almalinux9.6系统:k8s可选组件安装(1)
- 一、介绍
- 二、可选组件
-
-
- 1、网络插件-CNI
- 2、监控插件-metrics
-
- 自动扩缩容HPA/CPA
-
- [部署VPA CRD](#部署VPA CRD)
- 实验-自动伸缩HPA/VPA
-
一、介绍
上篇文章使用kubeadm将k8s集群拉起来了,做了快照还有实验创建了pod+svc+副本+更新+回滚等操作。
这篇文章我们部署下k8s集群还可以部署的可用组件,metrics提供监控,dashboard提供页面访问,ingress提供外部域名访问,promethues+grafana系统监控等等。
还有我们上篇文章部署的flannel组件,他就是一个可选组件,只不过为了保证master和node节点的同学成为了必须安装的,上篇文章我们就已经安装了。
机器信息:
| 主机名 | IP地址 |
|---|---|
| almalinux-master-192e168e100e30 | 192.168.100.30 |
| almalinux-node01-192e168e100e31 | 192.168.100.31 |
| almalinux-node02-192e168e100e32 | 192.168.100.32 |
版本信息:
| 描述 | 版本 |
|---|---|
| almalinux9.6 | 5.14.0-570.12.1.el9_6.x86_64 |
| flannel | v0.27.1 |
| metrics | v0.7.1 |
| VPA-CRD | 1.4.1 |
容器镜像压缩包:百度云
二、可选组件
1、网络插件-CNI
kubernetes中官方文档中关于网络插件的介绍,这里说实话,我是没找到如何部署这个网络插件,可能是我功力比较低了。
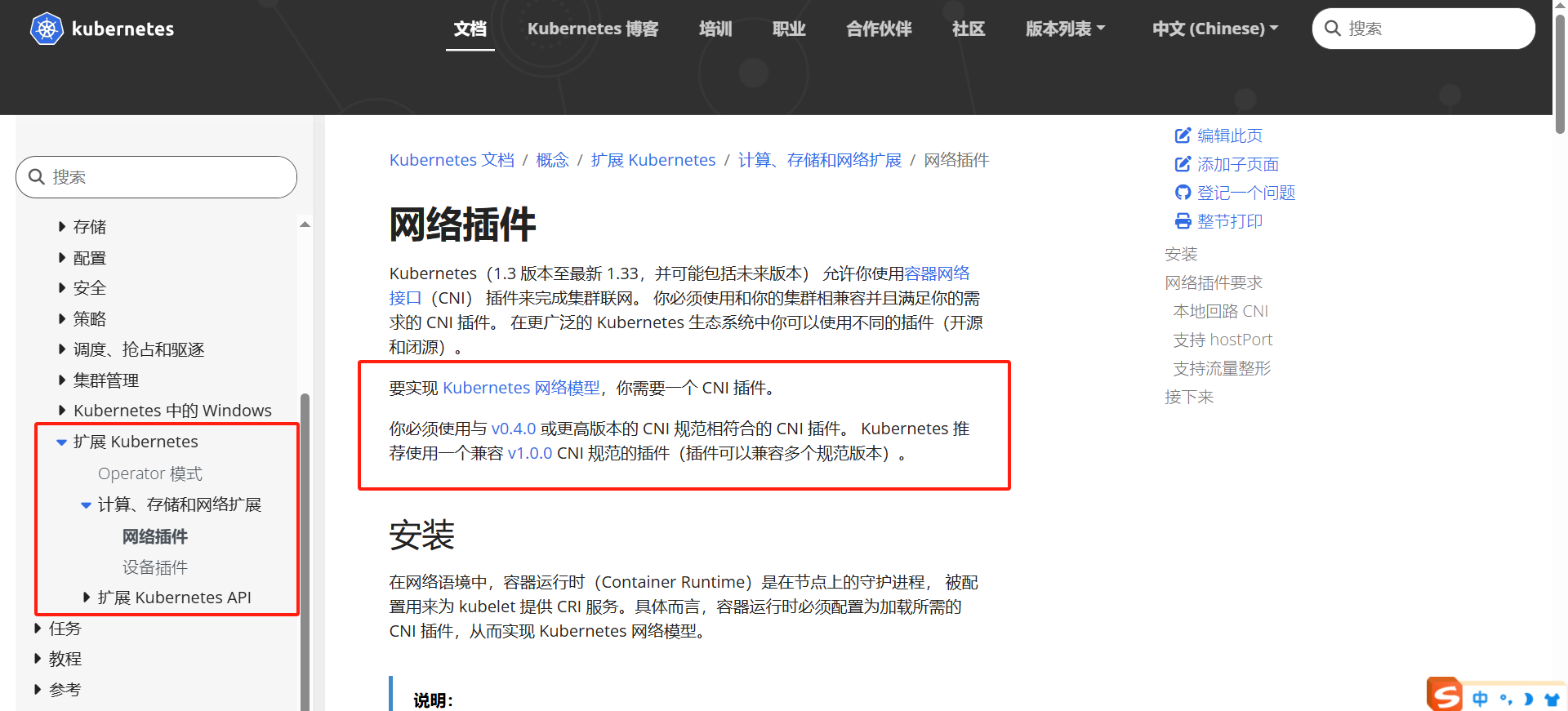
遇事不决问度娘,这里是给了三种网络CNI插件,特性适用场景如下:
calico ------》支持BGP路由和网络策略、高性能,适用需要高级安全控制的场景,适合大规模集群;
flannel ------》基于VXLAN隧道机制,配置简单默认不支持网络策略,适合中小集群;
weave net ------》提供加密通信和自动发现
我选择的是flannel组件,自己搭建环境做实验的场景下还是比较方便的,只需要初始化的时候增加参数指定个网络就好了。
github地址:flannel仓库
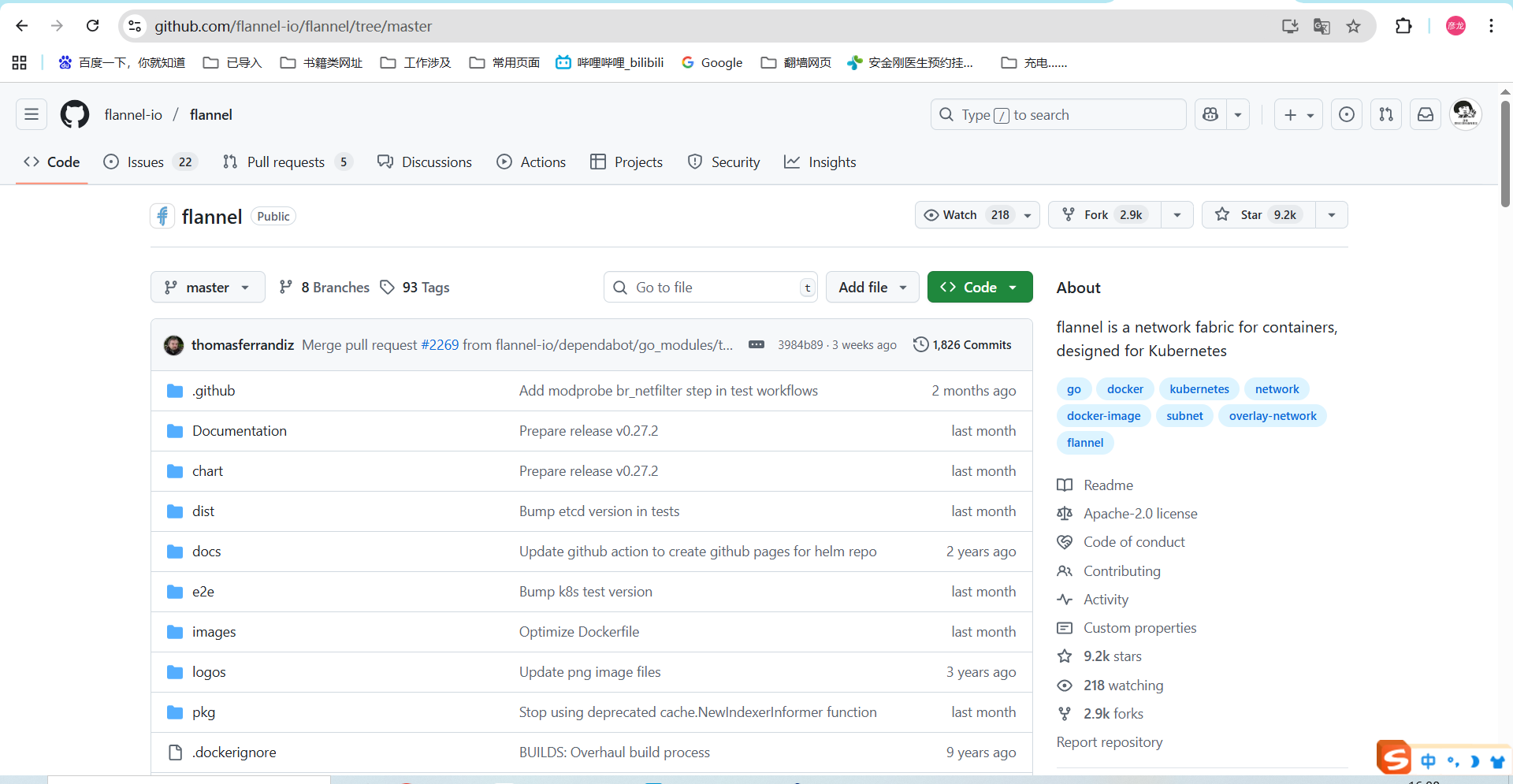
这里我们可以查看下他的tag看下都有哪些版本,我选择的是0.27.1的
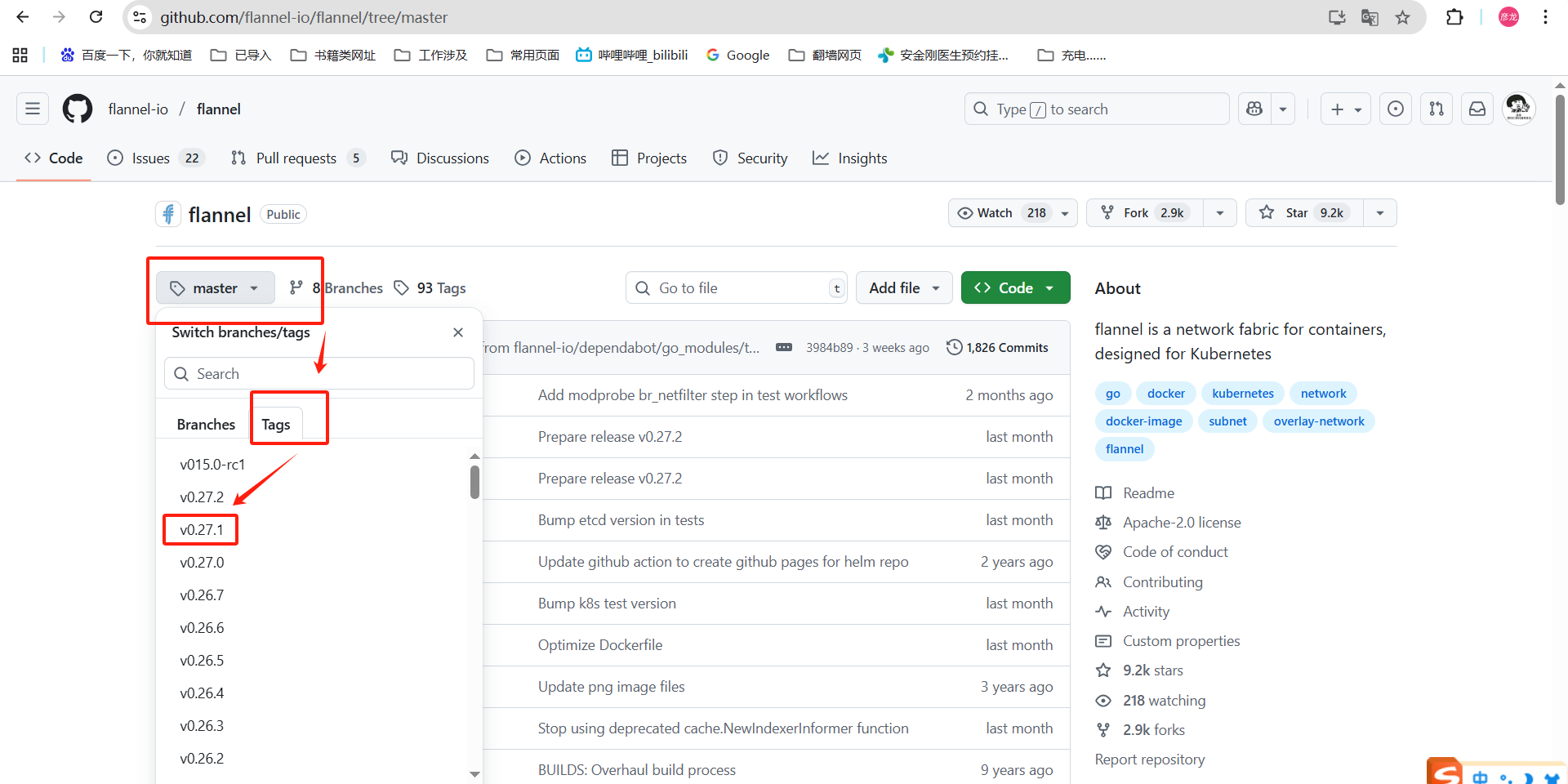
这个就是我使用yaml文件的位置了,部署的时候你可以使用我压缩包中的,也可以直接上github这个位置进行下载就好。
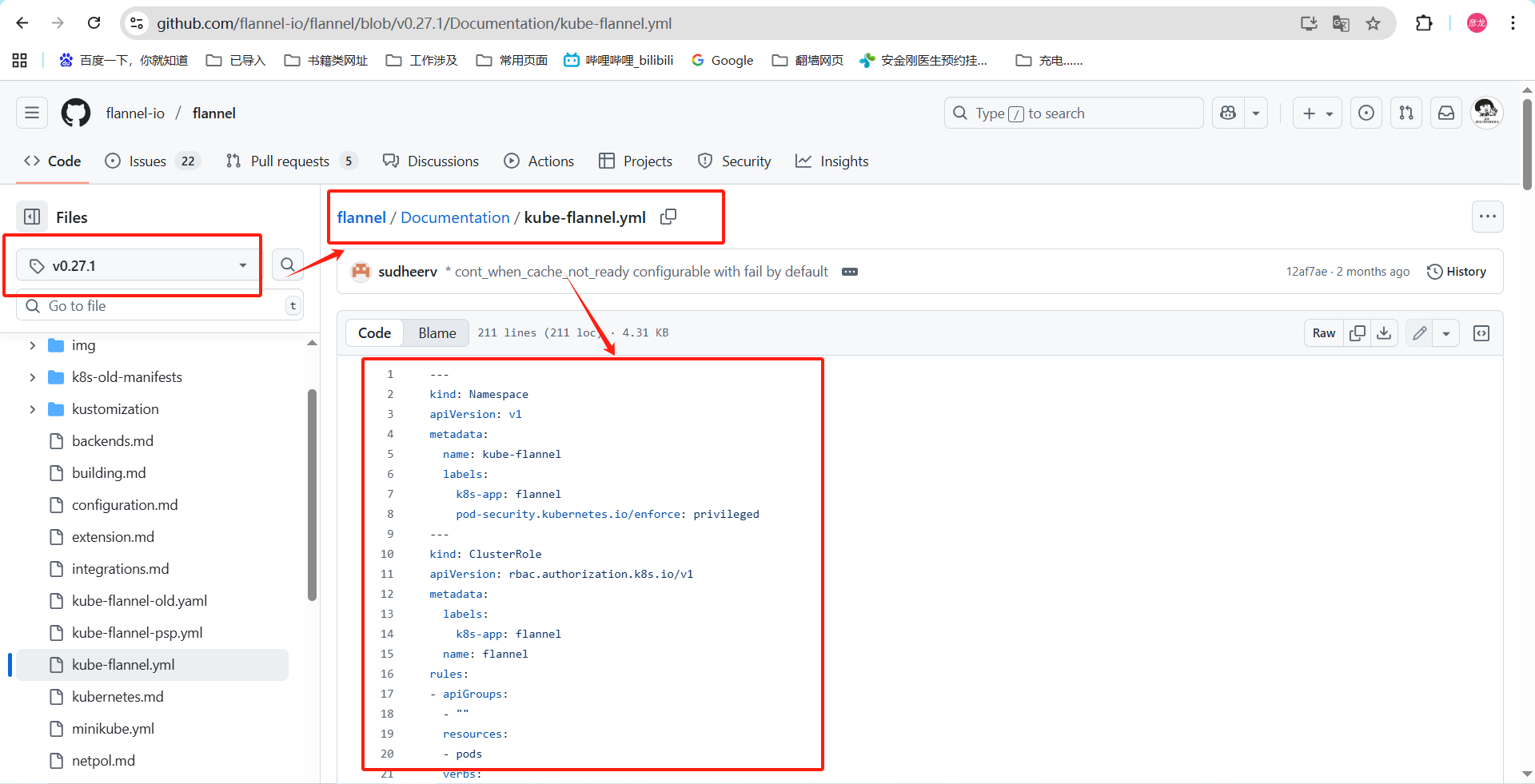
