摘要:
截至2025年,大型语言模型(LLM)已展现出惊人的能力,但其内在的"黑箱"特性和对深层语义理解的局限性也日益凸显。本报告旨在深入探讨一个充满潜力的前沿交叉领域:借鉴地球上最古老、最精密的语言处理器------人类大脑的运行机制,来指导下一代NLP技术的发展。我们将系统性地分析五个关键的交汇点:预测编码理论、语义角色标注的神经基础、词义表征的脑机共鸣、基于效价-唤醒度的情感分析,以及隐喻理解中的具身认知。通过整合最新的神经科学发现与NLP工程实践,本报告将揭示神经科学为NLP工程师绘制的这张"藏宝图",如何引领我们走向更深邃、更类人的机器智能。
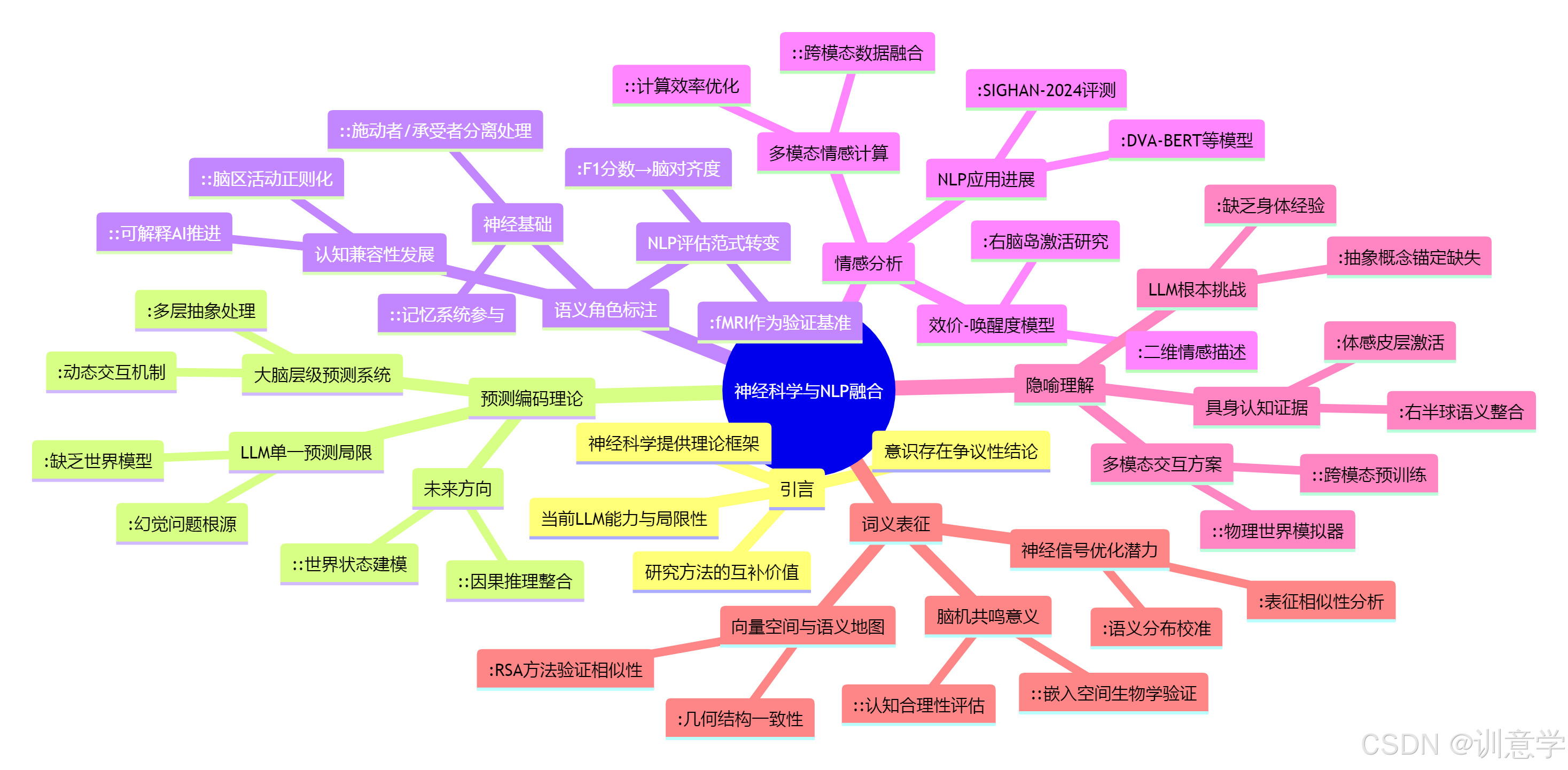
引言:从模仿文本到理解世界
现代NLP,尤其是以Transformer架构为核心的大型语言模型,其根本任务是基于海量文本数据预测序列中的下一个词 。这一范式无疑是成功的,它催生了GPT-4、BERT等一系列强大的模型 。然而,这种成功也带来了一个根本性的问题:这种基于统计规律的"模仿"是否等同于真正的"理解"?人类在处理语言时,远不止于预测下一个词,我们会构建复杂的意义网络、理解事件的因果逻辑、感受细腻的情感,并通晓抽象的隐喻。
为了突破当前模型的瓶颈,研究者们将目光投向了神经科学。大脑,这个经过数百万年进化而成的"黑箱",为我们提供了一个无与伦比的参照系。通过功能性磁共振成像(fMRI)、脑电图(EEG)等技术,我们得以窥见大脑在处理语言时的精妙运作。本报告将逐一剖析神经科学在关键NLP任务上的启示,探索如何将这些生物学洞见转化为可行的计算模型,从而开启一场从"文本模仿"到"世界理解"的范式革命。
一、 深层语义分析:超越"下一个词"的预测编码理论
1.1 理论基础:大脑中的多层次预测系统
当前LLM的核心机制可以被视为一种预测形式,即预测下一个词元 。然而,神经科学中的"预测编码"(Predictive Coding)理论揭示了一个远为复杂的图景。该理论认为,大脑是一个主动的预测机器,它不仅在底层预测即将到来的感官信号(如词语),更在认知的高层不断生成和修正关于世界状态的抽象预测(如事件的意义、对话的意图)。语言理解是一个自上而下(高层意义预测)与自下而上(感官信息输入)不断交互、验证、修正期望的动态过程。这意味着,大脑的语言处理是构建在一个从具体到抽象的意义阶梯之上的。
1.2 NLP的现状与挑战:从单一预测到层级推理的鸿沟
尽管"预测"是LLM训练的核心,但其现有的训练目标,如掩码语言模型(MLM)或下一句预测(NSP),大多停留在文本表层 。这些模型缺乏一个明确的、类似大脑的预测层级结构来处理抽象意义。
