目录
-
-
- [1)etcd 基本架构](#1)etcd 基本架构)
- [2)etcd 的读写流程总览](#2)etcd 的读写流程总览)
- 3)k8s存储数据过程
- [4)watch 机制](#4)watch 机制)
-
- [Informer 机制](#Informer 机制)
- [etcd watch机制](#etcd watch机制)
- etcd的watchableStore源码解读
- [5) k8s大规模集群时会存在哪些问题?](#5) k8s大规模集群时会存在哪些问题?)
-
1)etcd 基本架构
何为etcd?
unix 的"/etc"文件夹和分布式系统 ("D"istribute system) 的 D,组合在一起表示 etcd 是用于存储分布式配置的信息存储服务。
etcd v2 有如下缺点:
bash
1)Memory Tree
- 不支持多版本
- 内存开销大
- 快照备份开销大
2)不支持多key事务
3)watch事件不可靠,可能会丢失
4)数据模型
- 不支持范围查询
- 不支持分页
5)TTL
- 大量key TTL相同时续期开销大,扩展性较低
6)HTTP/1.x
- 不支持压缩,流量大
- 不支持连接多路复用比如说:
-
K8s 项目严重依赖 etcd Watch 机制,然而etcd v2 是内存型、不支持保存 key 历史版本的数据库,只在内存中使用滑动窗口保存了最近的 1000 条变更事件,当 etcd server 写请求较多、网络波动时等场景,很容易出现事件丢失问题,进而又触发 client 数据全量拉取,产生大量 expensive request,甚至导致etcd 雪崩。
-
etcd v2 Watch 机制实现中client 通过 HTTP/1.1 协议长连接定时轮询 server,获取最新的数据变化事件。etcd v3 中基于 HTTP/2 的 gRPC 协议实现了连接多路复用。
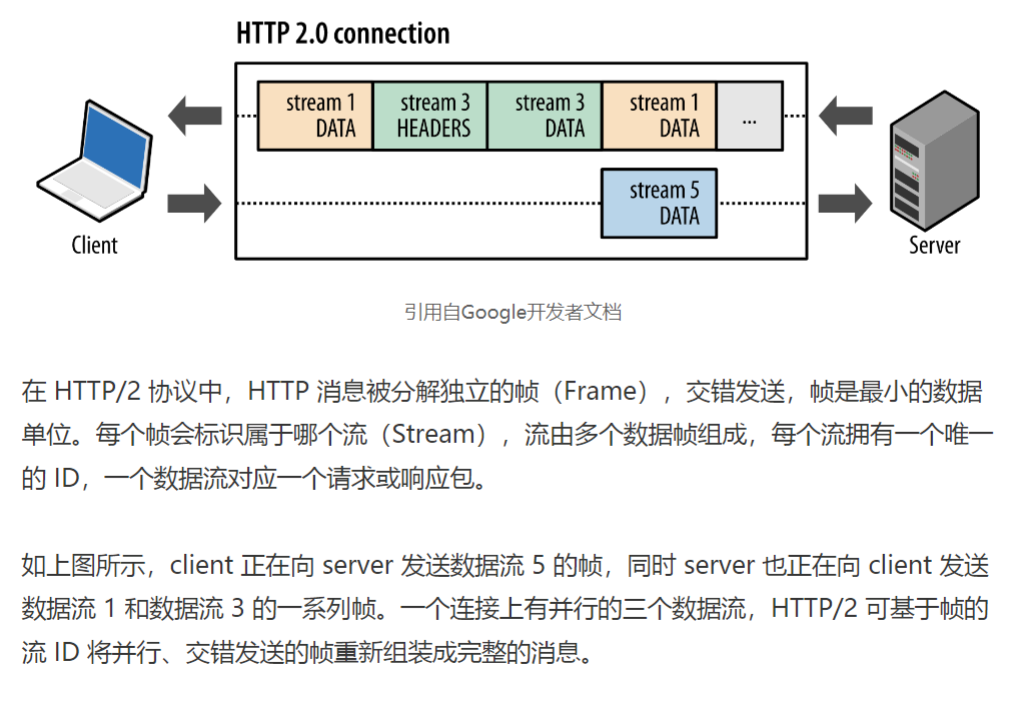
etcd v3的全景图如下:
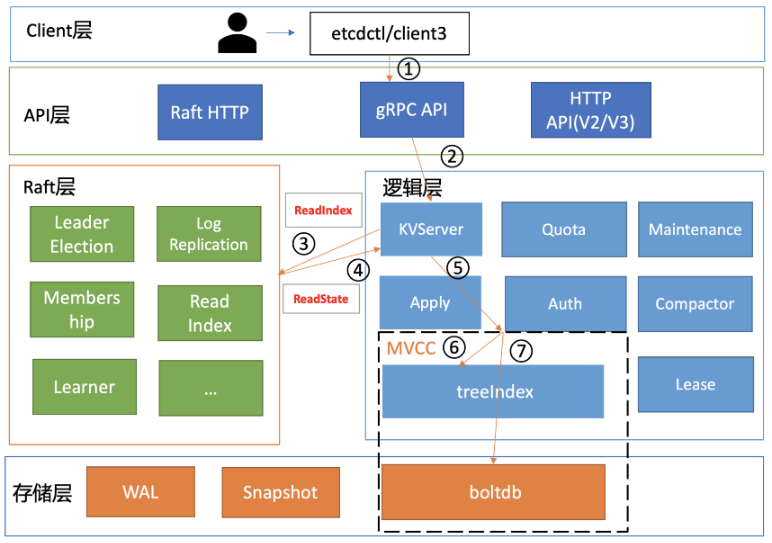
主要模块介绍:
1)Client 层提供 API 给用户调用,比如 etcdctl 命令行工具、Go/Python 客户端。本质是一个 gRPC Client,封装了请求(Put/Get/Watch/Txn)。
2)API 层 (gRPC API 层)etcd 进程内部运行了一个 gRPC Server,监听 :2379 端口。定义在 etcdserver/etcdserverpb/rpc.proto,里面有 KV、Watch、Lease、Cluster 等接口。Client 层发过来的请求(例如 Put key=foo)首先到达这里。
3)逻辑层1 KVServer:处理 Key-Value 操作(Put/Get/Delete/Txn/Range)。
2 LeaseServer:处理租约(key 绑定 TTL、心跳续租)。
3 AuthServer:权限管理(用户、角色、鉴权)。
4 ClusterServer:集群管理(Member Add/Remove)。
5 Quota:配额管理(防止单个租户占满空间)。
6 Maintenance:压缩、快照、Defrag 等。
注:
Quota模块: db配额在操作 etcd 过程中遇到过"etcdserver:mvcc: database space exceeded"错误,出现此错误,整个集群只读,不可写入。主要原因如下:
1)默认 db 配额仅为 2G,当你的业务数据、写入 QPS、Kubernetes 集群规模增大后,你的 etcd db 大小就可能会超过 2G。
2)etcd v3 是个 MVCC 数据库,保存了 key 的历史版本,当未配置压
缩策略的时候,随着数据不断写入,db 大小会不断增大,导致超限。
详细过程:
当 etcd server 收到 put/txn 等写请求的时候,会首先检查下当前 etcd db 大小加上你请求的 key-value 大小之和是否超过了配额;如果超过了配额,它会产生一个告警(Alarm)请求,告警类型是 NO SPACE,并通过Raft 日志同步给其它节点,告知 db 无空间了,并将告警持久化存储到 db 中。最终,无论是 API 层 gRPC 模块还是负责将 Raft 侧已提交的日志条目应用到状态机的Apply 模块,都拒绝写入,集群只读。
调大配额(不超过8G)-》 依然拒绝写入(需要清除NO SPACE 告警)Maintenance压缩模块
