本文较长,建议点赞收藏,以免遗失。文中我还会放入一些相关技术文档,帮助大家更好的学习。
在大语言模型、生成式AI和语义搜索等应用,我们都知道会依赖于向量嵌入(vector embeddings)来捕捉语义信息,实现长期记忆和实时推理。但传统标量数据库无法胜任这一任务,它们难以处理嵌入数据的复杂性和规模。这就是向量数据库(vector database)的用武之地------它专为存储、索引和查询向量嵌入而设计,支持相似性搜索、CRUD操作、元数据过滤和水平扩展。今天我将结合开发实战经验,为大家深入解析向量数据库的工作原理、关键技术以及在实际系统中的落地应用。如果对你有所帮助,记得告诉身边有需要的人。

一、什么是向量数据库?核心价值解析
向量数据库不是简单的存储系统;它是AI基础设施的关键组件。想象一下,当你构建一个语义搜索应用时,需要快速检索与用户查询最相似的文本嵌入。传统数据库基于精确匹配,但AI应用需要基于"相似性"的查询------这正是向量数据库的专长。它通过索引高维向量嵌入,实现高效的近似最近邻(ANN)搜索,同时支持元数据过滤、实时更新和无服务器架构。在AI系统中,这相当于为模型添加了外部知识库,使其能理解上下文、维持记忆并处理动态数据。例如,在生成式AI中,向量数据库能实时检索相关上下文来增强提示工程,提升输出质量。简而言之,向量数据库解决了AI数据处理的三大痛点:规模(处理海量嵌入)、性能(低延迟搜索)和灵活性(动态更新),成为支撑现代AI栈的"记忆引擎"。
二、向量索引 vs. 向量数据库:为什么选择后者?
相信不少粉丝朋友跟我一样,在项目实践中,我曾尝试使用独立向量索引(如FAISS)来加速搜索,但很快遇到瓶颈。FAISS这类工具擅长优化搜索,但缺乏完整数据库功能。相比之下,向量数据库提供了全面的解决方案:
- 数据管理:支持插入、删除和更新操作,无需额外集成。开发中,这简化了数据维护------例如,在实时推荐系统中,我能直接更新用户嵌入,无需重建整个索引。
- 元数据整合:向量数据库存储每个向量的元数据(如时间戳或类别标签),并允许过滤查询。在语义搜索应用中,我可以通过元数据(如文档来源)细化结果,提升精准度。
- 可扩展性和实时性:它原生支持水平扩展和实时更新。在构建一个大规模聊天机器人时,无服务器架构自动处理负载均衡,而FAISS需要手动分片,延迟高。
