激活被遗忘的训练信号:ERPO框架如何让大模型在数学推理中更进一步
随着大型语言模型在数学、编程等复杂推理任务中的表现日益出色,如何进一步提升其推理能力成为研究热点。本文介绍了一种创新的训练框架------ERPO(Explore Residual Prompts in Policy Optimization),通过巧妙利用训练过程中被"遗忘"的残余提示,显著提升了模型的数学推理性能,在多个基准测试中取得了显著改进。
论文标题: EXPLORE DATA LEFT BEHIND IN REINFORCEMENT LEARNING FOR REASONING LANGUAGE MODELS
来源: arXiv:2511.04800v1
链接: https://arxiv.org/abs/2511.04800
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
随着可验证奖励强化学习(RLVR)在提升大型语言模型推理能力方面的成功应用,基于Group Relative Policy Optimization(GRPO)的方法族展现出强大的性能。然而,随着训练步数的增加和模型规模的扩大,越来越多的训练提示变为"残余提示"------这些提示产生的奖励方差为零,无法提供训练信号。这导致参与训练的提示逐渐减少,降低了训练多样性,进而阻碍了模型性能的进一步提升。
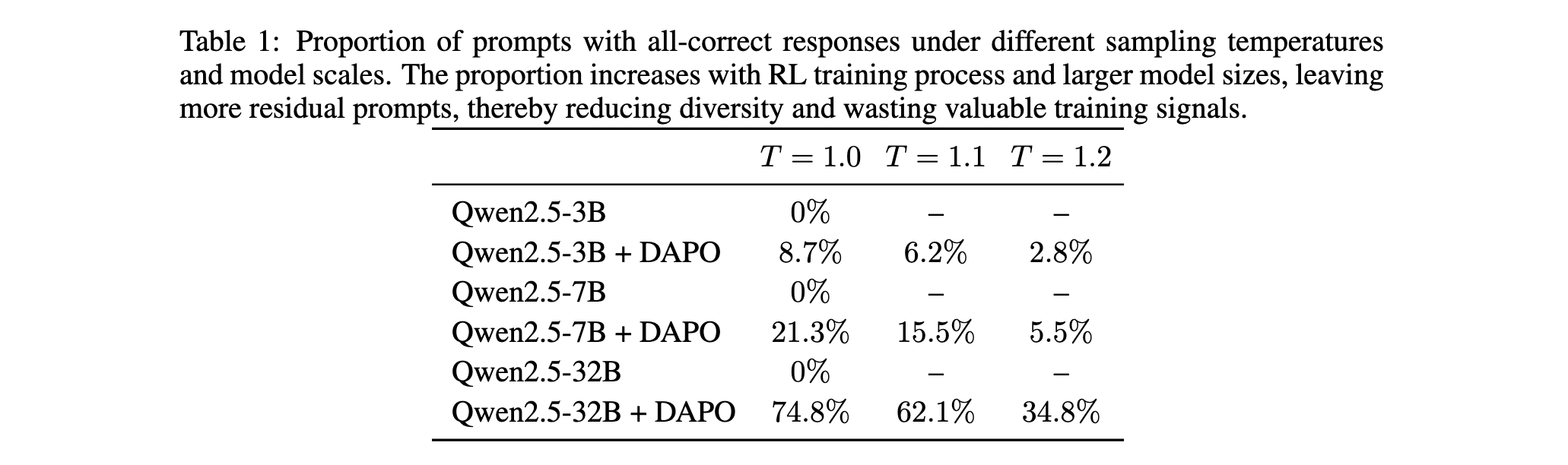
如表1所示,在Qwen2.5-32B模型上经过DAPO训练后,在T=1.0的采样温度下,高达74.8%的提示都会产生全正确的响应。这些残余提示虽然在当前策略下已经"学会",但它们仍然包含有价值的信息,可以帮助模型保持已获得的能力,并可能产生新的推理轨迹。更重要的是,这些提示并不真正健壮------微小的扰动(如增加采样温度)就很容易诱发错误。