etcd 保存了一个 key 所有变更历史版本,如果没有一个机制去回收旧的版本,那么内存和 db 大小就会一直膨胀,在 etcd 里面,压缩模块负责回收旧版本的工作。
1)仅仅是将旧版本占用的空间打个空闲(Free)标记,后续新的数据写入的时候可复用这块空间,而无需申请新的空间。
2)回收空间,减少 db 大小,得使用碎片整理(defrag), 它会遍历旧的 db 文
件数据,写入到一个新的 db 文件。
配额(quota-backend-bytes)行为:
a)默认'0'就是使用 etcd 默认的2GB 大小;
b)小于 0 的数,就会禁用配额功能,这可能会让 db 大小处于失控,导致性能下降。
Apply 模块Apply 模块基于 consistent index 和事务实现了幂等性,保证了节点在异常情况下不会重复执行重放的提案。提交给 Apply 模块执行的提案已获得多数节点确认、持久化,etcd 重启时,会从 WAL 中解析出 Raft 日志条目内容,追加到 Raft 日志的存储中,并重放已提交的日志提案给 Apply 模块执行。
那如何保证幂等性呢?
Raft 日志条目中的索引(index)字段。日志条目索引是全局单调递增的,每个日志条目索引对应一个提案, 如果一个命令执行后,我们在 db 里面也记录下当前已经执行过的日志条目索引,但是不安全。etcd 通过引入一个 consistent index 的字段,来存储系统当前已经执行过的日志条目索引,实现幂等性。Apply 模块在执行提案内容前,首先会判断当前提案是否已经执行过了,如果执行了则直接返回,若未执行同时无 db 配额满告警,则进入到 MVCC 模块,开始与持久化存储模块打交道。
MVCC模块
一个是内存索引模块 treeIndex,保存 key 的历史版本号信息,另一个是boltdb 模块,用来持久化存储 key-value 数据。还有就是etcd 在启动的时候会通过 mmap 机制将 etcd db 文件映射到 etcd 进程地址空间,并设置了 mmap 的 MAP_POPULATE flag,它会告诉 Linux 内核预读文件,Linux内核会将文件内容拷贝到物理内存中,此时会产生磁盘 I/O。节点内存足够的请求下,后续处理读请求过程中就不会产生磁盘 I/O 了。
整体流程解读:
bash
Client (etcdctl / SDK)
│
▼
┌──────────────┐
│ gRPC API层 │ ← 接收请求 (KV.Put / Txn / Delete / Range)
└──────────────┘
│
▼
┌──────────────┐
│ KVServer │ ← 逻辑层,执行一系列检查
└──────────────┘
│
▼
┌───────────────────────────┐
│ 1. Auth 鉴权检查 │
│ - 检查用户 token/角色 │
│ - 无权限 → 拒绝请求 │
└───────────────────────────┘
│
▼
┌───────────────────────────┐
│ 2. Request Size 大小检查 │
│ - 超过 --max-request-bytes│
│ - → 返回 "request too large" │
└───────────────────────────┘
│
▼
┌───────────────────────────┐
│ 3. Rate Limiting 限速检查 │
│ - QPS、并发、延迟控制 │
│ - 超过限制 → 超时/拒绝 │
└───────────────────────────┘
│
▼
┌───────────────────────────┐
│ 4. Quota 配额检查 │
│ - 超过 --quota-backend-bytes │
│ - → 返回 "no space" │
└───────────────────────────┘
│
▼
┌───────────────────────────┐
│ 5. Proposal 打包 │
│ - 生成唯一ID │
│ - 绑定通知 channel │
│ - 封装成 Proposal │
└───────────────────────────┘
│
▼
┌──────────────┐
│ Raft 层 │ ← Propose 提案
└──────────────┘
│
▼
┌──────────────┐
│ Storage层 │ ← MVCC + BoltDB 持久化
└──────────────┘
│
▼
┌──────────────┐
│ 返回结果 │ ← 成功 / 超时 / 拒绝
└──────────────┘
bash
