Week 3 -- Memory Hierarchy
学习目标
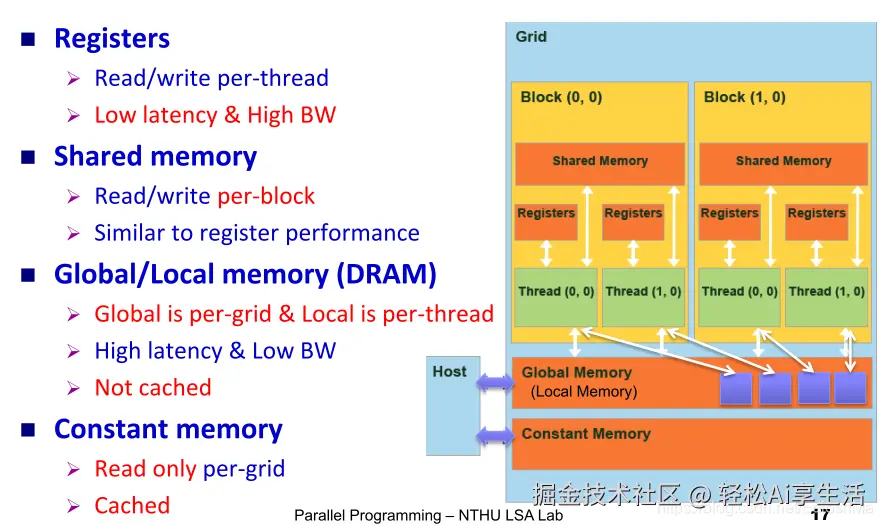
- 理解 CUDA 中的 内存层次结构:Global、Shared、Registers、Constant memory。
- 理解不同内存访问的延迟、带宽差异。
- 掌握
cudaMemcpy及 pageable vs pinned memory 的区别。 - 学会利用 Shared Memory 来减少 Global Memory 访问,提高性能。
- 动手完成:矩阵乘法 → 优化(Shared Memory Tiling)。
Part 1 -- CUDA 内存层次概览
1.1 内存分类
CUDA 程序运行在 GPU 上时,数据存放在不同的存储器中:
| 内存类型 | 特点 |
|---|---|
| Registers | 每个线程独有,速度最快,存放局部变量,延迟 ~1 cycle。 |
| Shared Memory | 每个 Block 内线程共享,速度快(~100× 快于 global),位于 SM 内,延迟 ~100 cycles。 |
| Global Memory | 所有线程可见,容量大(几 GB),但延迟高(~400-600 cycles)。 |
| Constant Memory | 所有线程只读,缓存优化,适合广播小数据。 |
Part 2 -- 内存拷贝与优化
2.1 cudaMemcpy
CUDA 提供 cudaMemcpy 在 Host ↔ Device 间传输数据:
cpp
cudaMemcpy(dst, src, size, cudaMemcpyHostToDevice);
cudaMemcpy(dst, src, size, cudaMemcpyDeviceToHost);2.2 Pageable vs Pinned Memory
- Pageable Memory(普通 malloc) 由 OS 管理,CUDA 需要先复制到临时缓冲区再传输 → 较慢。
- Pinned Memory (固定内存,
cudaHostAlloc) 内存固定在物理地址,DMA 直连 GPU → 传输速度更快。
实验对比:
cpp
float *h_data_pageable = (float*)malloc(N*sizeof(float));
float *h_data_pinned;
cudaHostAlloc((void**)&h_data_pinned, N*sizeof(float), cudaHostAllocDefault);Part 3 -- Hands-on 练习
3.1 矩阵乘法(Naive,使用 Global Memory)

公式:
css
C[i][j] = Σ A[i][k] * B[k][j]CUDA 代码(简化示例):
cpp
__global__ void matMulNaive(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}- 每个元素需要访问 2N 次 Global Memory(A、B 矩阵)。
- 缺点:大量重复访问 Global Memory,带宽浪费,性能低。
3.2 Shared Memory 优化 -- Tiling
核心思想:
- 把大矩阵分成 Tile(小块)。
- 每个 Block 的线程先把 Tile 加载到 Shared Memory。
- 计算时重复利用 Shared Memory,减少 Global Memory 访问。
图解:
css
矩阵 A (N×N) 矩阵 B (N×N)
[Tile1][Tile2] [Tile1][Tile2]
[Tile3][Tile4] [Tile3][Tile4]
→ 线程块先加载 Tile1A 和 Tile1B 到 Shared Memory
→ 在 SM 中完成子块计算
→ 最终合并结果优化后的 CUDA 核心代码:
cpp
#define TILE_SIZE 16
