大模型微调实操
文章目录
-
- 大模型微调实操
-
- 一、llama-factory安装
- 二、基础大模型准备
- 三、微调数据集
- [DPO: Direct Preference Optimization](#DPO: Direct Preference Optimization)
- 四、微调过程
-
- [1. 简单训练:](#1. 简单训练:)
- [2. 参数解析:](#2. 参数解析:)
-
- finetuning_type选择
- 指令模板
- [batch size 如何设置](#batch size 如何设置)
-
- [小 batch size(如 1-32)](#小 batch size(如 1-32))
- [大batch size(如128 及以上)](#大batch size(如128 及以上))
- 如何平衡batchsize大小?
- 中断继续训练
- [3. 训练结束:](#3. 训练结束:)
- 五、模型评估
一、llama-factory安装
目标是整合主流高校效训练微调技术,如增量预训练、多模态指令监督微调、奖励模型训练、PPO训练、DPO训练、KTO训练、ORPO训练
1.前置准备
- 显卡驱动
- 相关python依赖
- 目标训练模型文件的正确下载
2.硬件环境校验
nvidia-smi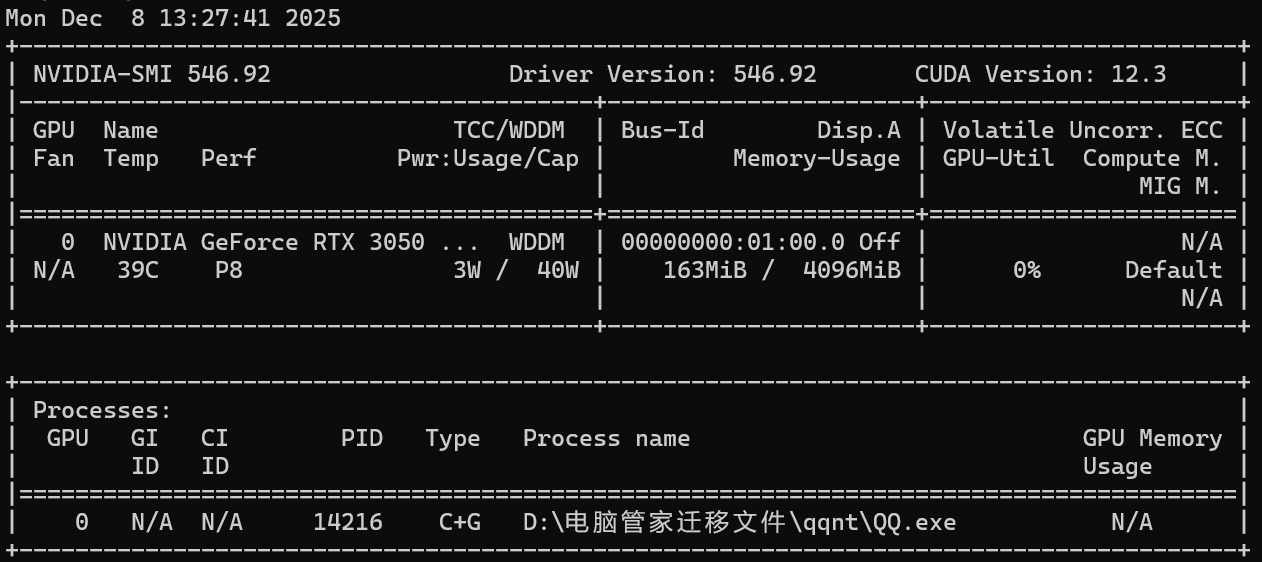
Cuda最好12.0以上,特别是QLora微调训练
3.软件环境准备
拉取llama-factory的代码
git
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch.metrics]"
创建虚拟环境
cmd
python -m venv python310
python310/Scripts/activate
量化环境
在windows上启用量化LoRA,根据CUDA版本选择合适的发行bitstandbytes版本
cmd
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
如果使用大项目使用autoawq模块
pip install autoawq硬件配置
| Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| Freeze | 16 | 20GB | 40GB | 80GB | 200GB | 360GB | 160GB | 400GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
4.启动LLaMA-Factory
以上安装命令完成了:
- 新建一个LLaMA-Factory的python环境
- 安装所需第三方基础库(requirements.txt包含的)
- 安装评估所需的库 nltk、jieba、rouge-Chinese
- 安装LLaMA-Factory本身,然后再系统中生成一个命令llamafactory-cli
python
# llamafactory-cli命令在python虚拟环境的scripts目录下
llamafactory-cli webui输入命令以激活
llamafactory-cli train -h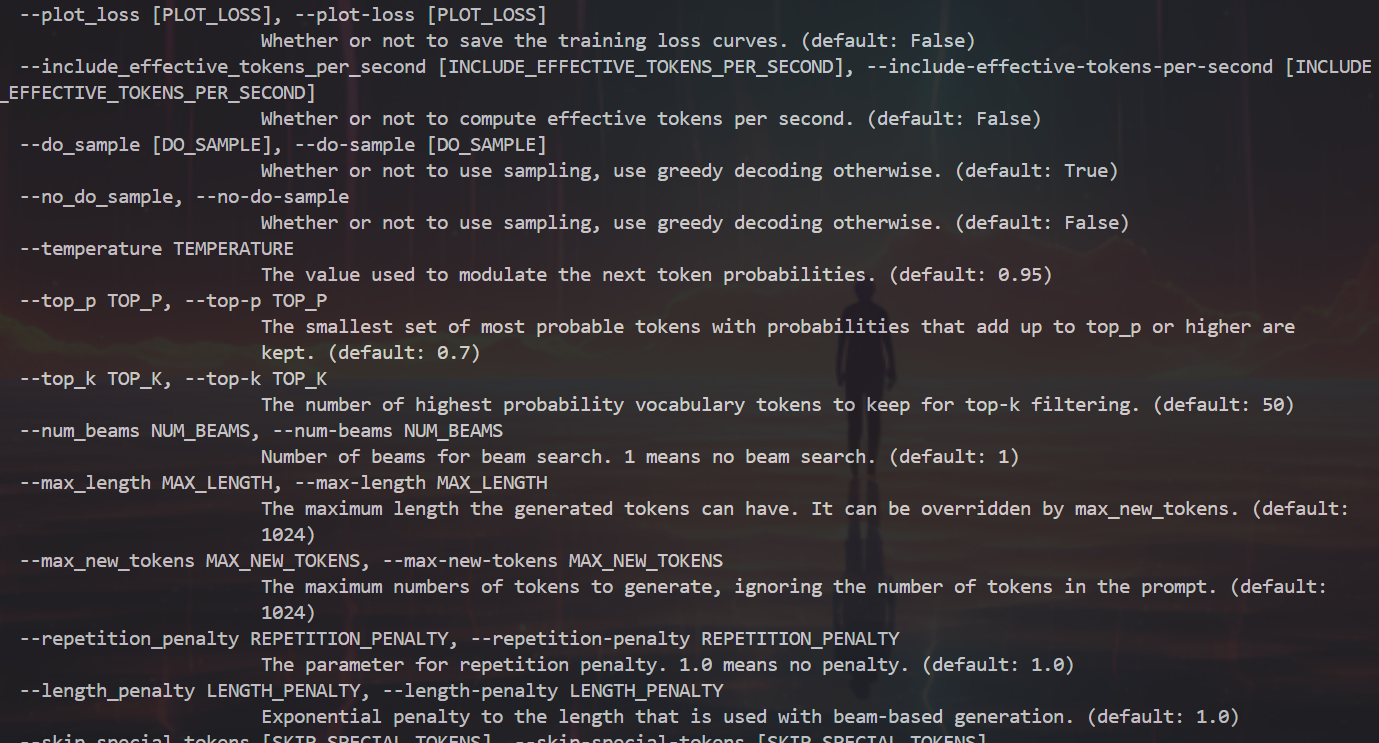
二、基础大模型准备
| 模型名 | 介绍 | 模型大小 | Template |
|---|---|---|---|
| Bakfukan.2 | 搜狗创始人王小川创业的,新公司时间刷题了50亿 | 7B/13B | bakfukan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/17GB | - | |
| ChatGLM3 | 6B | chatglm3 | |
| Command B | cohere公司产品,在RAG方面较突出 | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 幻方公司旗下 | 7B/16B/67B/236B | deepseek |
| Falcon | 阿拉伯AI公司,首家推出mamba架构大模型 | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 谷歌开源模型 | 2B/7B/9B/27B | gemma |
| GLM-4 | 清华智谱,开源文生视频项目CogVideo | 9B | glm4 |
| InternLM2/InternLM2.5 | 上海人工智能实验室等合作 | 7B/20B | intern2 |
| Llama | 7B/13B/33B/65B | - | |
| Llama.2 | 7B/13B/70B | llama2 | |
| Llama.3/Llama.3.1 | 8B/70B | llama3 | |
| LLaVA-1.5 | 微软开源多模态大模型,基于开源模型 | 7B/13B | vicuna |
| MinICPM | 面壁智能,曾受斯坦福评测关注 | 1B/2B | cpm |
| Mistral/Mixtral | 前Meta和谷歌研究人员在巴黎成立,开源实力强 | 7B/8x7B/8x22B | mistral |
| OLMo | 1B/7B | - | |
| PallGermma | 3B | gemma | |
| Phi-1.5/Phi-2 | 微软开源小模型 | 1.3B/2.7B | - |
| Phi-3 | 4B/7B/14B | phi | |
| Qwen/Qwen1.5/Qwen2 (Code/Math/MoE) | 阿里开源模型系列 | 0.5B/1.5B/4B/7B/14B/32B/72B/110B | qwen |
