开始总结一下这部分机器学习的算法模型知识,从GBDT开始。
先一句话总结学习完对GBDT的理解:每次训练一棵浅决策树,去拟合当前模型在损失函数上的负梯度(错误信号),用学习率控制每棵树的贡献,通过 M 轮串行迭代,将所有树的预测结果相加,最终得到一个强模型。
一、GBDT 的定位
GBDT 在机器学习体系中的位置 ------ 它属于集成学习(Ensemble Learning) 中的Boosting(提升学习) 分支,核心是通过 "串行训练弱学习器、逐步纠正错误" 来构建强模型。
几个关键前提概念:
- 集成学习:将多个 "弱学习器"(预测效果略优于随机猜测的模型)组合,形成 "强学习器",降低单模型的偏差或方差。
- Boosting 和 Bagging :
- Bagging(如随机森林):并行训练多个独立弱学习器,通过 "投票 / 平均" 降低方差(抗过拟合);
- Boosting(如 GBDT、AdaBoost):串行训练弱学习器,后一个模型专门纠正前一个模型的 "预测错误",通过逐步降低偏差提升精度。
- GBDT 的 "组件" :
- 基学习器(弱学习器):几乎只用深度较浅的决策树(如 CART 树,称为 "回归树",即使做分类任务也用回归树拟合);
- 核心逻辑:梯度提升(用 "梯度下降" 的思想优化损失函数,而非 AdaBoost 的 "样本权重更新")。
二、GBDT 的核心:"梯度下降 + 加法模型"
即"用梯度下降法最小化损失函数,通过加法模型逐步累积弱学习器"。
1. 加法模型:模型是 "弱学习器的加权和"
GBDT 的最终预测模型是多个弱学习器(决策树)的预测结果相加,数学表达式为: 对于样本 x,最终预测值:
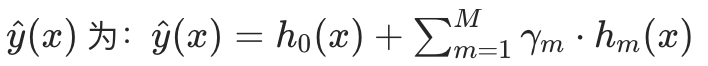
其中:
:初始模型 (最简单的模型,通常是 "所有样本真实标签的均值",如回归任务中,
是 "加法模型"的原因:Boosting是 "逐步优化",每次只新增一个弱学习器,不修改已训练好的模型(前向分步学习),所以只能用 "加法" 累积预测结果。
2. 梯度提升:用 "负梯度" 近似 "预测错误"
GBDT 的核心创新是:用 "损失函数对当前模型预测值的负梯度",作为 "需要纠正的错误信号",然后用弱学习器(决策树)拟合这个 "错误信号"。
| 概念 | 定义 | 适用场景 |
|---|---|---|
| 残差 | 真实标签 |
仅当损失函数是 MSE(均方误差) 时,残差 = 负梯度 |
| 负梯度 | 损失函数 |
通用场景(适用于任何损失函数,如分类任务的 LogLoss、回归任务的 MAE) |
比如当前任务是回归 ,用 MSE 作为损失函数:
- 损失函数对
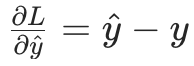 ;
; - 负梯度就是
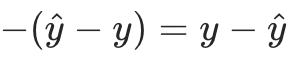 ,恰好等于残差。
,恰好等于残差。
即"回归任务中 GBDT 常说'拟合残差'"------ 本质是 MSE 损失下负梯度等于残差;但如果是分类任务(如用 LogLoss),负梯度就不等于残差了,此时必须用 "负梯度" 作为拟合目标。
梯度提升的核心逻辑: 每次训练新的弱学习器时,不直接拟合 "真实标签",而是拟合 "当前模型在损失函数上的负梯度"------ 相当于让新模型 "学习如何修正前一个模型的错误",最终通过多轮修正让损失函数最小化。
三、GBDT 的训练流程拆解
以回归任务(MSE 损失) 为例,假设训练 M 棵决策树,每一步的具体操作如下(分类任务流程类似,仅损失函数和负梯度计算不同):
步骤 1:初始化初始模型
初始模型是最简单的 "常数模型",目标是让初始损失最小化。 对于 MSE 损失,最优常数是所有样本真实标签的均值:
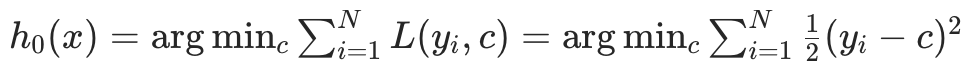
求解得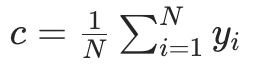 (即样本均值)。
(即样本均值)。
步骤 2:迭代训练 M 棵决策树(核心步骤)
对每一轮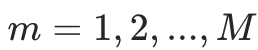 ,执行以下操作:
,执行以下操作:
2.1 计算 "负梯度"(即当前模型的 "错误信号")
对每个样本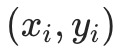 ,计算损失函数对当前预测值
