大模型入门实战 | 基于 YOLO 数据集微调 Qwen2.5-VL-3B-Instruct 的目标检测任务
这篇就是新手向的"保姆级"实操文。你将把 YOLO 检测数据 转成 对话式 Grounding 数据 ,用 ms-swift 做 LoRA 微调 ,再用脚本 推理 + 可视化 。
但值得注意的是,一般的检测任务不推荐这么用 哈,这仅仅是给大家学习使用,切勿"大炮打蚊子"。

0. Grounding 是什么?
Grounding(定位 / 指向) :给一张图 + 一段文字指令(如"找出 dog,并输出框"),模型用语言理解 来完成检测式定位 ,并把结果以JSON 形式吐出来。
区别于传统检测器(YOLO 等)只在固定类上训练,Grounding 可以用自然语言描述做更开放的目标定位。

1. 环境准备(一次性)
Python & CUDA
- Python ≥ 3.9(3.10/3.11 更佳)
- 已装好 PyTorch GPU 版本(
torch.cuda.is_available()为 True)
安装依赖
bash
pip install "transformers>=4.43" accelerate peft pillow pyyaml
pip install ms-swift # 微调工具
# 可选(内存更省、速度更快;没装也能训练):
# pip install flash-attn --no-build-isolation模型权重
- 基座:
models/Qwen2.5-VL-3B-Instruct(本地或 huggingface 路径) - 也可用 AWQ 量化版:
Qwen/Qwen2.5-VL-3B-Instruct-AWQ(更省显存)
2. 数据准备:把 YOLO 数据变成"对话式 Grounding"JSONL
我们希望每一行样本长这样(ms-swift 能直接吃):
json
{
"images": ["images/train/0001.jpg"],
"messages": [
{"role":"user", "content":"<image>\n请在图中定位 camera,并以JSON返回 bbox_2d。只输出JSON。"},
{"role":"assistant", "content":"{\"bbox_2d\":[x1,y1,x2,y2]}"}
]
}2.1 你的 YOLO 数据结构(典型)
json
root/
data.yaml # 里边有 names: ["classA","classB",...]
images/train/*.jpg|png
images/val/*.jpg|png
labels/train/*.txt # 每行: cls cx cy w h(归一化)
labels/val/*.txt2.2 转换脚本
将下面脚本存为 yolo2_ms_swift.py:
-
支持两种模式:
per-class(默认):每图每类产出一条样本,问"只找这一类"all:每图一条样本,让模型"找出所有目标"
-
选项:
--include_negatives:per-class下该类不出现 也产出,标成{"bbox_2d":[]}(非常有助于减少"幻觉输出")--lang zh/en:提示语中英文--image_path_prefix:把images字段写成带前缀的绝对路径(NFS/共享盘常用)
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
把 YOLO 检测数据集转成 ms-swift 可微调用的标准格式(JSONL):
每行形如:
{
"images": ["images/train/0001.jpg"],
"messages": [
{"role":"user", "content":"<image>\n请在图中定位 camera,并以JSON返回 bbox_2d。只输出JSON。"},
{"role":"assistant", "content":"{\"bbox_2d\":[x1,y1,x2,y2]}"} # 多框 -> {"bbox_2d":[[...],[...]]}
]
}
输入(典型 YOLO):
root/
data.yaml # names: [...]
