1前言
1.1规范
-
对于自己计算机的一个认知:代码存放的位置、anaconda 下载环境存放的位置、磁盘文件夹访问权限的问题、各种软件的环境变量配置问题
-
对于项目文件命名、项目文件夹的认知
-
针对不同阶段项目,需要有对应的虚拟环境;虚拟环境可以隔离不同项目之间对于下载库的版本的需求
-
这个阶段的 pytorch 环境,完全可以克隆一份出来(从之前的 pytorch 环境中)
bash
conda create -n 新环境名称 --clone 旧环境名称1.2学习重点
-
yolo 理论阶段:重点是去了解 yolo 的一个算法的一个发展史,以及在不同版本的 yolo 中存在哪些网络结构上的差异
-
算法:yolo 是一个目标检测算法
-
网络结构:yolo 是一个神经网络
-
因为这个 yolo 是一个开源的项目,我们就是基于这个开源的代码就行项目开发的
1.3视觉处理的三大任务
-
图像分类:就是输出图片中的内容属于哪一个类别 --- 一般情况下图像分类的图片中,只有一个物体
-
目标检测:就是输出图片中的内容属于哪一个类别且需要标注出来这个物体所在的位置 --- 一般情况下目标检测的图片中,包含多个物体【多个物体并不意味着都是我们的模型需要去学习、识别的】

-
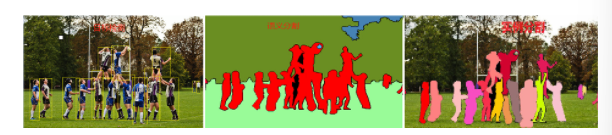
图像分割:实例分割、语义分割
-
实例分割是语义分割的进阶 :不仅要给每个像素分配类别标签,还要区分同一类别下的不同 "实例"(即个体)。
-
语义分割的本质是给图像中的每个像素分配一个 "语义类别标签" (比如 "天空""猫""汽车""路面"),但不区分同一类别下的不同个体。
-
| 对比维度 | 语义分割(Semantic) | 实例分割(Instance) |
|---|---|---|
| 核心目标 | 像素级类别划分 | 像素级类别划分 + 个体(实例)区分 |
| 是否区分同类别实例 | 不区分(如 2 只猫视为同一 "猫" 区域) | 区分(如 2 只猫视为 "猫 1""猫 2" 两个区域) |
| 输出结果 | 类别标签 → 像素的映射(无个体标识) | (类别标签 + 实例 ID)→ 像素的映射 |
| 本质 | "像素分类" | "目标检测 + 像素分类" 的结合 |
| 典型问题 | "这张图里有哪些类别?" | "这张图里有哪些类别?各有几个?" |
| 计算复杂度 | 相对较低(只需分类,无需区分个体) | 相对较高(需额外检测和区分个体) |
1.4训练、验证、测试、推理
-
算力【租赁 autoDL 网站】、模型结构【yolo 提供的预训练模型有五种,大小不一样】
-
训练模型的方式:
-
从零开始
-
迁移学习
-
-
训练:使用训练数据集训练模型,让模型学习。。。【数据集需要做标注】,图像分类的时候文件夹的名字就是图片所属的类别,目标检测不一样,需要自己打标签
-
验证:使用验证数据集验证模型性能,可以发生在模型训练过程中、最后,它可以动态的调整模型参数,让模型更加平稳的收敛。。。【数据集需要做标注】
-
测试:使用测试数据集测试模型,发生在模型训练完成之后,使用已知的数据集去验证模型的性能【已知的数据集就是你提前准备好的了的带有标签的数据集,一般情况下这个内容是可选项】
-
推理:使用未知图片来进行模型的推理过程,发生在模型训练完成之后,使用模型做应用开发【随便什么样的图片,没有标签,但是图片要和你的模型相关】
-
【重点】训练、验证、测试图片是不可以存在相同的
1.5上游任务和下游任务
-
上游任务:就是使用大量的数据集训练模型,得到预训练模型
-
下游任务:通过预训练模型得到自己的模型,做模型的应用开发【落地】
1.6卷积
-
浅层卷积(前几层卷积):感受野小(看到的内容少,具有丰富的空间结构信息)、看到的内容清晰、适合检测小目标
-
深层卷积(后几层卷积):感受野大(看到的内容大,具有丰富的语义信息)、看到的内容模糊、适合检测大目标
-
丰富提取出来的特性信息
2目标检测基础
2.1概念
-
目标检测(Object Detection) 是计算机视觉中的一个重要领域,它涉及到识别图片或视频某一帧中的物体是什么类别,并确定它们的位置。通常用于多个物体的识别,可以同时处理图像中的多个实例,并为每个实例提供一个边界框和类别标签
-
目标检测面临到的问题:
-
目标种类和数量问题
-
目标尺度问题
-
环境干扰问题
-

2.2标注(数据集)
-
yolo 来做目标检测模型,有一套输入自己专属的数据集标注格式,数据集标注格式指的就是把训练数据集的图片打标签,这个打标签就比较的繁琐【时间花费大】,但是没有多大的意义
-
寻找数据集的手段:
-
开源数据集:kaggle、huggingface.....