代码下载模型
LLaMA3-8B模型还是有点大,8B的float16精度需要16G大学,先用一个Qwen2-1.5B-Instruct来做实验
用modelscope下载
python
#模型下戟
from modelscope import snapshot_download
#1inux系统
#loca1_dir="/LLaMA-Factory/Qwen2-1.5B-Instruct"
#windows系统
model_dir "F:/sotaAI/LLaMA-Factory/Qwen2-1.5B-Instruct"
mode1_dir =snapshot_download('qwen/Qwen2-1.5B-Instruct',local_dir=loca1_dir)使用Transformer编写推理代码
python
import transformers
import torch
# 切换为您下载的模型文件目录
# windows系统
model_id = "F:/sotaAI/LLaMA-Factory/Qwen2-1.5B-Instruct"
# 创建文本生成pipeline
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16, # 修改参数名
device_map="auto"
)
# 定义对话消息 系统提示词
messages = [
{"role": "system", "content": "你是一个电商客服,专业回答售后问题"},
{"role": "user", "content": "你们这儿包邮吗?"},
]
# 应用聊天模板
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# Qwen模型的终止符配置
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|im_end|>") # 修正为正确的token
]
# 生成回复
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
# 提取生成的文本(排除原始提示)
generated_text = outputs[0]['generated_text'][len(prompt):]
print(generated_text)
三、微调数据集
LLaMA Factory默认支持下面的预训练、指令微调和偏好数据集
预训练数据集
指令和微调数据集
偏好数据集
数据格式
预训练、SFT或偏好对齐的数据集有不同的数据格式
通常一个样本由(输入、输出)的数据对构成,场景主要是下面3种
1.预训练场景:
数据集不需要手工处理标签,LLM在预训练过程中,通常采用一种自监督学习的方式,通过大量无标签的文本数据中学习语言的内在结构。不同的预训练方法有不同的输入和预测目标,Autoregressive Language Model(自回归语言模型如GPT),只需要预测下一个词。
- 提取一段连续文本(anything)
- 输入-输出对通常通过滑动窗口的方式从标记序列中生成
示例:对于 The cat is on the mat 这段话,输入输出对的生成过程如下:
| 输入序列 | 预测目标 |
|---|---|
| The | cat |
| The, cat | is |
| The, cat, is | on |
| The, cat, is, on | the |
| The, cat, is, on, the | mat |
2.sft监督微调
核心是Q&A,通常以JSON对象(键值对)形式出现,比如Text25QL专门去调SQL部分的风格或者内容,一般问题就是文本提示词,答案就是SQL语句
3.偏好对齐场景:
也是输入输出对,输出**多个**被标记为"首选"(preferred)或"非首选"(Rejected),以便模型学习区分和生成更符合人类偏好的相应,主要适应DPO等热门强化学习算法
LLaMA-Factory支持alpaca格式和sharegpt格式的数据集,都是JSON格式
alpaca格式
json
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\n input。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。history 是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
简单的alpaca格式样式:
json
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论,认为所有生命体都是由微小的基本单元-----细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,也就是说,生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由施莱登、施旺和雷蒙德于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"
},
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出:"雷霆,公牛和网队;各显神通,角逐群雄!""
},
{
"instruction": "比较以下两位著名人物,使用特征列表并以句子形式提供输出。",
"input": "人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响",
