
【导读】
这是一篇关于如何在无人机视频中高效、准确地追踪鸟类等微小、敏捷、成群目标的技术论文。该方案荣获了MVA 2025"寻找鸟类"小目标多目标追踪挑战赛(SMOT4SB)的冠军,其核心在于系统性地解决了此类任务中最棘手的两个问题:看不清(检测难)和跟不上(关联难)。
目录
随着无人机技术在自主系统领域的普及,其作为空中感知平台的应用范围日益扩大,特别是在生态监测、农业巡查和公共安全等领域。虽然无人机为广域场景捕捉提供了前所未有的灵活视角,但同时也对计算机视觉算法提出了严峻挑战。在这些应用中,对视频序列中多个小型运动目标的持续定位与身份维持(即小目标多目标追踪SMOT)成为尤为关键且艰巨的基础任务。无人机视角下的SMOT任务(尤其是追踪鸟类等敏捷生物时)远比传统多目标追踪(MOT)场景复杂,这种复杂性源自三个核心挑战的相互作用:
-
外观信息极端匮乏
-
复杂运动纠缠
-
密集群聚动态
本文介绍了针对该挑战赛的冠军解决方案。作者认为要攻克该问题,必须构建能协同解决检测与关联双重瓶颈的框架。为此,提出了一个高效的检测追踪系统,其核心贡献体现在两个精准应对前述挑战的方面:
-
针对信息稀缺的检测器优化
-
应对复杂动态的鲁棒追踪器
该方法在SMOT4SB数据集上实现了最先进的性能,公开测试集的SO-HOTA分数达到55.205,验证了本框架在解决复杂现实SMOT任务时的先进性与有效性。

论文标题:
YOLOv8-SMOT: An Efficient and Robust Framework for Real-Time Small Object Tracking via Slice-Assisted Training and Adaptive Association
论文 链接 :
https://arxiv.org/pdf/2507.12087
源代码 :
一、方法
追踪框架采用检测追踪范式设计,将检测与追踪匹配过程解耦。该范式分别优化检测器与追踪器,以构建近乎最优的MOT模型。
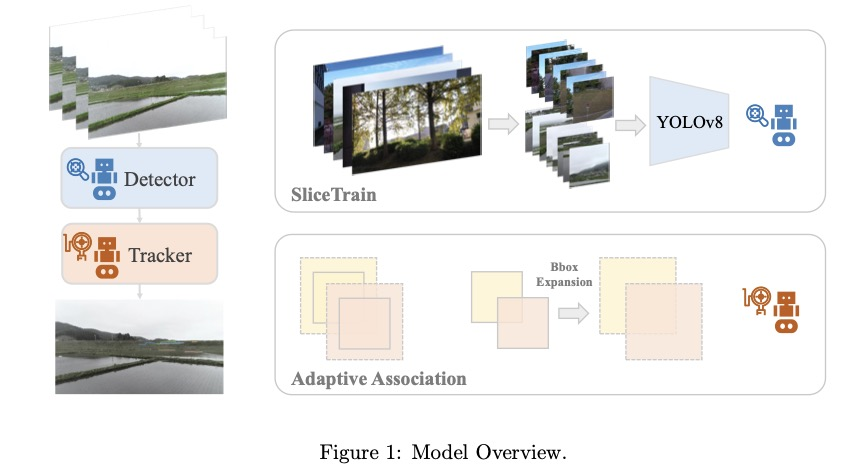
检测器
检测模块基于强大的YOLOv8模型 ,其性能飞跃主要归功于设计的SliceTrain框架。该框架在训练前对数据进行预处理,其核心机制分为两个关键步骤:先通过高质量微调增强模型对微小细节的感知能力,再对原始全尺寸图像进行高效推理。
