如何利用大语言模型(GPT-5)打造一个能深度分析任何PDF的自动化工具
在信息爆炸的时代,我们每天都面临着大量的长篇文档:学术论文、市场研究报告、财务报表、法律合同......阅读和提炼这些文档的核心信息既耗时又费力。如果我们能让 AI 成为我们的专属高级分析师,自动完成这项工作呢?

本教程将手把手带你从零开始以及OpenAI API Key怎么获取都给你铺垫好,构建一个强大的 Python 自动化工具。它能够:
- 处理任意长度的 PDF 文档,不受模型上下文窗口的限制。
- 智能提取文本和表格,保留关键的结构化数据。
- 利用 OpenAI GPT-5 的强大分析能力,生成结构化、有深度的 Markdown 分析报告。
- 拥有高并发处理能力,分析速度远超普通脚本。
- 具备专业级的配置和容错能力,安全且稳定。
无论你是开发者、数据分析师,还是仅仅想用技术赋能日常工作的效率达人,本教程都将为你提供一个完整且可复用的解决方案。
核心思想:用"分而治之"的 Map-Reduce 策略突破 Token 限制
所有大语言模型都有一个"上下文窗口"或"Token"限制。你无法一次性将一本 200 页的 PDF 全部扔给它。那么如何解决呢?答案就是经典的编程思想------Map-Reduce。
- Map(分而治之):我们将长长的 PDF 文档,像切蛋糕一样,切分成多个有少量重叠的、可管理的小文本块(Chunks)。然后,我们让 AI 并行地、独立地阅读每一个小块,并为每一块生成一个简洁的摘要。就像一个经理把一份大报告分发给多个实习生,让他们各自负责一部分。
- Reduce(综合归纳):在收集了所有小块的摘要后,我们将这些"实习生报告"整合在一起,提交给 AI 这个"高级经理"。"高级经理"的任务不再是阅读原文,而是基于这些高度浓缩的摘要,进行最终的、全面的、有深度的综合分析,并撰写最终报告。
这个策略巧妙地绕开了 Token 限制,让分析超长文档成为可能。

我们将从环境配置、依赖安装开始,一直到代码的运行和获取OpenAI API Key,确保即使是编程新手也能轻松上手。
准备篇:搭建你的 AI 分析环境
在施展魔法之前,我们需要先搭建好工作台。
第 1 步:项目初始化与虚拟环境
这是一个专业且强烈推荐的步骤。为每个项目创建一个独立的虚拟环境,可以像为项目建立一个"沙盒"一样,确保不同项目间的 Python 库不会互相干扰。
- 创建项目文件夹 :在你喜欢的位置,创建一个新的文件夹,例如
PDF-Analyzer,然后通过终端进入这个文件夹。mkdir PDF-Analyzer cd PDF-Analyzer或者用vscode编辑工具打开文件夹。
- 创建 Python 虚拟环境:
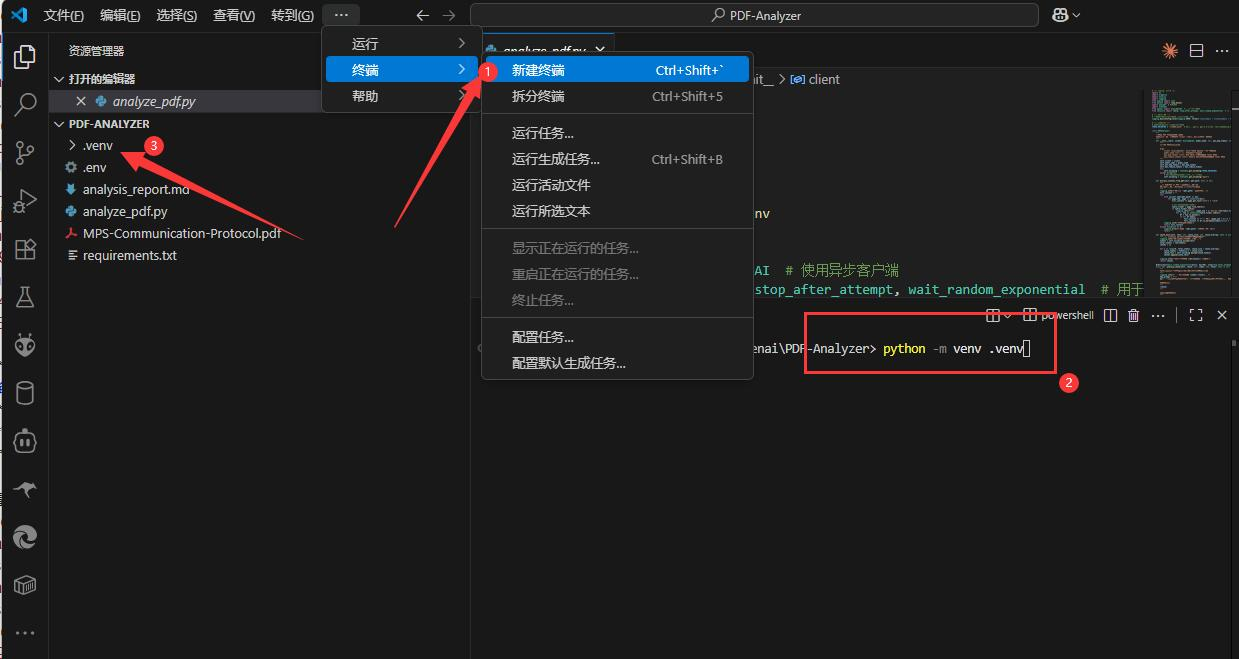
- 确保你的 Python 版本是 3.8 或更高 python -m venv .venv
- 激活虚拟环境 :
Windows (CMD/PowerShell):.venv\Scripts\activate
macOS / Linux:source .venv/bin/activate
- 激活成功后,你的命令行提示符前面会出现
(.venv)的字样,表示你已进入"沙盒"模式。
第 2 步:创建 requirements.txt 依赖清单
requirements.txt 文件就像一张购物清单,它精确地告诉 Python 需要安装哪些工具(库)才能让我们的项目跑起来。
在你的项目文件夹 (PDF-Analyzer) 中,创建一个名为 requirements.txt 的文件,并将以下内容完整地复制进去:
javascript
openai
pymupdf
tiktoken
tenacity
pandas
tabulate
python-dotenv第 3 步:一键安装所有依赖
有了"购物清单",我们现在就可以一键"采购"了。在已激活虚拟环境的终端中,运行以下命令:
javascript
pip install -r requirements.txtpip会自动读取 requirements.txt 文件,并下载安装所有列出的库。让我们认识一下这些强大的工具:
openai: 与大语言模型 API 交互的官方库。pymupdf: 高效读取 PDF 文本和表格的利器。tiktoken: OpenAI 官方的 Tokenizer,用于精确计算文本量。tenacity: 一个强大的重试库,能让我们的网络请求更稳定。pandas&tabulate: 这两个是处理表格数据的黄金搭档,pymupdf在提取表格时会用到它们。python-dotenv: 用于安全、方便地管理你的 API 密钥。

