人类表现出非凡的能力,可以利用末端执行器(手)的灵巧性、全身参与以及与环境的交互(例如支撑)来纵各种大小和形状的物体。 人类灵活性的分类法包括精细和粗略的作技能。尽管前者(精细灵巧性)已在机器人技术中得到广泛研究,但粗大灵活性是一个探索较少的领域。人类和其他灵长类动物的粗大运动技能涉及通过激活包括手臂、躯干和腿在内的大肌肉群来锻炼整个身体。这些技能使人类能够实现日常功能,例如携带杂货袋、在客厅里移动沙发、重新调整沉重的罐子的方向以及抱婴儿(即使是在猩猩的情况下爬树)。在机器人技术领域,长期以来一直在努力复制和整合这些灵巧的人类技能。为了能够对大型和笨重的物体进行全身作,丰田研究院开发了一个名为 Punyo 的硬件平台。Punyo 是一个上半身人形机器人,在坚硬的双臂"骨架"上拥有柔软的"肉"。Punyo 的末端执行器、手臂和胸部覆盖有高度可变形的压力感应材料,因此它可以感觉到接触并做出适当的反应。这种柔软度是由织物覆盖物下的被动顺应性充气气囊提供的,使 Punyo 能够贴合它所接触的表面。因此,通过增加摩擦力和更均匀的力分布来增强接触稳定性。这里介绍的最新版本的 Punyo 还配备了通过关节级导纳控制器的主动顺应,使机器人能够顺应广义外力。使用 Punyo 进行全身作的挑战是多方面的。首先,覆盖机器人的可变形结构难以建模。其次,物体属性,如惯性和摩擦力,是不确定的。第三,在包括与人交互在内的未来下游应用的推动下,Punyo 机器人需要以类似人类的自然运动进行操作,在相关文献中也称为清晰或可解释的运动,以使机器人的行为与人类期望保持一致,并增强感知和实际安全性。此外,对于在开放世界环境中作和快速积累新技能来说,技能获取的最少人工监督是可取的。例如, Punyo 的任务是将一个大盒子移动到所需的姿势。为此,机器人可能首先用双臂将盒子拉向自己,然后用一只手将盒子支撑在躯干上来旋转盒子,最后将其平移,直到达到所需的配置。设计一个框架来系统地规划和控制这种全身纵行为提出了一项艰巨的挑战,这主要是因为接触组合学的复杂性。基于模型的规划方法在接触丰富的领域中面临挑战,其中接触事件导致具有许多离散模式的僵硬和不连续的数字,从而导致非凸和不连接的搜索空间。然而,通过接触进行规划------仅从一个高层次目标中综合复杂的、丰富的接触行为------仍然是一项引人注目且积极追求的挑战。Mordatch 等人的引入接触不变优化,生成灵巧的纵运动。随后的接触隐式优化技术扩展了这一想法,减少了对启发式的依赖并提高了作规划的通用性。最近,采样和基于图的方法在高维空间中表现出了强大的可扩展性和有效的探索。尽管取得了这些进步,但此类方法仍然需要大量计算。规划单个动作可能需要几秒钟到几分钟的时间,这限制了这些方法的实用性,限制在离线设置中,尤其是在处理复杂的接触序列时。一旦生成运动,开环执行对模型参数和物体姿态的不确定性仍然敏感。实现稳健执行需要通过状态反馈来闭环。闭环控制的补充是利用身体顺应性实现的物理智能,这已被证明可以通过机械方式提高接触稳定性来缓解控制问题,并卸载原本会落到高级控制器(例如动物的大脑)上的计算。模仿学习 (IL) 已成为解决接触丰富作的一种有前途的途径,梯度场学习方法的最新进展支持了这一前景 。例如,扩散策略(DP)在学习复杂作任务方面表现出巨大的潜力。这种方法已被证明可以很好地推广到难以建模和估计状态的场景,例如剥蔬菜、擀面团和制作煎饼。然而,应用这种策略需要大量的专家演示,由于远程作方法的局限性,面临着大规模的挑战。