(1)鉴权 (Auth)
模块:AuthServer(逻辑层的子模块)。
检查客户端是否带有 token / 用户是否有权限访问该 key。
没有权限时,直接拒绝请求,不会进入 Raft。
(2)限速 (Rate Limiting)
模块:etcdserver/etcdserver.go 里的 isAvailable()、RequestLimiter。
防止过多请求同时进入 Raft,导致雪崩。
典型场景:Follower 挂掉恢复时,短时间内大量同步请求。
限速机制包括:
QPS 限制:限制每秒请求数。
并发数限制:限制同时处理的请求数量。
超时控制:默认 7 秒未提交 → 返回 etcdserver: request timed out。
(3)配额 (Quota)
模块:quota 包。
检查 etcd 数据库大小是否超过 --quota-backend-bytes。
如果超过:
普通写请求会被拒绝。
Lease keep-alive / system 请求可能例外。
这是为了避免磁盘写满,导致整个集群崩溃。
(4)打包 (Request Wrapping)
把请求封装成一个 Proposal:
包含请求的唯一 ID。
一个对应的 channel(通知通道),用来等候提交结果。
(5)Propose 提案
调用 Raft 的 node.Propose()。
Leader 会把 Proposal 写入 Raft log,复制到 Follower。
进入 Raft 共识流程:
过半节点确认提交 → 返回成功。
超时或 Leader 崩溃 → 返回 request timed out。
(6)等待提交
KVServer 在提交 Proposal 后,会 阻塞等待:
等待 Raft 层通知(通过 channel 返回)。
或者超时(7 秒)。
(7)存储 (MVCC + Backend)
提交成功后,Proposal 被应用到状态机:
调用 mvcc.Put()。
更新 Revision(比如 rev=12345)。
写入 bbolt(后端存储引擎)。
(8)返回响应
响应结果通过 gRPC 返回给 Client(例如 etcdctl)。总结:
API 层只转发请求。
逻辑层负责检查、校验、限流、组装 Raft 日志。
Raft 层只关心复制,不懂业务细节。
2)etcd 的读写流程总览
etcd 是典型的读多写少存储,在我们实际业务场景中,读一般占据 2/3 以上的请求。
a)一个读流程
一个读请求从 client 通过 Round-robin 负载均衡算法,选择一个etcd server 节点,发出 gRPC 请求,经过 etcd server 的 KVServer 模块、线性读模块、MVCC 的 treeIndex 和 boltdb 模块紧密协作,完成了一个读请求。
问题: Kubernetes 在执行 kubectl get pod 时,etcd 如何获取到最新的数据返回给 APIServer?
bash
1) 执行 kubectl get pod -n default
kubectl 调用 API Server 的 REST 接口:
GET /api/v1/namespaces/default/pods
2) API Server 接收到请求
API Server 内部处理顺序:
a、认证和鉴权
确认你是否有权限访问 pods。
b、RESTStorage (storage.go)
API Server 内部的 Pod REST handler 被调用。
具体实现绑定在 pkg/registry/core/pod/storage/storage.go,最终调用 genericregistry.Store.List()。
3) genericregistry.Store → etcd 存储接口
在 genericregistry.Store.List() 里,API Server 会调用 storage backend(etcd3 实现):
// staging/src/k8s.io/apiserver/pkg/storage/etcd3/store.go
func (s *store) List(...) {
// 调用 etcd client
resp, err := s.client.KV.Get(ctx, keyPrefix, clientv3.WithPrefix())
...
}
其中:
keyPrefix = "/registry/pods/default/"
所有 Pod 在 etcd 中的存储路径是:
/registry/pods/<namespace>/<podName>
4) etcd 如何保证数据是最新的?