我部署的时候就是用的事flannel作为kubernetes网络组件进行通信的,在初始化集群的时候我们指定的网段【--pod-network-cidr=10.244.0.0/16】。
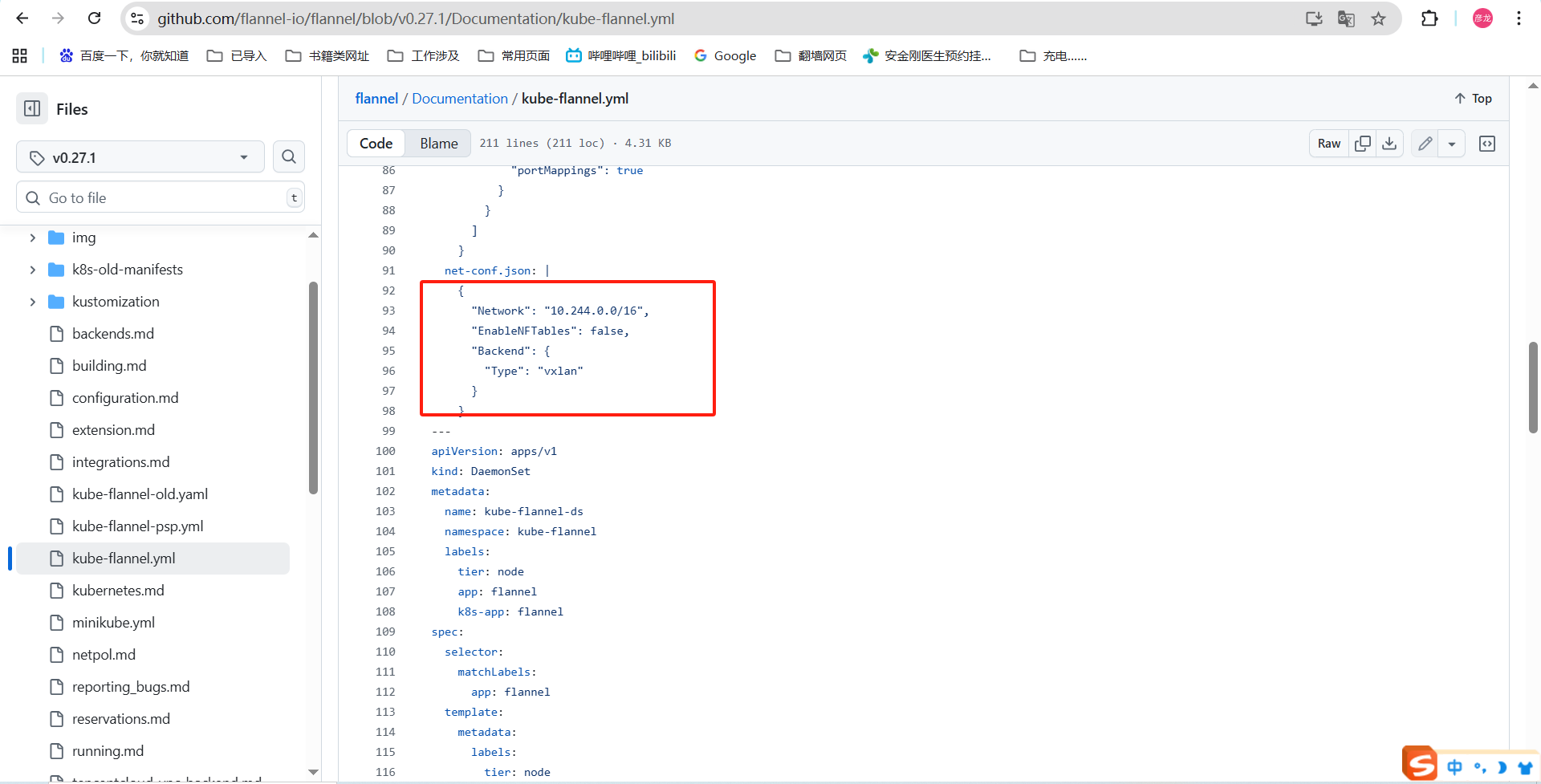
flannel组件是用于集群内节点通信的,那么他就需要在每个节点上都部署一个,他是怎么实现的------》通过DaemonSet定义。
DaemonSet是kubernetes的核心pod控制器之一,他是为了确保集群中所有节点或者符合标签的节点运维唯一的副本,简单理解我给flannel设置了DaemonSet那么每多一个node节点就要启动一个flannel,要是节点上这个flannle折了那么DaemonSet会负责把他拉起来,多一个不行,少一个不干。
bash
kubectl get ds -A # 查看ds-DaemonSet能看到flannel
flannel部署完可以到master上查看是有路由的,用于pod跨节点通讯。
bash
ip r show | grep flannel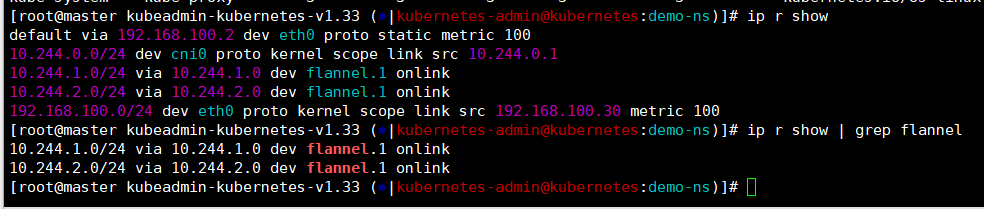
上面就是flannel组件的描述和部署后的检查,上一篇文章是为了简介的进行环境部署所以也没介绍,这里简单说明下。
2、监控插件-metrics
在kubernetes中metrics是用来收集和提供集群资源的实时使用数据如内存和cpu的指标,他还是自动扩缩容HPA/VPA的核心依赖。
github地址:metrics仓库
这里我们点击code之后往下拉可以看懂啊这个release点击下
再往下划拉下你就可以找到0.7.1了,这里下载可以或者是用我压缩包里面的也可以。
bash
pwd ------》/home/secure/kubeadmin-kubernetes-v1.33
kubectl apply -f components.yaml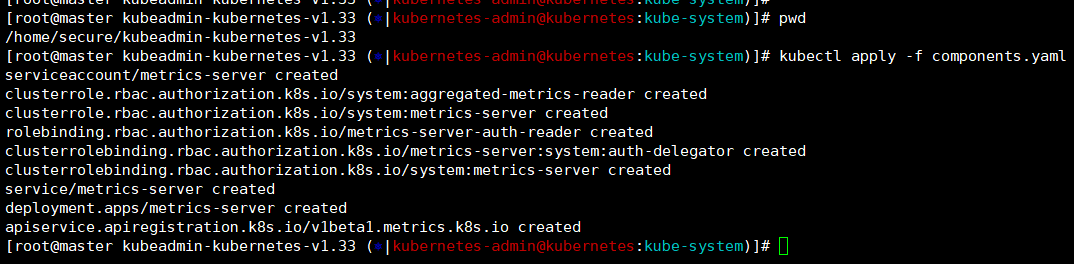
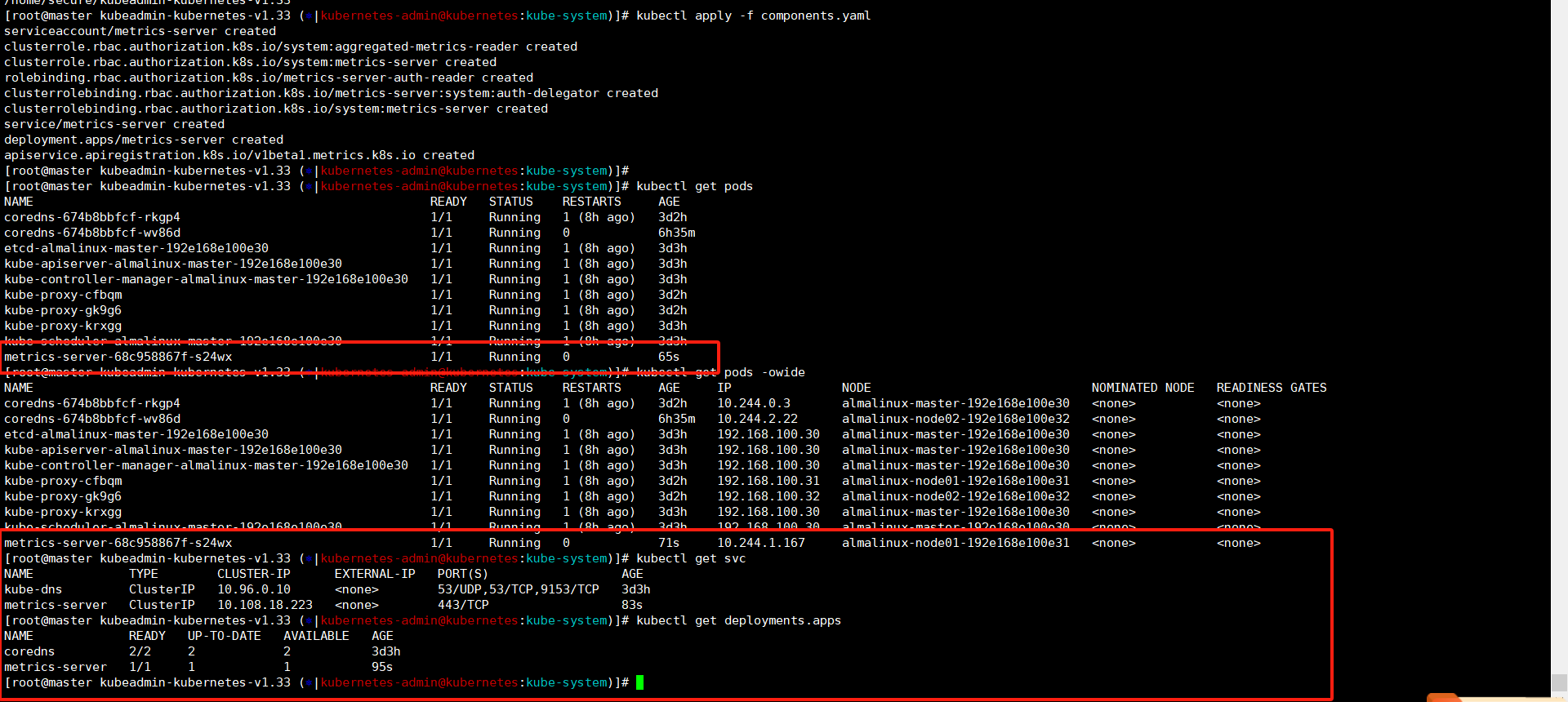
这里可以看到metrics的pod已经起来了,还可以看到metrics所属的service和deployment。
等个三五分钟我们就可以用top命令看到node和pod的cpu和内存的使用情况了------》注意,他这里显示的是已使用的容量不是总量,如果你给node节点扩容了内存或者是cpu,这里是没法明显的看出来。
bash
kubectl top node
kubectl top pod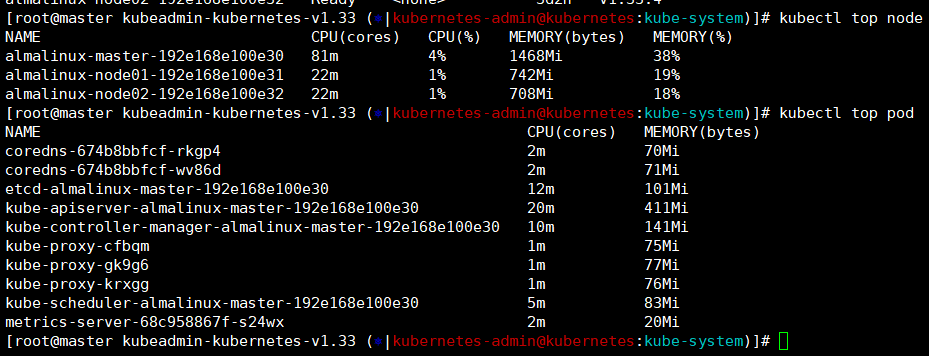
自动扩缩容HPA/CPA
HPA水平自动伸缩,VPA垂直自动伸缩,他们都是依赖metrics的数据来进行动态调整的。
什么叫水平?什么叫垂直呢?我也不知道,但是根据百度到的现象和实验看到的现象来说。