第 4 步:配置你的 API 密钥
这是最关键的一步,是连接 AI 大脑的钥匙。
获取OpenAI API KEY你只需以下两步选择:
方式A:官方直连模式
- 流程较为复杂,且对网络环境要求较高,新手容易遇到障碍。
方式B:国内加速模式
- 借助国内技术团队(如:
uiuiapi.com)提供的中转服务,连接更稳定,速度更快,许多资深用户都在用。
- 在项目文件夹中,创建一个名为
.env的文件。 - 打开
.env文件,填入以下内容,并替换成你自己的信息:
javascript
# 输入你在 uiuiapi.com 获取的 API 密钥或官方API秘钥
API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# API 的基础 URL (例如 OpenAI 官方地址或uiuiAPI地址)
BASE_URL="https://uiuiapi地址/v1"
# 你希望默认使用的模型名称 (可选)
MODEL_NAME="gpt-5"安全提示 :
.env文件包含了你的敏感信息。请绝对不要将此文件分享给他人或上传到公开的代码仓库(如 GitHub)。
第 5 步:保存核心代码
将以下Python 脚本代码,保存到项目文件夹中,命名为 analyze_pdf.py。
python
# -*- coding: utf-8 -*-
import os
import argparse
import asyncio
import logging
from typing import List
from dotenv import load_dotenv
import pymupdf # PyMuPDF
import tiktoken
from openai import AsyncOpenAI # 使用异步客户端
from tenacity import retry, stop_after_attempt, wait_random_exponential # 用于API调用重试
# --- 日志配置 ---
# 配置日志记录,方便调试和追踪程序运行状态
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- 常量定义 ---
# 将编码名称定义为常量,方便管理
TOKEN_ENCODING = "cl100k_base" # 适用于 gpt-4, gpt-3.5-turbo, text-embedding-ada-002 的推荐编码
class PDFAnalyzer:
"""
封装了 PDF 分析的核心逻辑。
优化:通过构造函数接收 client 实例,而不是依赖全局变量。
"""
def __init__(self, client: AsyncOpenAI, model_name: str, max_map_tokens: int, max_reduce_tokens: int):
"""
初始化 PDFAnalyzer。
Args:
client (AsyncOpenAI): 已初始化的 OpenAI 异步客户端。
model_name (str): 用于分析的模型名称。
max_map_tokens (int): Map 阶段每个块的最大 token 数。
max_reduce_tokens (int): Reduce 阶段整合摘要的最大 token 数。
"""
self.client = client
self.model_name = model_name
self.max_map_tokens = max_map_tokens
self.max_reduce_tokens = max_reduce_tokens
try:
self.encoding = tiktoken.get_encoding(TOKEN_ENCODING)
except Exception:
# 如果推荐的编码不可用,则使用备用编码
self.encoding = tiktoken.get_encoding("gpt2")
def extract_content_from_pdf(self, pdf_path: str) -> str:
"""
使用 PyMuPDF 从 PDF 中提取文本和表格。
表格将被转换为 Markdown 格式以保留结构。
"""
logging.info(f"正在从 '{pdf_path}' 提取内容...")
full_content = ""
try:
with pymupdf.open(pdf_path) as doc:
for page_num, page in enumerate(doc):
full_content += page.get_text("text") + "\n\n"
# 查找并处理页面中的表格
table_finder = page.find_tables()
if table_finder.tables:
logging.info(f"在第 {page_num + 1} 页找到 {len(table_finder.tables)} 个表格。")
for i, tab in enumerate(table_finder.tables):
df = tab.to_pandas()
if not df.empty:
full_content += f"--- 表格 {page_num + 1}-{i + 1} ---\n"
full_content += df.to_markdown(index=False) + "\n\n"
logging.info("内容提取完成。")
return full_content
except Exception as e:
logging.error(f"提取 '{pdf_path}' 内容时出错: {e}")
return ""
def chunk_text(self, text: str, chunk_size: int, chunk_overlap: int) -> List[str]:
"""使用 tiktoken 将长文本分割成带重叠的块。"""
logging.info("正在将文本分割成多个块...")
tokens = self.encoding.encode(text)
total_tokens = len(tokens)
chunks = []
for i in range(0, total_tokens, chunk_size - chunk_overlap):
chunk_tokens = tokens[i:i + chunk_size]
chunk_text = self.encoding.decode(chunk_tokens)
chunks.append(chunk_text)
logging.info(f"文本被分割成 {len(chunks)} 个块。")
return chunks
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
async def _analyze_chunk(self, chunk: str, index: int, total: int) -> str:
"""
(内部方法)异步分析单个文本块,并带有重试机制。
"""
logging.info(f" - 正在处理块 {index}/{total}...")
map_prompt = f"""
你是一位专业的分析师。以下是一份长文档的一部分。请对这部分内容进行简洁的摘要,提取出关键信息、数据和要点。
文档片段:
---
{chunk}
---
请提供你的摘要:
"""
try:
response = await self.client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "你是一位专业的分析师,擅长从文本片段中提取核心信息。"},
{"role": "user", "content": map_prompt}
],
temperature=0.2,
)
summary = response.choices[0].message.content
logging.info(f" - 块 {index}/{total} 处理完成。")
return summary if summary else f"块 {index} 返回了空摘要。"
except Exception as e:
logging.error(f" - 处理块 {index} 时出错: {e}")
return f"块 {index} 分析失败。"
async def analyze_text_with_gpt(self, text: str) -> str:
"""
使用 Map-Reduce 策略分析文本。
Map 阶段使用 asyncio 实现并行处理。
"""
chunks = self.chunk_text(text, chunk_size=self.max_map_tokens, chunk_overlap=200)
logging.info("Map 阶段:正在并行分析所有文本块...")
