一.hadoop概述:
1.Hadoop的框架最核心的设计包括:HDFS和MapReduce
HDFS:分布式文件系统,为海量的数据提供了存储
MapReduce:为海量的数据提供了计算能力,分而治之,map将大任务分成小任务,reduce将小任务结果重新合并成总的结果
处理任务的奇妙比喻:
我们可以用一个生动的比喻来理解:
想象一下,让你数一个体育馆里所有观众的总人数。
传统方式(单机处理):
你一个人从第一排开始,一个一个数到最后排。速度慢,且你一个人承担所有工作。
Hadoop方式(分布式处理):
Map阶段(分而治之):你雇佣了很多助手,让每个助手负责数一个区域(相当于一个数据块)。所有助手同时开始数,速度极快。每个助手交上来一张纸条,写着:"我负责的区域有X人"。
Shuffle阶段(归类):你把这些纸条收上来。
Reduce阶段(合并):你(或者另一个专门负责汇总的人)把这些纸条上的数字全部加起来,得到总人数。
结论:
1.它先把一个巨大的计算任务"拆分"成大量可以在数据本地并行执行的"小任务"(Map),这是为了极致的并行效率。
2.然后,它再通过一个高度结构化和自动化的过程(Shuffle & Reduce),将这些小任务产生的中间结果"合并"成最终的全局答案。
2.Hadoop是一种典型的 Master-Slave 架构:
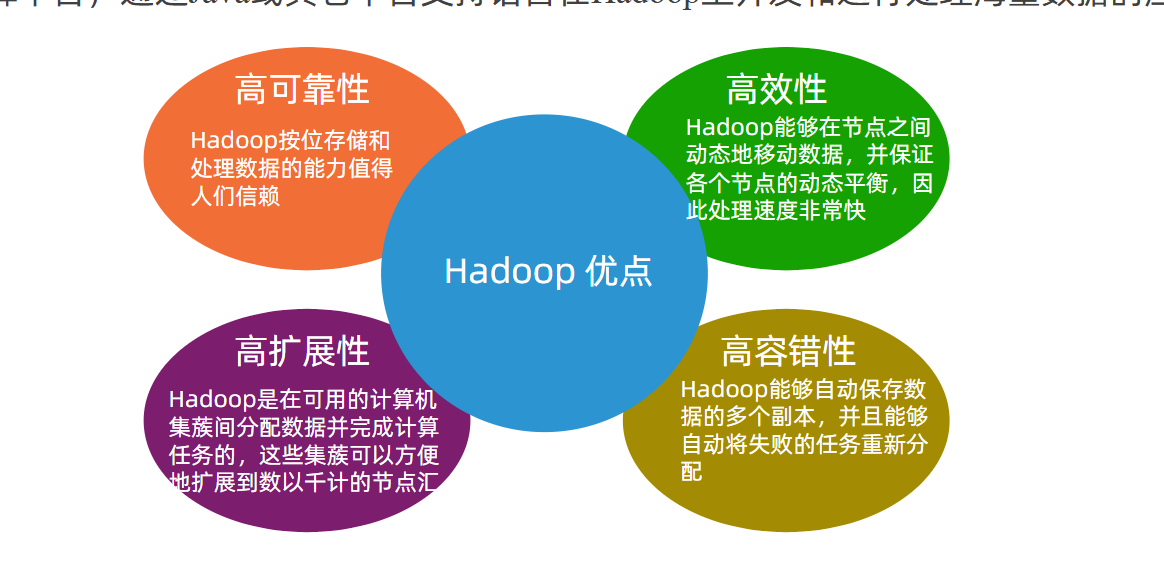
3.hadoop的特色与优势:
二.HDFS:分布式文件系统
1.集群解析:
下图展示了其数据存储与元数据管理的架构逻辑:
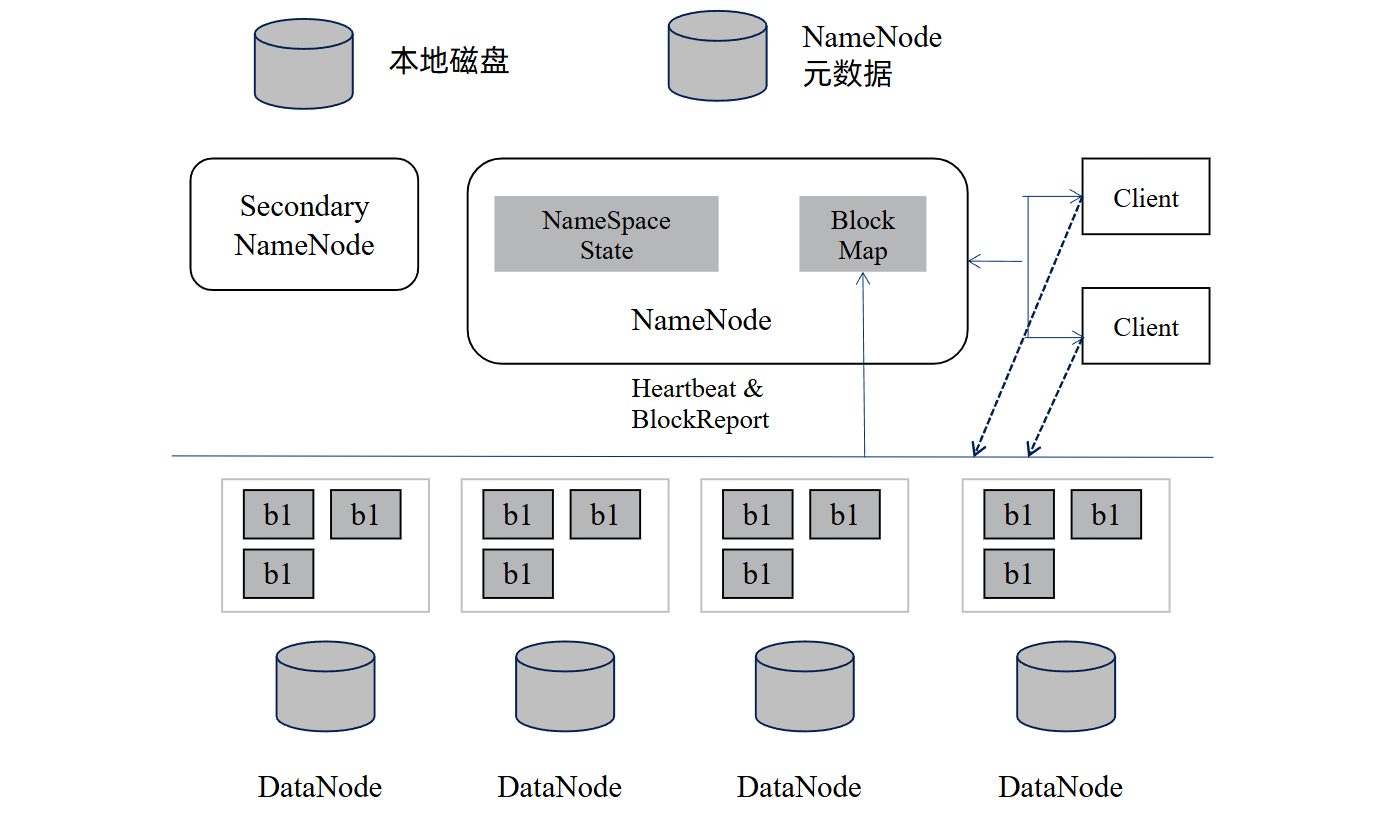
核心组件:
1、 NameNode(Master 节点):NameNode被称为名称节点或元数据节点,是整个集群的管理者。HDFS 的 "大脑",一个集群通常只有一个活动的NameNode节点,通常NameNode独立运行在集群的某个节点上,主要职责是HDFS文件系统的管理工作,具体包括命名空间管理
(NameSpace)和文件Block管理。NameNode决定是否将文件映射到DataNode的副本上。