a、etcd 使用 MVCC(多版本并发控制)存储
每一次写入都会增加一个全局递增的 revision。
Get 请求时,可以指定读取最新的 revision
b、强一致性保证
API Server 调用的是 etcd 的 Serializable 或 Linearizable 读:
默认 kubectl get 会走 Linearizable Read(强一致性)。
etcd Linearizable Read 要么直接在 Leader 本地读取,要么确保 Follower 的状态至少追上最新的 commit index。这样保证返回的数据一定是最新的。
【注】
Serializable(串行读)
这种直接读状态机数据返回、无需通过 Raft 协议与集群进行交互的模式,在 etcd 里叫做串行 (Serializable) 读,它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
比如说数据敏感的场景:
发布服务,更新服务的镜像的时候,提交的时候显示更新成功,结果你一刷新页面,
发现显示的镜像的还是旧的,再刷新又是新的,这就会导致混乱。再比如说一个转账场
景,Alice 给 Bob 转账成功,钱被正常扣出,一刷新页面发现钱又回来了,这也是令人不
可接受的。
Linearizable(线性读)
一旦一个值更新成功,随后任何通过线性读的 client 都能及时访问到。虽然集群中有多个节点,但 client 通过线性读就如访问一个节点一样。
etcd 默认读模式是线性读,因为它需要经过 Raft 协议模块,反应的是集群共识,因此在延时和吞吐量上相比串行读略差一点,适用于对数据一致性要求高的场景。b)一个写流程
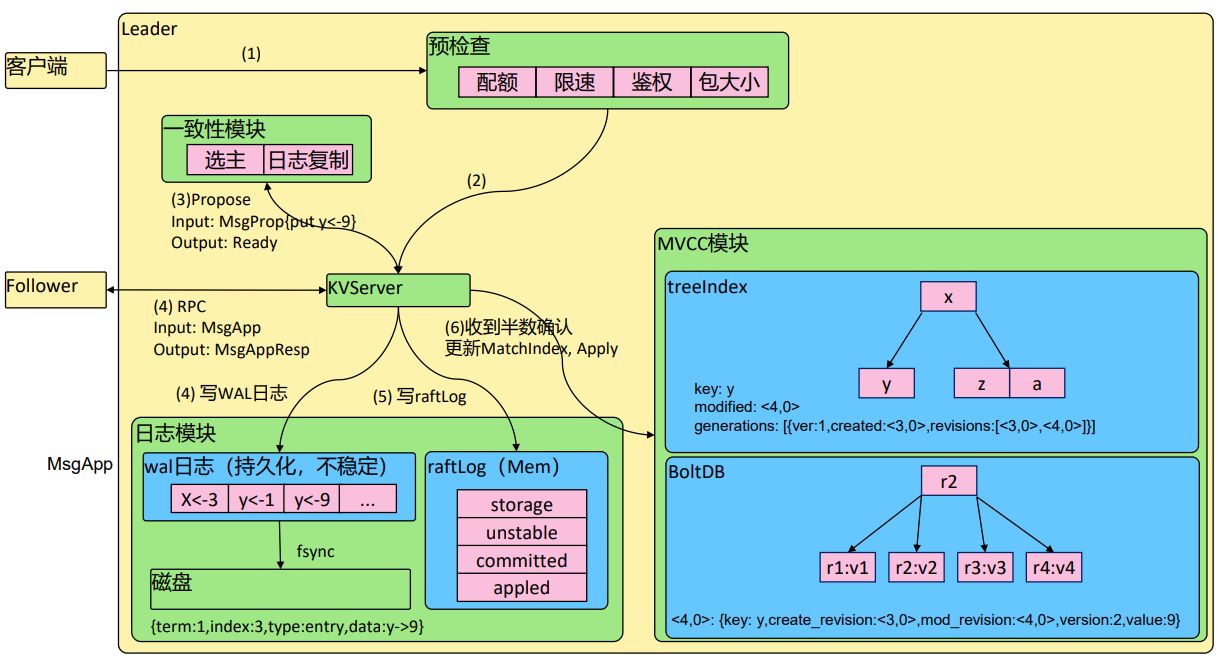
如图整体流程如下:
1)整体流程串联(图里编号)
2)客户端发起写请求(put y=9)。
3)KVServer 做预检查(配额、限速、鉴权、包大小)。
4)Leader 调用 Propose,把请求封装成 Raft entry。
5)Leader 通过 RPC 复制日志到 Follower。
6)Leader/Follower 本地写 WAL 日志、更新内存 raftLog。
7)Leader 收到半数以上确认 → 提交 → Apply 到 MVCC。
8)MVCC 模块更新 treeIndex + BoltDB,记录 revision 和数据。
9)客户端收到写入成功的响应
详细解读如下:
bash
1. 客户端请求
客户端发起 put y=9 请求,发送到 Leader 节点的 API 层。
2. KVServer 前置检查(预检查)
在 KVServer 模块,写入前会做一系列 逻辑层校验:
鉴权(Auth):用户是否有权限写这个 key。
限速(Rate Limit):避免高并发写导致雪崩。
配额(Quota):检查是否超过 --quota-backend-bytes。
包大小(MaxRequestBytes):是否超过单请求大小限制。
只有通过了这些检查,才能继续走 Raft 流程。
3. Propose 提案
KVServer 调用 Raft 模块的 Propose 方法。
Propose 会把请求封装成一个 Raft entry(日志条目),包含:
term: 1,
index: 3,
type: entry,
data: y->9
Leader 把这个 entry 放 待复制队列,输出一个 Ready 事件。
4. 日志复制(Leader → Follower)
Leader 通过 AppendEntries RPC(图里的 MsgApp)把这个日志条目发给 Follower。
Follower 收到后:
写入本地 WAL 日志文件(磁盘持久化,但还未 apply)。
放入内存中的 raftLog(storage/unstable/committed/applied 结构)。
然后返回 MsgAppResp 给 Leader,表示"我收到了"。
5. Leader 本地写日志
Leader 自己也做相同的事:
把日志写入 WAL(Write Ahead Log,预写日志)。
同时更新内存的 raftLog 状态。
注意:这时数据还不能对外可见,只是进入了 Raft 日志。
6. 达到多数派确认 → 提交
当 Leader 收到 半数以上节点确认时:
Leader 更新 MatchIndex,把该日志条目标记为 committed。
然后触发 Apply:把日志条目应用到状态机(MVCC)。
即:y=9 被真正写入到 etcd 的 MVCC 存储。
7. MVCC 模块(最终存储)
etcd 的存储分成两部分:
treeIndex:内存索引(B+树),快速定位 key。
BoltDB:持久化存储(底层 KV 数据库)。
这里:
y=9 的写入生成新的 revision(比如 <4,0>)。
treeIndex 更新 key 的元信息(哪个 revision,什么时候创建/修改)。
BoltDB 存储实际值:
<4,0>: {key:y, create_revision:<3,0>, mod_revision:<4,0>, version:2, value:9}
这样 etcd 就支持 多版本:比如之前 y=1, y=3 都会留在历史 revision 里。
8. 返回结果
写请求在 MVCC 成功 apply 后,KVServer 通知等待的客户端。
如果 apply 超时(7s 没有多数确认),返回 etcdserver: request timed out。3)k8s存储数据过程
API Server = 业务逻辑 + 校验 + 对外暴露 API
etcd = 持久化存储 + Watch 机制
流程图如下:
bash
客户端 (kubectl apply -f pod.yaml)
│
▼
┌───────────────────────────────┐
│ Kubernetes API Server │
│ │
│ 1. 接收请求 │
│ POST /api/v1/namespaces/default/pods │
