数据预处理6.1.1
数据预处理是指对数据进行一定规则的处理,使其更易于后续的分析和计算处理。预处理分为离线预处理与在线预处理。
离线预处理指对数据事先进行手工处理。在数据集不够好的时候,通过人为对数据进行干预,使数据更易于模型的学习。其中包括人工指定规则进行的数据清理,如使用 cleanlab 等工具、算法或手工清洗噪音样本(noisy label)、类别合并、相近或重复的样本删除、异常样本删除、大图像进行ROI Crop(剪切图像中无关区域)等;对于类别不平衡的数据进行过采样或欠采样来调整分布;离线图像增强,如intensity normalization、高通滤波、颜色增强等。
在线预处理指在训练和推理时,提前对载入的图像进行一定的处理,使之符合网络的输入格式或加快收敛速度。
下面的代码给出了一个简单的基于torchvision 的图像在线预处理示例。
6.1.2 数据增强
数据增强是一种通过对原始数据进行变换组合等的操作,产生更多的数据来人工扩展训练数据集的技术。深度学习模型一般需要足够的训练数据进行训练,在数据有限时,通过数据增强策略可以大大扩充数据量,在实战中往往能够显著地提高训练的效果。
下面介绍几种常见的数据增强方法和对应代码。
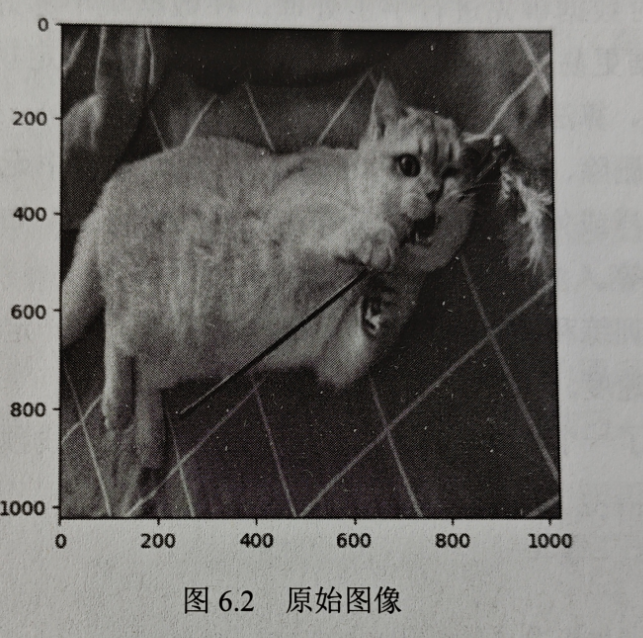
图 6.2所示为原始图像,下面将展示经过一系列数据增强后得到的图像以说明不同数据增强方法的原理。
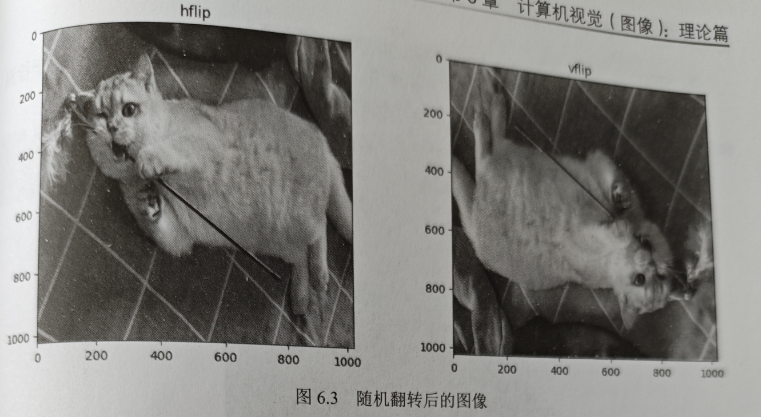
- flip
对图像应用随机的水平/垂直翻转,代码如下

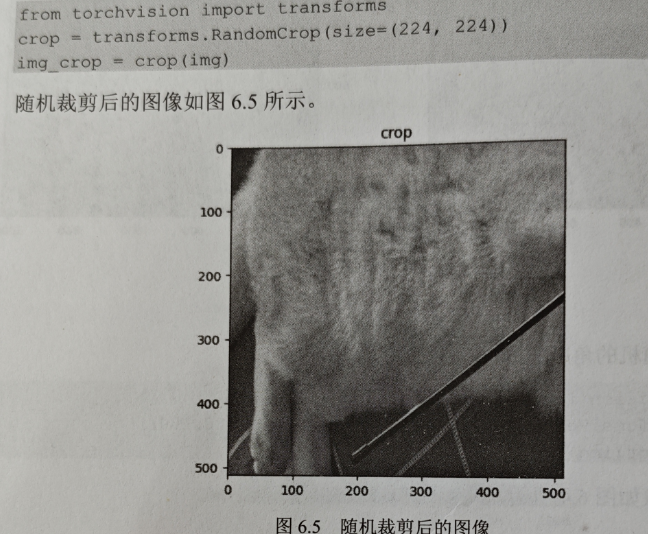
增强后的图像如图 6.3 所示。
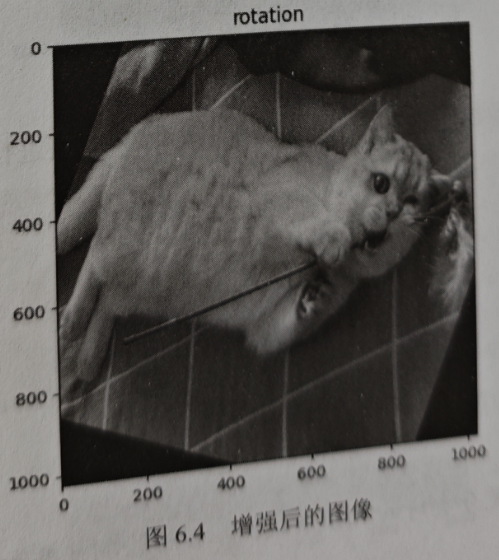
- rotation
对图像应用随机的角度旋转,代码如下。