(1)NameNode的主要功能:
NameNode提供名称查询服务,它是一个Jetty服务器
NameNode保存metadate信息。具体包括:owership和permissions;文件包括哪些块;Block块保存在哪个DataNode(DataNode通过"心跳"机制上报)
NameNode的metadate信息在启动后会加载到内存
(2)NameNode容错机制:
使用SecondaryNameNode恢复NameNode
利用NameNode的HA机制
2.Secondary NameNode:辅助 NameNode 进行元数据持久化(并非热备节点),定期合并NameNode 的元数据日志,缓解 NameNode 压力。
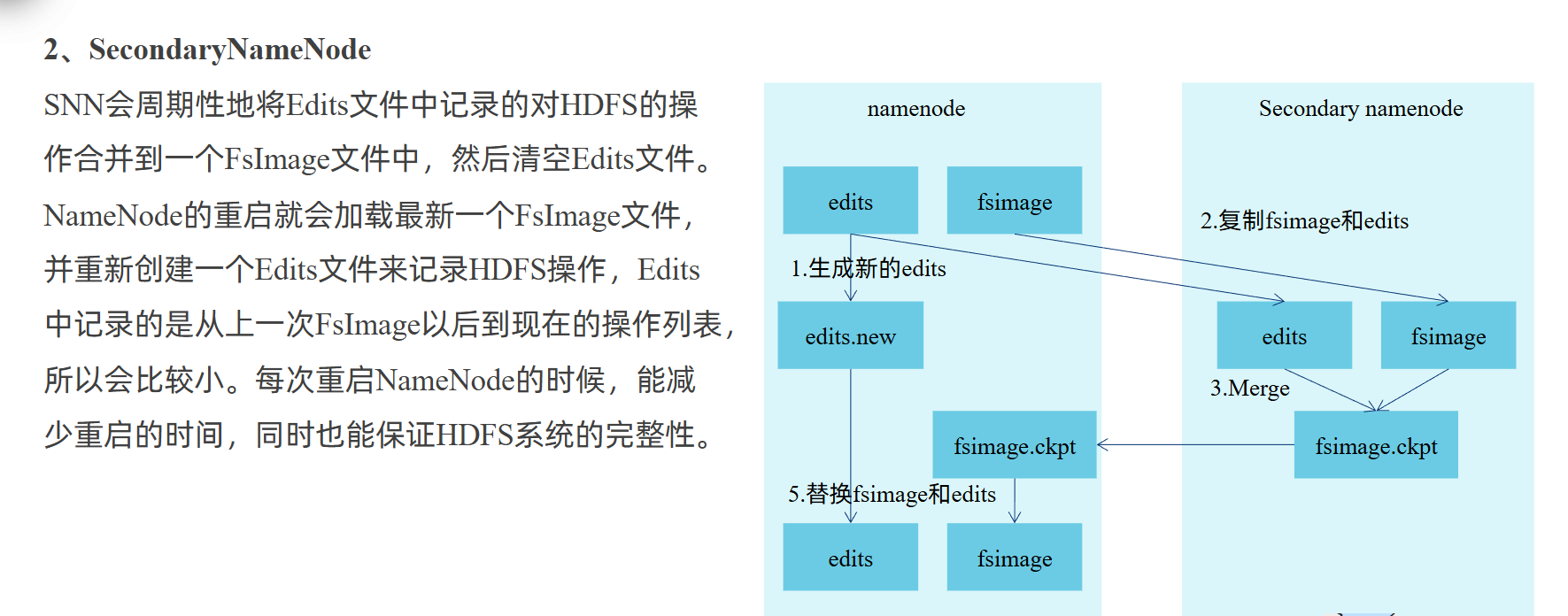
NameSpace State:文件系统的命名空间(如文件路径、目录结构);
Block Map:数据块(Block)与 DataNode 的映射关系(即数据块存放在哪些 Slave 节点上)。
DataNode(Slave 节点):实际存储数据的 "载体",每个 DataNode 存储若干数据块(如图中的 b1),并定期向 NameNode 发送 "心跳(Heartbeat)" 和 "数据块报告(BlockReport)",汇报自身状态与存储的块信息。
交互流程:
1.客户端与 NameNode 交互,获取文件的元数据(如数据块位置);
2.DataNode 持续向 NameNode 发送心跳和块报告,确保 NameNode 掌握集群存储状态;
3.客户端根据 NameNode 提供的块位置,直接与 DataNode 交互读写数据,实现 "数据本地化",提升访问效率。
2.HDFS的数据块:
默认为128MB,与一般文件系统相似,HDFS上的文件也被划分为块大小的多个分块,作为独立的存储单元,它是HDFS文件系统存储处理数据的最小单元。