__global__ void matMulTiled(float *A, float *B, float *C, int N) {
__shared__ float sA[TILE_SIZE][TILE_SIZE];
__shared__ float sB[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
for (int t = 0; t < (N + TILE_SIZE - 1)/TILE_SIZE; t++) {
if (row < N && t*TILE_SIZE + threadIdx.x < N)
sA[threadIdx.y][threadIdx.x] = A[row*N + t*TILE_SIZE + threadIdx.x];
else
sA[threadIdx.y][threadIdx.x] = 0.0f;
if (col < N && t*TILE_SIZE + threadIdx.y < N)
sB[threadIdx.y][threadIdx.x] = B[(t*TILE_SIZE + threadIdx.y)*N + col];
else
sB[threadIdx.y][threadIdx.x] = 0.0f;
__syncthreads();
for (int k = 0; k < TILE_SIZE; k++) {
sum += sA[threadIdx.y][k] * sB[k][threadIdx.x];
}
__syncthreads();
}
if (row < N && col < N)
C[row*N + col] = sum;
}性能提升点:
- 减少了重复的 Global Memory 访问。
- 提升 带宽利用率,更接近理论峰值。
Part 4 -- 实验步骤
-
编写
matMulNaive.cu,实现普通矩阵乘法。 -
编写
matMulTiled.cu,实现 Shared Memory 优化版本。 -
使用
nvcc编译:bashnvcc matMulNaive.cu -o naive nvcc matMulTiled.cu -o tiled -
测试运行并对比耗时:
bash./naive ./tiled预期结果:
tiled明显比naive快。
Part 5 -- 思考题
- 为什么 Global Memory 的访问延迟高?(提示:DRAM 结构、带宽限制)
- 为什么 Shared Memory 能加速矩阵乘法?(提示:数据复用)
- 如果 TILE_SIZE 改大或改小,性能会怎样?如何选择合适大小?
- 如何利用 Pinned Memory 加速 Host ↔ Device 的数据传输?
- Registers 在 CUDA 内存层次中的作用是什么?为什么编译器可能会"溢出"到 Local Memory?
📌 总结: 这一周的学习让你掌握了 CUDA 内存体系结构,并通过 矩阵乘法案例 体会到 Shared Memory 的优化威力。下一步可以进一步学习 bank conflict 、constant memory 的优化技巧。
Week 3 -- Memory Hierarchy 中 5 个思考题的标准答案 + 解释
1) 为什么 Global Memory 的访问延迟高?
结论: Global Memory 位于 GPU 芯片外部的显存(如 GDDR),属于高容量、低局部性 的存储层;访问它需要经过片上缓存/互连到外部 DRAM,链路长、协议复杂,因此单次访问延迟高。如果访问模式不连续,还会触发更多内存事务,进一步放大"有效延迟"。
关键原因(逐条解释):
- 物理位置与路径长:Global Memory 在芯片外(DRAM),访问需要跨越片上互联、控制器,再到 DRAM 芯片,链路远、握手多。
- 带宽与事务粒度限制 :DRAM 以固定事务粒度服务请求;一个 warp 的访问若未合并(uncoalesced),会拆成多个事务,等价于更多往返与等待。
- 访问局部性弱:如果线程以大步长/散乱地址访问,同一缓存线难以复用,缓存命中率低,导致频繁访问 DRAM。
- 页表/地址转换与一致性开销:访问要经过地址转换与层级缓存一致性维护,这些都叠加在端到端延迟上。
可控点:
- 让 warp 内 32 个线程尽量顺序且对齐访问(coalescing)。
- 通过 shared memory / 寄存器 提升数据复用,减少去 DRAM 的频次。
2) 为什么 Shared Memory 能加速矩阵乘法?