map_tasks = [self._analyze_chunk(chunk, i + 1, len(chunks)) for i, chunk in enumerate(chunks)]
map_summaries = await asyncio.gather(*map_tasks)
logging.info("Reduce 阶段:正在整合所有摘要以生成最终报告...")
combined_summaries = "\n\n---\n\n".join(map_summaries)
combined_tokens_len = len(self.encoding.encode(combined_summaries))
if combined_tokens_len > self.max_reduce_tokens:
logging.warning(f"整合后的摘要过长 ({combined_tokens_len} tokens),将进行递归 Reduce。")
# 递归调用自身来处理过长的摘要
return await self.analyze_text_with_gpt(combined_summaries)
reduce_prompt = f"""
你是一位顶级的策略分析师和报告撰写人。你收到了关于同一份文档不同部分的多个摘要。你的任务是将这些零散的摘要整合升华,形成一份结构完整、逻辑清晰、观点深刻的最终分析报告。
报告应遵循以下 Markdown 格式:
# [文档标题] - 综合分析报告
## 1. 执行摘要
在此处提供一个高度浓缩的摘要,总结整个文档的核心内容和主要结论。
## 2. 关键主题与洞察
识别并阐述文档中反复出现的 3-5 个核心主题。对于每个主题,提供简要的解释和相关的证据或例子。
- **主题一**:[描述]
- **主题二**:[描述]
- **主题三**:[描述]
## 3. 关键数据与发现
列出文档中提到的具体数据、统计信息或重要发现。
- [发现一]
- [发现二]
## 4. 潜在影响与可操作建议
基于以上分析,推断这些信息可能带来的潜在影响,并提出具体的、可操作的建议。
以下是各部分的摘要,请基于它们完成报告:
---
{combined_summaries}
---
"""
try:
final_response = await self.client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "你是一位顶级的策略分析师和报告撰写人。"},
{"role": "user", "content": reduce_prompt}
],
temperature=0.5,
)
return final_response.choices[0].message.content or "最终报告生成失败,返回为空。"
except Exception as e:
logging.error(f"在 Reduce 阶段出错: {e}")