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间,因此,传输一个由多个块组成的文件的时间取决于磁盘传输的速率。
举例:要传输100MB的数据,假设寻址时间为10ms,而传输的速率为100MB/s:如果我们将块大小设置为100MB,这时寻址的时间仅占传输时间的1%;
如果将块的大小设置为10MB,这时寻址的时间会占传输时间的10%。(找到一个块0.01s,传输进去0.1s,总共10个块,共1.1s,传输1s,寻址0.1s,占10%)
3.数据复制(机架感知)
HDFS 默认的副本复制因子设置为 3,即一个数据还有两个复制体,共三个
目的是当硬件遭到破坏的时候,还有副本提供使用,或当多个进程用一个数据是,可以调用副本同时进行,避免单点瓶颈。
-
第一个副本:在客户端所在的节点(如果客户端不在集群内,则随机选一台)。
-
第二个副本 :放在不同机架的另一个节点上。
-
第三个副本 :放在与第二个副本相同机架的另一台节点上。
4.读写流程
1 RPC模型:RPC(Remote Procedure Call Protocol)------远程过程调用协议
(1)通俗解释RPC模型:
假设你在公司(本地电脑)想让上海总部(远程服务器)帮你查一份客户资料 ------
- 没有 RPC 时:你得自己搞清楚 "怎么联系上海总部"(比如找总部的 IP 地址)、"用什么方式传消息"(比如发邮件还是打电话)、"对方怎么看懂你的需求"(比如把 "查资料" 写成标准格式),整个过程又麻烦又容易出错。
- 有了 RPC 后:你只需要像 "在本地找同事要资料" 一样,直接说 "帮我查 XX 客户的资料"(调用一个方法),剩下的 "怎么联系总部、怎么传数据、怎么让对方理解",RPC 会帮你全自动搞定,你完全不用管底层的网络细节。
简单说,RPC 的本质就是 "假装调用本地方法,实际调用远程服务器的方法",把复杂的网络通信 "包装" 成简单的本地调用,让程序员不用再手写网络代码。
(2)一个完整的RPC架构里面包含了四个核心的组件:
客户端(Client),服务的调用方。
客户端存根(Client Stub),存放服务端的地址消息,再将客户端的请求参数打包成网络消息,