结论: Shared Memory 位于每个 SM(Streaming Multiprocessor)上,是片上存储,访问延迟远低于 Global Memory。通过 tiling(分块),把将要重复使用的 A、B 子块先从 Global 读入 Shared,再在片上多次复用,显著减少 DRAM 访问次数。
"少访问"的量化对比(核心公式):
- 设 tile 边长为 T ,每个 block 计算一个 T×T 的 C 子块。
- Naive :每个 Ci,j 需要从 Global 读取 2N 个元素(A 的一行 N 次 + B 的一列 N 次)。
- Tiling :每次迭代加载 A 子块(T×T) 和 B 子块(T×T) ,共 2·T² 次 Global 读;这批数据被本 block 内 T² 个输出元素共同复用 : 每次迭代摊到每个输出 只需 2 次 Global 读。总共有 N/T 次迭代,所以每个输出总 Global 读≈ 2·(N/T)。
- 对比节省比例 :从 2N 降到 2·(N/T) ,节省因子≈ T 倍。
额外收益:
- Shared Memory 可按线程组织协同加载两块数据(A 行、B 行/列)并保持局部性 ,更易实现合并访问 Global Memory。
3) TILE_SIZE 变大或变小对性能的影响?如何选择合适大小?
权衡点(一定要同时考虑):
-
数据复用收益
- 越大 T ⇒ 复用倍数越高(≈T 倍节省 Global 访问),有利于性能。
-
资源占用与并发度(occupancy)
- 一个 block 的线程数为 T×T(每线程算一个 C 元素)。
- 共享内存使用量约为
2 * T * T * sizeof(dtype)(A、B 两个 tile)。 - T 过大 ⇒ 单个 block 占用的 Shared Memory / 寄存器 太多 ⇒ 每个 SM 可同时驻留的 block 数下降 ⇒ 并发度下降,可能抵消复用带来的收益。
-
硬件上限约束
- 每 block 最大线程数 (常见上限为 1024) ⇒ 要求
T×T ≤ maxThreadsPerBlock。 - 每 block 最大共享内存 ⇒
2 * T * T * sizeof(dtype)必须小于设备sharedMemPerBlock限制。 - 寄存器压力:过大 T 往往增加每线程寄存器需求,可能触发寄存器溢出(见问题 5)。
- 每 block 最大线程数 (常见上限为 1024) ⇒ 要求
-
访存冲突(Shared Memory bank 冲突)
- Shared Memory 按"bank"并行服务;如果同一 warp 的线程访问映射到同一 bank 且地址不同,会发生冲突,降低吞吐。
- 常见做法:为容易列访问的 tile 维度做 +1 填充 (例如
float sB[TILE_SIZE][TILE_SIZE+1]),降低冲突风险。
-
边界与实现复杂度
- N 与 T 不整除时需要边界判断;T 太大时边界处理负担加重。
实操选择建议:
- 先基于设备属性做可行性筛选(最大线程数、每 block 共享内存等)。
- 在可行范围内,选择能保证至少两个 block/SM 并发 的 T,以兼顾复用 与occupancy。
- 常用起点:
T = 16或T = 32(依数据类型、架构与资源配额而定)。 - 用实际基准(同一输入、同一编译选项)对不同 T 做 A/B 测试,观察吞吐与占用指标,再定型。
4) 如何利用 Pinned Memory 加速 Host ↔ Device 的数据传输?