增强后的图像如图 6.4 所示。
- crop
对图像进行随机的裁剪,这种做法可能会影响图像本身的语义信息,注意,对于检》和分割任务,应当对label进行同样的裁剪,代码如下。
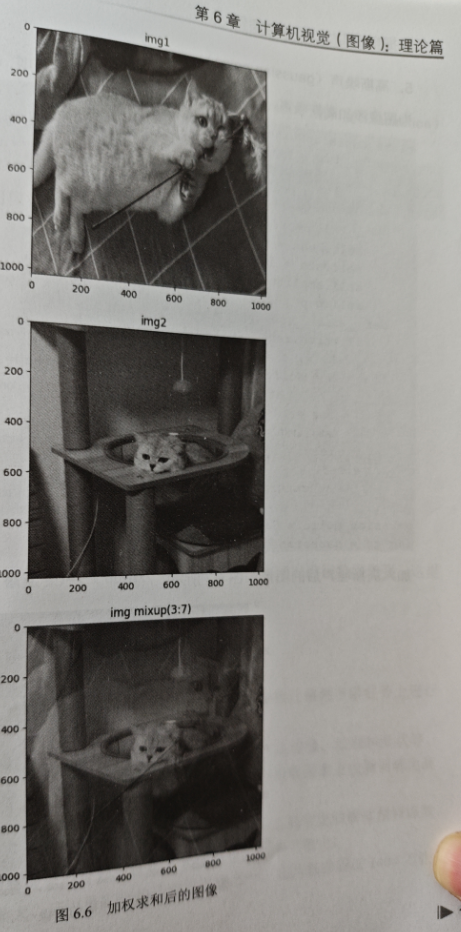
4.mixup
叠加两张不同的图像加权求和,并将1abel 以相同的权重进行叠加,代码如下

注意:
这里举例的 mixup 是分类时的混合方式,在目标检测任务和语义分割任务中,mixupⅫ暫喉样适用。
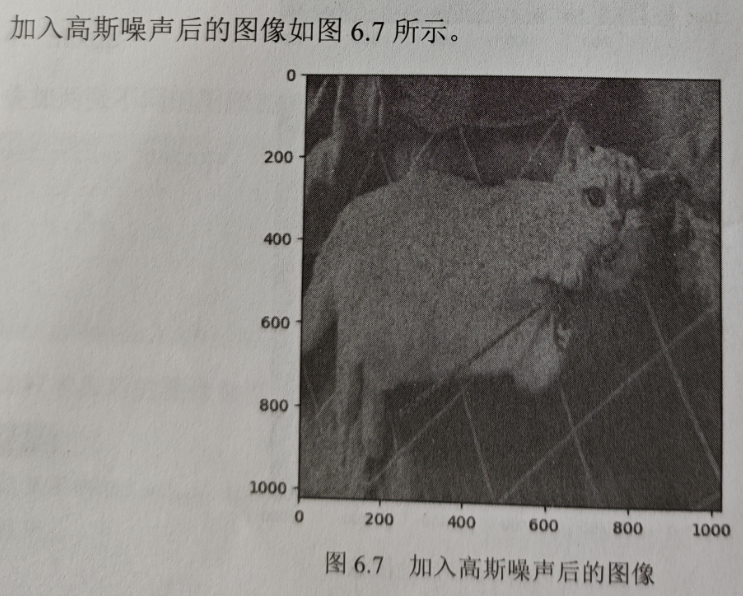
5.高斯噪声(gaussian noise)
为图像添加高斯噪声,代码如下。

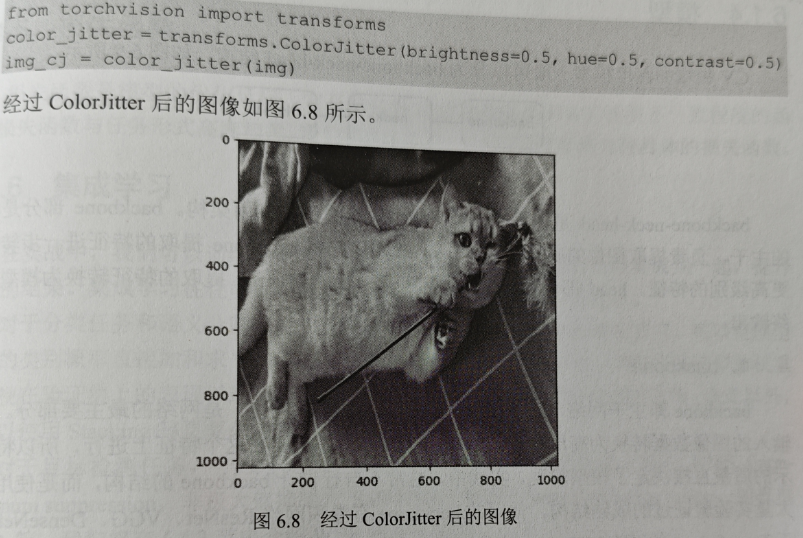
- ColorJitter