然后通过网络远程发送给服务方。
服务端(Server),真正的服务提供者。
服务端存根(Server Stub),接收客户端发送过来的消息,将消息解包,并调用本地的方法。
(3)为什么Hadoop引入RPC :
Hadoop的核心组件(比如存储数据的 HDFS、计算数据的 MapReduce/YARN)不是装在一台机器上,而是分散在成百上千台服务器组成的集群里。这些分散的组件要协同工作,就必须频繁 "互相调用、传递信息",而 RPC 正是解决这种 "跨机器通信" 的关键工具。
- 没有 RPC,分散的 HDFS、YARN、MapReduce 组件无法协同工作;
- 没有 RPC,开发人员会被网络细节拖累,无法实现大规模集群的逻辑;
- 没有 RPC,Hadoop 无法在 "大规模调用" 场景下保证效率和可靠性。
(4)Hadoop RPC分为四个部分:
序列化层:
Client与Server端通信传递的信息采用Hadoop提供的序列化类或自定义的Writable类型;
函数调用层:
Hadoop RPC通过动态代理以及Java反射实现函数调用;
网络传输层:
Hadoop RPC采用了基于TCP/IP的Socket机制;
服务器端框架层:
RPC Server利用Java NIO以及事件驱动的I/O模型,提高RPC Server并发处理能力。
2.HDFS文件写入流程
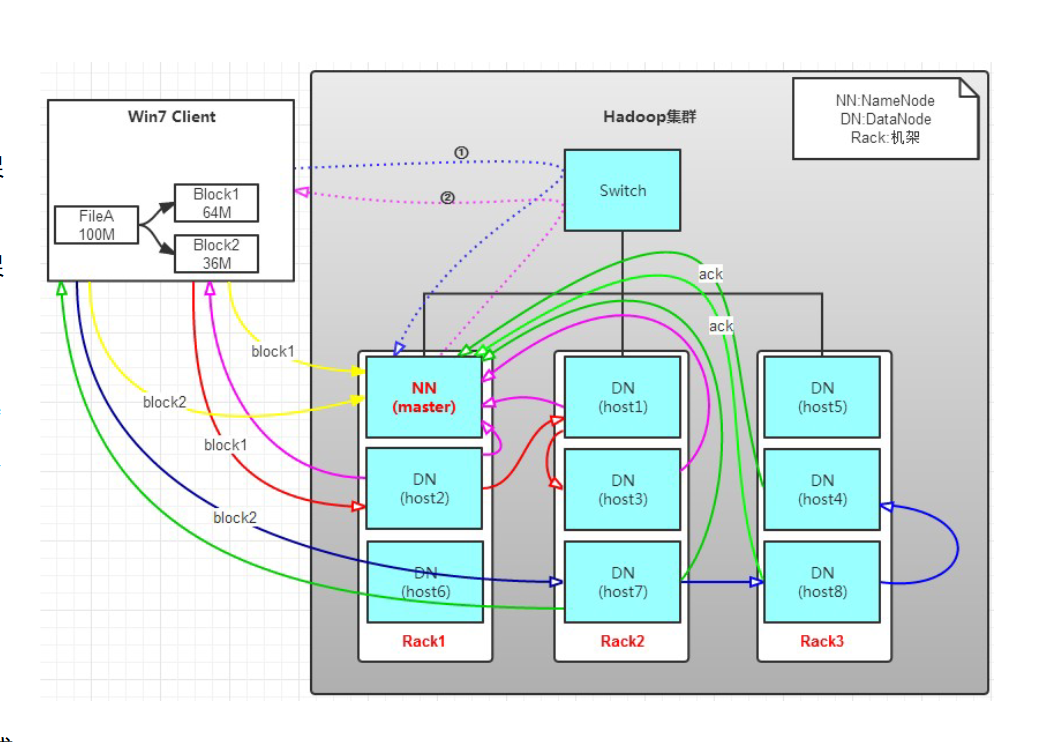
首先将64M的block1数据块按64k的package为单位划分,
(1)第一个package的传输:
时间点 T0: Client → host2 (发送package1)
时间点 T1: host2接收完成 → host1 (转发package1)
Client → host2 (发送package2)
时间点 T2: host1接收完成 → host3 (转发package1)
host2 → host1 (转发package2)
Client → host2 (发送package3)(2)确认流程:
当block1全部发送完成后,host2,host1,host3向NameNode节点发送通知,NameNode记录并将消息发送给host2
host2再向client发送消息通知client数据块block1已经发送完成,NameNode需要等待client确认;
client收到host2发送的消息后,向NameNode发送确认消息,至此,block1才真正完成了写入的过程
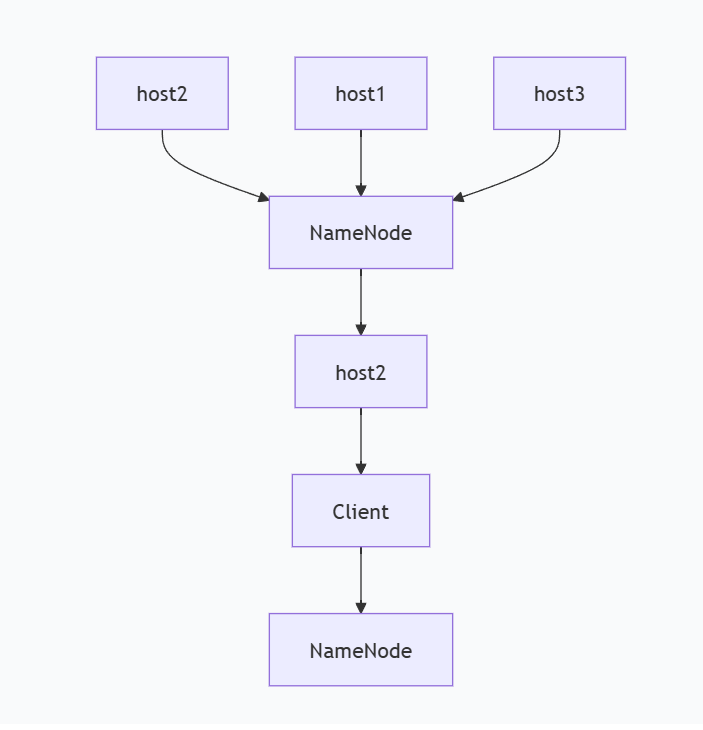
(3)完整写入流程总结
-
Block1写入:Client → host2 → host1 → host3
-
Block1确认:host2,host1,host3 → NameNode → host2 → Client → NameNode
-
Block2写入:Client → host7 → host8 → host4
-
Block2确认:类似Block1的确认流程
-
重复:直到所有数据块写入完成
3HDFS文件读取流程:
读取过程:
1.Block的位置是有先后顺序的:客户端首先处理 Block1 的位置列表,然后才处理 Block2 的位置列表。这是Block之间的先后顺序。
(这里是指逻辑顺序,不是物理读入顺序)
PS:在读取过程中,某时间节点可能会有延迟,导致物理存储顺序不是按照123来存储的,牢记读取顺序是按照逻辑顺序排列,而不是物理读入顺序
2.首先到host2上读取Block1;
3.然后再到host7上读取Block2。
PS:客户端(Client)发起请求,NameNode会返回一个列表,里面有block123的位置信息,对于每个块(例如Block1),客户端会从它的DataNode列表里,根据就近原则 (优先同节点、其次同机架、最后跨机架)选择一个最优的DataNode。客户端直接与这个选定的 DataNode 建立连接,读取整个Block1的数据,同理读取block23的数据。
HDFS读取过程分析:
1.上面的例子中,Client位于机架之外,也可以位于机架之内的某个DataNode上;