-
闲鱼上买一个【质量很好,一定要选择符合 yolo 格式的】
-
-
yolo 要求数据集满以下格式:
-
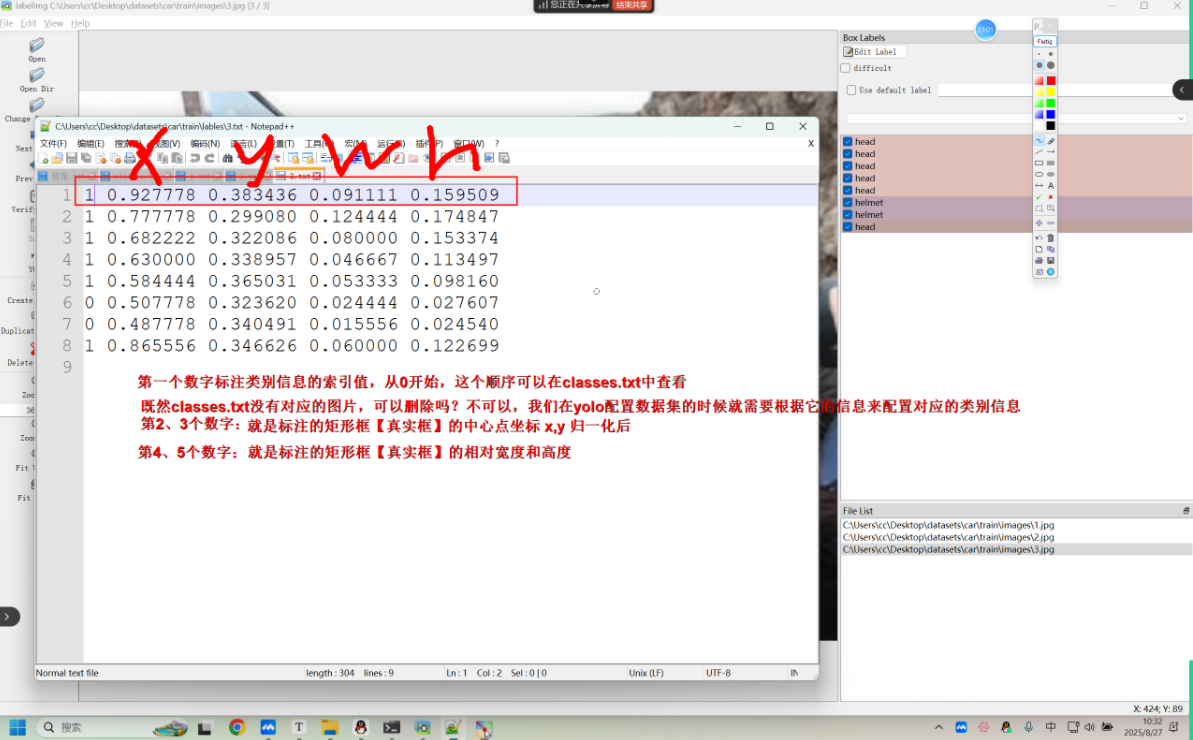
训练数据集、验证数据集、测试数据集【可选】都是需要打标签的,这个标签就是针对于某一张图片的一个 txt 文件,文件中存储的内容就是关于这张图片中标注的物体的类别信息、位置信息
-
推荐大家使用 yolo 训练模型就保证数据集的格式如下:每一个名称都是一个文件夹
-
datasets:存放所有的数据集,这个所有的意思就是训练任何模型的数据集
-
car:训练car的数据集信息
-
train:训练数据集
-
images:图片信息
-
lables:标签信息
-
-
val:验证数据集
-
images:图片信息
-
labels:标签信息
-
-
-
helmet:
-
train:训练数据集
-
images:图片信息
-
lables:标签信息
-
-
val:验证数据集
-
images:图片信息
-
labels:标签信息
-
-
-
-
-
-
数据集标注实现方案:
-
安装 lableimg 工具,这工具如果安装在 python 3.12 版本下,会有一点小 bug,我们需要去修改对应的源码
-
第一步:创建一个虚拟环境
bashconda create -n labels_env python=3.12- 第二步:激活虚拟环境【有的版本的anaconda不需要写 conda】
bashconda activate labels_env- 第三步:下载 labelimg
bashpip install labelimg- 第四步:查看是否安装了 labelimg
bashconda list labelimg- 第五步:启动 labelimg 标注工具【遇到bug就去解决】
bashlabelimg
-
2.3 本质
-
对于目标检测,主要是关注两个问题:
-
目标在哪里?where
-
目标是什么?what
-
2.4应用场景
2.5技术架构(了解即可)
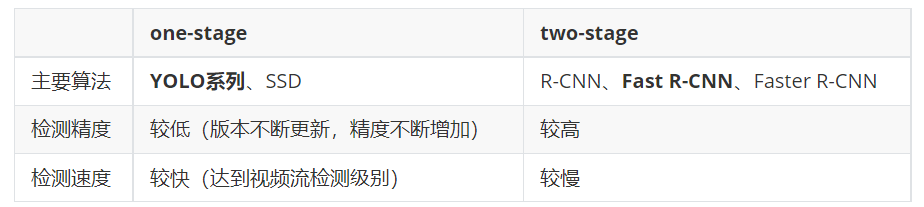
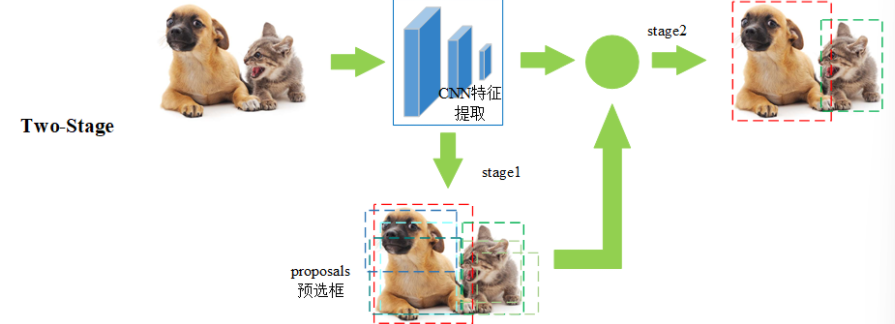
