【导读】
这篇论文聚焦于计算机视觉目标检测领域中的一个经典难题------小目标检测(Small Object Detection, SOD) ,并以车牌检测这一具体且具有挑战性的任务作为案例进行研究。
多目标检测(MOD)是一种广泛应用,受益于深度学习技术,旨在同时实现边界框回归和准确的目标分类。根据物体的大小,它们可以分为正常大小或小目标。典型应用包括车辆车牌检测和航空目标检测。然而,在 MOD 的背景下,像素覆盖有限的小目标尚未得到充分解决。
本文的贡献总结如下:
- 首先,我们利用 SOD 中的类间空间关系设计了 ICR 损失 。我们提出的损失提供了一个额外的空间规则,为小目标提供了细粒度的监督信号。此外,我们强调 ICR 损失惩罚显示了跨不同模型、数据集和基于 IoU 的损失的潜力。
- 其次,我们创建了一个新的小型车辆多车牌数据集(SVMLP) 。该数据集包含车牌与其对应车辆的一一对应关系。它包括3,000张图像,在不同背景和光照条件下拥有超过10,000个标注。标注保持了高质量和泛化能力,更充分地证明了 ICR 损失惩罚的效率。

论文标题:
Inter-Class Relational Loss for Small Object Detection: A Case Study on License Plates
论文 链接 :
SVMLP 数据集
为解决噪声数据和缺乏不同尺寸车牌的问题,我们提出了一个名为小型车辆多车牌数据集(SVMLP) 的数据集,旨在发现现实世界场景中汽车与其车牌之间的关系。