2.如果Client位于机架之内的某个DataNode上,那么读取的时候,遵循的原则是优先
读取本机架上的数据。
5.HA机制
(1)HA出现的原因
传统HDFS单点故障问题( "NameNode 和 SecondaryNameNode(SNN))
-
单NameNode架构:NameNode是唯一的主节点
-
SPOF(单点故障):NameNode宕机导致整个集群不可用
-
计划内维护:需要停机窗口进行升级维护
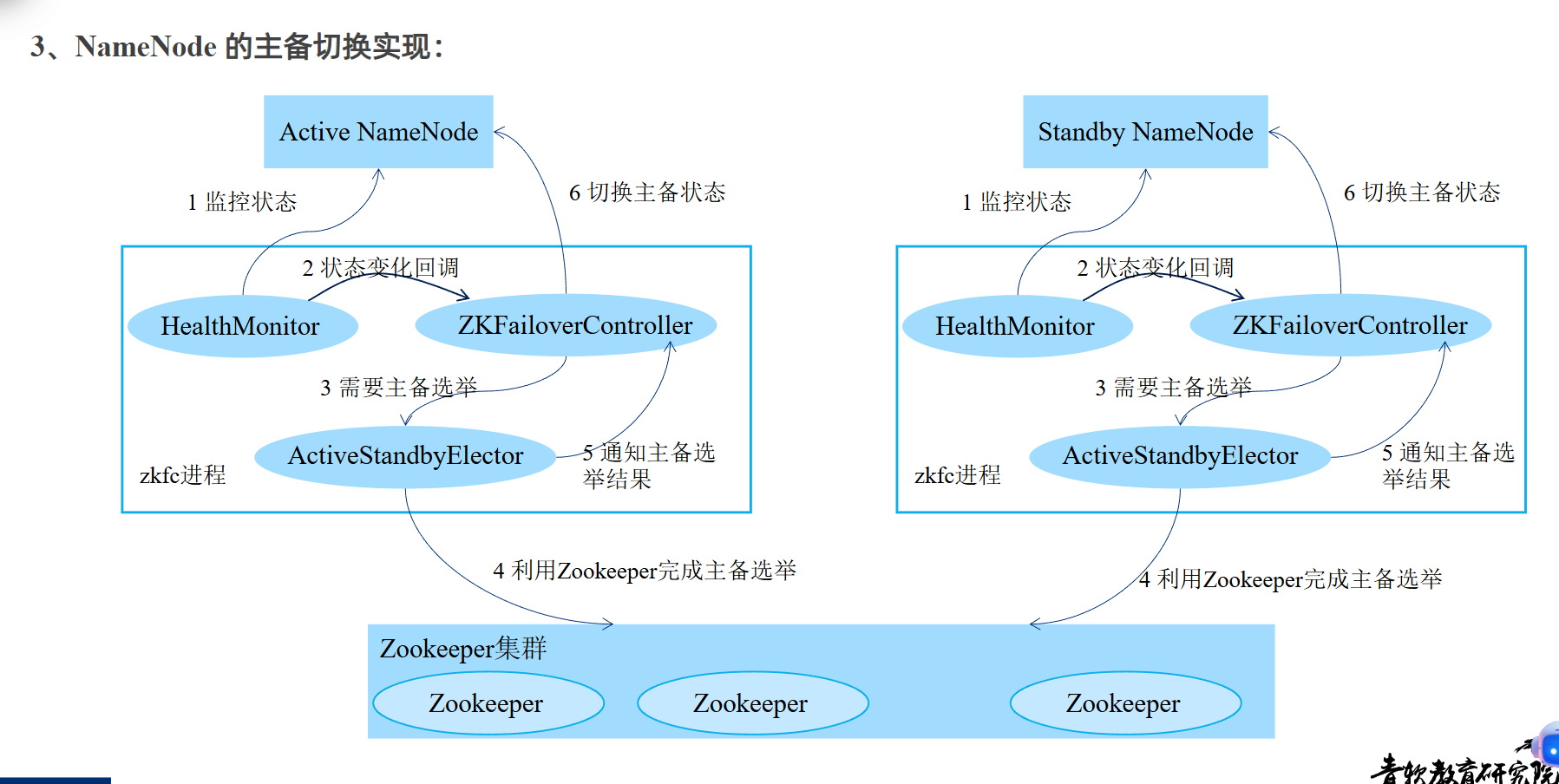
(2)NameNode 的主备切换实现:
在HA机制下只有Active/Standby NN"这两个主从节点,
Standby NameNode:
-
它的状态与Active NameNode保持同步。
-
不处理任何客户端的写请求(但可以处理读请求,这是一个可选的优化)。
-
时刻准备着,在Active节点故障时立即切换为Active状态。
NameNode主备切换(这里是指Active NameNode)由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 协同实现。
1. ZKFailoverController (zkfc)
角色:总指挥、协调器
-
作为独立进程运行在每个NameNode节点上
-
创建并管理另外两个组件(HealthMonitor和ActiveStandbyElector)
-
接收状态变化回调,决策并执行最终的主备切换动作
-
是整个故障转移流程的控制中心
2. HealthMonitor
角色:健康检测员
-
持续监控本地NameNode的健康状态
-
检测范围:进程存活、服务可用性、系统资源等
-
当发现NameNode状态异常时,立即通知zkfc
-
提供故障发现能力
3. ActiveStandbyElector
角色:选举协调员
-
封装与ZooKeeper集群的所有交互逻辑
-
负责参与主备选举,竞争Active身份
-
通过ZooKeeper的分布式锁机制实现选举
-