- 目标检测方法可以根据其架构和技术特点进行分类。目前主流的目标检测方法可以分为两大类:两阶段检测方法(Two-stage Detection Methods)和单阶段检测方法(One-stage Detection Methods)
- 分类信息如下表:
2.5.1two-stage
-
两阶段检测开始于 2014 年左右,是目标检测领域中非常重要的一类方法,这类方法通常因为其高检测精度和可靠性而被广泛应用于各种复杂的目标检测任务中
-
两阶段检测方法将目标检测任务分为两个连续的阶段:
-
第一阶段:第一阶段是生成候选区域(Region Proposals),即可能包含目标的区域,通常通过区域提议网络(RPN)或其他方法实现
-
第二阶段:对生成的候选区域进行分类和边界框回归,即确定候选区域中的物体类别以及调整候选区域的位置,以更精确地框中目标
-
-
基本流程如下:
-
第一步 Input:输入一张图像
-
第二步 Conv&pooling:使用卷积神经网络做深度特征提取,通过称这个卷积神经网络为主干神经网
-
第三步 Conv-proposal:使用 RPN 网络生成候选区域,并对这些区域进行初步的分类(区分背景和目标)以及位置预测
-
第四步 roi pooling:候选区域进一步精确进行位置回归和修正,对不同大小的候选区域提取固定尺寸的特征图
-
第五步 fc:全连接层,对候选区域的特征进行表示
-
第六步 Lcls、Lreg:通过分类和回归来分别完成对候选目标的类别的预测以及候选目标位置的优化,这里的类别不同于 RPN 网络的类别,这里通常会得到物体真实的类别,回归主要得到当前目标具体的坐标位置,通常表示为一个矩形框,即四个值(x,y,w,h)

-
- 比如猫狗混合图:
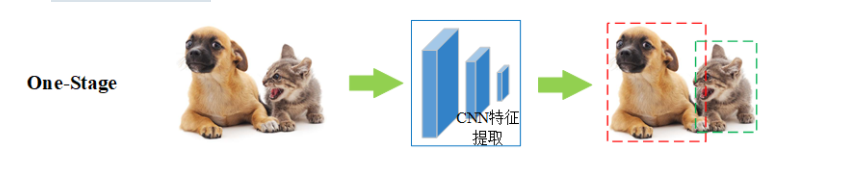
2.5.2one-stage
-
单阶段目标检测开始于 2016 年左右,没有像 two-stage 那样先生成候选框,而是直接回归物体的类别概率和位置坐标值
-
基本流程图如下:
-
第一步 Input:输入一张图像
-
第二步 CNN:使用卷积神经网络做深度特征提取,通过称这个卷积神经网络为主干网络
-
第三步 Lcls、Lreg:通过分类和回归来分别完成对候选目标的类别的预测以及候选目标位置的优化

-
- 比如猫狗混合图:
2.6指标(重点)
2.6.1边界框和真实框
