安装配置
-
将压缩包 flink-1.19.3-bin-scala_2.12.gz上传到服务器
-
解压安装
tar -zxvf flink-1.19.3-bin-scala_2.12.tgz -C /opt/module/ -
配置环境变量
bashsudo vim /etc/profile.d/myprofile.sh #设置 flink 环境变量 export FLINK_HOME=/opt/module/flink-1.19.3 export PATH=$FLINK_HOME/bin:$PATH # 配置生效 source /etc/profile -
配置flink-conf
sqlvim $FLINK_HOME/conf/config.yaml # 设置taskmanager有4个作业Slot taskmanager.numberOfTaskSlots: 4 # checkpoint设置(15秒) execution.checkpointing.interval: 15000 # 设置状态目录 state.checkpoints.dir: hdfs://mydoris:9000/flink/checkpoints state.savepoints.dir: hdfs://mydoris:9000/flink/savepoints # flink web ui 可在外部访问 rest.address: mydoris rest.bind-address: 0.0.0.0-
放置JAR包
bash# 将以下JAR包放入 $FLINK_HOME/lib/ # mysql驱动 cp ~/mysql-connector-java-8.0.17.jar $FLINK_HOME/lib # iceberg 1.6.1 相关 cp ~/iceberg-flink-1.19-1.6.1.jar $FLINK_HOME/lib cp ~/iceberg-hive-runtime-1.6.1.jar $FLINK_HOME/lib # 不能用flink-sql-connector-hive-3.1.3_2.12-1.19.3.jar,会导致集群起不来 cp ~/flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar $FLINK_HOME/lib cp ~/flink-sql-connector-mysql-cdc-3.5.0.jar $FLINK_HOME/lib cp ~/flink-sql-connector-kafka-3.3.0-1.19.jarr $FLINK_HOME/lib # Hadoop 3.3.0 客户端 cp $HADOOP_HOME/share/hadoop/client/hadoop-client-api-3.3.6.jar $FLINK_HOME/lib cp $HADOOP_HOME/share/hadoop/client/hadoop-client-runtime-3.3.6.jar $FLINK_HOME/lib # hive 3.1.3 客户端(使用 hive catalog) cp $HIVE_HOME/lib/hive-exec-3.1.3.jar $FLINK_HOME/lib cp $HIVE_HOME/lib/hive-metastore-3.1.3.jar $FLINK_HOME/lib # 日志(Hive依赖) cp $HIVE_HOME/lib/commons-logging-1.0.4.jar $FLINK_HOME/lib # 缓存库 cp ~/caffeine-3.1.8.jar $FLINK_HOME/lib|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------|
| Flink自带jar | 需要添加的Jar | |
| flink-cep-1.19.3.jar flink-connector-files-1.19.3.jar flink-csv-1.19.3.jar flink-dist-1.19.3.jar flink-json-1.19.3.jar flink-scala_2.12-1.19.3.jar flink-table-api-java-uber-1.19.3.jar flink-table-planner-loader-1.19.3.jar flink-table-runtime-1.19.3.jar log4j-1.2-api-2.17.1.jar log4j-api-2.17.1.jar log4j-core-2.17.1.jar log4j-slf4j-impl-2.17.1.ja | caffeine-3.1.8.jar commons-logging-1.0.4.jar hive-exec-3.1.3.jar hive-metastore-3.1.3.jar iceberg-flink-1.19-1.6.1.jar iceberg-hive-runtime-1.6.1.jar iceberg-flink-runtime-1.19-1.6.1.jar | |
| | flink-sql-connector-mysql-cdc-3.5.0.jar mysql-connector-java-8.0.17.jar | # Mysql # 标准 JDBC 驱动:连接 MySQL、查询表结构(schema)、执行快照读 # Flink Mysql CDC Source 实现:读 binlog、解析 DDL/DML、生成 changelog 流 |
| | hadoop-client-api-3.3.6.jar hadoop-client-runtime-3.3.6.jar | # Hadoop 轻量级客户端:用于将状态数据(checkpoint/savepoint)写入hadoop |
| | flink-sql-connector-kafka-3.3.0-1.19.jar | # Kafka # 读/写kafka数据 |
| | flink-doris-connector-1.19-25.1.0.jar | # Doris # 只支持 Sink(写入),不支持 Source(读取) |
| | flink-connector-jdbc-1.19.3.jar | # 读写jdbc数据源,读写能力参考数据库 |
| | flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar | # 访问 Hive Metastore,并读写 Hive 表 |
-
-
启动集群:$FLINK_HOME/bin/start-cluster.sh
-
访问Flink Web UI
http://mydoris:8081
启停脚本
bash
#!/bin/bash
# 检查是否传入参数
if [ $# -lt 1 ]; then
echo "No Args Input..."