视频场景涵盖了车牌检测任务在不同城市、道路类型和亮度方面的几个重要特征。选择了中国城市(如深圳、梅州、沈阳和重庆等)以确保车牌的基本设计相似。道路类型包括市区和高速公路。包含 3,000 张图像,分为训练集、验证集和测试集,分别包含 2,400、300 和 300 张图像。每个子集包含相同数量的白天和夜间场景图像。
我们提出的 SVMLP 数据集相较于现有数据集(如 UFPR-ALPR、CRPD 和 LSV-LP*)具有几个关键优势。摘要如表 1 所示。对于 LSV-LP*,仅使用其动态对动态子集进行分析,因此用星号 (*) 标记。首先,SVMLP 平均每张图像包含 2.96 个车牌,鼓励多目标检测。其次,它包含了在绝对和相对尺寸上都是最小的已标注小目标车牌。 此外,SVMLP 数据集在图像分辨率、物体尺度、光照条件(白天和夜晚)以及场景(高速公路、城市道路和乡村道路)方面高度多样化。这种全面的变化非常适合于在真实世界条件下进行鲁棒的训练和评估。

实验
在本节中,进行了广泛的模拟以进行定量分析,证明了所提出的类间损失相较于基于 IoU 的方法的鲁棒性和有效性
- 实验设置
使用四个数据集UFPR-ALPR、CRPD、LSV-LP 和提出的 SVMLP 在各种场景中进行评估。这些公共数据集根据其官方推荐的训练集、验证集和测试集划分进行分区。
- 实验结果