------》HPA是根据我们设置的阈值,比如将cpu使用率设定为百分之70,那么当pod的cpu使用率超过百分之77的时候(这里比较坑HPA除了我们设置阈值自己还有百分之10的预留量)他会通过增加pod的数量来减轻复杂让环境平稳运行;
------》VPA也是根据我们设置的阈值,比如我们给pod一个cpu和内存能使用最大最小区间,他会根据metrics收集的数据来进行扩缩容,他不会修改pod的数量而是修改pod中的最大和最小能使用的cpu内存容量来进行调整;
上面这两个概念看着字都认识但是组合在一起是真不知道他想表达什么,让我们做实验吧!
首先这里我们明确一点,HPA/VPA是依赖于metrics的,所以我们需要先部署了并且保证top能正常看到node和pod的数据,接着VPA我们还需要安装一个VPA CRD才能正常使用,然后我们通过yaml的方式来创建HPA和VPA就好了。
这里需要说一点,HPA/VPA是基于namespace命名空间的,所以我下面的实验都是在demo-ns命令空间中操作的。
部署VPA CRD
github地址:VPA-CRD仓库
VPA的这个CRD这个比较特殊,其他的组件部署都是下载yaml直接执行,而它是需要git clone下来然后到指定目录进行执行。
还是那个dns污染闹得,我这通过ssh和https是无法正常把仓库拉下来的。
bash
yum install git -y
git clone git@github.com:kubernetes/autoscaler.git
git clone https://github.com/kubernetes/autoscaler.git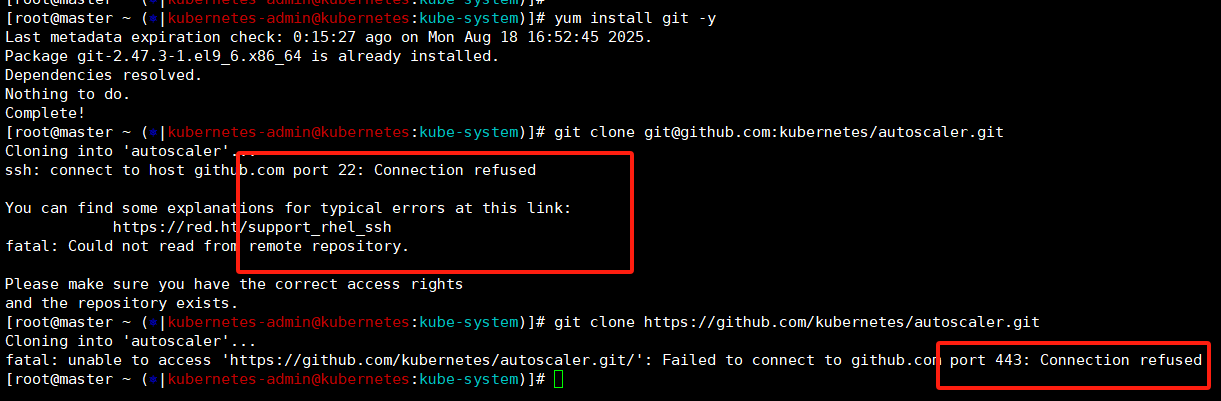
这里我们还是使用ssh然后将端口修改为443,就可以正常clone下来了,就是速度慢------》我这里也会放到压缩包中,兄弟们直接用也行。
bash
[root@master vpa-crd (?|kubernetes-admin@kubernetes:kube-system)]# cat ~/.ssh/config
Host github.com
Hostname ssh.github.com
Port 443
user git
git clone git@github.com:kubernetes/autoscaler.git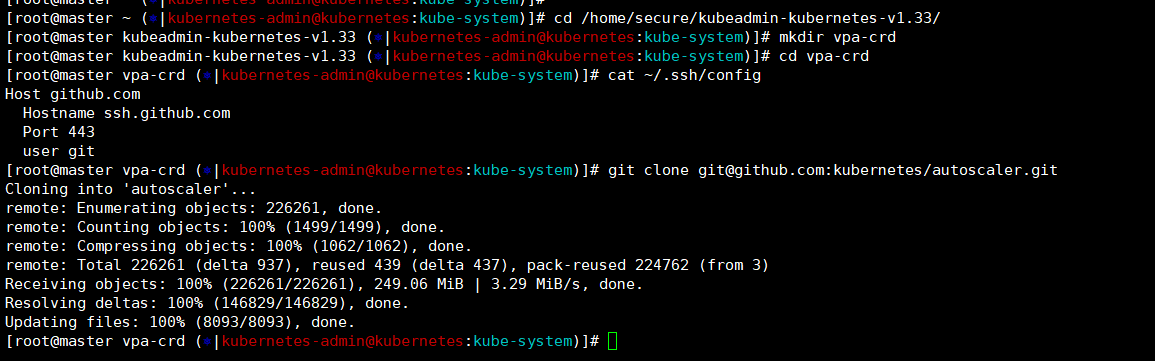
老样子还是将容器镜像导入,在两个node节点上导入就好了。
bash
ll /tmp/docker-images/kubernetes-metrics-VPA-CRD-1.4.1/
ls /tmp/docker-images/kubernetes-metrics-VPA-CRD-1.4.1/* | awk '{print "ctr -n=k8s.io images import " $1}' | bash
bash
