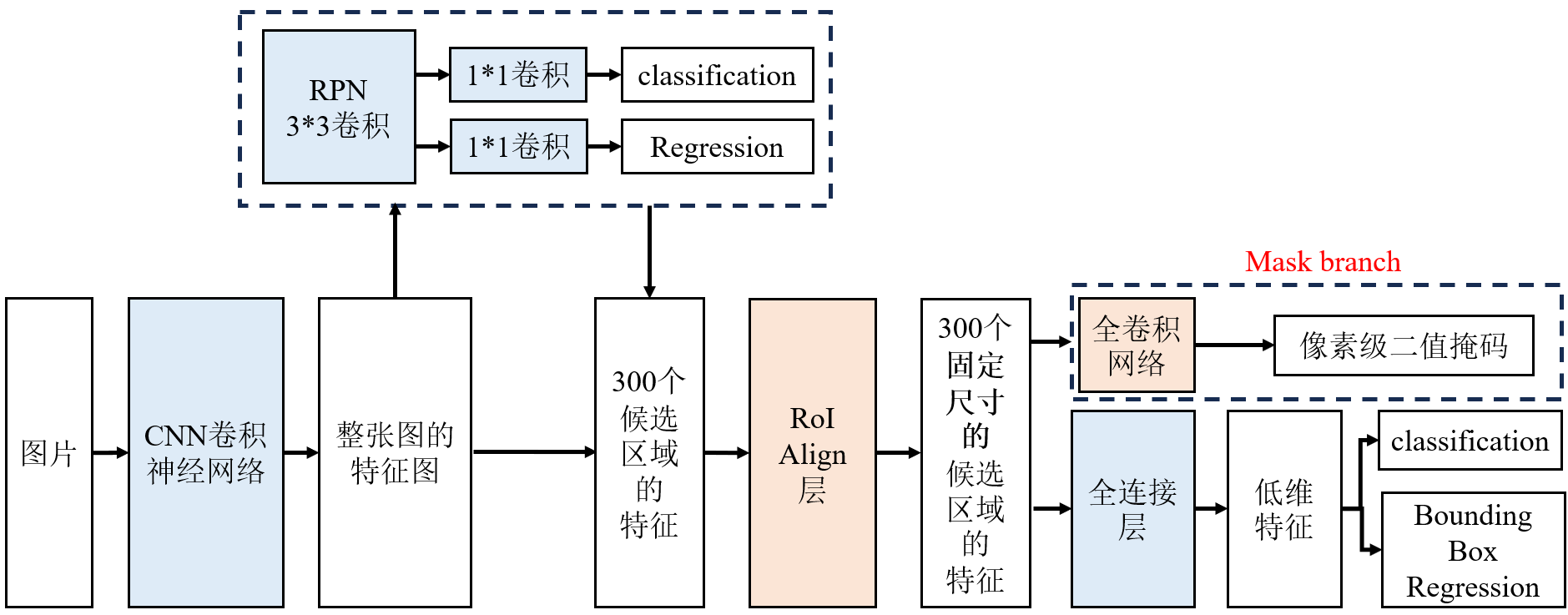
改进1:RoI Align对齐:用RoI Align替代 RoI Pooling,解决区域特征提取时的量化误差问题。
- 保留候选框映射到特征图后的浮点坐标(不量化)。RoI pooling会对坐标进行整数量化(如向下取整)
- 将特征图上的候选区域划分为固定数量的子网格(如 14×14),每个子网格的坐标仍为浮点数。
对每个子网格,通过双线性插值计算 4 个参考点的像素值。 - 再取最大值(或平均值)作为该子网格的特征值。
详见链接https://cloud.tencent.com/developer/article/1829792
改进2:mask branch:新增掩码分支,用于实现实例分割的关键组件,其核心作用是为每个检测到的目标生成像素级的二进制掩码(binary mask),精准标记出目标在图像中的像素位置。让检测结果从矩形框升级为像素级别的目标轮廓。
- 输入:RoI Align 处理后的候选区域特征(固定尺寸,如 14×14)
- 通过一系列反卷积层(上采样操作)将特征图从 14×14 放大到m×m。
- 输出:一个二值掩码:掩码中每个像素的值为 0 或 1(通过 Sigmoid 激活函数处理),1 表示该像素属于目标,0 表示属于背景。例如,检测到 "猫" 的区域后,掩码分支会生成一个与猫轮廓完全重合的掩码,精准标记出猫的每一个像素。
类特异性掩码(class-specific mask):掩码分支为每个类别单独生成掩码,即当模型判定某个候选区域属于类别 k 时,仅输出该类别对应的掩码,其他类别的掩码输出会被忽略。若候选区域被分类为 "猫",则仅生成 "猫" 的掩码,忽略其他类别的掩码输出。
损失函数为三部分之和:
L = L cls + L box + L mask L=L \text{cls} +L\text{box}+L _\text{mask} L=Lcls+Lbox+Lmask
最终效果:
- 分类分支:判断是狗还是猫。
- 回归分支:调整边界框,让它更准确。
- mask branch:在狗的框里,把每个像素标记为"狗"还是"背景",得到一个清晰的目标轮廓。
六、Cascade R-CNN
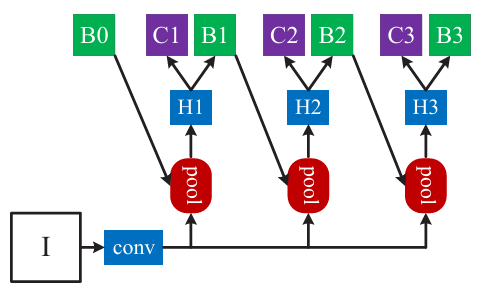
Cascade R-CNN 的每个阶段有针对性目标:
- 第 1 阶段:专注修正低质量框(IoU ≥ 0.5),输出中等质量框(IoU ~0.6)。
- 第 2 阶段:专注修正中等质量框(IoU ≥ 0.6),输出高质量框(IoU ~0.7)。
- 第 3 阶段:专注修正高质量框(IoU ≥ 0.7),输出更高质量框(IoU ~0.8+)。
每个阶段的回归器 "各司其职"。