值得一提的是,对于希望复现或进一步探索此类模型的研究者,可以借助如Coovally这样的高效AI开发平台,**Coovally不仅提供了丰富的开源数据资源和算法组件,更在开发体验和训练效率上进行了全面优化。**研究者可以在平台上使用自己熟悉的开发工具(如 VS Code、Cursor 等),通过 SSH 协议直连云端算力,享受如同本地一样的实时开发与调试体验,同时调用高性能 GPU 环境,极大地加速了实验迭代与模型训练进程。

追踪器
提出的追踪器是对观测中心化SORT(OC-SORT) 框架的增强,并融合了ByteTrack思想。当目标物体过小时外观特征往往不可靠,这些框架实现了无需外观特征的匹配。
首先简要概述OC-SORT的基础概念:该框架通过采用优先考虑检测器观测而非模型预测的多阶段策略(特别是在挑战性场景下),改进了传统追踪器。
尽管OC-SORT假设追踪目标在时间间隔内具有恒定速度(称为线性运动假设),但如图2所示,**76.2%的标注鸟类实例速度变化不超过前一帧的±20%,64.2%不超过前4帧。**更多结果见表1。因此可以认为大多数鸟类运动满足线性运动假设,OC-SORT是该MOT任务的合理选择。

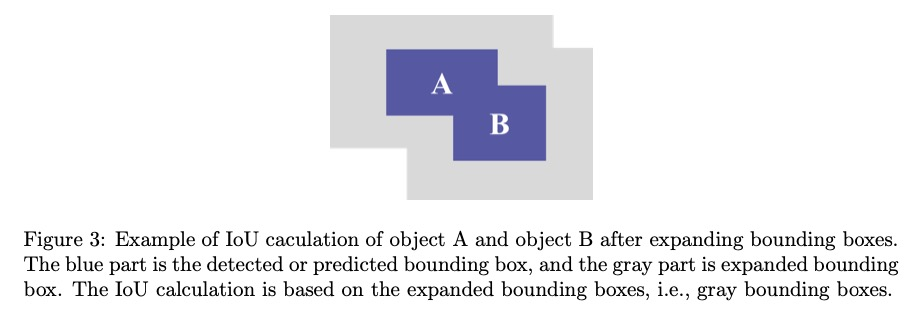
OC-SORT默认相似度度量是IoU,当两个边界框不相交时该度量失效,而这种情况在小目标上经常发生。小目标的这种特性使得追踪过程中的匹配变得困难。但建议利用该特性:考虑到物体较小,重叠和大位移的可能性比某些MOT任务相对更低。基于该假设,在计算IoU前扩展边界框尺寸来模拟普通物体匹配任务。边界框扩展的主要思想如图3所示。
二、实验
数据集与评估指标
- 数据集
所有实验均在SMOT4SB 数据集上进行,该数据集中的目标多为运动模式不规则的小型物体。SMOT4SB由无人机拍摄视频构成,包含128段训练序列、38段验证序列和45段测试序列。与普通MOT数据集相比,其挑战性体现在:1) 目标运动不规则;2) 相机突发性大幅运动;3) 小目标外观信息有限。
- 评估指标
采用官方基于HOTA指标改进的SO-HOTA 系列 指标(SO-HOTA、SO-DetA、SO-AssA)。SO-HOTA引入点距(DotD)进行相似性评分,通过精确的点状目标表征进行比较。
实现细节
- 检测器
YOLOv8-SOD检测器基于三种尺寸(L/M/S)的YOLOv8构建。训练采用SliceTrain策略:将原始高分辨率训练图像(如2160×3840)按20%重叠率切片为1280×1280子图像。该策略使得单张Nvidia RTX 3090 GPU上的训练批量从全图时的1提升至切片后的6。所有模型均在训练集上训练,推理时直接处理原始全尺寸图像以确保效率与全局上下文保留。
- 追踪器