结论: 使用 Pinned(page-locked)Host 内存 能提升传输带宽,并且是使用 cudaMemcpyAsync 进行异步传输与计算重叠 的前提。做法是:用 cudaHostAlloc / cudaMallocHost 分配主机缓冲区,配合 stream 和 cudaMemcpyAsync 把传输与 kernel 执行流水化。
关键点:
-
为什么更快 :Pinned 内存固定在物理内存中,GPU 的 DMA 引擎可以直接 从这块内存搬运数据;而 pageable 内存(普通
malloc)需要先被驱动复制到临时的 pinned 缓冲区再传输,多了一次拷贝。 -
如何启用异步与重叠:
- 用
cudaHostAlloc/cudaMallocHost分配主机缓冲区; - 创建一个或多个
cudaStream_t; - 使用
cudaMemcpyAsync(..., cudaMemcpyHostToDevice, stream)把 H→D 放入队列; - 在同一 stream 中 launch kernel;
- 再用
cudaMemcpyAsync(..., cudaMemcpyDeviceToHost, stream)回传结果; - 通过
cudaEvent或cudaStreamSynchronize检查完成。
- 用
-
注意事项:
- Pinned 内存受系统资源限制;只为热点、长驻或大批量传输的缓冲区使用,并注意及时释放。
- 重叠需要设备支持"同时拷贝与计算";多数现代 GPU 支持,可通过设备属性确认(
deviceProp.deviceOverlap等)。
5) Registers 的作用是什么?为什么会"溢出"到 Local Memory?
结论: Registers(寄存器)是每线程私有 的片上存储,访问速度最快,用于保存线程的标量临时变量、循环计数等。寄存器数量有限;当编译器判断"寄存器不够放下所有需要的活跃变量"时,会把一部分变量 溢出(spill 到 Local Memory 。注意:Local Memory 名字里有 "local",但它实际位于 Global Memory 空间(只是地址空间上线程私有),因此访问它会像 Global 一样慢。
常见导致溢出的原因:
- 寄存器压力过大:内联函数多、表达式复杂、同时活跃的变量太多。
- 线程私有大数组 或需动态索引的数组:这类对象很难完整映射到寄存器,往往落在 Local Memory。
- 过度循环展开 / 过多临时变量:编译优化导致活跃值激增,超出寄存器预算。
发现与缓解:
-
编译时查看
ptxas报告(如-Xptxas -v)可见寄存器数与 spill 情况(stores/loads)。 -
代码层面:
- 避免过大的 per-thread 数组;能放 shared memory 的放 shared(且考虑 bank 冲突)。
- 简化表达式与变量生存期,减少同时活跃的中间值。
- 使用
__restrict__指针帮助编译器别名分析,减少不必要的内存回写/读回。 - 必要时调整编译参数(如限制最大寄存器数),但要权衡:寄存器太紧也会增加 spill。
-
评估方式:用 Nsight Compute/Systems 或
nvprof/ncu对比有无 spill 的执行时间与访存统计。
小结
- Q1:Global 慢在"外部 DRAM + 不合并访问放大事务数"。
- Q2:Shared 快在"片上 + Tiling 让每次 DRAM 读被复用 T 次"。
- Q3:TILE_SIZE 要在"复用收益 vs 资源占用/并发/冲突/实现复杂度"间折中,实测定型。
- Q4 :Pinned 内存 +
cudaMemcpyAsync+ streams ⇒ 更高带宽 与传输-计算重叠。 - Q5:寄存器最快;溢出到 Local(实为 Global)会变慢;通过减压寄存器与结构化内存使用来避免。
📘 Week 3 -- Memory Hierarchy FAQ
Q1: CUDA 中有哪些主要的内存类型?它们的特点是什么?