- 真实框:就是我们在训练模型之前,基于数据集内容,做的标注信息的矩形框;在推理阶段是否存在真实框?推理阶段是没有真实框的
-
边界框:边界框(bounding boxes),也可以称为预测框,这个框就是模型输出的结果,是用来定位图像中检测到的物体位置 的一个矩形框 ;用来表示该物体在图像中的位置 和大小
-
在训练阶段,我们通过控制损失函数,让边界框更加接近于真实框(提高模型的性能);
-
在推理阶段,这个边界框就是我们通过模型推理出来的结果,这个过程诠释是否模型学习到的东西的一个输出,
-
2.6.2交并比
-
在目标检测 任务中,IoU(Intersection over Union,交并比)是一个非常关键的评估指标 ,用于衡量模型预测的边界框(Predicted Bounding Box)与真实边界框(Ground Truth Bounding Box)之间的重合程度
-
IOU:就是真实框和边界框的交集面积比上真实框和边界框的并集面积,取值范围:0,1

-
IOU = 0:完全没有相交的面积
-
IOU = 1:完全重合
-
0 =< IOU <= 1:部分重合
-
| IoU 值 | 含义说明 |
|---|---|
| IoU = 0 | 两个框完全不重合,预测框与真实框没有任何交集 |
| 0 < IoU < 0.5 | 有一定重合,但重合度较低,预测效果一般 |
| 0.5 ≤ IoU < 1 | 重合度较高,预测框接近真实框,效果较好 |
| IoU = 1 | 完全重合,预测框与真实框完全一致,可能是理想情况或存在过拟合风险 |
2.6.3置信度
-
置信度就是模型输出某个物体的未知和类别的时候,模型对预测框是否包含目标物体、以及框的位置是否准确的"信心值",取值范围 0 到 1 之间的数值 ,给出的一个浮点数,这个浮点数衡量模型对于结果的自信程度
-
在训练阶段,置信度计算公式:
-
confidence = Pr(obj) * IOU
-
Pr(obj):
-
当有物体的时候为 1
-
当没有物体的时候为 0
-
-
-
在推理阶段,由于没有真实框的存在,所以没有办法去计算 IOU 的值,那么模型推理阶段的置信度输出,完全就是有模型学习的结果产生的【即模型预测的,包含了类别置信度 + 目标存在置信度】
-
预测的 IoU:不是真实计算出来的,而是模型自己"估计"的,表示它认为这个框和真实框有多接近
-