return "生成最终报告时出错。"
def generate_markdown_report(analysis_content: str, output_path: str):
"""将分析内容写入 Markdown 文件。"""
logging.info(f"正在将报告写入 '{output_path}'...")
try:
with open(output_path, "w", encoding="utf-8") as f:
f.write(analysis_content)
logging.info(f"报告生成成功!文件保存在: {output_path}")
except Exception as e:
logging.error(f"写入文件时出错: {e}")
async def main():
"""主执行函数,负责解析参数、初始化和协调整个分析流程。"""
# --- 1. 加载和检查配置 ---
# load_dotenv() 会查找当前目录下的 .env 文件并加载其内容
load_dotenv()
# 使用 os.getenv() 安全地获取配置
api_key = os.getenv("API_KEY")
base_url = os.getenv("BASE_URL")
# --- 检查配置是否存在 ---
if not api_key or not base_url:
logging.error("错误:API_KEY 或 BASE_URL 未在 .env 文件中设置。")
logging.error("请确保在项目根目录下创建了 .env 文件并正确配置。")
return
# --- 2. 解析命令行参数 ---
parser = argparse.ArgumentParser(description="使用大语言模型分析 PDF 文件并生成 Markdown 报告。")
parser.add_argument("pdf_path", type=str, help="待分析的 PDF 文件路径。")
parser.add_argument("--output", type=str, default="analysis_report.md", help="输出的 Markdown 文件名。")
# 从环境变量获取模型名称作为默认值,如果未设置则使用 'gpt-4o'
default_model = os.getenv("MODEL_NAME", "gpt-4o")
parser.add_argument("--model", type=str, default=default_model, help=f"用于分析的模型名称 (默认: {default_model})。")
parser.add_argument("--max_map_tokens", type=int, default=8000, help="Map 阶段每个分块的最大 Token 数。")