pwd ------》/home/secure/kubeadmin-kubernetes-v1.33/vpa-crd/autoscaler/vertical-pod-autoscaler
ll ./hack/vpa-up.sh ./hack/vpa-down.sh
bash ./hack/vpa-up.sh # 部署VPA-CRD
bash ./hack/vpa-down.sh # 卸载VPA-CRD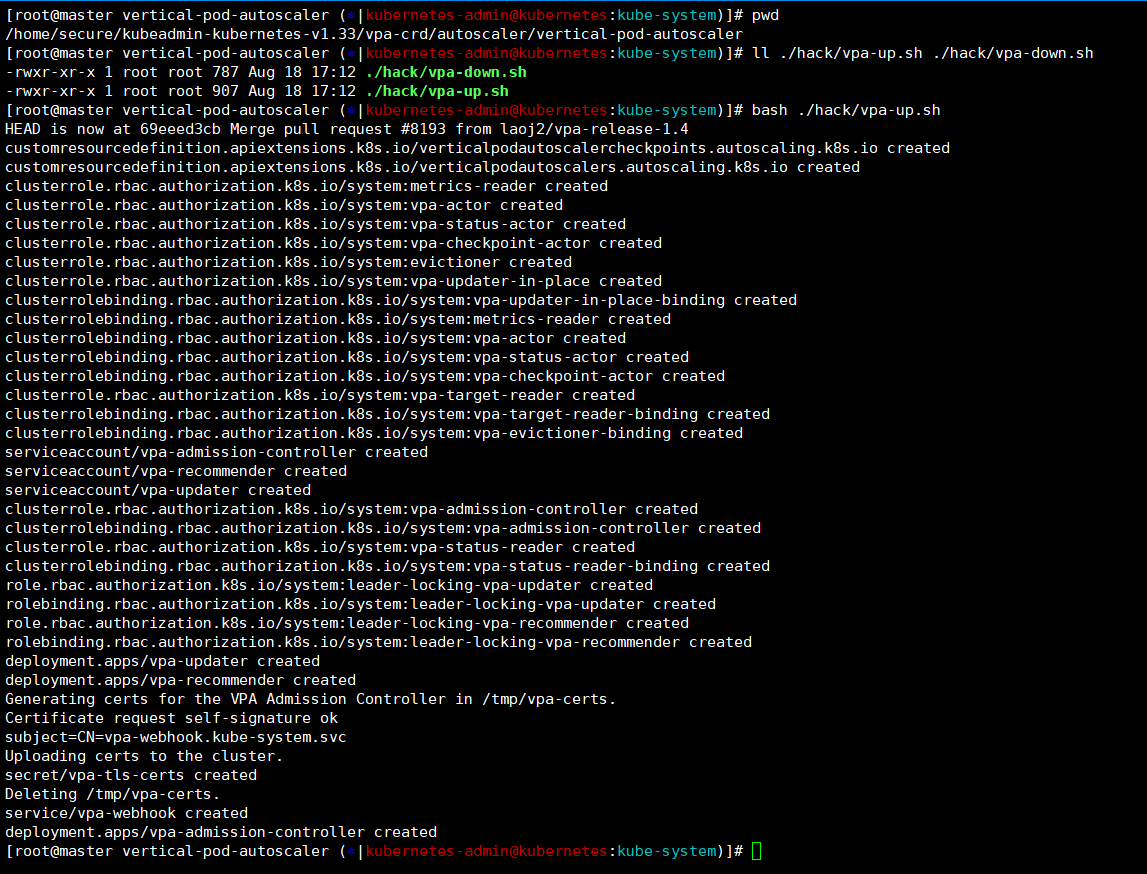
这里我们可以查看到在kube-system命名空间中启动了三个vpa的pod。
bash
kubectl -n kube-system get pods -owide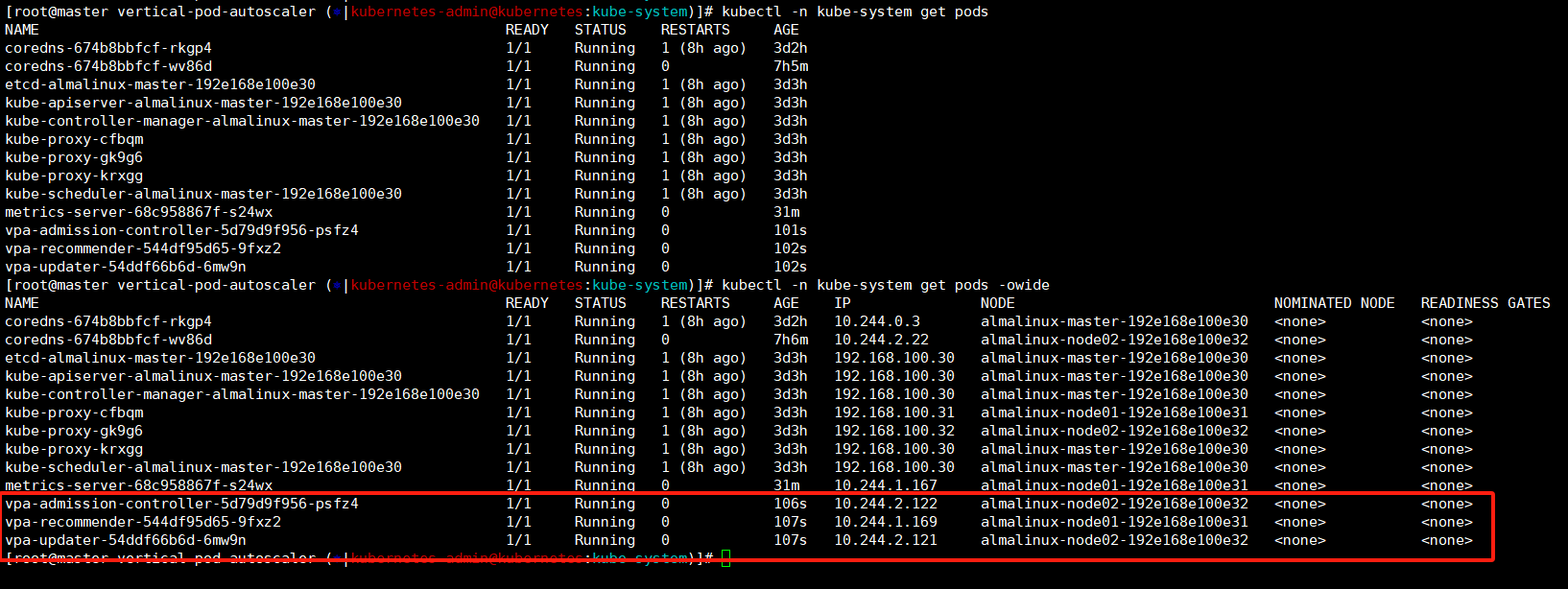
实验-自动伸缩HPA/VPA
现在HPA和VPA可以正常调用了,现在我们可以开始做点有趣的实验了!
步骤:
1、创建一个namespace命名空间【demo-ns】
2、创建一个deployment【nginx-app】这里需要额外制定下最大最小资源
3、创建一个service给deployemtn,后面压测需要访问页面,整一个
4、创建HPA和VPA然后查看状态
5、手动触发HPA和VPA,HPA可以通过压测来看到明显现象,pod变多了;VPA这个比较抽象只能查看下,具体现象没得;
这个是下面配置HPA/VPA会使用的cpu/内存组合,先码在这里方便我一会配置的时候过来查看。
| CPU | 内存 |
|---|---|
| 1 CPU = 1000m(milliCPU) | 2G = 2048Mi |
| 500M | 1024Mi |
| 250m | 512Mi |
| 125m | 256Mi |
| 64m | 128Mi |
| 32m | 64Mi |
| 16m | 32Mi |
| 8m | 16Mi |
| 4m | 8Mi |
HPA
创建下命令空间然后通过deployment方式创建pod,这里可以看到一个现象,我们先创建的deploy然后set设置的资源限额,这里可以看到pod在set之后重建了,然后我们查看deploy和pod的cpu/内存设置和我们设置的是一样的。
PS:这里我们创建deployment的时候通过set指定了资源限额,如果没有限额HPA的阈值没法计算百分比就无法触发更新机制。VPA是可以给pod设置这个资源限额的,这种情况下其实是可以先做VPA实验然后pod有了资源限制然后再做HPA实验的。我这里已经这样了,也就懒得改了。
bash
kubectl create namespace demo-ns
kubens demo-ns
kubectl create deployment nginx-app --image nginx:1.27.0 --replicas 3 --save-config
kubectl set resources deployment nginx-app --limits=cpu=64m,memory=128Mi --requests=cpu=16m,memory=32Mi
