本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院
随着AI应用从单次交互转向复杂智能体系统,传统Prompt Engineering(提示工程)的局限性日益凸显。今天我将系统阐述AI工程范式的演进路径,深入剖析Context Engineering(上下文工程)的核心架构与关键技术,希望能帮助到大家。
一、范式转移:从静态指令到动态上下文
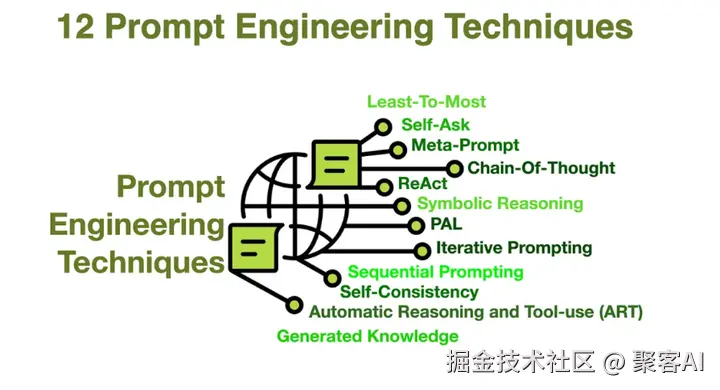
1. Prompt Engineering的局限性
定义:通过设计结构化输入(指令/示例/上下文)引导模型生成目标输出
技术矩阵:
- 零样本提示:依赖预训练知识
- 少样本提示:1-5个高质量示例
- 思维链(CoT):分解复杂问题
核心缺陷:
- 脆弱性:微调措辞导致输出剧变
- 扩展瓶颈:难以应对高并发场景
- 无状态性:无法处理多轮对话
2. Context Engineering的崛起
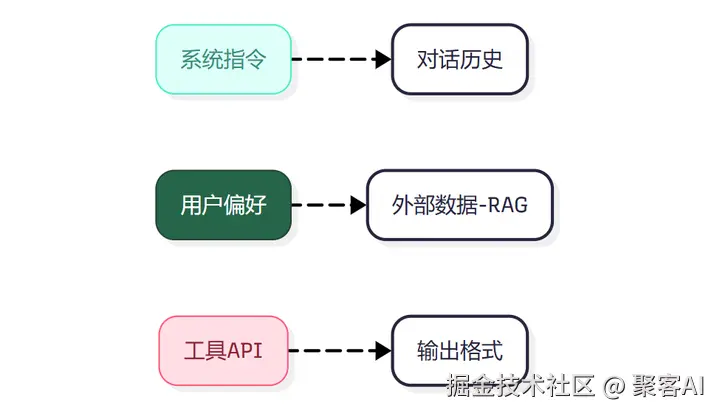
本质区别:
| 维度 | Prompt Engineering | Context Engineering |
|---|---|---|
| 目标 | 优化单次指令 | 构建动态上下文系统 |
| 范围 | 单轮交互 | 多源数据流整合 |
| 关键技术 | 指令设计 | RAG/向量数据库/工作流编排 |

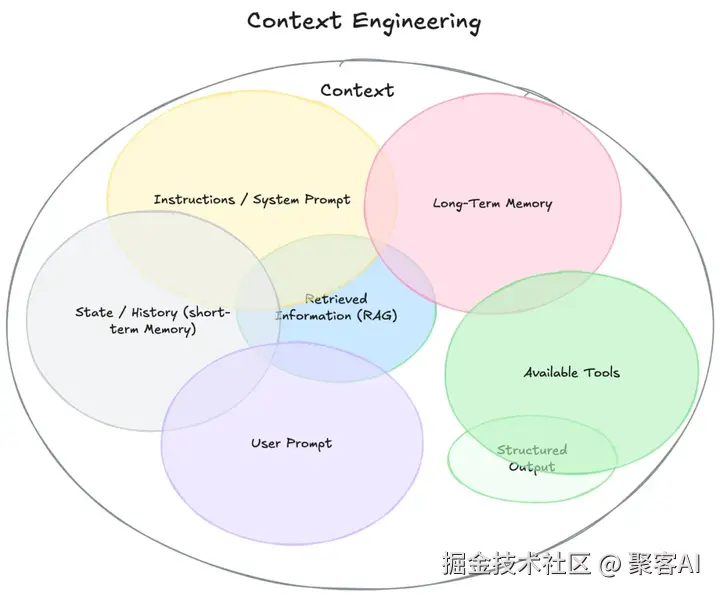
上下文范畴:
二、Context Engineering技术支柱
1. RAG:动态上下文引擎
架构演进:
Naive RAG:基础检索→增强提示→生成
Advanced RAG:
- 检索前优化:语义分块/查询转换
- 检索后处理:重排序/上下文压缩
Agentic RAG:多步骤工具调用+状态保持
2. 向量数据库选型指南