表 2 显示了基于 SVMLP 数据集,提出的 LICR 与各种基线模型(包括基于 YOLO 和基于 DETR 的架构)的性能比较。在所有模型中都观察到一致的改进,特别是在小目标的平均精度(AP)APval 上。
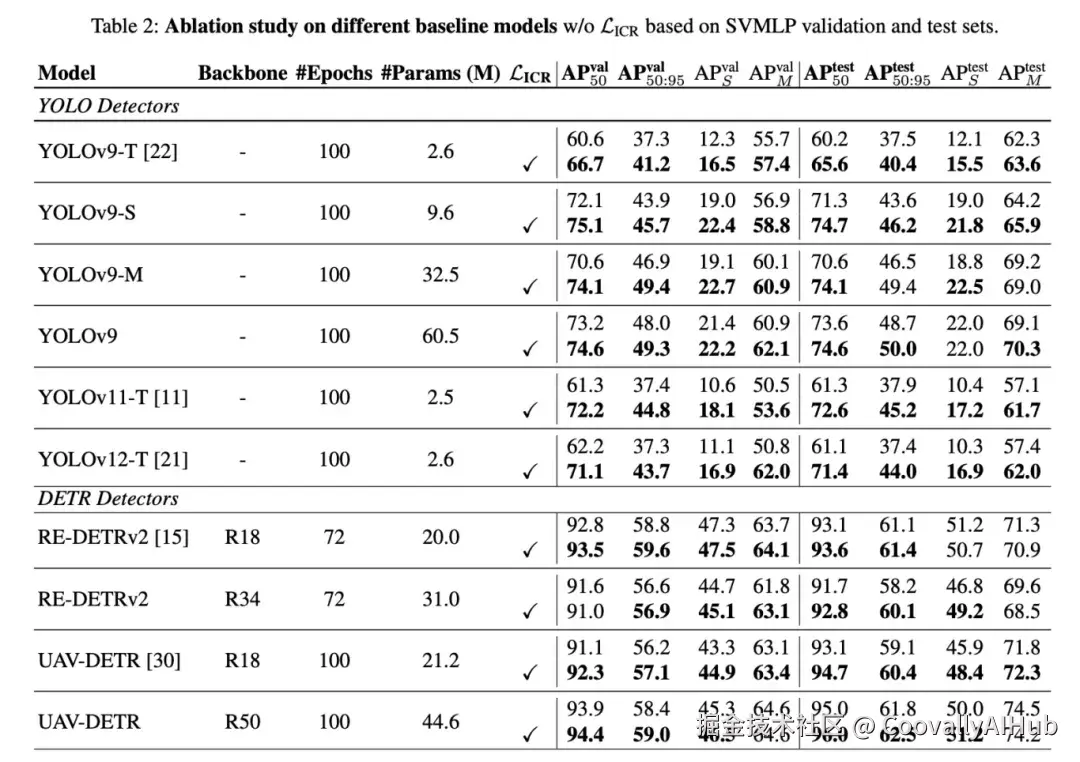
表 3 展示了 LICR-CIoU 在四个数据集上的消融实验结果。基于不同的数据集,在相同的 YOLOV9-T 模型上,LICR 在大多数 AP 和平均召回率(AR)指标上均优于 CIoU 损失。
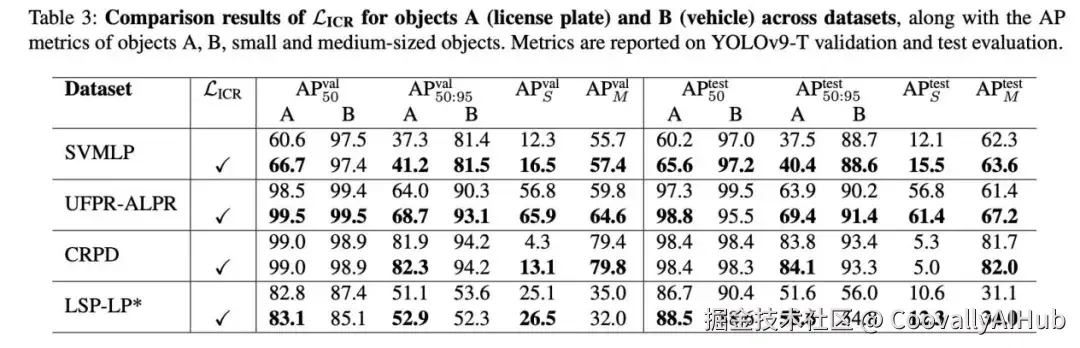
基于上表可以得出三个重要结论:
-
提出的类间损失有效提高了验证集和测试集上的 AP 和 AR,特别是对于小目标。在 UFPR-ALPR 测试集上,我们的方法实现了 AP 1.2% 到 1.5% 的增长,小目标 AP 增加了 4.6%,中等目标 AP 增加了 9.5%;
-
在多类别检测下,物体 B(车辆)的性能保持稳定;
-
当训练数据标注准确时,性能提升最为明显。如果使用的数据集存在显著的标签噪声或脏标注,则改进变得不太稳定,如 CRPD 和 LSV-LP 中所示的性能。
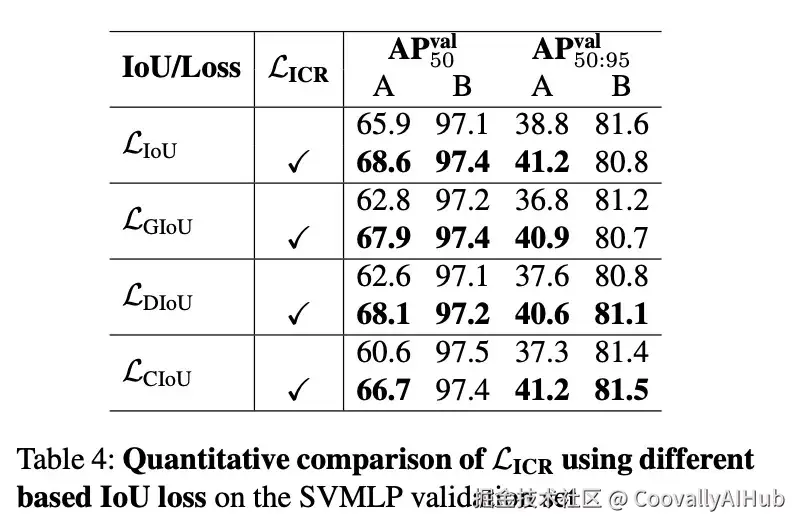
表 4 显示了使用 LICR-IoU、LICR-DIoU 和 LICR-GIoU 训练的模型的定量比较。所提出的 ICR 损失惩罚能够可靠地基于现有的基于 IoU 的损失改进小目标的 AP 指标。例如,LICR-IoU 显著提高了 AP 指标,而没有增加任何模型参数。