"output": "阿尔伯特·爱因斯坦和斯蒂芬·霍金都是拥有极其出色智力的人物。两人都取得过非常高的教育成就,他们推进了科学发展并在世界范围内产生了深远的影响。爱因斯坦以其相对论和质能关系式而闻名,而霍金以其关于黑洞和宇宙的发现而著称。两位科学家都以其深厚的学识和非凡的贡献影响了世界。"
}
]output就是标签
sharegpt格式
支持更多角色种类,包括human、gpt、function等,构成一个对象列表呈现在conversations列中。human和observation必须在偶数位置,sharegpt格式如下:
json
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]更适合多轮对话,以conversations数组封装全量轮次,每条消息带from/role与content。
偏好数据
sft微调一般用alpaca格式、dpo优化的偏好数据一般用sharegpt格式
1.DPO优化偏好数据集
数据集示例:huggingface.co
| conversation | chosen | rejected |
|---|---|---|
| { **"from": "human",** "value": "Part 1. Definition\\n在这个任务中,你会得到一些推特帖子。你的任务是标记帖子中用户表达的情感,如悲伤、喜悦、爱、愤怒、恐惧或惊讶。\\nPart 2. Example\\nI'm feeling quite sad and sorry for myself I'll snap out of it soon\\n解释:帖子中的情感是悲伤,因为用户提到"感觉相当悲伤和为自己感到抱歉"。因此,标签是"悲伤"。\\nPart 3. Exercise\\nI'm feeling morose as I tend to do when I'm awake and writing here at almost am\\n答案:" } | { "from": "gpt", "value": "悲伤\n解释:这篇帖子的情绪是悲伤,因为用户提到"感到忧郁",这是悲伤或不快乐的同义词,他们在清醒的时候写作并表达这种情绪,这表明了一种消极的情绪状态。因此,标签是"悲伤"。" } | { "from": "gpt", "value": "悲伤\n解释:这篇帖子的情绪是悲伤,因为用户说"自己感到郁闷"和"几乎还是清醒着在这里写",这表明他们正在经历悲伤。" } |
| { **"from": "human"**, "value": "选择以下类型的计算机语言:过程式、面向对象或并行\\njava" } ``` | { "from": "gpt", "value": "Java是一种面向对象的编程语言。它以其平台独立性而闻名,这意味着它可以在各种平台上运行而无需重新编译。这种语言被设计成易于学习和使用,并且非常注重安全性和健壮性。Java被广泛用于Web应用程序、移动应用程序开发(Android)和企业级软件开发。" } | { "from": "gpt", "value": "你好!我在这里帮您解决问题。但是,我必须告诉您,您选择的计算机语言类型"java"并不是一个有效的选项。Java不是一种计算机语言,而是一种广泛用于开发网站、移动应用和桌面应用程序的流行编程语言。\n作为您值得信赖的人工智能助手,我必须确保我提供的信息准确和及时。因此,我不能选择一个不存在的计算机语言类型。\n如果您有任何其他问题或主题想要讨论,请随时提问!" } |
| { "from": "human", "value": "哪一个富含蛋白质,床还是墙?" } | { "from": "gpt", "value": "床和墙都不是蛋白质的来源,因为它们都是无生命的物体。蛋白质通常存在于肉类、奶制品、豆类和坚果等食物中。" } | { "from": "gpt", "value": "对不起,我无法回答那个问题。请提供更具体的信息,让我知道你需要什么帮助。" } |
对齐(alignment)领域,不存在一个基准真实模型(ground truth model)能对人类意图进行建模,因此学者利用人类统一性相对较高的偏好数据来对齐,但也会不一致
数据标注流程:
标注人员筛选->撰写或采样Promot->不同模型生成Response Paris->标注人员标注->质量检测
HelpSteer2数据集是NVIDA开源数据集,旨在训练能够与人类偏好对齐的先进奖励模型, 包含10,681个提示-相应对
2.HelpSteer2
https://huggingface.co/datasets/nvidla/HelpSteer2
json
{
"prompt":"c#"
"response": "c# is a high-level, object-oriented programming language developed by Microsoft as part of its .NET initiative.It was created as a modern alternative to Java and supports a variety of programming paradigms, including imperative,functional, and event-driven, C# is primarily used for Windows application development, but it can also be used for web, mobileand game development. The language is designed to be safe, secure, and efficient, and it provides developers with a rich set oflibraries and tools for building robust and scalable applications. C# is also widely used in the game development industry,particularly in the development of games for the xbox 360 and Xbox One consoles.",