images/train/*.jpg|png
images/val/*.jpg|png
labels/train/*.txt # YOLO: cls cx cy w h (归一化)
labels/val/*.txt
支持两种生成模式:
- per-class(默认):每张图、每个类别一条样本(只让模型找该类,答案只给该类的框)
- all:每张图一条样本(不区分类,返回所有框)
可选:
- --include_negatives:per-class 时,即使该类不在图中也产出(bbox_2d = [])
- --image_path_prefix:把 image 字段写成绝对(NFS)前缀
- --lang zh/en:提示语语言
"""
import argparse, json
from pathlib import Path
from typing import List, Tuple, Dict, Any, Optional
from PIL import Image
import yaml
def load_class_names(p: Path) -> List[str]:
meta = yaml.safe_load(p.read_text(encoding="utf-8"))
names = meta.get("names") or meta.get("class_names")
assert isinstance(names, list) and len(names) > 0, "data.yaml 里需要 names 列表"
return [str(x) for x in names]
def yolo_line_to_xyxy(line: str, W: int, H: int) -> Optional[Tuple[int, List[int]]]:
ps = line.strip().split()
if len(ps) != 5: return None
try:
cid = int(float(ps[0])); cx, cy, w, h = map(float, ps[1:])
except: return None
bw, bh = w*W, h*H
x1 = int(round(cx*W - bw/2)); y1 = int(round(cy*H - bh/2))
x2 = int(round(cx*W + bw/2)); y2 = int(round(cy*H + bh/2))
x1 = max(0, min(x1, W-1)); y1 = max(0, min(y1, H-1))
x2 = max(0, min(x2, W-1)); y2 = max(0, min(y2, H-1))
if x2 <= x1 or y2 <= y1: return None
return cid, [x1,y1,x2,y2]
def iter_image_label_pairs_from_yaml(root: Path, split: str, yaml_path: Path):
cfg = yaml.safe_load(yaml_path.read_text())
img_dirs = cfg.get(split)
if not img_dirs:
return []
if isinstance(img_dirs, str):
img_dirs = [img_dirs]
pairs = []
exts = {".jpg",".jpeg",".png",".bmp",".webp"}
for d in img_dirs:
d = Path(d)
for p in d.rglob("*"):
if p.suffix.lower() in exts:
# 找对应 label
rel = p.relative_to(d)
lbl_dir = Path(str(d).replace("images", "labels"))
lbl_path = (lbl_dir/rel).with_suffix(".txt")
pairs.append((p, lbl_path))
return pairs
def zh_user_prompt_one(label_name: str) -> str:
return f"<image>\n请在图中定位 {label_name},并以JSON返回 bbox_2d。只输出JSON。"
def en_user_prompt_one(label_name: str) -> str:
return f"<image>\nLocate {label_name} in this image and return bbox_2d as JSON. Output JSON only."
def zh_user_prompt_all() -> str:
return "<image>\n请在图中定位所有目标,并以JSON返回 bbox_2d。只输出JSON。"
def en_user_prompt_all() -> str:
return "<image>\nLocate all objects and return bbox_2d as JSON. Output JSON only."
def gpt_value_from_boxes(boxes: List[List[int]]) -> str:
# 紧凑 JSON(不缩进,减少训练时token)
if len(boxes) == 1:
return json.dumps({"bbox_2d": boxes[0]}, ensure_ascii=False)
else:
return json.dumps({"bbox_2d": boxes}, ensure_ascii=False)
def main():
ap = argparse.ArgumentParser("YOLO -> ms-swift JSONL")
ap.add_argument("--root", required=True, help="YOLO 数据集根目录")
ap.add_argument("--split", required=True, choices=["train","val","test"])
ap.add_argument("--out", required=True, help="输出 JSONL 路径")
ap.add_argument("--mode", default="per-class", choices=["per-class","all"])
ap.add_argument("--include_negatives", action="store_true", help="per-class 下也产出缺类样本(bbox_2d=[])")
ap.add_argument("--lang", default="zh", choices=["zh","en"])
ap.add_argument("--image_path_prefix", default="", help="把 image 字段写成带此前缀的路径(绝对/NFS)")
args = ap.parse_args()
root = Path(args.root).resolve()
names = load_class_names(root/"data.yaml")
pairs = iter_image_label_pairs_from_yaml(root, args.split, root/"data.yaml")
if not pairs:
raise SystemExit(f"没有找到图片:{root}/images/{args.split}")
outp = Path(args.out); outp.parent.mkdir(parents=True, exist_ok=True)
if args.lang == "zh":
prompt_one = zh_user_prompt_one
prompt_all = zh_user_prompt_all
