循环神经网络(RNN)、LSTM 与 GRU (一)
文章目录
- [循环神经网络(RNN)、LSTM 与 GRU (一)](#循环神经网络(RNN)、LSTM 与 GRU (一))
- [循环神经网络(RNN)、LSTM 与 GRU](#循环神经网络(RNN)、LSTM 与 GRU)
-
- [一、RNN(Recurrent Neural Network)](#一、RNN(Recurrent Neural Network))
-
- [1. 基本思想](#1. 基本思想)
- [2. 数学表达](#2. 数学表达)
- [3. 优缺点](#3. 优缺点)
- [二、LSTM(Long Short-Term Memory)](#二、LSTM(Long Short-Term Memory))
-
- [1. 引入背景](#1. 引入背景)
- [2. 核心结构](#2. 核心结构)
- [3. 状态更新](#3. 状态更新)
- [4. 优缺点](#4. 优缺点)
- [三、GRU(Gated Recurrent Unit)](#三、GRU(Gated Recurrent Unit))
-
- [1. 概述](#1. 概述)
- [2. 核心公式](#2. 核心公式)
- [3. 特点](#3. 特点)
- 四、对比总结
- 五、结构对比图
- 六、结语
循环神经网络(RNN)、LSTM 与 GRU
一、RNN(Recurrent Neural Network)
1. 基本思想
- RNN 通过在网络中引入"循环"结构,使得当前时刻的输出不仅依赖当前输入,还依赖之前的隐藏状态。
- 适合处理 序列数据,如文本、语音、时间序列预测。
2. 数学表达
- 隐藏层更新:
h t = f ( W x h x t + W h h h t − 1 + b h ) h_t = f(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht=f(Wxhxt+Whhht−1+bh) - 输出层:
y t = g ( W h y h t + b y ) y_t = g(W_{hy}h_t + b_y) yt=g(Whyht+by)
3. 优缺点
- 优点:能够建模序列信息,捕捉上下文依赖。
- 缺点:存在梯度消失和梯度爆炸问题,难以学习长期依赖。
二、LSTM(Long Short-Term Memory)