提供选举决策能力
HealthMonitor --监控--> NameNode健康
ActiveStandbyElector --协调--> ZooKeeper选举
ZKFailoverController --整合--> 执行最终切换
6.Federation机制
(1)HDFS的Federation机制主要是为了解决单个NameNode(命名空间和性能)的瓶颈问题。
-
命名空间瓶颈:单个NameNode在内存中存储整个HDFS的文件系统元数据(文件、目录、块信息)。当文件数量极其庞大时(例如数亿个),单个NameNode的内存会成为限制,无法继续扩展。
-
性能瓶颈:所有元数据操作(如创建文件、列出目录)都必须通过这一个NameNode。当客户端数量非常多时,单个NameNode的吞吐量会成为整个系统的上限。
-
隔离性问题:多个业务部门共享一个命名空间,缺乏隔离,一个用户的繁忙操作可能影响所有其他用户。
(2)解决措施:
Federation的核心思想是:引入多个独立的NameNode来管理不同的命名空间卷(Namespace Volume),这些NameNode是相互独立的,不需要彼此协调。
1. 架构变化
-
多个NameNode:每个NameNode管理文件系统命名空间的一部分。例如:
-
NameNode-1管理/user目录下的所有文件。 -
NameNode-2管理/project目录下的所有文件。
-
-
共享DataNode :集群中的所有DataNode不变,但它们同时向所有NameNode注册,并存储来自不同命名空间的数据块。一个DataNode上可能同时存储着由
NameNode-1管理的块和由NameNode-2管理的块。
2. 带来的好处
-
水平扩展命名空间:通过添加新的NameNode,可以扩展整个集群的命名空间容量,突破单个NameNode的内存限制。现在,10亿个文件可以分散在5个NameNode上,每个只需管理2亿个。
-
提升整体吞吐量 :因为客户端可以访问不同的NameNode来进行元数据操作,所以系统的总体吞吐量得到了提升。访问