parser.add_argument("--max_reduce_tokens", type=int, default=120000, help="Reduce 阶段整合摘要的最大 Token 数。")
args = parser.parse_args()
logging.info("--- 配置加载成功 ---")
logging.info(f"将要使用的模型: {args.model}")
# --- 3. 初始化API客户端 ---
try:
client = AsyncOpenAI(
api_key=api_key,
base_url=base_url,
)
except Exception as e:
logging.error(f"初始化 OpenAI 客户端时出错: {e}")
return
# --- 4. 执行分析流程 ---
analyzer = PDFAnalyzer(
client=client, # 传入 client 实例
model_name=args.model,
max_map_tokens=args.max_map_tokens,
max_reduce_tokens=args.max_reduce_tokens
)
pdf_content = analyzer.extract_content_from_pdf(args.pdf_path)
if not pdf_content:
logging.error("未能从 PDF 中提取任何内容,程序终止。")
return
analysis_result = await analyzer.analyze_text_with_gpt(pdf_content)
if analysis_result:
generate_markdown_report(analysis_result, args.output)
else:
logging.error("分析未能生成结果,报告未创建。")
if __name__ == "__main__":
# 使用 asyncio.run() 来运行异步的 main 函数
asyncio.run(main())至此,你的项目文件夹结构应该如下所示:
javascript
PDF-Analyzer/
├── .venv/ # 虚拟环境文件夹
├── .env # 你的 API 密钥配置文件
├── requirements.txt # Python 依赖清单
├── analyze\_pdf.py # 我们的核心脚本
└── (你准备分析的PDF文件)
实战篇:一行命令,启动你的分析机器人
万事俱备!现在,让我们见证奇迹。
-
放入 PDF :将你想要分析的 PDF 文件(例如
年度财报.pdf)放到PDF-Analyzer文件夹中。 -
执行命令 :在你的终端(确保还处于激活的虚拟环境中),运行以下命令(
以下命令基于我的PDF文件示例),实际运行命令根据你的文件名修改:
bash