kubectl get pods
kubectl describe deployments.apps nginx-app
kubectl describe pods nginx-app-5474fb8dd7-gb2p6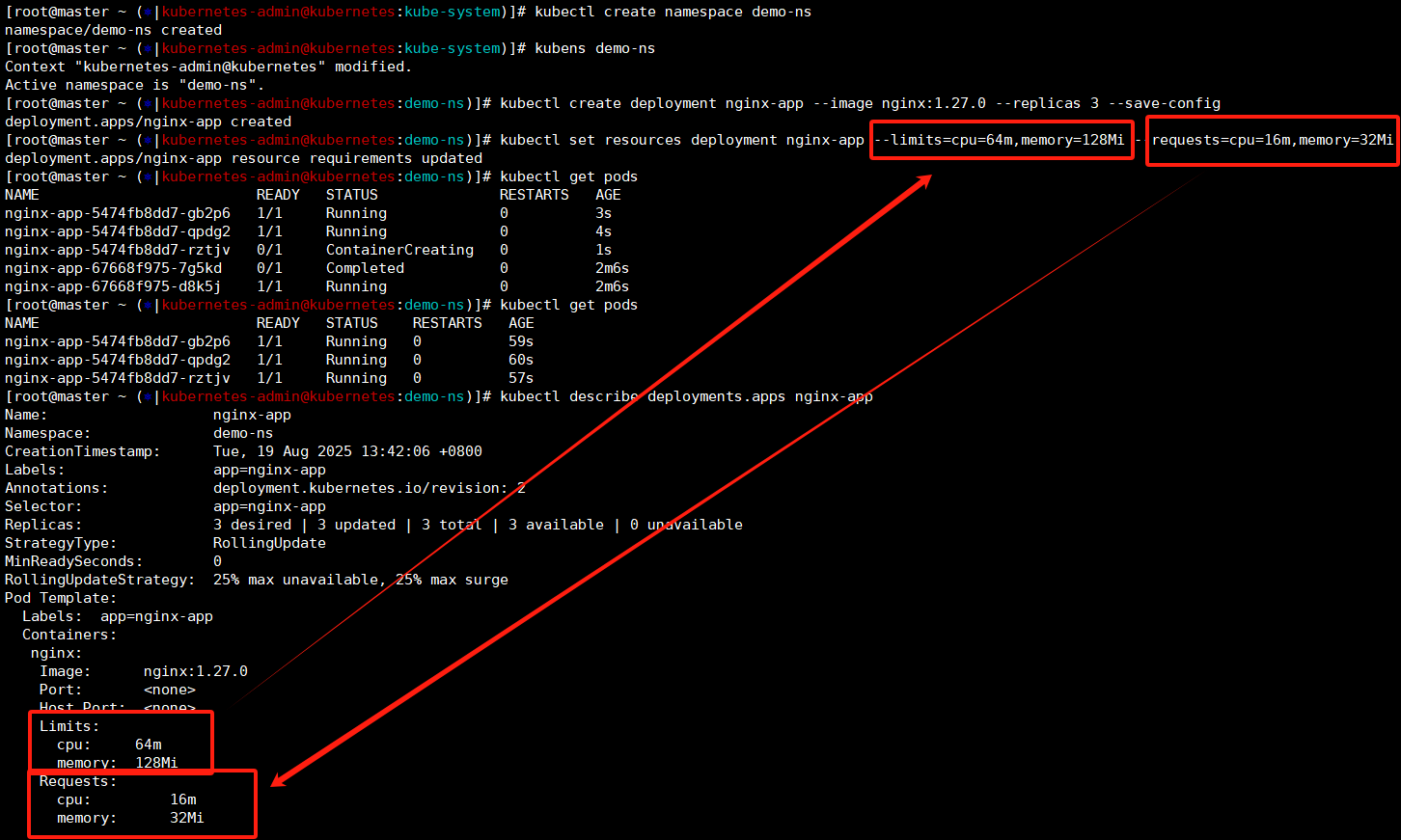
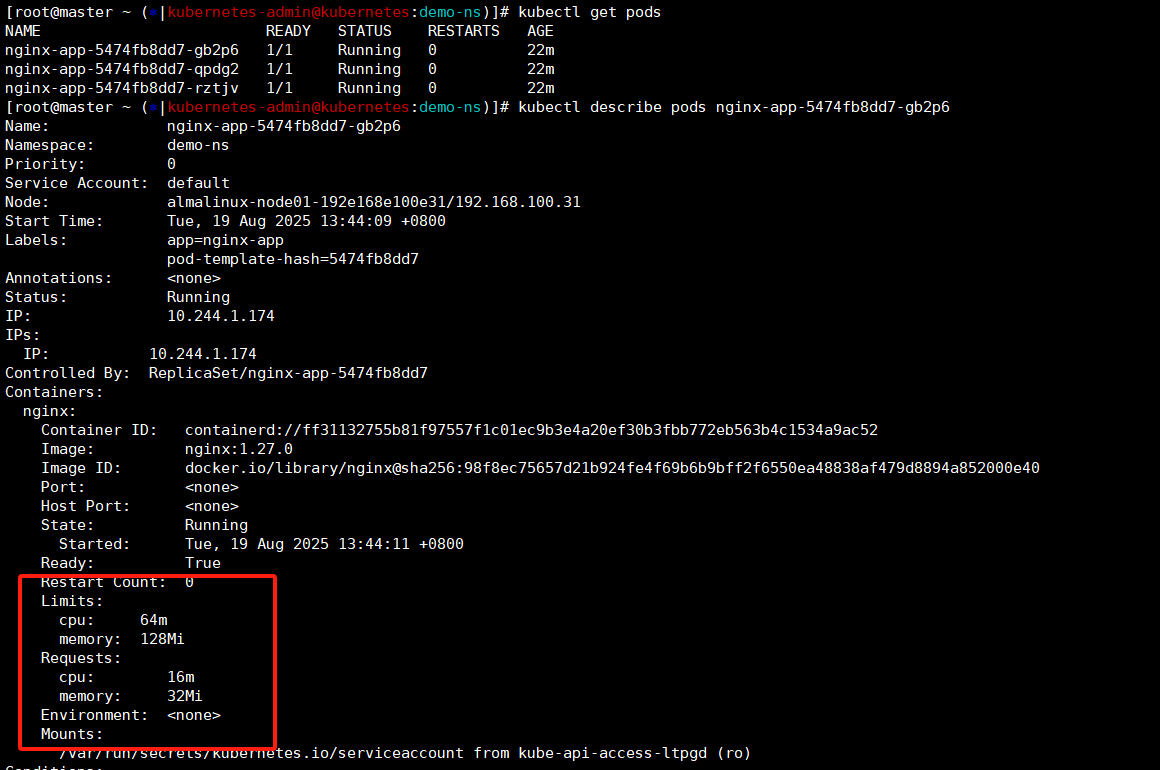
那么我有个疑问,如果我不设置deploy的资源限制他默认是多少的呢?------》默认是不限制的。
我们可以在创建deploy查看下,deploy如果不指定默认是没有资源限制的,那么创建出来的pod也是没有资源限制的,这样的话node有多少资源他就可以使用多少资源,我这种测试环境还好,最多跑了nignx没啥冲突,这要是正式环境,一个节点上跑多个不同服务,一旦运行起来资源不足开始抢占,我们就爽了。------》这就是HPA和VPA的目的了,通过给deploy设置资源限额进行自动扩缩容还可以限制资源防止资源抢占。
bash
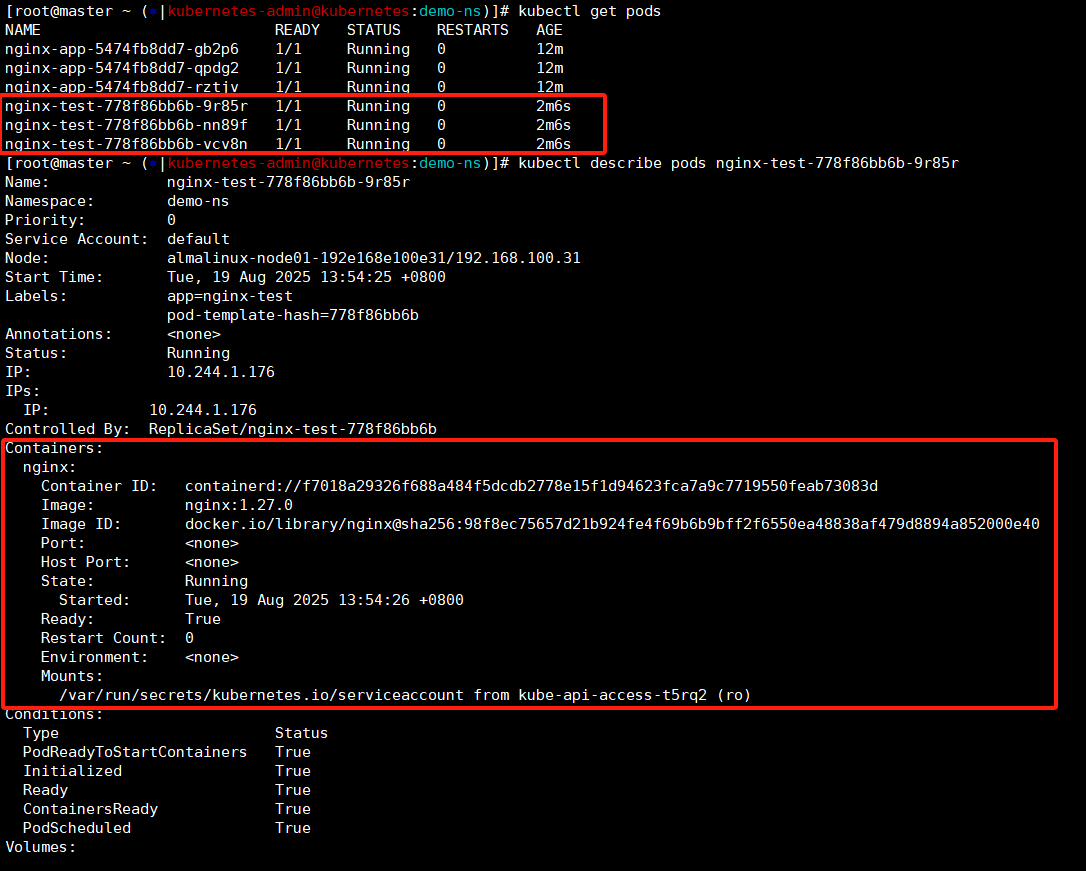
kubectl create deployment nginx-test --image nginx:1.27.0 --replicas 3 --save-config
kubectl describe deployments.apps nginx-test
kubectl describe pods nginx-test-778f86bb6b-9r85r
kubectl delete deployments.apps nginx-test 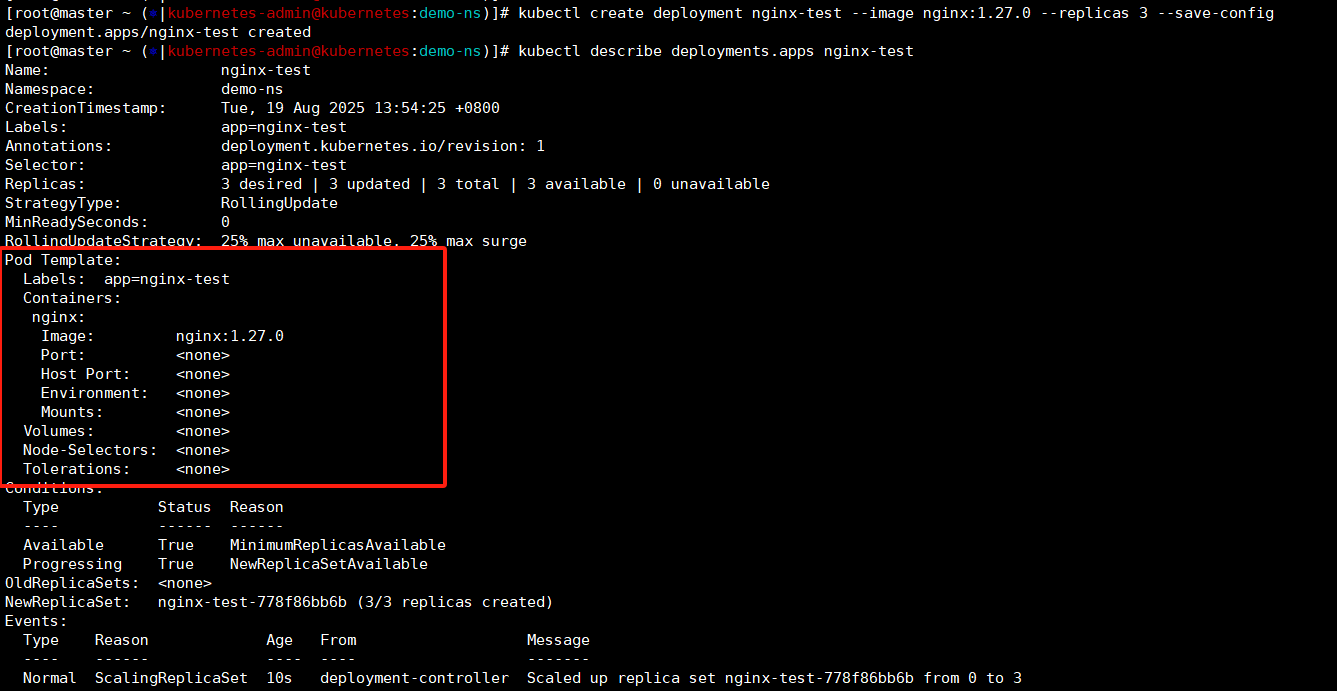
接着创建一个svc方便我们一会使用curl命令访问提高资源占用查看自动扩容hpa的现象
bash
kubectl delete deployments.apps nginx-test
kubectl expose deployment nginx-app --type NodePort --port 80
kubectl get svc
curl 192.168.100.30:31703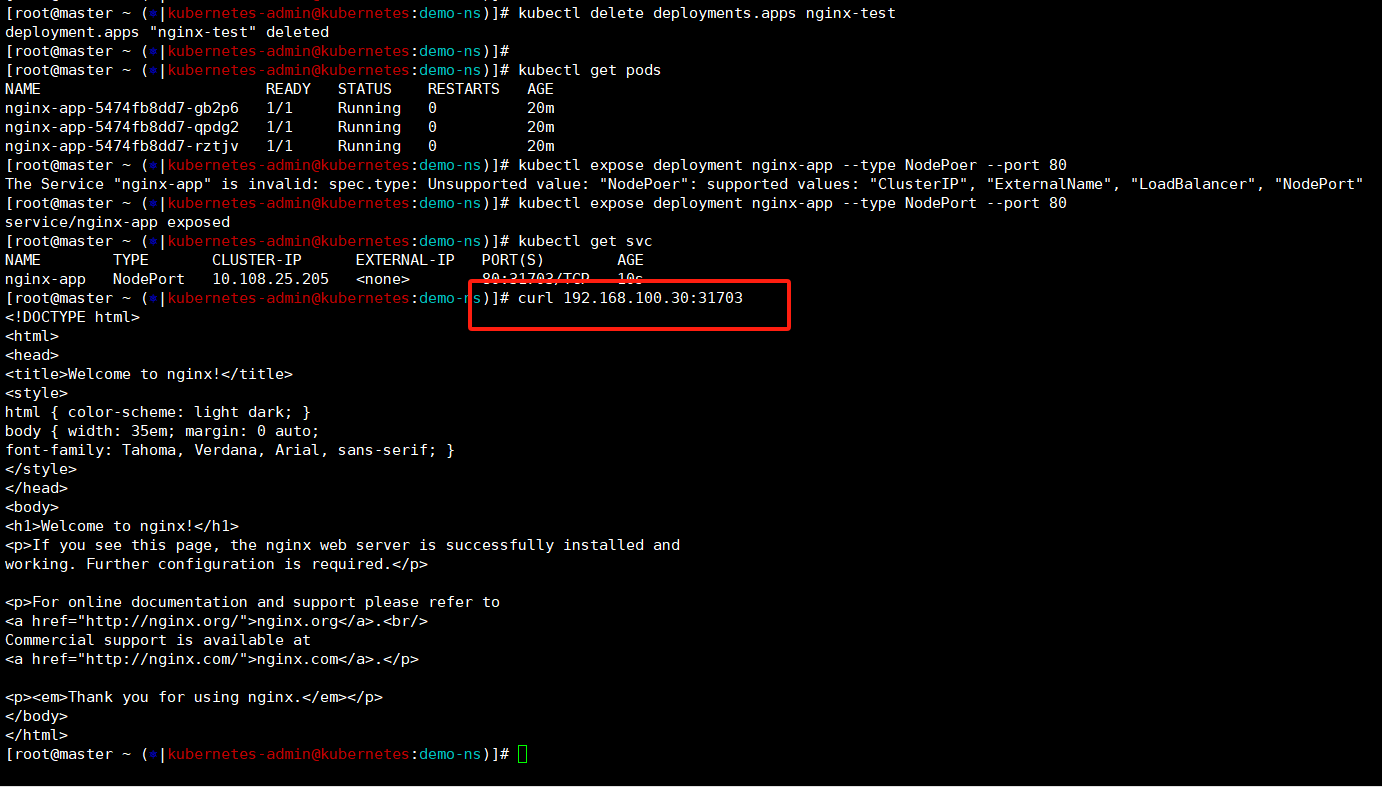
接着我们进入压缩包中查看hpa/vpa的yaml文件,
yaml
[root@master kubeadmin-kubernetes-v1.33 (?|kubernetes-admin@kubernetes:demo-ns)]# cat metrics-hpa-demo.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: demo-ns-hpa ### hpa的名称