截至2025年,尽管预测编码的理论在神经科学界和认知科学界对语言的解释力越来越强 但在主流NLP模型中,我们尚未看到其具体的、成型的架构设计或实现 (Query: What are the specific architectural designs for NLP models implementing predictive coding theory in 2025?)。相关的搜索查询显示,目前还没有名为"预测编码模型"并能在标准NLP基准(如GLUE, SuperGLUE)上取得优异性能的具体模型被广泛报道 ; Query: What are the names of specific NLP models that have successfully integrated predictive coding as of 2025...?)。这表明,将这一精妙的神经理论转化为高效的计算架构,仍然是NLP领域面临的重大挑战和未来重要的研究方向。
1.3 未来展望:构建具备世界模型的NLP
预测编码理论对NLP的终极启示在于,未来的模型需要超越单纯的文本序列预测,构建一个能够预测抽象概念和世界状态的内部模型。这意味着模型不仅要学习语言的统计规律,更要学习语言所描述的世界的因果、物理和社会常识。这可能是通往解决LLM"幻觉"问题 和实现真正推理能力的关键路径。
二、 语义角色标注(SRL):解码大脑中的"事件剧场"
2.1 神经基础:"谁对谁做了什么"的生物学证据
语义角色标注(SRL)是NLP的一项核心任务,旨在识别句子中的谓词-论元结构,即"谁(施动者)对谁(承受者)做了什么" 。这看似是一个纯粹的语言学任务,但fMRI研究发现,它在大脑中有着清晰的生物学对应。当人们处理"施动者"(Agent)和"承受者"(Patient)时,被激活的神经区域存在显著差异。特别是处理事件的承受者时,大脑会调动更广泛的认知和记忆相关脑区,仿佛在大脑中为不同的语义角色分配了不同的"演员"和"舞台"。
2.2 NLP的实践:从验证到评估的新范式
在NLP领域,基于神经网络,特别是深度学习模型(如RNN、LSTM和Transformer)的SRL方法已经成为主流,并取得了显著的性能 。这些模型能够自动学习复杂的句法和语义特征,极大地提升了标注的准确性。
然而,神经科学的洞见为SRL研究开辟了一个新的维度。截至2025年,我们尚未发现有研究成功地将fMRI数据作为直接输入来"整合"进SRL模型以提升其在传统NLP指标(如F1分数)上的性能 (Query: How is fMRI data integrated into semantic role labeling models to improve performance in NLP?; Query: 2025年基于fMRI的语义角色标注模型在NLP任务中的准确率提升百分比是多少?)。相反,研究的焦点转向了一个更深刻的问题:NLP模型的内部表征与大脑的神经活动模式有多相似?