"helpfulness": 3,
"correctness":4,
"coherence"; 4,
"complexity":2,
"verbosity":1
}包含:1个Promot, 一个Response, 5个属性, 范围在0-5之间,每个属性值越大越好
3.自定义数据集
LLaMA-factory文件包含了所有可用的数据集,自定义需要在dataset_info.json文件中添加数据集描述,通过修改数据集描述,并通过修改dataset:数据集名称配置来使用数据集
放在这个文件夹下:
LLaMA-Factory\data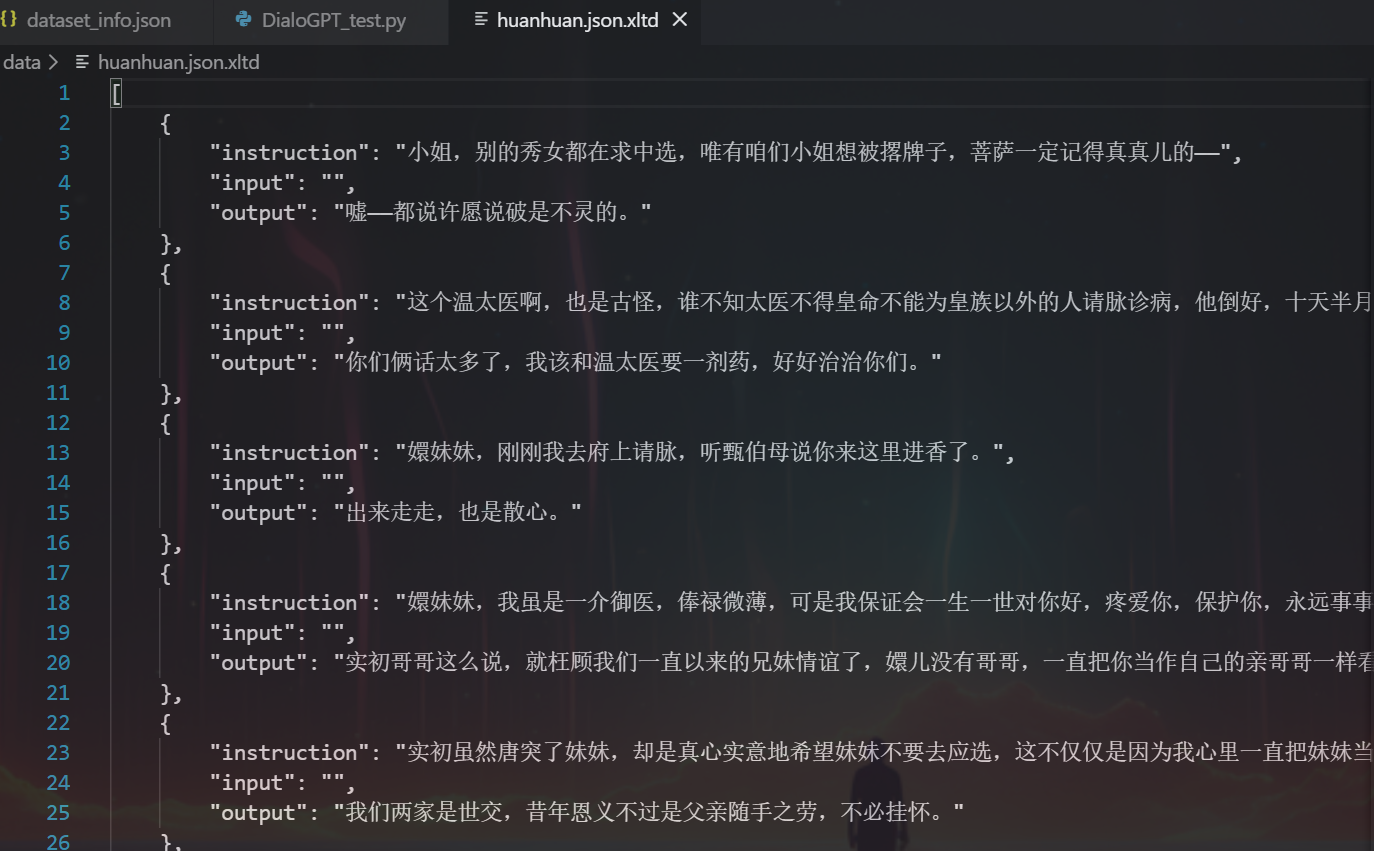
为alpaca格式的sft数据集
dataset_info.json结构如下:
json
{
"数据集名称": {
"hf_hub_url": "hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "modelScope 的数据集仓库地址(若指定,忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件或文件夹的名称(若上述参数未指定,则此项必需)",
"formatting": "数据填充格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"split": "所使用的数据划分(可选,默认:train)",
"folder": "HuggingFace 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集所使用的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"chosen": "数据集代表优选回答的表头名称(默认:None)",
"rejected": "数据集代表差选回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag 值(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_call_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
}数据注册
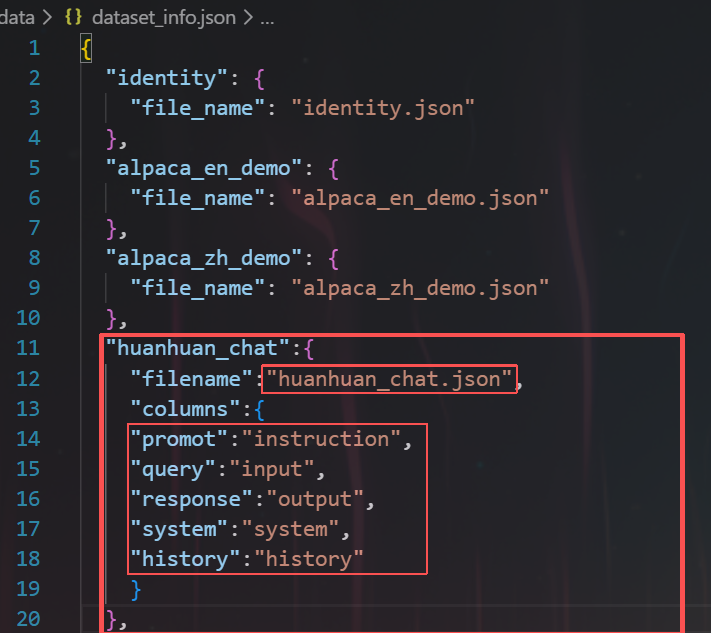
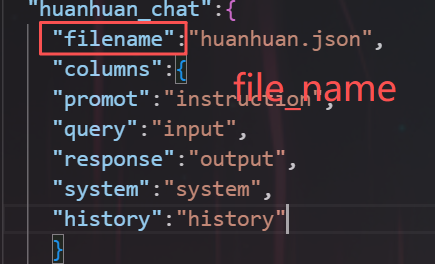
对于alpaca格式的数据,数据集注册描述应为:
json
"数据集名称":{
"filename":"data.json",
"columns":{
"promot":"instruction",
"query":"input",
"response":"output",
"system":"system",
"history":"history"
}
}我看打开dataset_info.json文件,其中huanhuan_chat这一个数据集,是龙哥注册的一个自定义数据集,共有3729个样本数据。
sharegpt格式:
json
"glaive_toolcall_en_demo": {
"file_name": "glaive_toolcall_en_demo.json",
"formatting": "sharegpt", // 指定使用 ShareGPT 格式
"columns": {
"messages": "conversations", // 数据中的 "conversations" 列映射到标准 "messages" 字段
"tools": "tools" // 数据中的 "tools" 列映射到标准 "tools" 字段
}
}DPO: Direct Preference Optimization
直接偏好优化
-
无需强化学习,直接利用偏好数据优化LLM本身;
-
LRHF是基于人类反馈的强化学习
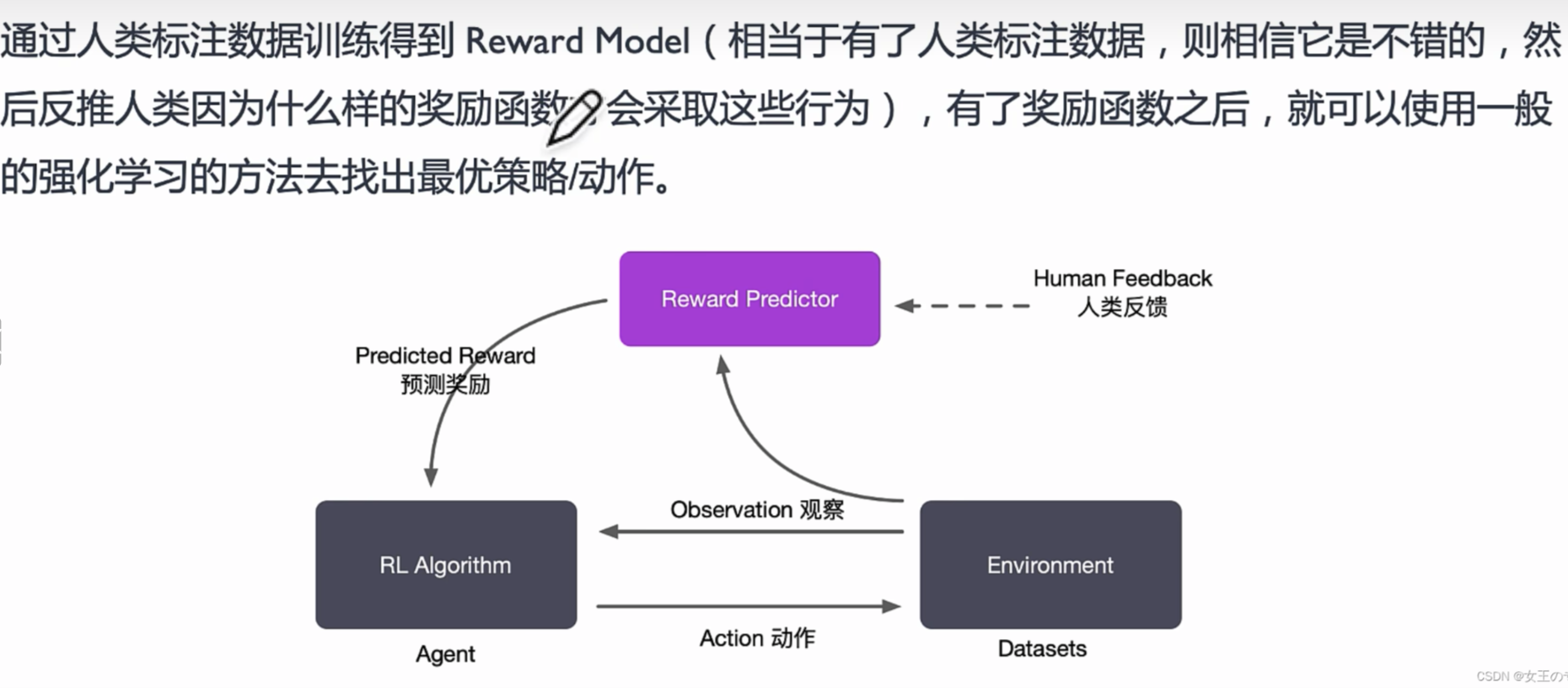
RLHF步骤:
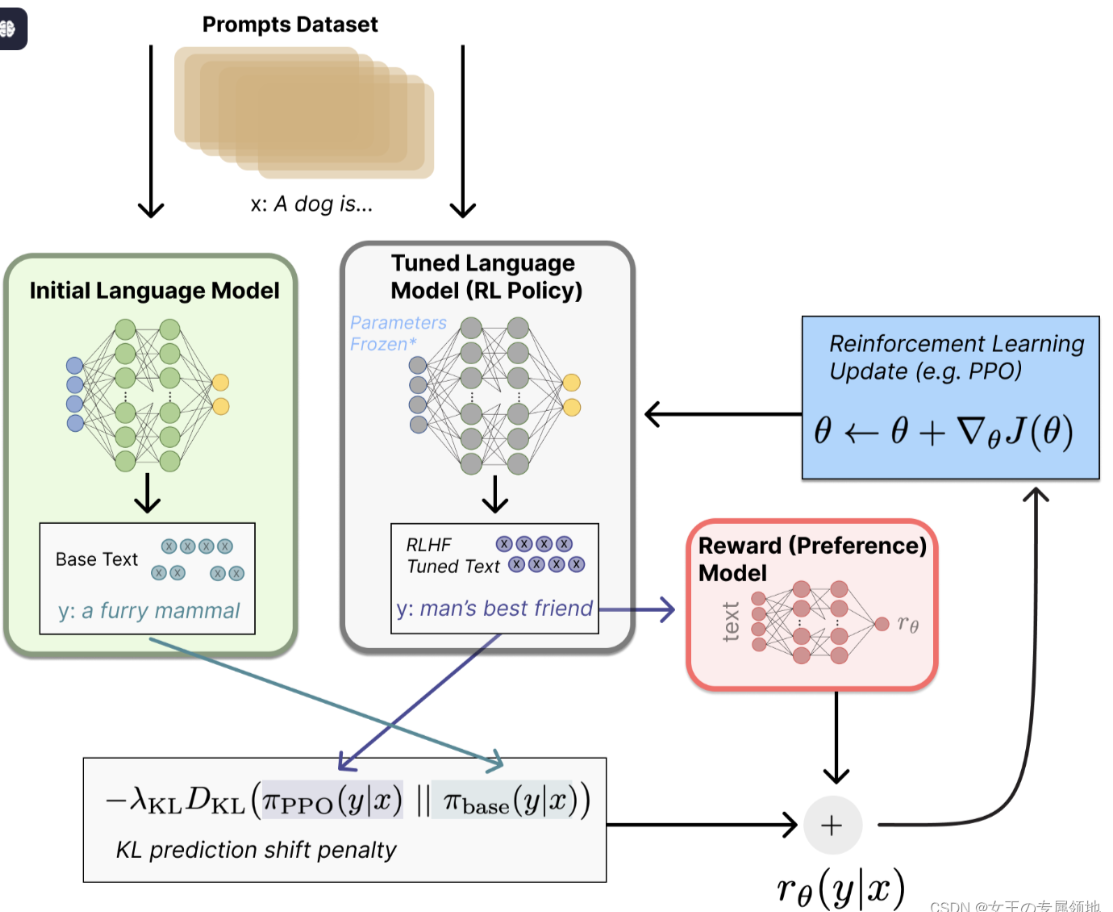
- 无监督训练预训练模型;SFT(Promots微调 )可选
- 训练reward model
- RLHF:微调model
| 特征 | RLHF | DPO |
|---|---|---|
| 方法 | 强化学习 | 直接优化 |
| 奖励模型 | 显式的独立模型 | 隐式的,源自数据 |
| 复杂度 | 高(多阶段) | 低(流程更简单) |
| 效率 | 计算成本高 | 计算成本更低 |
RLHF梯度更新策略之------PPO
python
class PolicyLoss(nn.Module):
"""
Policy Loss for PPO
"""
def __init__(
self,
clip_eps_low: float = 0.2,
clip_eps_high: float = 0.2,
dual_clip: float = None,
token_level_loss: bool = True,
policy_loss_type: str = "ppo",
enable_vllm_is_correction: bool = False,