│ │
│ 2. 认证 & 鉴权 (Authn/Authz) │
│ │
│ 3. Admission 控制器 │
│ - MutatingWebhook │
│ - ValidatingWebhook │
│ │
│ 4. RESTStorage (storage.go) │
│ - PodStrategy 校验、默认值 │
│ - 调用 genericregistry.Store│
│ │
│ 5. 调用 etcd3 backend │
│ key=/registry/pods/default/mypod │
│ value=Pod 对象 protobuf │
└───────────────┬───────────────┘
│ gRPC (clientv3 Put)
▼
┌───────────────────────────────┐
│ etcd Leader │
│ │
│ A. KVServer 预检查 │
│ - 鉴权、限速、配额、包大小 │
│ │
│ B. Propose 提案 │
│ - 生成 Raft entry (y->9) │
│ - term/index/data 封装 │
│ │
│ C. 日志复制 │
│ - AppendEntries RPC → Follower │
│ - 写 WAL (磁盘预写日志) │
│ - 写 raftLog (内存日志) │
│ │
│ D. 多数确认 │
│ - 半数节点返回 MsgAppResp │
│ - Leader 标记 committed │
│ │
│ E. Apply 到状态机 (MVCC) │
│ - 更新 treeIndex (索引) │
│ - 写入 BoltDB (持久化) │
│ - 分配 revision=12345 │
└───────────────┬───────────────┘
│
▼
返回 API Server
│
▼
kubectl 输出: "pod/my-pod created"注意:
API Server 负责:
权限控制、校验对象是否合法(Strategy)、调用 etcd 客户端写数据。
etcd 负责:
请求预检查(Auth/Quota/RateLimit/Size)。
Raft 日志复制(强一致性)。
WAL + raftLog(高可靠)。
MVCC 存储(多版本数据)。
最终,Kubernetes 的所有对象(Pod/Deployment/ConfigMap/Service 等)最终都会转化为:
bash
etcd key = /registry/<资源>/<命名空间>/<对象名>
etcd value = 序列化后的对象(protobuf)源码解读
(1)API Server 的存储抽象
在 Kubernetes 源码里,API Server 并不是直接对接 etcd 的。它用了一个分层架构:
etcd3 实现层:staging/src/k8s.io/apiserver/pkg/storage/etcd3/
实现了和 etcd v3 的具体交互(Put/Get/Delete/Watch)。
通用存储接口层:staging/src/k8s.io/apiserver/pkg/registry/generic/registry/
提供了一套通用的 CRUD(Create/Update/Delete/List/Watch)。
具体资源的 storage.go(例如 pkg/registry/core/pod/storage/storage.go)
把具体资源(Pod、Service)和通用存储接口结合起来。
bash
K8s Resource Object -> storage.go (定义存储规则)
-> generic.Store (通用 CRUD 实现)
-> etcd3 (最终调用 etcd API)(2)Pod 的 storage.go 示例
路径:pkg/registry/core/pod/storage/storage.go,简化后的代码如下:
bash
// NewStorage creates a new pod storage.
func NewStorage(optsGetter generic.RESTOptionsGetter) (PodStorage, error) {
store := &genericregistry.Store{
//说明这个 store 管理的对象类型是 Pod
NewFunc: func() runtime.Object { return &api.Pod{} },
//支持 List 时返回 PodList
NewListFunc: func() runtime.Object { return &api.PodList{} },
KeyRootFunc: func(ctx context.Context) string {
return "/pods" // 顶层 key 前缀
},
KeyFunc: func(ctx context.Context, name string) (string, error) {
ns, ok := genericapirequest.NamespaceFrom(ctx)
//Pod 的 etcd 存储路径是/registry/pods/{namespace}/{podName}
return "/registry/pods/" + ns + "/" + name, nil
},
//存储时提取对象的名字
ObjectNameFunc: func(obj runtime.Object) (string, error) {
return obj.(*api.Pod).Name, nil
},
PredicateFunc: MatchPod, // 用于 List/Watch 过滤
//定义在 pkg/registry/core/pod/strategy.go 通用存储接口层
CreateStrategy: pod.Strategy,
UpdateStrategy: pod.Strategy,
DeleteStrategy: pod.Strategy,