| 维度 | Pinecone | Milvus | Weaviate |
|---|---|---|---|
| 部署模式 | 全托管 | 自托管/云 | 混合 |
| 扩展性 | 千万级 | 十亿级 | 百万级 |
| 特色功能 | API简易 | 多索引算法 | 混合搜索 |
3. 突破上下文窗口限制
Lost in the Middle问题:LLM对长文本中间信息利用率骤降
解决方案:
语义分块:按主题边界切割(优于固定分块)
重排序机制:Cross-Encoder深度评估相关性
上下文压缩:
ini
# LangChain实现示例
compressor = LLMChainExtractor()
compressed_docs = compressor.compress(docs, query)三、智能体系统的上下文管理
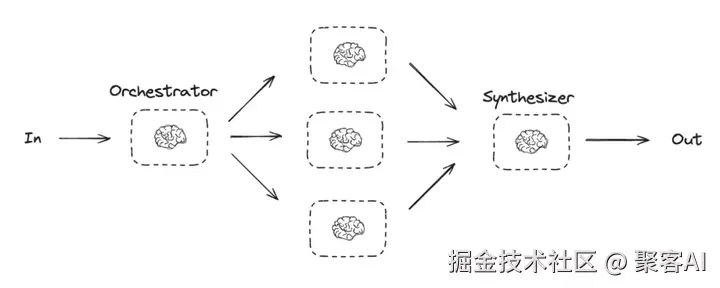
1. 核心架构模式
- 链式工作流:线性模块化执行
- 路由工作流:动态选择执行分支
- Orchestrator-Workers:
2. 自主决策机制
ReAct框架:
ini
Thought: 需查询天气 → Action: search_weather(location="上海") → Observation: "25℃晴"反思机制:
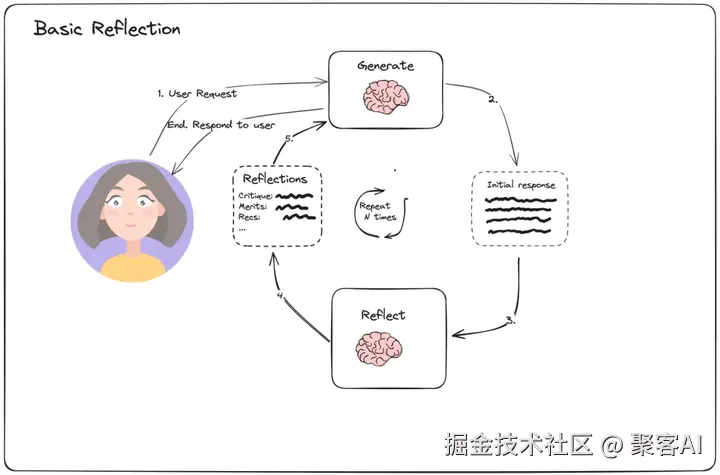
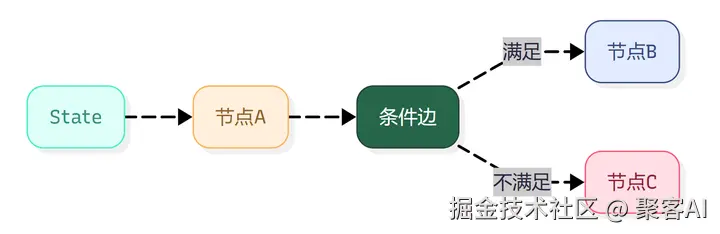
3. LangGraph实现工作流引擎
作者结语
Context Engineering不是简单替换Prompt Engineering,而是构建可扩展AI系统的必由之路。开发者需掌握三大核心能力:动态上下文构建(RAG)、工作流编排(LangGraph)、资源优化(向量数据库),方能在智能体时代构建高可靠性应用。好了,今天的分享就到这里,点个小红心,我们下期见。