python analyze_pdf.py "MPS-Communication-Protocol.pdf""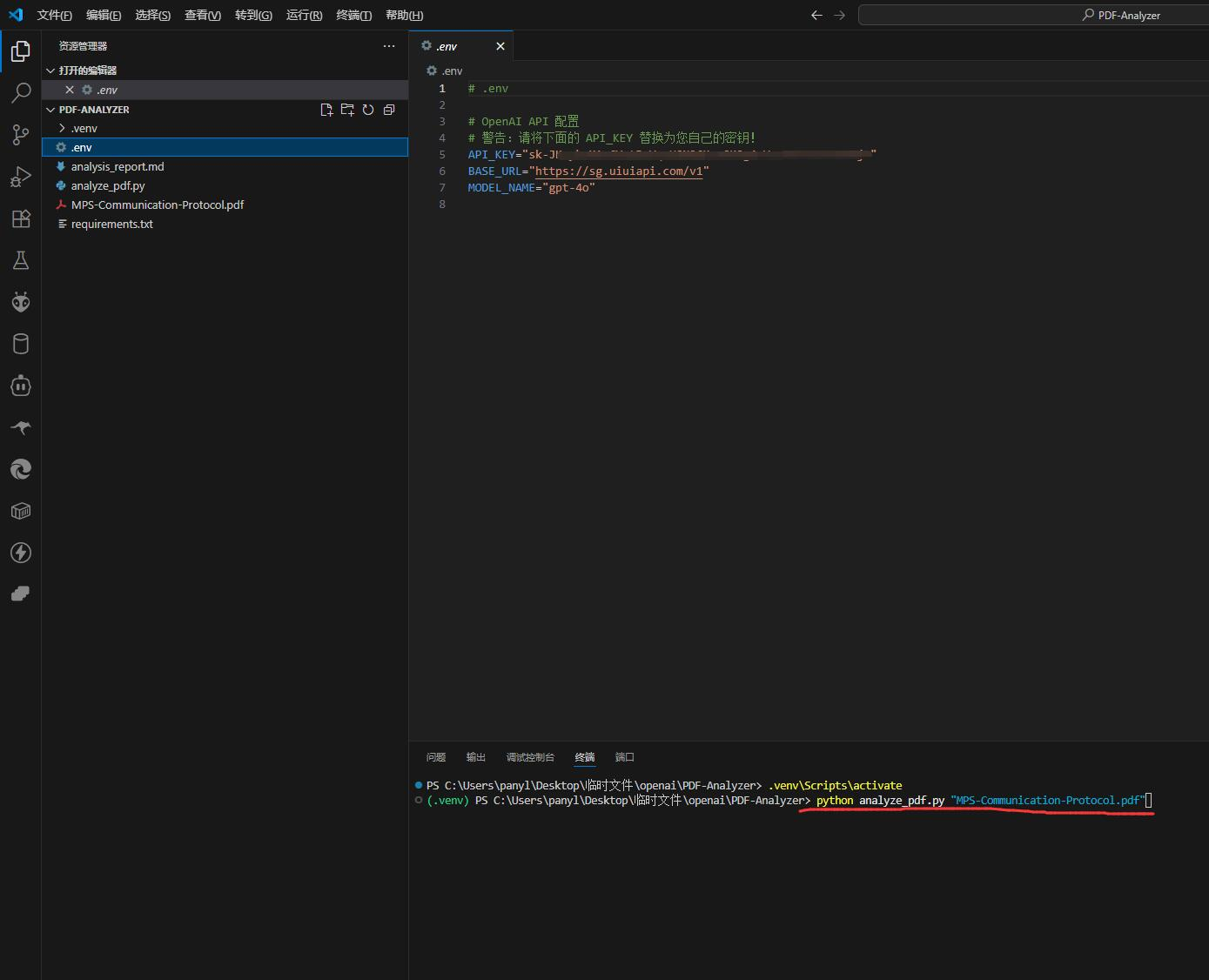
- 脚本会立刻开始工作。你会在终端看到实时的日志输出,它会告诉你当前正在进行哪一步:提取内容 -> 分割文本块 -> 并行处理摘要 -> 整合最终报告。
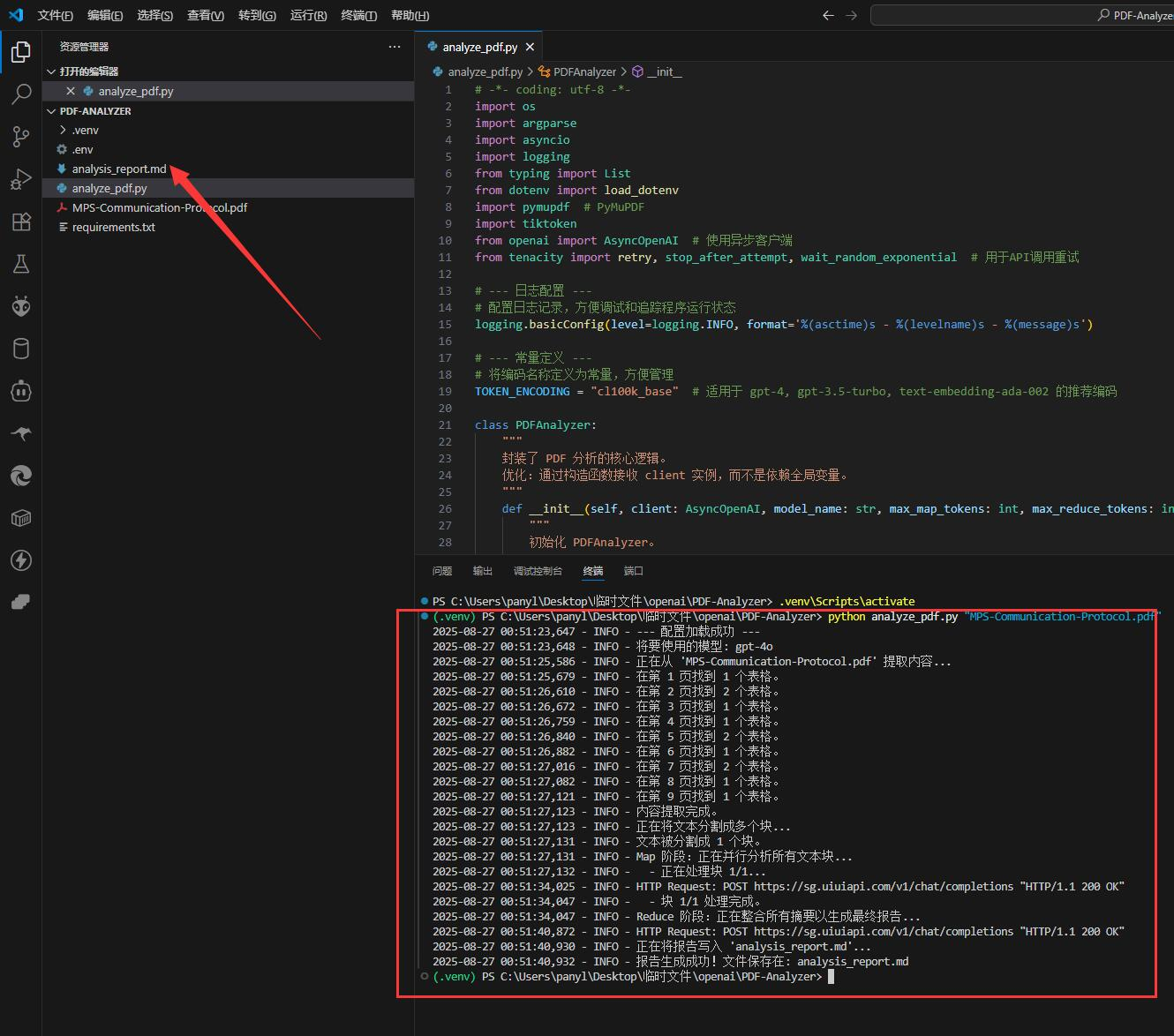
- 任务完成后,一个名为
analysis_report.md的 Markdown 文件就会出现在你的文件夹里。打开它,一份由 AI 为你量身定制的、结构化的深度分析报告就呈现在眼前了!
进阶玩法
你可以通过添加额外参数来微调脚本的行为:
-
指定输出文件名:
bashpython analyze_pdf.py "年度财报.pdf" --output "财报核心洞察.md" -
临时切换 AI 模型:
bashpython analyze_pdf.py "年度财报.pdf" --model "gpt-4-turbo"
原理篇:揭秘机器人背后的智慧
简单了解脚本的工作原理,能帮助你更好地使用甚至改造它。
我们的脚本核心是**"分而治之"(Map-Reduce)**策略,以绕过 AI 模型一次性处理文本的长度限制。
-
分 (Map) :脚本首先使用
pymupdf精准地提取 PDF 的所有文本和表格,然后用tiktoken将长文本切成多个带有重叠部分的小块。最后,利用asyncio的异步能力,像派出多个机器人同时工作一样,将这些小块并发地发送给 AI,为每一块生成摘要。 -
治 (Reduce) :当所有小块的摘要都完成后,脚本会将它们整合起来,再次发送给 AI。但这一次,它会给 AI 一个更高级的指令(通过
reduce_prompt),要求它扮演"顶级策略分析师"的角色,基于这些零散的摘要,撰写一份包含执行摘要、关键主题、数据发现和行动建议的、结构化的最终报告。
这种设计不仅解决了长度限制,更通过结构化的指令,确保了输出结果的高质量和专业性。

界智通(jieagi)整个教程结语
恭喜你!你已经成功搭建并运行了一个属于自己的 AI 文档分析工具。从一个简单的想法到一个强大的工具,我们经历了一个典型的软件开发迭代过程。通过解决实际问题,我们不仅让脚本变得更好,也学习和应用了异步编程、高级文件解析、专业配置管理和容错设计等宝贵技能。
这个工具已经非常强大,但探索永无止境。你还可以继续为它添加更多功能,例如:
- 支持更多文件类型 :如
.docx,.txt。 - 图像分析:结合 GPT-5 等多模态模型,让它能"读懂"PDF 中的图表和图片。
- Web 界面:使用 Streamlit 或 Flask 为它创建一个图形用户界面,让非技术人员也能方便使用。
希望本教程能为你打开一扇通往自动化与 AI 生产力的大门。现在,去释放你的创造力,让 AI 为你工作吧!
版权信息: 本文由界智通(jieagi)团队编写,保留所有权利。未经授权,不得转载或用于商业用途。