}
options := &generic.StoreOptions{ ... }
//把通用 genericregistry.Store 和 etcd3 backend 绑定
if err := store.CompleteWithOptions(options); err != nil {
return PodStorage{}, err
}
return PodStorage{Pod: store}, nil
}
总结:
每个资源的 storage.go 定义了:
对象类型(Pod/Service/Deployment)。
etcd key 命名规则(/registry/...)。
CRUD 策略(Strategy)。
调用 generic.Store 绑定到 etcd3 backend。
API Server 不直接操作 etcd,而是通过 genericregistry.Store 抽象。
etcd 里最终存的就是序列化后的对象(Protobuf 或 JSON),键名由 storage.go 定义。4)watch 机制
Informer 机制
Informer 的内部机 Informer 是 API Server watch 机制的一个封装,它帮 Controller 高效感知对象变化:
本地缓存 (Indexer + Thread Safe Store) → 减少对 API Server 的压力。
增量事件推送 (DeltaFIFO + Reflector) → 只同步变化,不用全量拉。
事件驱动 (Resource Event Handler + WorkQueue) → 变化时才触发 Controller 的逻辑。
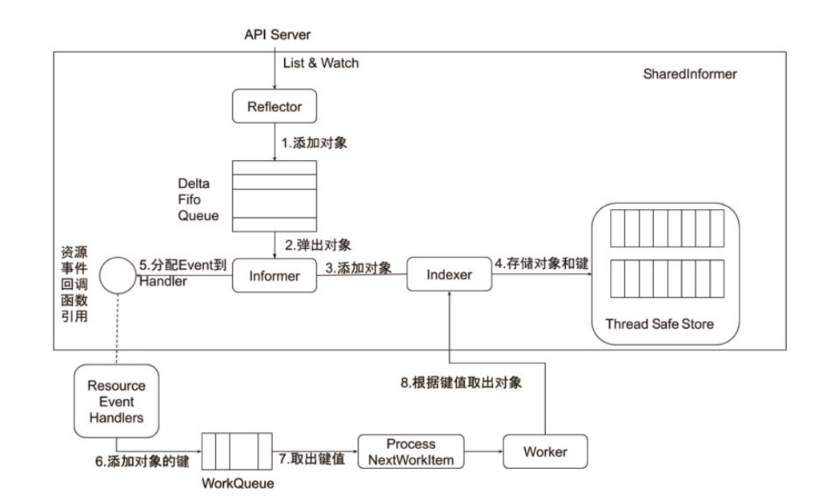
(1)Reflector
向 API Server 发起 ListAndWatch:
List():先全量获取对象,保存下来。
Watch():然后订阅后续变化事件。
把拿到的对象/事件放进 DeltaFIFO 队列。
(2)DeltaFIFO Queue
FIFO 队列,保存对象的增量变化(Delta = add/update/delete)。
例如:
Pod 新建 → 入队一个 Add delta。
Pod 更新 → 入队一个 Update delta。
(3)Informer
从 DeltaFIFO 队列里 弹出对象。
调用 Indexer 更新本地缓存。
同时调用 Resource Event Handler(比如 Controller 注册的回调函数)。
(4)Indexer + Thread Safe Store
Indexer 负责把对象按 key 存入缓存(比如 namespace/name)。
Thread Safe Store 是真正的本地存储,保证并发安全。
Controller 可以直接从 Indexer 拿对象,不用每次都找 API Server。
(5)Resource Event Handlers
Controller 注册的回调,比如:
bash
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: onUpdate,
DeleteFunc: onDelete,
})当对象变化时,Informer 会调用这些回调函数。
(6)WorkQueue
Handler 通常不会直接处理对象,而是 把对象的 key (namespace/name) 放进 WorkQueue。
WorkQueue 支持:去重、重试、速率限制。
保证 Controller 处理不过来时不会丢数据。
(7)Worker
控制器里的 Worker 会不断从 WorkQueue 取出 key。
根据 key 去 Indexer 缓存里拿对象。
执行 Reconcile 逻辑:对比期望状态 vs 实际状态,做出修复动作。
bash
Reflector = "眼睛",盯着 API Server 看变化。
DeltaFIFO = "快递站",收集所有变化事件。
Informer = "快递员",把变化送到缓存 + 通知 Controller。
Indexer/Store = "仓库",存放所有对象的最新版本。
Handler + WorkQueue = "派单系统",把要处理的对象派发给工人。
Worker = "工人",拿到派单后去仓库取货(对象),执行任务(Reconcile)。etcd watch机制
当 API Server / Controller 需要持续获取某些对象的变化(比如Pods/Deployments),就会调用 etcd 的 Watch API,而不是不停地去 List。
核心模块就是 watchableStore(在 etcd 的存储层)。它的实现逻辑:
bash
(1)三类 watcher
unsynced:刚建立,还没同步到最新 revision 的 watcher。
synced:已经追上最新 revision,处于 steady 状态,能直接收到新事件。
victim:因为通道阻塞、慢消费、断连等原因落后的 watcher,需要单独处理。
(2)后台 goroutines
etcd 内部有多个后台循环:
一个负责给 synced watcher 推送最新事件。
一个负责帮 unsynced watcher catch up(从存储里把 missed 的历史 revision replay 一遍)。
一个负责处理 victim watcher(重试,必要时断开)。
这样就能保证:事件按 revision 顺序投递(基于 MVCC 版本)。
不会丢失事件(即使 client 慢了,也能在 unsynced 队列里补数据)。
不会阻塞全局(慢的 watcher 被移到 victim,不影响其他 watcher)。
(3)保证逻辑时钟顺序
etcd 的数据都有 revision,每个事件都是按 revision 排序推送。
所以 client(API Server/Controller)收到的事件顺序就是 一致且不乱序的。Deployment Controller 如何感知变化?