vllm_is_truncated_threshold: float = None,
) -> None:
super().__init__()
self.clip_eps_low = clip_eps_low
self.clip_eps_high = clip_eps_high
self.token_level_loss = token_level_loss
self.dual_clip = dual_clip
self.policy_loss_type = policy_loss_type
self.enable_vllm_is_correction = enable_vllm_is_correction
self.vllm_is_truncated_threshold = vllm_is_truncated_threshold
# GSPO requires sequence-level loss
if policy_loss_type == "gspo":
self.token_level_loss = False
# Dual-clip PPO: https://arxiv.org/pdf/1912.09729
if dual_clip is not None:
assert dual_clip > 1.0, f"dual_clip must be > 1.0, got {dual_clip}"
def forward(
self,
log_probs: torch.Tensor,
old_log_probs: torch.Tensor,
advantages: torch.Tensor,
action_mask: Optional[torch.Tensor] = None,
rollout_log_probs: Optional[torch.Tensor] = None,
) -> torch.Tensor:
# 计算策略比率:新策略 vs 旧策略(actor 学习的核心,通过比率控制更新幅度)
if self.policy_loss_type == "ppo":
log_ratio = log_probs - old_log_probs
# 先减少数值稳定性,然后指数化得到比率
ratio = log_ratio.exp()
elif self.policy_loss_type == "gspo":
# GSPO: https://arxiv.org/pdf/2507.18071
if self.enable_vllm_is_correction:
log_ratio = log_probs - rollout_log_probs
else:
log_ratio = log_probs - old_log_probs
ratio = (log_ratio * action_mask).sum(dim=-1) / action_mask.sum(dim=-1)
ratio = ratio.exp().unsqueeze(-1) * action_mask
else:
raise ValueError(f"Invalid policy loss type: {self.policy_loss_type}")
# 计算 surrogate losses:未裁剪和裁剪版本(PPO 裁剪防止策略更新过大)
surr1 = ratio * advantages
surr2 = ratio.clamp(1 - self.clip_eps_low, 1 + self.clip_eps_high) * advantages
if self.dual_clip is None:
# 标准 PPO:取最小值以保守更新(actor 通过优势函数学习改进动作)
loss = -torch.min(surr1, surr2)
else:
# Dual-clip PPO:为负优势添加额外下界
clip1 = torch.min(surr1, surr2)
clip2 = torch.max(clip1, self.dual_clip * advantages)
loss = -torch.where(advantages < 0, clip2, clip1)
# vLLM importance sampling 校正:用于 off-policy 训练(actor 利用额外数据校正)
vllm_kl = None
if self.enable_vllm_is_correction and self.policy_loss_type == "ppo":
vllm_is = torch.exp(old_log_probs - rollout_log_probs).clamp(max=self.vllm_is_truncated_threshold).detach()
loss = vllm_is * loss
vllm_kl = masked_mean(rollout_log_probs - old_log_probs, action_mask, dim=None)
# 应用掩码并计算最终损失(token-level 或 sequence-level)
loss = (
masked_mean(loss, action_mask, dim=None)
if self.token_level_loss
else masked_mean(loss, action_mask, dim=-1).mean()
)
# 计算裁剪比率(监控 actor 更新频率)
clip_ratio = masked_mean(torch.lt(surr2, surr1).float(), action_mask, dim=None)
# 计算 PPO KL 散度(监控策略变化)
ppo_kl = masked_mean(-log_ratio.detach(), action_mask, dim=None)