研究问题
当前RLVR方法主要存在以下三个关键问题:
- 训练信号浪费:残余提示在训练过程中被完全丢弃,要么被分配零优势,要么直接从训练批次中过滤掉,导致宝贵的训练信息未被利用。
- 训练多样性下降:随着RL训练的进行,越来越多的提示变为残余提示,可用训练提示不断减少,训练集的大小和多样性逐渐降低。
- 模型可扩展性问题:更大的模型在相同训练条件下会产生更多残余提示,如Qwen2.5-32B相比3B模型残余提示比例显著增加,这揭示了模型规模对RLVR可扩展性的挑战。
主要贡献
- 问题识别:首次系统性地揭示了GRPO家族算法的一个关键局限------随着训练进程和模型规模扩大,残余提示的积累导致训练多样性降低和有价值训练信号的丢失。
- 方法创新:提出ERPO框架,通过为每个提示维护历史跟踪器,自适应地增加残余提示的采样温度,鼓励模型在这些提示上进行探索,恢复其学习潜力。
- 实验验证:在多个数学推理基准上的广泛实验证明,ERPO在平均评估和多数投票评估中都一致性地超越了强基准,特别是在不太可能存在数据污染的数据(如AIME2025)上表现出色。
方法论精要
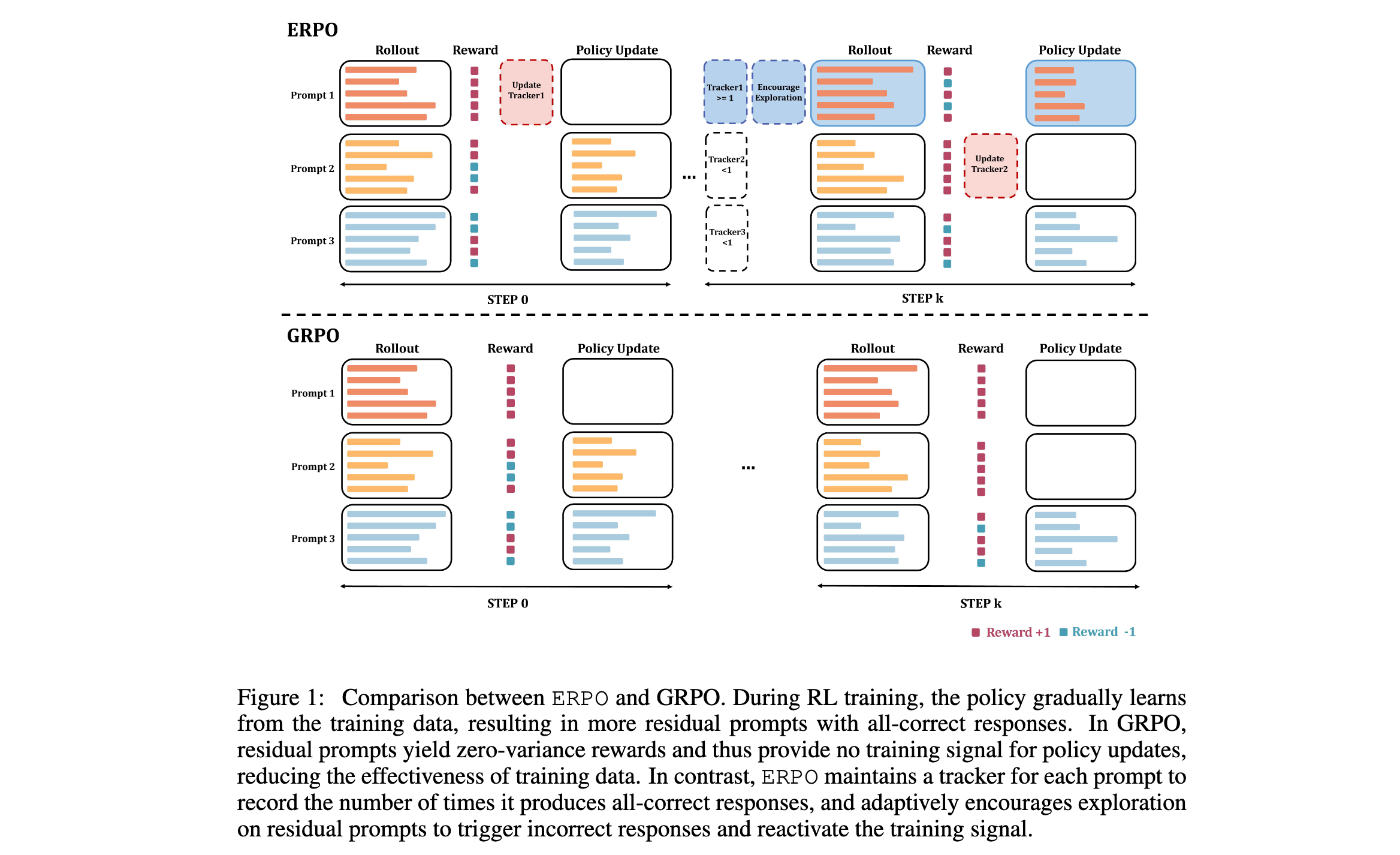
ERPO框架的核心思想是充分利用训练过程中被传统RL算法遗弃的残余提示,通过自适应的探索策略重新激活这些提示的训练信号。该方法主要包括两个关键组件:训练信号激活和残余提示探索。
训练信号激活
传统RLVR算法通常通过为全正确的响应分配零优势或直接从训练批次中过滤掉残余提示来处理这些提示。这种做法虽然简单,但完全浪费了残余提示中包含的有价值信息。为了重新激活这些训练信号,ERPO引入了一个简单但有效的方法:对于产生全正确响应的残余提示,通过在优势计算中引入伪负奖励来替换零优势。
具体而言,新的激活优势(Reactivated Advantage, RA)计算公式为:
R A ^ i , t = r i − mean ( { R i + } i = 1 G ∪ { R − } ) std ( { R i + } i = 1 G ∪ { R − } ) \hat{RA}_{i,t} = \frac{r_i - \text{mean}(\{R^+i\}{i=1}^G \cup \{R^-\})}{\text{std}(\{R^+i\}{i=1}^G \cup \{R^-\})} RA^i,t=std({Ri+}i=1G∪{R−})ri−mean({Ri+}i=1G∪{R−})
其中, R + R^+ R+是正确响应的奖励, R − R^- R−是错误响应的奖励。通过这种方式,产生全正确响应的残余提示仍然保留一个小的正优势,为训练提供有效信号,而不是被RL算法丢弃。
残余提示探索策略
虽然使用激活优势可以强制模型从残余提示中学习信息,但如果残余提示在训练过程中占主导地位,会导致负面反馈减少,阻碍训练效果。此外,模型可能面临探索与利用之间的不平衡,过度拟合到狭窄的探索空间。
为了解决这一限制,ERPO通过控制采样温度来自适应地鼓励对残余提示的探索。如表1所示,更高的采样温度可以触发错误响应,从而重新激活残余提示的训练信号。训练数据通常在不同轮次之间表现出强时间相关性,即在当前轮次产生全正确响应的提示在下一轮次也很可能产生全正确响应。因此,ERPO为每个提示 q i q_i qi维护一个历史跟踪器 H i H_i Hi,用于跟踪策略为该提示生成全正确响应的次数:
H i ( 0 ) = 0 , H i ( t ) = H i ( t − 1 ) + 1 q i has all-correct responses at step t H^{(0)}_i = 0, \quad H^{(t)}_i = H^{(t-1)}_i + \mathbb{1}q_i \\text{ has all-correct responses at step } t Hi(0)=0,Hi(t)=Hi(t−1)+1qi has all-correct responses at step t