现有的远程作技术主要为末端执行器跟踪量身定制,难以有效演示复杂的全身动作,最近利用学习到的人形机器人重定向模型的显著例外。即使采用全身远程作技术,例如传统的运动学重定向,重复执行相同的任务来训练熟练的策略也可能很乏味。对于可以模拟的更结构化的任务,强化学习 (RL) 已被证明可以产生显著的结果 。这些进步通常取决于特定于任务的见解的可用性,无论是以明确定义的奖励函数还是专家指导的形式。作为简化奖励设计过程的一种手段,引导式 RL 利用从数据中推断的预先存在的知识来提高 RL 过程的效率和功效。特别是,示例引导的 RL (EGRL) 旨在将运动模仿与基于任务的奖励(标准 RL)相结合,并通过灌输所需的运动风格来帮助探索,从而加速学习并简化奖励塑造。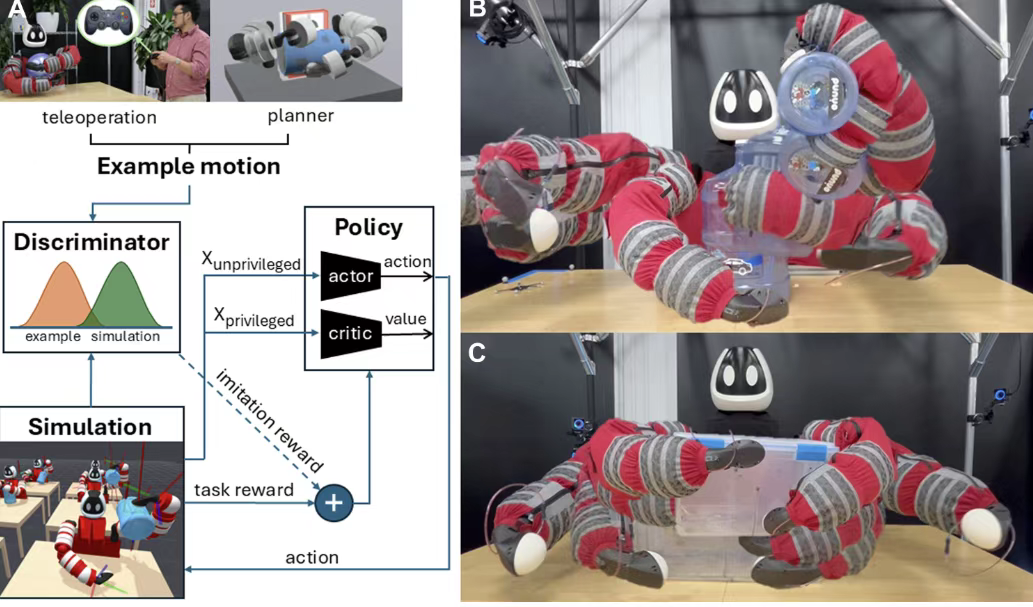
例如,生成对抗模仿学习 (GAIL)有效地集成了生成对抗网络,RL 结合了一个鉴别器来评估策略和示例运动之间的相似性。然而,GAIL 的直接适用性仅限于演示者行为可观察的情况。为了解决这个问题,最近的一项工作引入了对抗性运动先验(AMP),它利用GAIL框架来辨别状态转换是来自示例运动的样本还是由代理生成的样本。这种方法不需要设计模仿目标或运动选择机制,它可以自动合成一个策略,在给定一组示例运动和通用奖励函数的情况下完成所需的高级任务。由于其承诺在没有奖励工程负担的情况下将运动风格强加于RL策略,
AMP的想法(最初是为角色动画提出的)引起了机器人界的关注,并为四足运动带来了令人印象深刻的结果。AMP 已被应用于为动画角色生成全身运动,例如踢腿和击打,其中物理的保真度和物体的纵不是关键限制。这种方法在现实世界中的作任务中的转化涉及机器人与物体之间复杂的接触交互和约束所产生的独特挑战,以前从未就其适用性和有效性进行过探索。在这篇研究文章中证明了我们的控制器基于AMP结合Punyo的被动和主动顺应性,解决了上述全身纵中的挑战,并能够在人形机器人上稳健地执行复杂的全身纵任务。利用 AMP 公式的多功能性来接受任何基于状态的轨迹作为示例运动,我们使用了模拟中收集的远程作数据和来自基于模型的规划器的单独运动计划,并评估了运动源选择的权衡。我们表明,在模拟中收集的单个远程作演示足以训练风格化、接触丰富的运动的策略。我们进一步表明,即使是粗略的、动态不可行的运动计划也可以作为一个有效的例子,允许该方法超越远程作的限制。使用非对称的 actor-critic 策略,我们使用在模拟中随时可用的特权信息训练策略,同时在推理时仅依赖本体感觉和触觉输入,从而实现无需对象姿势跟踪的盲目作。由此产生的策略成功地完成了各种现实世界的任务,包括将水壶举过肩膀、将其倒置以及重新定位一个大盒子。最后,我们分析了示例运动质量如何影响学习性能,并评估了合规性和领域随机化(DR)对最终策略鲁棒性的影响,通过随机初始对象姿态下的成功率来衡量。我们的方法的有效性在丰田研究所的 Punyo 机器人上得到了证明,这是一种具有高度变形、压力感应皮肤的人形上半身。训练是在模拟中进行的,每个对象做任务只有一个示例运动,并且由于域随机化和机器人的合规性,策略很容易转移到硬件上。生成的代理可以以与示例运动类似的方式操作各种日常对象,例如水壶和大盒子。此外,我们还展示了灵巧全身盲操,仅依靠本体感觉和触觉反馈,而没有物体姿势跟踪。我们的分析强调了合规性在促进人形机器人全身作方面的关键作用。