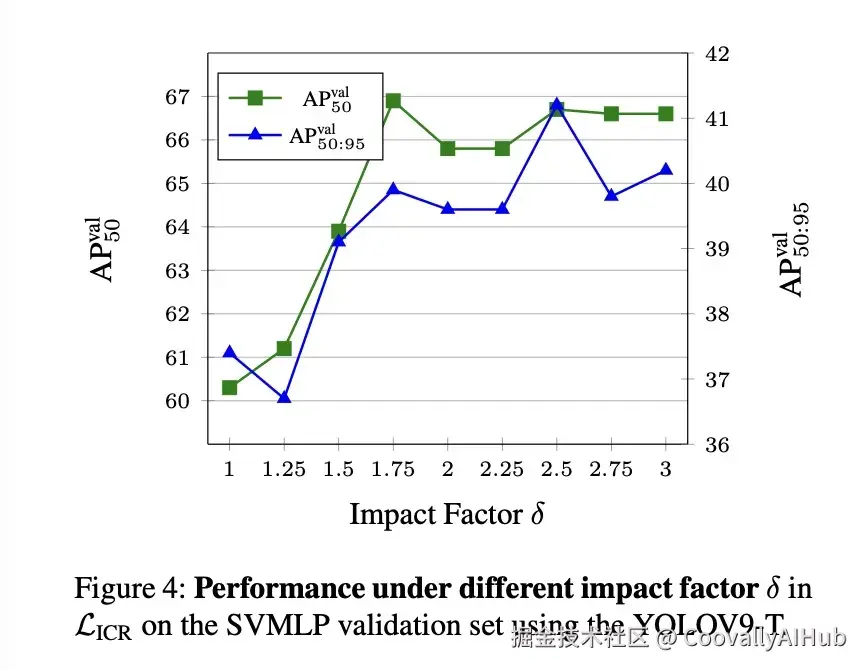
不同的 δ 会影响梯度更新,如图 4 所示。AP 在 1.75 到 3.0 的范围内保持相对稳定,最佳性能在 δ = 2.5 时实现,使得 AP50:95 和 AP50 均提高了约 1%。
- 可视化
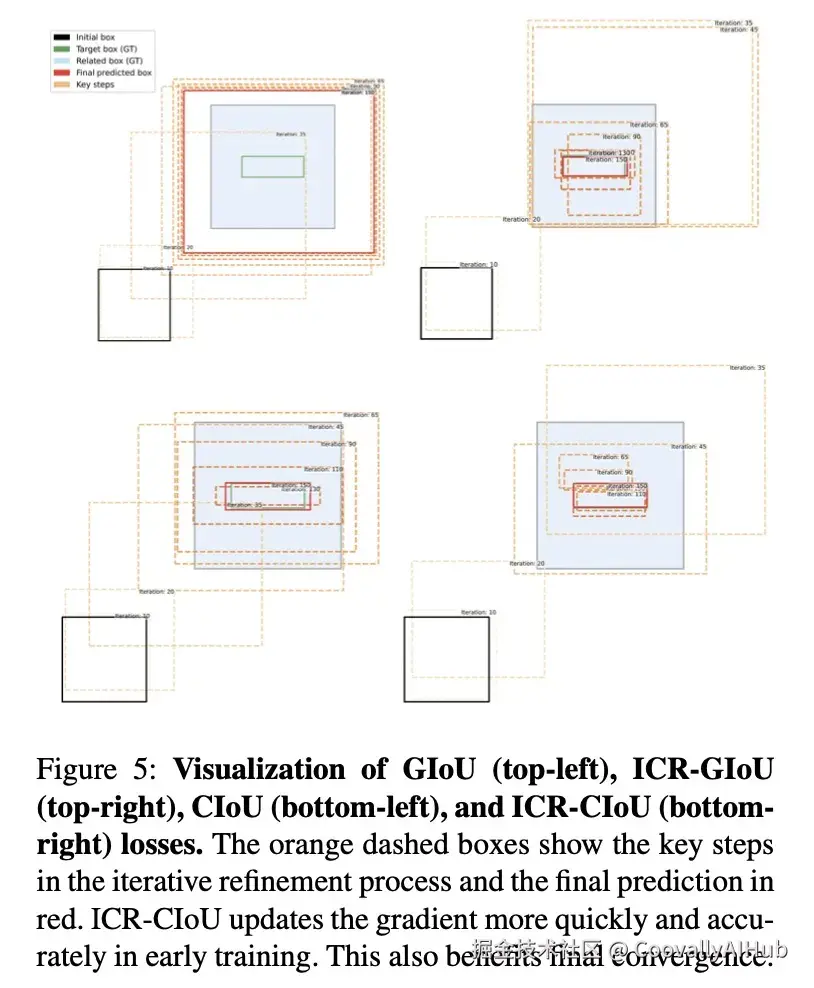
轨迹过程如图 5 所示,CIoU 预测框平滑地接近目标绿色框,然后调整宽度和高度以优化拟合。我们的方法快速调整预测使其进入类间边界框,并在细化目标大小的同时减少了振荡。
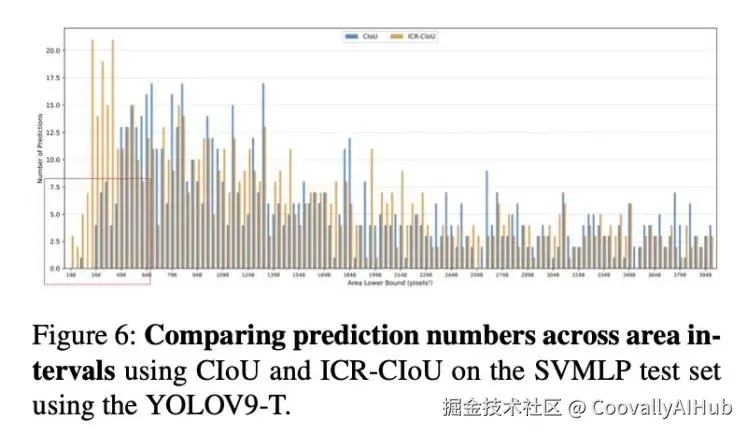
为了证明 ICR 损失惩罚有益于更深层的特征学习,图 6 显示了按物体面积划分的预测边界框分布。我们的方法在面积范围为 198 到 498 的小物体区域显示出显著改进。 检测到的最小面积是 198 像素²,而 CIoU 是 261 像素²。
结论
分析了 MOD 中的 SOD 损失问题,并提出了一种类间损失惩罚,该惩罚适用于所有基于 IoU 的损失。创建了更真实的 SVMLP 数据集并用于评估所提出的解决方案。广泛的模拟结果表明,小类别和大类别之间的空间关系有利于小目标检测,同时不会损害其他物体的学习。 ICR 损失惩罚提供了一种简单、高效的方法来改进模型性能,而无需额外的计算。