然后, H i H_i Hi用于确定是否应该为提示 q i q_i qi分配更大的采样温度。如果 H i > 0 H_i \gt 0 Hi>0,说明提示 q i q_i qi对策略来说已经很容易生成全正确响应,下次策略采样时很可能不再提供训练信号。因此,ERPO为 H i > 0 H_i \gt 0 Hi>0的提示分配更大的采样温度,以鼓励对其推理轨迹进行更多探索,并通过触发错误响应来重新激活训练信号。
自适应温度调整
由于不同提示的健壮性各不相同,一些残余提示只需要略微增加采样温度就能诱发错误响应,而其他提示则需要大幅调整。同时,为了保持on-policy学习的优势,必须将分布偏移限制在合理范围内,以确保训练的稳定性和有效性。为健壮性较低的提示分配过大的采样温度尤其有害。
这种权衡突出了选择单一、统一的采样温度的困难,该温度需要能够一致地诱发错误响应、增强探索,并在所有残余提示上保持可控的分布偏移。因此,ERPO引入了采样温度的提示自适应调整:
T i ( t ) = min ( T 0 + T s ⋅ H i ( t ) , T max ) T^{(t)}_i = \min(T_0 + T_s \cdot H^{(t)}i, T{\max}) Ti(t)=min(T0+Ts⋅Hi(t),Tmax)
其中, T 0 T_0 T0、 T max T_{\max} Tmax和 T s T_s Ts是超参数,分别表示初始温度、最大温度和温度步长。通过这种方式,ERPO逐渐增加残余提示的采样温度,直到策略生成错误响应。这使得ERPO能够在重新激活训练信号、鼓励探索和保持合理的分布偏移之间取得平衡。
算法流程