bash
K8S 的 Controller 模式就是建立在 Watch 之上的。
以 Deployment Controller 为例:
(1)Controller Manager 启动
kube-controller-manager 启动时会初始化各种控制器(Deployment、ReplicaSet、Job、Node...)。每个控制器里都有一个 Informer。
(2)Informer 的机制
Informer 使用 ListAndWatch 模式:
先从 API Server List 一次资源(获取最新全量对象 + resourceVersion)。
然后从这个 resourceVersion 开始,对 API Server 发起 Watch 请求。
API Server 本身就是 etcd 的代理,它在内部用 etcd 的 watchableStore 来获取变化,然后转发给客户端。
(3)事件推送
API Server 从 etcd 拿到 watch 事件(Pod/RS/Deployment 的 add、update、delete)。把事件推送到 Controller Manager 的 Reflector → DeltaFIFO → Informer → WorkQueue。最终,Deployment Controller 会收到一个"对象变化"的事件。
(4)控制循环(Reconcile Loop)
Deployment Controller 的逻辑是:
期望状态(用户提交的 Deployment.spec) ← 存在 etcd。
实际状态(集群里当前的 ReplicaSet / Pods)。
每次有事件(Deployment 或 Pod/RS 变化),就触发一次 Reconcile:
比较期望副本数 vs 实际 Pod 数量。
如果少,就创建新的 ReplicaSet/Pod。
如果多,就删除多余的 Pod。
(5)高效性来源
Controller 不会去轮询 etcd,而是通过 Watch 机制被动接收事件。
Informer 有 本地缓存 + 只 watch 增量,避免全量拉取。
所以 Controller 能在毫秒级感知到 Deployment/Pod 的变化。总结:
etcd 的 watchableStore 提供了可靠的事件推送机制,保证不丢失、不乱序。
K8S Deployment Controller 通过 Informer + Watch,能实时感知 Deployment 对象的变化,然后在 Reconcile 循环中把集群实际状态调到期望状态。
etcd的watchableStore源码解读
etcd 的 Watch:
etcd 提供的 Watch 能力,其实是 基于 MVCC 版本号 (revision) 的。
每次写请求(Put/Delete/Txn)都会生成一个新的 全局递增 revision。
所以,只要有新的 revision 出现,就说明有数据变化,watcher 就应该被触发。
watchableStore 的任务就是:
管理所有活跃的 watcher,并在有新 revision 写入时,把相应事件分发出去。
如下图所示,每次操作都会更新reivsion。
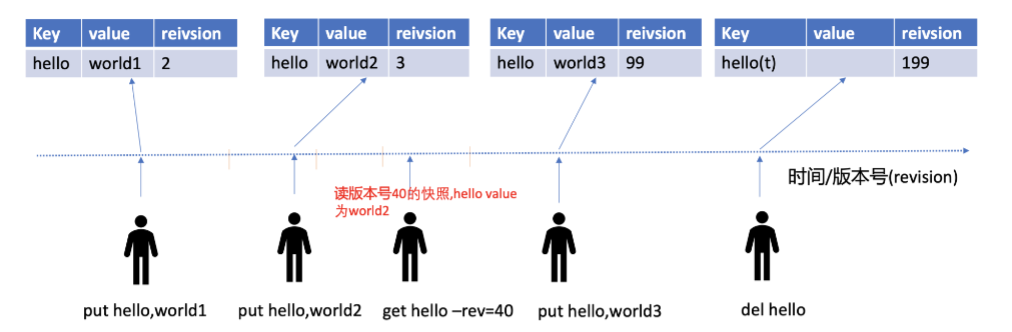
总体流程:
写请求进入 etcd,生成新 revision + event。
watchableStore 的 notify() 被调用。
遍历 watchers,筛选出关心这个 key 的。
如果 watcher 落后 → 放到 unsynced 补历史。
如果 watcher 正常 → 放到 synced,直接推送。
如果 watcher 堵塞 → 放到 victims,异步处理。
在 etcd 源码里(server/mvcc/watchable_store.go):
bash
type watchableStore struct {
*store // 底层 MVCC 存储 (treeIndex + BoltDB)
mu sync.RWMutex
watchers map[*watcher]struct{} // 当前活跃的 watcher
unsynced watcherGroup
synced watcherGroup
victims watcherGroup
...
}
store:真正的 MVCC 存储,负责 Put/Get/Delete。
watchers:所有活跃 watcher。
unsynced:刚建好,还没追上最新 revision 的 watcher。
synced:已经和最新 revision 对齐的 watcher。
victims:推送失败的 watcher。
问:为什么分 synced / unsynced / victim?
unsynced:新建 watcher 时,可能有一堆历史事件需要补齐。
etcd 会扫描 MVCC(BoltDB),把从 minRev 到当前最新 revision 的历史事件一次性 replay 给 watcher。
synced:一旦补齐,就只需要实时推送新事件。
victim:如果某个 watcher 处理不过来(channel 堵住),会放到 victim,异步慢慢重试,避免拖慢其他 watcher。
这样 etcd 就能:
确保新建 watcher 不会丢历史事件。
确保慢消费者不会拖垮快消费者。
确保所有事件严格按照 revision 顺序推送。写请求如何触发 Watch?
bash
以 Put(key, val) 为例:
1)写入 MVCC 层
新 key 写入 treeIndex + BoltDB。
分配 revision = 12345。
2)生成事件 (Event)
事件结构包含:
type Event struct {
Type EventType // PUT/DELETE
Kv *mvccpb.KeyValue
PrevKv *mvccpb.KeyValue
}
3)watchableStore 通知 watchers
在 store.put() 里会调用 notify():
ws.mu.Lock()
ws.notify(revision, events)
ws.mu.Unlock()
//解释
notify() 遍历所有 watcher,判断:
这个 watcher 是否对该 key 感兴趣?
这个 watcher 当前 revision < 新 revision?
如果满足,就把 event 推送到 watcher 的 channel。
4)Watcher 的处理
每个 watcher 是一个结构体:
type watcher struct {
id int64
key []byte
end []byte
minRev int64 // watcher 关注的最小 revision
ch chan WatchResponse
...
}
minRev = 从哪个 revision 开始关注。
当 notify 推送时,如果 event.revision >= minRev 且 key 匹配,就把 event 放进 channel。
goroutine 会从 channel 里读,最终通过 gRPC 流返回给 API Server / Client。总结:
watchableStore 并不是主动"检测变化",而是挂在 etcd 的 MVCC 写路径上,每次有新 revision 就触发 notify(),把事件按照 revision 顺序推送到合适的 watcher 队列(synced/unsynced/victim),最终通过 gRPC 返回给 API Server。
5) k8s大规模集群时会存在哪些问题?