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment ### 类型deploy------》我们是针对deploy做HPA操作,这个是对应的
name: nginx-app ### 我们要限制的deployment名称
minReplicas: 3 ### 最小pod数量,如果小于3那么会立刻触发扩缩容
maxReplicas: 15 ### 最大pod数量,如果超过15那么也会立刻触发扩缩容
metrics:
- type: Resource
resource: ### 检查cpu作为检查项
name: cpu
target:
type: Utilization
averageUtilization: 30 ### 正常CPU 使用率阈值设为 70%------》这里是为了看到现象我们将阈值降低为30%
[root@master kubeadmin-kubernetes-v1.33 (?|kubernetes-admin@kubernetes:demo-ns)]# 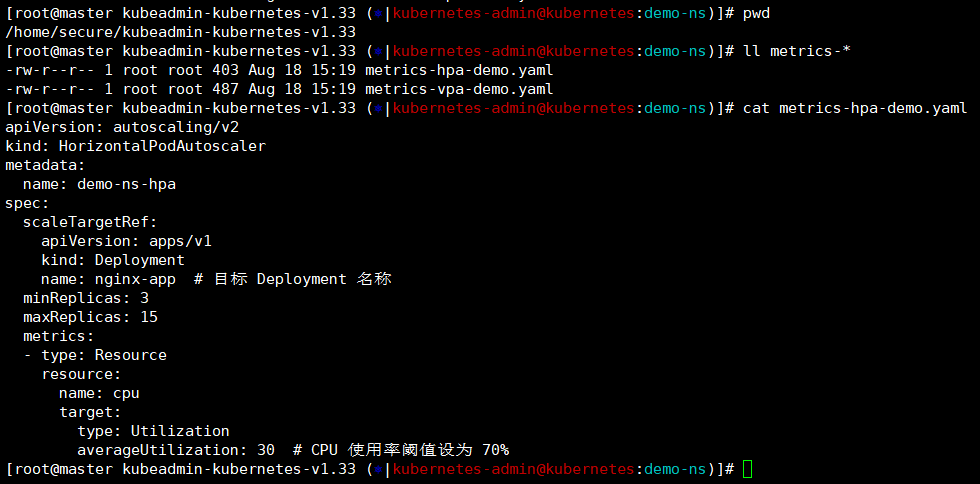
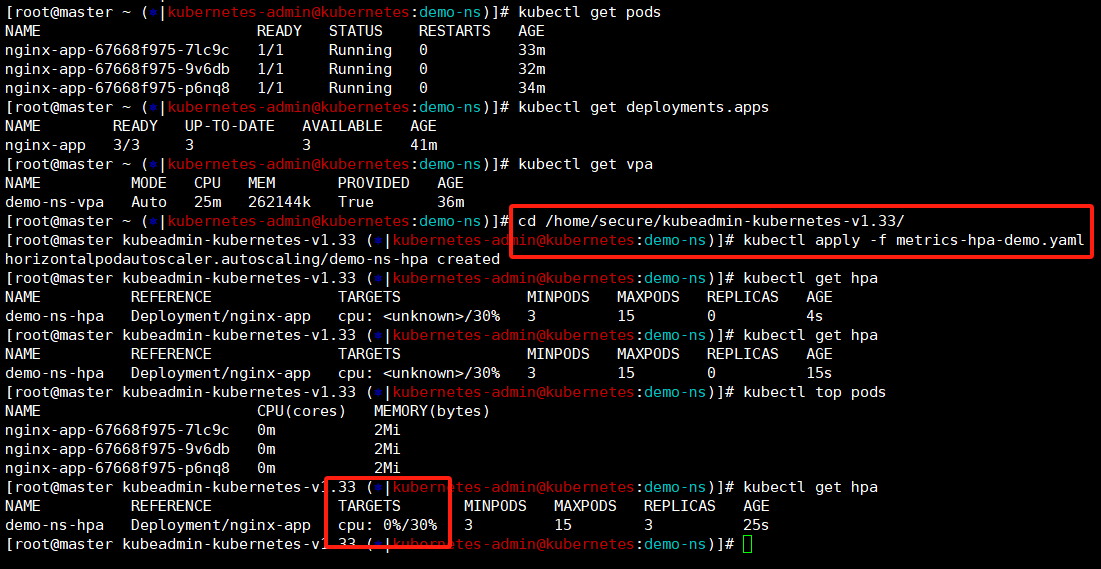
将设置nginx-app的hpa创建出来,这里我们可以看到最开始这里设置的阈值前面是unknown的,这是在等待metrics监控数据,这里就需要确保metrics服务是正常的,那么hpa就是没有问题的。
bash
kubectl apply -f metrics-hpa-demo.yaml
kubectl get hpa
kubectl top pods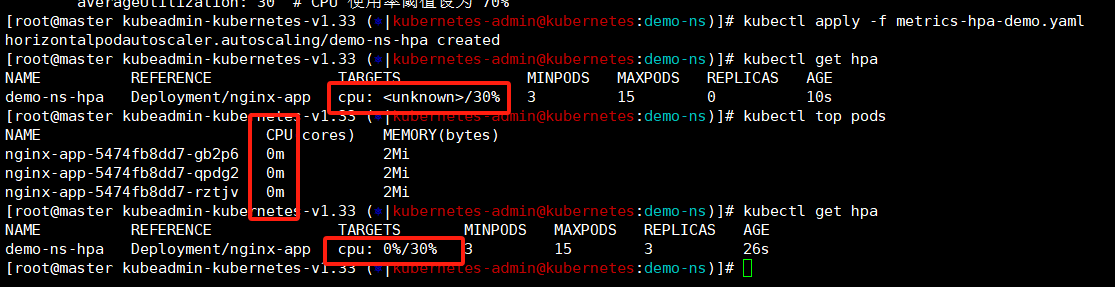
我们再开个终端,通过curl命令来增加cpu使用率,这个命令会通过busybox容器镜像启动一个pod然后一直执行curl命令。
bash
kubectl get svc ------》80:31703/TCP
kubectl run -it --rm load-generator --image=busybox:1.37.0 -- /bin/sh -c "while true; do wget -q -O- http://192.168.100.30:31703; done"
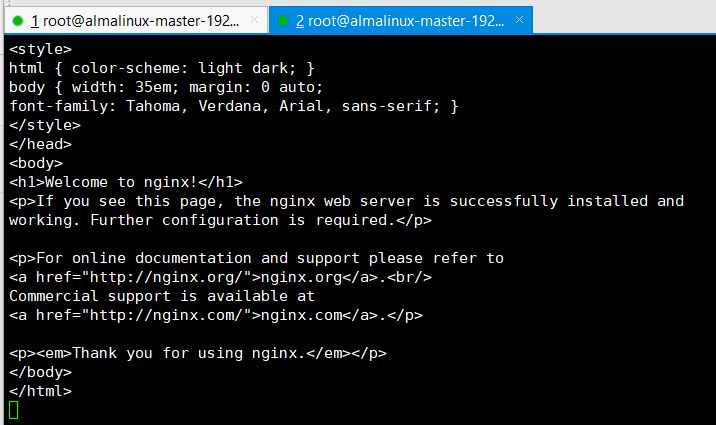
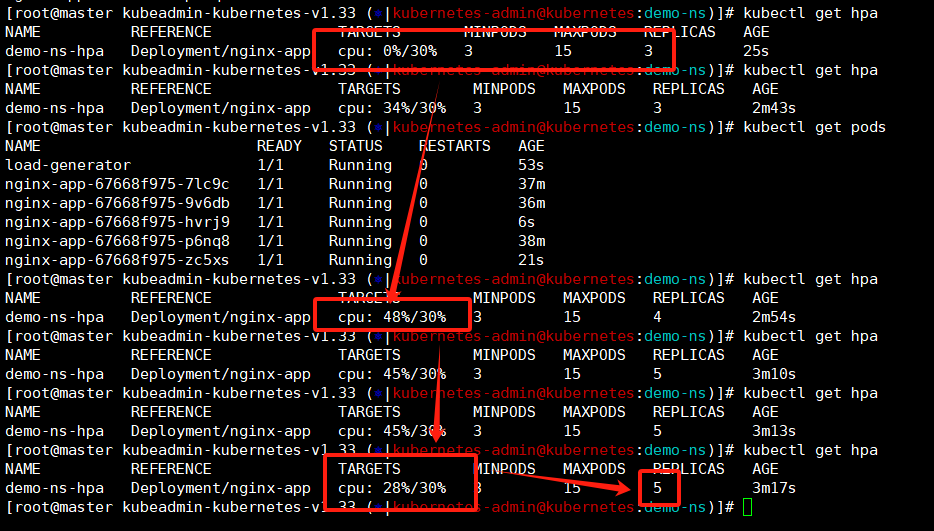
这时候我们回到第一个终端就能看到hpa的现象了,deploy创建时候是三个副本,现在是8个了,pod在我们curl的时候cpu使用率超过阈值之后HPA感知到之后立刻就进行了扩容操作。
bash
kubectl get hpa
kubectl get pods这里有个疑问,我上面说了,这个设置必须超过阈值的百分之十,也就是我设置cpu使用超过是30那么要触发hpa必须cpu使用率达到百分之33才可以进行触发,为啥我这截图中阈值是百分之29他就已经出发了?