,计算损失函数对当前预测值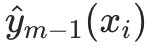 的负梯度,作为 "伪残差"
的负梯度,作为 "伪残差"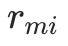 (伪残差 = 负梯度,是新树的拟合目标):
(伪残差 = 负梯度,是新树的拟合目标):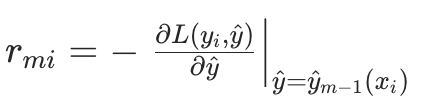
- 若用 MSE 损失:
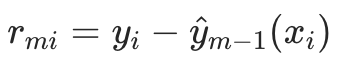 (即真实残差);
(即真实残差); - 若用 LogLoss(二分类):
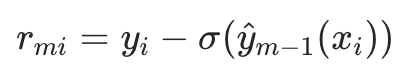 (
(
2.2 用决策树拟合伪残差
将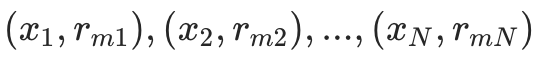 作为新的训练数据,训练一棵回归决策树
作为新的训练数据,训练一棵回归决策树 ,得到树的叶子节点划分(假设树有
个叶子节点,记第
个叶子节点对应的样本集合为
。
⚠️ 关键注意:GBDT 的基学习器必须是回归树,即使做分类任务 ------ 因为分类任务的 "伪残差" 是连续值(如 LogLoss 的负梯度是 0,1 之间的连续值),需要回归树拟合;最终分类结果由 "所有树的预测值之和经过 sigmoid/softmax 映射" 得到。
2.3 计算叶子节点的 "最优权重"
对每个叶子节点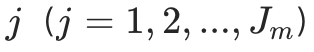 ,计算该节点的最优输出权重
,计算该节点的最优输出权重------ 目标是最小化当前叶子节点上的损失函数(相当于 "微调" 叶子节点的预测值,让损失更小):
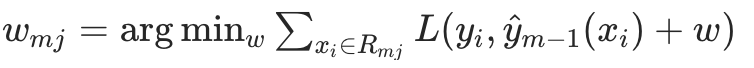
- 若用 MSE 损失:
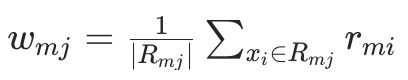 (即该叶子节点上伪残差的均值);
(即该叶子节点上伪残差的均值); - 若用其他损失函数(如 LogLoss):需要通过牛顿法或梯度下降求解
2.4 用 "学习率" 控制新树的贡献
为了防止单棵树的影响过大(避免过拟合),引入学习率 (通常取 0.01~0.1),将新树的权重缩放为
。
学习率的作用:让每棵树只贡献 "一小步" 优化,通过多轮迭代逐步逼近最优解,增强模型的泛化能力(学习率越小,需要的树数量 M 越多)。
2.5 更新模型
将新树的预测结果(缩放后)加入到当前模型中,得到新一轮的预测模型:
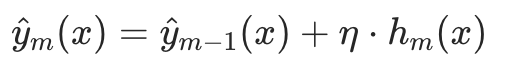
步骤 3:得到最终模型
当 M 棵树全部训练完成后,最终的预测模型为: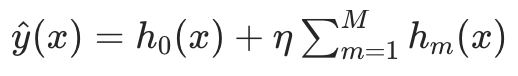
- 回归任务:直接输出
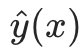 ;
; - 二分类任务:输出
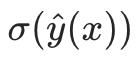 (sigmoid 映射,得到类别 1 的概率);
(sigmoid 映射,得到类别 1 的概率); - 多分类任务:输出
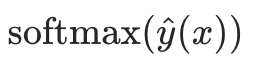 (得到每个类别的概率)。
(得到每个类别的概率)。
四、GBDT 的应用场景与优缺点
1. 核心应用场景
GBDT 是工业界常用的 "万能模型" 之一,主要用于以下任务:
- 回归任务:预测连续值(如房价、销量、用户消费金额);
- 分类任务:二分类(如用户是否点击广告、是否违约)、多分类(如图像分类、文本分类);
- 排序任务:CTR 预估(点击率预测)、推荐系统(对物品排序)、搜索结果排序(如百度搜索的结果权重)------ 因为 GBDT 能有效捕捉特征的非线性关系,对排序的 "相对顺序" 优化效果好。
2. 优势
- 强非线性拟合能力:通过多棵决策树的组合,能捕捉特征与标签之间复杂的非线性关系(比线性模型如 LR 强);
- 自带特征重要性:可以直接输出每个特征的重要性(通过特征在决策树中被分裂的次数、分裂带来的损失减少量衡量),方便特征选择和模型解释;
- 鲁棒性较强:相比单棵决策树,通过集成和正则化,抗过拟合能力更强(但对异常值敏感,需注意);
- 不依赖特征归一化:决策树的分裂不依赖特征的尺度,因此 GBDT 不需要对特征做归一化 / 标准化(比 SVM、神经网络方便)。
3. 局限性(什么时候不适合用 GBDT?)