在深度学习的目标检测任务中,置信度是由网络的输出层(通常包括卷积层、池化层和全连接层等)共同作用的结果
-
在目标检测任务中,通常涉及到三种类型的置信度:目标存在置信度、类别置信度、综合置信度
| 类型 | 计算对象 | 核心作用 | 是否依赖 GT? |
|---|---|---|---|
| 真实 IoU | 预测框 ↔ GT 框 | 训练时衡量定位精度 | 是(仅训练) |
| 预测 IoU | 预测框 ↔ (模型估计的)GT 框 | 推理时估计定位精度 | 否(仅推理) |
| 推理时的 pairwise IoU | 预测框 A ↔ 预测框 B | NMS 中去重重复预测框 | 否(仅推理) |
| 类型 | 含义 |
|---|---|
| 目标存在置信度 | 表示当前预测框中存在目标物体的概率(不管是什么类别) |
| 类别置信度 | 表示当前框中的物体属于某个类别的概率(如"猫"、"狗"、"人"等) |
| 综合置信度 | 最终输出的置信度,等于目标存在置信度 × 类别置信度 |
| 阶段 | 置信度的计算方式 | 说明 |
|---|---|---|
| 训练阶段 | 使用真实框(Ground Truth)计算 IoU | 模型通过对比预测框与真实框,学习如何提升置信度 |
| 预测阶段 | 模型无法访问真实框,置信度完全由网络直接输出 | 通过设置置信度阈值(如 0.5)过滤低质量预测框,再通过 NMS 去除重复框 |
2.6.4混淆矩阵
-
混淆矩阵是一种用于评估分类模型性能的表格形式,特别适用于监督学习中的分类任务。它通过将模型的预测结果与真实标签进行对比,帮助我们直观地理解模型在各个类别上的表现
-
在混淆矩阵中:
-
列(Columns) :表示真实类别(True Labels)
-
行(Rows) :表示预测类别(Predicted Labels)
-
单元格中的数值:表示在该真实类别与预测类别组合下的样本数量
-
-
在目标检测任务中,混淆矩阵的构建依赖于 IoU 阈值,因为 IoU 决定了哪些预测被认为是"正确检测",从而影响 TP、FP、FN 的统计,最终影响混淆矩阵的结构和数值
|-----------|-----------|-----------|
| | 实际为正类 | 实际为负类 |
| 预测为正类 | TP(真正例) | FP(假正例) |