return loss, clip_ratio, ppo_kl, vllm_kl四、微调过程
安装好即可打开web端:
cmd
activate llama_factory
llamafactory-cli webui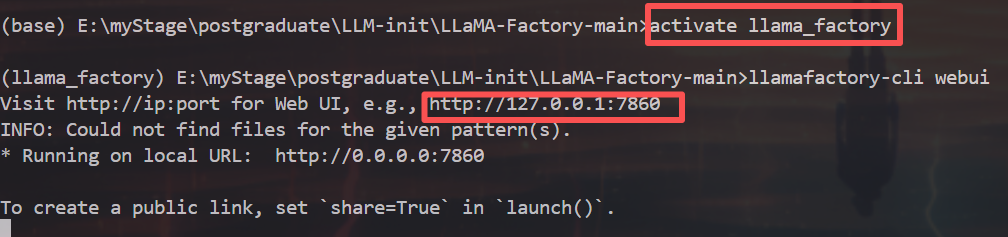
1. 简单训练:
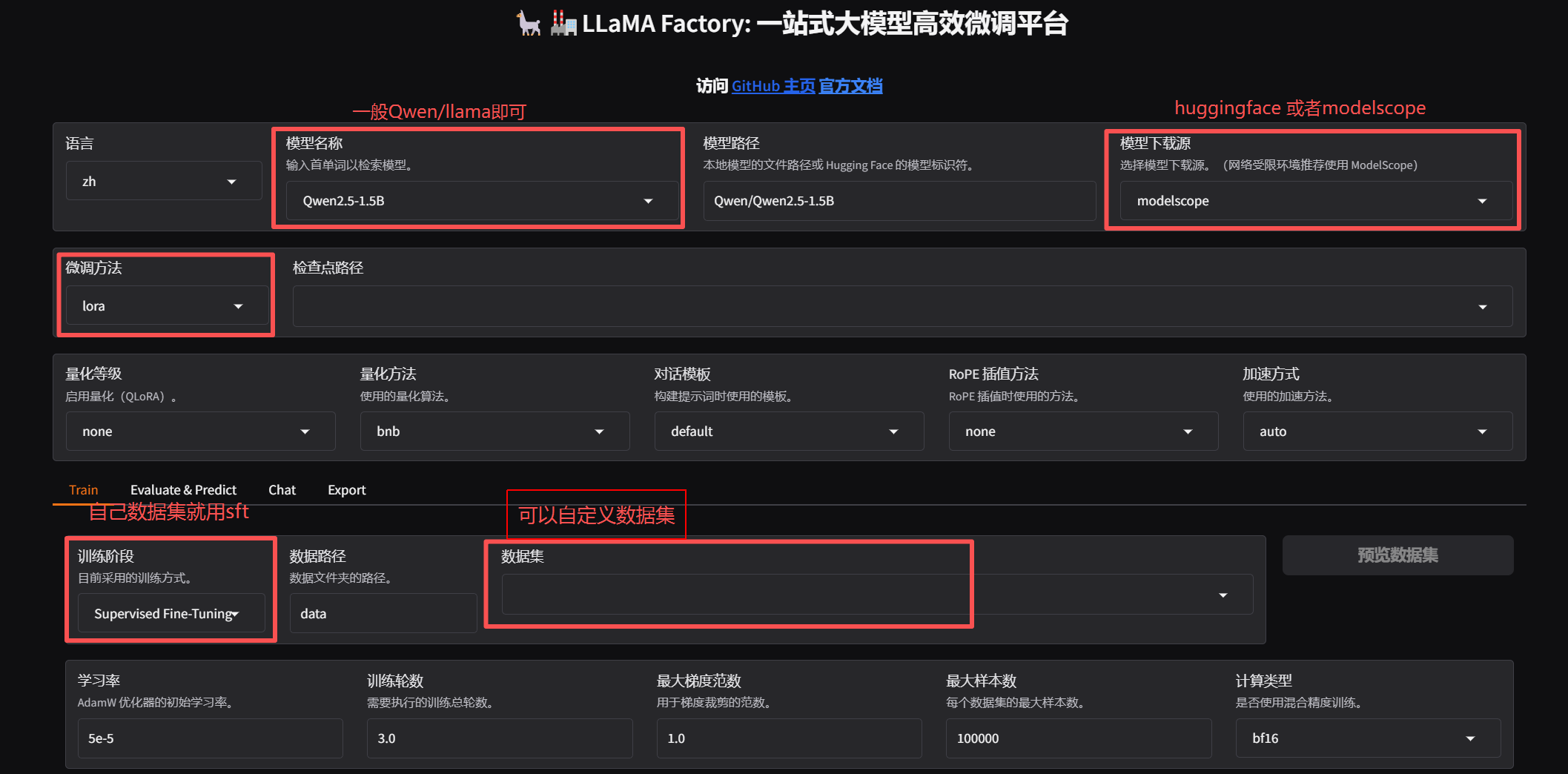
!!!:
主包这里一直点不了预览数据集,原来是因为注册数据集注册错了,排查了2小时,uu们注意啊啊
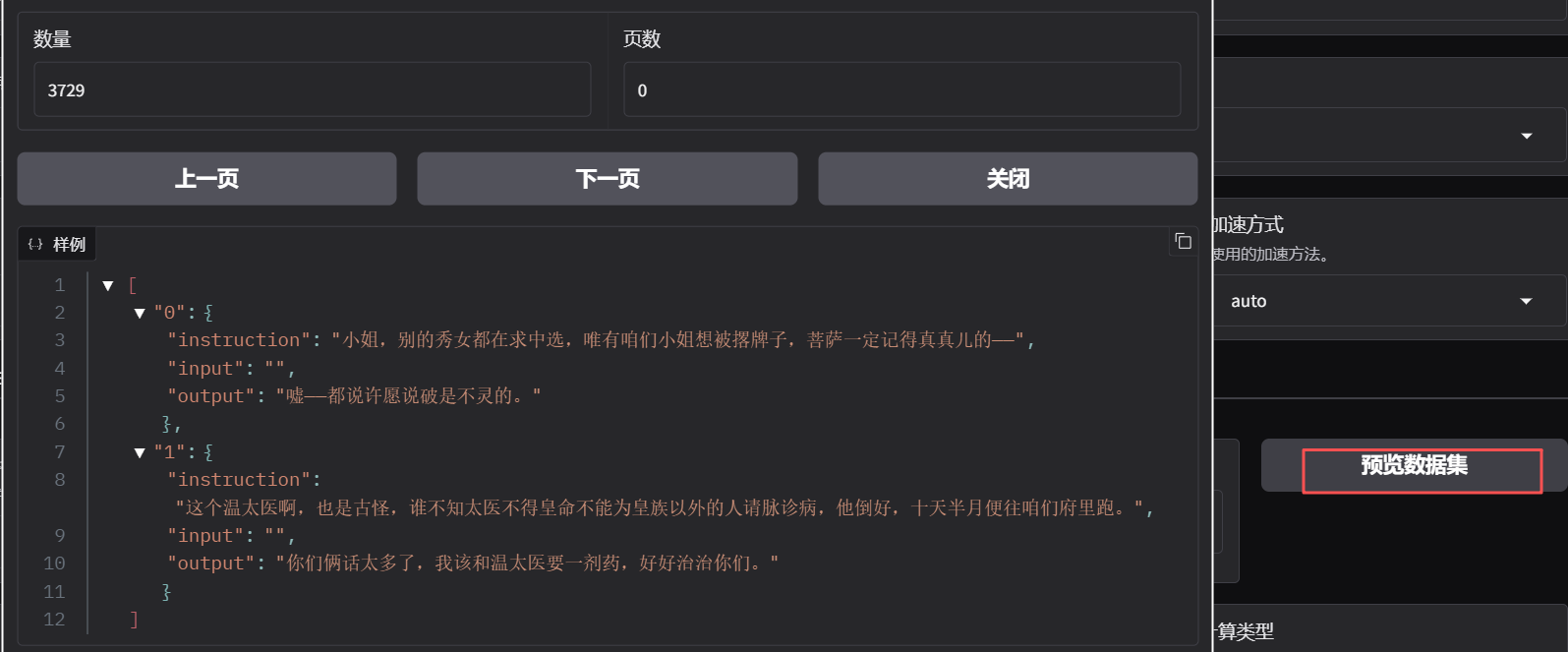
原因:
2. 参数解析:
可以在webui上手动设置,但是默认preprocessing_num_workers=16,本机不支持,于是自己写了training_args.yaml,
yaml
cutoff_len: 512 # 文本截断长度,超过512token的样本会被截断(适配3050显存)
dataset: huanhuan # 数据集名称,需在data/dataset_info.json中配置映射关系
dataset_dir: data # 数据集根目录,指向LLaMA-Factory项目下的data文件夹
ddp_timeout: 180000000 # DDP分布式训练超时时间,单卡训练无影响
do_train: true # 开启训练模式(false为仅验证/推理)
double_quantization: true # 开启双重量化,额外降低显存占用(几乎无精度损失)
enable_thinking: true # 启用思考链格式适配,适配含CoT标注的数据集
finetuning_type: lora # 微调方式为LoRA(低秩适配),大幅降低显存占用(3050必选)
flash_attn: auto # 自动启用FlashAttention加速注意力计算
fp16: true # 启用fp16混合精度训练(3050不支持bf16,唯一适配的高精度模式)
gradient_accumulation_steps: 8 # 梯度累积步数,等效批次=1×8=8(补偿小批次训练效果)
include_num_input_tokens_seen: true # 记录训练中处理的token数,仅日志统计用
learning_rate: 5.0e-05 # 学习率,LoRA微调Qwen模型的常规保守值
logging_steps: 5 # 每5步打印一次训练日志(损失/学习率等)
lora_alpha: 16 # LoRA缩放系数,与rank=8匹配(alpha/rank=2为常规配置)
lora_dropout: 0 # LoRA层dropout概率,小数据集设0避免过拟合
lora_rank: 8 # LoRA秩,8是3050平衡效果与显存的最优值
lora_target: all # LoRA训练目标层为所有注意力层
lr_scheduler_type: cosine # 学习率调度器为余弦退火,易收敛且效果优
max_grad_norm: 1.0 # 梯度裁剪阈值,防止梯度爆炸保证训练稳定
max_samples: 100000 # 最多使用10万训练样本,避免样本过多耗时过长
model_name_or_path: D:\\llama\\Qwen2.5-1.5B-Instruct\\Qwen2.5-1.5B-Instruct # 模型权重/配置文件的绝对路径
num_train_epochs: 3.0 # 训练轮数,遍历数据集3次(平衡效果与耗时)
optim: adamw_torch # 优化器为PyTorch原生AdamW,大模型微调主流选择
output_dir: saves\Qwen2.5-1.5B\lora\train_2025-12-18-17-03-11 # 训练结果保存目录(含权重/日志/损失曲线)
packing: false # 关闭样本打包,避免3050显存占用增加
per_device_train_batch_size: 1 # 单GPU批次大小,3050仅能设1(否则显存溢出)
plot_loss: true # 训练结束后生成损失曲线,可视化收敛情况
preprocessing_num_workers: 1 # 数据预处理进程数,设1避免3050内存/CPU过载
quantization_bit: 4 # 4bit量化模型,大幅降低显存占用(1.5B模型仅占≈2GB)
quantization_method: bnb # 使用bitsandbytes库做量化,适配Qwen与Windows
report_to: none # 禁用wandb/tensorboard等实验跟踪工具,避免依赖冲突
save_steps: 100 # 每100步保存一次模型检查点,防止训练中断丢失进度
stage: sft # 训练阶段为有监督微调(SFT),大模型微调基础阶段
template: qwen # 对话模板为Qwen专属,匹配模型输入输出格式
trust_remote_code: true # 允许加载Qwen自定义代码,否则无法加载模型
warmup_steps: 0 # 关闭学习率预热,小数据集/少轮数训练无需预热直接手动训练即可:
cmd
llamafactory-cli train your_config.yaml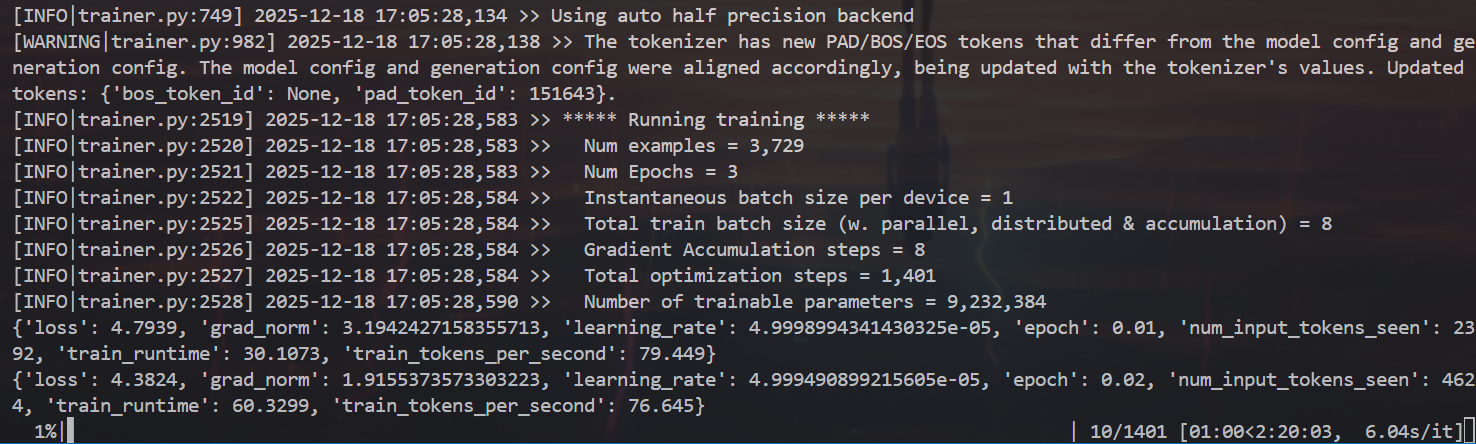
训练过程可以看loss变化:
cmd