/user的请求发往NameNode-1,访问/project的请求发往NameNode-2,它们互不干扰。 -
更好的隔离性:可以为不同的业务或团队分配独立的命名空间(由不同的NameNode管理),实现更好的资源隔离和性能隔离。
(3)一个简单的比喻:
非Federation(单NameNode):就像一个巨大的图书馆,只有一个总管理员。所有借书、还书、查书的人都要找他一个人。书(数据)越来越多,找他办事的人(客户端)也越来越多,他终于忙不过来了,而且他一个人的脑子(内存)也记不下所有书的位置了。
Federation(多NameNode):图书馆被分成了几个主题分馆(如科技馆、文学馆、历史馆)。每个分馆有自己独立的管理员(NameNode)。借科技书的人找科技馆管理员,借文学书的人找文学馆管理员。这些书(数据块)仍然可以存放在同一个大的书库(DataNode集群)中。这样,管理效率和处理并发的能力都大大提升了
7.文件压缩:
HDFS 常见压缩格式对比
| 压缩格式 | 压缩率 | 压缩/解压速度 | 是否支持 Split | 典型应用场景 |
|---|---|---|---|---|
| gzip | 中等 | 快 | 否 | 单个压缩文件小于一个HDFS块大小(如130MB),需要平衡压缩率和速度时。例如:按小时或天压缩的日志文件。 |
| lzo | 较低 | 中等 | 否 | 单个大文件(如超过200MB)压缩,处理速度比bzip2快。 |
| snappy | 较低 | 非常快 | 否 | MapReduce作业中,map阶段输出数据的压缩格式,用于提升shuffle阶段的效率。 |
| bzip2 | 高 | 慢 | 是 | 对存储空间要求极高,但对处理速度要求不高的场景。例如:冷数据存档、需要支持Split的大文件。 |
场景选择简化指南
-
追求速度 :选择 Snappy。
-
追求压缩率 :选择 Bzip2(并享受其支持Split的额外好处)。
-
平衡之选 :选择 Gzip。
-
处理大文件 :考虑 Lzo (需索引)或 Bzip2(需接受其速度慢)。