- 对异常值敏感:因为 GBDT 是 "串行纠正错误",异常值会导致前序模型的预测偏差很大,后续模型会过度关注异常值,影响整体效果(可通过预处理去除异常值,或用 MAE 损失替代 MSE);
- 训练速度慢:串行训练(每棵树依赖前一棵的结果),无法像随机森林那样并行训练(后续的 XGBoost、LightGBM 通过优化并行化了部分步骤,但核心逻辑仍是串行);
- 容易过拟合:若树的深度过深、树的数量过多、学习率过大,容易对训练集过拟合(需通过正则化控制);
- 高维稀疏数据表现一般:在高维稀疏特征(如文本的 One-Hot 特征)上,效果不如 LR、FM(因子分解机)等模型。
五、 GBDT 的一些坑
1. 基学习器为什么是 "浅决策树"?
GBDT 的基学习器必须是弱学习器(深度通常 3-5 层,叶子节点数 10-30 个),原因:
- 若用深度很深的决策树(强学习器),单棵树就能拟合大部分数据,后续树的纠正空间小,容易过拟合;
- 弱学习器的 "偏差高、方差低",通过多轮集成可以逐步降低偏差,同时保持低方差(符合 Boosting "降低偏差" 的核心目标)。
2. 正则化:如何防止 GBDT 过拟合?
GBDT 的过拟合主要来自 "树太多、树太深、对训练数据过度拟合",常用正则化手段有 4 种:
| 正则化手段 | 作用 | 具体操作 |
|---|---|---|
| 学习率 |
降低单棵树的贡献,迫使模型通过多轮迭代优化 | 取小值(0.01~0.1),同时增加树的数量 M |
| 树的深度限制 | 控制单棵树的复杂度,避免过拟合 | 限制 max_depth(如 3-5)、max_leaf_nodes(如 10-30) |
| 子采样(Row Sampling) | 每次训练树时,随机采样一部分样本(无放回) | 采样比例 subsample=0.8~0.9(类似随机森林的样本采样,增加多样性) |
| 特征采样(Column Sampling) | 每次分裂时,随机采样一部分特征 | 采样比例 colsample_bytree=0.8~0.9(减少特征相关性,增加多样性) |
3. GBDT 与 XGBoost、LightGBM 的区别
很多人会混淆这三个模型,核心区别是:XGBoost、LightGBM 是 GBDT 的 "优化升级版本",而非全新算法。三者的关系如下:
- GBDT(基础版):仅用损失函数的一阶导数(梯度)优化,无显式正则化(需手动控制树深、学习率),训练速度慢;
- XGBoost(优化版) :
- 引入损失函数的二阶导数(Hessian),优化更精准(牛顿法优化,比梯度下降快);
- 加入显式正则化项(如树的复杂度惩罚),抗过拟合能力更强;
- 支持并行化(特征分裂的计算并行),训练速度比 GBDT 快;
- LightGBM(更高效版) :
- 采用 "直方图优化"(将连续特征离散为直方图,减少分裂时的计算量),训练速度比 XGBoost 快 10-100 倍;
- 采用 "叶子节点优先分裂"(而非 XGBoost 的 "深度优先"),更高效;
- 支持更多并行策略(如特征并行、数据并行)。
总结一下就是:GBDT 是 "原理基础",XGBoost 是 "工程优化",LightGBM 是 "速度优化"。
4. 常见误区
-
❌ 误区 1:GBDT 的残差就是真实残差。 ✅ 正确:只有当损失函数是 MSE 时,负梯度 = 真实残差;其他损失函数(如 LogLoss、MAE)的负梯度是 "伪残差",不等于真实残差。
-
❌ 误区 2:GBDT 可以并行训练。 ✅ 正确:GBDT 的树训练过程是串行的(后一棵树依赖前一棵树的伪残差),无法并行;但 XGBoost、LightGBM 通过 "特征分裂计算并行""数据并行" 等方式,优化了训练效率,但核心的 "树迭代顺序" 仍是串行。
-
❌ 误区 3:GBDT 的树数量 M 越多越好。 ✅ 正确:M 过大时,模型会对训练集的噪声过度拟合,导致测试集效果下降;需通过交叉验证选择最优 M(通常几百到几千)。
六、其他
-
个人感觉要先看一下"决策树(CART 树)" 和 "集成学习(Bagging/Boosting)" 的基本原理 毕竟GBDT 的基学习器是 CART 树,核心逻辑是 Boosting(后续再补吧)。
-
另外要实践一下"初始模型→计算残差→拟合树→更新模型" 的完整流程,感觉业务场景的调参也存在一些坑不易解释。