tensorboard --port 6007 --logdir E:\myStage\postgraduate\LLM-init\LLaMA-Factory-main\saves\Qwen2.5-1.5B\lora\train_2025-12-18-17-03-11训练过程中,系统会按照logging_steps的参数设置,定时输出训练日志,包含当前loss,训练进度等训练完后就可以在设置的output_dir下看到如下内容,主要包含3部分:
- adapter开头的就是 LORA保存的结果了,后续用于模型推理融合
- training_loss 和tralner_log等记录了训练的过程指标
- 其他是训练当时各种参数的备份
loss在 正常情况下会随着训练的时间慢慢变小,最后需要下降到1以下的位置才会有一个比较好的效果,可以作为训练效果的一个中间指标、
finetuning_type选择
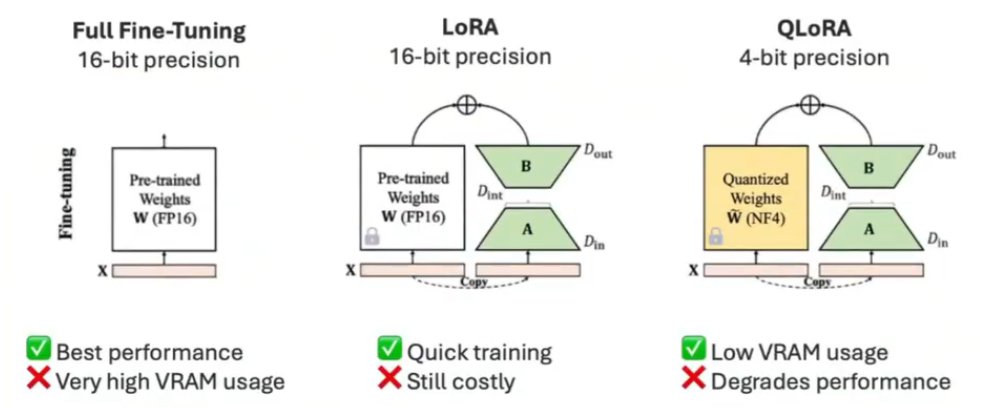
- 全参微调:涉及在指令数据集上重新训练预训练模型所有参数
- LoRA:冻结权重并在每个目标层引入小型适配器(低秩矩阵)。参数数量大大低于完全微调(不到1%),减少了内存使用量和训练时间,这种方法是非破坏性的,可以随时切换或组合适配器。
- QLoRA(量化感知低秩自适应):LoRA的扩展,可进一步节省内存,与标准LoRA相比,最多可额外节省33%的内存,这在GPU内存受限时尤其有用。资源的节省是以更长的训练时间为代价的,QLoRA的训练时间比常规LoRA多39%。
指令模板
本项目 Llama3-Chinese-Instruct 沿用原版 Llama3-Instruct 的指令模板。以下是一组对话示例:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.你是一个乐于助人的助手。<|eot_id|><|start_header_id|>user<|end_header_id|>
你好<|eot_id|><|start_header_id|>assistant<|end_header_id|>
你好!有什么可以帮助你的吗?<|eot_id|>
- 角色需要 "开始 + 结束"→ 避免角色名与内容混淆;
- 内容不需要 "开始"→ 角色结束后自然衔接内容;
- 整个文本不需要 "结束"→ 最后一个内容结束就是文本收尾。
batch size 如何设置
在深度学习中,选择合适的 batch size(批次大小)对模型的训练效果、训练时间和资源消耗有重要影响:
小 batch size(如 1-32)
- 模型泛化性好 :小的 batch size 往往会产生更多的梯度噪声,这种噪声有助于避免模型陷入局部最优解,从而提高模型的泛化能力。
- 内存占用少:适合在 GPU 显存有限的情况下使用。
- 训练时间长:由于每个 batch 的数据较少,完整训练完一遍数据需要很长的时间,训练效率很低。
- 不稳定的梯度:由于个体的差异性或者异常值的影响,模型的参数变化也会很大,每一层的梯度都具有很高的随机性,梯度波动较大,可能会导致训练过程不稳定,导致模型难以收敛,有可能导致模型欠拟合。
大batch size(如128 及以上)
- 训练速度快:由于每个 batch 包含更多的数据,模型的并行计算效率更高,每轮选代的时间更短稳定的梯度:梯度更加平滑,模型训练曲线会更加平滑,训练过程更稳定,尤其是对于深层网络,一般来说batchslze越大,其确定的下降方向越准,引起训练震荡越小。
- 需要更多的内存: batch size 需要更大的 GPU 显存,对于资源受限的环境不适用
- 可能导致泛化性下降:大 batch size 会降低梯度的随机性,可能导致模型更容易过拟合,导致模型泛化能力下降
如何平衡batchsize大小?
batchsize太大或者太小都不好。所以batch size 的值越大,梯度也就越稳定,而 batch size 越小,梯度具有越高的随机性,但如果 batch size太大,对于内存的需求就更高,同时也不利于网络跳出局部极小点。所以,我们需要设置一个合适的batchsize值,在训练速度和内存容量之间导找到最佳的平衡点。
-
一般在Batchsize增加的同时,我们需要对所有样本的训练次数(也就是后面要讲的epoch)增加(以增加训练次数达到更好的效果)。这同样会导致耗时增加,因此需要寻找一个合适的batchsize值,在模型总体效率和内存容量之间做到最好的平衡。由于上述两种因素的矛盾,batchsize增大到某个时候,达到时间上的最优,由于最终收敛精度会陷入不同的局部极值,因此batchsize增大到某些时候,达到最终收敛精度上的最优。
大 batch 会减少单 epoch 的 step 数和时间,为了保证总训练步数足够,需要适当增加 epoch 数。
-
线性调节学习率:有些研究表明,当batch size增加时,学习率可以成比例增大_以稳定训练效果,例如,如果 batch size 增加2倍,学习率可以相应增加 2营
-
逐步增加:在训练的早期使用较小的 batch size,随着训练的进行,逐渐增大batch size,这种策略有时能帮助模型更快地收敛。
-
数据集规模:对于非常大的数据集,较大的 batch size 可能更合适,因为它能加快训练速度。
-
任务类型:对于某些任务(如图像分类),较大的 batchsize 可能效果更好,而对于其他任务(如语音识别、文本生成),可能需要较小的 batch size 以获得更好的泛化性。
-
使用自适应 batch size 技术:动态调整:有些优化器(如 LAMB)支持自适应调整batch size,根据训练的不同阶段自动调整,以获得最佳的训练效果。还有比如batch scaling等
-
硬件资源的限制:如果 GPU 显存限制了 batch size,可以考电梯度票积(Gradient Accumulation)技术,在多次小batch 的基础上累积梯度,以模拟更大的batch size.