| 预测为负类 | FN(假反例) | TN(真反例) |
2.6.5精确度和召回率
-
精确度(Precision):在所有预测为正类的样本中,预测正确的比例,也称为查准率
-
召回率(Recall):在所有实际为正类的样本中,预测正确的比例,也称为查全率
-
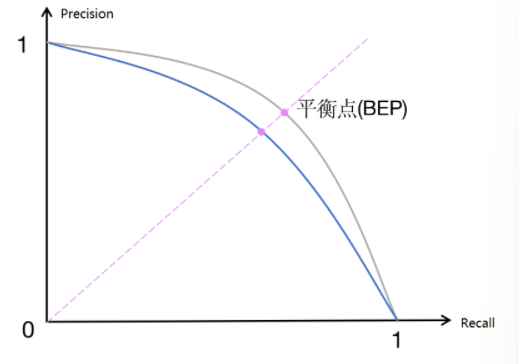
准确度、精确度、召回率、F1 分数在机器学习中已经讲过,定义和公式如下图:

- 混淆矩阵在目标检测中的 TP、FP、FN、TN 的含义:
| 类型 | 定义 | 通俗解释 | 示例 |
|---|---|---|---|
| TP(True Positive) 真正例 | 预测类别正确,且预测框与真实框的 IoU ≥ 阈值 | 模型正确识别了目标,位置也大致准确 | 模型预测这是一个"猫",IoU=0.85,确实是一只猫 |
| FP(False Positive) 假正例 | 两种情况: 1. 类别错误:预测类别错误,即使 IoU ≥ 阈值 2. 类别正确,但 IoU < 阈值 | 模型误以为检测到了目标,但实际上错了 | 模型预测该物体为"猫",且预测框与真实框的 IoU 为 0.4,但实际类别为"狗";或者模型预测为"猫",IoU 为 0.3,类别虽然正确,但定位精度未达到设定的阈值 |
| FN(False Negative) 假反例 | 真实存在目标,但模型没有检测出来 | 模型漏掉了真实目标 | 图片里有一只猫,但模型没检测到 |
| TN(True Negative) 真反例 | 图像背景区域被正确识别为"无目标" | 模型没有把背景误认为是目标 | 图像背景区域没有预测框,模型正确识别为"无物体" |
2.6.6mAP(重要)
2.6.6.1PR曲线
-
就是根据不同阈值下计算出来的每一对**(r, p)【召回率作为横坐标,精确度作为纵坐标】**,假设有 n 组(r,p)数据,那么是不是可以得到 n 个这样的坐标点,把这些点连接起来,形成一条曲线,这条曲线就是 PR 曲线
-
PR 曲线的生成过程:
-
对于每个样本,模型会输出一个预测分数或置信度,表示该样本属于某一类别的概率
-
设定多个置信度阈值:通常会设定一系列的置信度阈值,比如从 0 到 1,每隔 0.1 设置一个阈值,这些阈值将用于决定哪些预测被视为"正例"(Positive),哪些被视为"负例"(Negative)