ERPO框架的完整算法流程如算法1所示。在每一步训练中,首先从提示集中采样一个mini-batch,然后为每个提示根据其历史跟踪器 H i H_i Hi计算自适应采样温度 T i ( t ) T^{(t)}_i Ti(t)。使用该温度采样 n n n个rollout,计算奖励并更新历史跟踪器。最后,使用RL算法(如DAPO)更新策略参数。
通过这种设计,ERPO能够有效地利用训练过程中被遗弃的残余提示,提高训练多样性,并在不牺牲训练稳定性的前提下提升模型性能。

实验洞察
实验设置
研究者在Qwen2.5-3B和Qwen2.5-7B模型上进行了实验,使用DAPO-Math-17K数据集进行训练。采用DAPO算法作为基线和ERPO的优化方法,学习率设置为 1 × 10 − 6 1 \times 10^{-6} 1×10−6,在10个rollout步上进行线性预热。对于rollout,使用512的提示批次大小,每个提示采样16个响应。训练期间,mini-batch大小设置为512,每个rollout步进行16次梯度更新。
初始rollout温度 T 0 T_0 T0设置为1.0。温度增量步 T s T_s Ts在Qwen2.5-3B上设置为0.02,在Qwen2.5-7B上设置为0.05,而最大rollout温度 T max T_{\max} Tmax在Qwen2.5-3B上设置为1.2,在Qwen2.5-7B上设置为1.4。奖励分配为正确响应1分,否则-1分。
评估在AIME2025/2024、AMC2023和MATH500上进行,使用1.0的rollout温度和 p = 0.7 p=0.7 p=0.7的top-p采样。对于AIME和AMC,每个提示采样32个独立响应,报告平均准确率mean@32。此外,提供多数投票准确率maj@32作为补充指标。对于更大且不太具挑战性的MATH500基准,每个提示采样4个响应,报告平均准确率mean@4和多数投票准确率maj@4。
基准比较
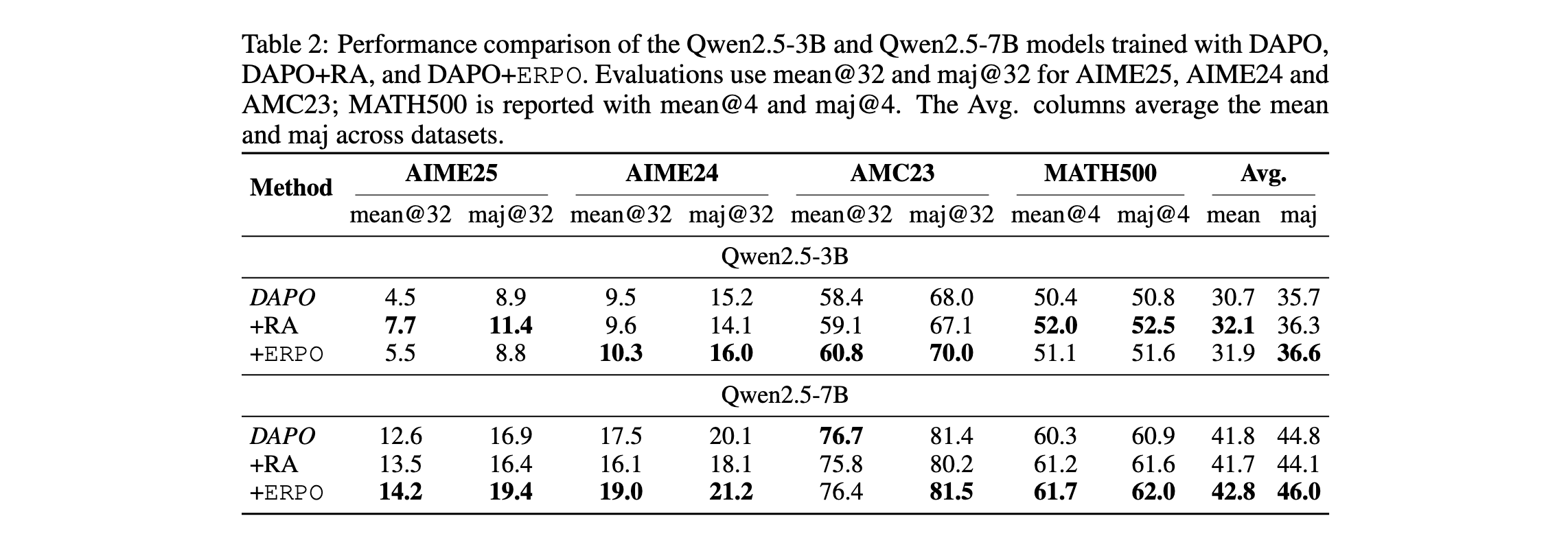