else:
prompt_one = en_user_prompt_one
prompt_all = en_user_prompt_all
n = 0
with outp.open("w", encoding="utf-8") as fout:
for img_path, lbl_path in pairs:
# 读尺寸
try:
with Image.open(img_path) as im: W,H = im.size
except: continue
# 解析标签
cls2boxes: Dict[int, List[List[int]]] = {}
if lbl_path.exists():
for line in lbl_path.read_text(encoding="utf-8").splitlines():
r = yolo_line_to_xyxy(line, W, H)
if not r: continue
cid, box = r
cls2boxes.setdefault(cid, []).append(box)
# image 字段:相对 root 或带 prefix 的绝对路径
if args.image_path_prefix:
try:
image_field = str((Path(args.image_path_prefix)/img_path.relative_to(root)).resolve())
except Exception:
image_field = str((Path(args.image_path_prefix)/img_path.name).resolve())
else:
image_field = str(img_path.relative_to(root))
if args.mode == "per-class":
for cid, cname in enumerate(names):
boxes = cls2boxes.get(cid, [])
if not boxes and not args.include_negatives:
continue
user = prompt_one(cname)
asst = gpt_value_from_boxes(boxes)
rec = {"images":[image_field],
"messages":[{"role":"user","content":user},
{"role":"assistant","content":asst}]}
fout.write(json.dumps(rec, ensure_ascii=False)+"\n"); n += 1
else: # all
all_boxes: List[List[int]] = []
for b in cls2boxes.values(): all_boxes.extend(b)
user = prompt_all()
asst = gpt_value_from_boxes(all_boxes)
rec = {"images":[image_field],
"messages":[{"role":"user","content":user},
{"role":"assistant","content":asst}]}
fout.write(json.dumps(rec, ensure_ascii=False)+"\n"); n += 1
print(f"Done. wrote {n} samples -> {outp}")
if __name__ == "__main__":
main()2.3 一键生成 JSONL
bash
# 例:转训练集(每图每类一条)
python yolo2_ms_swift.py \
--root /home/q/nfs_share/datasets/your_yolo_dataset \
--split train \
--out /home/q/nfs_share/datasets/your_yolo_dataset/train_ms.jsonl \
--mode per-class \
--lang zh \
--image_path_prefix /home/q/nfs_share/datasets/your_yolo_dataset
# 转验证集
python yolo2_ms_swift.py \
--root /home/q/nfs_share/datasets/your_yolo_dataset \
--split val \
--out /home/q/nfs_share/datasets/your_yolo_dataset/val_ms.jsonl \
--mode per-class \
--lang zh我这个数据集是检测的 狗 ,所以我只有一类 dog
单类数据同样可用 :names: ["camera"] 时,每张图就会得到"找 dog"的样本;多实例会自动写成 {"bbox_2d":[[...],[...]]}。
样例
json
{"images": ["/home/q/.../images/07_alldatasets/202506291136004523.jpg"],
"messages": [
{"role": "user", "content": "<image>\n请在图中定位 dog,并以JSON返回 bbox_2d。只输出JSON。"},
{"role": "assistant", "content": "{\"bbox_2d\": [2738, 522, 2844, 616]}"}]}3. 开始微调:用 ms-swift 做 LoRA
多卡训练用环境变量控制可见 GPU,梯度累积可以在小 batch 下堆出更大的有效 batch。
命令行
bash
CUDA_VISIBLE_DEVICES=1,2,3,4,5,6 swift sft \
--model models/Qwen2.5-VL-3B-Instruct \
--dataset train_ms.jsonl \
--val_dataset val_ms.jsonl \
--output_dir qwen25vl_camera_lora \
--lora_rank 16 \
--lora_alpha 32 \
--lora_dropout 0.05 \
--learning_rate 1e-4 \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 2 \
--logging_steps 20 \
--save_steps 500 \
--eval_strategy steps \
--eval_steps 500 \
--bf16 true \
--gradient_checkpointing true \
--max_length 4096 \
--max_pixels 921600 \
--truncation_strategy delete关键参数怎么调?
-
--lora_rank/alpha/dropout:LoRA 容量与正则,16/32/0.05是不错的起点。 -
--per_device_train_batch_size+--gradient_accumulation_steps:- 有效 batch ≈
batch_size × 累积步数 × GPU数
- 有效 batch ≈
-
--bf16 true+--gradient_checkpointing true:省显存。 -
--max_pixels:强相关显存(图像 token 数),小显存就把它调低(如 512×512 ≈ 262k pixels)。 -
--eval_strategy steps / --save_steps:定期评估与保存。
日志长这样
{"loss": 0.9062, "token_acc": 0.7087, "memory(GiB)": 46.95, "global_step/max_steps": "20/3669", ...}
...