大规模 Kubernetes 集群的痛点:
1)请求多(心跳、List、Watch)
bash
在大集群(几千 ~ 上万节点)里:
1)心跳请求
每个 kubelet 定期向 API Server 汇报 Node 状态 & Pod 状态(Condition、Status)。
大规模时 → 指数级增加写请求。
2)List 请求
控制器通常要全量 List 一次(比如 Pod Informer),然后 watch。
对象数量巨大(几十万 Pod),全量 List 会非常耗时。
Expensive Request:
全量 List 所有 Pods、Nodes、Endpoints 等。
序列化/反序列化、网络传输、etcd 读压力都变大。
本质:API Server 承受高 QPS 压力,etcd 要频繁处理大范围的读写。2)写多(Node 心跳 / Pod 状态)
bash
1)Kubernetes 中很多控制器 & kubelet 会不停写 etcd:
Node 心跳(status.conditions 更新)。
Pod 状态(调度、运行时、探针)。
Endpoint 更新(Service 的 endpointslices)。
在上万节点时,这种小写请求的数量非常大。
上面的情况会导致下面的问题:
db size 持续增长(etcd MVCC 保留历史 revision)。
写放大(每次写入都触发 Raft 共识 + WAL + BoltDB fsync)。
写性能瓶颈 → 导致限速,影响读性能。
本质:etcd 的一致性写模型 (Raft + WAL) 不擅长高频小写。3)数据大(ConfigMap / Secret / CRD)
bash
etcd 适合存储小 kv(几十 KB)。
硬限制:
value 默认最大 1.5MB。
request 最大 1.5MB。
在大集群里,某些对象(ConfigMap、Secret、CRD、Endpoints)可能会变得非常大:
Endpoints:如果一个 Service 绑定几千 Pod,Endpoints 对象可能几 MB。
CRD:用户定义的复杂 CR,存储时也可能超过限制。
会存在如下问题:
etcd 内存压力增大(反序列化大对象)。
网络传输耗时。
API Server GC 压力大。
本质:大对象不适合存到 etcd,但 Kubernetes 的抽象模型天然依赖 etcd。4)Watch 消费问题
c
Controller Manager、Scheduler、kube-proxy 都依赖 ListAndWatch。
大集群里 watch 的事件数量非常庞大。
如果某个 Controller 消费慢,事件会堆积,etcd 会把它移到 victim 队列,需要 replay 历史事件,导致 更多的 IO 压力。
本质:watch 是长连接 & 增量流,但在大规模下容易堆积和抖动。5)Leader 瓶颈
bash
etcd 是 Raft 模型,所有写都必须走 Leader。
Leader 压力极大(所有写集中在一台)。
虽然可以有多个 Follower 分担读,但写的瓶颈始终在 Leader。
大规模集群可能导致 Leader 过载,心跳丢失,触发频繁选主。
本质:Raft 强一致性的 Leader 写瓶颈。常见解决方案
大规模 Kubernetes 集群的优化核心是:减少 etcd 压力(少写/少全量读/避免大对象),利用缓存和分片机制,把频繁请求转为增量事件。
bash
大规模 K8S 集群
│
├── 1. Expensive Request (频繁 List/Watch)
│ │
│ ├─ 问题: 全量 List 对象太大,Watch 事件过多
│ │
│ └─ 优化:
│ • Shared Informer 缓存(复用本地缓存,减少重复 List/Watch)
│ • 分页 List (?limit)(避免一次全量拉取)
│ • Endpointslices(切片化,避免大 Endpoints)
│ • API Server 内存缓存(减少直接读 etcd)
│
├── 2. 写入压力 (Node/Pod 状态 & 心跳)
│ │
│ ├─ 问题: 心跳 & 状态频繁写 etcd → 写放大
│ │
│ └─ 优化:
│ • Node Lease (轻量心跳对象)
│ • 延长心跳周期 (--node-status-update-frequency)
│ • Pod 状态更新合并 (kubelet 不每次都写)
│
├── 3. 大对象 (ConfigMap / Endpoints / CRD)
│ │
│ ├─ 问题: etcd 不适合存大对象 (>1.5MB)
│ │
│ └─ 优化:
│ • 避免大 ConfigMap/Secret → 存外部对象存储 (S3/OSS)
│ • Endpointslices → 拆分大对象
│ • CRD 数据裁剪 (不要放日志/大二进制)
│
├── 4. Watch 压力
│ │
│ ├─ 问题: 大量 Watch 事件,慢消费者 backlog
│ │
│ └─ 优化:
│ • Watch Bookmarks (减少全量 replay)
│ • client-go Informer 缓存 (减少 API Server 压力)
│ • 控制器分片/拆分 (按 namespace/label 分组 watch)
│
├── 5. etcd Leader 瓶颈
│ │
│ ├─ 问题: 所有写集中到 Leader,写放大严重
│ │
│ └─ 优化:
│ • etcd 集群扩展 (3/5 节点,提升可用性)
│ • 读写分离 (serializable 弱一致读)
│ • 定期 compact + defrag (清理历史 revision,回收空间)
│
└── 6. API Server 压力
│
├─ 问题: 大请求 (List Pods) 可能阻塞小请求 (心跳)
│
└─ 优化:
• API Priority and Fairness (APF) 请求优先级队列
• client 请求限流 (--kube-api-qps / --kube-api-burst)推荐阅读:
3)文件系统