答案:
-
Global Memory(全局内存)
- 位于 GPU 的 device memory(显存)。
- 大容量(GB级),但访问延迟高(几百个时钟周期)。
- 所有线程都可以访问。
- 典型用途:存放输入/输出数据。
-
Shared Memory(共享内存)
- 位于 每个 Streaming Multiprocessor (SM) 内部。
- 小容量(通常 48KB 左右),延迟远低于全局内存(几十个时钟周期)。
- 仅同一个线程块(block)内的线程可共享访问。
- 典型用途:缓存常用数据,减少重复的全局内存访问。
-
Registers(寄存器)
- 位于每个 CUDA 核心内部。
- 延迟最低(几乎 1 个时钟周期),访问速度最快。
- 每个线程独享,不能共享。
- 容量有限(通常每个线程几十个寄存器)。
-
Constant Memory(常量内存)
- 只读,容量较小(64KB)。
- 所有线程共享,适合存放不变的常量数据。
- 如果多个线程访问同一个常量,会被缓存优化。
Q2: cudaMemcpy 有哪些模式?pageable 和 pinned 内存的区别是什么?
答案:
-
cudaMemcpy 模式:
cudaMemcpyHostToDevice(H → D):CPU → GPUcudaMemcpyDeviceToHost(D → H):GPU → CPUcudaMemcpyDeviceToDevice(D → D):GPU → GPUcudaMemcpyHostToHost(H → H):CPU → CPU(不常用)
-
Pageable 内存(可分页内存):
- 普通的
malloc分配。 - 系统可能会把它换出到磁盘。
- CUDA 需要 额外复制到临时 pinned buffer 才能传输到 GPU。
- 因此速度较慢。
- 普通的
-
Pinned 内存(页锁定内存):
- 使用
cudaMallocHost()分配。 - 驻留在物理内存,不会被换出。
- GPU 可以直接进行 DMA 传输 → 更快。
- 缺点:过多 pinned 会降低系统整体性能。
- 使用
Q3: 为什么使用 Shared Memory 能减少 Global Memory 访问?
答案:
-
直接从 Global Memory 读取 → 每次访问都有几百个 cycle 延迟。
-
如果多个线程都需要相同数据,会重复读取 → 性能浪费。
-
优化方式:
- 先从 Global Memory 把数据加载到 Shared Memory。
- 同一个 block 的所有线程 共享使用。
- 只需要一次 Global Memory 访问,后续用 Shared Memory 替代。
-
结果:
- 减少了大量冗余的全局访问。
- 提升吞吐量和性能。
Q4: 在矩阵乘法中,如何用 Shared Memory 做 tiling 优化?
答案:
-
Naive 实现 : 每个线程计算一个
C[row][col],需要遍历A的一行和B的一列。- 每次都从 Global Memory 读取数据。
- 重复访问相同元素,效率低。
-
Tiling 优化:
- 将矩阵划分为 tile(小块,例如 16×16)。
- 每个线程块(block)加载一个 tile 的数据到 Shared Memory。
- 所有线程在 Shared Memory 上进行计算。
- 遍历所有 tile,累积结果。
- 最终写回 Global Memory。
-
效果:
- 原来每个线程会多次从 Global Memory 读取同一个数据。
- 现在每个 tile 的数据只需 一次读取,大幅降低全局内存访问。
Q5: Shared Memory 的 Bank Conflict 是什么?如何避免?
答案:
-
概念:
- Shared Memory 由多个 bank 组成(通常 32 个)。
- 每个 bank 每次只能服务一个线程。
- 如果多个线程同时访问同一个 bank 的不同地址,就会冲突(bank conflict)。
- 导致访问串行化,性能下降。
-
避免方法:
-
内存对齐:确保线程索引和内存地址映射合理。
-
Padding:在数组末尾增加填充列,打破冲突模式。
- 例如:把
tile[16][16]改成tile[16][16+1]。
- 例如:把
-
尽量让 线程访问模式连续,避免集中到同一 bank。
-
Q6: 在实际应用中,如何选择不同的内存?
答案:
- Global Memory 存放大规模数据(输入/输出矩阵、图像等)。
- Shared Memory 存放频繁访问的中间结果(如矩阵 tile)。
- Registers 存放局部变量(循环计数器、累加器)。
- Constant Memory 存放不会改变的参数(如卷积核权重)。
原则:
- 优先放寄存器 → Shared Memory → Constant Memory。
- 尽量减少 Global Memory 的直接访问。