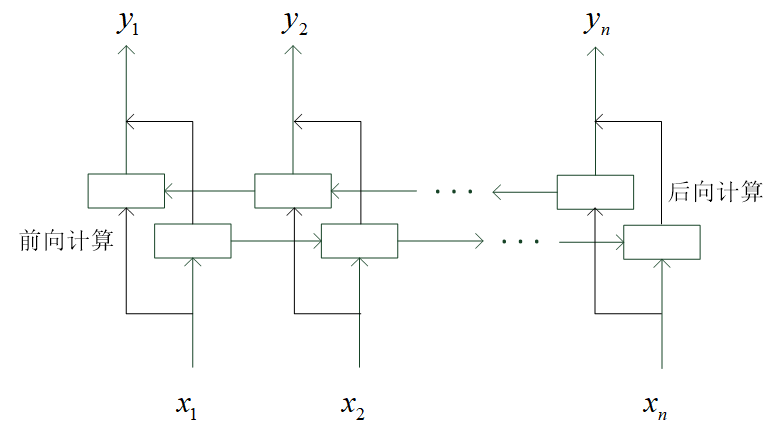
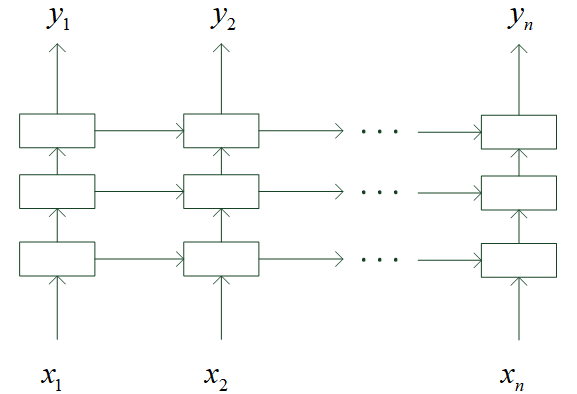
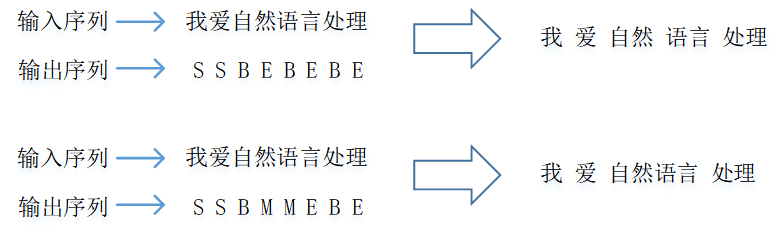
### 训练样本预处理
import numpy as np
file = open("traindata.txt", encoding='utf-8')
test_str = "中国首次火星探测任务天问一号探测器实施近火捕获制动"
new_sents = []
sents_labels = []
for line in file.readlines():
line = line.split()
new_sent = ''
sent_labels = ''
for word in line:
if len(word) == 1:
new_sent += word
sent_labels += 'S'
elif len(word) >= 2:
new_sent += word
sent_labels += 'B' + 'M'*(len(word)-2) + 'E'
if new_sent != '':
new_sents.append([new_sent])
sents_labels.append([sent_labels])
print("训练样本准备完毕!")
print('共有数据 %d 条' % len(new_sents))
print('平均长度:', np.mean([len(d[0]) for d in new_sents]))
输出:训练样本准备完毕!
共有数据 62946 条
平均长度: 8.67100371747212
python复制代码
import torch
import torch.nn as nn
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence
# 参数设置
tags = {'S': 0, 'B': 1, 'M': 2, 'E': 3, 'X': 4} # 标签
embedding_size = 32 # 词向量大小
maxlen = 32 # 序列长度,长则截断,短则填充0
hidden_size = 32
batch_size = 64
epochs = 3
# 1.提取出所有用到的字,形成字典
stat = {}
for i in range(len(new_sents)):
for v in new_sents[i][0]:
stat[v] = stat.get(v, 0) + 1
stat = sorted(stat.items(), key=lambda x:x[1], reverse=True)
vocab = [s[0] for s in stat]
char2id = {c: i+1 for i, c in enumerate(vocab)} # 编号0为填充值,因此从1开始编号
id2char = {i+1: c for i, c in enumerate(vocab)}
print("用到的所有字的个数:", len(vocab))
输出:用到的所有字的个数: 3878
python复制代码
# 2.将训练语句转化为训练样本
trainX = []
trainY = []
for i in range(len(new_sents)):
sent = new_sents[i][0]
labe = sents_labels[i][0]
rep_len = len(sent)
x = [0] * rep_len
y = [4] * rep_len
for j in range(rep_len):
x[j] = char2id[sent[j]]
y[j] = tags[labe[j]]
trainX.append(torch.LongTensor(x))
trainY.append(torch.LongTensor(y))
# 自定义Dataset
class CWSDataset(Dataset):
def __init__(self, X, Y):
self.X = X
self.Y = Y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.Y[idx]
# 创建DataLoader
def collate_fn(batch): # 批加载时填充
X, Y = zip(*batch)
X = pad_sequence(X, batch_first=True, padding_value=0)
Y = pad_sequence(Y, batch_first=True, padding_value=4)
return X, Y
dataset = CWSDataset(trainX, trainY)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
# 3.定义双层双向LSTM模型,训练
class BiLSTM_CWS(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags):
super(BiLSTM_CWS, self).__init__()
self.embedding = nn.Embedding(vocab_size+1, embedding_dim, padding_idx=0)
self.lstm = nn.LSTM(embedding_dim, hidden_dim//2,
num_layers=2,
bidirectional=True,
batch_first=True,
dropout=0.4)
self.fc = nn.Linear(hidden_dim, num_tags)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x)
x = self.fc(x)
return x
# 初始化模型
model = BiLSTM_CWS(len(vocab), embedding_size, hidden_size, len(tags))
# 打印模型详细结构
print("\n模型结构:")
summary(model, input_size=(batch_size, maxlen), dtypes=[torch.long])
# 训练设置
criterion = nn.CrossEntropyLoss(ignore_index=4) # 忽略填充标签
optimizer = torch.optim.Adam(model.parameters())
# 训练循环
for epoch in range(epochs):
total_loss = 0
for batch_X, batch_Y in dataloader:
optimizer.zero_grad()
outputs = model(batch_X)
loss = criterion(outputs.view(-1, len(tags)), batch_Y.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss/len(dataloader):.4f}')
# 保存模型
torch.save(model.state_dict(), 'bi_lstm_cws.pth')
输出:Epoch 1, Loss: 0.8789
Epoch 2, Loss: 0.5091
Epoch 3, Loss: 0.4288
python复制代码
# 4.利用训练好的模型进行分词
def predict(model, testsent):
model.eval()
x = [0] * maxlen
replace_len = min(len(testsent), maxlen)
for j in range(replace_len):
x[j] = char2id.get(testsent[j], 0)
x = torch.LongTensor(x).unsqueeze(0)
with torch.no_grad():
label = model(x)
label = torch.argmax(label, dim=2).squeeze(0)
s = ''
for i in range(min(len(testsent), maxlen)):
tag = label[i].item()
if tag == 0 or tag == 3:
s += testsent[i] + ' '
elif tag == 1 or tag == 2:
s += testsent[i]
print(s)
# 测试预测
predict(model, test_str)