随机改变图像的属性,如亮度(brightness)、对比度(contrast)、饱和度(saturation和色调(hue),代码如下
除此以外,高斯模糊、椒盐噪声、CutMix、Mosaic 等方法也可以进行数据增强,这里不再详述。
6.1.3 预训练
预训练是指先将模型在其他较大数据集上训练,再将模型参数迁移到下游任务上进行
在大型数据集上预训练的模型已经学会了通用的图像特征,如边缘、纹理和形状等微调它可以帮助加快网络的收敛速度、提升泛化能力,使得在下游小型数据集上也能训练出高
根据任务的不同,使用的预训练数据集有所不同,ImageNet是最常用的视觉预训练数质量的模型训练数据集。有时也可设计如自监督或无监督预训练任务来提高模型的表示能力。ImageNet 是 CV 领域最大、应用最广泛的开源数据集之一。它共包含超过 1400 万张手动标准的图像。


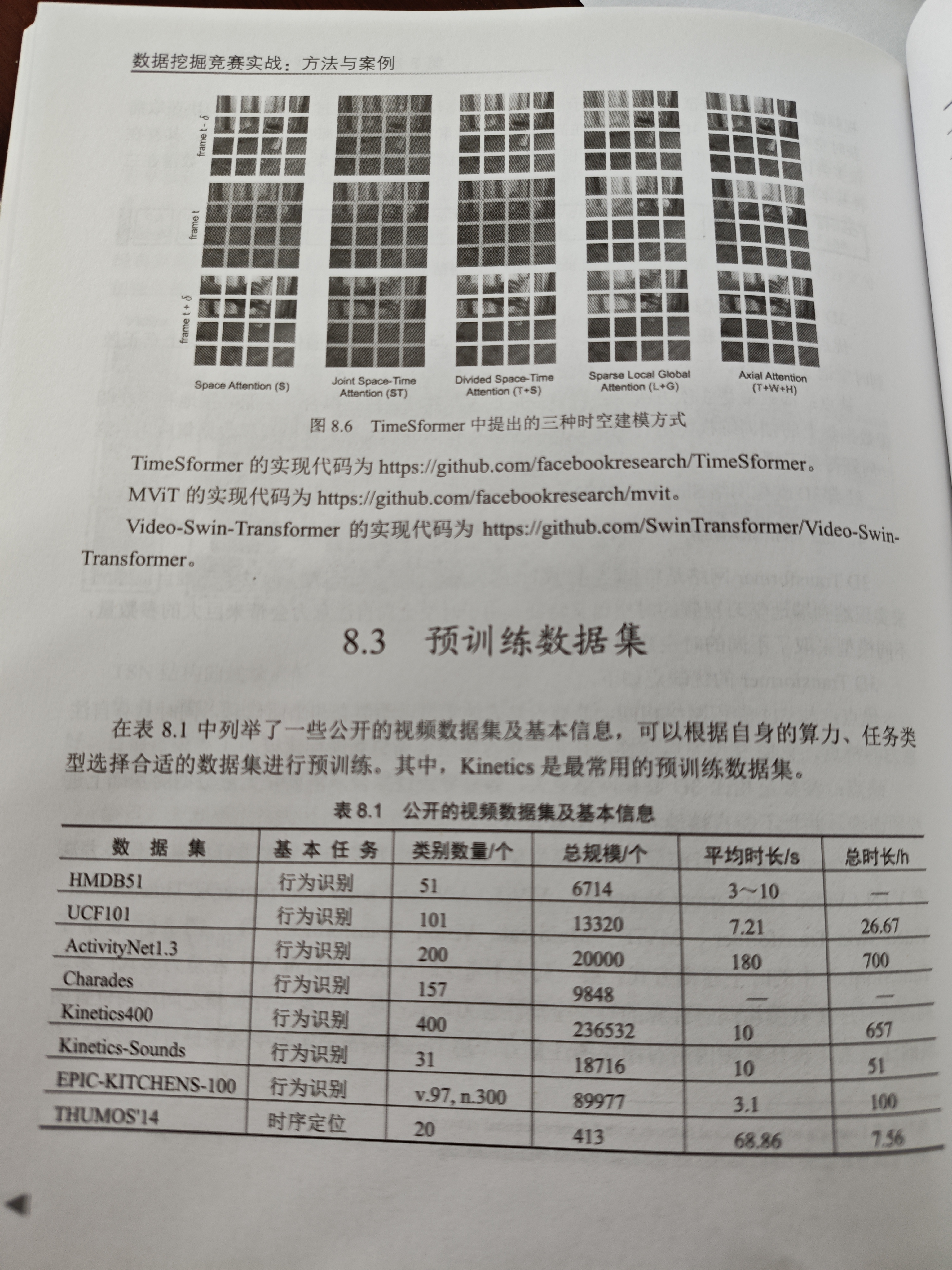
3D Transformer