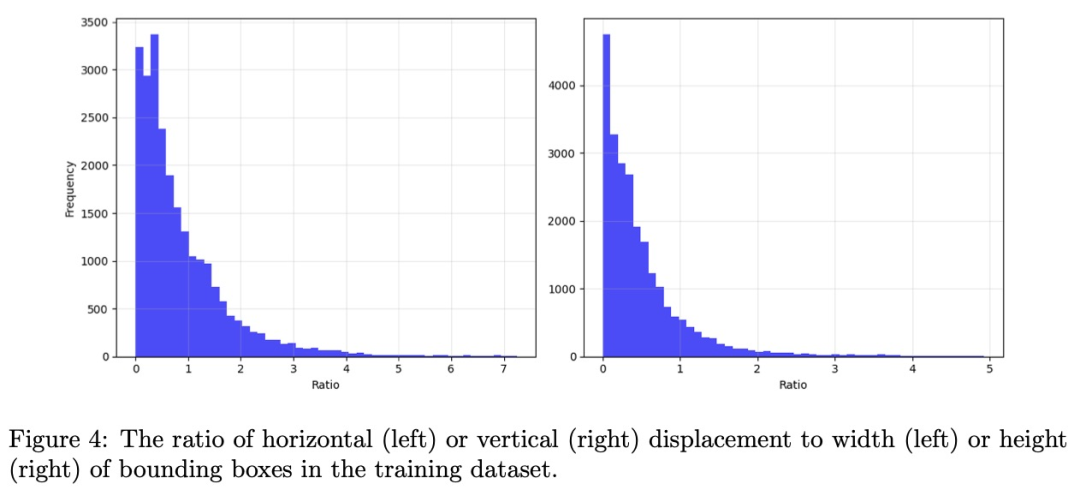
通过网格搜索确定匹配阶段的IoU阈值及其衰减超参数最优值:主匹配阶段IoU阈值为0.25,第二/三阶段递减0.08;根据训练集检测结果分析,轨迹置信度阈值设为0.25;通过交叉验证设定EMA系数α=0.8。边界框扩展比例简化为2倍,依据实证观察:当位移小于边界框短边30%时视为相对静止,多数目标边界框的帧间位移不超过其宽高的2倍(统计示意图见图4)。
基准评测
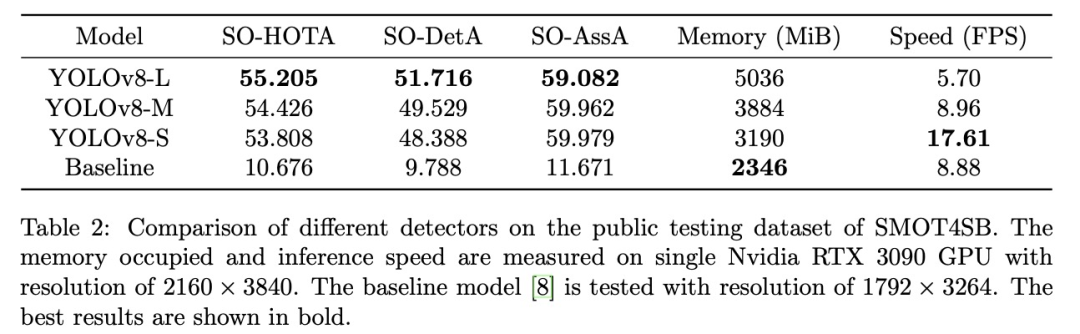
在公开测试集上的实验结果如表2所示。不同尺寸YOLOv8检测器的对比表明:最大模型YOLOv8-L以 55.205 的 SO-HOTA 得分达到最高精度,但速度最低(5.70 FPS);最小模型 YOLOv8-S 将推理速度提升近3倍至 17.61 FPS,内存占用显著降低,而SO-HOTA仅下降1.397,适合准实时应用。
通过模型量化可进一步提升效率:采用GPLQ等量化感知训练(QAT)方法,或QwT、QwT-v2等训练后量化(PTQ)技术,能在保持实时性的同时将框架部署至低功耗边缘设备。
消融实验
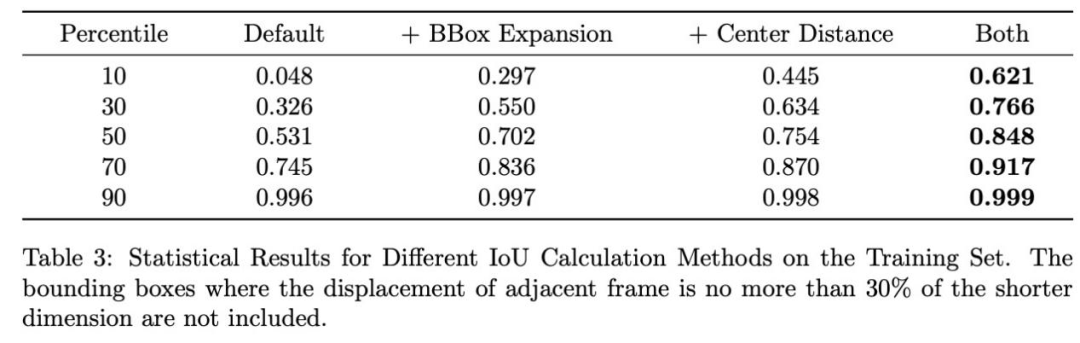
为验证改进有效性,针对小目标追踪的核心挑战------标准IoU度量在微小位移下的失效问题进行了统计分析。筛选训练集中帧间位移小于边界框短边30%的真实框对(代表稳定但IoU难以处理的场景),结果如表3所示:默认IoU在第10百分位数仅得0.048,而结合边界框扩展与中心距离惩罚的方法将该值提升至 0.621,中位数达0.848,证明新度量在IoU失效场景下具有显著鲁棒性。
如表4所示,从基线SO-HOTA 44.200出发:引入EMA运动稳定机制后提升至47.916;分两步添加增强相似度度量------边界框扩展使SO-HOTA升至51.387,距离惩罚带来最大增益,最终达55.205。这证实了针对低位移场景设计的相似度信号可直接转化为更优的追踪精度。

结论
本文提出的YOLOv8-SMOT是MVA 2025 SMOT4SB无人机小目标追踪挑战的冠军方案。该检测追踪框架具有两项核心创新:1) 面向小目标检测的SliceTrain训练框架;2) 融合运动方向保持与自适应相似度度量的无外观鲁棒追踪器。55.205的SO-HOTA得分验证了其先进性,但依赖运动启发式规则在极端运动或长期遮挡时仍存在局限。未来工作可探索更高级的动态模型或微特征提取技术。本研究希望为SMOT领域提供坚实的基线参考与方法启示。