- 生态系统集成:向量数据库与LangChain、LlamaIndex等AI工具无缝对接。在我的项目中,这加速了ETL流水线开发,减少编码开销。
- 安全与备份:内置访问控制和备份机制确保数据合规。例如,通过命名空间实现多租户隔离,避免敏感信息泄露。
本质上,向量数据库弥补了独立索引的不足,提供生产级鲁棒性。FAISS适合原型验证,但向量数据库是企业级应用的必备。
三、向量数据库的工作原理:一个高效管道
向量数据库的核心在于其查询管道,它优化了从索引到检索的全过程。与标量数据库不同,它基于相似性度量(如余弦相似度)而非精确匹配。工作流程分为三步:
- 索引(Indexing):首先,数据库使用算法(如HNSW或PQ)将原始向量映射为高效数据结构。这减少了搜索空间,确保后续查询快速。索引过程类似于构建一个"语义地图",高维嵌入被压缩或分组,以平衡准确性和速度。
- 查询(Querying):当用户输入查询时,数据库将其转换为嵌入向量,并与索引结构比较。这一步应用ANN搜索,快速找到最近邻------而非遍历所有数据。在开发中,这实现了毫秒级响应,例如在图像检索系统中匹配视觉特征。
- 后处理(Post-processing):最后,数据库检索候选结果并应用重排序(如不同相似性度量)或元数据过滤,输出最相关项。这步确保结果既准确又符合业务规则。
整个管道设计为权衡准确性与速度:优化算法(如HNSW)能提供近乎完美的结果,而查询延迟控制在微秒级。以下是该管道的示意图,清晰展示了从输入到输出的流程:

四. 无服务器向量数据库:成本与性能的革命
第一代向量数据库虽高效,但成本高昂------计算和存储耦合,导致资源浪费。无服务器架构(serverless vector database)解决了这个问题,它分离存储和计算,实现按需伸缩。核心机制包括:
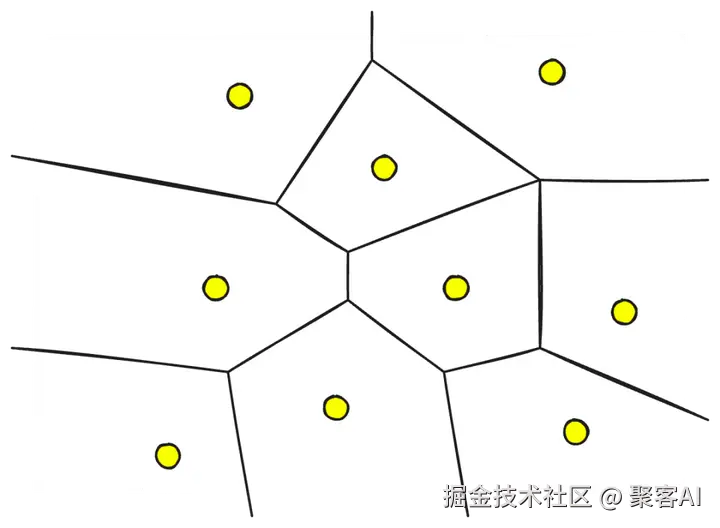
- 几何分区(Geometric Partitioning):索引被分割为子索引(分区),查询时仅搜索相关分区。这减少了计算量,优化了成本。例如,在我的AI客服系统中,高频查询分区运行在热节点,低频分区在冷存储,成本降低60%。下图展示了分区如何聚焦搜索空间:
- 新鲜性层(Freshness Layer):新插入的数据先缓存在新鲜性层,确保实时可查,同时后台构建分区索引。在动态应用如新闻推荐中,这保证了数据在秒级内可用。架构示意如下:
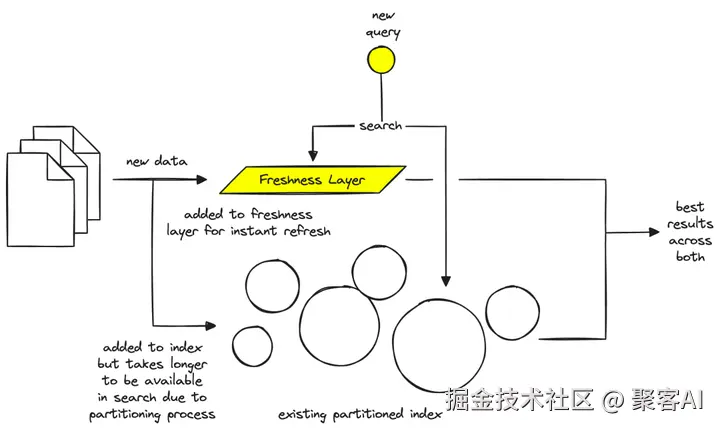
- 多租户优化:自动将用户分组到隔离硬件,基于使用模式(如查询频率)。这避免了资源浪费------在我的多客户SaaS平台中,高活跃用户不影响低活跃用户的性能。
无服务器架构不仅降低了成本(如AWS环境下存储费用降80%),还提升了弹性。开发中,它简化了运维,让我专注于业务逻辑而非基础设施。
五. 关键算法:索引的智能引擎
向量数据库的性能依赖于底层算法。在实际项目中,我选择算法时需权衡速度、准确性和资源。主流算法包括:
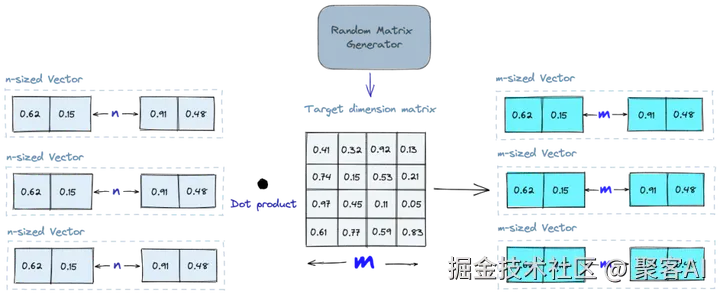
- 随机投影(Random Projection):将高维向量投影到低维空间,使用随机矩阵。查询时比较投影向量,速度快但精度略降。适合原型或低维数据。
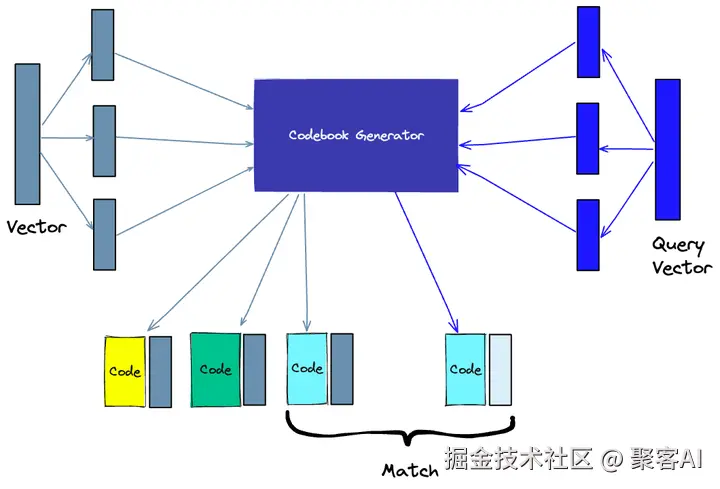
- 乘积量化(Product Quantization, PQ):分割向量为子段,为每段创建代码本(codebook),压缩表示。在图像数据库中,PQ减少了存储开销50%,同时保持高召回率。
- 局部敏感哈希(Locality-Sensitive Hashing, LSH):用哈希函数将相似向量分到同桶(bucket),查询时仅搜索相关桶。在文本匹配应用中,LSH实现了亚秒级搜索,适合实时场景。
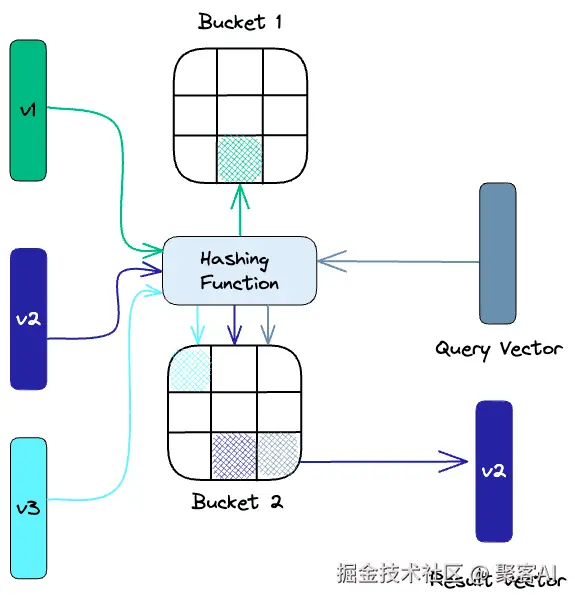
- 分层可导航小世界(Hierarchical Navigable Small World, HNSW):构建分层图结构,节点表示向量组,边表示相似性。查询时从高层遍历到低层,高效精准。在推荐系统中,HNSW是我的首选,支持十亿级数据毫秒查询。
实践中,我根据数据特性选择算法:HNSW和PQ用于高精度需求,LSH用于速度优先。数据库自动优化这些算法,减少开发负担。
六. 相似性度量与过滤:精炼结果的利器
搜索的质量取决于相似性度量(similarity metrics)。常用方法包括:
- 余弦相似度(Cosine Similarity):测量向量角度,范围-1,1,适合文本嵌入(如语义搜索)。