-
对于每一个阈值,根据预测分数与该阈值的比较结果,我们可以计算出当前阈值下的精确率(Precision)和召回率(Recall)
-
将每个阈值下的精确率和召回率作为坐标点,绘制在二维平面上,横轴为召回率 ,纵轴为精确率,从而形成一条曲线
-
2.6.6.2AP
-
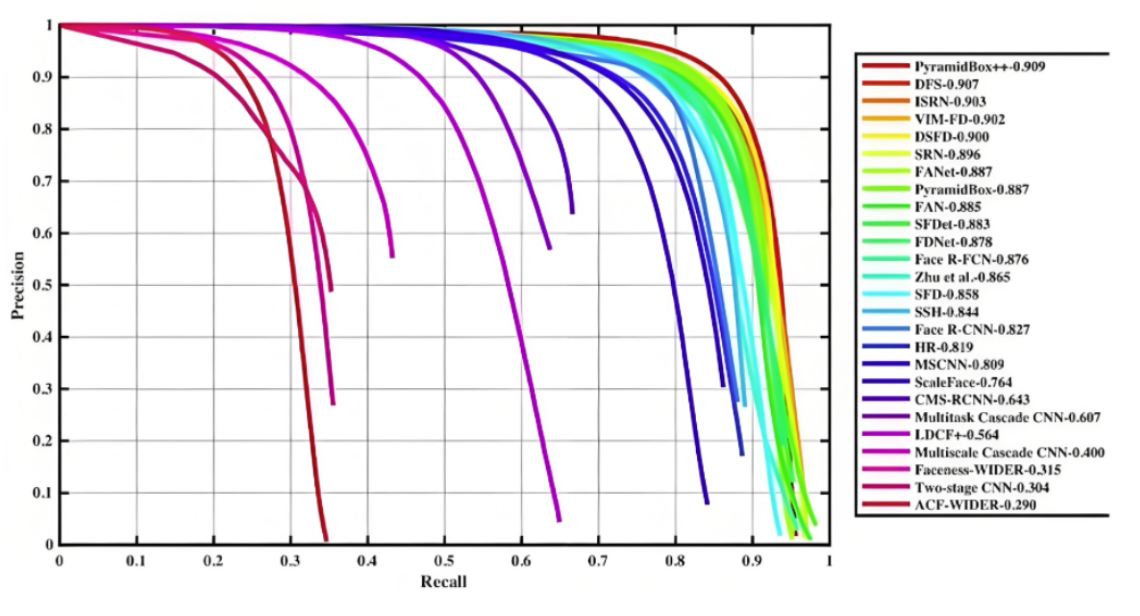
PR 曲线和坐标轴围起来的面积,叫做 AP(平均精确度),他衡量的是某一个类别的指标信息,越大越好(值越接近 1 越好 )
-
AP 就是用来衡量一个训练好的模型在识别某个类别时的表现好坏。AP 越高,说明模型在这个类别上的识别能力越强
2.6.6.3AP计算(了解)
- 11 点插值法:只需要选取当 Recall >= 0, 0.1, 0.2, ..., 1 共11个点,找到所有大于等于该 Recall 值的点,并选取这些点中最大的 Precision 值作为该 Recall 下的代表值,然后 AP 就是这 11 个 Precision 的平均值

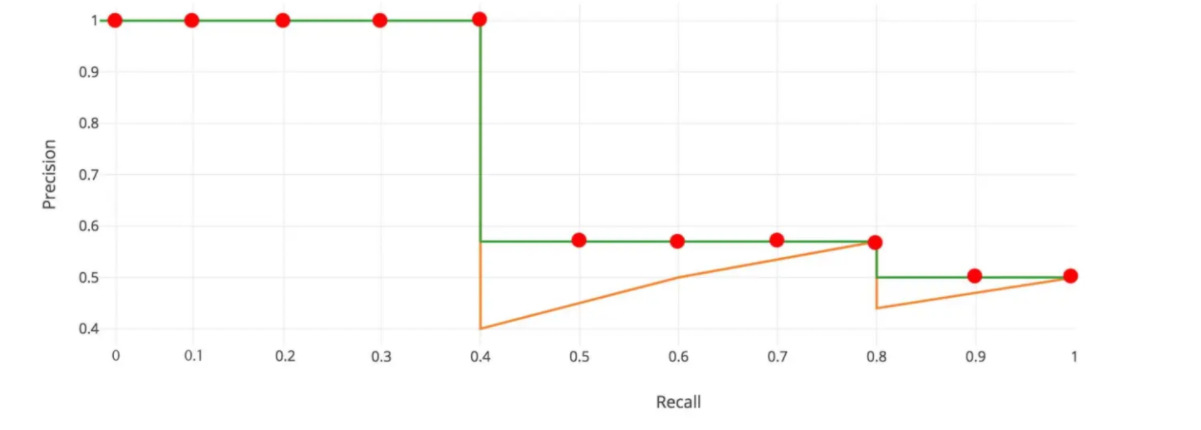
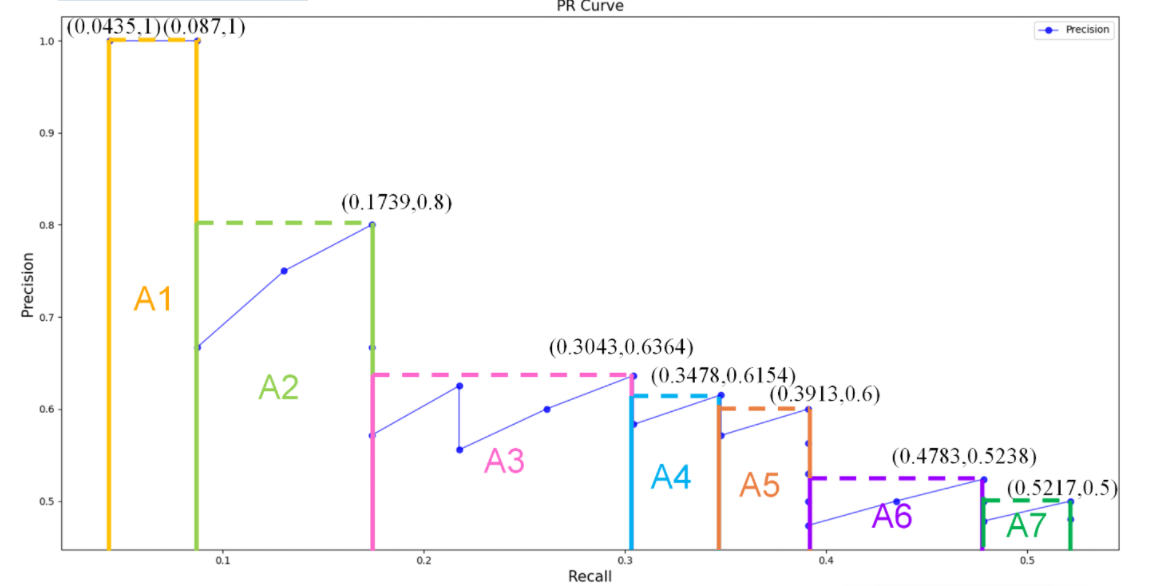
- 面积法:需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些 Recall 值时的 Precision 最大值,然后计算 PR 曲线下面积作为 AP 值,假设真实目标数为 M,recall 取样间隔为 0, 1/M, ..., M/M,假设有 8 个目标,recall 取值 = 0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0

2.6.6.4mAP
- 平均平均精度(mean Average Precision,mAP) 是在不同置信度阈值下计算的平均精确度(Average Precision, AP)的平均值AP 是在不同召回率水平下的精确度平均值,而 mAP 则是多个类别上的 AP 的平均值
| 名称 | 含义 | 说明 |
|---|---|---|
| AP(Average Precision) | 衡量模型在某一类别上的检测或分类性能 | 通过 Precision-Recall 曲线下的面积来计算,值越高表示模型在该类别上的性能越好 |