------》首先,我们使用busybox批量curl的时候他是有个峰值的,过了峰值之后出发了缓存他的cpu使用率会下降一下;
------》还有就是我们的metrics收集监控数据是周期性的,默认15-30秒,可能是我们错过了峰值的那个数据。
这里可以后续我们部署完promethues有了系统监控之后再来一次,那时候通过监控页面可以更明显的看到cpu峰值。
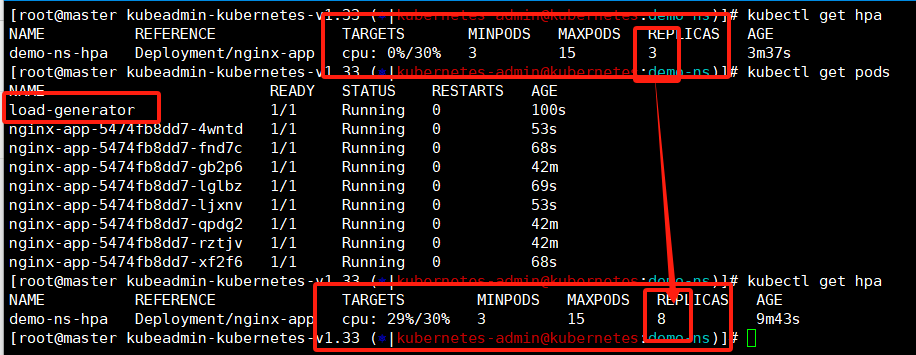
这里我们将busybox的pod使用ctrl+c停止之后还可以看到个现象,刚才是批量的curl认为增加cpu使用量看到了扩容现象,现在我们停下了curl,cpu使用率就降下来那么缩容呢?------》这就需要等待一会了。
扩容是感知到超过阈值立刻生效但是缩容需要监控数据平稳之后等待300s也就是五分钟才会触发,这里其实查看下他pod已经变少了,我这是边做实验边编写文档,可能是码字速度比较慢,已经触发了缩容。
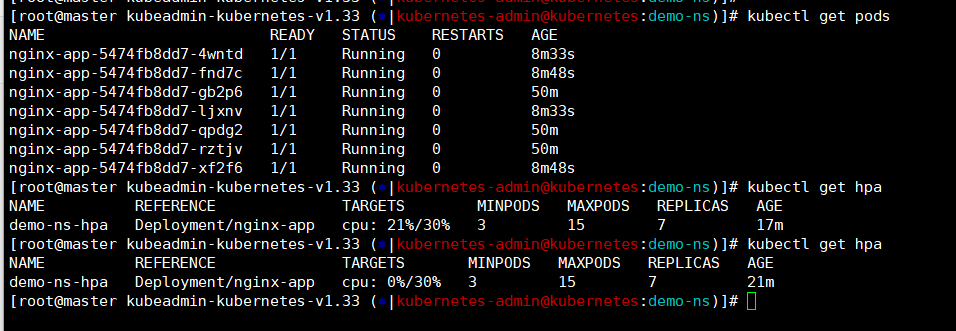
我们等待个三五分钟再查看pod数量就降下来,因为我们的设置他最小数量是三个pod。还可以查看下hpa的详细描述这里可以看到些event事件记录,这就是缩容的操作了!
bash
kubectl get hpa
kubectl get pods
kubectl describe hpa demo-ns-hpa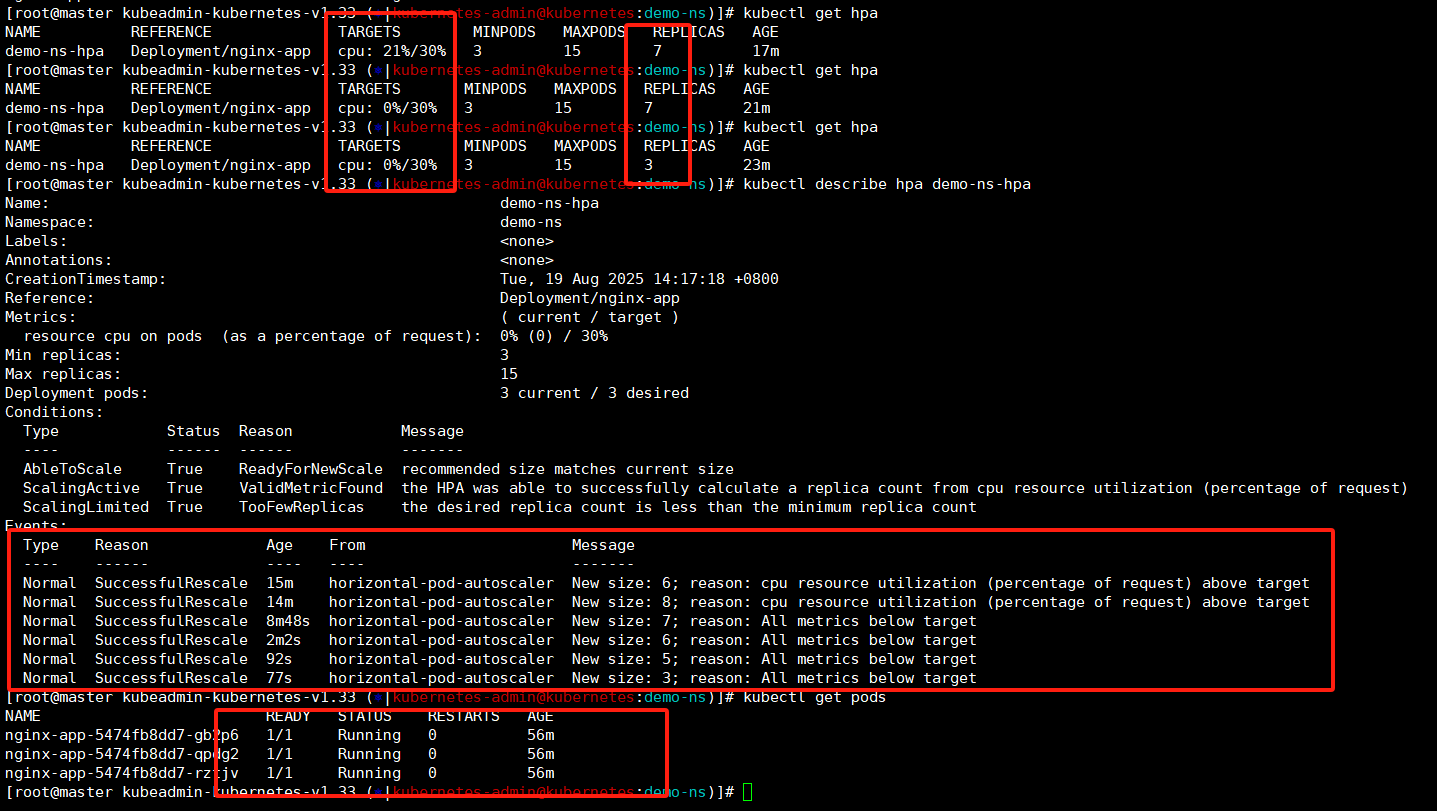
这里我们删除下hpa看下他的资源限制是否进行清除------》不会,hpa规则删除了查看deployment中资源限制还是在的。
bash
kubectl get hpa
kubectl delete -f metrics-hpa-demo.yaml
kubectl get pods
kubectl describe deployments.apps nginx-app 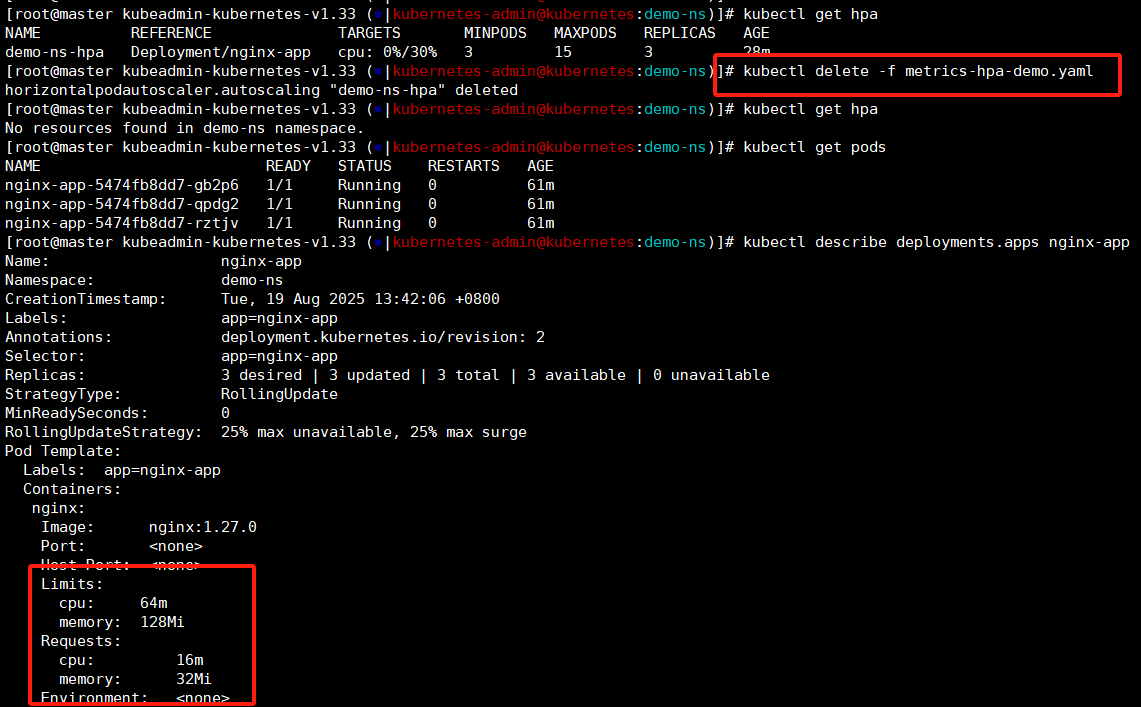
VPA
HPA和VPA都是自动扩缩容,HPA是设置阈值通过增加pod数量来维护资源使用率,而vpa就是通过metrics收集监控数据长期判断之后直接修改pod的资源限制来进行扩缩容。这两个东西一个解决短期负载一个优化长期使用,我们只需要指定检查值然后设置阈值之后他自己设置就好了。
bash
kubectl delete deployments.apps nginx-app
kubectl create deployment nginx-app --image nginx:1.27.0 --replicas 3 --save-config上面我们已经将hpa的扩缩容都查看了,接着做vpa实验他是通过metrics收集监控数据之后调整deploy的配置来进行扩缩容的。
这里我们需要将nginx-app的deployment删除重建下,保证创建pod的没有指定最大最小配置。
这里我们查看下要设置的vpa配置,和hpa比较类似,都是对deploy进行设置,这里指定了cpu和内存的最大最小资源配置。
yaml
pwd ------》/home/secure/kubeadmin-kubernetes-v1.33
[root@master kubeadmin-kubernetes-v1.33 (?|kubernetes-admin@kubernetes:demo-ns)]# cat metrics-vpa-demo.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: demo-ns-vpa ### vpa的名称