"Neural Language Taskonomy"等前沿研究项目发现,不同的NLP任务在预测大脑活动方面的能力各不相同,而SRL恰恰是其中与大脑语言处理区域活动高度相关的任务之一 。这意味着,一个在SRL任务上表现优异的模型,其内部形成的对事件结构的表征,在某种程度上模拟了大脑的处理方式。因此,fMRI数据正在从一个潜在的"训练特征"转变为一种全新的"评估基准" 。我们可以通过比较模型在处理相同句子时产生的内部激活模式与fMRI记录的人脑活动模式的相似度,来评估该模型"理解"语义角色的生物学合理性 。
2.3 未来展望:迈向认知兼容的SRL
这一转变意义重大。它意味着未来的SRL模型设计,除了追求更高的F1分数外,还将追求更高的"大脑对齐度"(Brain Alignment)。通过将神经科学数据作为模型评估乃至正则化的一部分,我们有望开发出不仅准确,而且其决策过程更符合人类认知习惯的SRL系统,这对于构建可解释、可信赖的AI至关重要。
三、 情感分析:构建更细腻的二维情感罗盘
3.1 神经基础:超越褒贬的效价-唤醒度模型
传统的情感分析通常将情感划分为"积极"、"消极"、"中性"等离散类别 。然而,人类的情感体验远比这丰富。"狂喜"和"宁静"同为积极情绪,但其生理和心理状态截然不同。神经科学研究普遍采用"效价-唤醒度"(Valence-Arousal, VA)二维模型来更精确地描述情感 。其中,"效价"衡量情感的愉悦程度(从积极到消极),"唤醒度"衡量情感的强度(从平静到激动)。fMRI研究进一步揭示,大脑在处理这两个维度时调用了不同的神经回路,例如右侧脑岛在处理效价和唤醒度冲突的情感(如高唤醒度的积极情绪)时会表现出特殊激活。
3.2 NLP的进展:维度情感分析的兴起
受此启发,NLP领域近年来大力发展"维度情感分析"(Dimensional Sentiment Analysis),直接预测文本所表达情感的效价和唤醒度数值 。这一领域在2025年已取得长足进步。研究者们利用BERT等大型预训练模型作为基础,开发出专门用于VA预测的模型,如DVA-BERT ,并在专门标注了VA值的语料库(如Chinese EmoBank)上进行训练和评估 。SIGHAN-2024等学术评测也设立了相关的任务,推动了技术的发展 。
3.3 工具、挑战与效率
目前,已有多种工具和框架可用于实现VA情感分析。虽然VADER(其名称本身即意为"效价感知词典和情感推理器")等传统工具提供了基础 但基于深度学习的方法正成为主流 。
然而,这一方向也面临着挑战。首先是高质量VA标注数据的稀缺性和主观性问题 。其次是计算成本。与传统的分类模型相比,基于大型模型的VA回归模型通常计算成本更高。有研究提出,可以采用传统机器学习与VA模型结合的两阶段分层系统,在保持较好性能的同时降低对计算资源的需求,这为资源受限场景提供了解决方案 。
3.4 未来展望:通往精细化情感智能
基于VA模型的维度情感分析,使机器能够更细腻地捕捉和理解文本背后复杂的人类情感,这在人机交互、心理健康监测、舆情分析等领域具有巨大的应用价值。未来的研究将聚焦于构建更大规模、更高质量的VA语料库,并探索更高效、更鲁棒的多模态(结合文本、语音、视觉)情感分析模型。
四、 隐喻理解:为机器注入"具身认知"
4.1 神经基础:根植于身体经验的抽象概念
隐喻是人类语言创造力和抽象思维的核心。当我们说"抓住一个概念"或"度过了艰难的一天"时,我们并非在进行字面描述。神经科学的"具身认知"(Embodied Cognition)理论为理解这一现象提供了革命性的视角。fMRI研究惊人地发现,当人们理解与触觉相关的隐喻(如"艰难的/rough的一天")时,大脑中负责处理真实触觉的体感皮层会被激活。这有力地证明了我们的抽象概念并非凭空存在,而是深深地根植于我们的身体感知和运动经验之中。此外,大脑右半球在处理新奇隐喻时扮演着关键角色,它负责激活更广泛的语义网络,帮助我们在看似不相关的概念间建立联系。