表2展示了DAPO、激活优势(RA)和ERPO在AIME25、AIME24、AMC23和MATH500基准上的性能比较。在Qwen-3B上,RA和ERPO都实现了比基线DAPO更高的平均和多数投票准确率。RA的改进证明了残余提示仍然包含有价值的训练信息,不应完全从RL训练中排除。
在AIME2025上,RA相比基线取得了显著的性能提升:mean@32提升约70%,maj@32提升约28%。由于AIME2025相比其他数学基准在模型预训练期间受到的数据污染较少,这些结果证实了在残余提示上学习对于模型新颖且具有挑战性的任务特别有帮助。
在Qwen2.5-7B上,ERPO在平均和多数投票准确率上都实现了与DAPO和RA相比的最佳整体性能,表明该算法的可扩展性。在AIME2025上,ERPO相比基线取得了最大的改进,mean@32和maj@32分别提升约12%和16%。
然而,与3B模型上的结果不同,RA在7B模型上的表现不如ERPO。一个可能的原因是,当训练期间残余提示比例较高时,重新激活所有残余提示可能导致过拟合。如表1所示,Qwen2.5-7B有超过20%的残余提示,随着模型规模扩大,这个问题变得更加突出。相比之下,ERPO通过设置 T max T_{\max} Tmax避免了这个问题,防止了采样温度的无界增加。一旦残余提示被完全学习并对更高温度具有健壮性,它就不再提供训练信号。
残余提示探索分析
为了研究采样温度对残余提示的影响,研究者进行了实验来测量不同温度设置下残余提示的比例。具体而言,从训练数据集DAPO-Math-17K中选择一个2k的子集,按照相同的训练配置对每个提示采样16次,并计算该子集中残余提示的比例。评估使用DAPO训练的Qwen2.5-3B、Qwen2.5-7B和Qwen2.5-32B模型。