echo "Usage: $0 {start|stop}"
exit 1
fi
# 定义环境变量
JAVA_HOME="/opt/module/jdk-17.0.10"
FLINK_HOME=${FLINK_HOME:-"/opt/module/flink-1.19.3"} # 如果未设置 FLINK_HOME,则使用默认路径
# 获取命令参数
case $1 in
"start")
echo "============== 启动 Flink 集群 ==================="
# 检查 FLINK_HOME 是否有效
if [ ! -d "$FLINK_HOME" ]; then
echo "Error: FLINK_HOME ($FLINK_HOME) 路径不存在,请检查配置。"
exit 1
fi
# 启动 Flink 集群
ssh mydoris "export JAVA_HOME=$JAVA_HOME && ${FLINK_HOME}/bin/start-cluster.sh"
;;
"stop")
echo "============== 关闭 Flink 集群 ==================="
# 检查 FLINK_HOME 是否有效
if [ ! -d "$FLINK_HOME" ]; then
echo "Error: FLINK_HOME ($FLINK_HOME) 路径不存在,请检查配置。"
exit 1
fi
# 停止 Flink 集群
ssh mydoris "export JAVA_HOME=$JAVA_HOME && ${FLINK_HOME}/bin/stop-cluster.sh"
;;
*)
echo "Input Args Error... Usage: $0 {start|stop}"
exit 1
;;
esac场景练习
Iceberg 建表
- 创建 SQL 初始化文件
bash
cat > $FLINK_HOME/conf/init-iceberg.sql <<'EOF'
-- 创建 Iceberg catalog
CREATE CATALOG iceberg_hms WITH (
'type' = 'iceberg',
'catalog-type' = 'hive',
'uri' = 'thrift://mydoris:9083',
'warehouse' = 'hdfs://mydoris:9000/user/hive/warehouse',
'clients' = '5'
);
EOF-
打开客户端
bash$FLINK_HOME/bin/sql-client.sh -i $FLINK_HOME/conf/init-iceberg.sql bash
bash# 客户端启动有问题,可临时使用日志 # 临时开启 SQL Client 的 DEBUG 日志 # 备份原日志配置 cp $FLINK_HOME/conf/log4j-cli.properties $FLINK_HOME/conf/log4j-cli.properties.bak # 添加 DEBUG 配置 cat >> $FLINK_HOME/conf/log4j-cli.properties <<EOF logger.iceberg.name = org.apache.iceberg logger.iceberg.level = DEBUG logger.client.name = org.apache.flink.table.client logger.client.level = DEBUG EOF # 启动 SQL Client 并查看日志 cat /opt/module/flink-1.18.1/log/flink-ph-sql-client-mydoris.log -
操作数据表
sql-- 如果不是 iceberg_hms,则需切换或加前缀 SHOW CATALOGS; SHOW CURRENT CATALOG; USE CATALOG iceberg_hms; -- SHOW DATABASES; -- 创建数据库(如果 default_db 不存在) CREATE DATABASE IF NOT EXISTS default_db; -- 切换到该库 USE default_db; -- 在 Iceberg 中建表 CREATE TABLE default_db.user_events ( id BIGINT, event_time TIMESTAMP(3), user_id STRING, event_type STRING ) PARTITIONED BY (event_time) WITH ( 'write.format.default' = 'parquet', 'write.target-file-size-bytes' = '536870912', -- 512MB 'format-version' = '2' ); -- 看有哪些表 SHOW TABLES; -- 描述表 DESCRIBE user_events; -- 插入数据 INSERT INTO user_events VALUES (1, NOW(), 'user2', 'click'); -- 查询数据 SELECT * FROM user_events; -
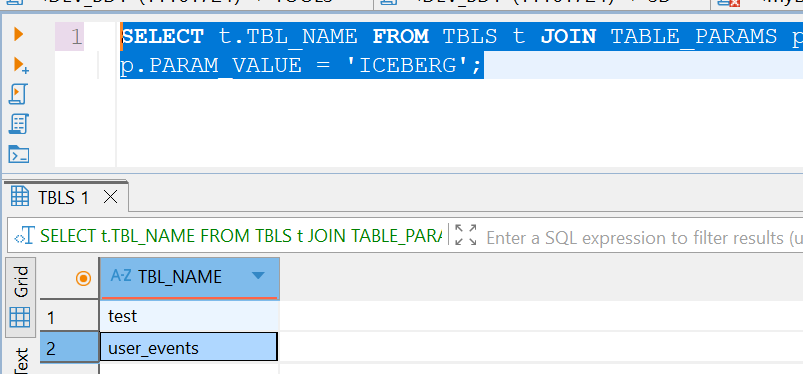
在mysql通过查询元数据看iceberg中有哪些表
sqlSELECT t.TBL_NAME FROM TBLS t JOIN TABLE_PARAMS p ON t.TBL_ID = p.TBL_ID WHERE p.PARAM_KEY = 'table_type' AND p.PARAM_VALUE = 'ICEBERG';