| mAP(mean Average Precision) | 模型在所有类别上的 AP 的平均值 | 衡量模型整体性能的综合指标,值越高表示模型在所有类别上的平均表现越好 |
mAP 计算步骤:
-
计算每个类别的 AP:对于数据集中包含的每个类别,分别计算 AP
-
计算 mAP:将所有类别的 AP 取平均值,得到 mAP
2.7NMS后处理技术
-
非极大值抑制(Non-Maximum Suppression,NMS) 是目标检测任务中常用的后处理技术 ,用于去除冗余的边界框(Bounding Boxes) ,保留最有可能的检测结果
-
图片通过 yolo 模型,输出的结果里面会有很多个框BB(一个目标就有很多个框BB),但是我们最终看到的结果里面,一个目标只有 1 个框,原因就是因为多余的框都被过滤掉了,一共要经过两次过滤:
-
第一次过滤:设置置信度阈值,如果输出的 BB 的置信度得分 < 阈值,那么直接舍弃这些框 BB【这个过程就为 NMS 过滤减轻了计算压力】
-
第二次过滤:设置 IOU 阈值,首先需要把不同的类别分别进行处理,把这个类别的 BB 中的置信度按照从大到小的方式排序,取出最大置信度最大的这个 BB,然后使用其他的 BB 和这个 BB 做 IOU,如果的出来的 IOU 的值大于等于设置的 IOU 阈值,应该舍弃,否则保留
-
NMS 的基本思想是:对于每一个预测的类别,按照预测边界框的置信度(Confidence Score)对所有边界框进行排序,然后依次考虑每个边界框,将其与之前的边界框进行比较,如果重叠度过高,则丢弃当前边界框,保留置信度更高的那个,对于每个类别会独立进行操作
-
NMS 的步骤:
-
设定目标框置信度阈值,常设置为 0.5,小于阈值的目标框被过滤掉
-
将所有预测的满足置信度范围的边界框按照它们的置信度从高到低排序
-
选取置信度最高的框(不同类型分开处理)添加到输出列表,并将其从候选框列表中删除
-
对于当前正在考虑的边界框,计算其与前面已选定的边界框的重叠程度(IoU),如果当前边界框与已选定边界框的 IoU 大于某个阈值(如 0.5),则将其抑制(即不保留,重合度过高);否则保留当前边界框,并继续处理下一个边界框
-
重复上述步骤,直到所有边界框都被处理完毕
-
输出列表就是最后留下来的目标框
-

-