4.2 NLP的根本性挑战:无"身"之"心"的局限
这一发现对当前主流的NLP模型提出了一个根本性的挑战。LLM通过学习海量文本数据中的词语共现关系来处理语言,它们没有"身体",没有与物理世界交互的感知经验。因此,它们对隐喻的"理解"可能只是一种基于上下文的浅层模仿,而非真正把握其背后基于身体经验的深层含义。在我们的搜索查询中,几乎没有找到关于在NLP模型中成功实现具身认知以进行隐喻分析的具体研究或应用。这表明,截至2025年,该领域仍处于非常初期的探索阶段。
4.3 未来展望:构建多模态、世界交互的AI
神经科学的启示是明确的:要让机器真正理解隐喻,乃至更广泛的抽象概念,仅靠文本学习是远远不够的。未来的研究方向必须走向多模态学习,将语言模型与视觉、听觉、触觉等信息相结合。更进一步,需要为AI构建一个能够与物理世界或高质量模拟环境进行交互的"身体"模型。通过这种方式,AI可以在与世界的互动中,将语言符号与其所指代的感知运动经验"锚定"在一起,从而为抽象概念建立起坚实的"地基"。这不仅是攻克隐喻理解的必由之路,也是通向通用人工智能(AGI)的关键一步。
五、 词义表征:从向量空间到大脑语义地图的映射
最后,我们回到NLP中最基础也最成功的领域之一:词嵌入(Word Embeddings)。该技术将词语映射到高维向量空间,使得意义相近的词语在空间中也彼此靠近 。这种思想与人脑组织语义知识的方式惊人地相似。
神经科学中的"表征相似性分析"(Representational Similarity Analysis, RSA)等方法,可以直接比较不同"系统"(如人脑不同区域、人脑与AI模型)中概念表征的几何结构。多项研究通过这种方法比较了NLP词向量模型中的词间关系矩阵和人脑在处理这些词语时产生的神经活动模式矩阵。结果令人振奋:两者之间存在显著的相关性 。
这意味着,尽管实现机制(硅基芯片 vs. 碳基神经元)天差地别,但为了高效地组织和处理海量的语言信息,人工神经网络"进化"出的语义表征结构,在某种程度上复现了生物大脑的解决方案。这不仅从生物学角度验证了当前词嵌入方法的有效性,也为未来的优化提供了方向。我们可以设想,利用神经信号作为一种"监督"或"校准"信号,直接优化词向量的分布,从而创造出更精准、更符合人类认知的"语义地图"。
结论:一场双向奔赴的智慧探索
从预测编码的理论前沿,到语义角色的认知评估;从情感分析的维度深化,到隐喻理解的具身挑战;再到词义表征的脑机共鸣------神经科学正在为自然语言处理的未来发展提供一张日益清晰的"藏宝图"。
截至2025年,这条探索之路呈现出不均衡的发展态势:
- 较为成熟的共鸣区: 词义表征和维度情感分析,神经科学的洞见已经转化为具体的模型和应用,并取得了显著进展。
- 新兴的评估与验证区: 语义角色标注,神经科学数据更多地被用作评估模型认知合理性的新基准,而非直接提升性能的工具。
- 亟待开垦的前沿区: 预测编码和具身认知(隐喻),相关的神经理论极具启发性,但如何将其转化为可计算、可扩展的NLP模型架构,仍是该领域最艰巨也最激动人心的挑战。
这场神经科学与自然语言处理的交汇,是一场双向奔赴的智慧探索。我们不仅在用大脑的奥秘点亮人工智能的未来,也在用人工智能的工具和模型来反思和验证关于大脑和心智的理论。前路漫漫,道阻且长,但我们有理由相信,沿着这张"藏宝图"前进的每一步,都将让我们离"理解"这一智能的终极本质更近一点。