{"eval_loss": 0.6329, "eval_token_acc": 0.7492, "epoch": 3.0, "global_step/max_steps": "3669/3669", ...}
{"train_loss": 0.5660, "train_steps_per_second": 0.072, "epoch": 3.0, ...}-
token_acc :生成时"下一个 token 预测正确"的比例,能反映模型是否学会按格式输出 JSON(但它不是检测 IoU 指标,下文会讲怎么评估 IoU)。
-
训练结束时 ms-swift 会告诉你:
best_model_checkpoint(最优)last_model_checkpoint(最后)
4. 推理:让模型按你的"文字指令"输出 JSON 框
把下面脚本存成 qwen_vl_grounding_infer.py 直接跑:
python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info # 来自 Qwen-VL 项目
# 1) 加载基座(或加载 AWQ 量化版)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"models/Qwen2.5-VL-3B-Instruct",
torch_dtype="auto",
device_map="auto",
# attn_implementation="flash_attention_2", # 若已安装 flash-attn 再开启
)
# 2) Processor(可用 min/max_pixels 控制视觉 token 开支)
processor = AutoProcessor.from_pretrained("models/Qwen2.5-VL-3B-Instruct")
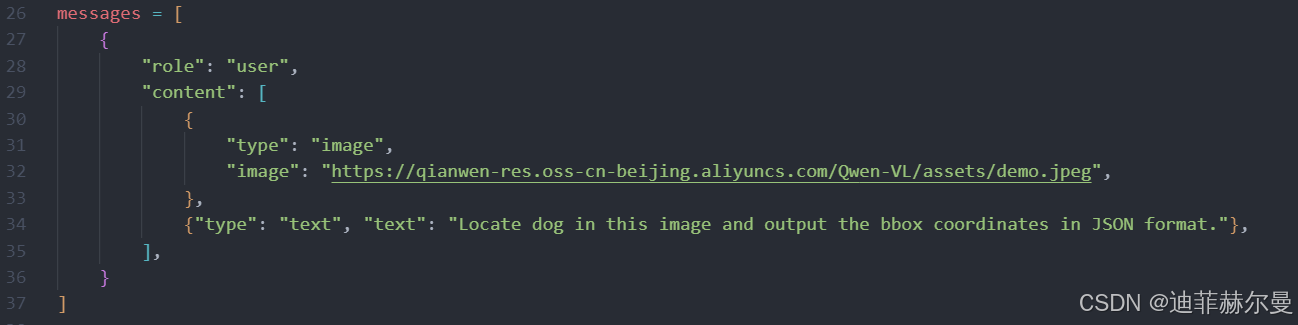
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"type": "text", "text": "Locate dog in this image and output the bbox coordinates in JSON format."}
]}]
# 3) 组批 & 上卡
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs,
padding=True, return_tensors="pt").to("cuda")
# 4) 生成
out_ids = model.generate(**inputs, max_new_tokens=128)
trimmed = [o[len(i):] for i, o in zip(inputs.input_ids, out_ids)]
print(processor.batch_decode(trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False))预期输出

['json\n[\n\t{"bbox_2d": [456, 587, 1183, 1214], "label": "dog"}\n]\n']如果你训练的是"只返回
bbox_2d不带 label"的格式,请确保推理时的文字提示与训练保持一致,比如明确"只输出 JSON,不要多余文本"。
5. 可视化:把预测框画回图片
把下面脚本存为 viz_simple.py,用 PIL 画框:
bash
python viz_simple.py \
--image demo.jpeg \
--pred-str '[{"bbox_2d":[456,587,1183,1213],"label":"dog"}]' \
--out demo_boxed.jpg找不到
DejaVuSans.ttf时脚本会自动回落默认字体,能正常出图。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from PIL import Image, ImageDraw, ImageFont
import json, argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--image", required=True, help="原始图片路径")
parser.add_argument("--pred-str", required=True,
help="预测结果JSON字符串,例如 '[{\"bbox_2d\":[456,587,1183,1213],\"label\":\"dog\"}]'")
parser.add_argument("--out", required=True, help="输出图片路径")
args = parser.parse_args()
# 解析预测结果
preds = json.loads(args.pred_str)
im = Image.open(args.image).convert("RGB")
draw = ImageDraw.Draw(im)
# 尝试加载字体
try:
font = ImageFont.truetype("DejaVuSans.ttf", 20)
except:
font = ImageFont.load_default()
for obj in preds:
bbox = obj.get("bbox_2d")
label = obj.get("label", "")
if not bbox or len(bbox) != 4:
continue
x1,y1,x2,y2 = bbox
# 画框
draw.rectangle([x1,y1,x2,y2], outline="red", width=8)
if label:
# 获取文本尺寸
try:
# 新Pillow推荐 textbbox
tw, th = draw.textbbox((0,0), label, font=font)[2:]
except:
# 兼容旧版本
tw, th = font.getsize(label)
# 绘制文字背景+文字
draw.rectangle([x1, y1-th-4, x1+tw+4, y1], fill="red")
draw.text((x1+2, y1-th-2), label, fill="white", font=font)
im.save(args.out)
print(f"saved -> {args.out}")
if __name__ == "__main__":
main()
'''
python viz_simple.py \
--image demo.jpeg \
--pred-str '[{"bbox_2d":[456,587,1183,1213],"label":"dog"}]' \
--out demo_boxed.jpg
'''6. 评估思路(从"会说 JSON"到"框得准")
训练日志里的 token_acc 说明模型学会了 JSON 话术 ,但定位效果还要看 IoU:
-
简易评估:把模型输出的
bbox_2d与 YOLO 标签(换算到xyxy)做 IoU,统计 mAP@0.5 或 Recall/Precision。 -
实操要点:
- 解析 JSON 时做好容错(有时模型会多给一层
json\n[...]前缀,strip 再json.loads)。 - 多框匹配用匈牙利匹配或贪心按 IoU 最大配。
- 负样本 (
bbox_2d=[])很关键,能明显降低"幻觉预测"。
- 解析 JSON 时做好容错(有时模型会多给一层
7. 常见坑与排查
data.yaml 里需要 names 列表
转换脚本依赖names。没有就补上或改为class_names。- 图片路径不对
训练机和标注机不在一台?用--image_path_prefix写绝对路径(NFS 前缀)。 - 显存爆掉 / OOM
降低--max_pixels(如 921600 → 589824)、把per_device_train_batch_size调 1、增大--gradient_accumulation_steps,或上AWQ基座。 - 没装 Flash-Attention
把attn_implementation="flash_attention_2"去掉即可;想用就先装兼容版本。 - 输出不是纯 JSON
提示词务必包含"只输出 JSON ";训练数据和推理提示要风格统一。 - 字体报错
viz_simple.py已内置默认字体兜底,或你额外放一份DejaVuSans.ttf。 - 多 GPU 没生效
用CUDA_VISIBLE_DEVICES=0,1,2,...控制卡,ms-swift 会自动并行。
有效 batch ≈per_device_bs × grad_acc × GPU数。
8. 你可以直接复用的完整代码
- yolo2_ms_swift.py:YOLO → JSONL 转换(已包含中英提示、per-class/all、负样本)
- qwen_vl_grounding_infer.py:推理脚本(按指令吐 JSON)
- viz_simple.py:可视化脚本(画框/文字)
以上三个脚本你在题面都给了完整版本,按需直接落盘即可使用。
9. 参考训练记录(帮助你对齐预期)
你的一次训练收敛片段(节选):
Train: ... 3669/3669
Eval: eval_loss=0.6329, eval_token_acc=0.7492
Train: train_loss=0.5660
best_model_checkpoint: .../checkpoint-3000
last_model_checkpoint: .../checkpoint-3669这说明:
- 模型已稳定学会"按 JSON 说话"(token_acc ~ 0.75)
- 你可以用 best checkpoint 做下游评估与部署
10. 小结 & 你的下一步
-
你已经完成:数据转换 → LoRA 微调 → 指令化推理 → 可视化与评估。
-
下一步建议:
- 多负样本 (
include_negatives)与多风格提示词混合,增强鲁棒性。 - 引入困难样本挖掘(高误检/漏检图)做二次微调。
- 用
min/max_pixels做分辨率分级训练,兼顾精度与速度。
- 多负样本 (
Grounding 的优势在于"语言可控 "。当你的业务只检测"摄像头"等少数类时,小规模 LoRA 就能把 Qwen2.5-VL-3B 调得很"乖",而且有了语言接口,后续加类、改描述都更灵活。
祝你首训即收敛,推理一路绿灯!如果需要,我可以把评估 IoU 的脚本也给你补上(含 mAP@0.5/0.5:0.95 计算与日志汇总)。