1. 引入背景
- 针对 RNN 的 长期依赖问题,LSTM 在结构上引入了"门控机制",有效缓解梯度消失问题。
- 在自然语言处理、语音识别、时间序列预测等任务中应用广泛。
2. 核心结构
LSTM 的关键在于 细胞状态(Cell State) 和 三个门(Gates):
-
遗忘门(Forget Gate) :决定丢弃多少历史信息。
f t = σ ( W f x t , h t − 1 + b f ) f_t = \sigma(W_fx_t, h_{t-1} + b_f) ft=σ(Wfxt,ht−1+bf) -
输入门(Input Gate) :决定写入多少新信息。
i t = σ ( W i x t , h t − 1 + b i ) i_t = \sigma(W_ix_t, h_{t-1} + b_i) it=σ(Wixt,ht−1+bi)
C ~ t = tanh ( W c x t , h t − 1 + b c ) \tilde{C}_t = \tanh(W_cx_t, h_{t-1} + b_c) C~t=tanh(Wcxt,ht−1+bc) -
输出门(Output Gate) :决定输出多少细胞状态的信息。
o t = σ ( W o x t , h t − 1 + b o ) o_t = \sigma(W_ox_t, h_{t-1} + b_o) ot=σ(Woxt,ht−1+bo)
3. 状态更新
- 细胞状态:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t = f_t * C_{t-1} + i_t * \tilde{C}_t Ct=ft∗Ct−1+it∗C~t - 隐藏状态:
h t = o t ∗ tanh ( C t ) h_t = o_t * \tanh(C_t) ht=ot∗tanh(Ct)
4. 优缺点
- 优点:能解决长期依赖问题,更好地捕捉长距离信息。
- 缺点:结构复杂,计算量大,训练速度较慢。
三、GRU(Gated Recurrent Unit)
1. 概述
- GRU 是 LSTM 的简化版本,仅包含 更新门(Update Gate) 和 重置门(Reset Gate)。
- 没有独立的细胞状态,直接用隐藏状态传递信息。
2. 核心公式
- 更新门:
z t = σ ( W z x t , h t − 1 ) z_t = \sigma(W_zx_t, h_{t-1}) zt=σ(Wzxt,ht−1) - 重置门:
r t = σ ( W r x t , h t − 1 ) r_t = \sigma(W_rx_t, h_{t-1}) rt=σ(Wrxt,ht−1) - 新隐藏状态:
h ~ t = tanh ( W x t , ( r t ∗ h t − 1 ) ) \tilde{h}_t = \tanh(Wx_t, (r_t \* h_{t-1})) h~t=tanh(Wxt,(rt∗ht−1)) - 最终隐藏状态:
h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ~ t h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t ht=(1−zt)∗ht−1+zt∗h~t
3. 特点
- 结构更简洁,参数更少,训练更快。
- 在很多任务中性能与 LSTM 接近甚至更优。
四、对比总结
| 特性 | RNN | LSTM | GRU |
|---|---|---|---|
| 结构 | 简单,循环层 | 复杂,含门控单元(3门+细胞状态) | 较简洁,仅2门 |
| 长期依赖建模 | 弱 | 强 | 强 |
| 计算复杂度 | 低 | 高 | 中等 |
| 训练速度 | 快 | 慢 | 较快 |
| 典型应用 | 简单序列建模 | 机器翻译、语音识别 | NLP、推荐系统、时序预测 |
五、结构对比图
GRU 反馈 更新门+重置门 隐藏状态 h_t x_t y_t LSTM 反馈 门控 隐藏状态 h_t x_t 细胞状态 C_t y_t RNN 反馈 隐藏状态 h_t x_t y_t
六、结语
- RNN 是序列建模的基础,但受限于梯度消失问题。
- LSTM 通过门控机制成功解决长期依赖,是深度学习里程碑式的模型。
- GRU 在保持效果的同时,计算更高效,是实际工程中的常见选择。
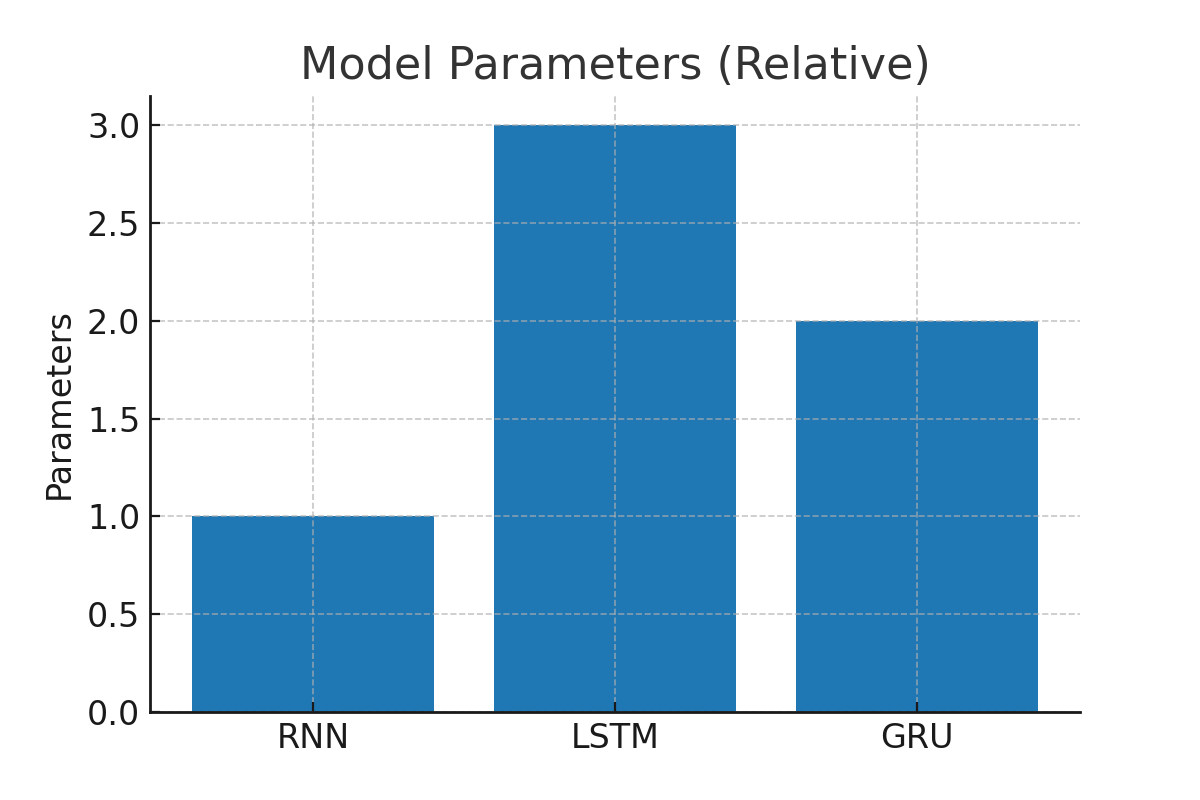
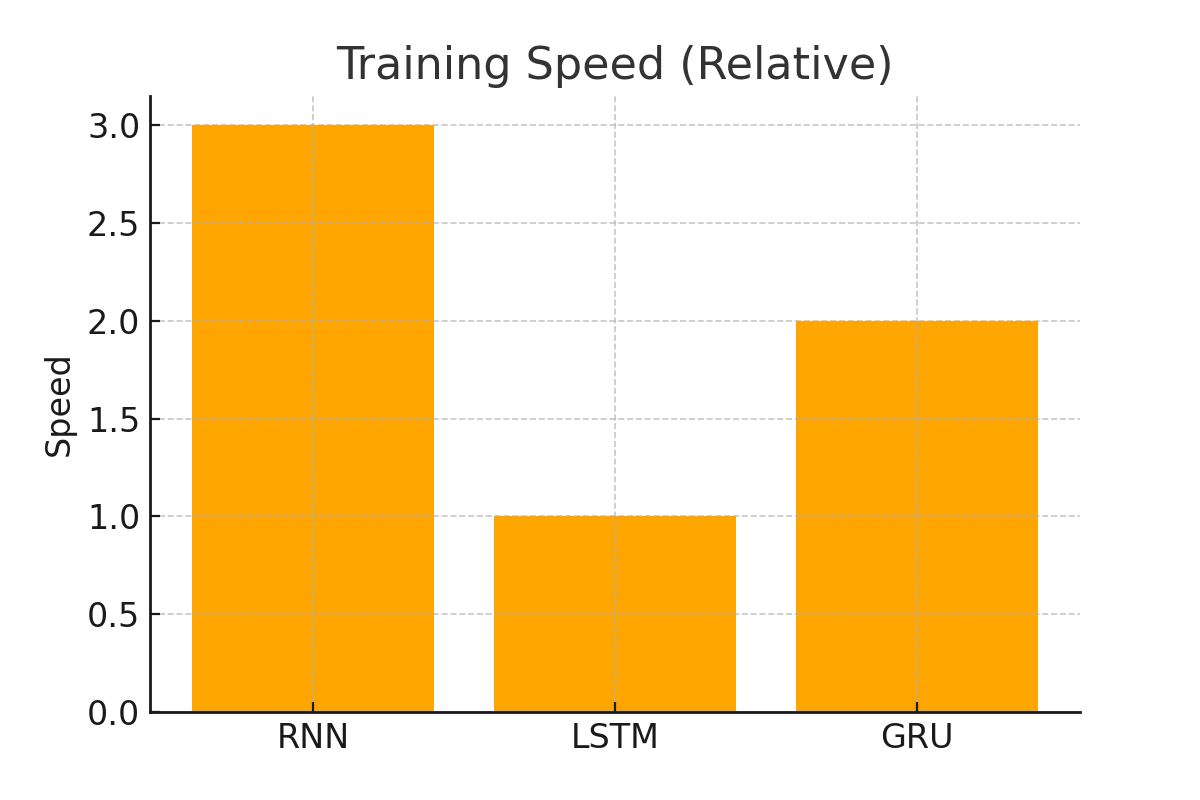
总结一句:
如果序列较短,用 RNN 即可;
如果需要捕捉长期依赖,LSTM 更稳健;
如果追求训练速度和效果平衡,GRU 是不错的选择。