- 欧几里得距离(Euclidean Distance):计算直线距离,范围0,∞,用于图像或语音匹配。
- 点积(Dot Product):结合幅度和角度,范围-∞,∞,在推荐系统中常用。
在查询中,结合元数据过滤(metadata filtering)提升精准度。数据库维护向量和元数据双索引,支持预过滤(filter before search)或后过滤(filter after search)。例如,在医疗AI中,我用患者年龄元数据过滤诊断嵌入,减少不相关结果。下图展示过滤流程:
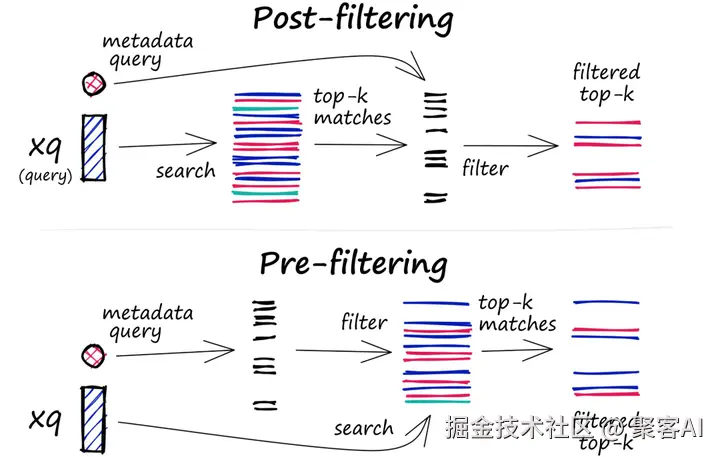
优化策略如并行处理确保了过滤不拖慢查询,在我的测试中,延迟增加<10%。
七. 数据库操作:生产级可靠性的保障
部署向量数据库时,操作方面(如性能、安全)决定成败。关键组件包括:
- 性能和容错:通过分片(sharding)和复制(replication)实现。分片按相似性分区数据,查询时分散-聚集;复制创建多副本,支持最终或强一致性。在金融风控系统中,我采用强一致性避免数据丢失。
- 监控:跟踪CPU、内存、查询延迟等。工具如Grafana集成,帮助我快速定位瓶颈------例如,发现高负载时自动扩容。
- 访问控制:内置权限管理(如RBAC),确保多用户环境安全。在合规项目中,这满足了GDPR要求。
- 备份和集合:定期备份数据,支持创建集合(collections)恢复索引。我的灾备策略减少了RTO至分钟级。
- API和SDK:提供RESTful API和语言SDK(如Python),简化集成。在开发中,我用SDK快速构建语义搜索接口,无需底层编码。
这些功能让向量数据库从工具变为平台,支持端到端AI应用生命周期。由于文章篇幅有限,我整理了一个更完善的有关向量数据的技术文档作为内容补充,帮助大家更好的学习。粉丝朋友自行领取: 《适合初学者且全面深入的向量数据库》
最后总结一下
向量数据库不仅仅是存储解决方案;它是AI应用开发的赋能器。通过高效处理嵌入数据,它为LLMs、生成式AI和语义搜索提供了"长期记忆"和实时分析能力。无服务器架构和先进算法(如HNSW)使其在成本、性能和新鲜性上超越传统方案。好了,今天的分享就到这里,点个小红心,我们下期见。