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment ### 限制的类型海慧寺deploy
name: nginx-app ### 创建的测试deploy,这里是对应的哈
updatePolicy:
updateMode: "Auto" ### 模式:Auto(自动更新)/Recreate(重启更新)
resourcePolicy:
containerPolicies:
- containerName: "*"
minAllowed: ### 资源最小设置
cpu: 8m
memory: 16Mi
maxAllowed: ### 资源对答限制
cpu: 125m
memory: 256Mi
[root@master kubeadmin-kubernetes-v1.33 (?|kubernetes-admin@kubernetes:demo-ns)]# 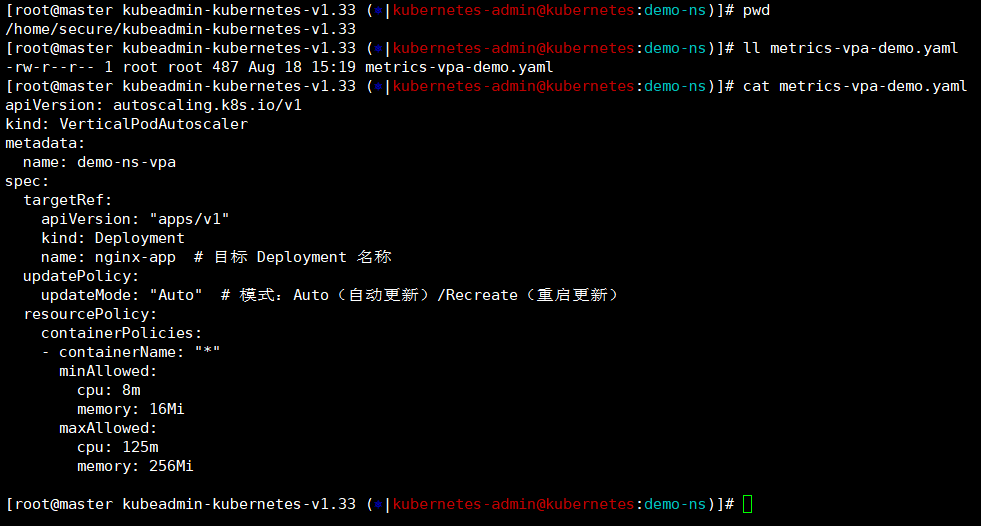
我们给nignx-app添加下vpa配置,
bash
kubectl apply -f metrics-vpa-demo.yaml
kubectl get vpa
kubectl describe vpa demo-ns-vpa查看vpa状态是正常的,mode状态也是Auto的,然后cpu和mem现在没有数据,需要等待一会。
这里我们查看vpa的详细信息,这里还没出现target推荐值,还需要稍等下。
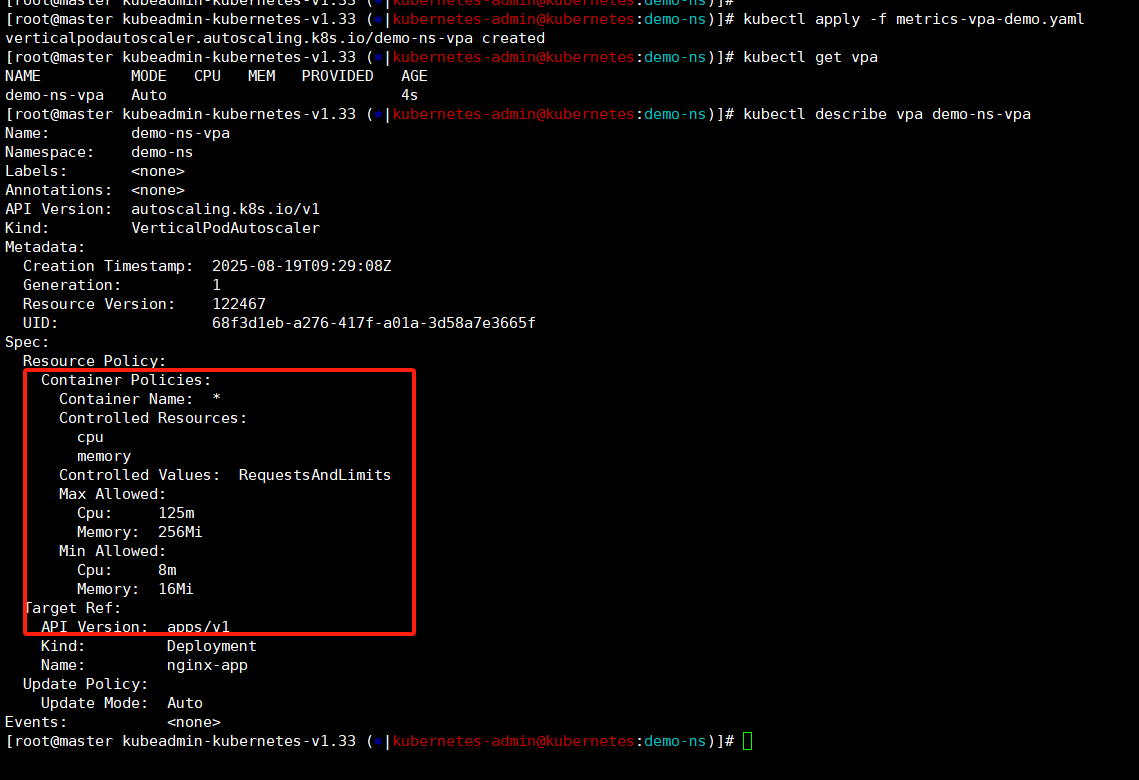
稍等一会再看,vpa已经算出来推荐值了,这里我们可以看到已经开始重启pod了。
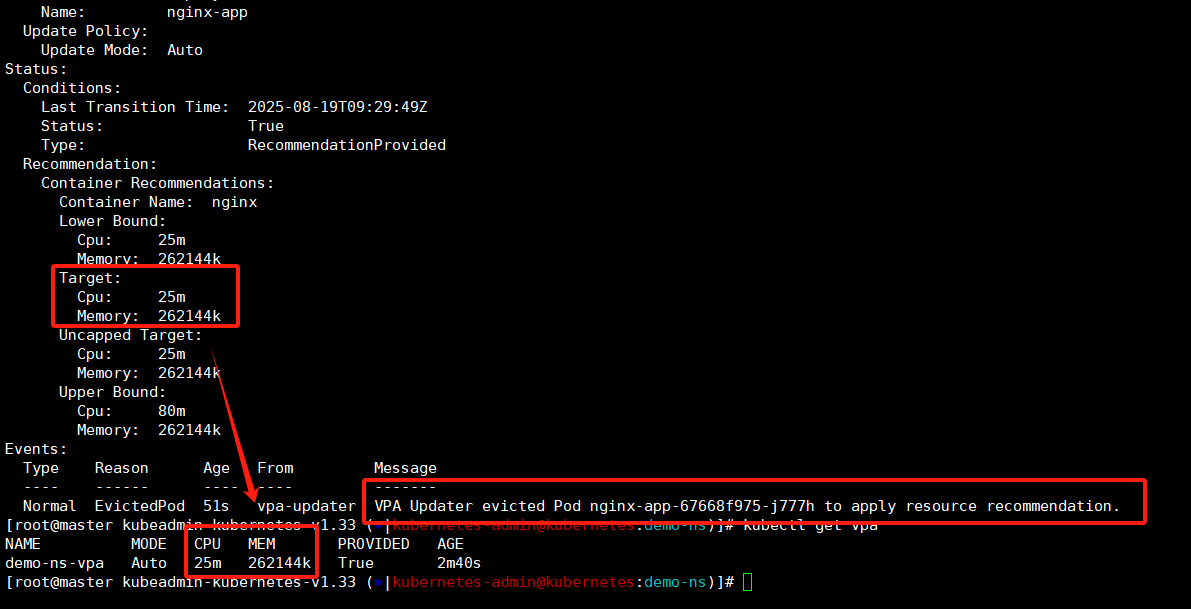
现在查看三个pod都是已经重启了,通过pod启动时间也能看到,具体查看pod资源设置是有了。
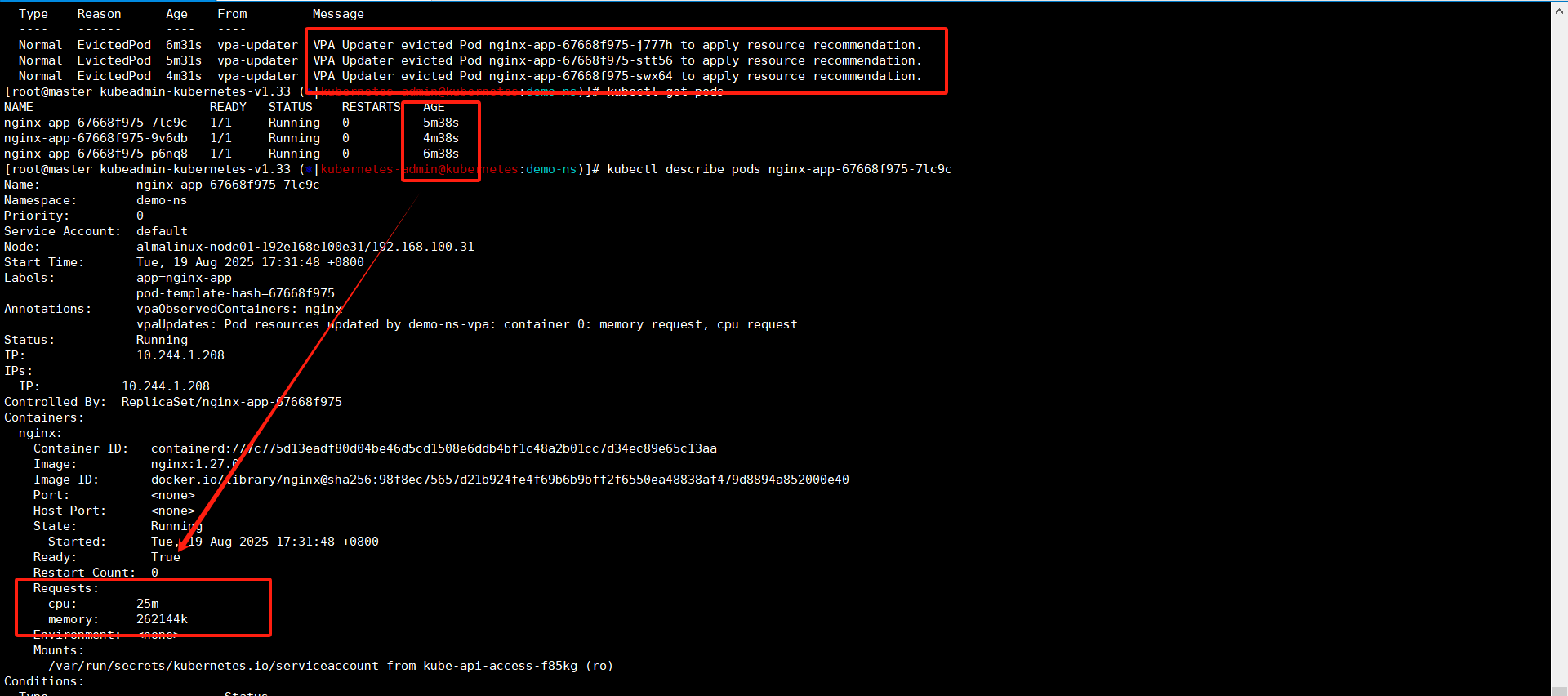
这里有一点挺诡异的,为毛只有request最小资源配置,没有limits最大的资源限制?------》默认VPA只会将pod的requests进行设置,limits在VPA-CRD1.41.版本是支持的但是它需要依赖正确的 updateMode(如 Recreate)和足够的 metrics 数据。
这个足够的metrics数据,至少需要24小时。注意,这里是至少不是说过了24小时metrics数据量就是够的,闹不好VPA收集个几天一周数据然后给出可靠的limits推荐数值也是有可能的,这里就不等了,能看到pod设置了request就行。
HPA和VPA结合使用
上面我们将vpa的实验做完了,在创建deployment的时候没有设置资源限额,通过vpa我们添加上了(只有requests最小值,没有limits最大值)。HPA限制前提是需要给deployemt设置资源限额,他需要作为阈值判断基础(阈值是百分比的不是具体配置)。
这种情况我们完全可以创建deployment正常创建------》然后添加VPA给pod增加资源限额------》然后部署HPA进行自动扩缩容配置------》完美!
再来一把压测,看下hpa的现象
这次就抓住了,峰值直接上百分之四十八,舒服!
以上就是kubernetes1.33版本基于metrics的自动扩缩容实验了,本来一篇文章将可选组件都写完得了,结果这个一篇边做越写越多,还是分开吧。