表1的详细结果突出了三个关键观察:(1)训练后残余提示的比例增加;(2)更大的模型倾向于产生更多残余提示,揭示了模型规模对RLVR可扩展性的挑战;(3)更高的采样温度鼓励更大的探索,并可以从残余提示中诱发更多错误响应。
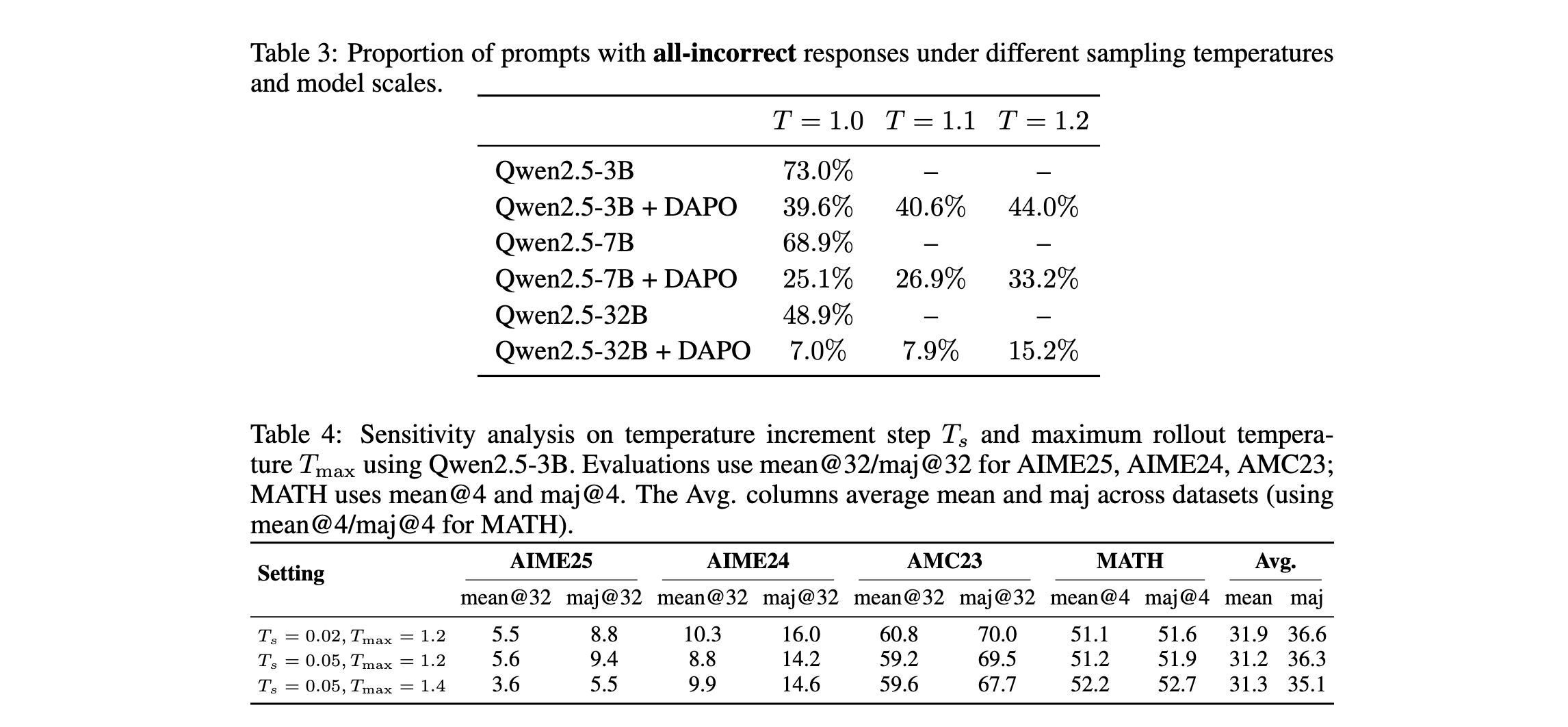
另一方面,研究者也检查了采样温度对产生全错误响应提示的影响。实验设置保持不变,结果如表3所示。研究结果表明,RL训练和模型规模降低了产生全错误响应提示的比例。此外,采样温度对该比例的影响远小于对残余提示的影响。因此,ERPO仅应用于更可能产生全正确响应的残余提示。
敏感性分析
研究者对温度增量步( T s T_s Ts)和最大rollout温度( T max T_{\max} Tmax)进行了敏感性分析,以评估其对Qwen2.5-3B模型的影响。具体而言,实验了三种参数设置: T s = 0.02 , T max = 1.2 T_s=0.02, T_{\max}=1.2 Ts=0.02,Tmax=1.2; T s = 0.05 , T max = 1.2 T_s=0.05, T_{\max}=1.2 Ts=0.05,Tmax=1.2;以及 T s = 0.05 , T max = 1.4 T_s=0.05, T_{\max}=1.4 Ts=0.05,Tmax=1.4。
表4报告了这些设置下的性能。结果表明, T s = 0.02 , T max = 1.2 T_s=0.02, T_{\max}=1.2 Ts=0.02,Tmax=1.2产生最佳性能,而增加 T s T_s Ts或 T max T_{\max} Tmax都会导致性能下降。值得注意的是,设置 T s = 0.05 , T max = 1.2 T_s=0.05, T_{\max}=1.2 Ts=0.05,Tmax=1.2仍然优于vanilla DAPO算法,而 T s = 0.05 , T max = 1.4 T_s=0.05, T_{\max}=1.4 Ts=0.05,Tmax=1.4实现了与DAPO基线相当的性能。由于较小的模型通常比较大的模型健壮性较差,3B模型上的这些结果进一步验证了ERPO的有效性,并表明它对超参数的选择不太敏感。
进一步分析
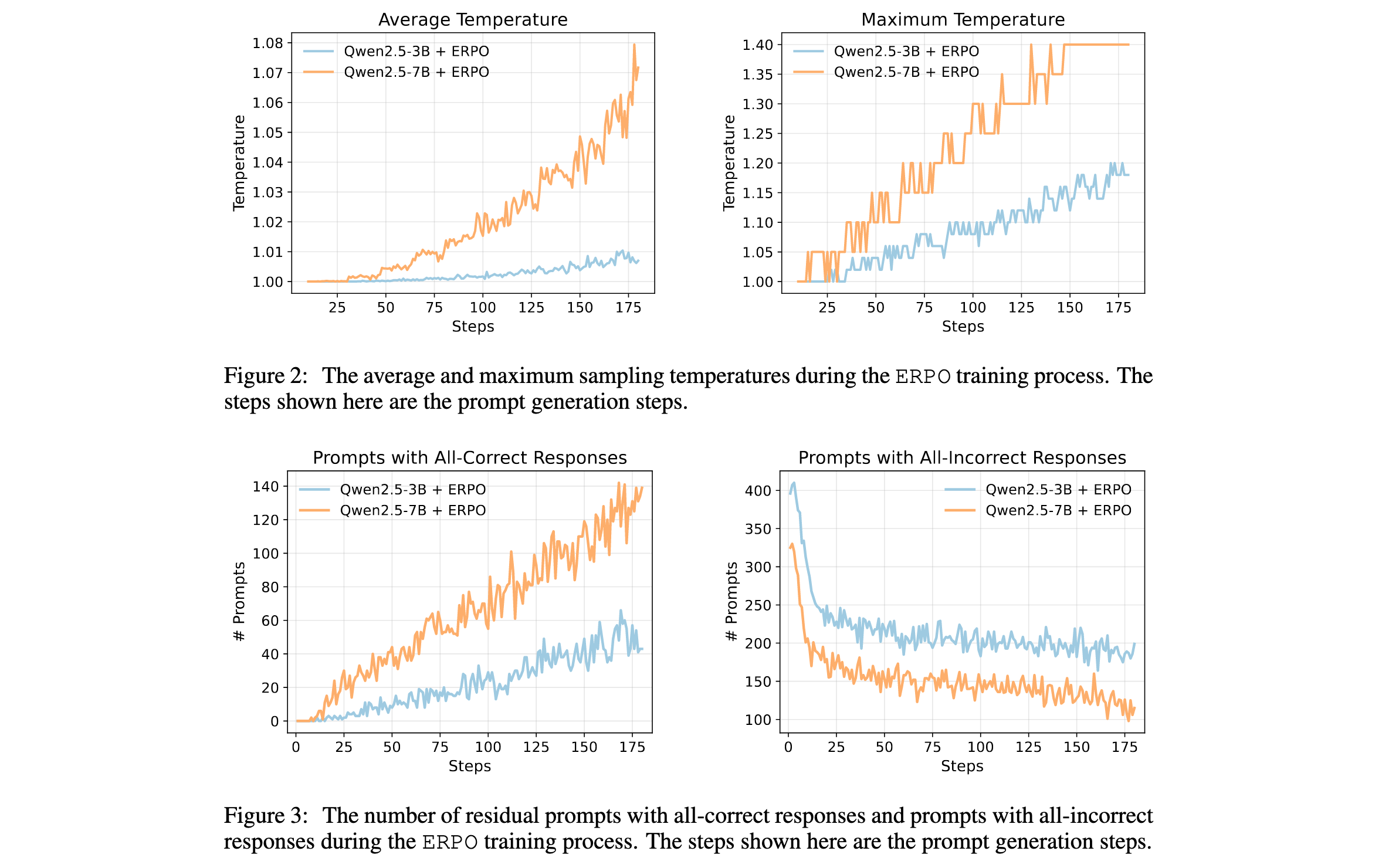
图2显示了ERPO训练过程中的平均和最大采样温度。最大温度线性增加,而平均温度指数增加,表明更多提示变为残余提示,其采样温度被ERPO提高。设置温度上限 T max T_{\max} Tmax对于防止采样温度不受控制地增长是必要的。
图3显示了大小为512的训练批次中,产生全正确响应的残余提示数量和产生全错误响应的提示数量。在训练过程中,产生全错误响应的提示数量持续减少,而残余提示数量稳步增加。此外,残余提示的增长率高于全错误提示的衰减率,突出了利用残余提示的重要性。
此外,Qwen2.5-3B和Qwen2.5-7B的历史跟踪器表明,训练数据集中15.3%和40.2%的提示有记录 H i > 0 H_i \gt 0 Hi>0,进一步证明了ERPO在训练过程中的关键作用。
总结
ERPO框架通过创新性地利用训练过程中被遗弃的残余提示,为强化学习在推理语言模型中的应用提供了新的思路。该方法通过自适应调整采样温度,在重新激活训练信号、鼓励探索和保持合理分布偏移之间取得了良好平衡。实验结果表明,ERPO不仅缓解了提示塌缩问题,还提高了平均和多数投票性能,特别是在不太受数据污染影响的任务上表现出色。
这项研究的重要性在于,它揭示了一个被广泛忽视的问题------随着模型规模的扩大和训练时间的延长,越来越多的训练提示变为残余提示,传统方法简单地丢弃这些提示实际上浪费了大量有价值的信息。ERPO框架提供了一种有效利用这些信息的方法,为未来强化学习在大型语言模型中的应用开辟了新的方向。
代码已在GitHub上开源:https://github.com/DawnLIU35/ERPO