选择合适的 batch size是一个需要平衡训练速度、资源使用和模型性能的问题,可以通过实验和验证来找到适合你具体任务的最佳 batch size,通常从一个较小的值开始,然后逐步调整。
中断继续训练
经常因为设备故障,或者调整参数等中断了训练,从头训练则费时费力,则可以从保存的 checkpoint 处继续训练
中断之后继续训练,可以使用下面命令,训练步数也会从保存的 checkpoint 处开始,比如 checkpoint 保存点是 400 步,但是在 450 步中断,会从 400 开始继续
bash
--resume_from_checkpoint /workspace/checkpoint/codellama34b_sk_10epoch/checkpoint-4000
--output_dir new_dir
#--resume_lora_training 这个可以不设置
#如果不需要output_dir,另外两条命令都不加,脚本会自动寻找最新的 checkpoint
--output_dir /workspace/checkpoint/codellama34b_sk_10epoch当然使用命令训练,没有用 webui 看 loss 那么直观,需要加一个命令
bash
--plot_loss # 添加此参数以生成loss图在训练结束后,loss 图会保存在--output_dir指定的目录中
如果可以通过添加命令,从检查点开始继续训练,但训练集会从头开始训练,适合用新数据集继续训练
bash
# lora的保存路径在llama-factory根目录下,如saves/qwen2-7b-int4-Chat\lora\train_2024-07-17-15-56-58\checkpoint-500
--adapter_name_or_path lora_save_patch也可以在 webui 中指定检查点路径,把路径复制进去
3. 训练结束:
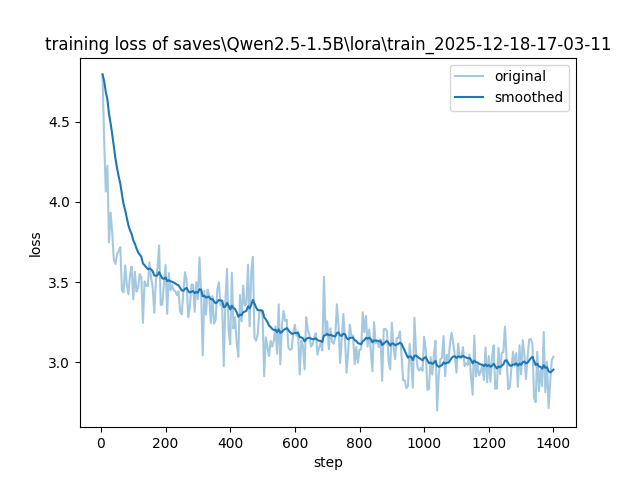
微调结束后,由于使用的是LoRA训练,所以需要对模型参数进行合并导出 ,根据官方导出教程,合并命令和配置文件merge_config.yaml如下:
五、模型评估
1. LoRA动态加载测试
bash
llamafactory-cli chat --model_name_or_path D:\\llama\\Qwen2.5-1.5B-Instruct\\Qwen2.5-1.5B-Instruct --adapter_name_or_path saves\Qwen2.5-1.5B\lora\train_2025-12-18-17-03-11\checkpoint-1401 --template qwen2. 0-shot和5-shot评测
0-shot和5-shot评测是评估大型语言模型(LLMs)在没有或有限的样本下解决问题的能力的方法
0-shot评测
0-shot评测是指在没有任何针对特定任务的训练或示例的情况下,直接评估模型在新任务上的表现。这种方法测试了模型能否利用其预训练期间获得的知识和推理能力来解决问题。
示例 :假设我们有一个预训练的语言模型,我们想评估它在解析法律问题上的能力。在0-shot评测中,我们不会提供任何法律问题的例子或训练数据给模型。我们直接给模型一个法律问题,比如:
"What is the difference between a tort and a crime?"
然后,我们评估模型生成的答案是否准确和全面。
5-shot评测
5-shot评测提供了一个折中的方法,其中模型在尝试任务之前会看到几个示例。这些示例提供了一些上下文和任务的基本信息,但仍然要求模型展示其泛化能力。
示例:继续使用法律问题的例子,但在5-shot评测中,我们会先给模型提供5个类似的法律问题和它们的答案,例如:
- "What is the legal definition of theft?"
- "What are the elements of a contract?"
- "Can you explain the concept of due process?"
- "What is the difference between civil law and criminal law?"
- "What rights do defendants have in a criminal trial?"
然后,模型会被要求回答一个新的问题,比如:
"What are the key differences between common law and statutory law?"
在这种情况下,模型已经通过前5个问题获得了一些关于法律术语和概念的知识,我们可以评估它是否能够利用这些信息来正确回答问题。
3. 大模型主流评测benchmark
虽然大部分的主流需求是定制一个下游的垂直模型,但是在部分场景下,也可能有同学会使用本项目来做更高要求的模型训练,用于大模型刻单等,比如用于评测mmlu等任务。当然这类评测同样可以用于评估大模型二次微调之后,对于原来的通识知识的泛化能力是否有所下降。(因为一个好的微调,尽量是在具备垂直领域知识的同时,也保留了原始的通用能力)
在完成模型训练后,您可以通过 llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml 来评估模型效果。
配置示例文件 examples/train_lora/llama3_lora_eval.yaml 具体如下:
yaml
### examples/train_lora/llama3_lora_eval.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft # 可选项
### method
finetuning_type: lora
### dataset
task: mmlu_test
template: fewshot
lang: en
n_shot: 5
### output
save_dir: saves/llama3-8b/lora/eval
### eval
batch_size: 4相关参数介绍
| 参数名称 | 类型 | 介绍 |
|---|---|---|
| task | str | 评估任务的名称,可选项有 mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 评估数据集的文件夹路径,默认值为 evaluation。 |
| batch_size | int | 每个GPU使用的批量大小,默认值为 4。 |
| seed | int | 用于数据加载器的随机种子,默认值为 42。 |
| lang | str | 评估使用的语言,可选项为 en、zh,默认值为 en。 |
| n_shot | int | few-shot 的示例数量,默认值为 5。 |
| save_dir | str | 保存评估结果的路径,默认值为 None。如果该路径已经存在则会抛出错误。 |
| download_mode | str | 评估数据集的下载模式,默认值为 DownloadMode.REUSE_DATASET_IF_EXISTS。如果数据集已经存在则重复使用,否则则下载。 |
windows下评测实例:
cmd
llamafactory-cli train --stage sft --do_train False --do_eval True --model_name_or_path D:\llama\Qwen2.5-1.5B-Instruct\Qwen2.5-1.5B-Instruct --adapter_name_or_path saves\Qwen2.5-1.5B\lora\train_2025-12-18-17-03-11\checkpoint-1401 --finetuning_type lora --template qwen --dataset alpaca_zh_demo --eval_dataset alpaca_zh_demo --per_device_eval_batch_size 1 --output_dir saves\Qwen2.5-1.5B\eval_result4. 大模型评估集
知识语言理解、推理能力,多轮开放式对话,总数抽取与生成能力,内容审核和叙事控制,编程能力
两个开源自动化评测项目
支持非常全面的自动化评测任务:
5. 批量推理
BLEU(Bilingual Evaluation Understudy)和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是两种在自然语言处理(NLP)领域中广泛使用的评估指标
BLEU
- BLEU是一种评估机器翻译质量的指标,它通过计算机器翻译输出与一组参考翻译之间的重叠程度来评分。
- 它主要关注n-gram的精确度,即机器翻译输出中的n-gram(连续的n个词,预测后面的词)与参考翻译中的n-gram有多少是匹配的。
- BLEU分数越高,表示机器翻译的质量越接近人类翻译。
- BLEU也考虑了短句惩罚,以避免机器翻译输出过短而获得不准确的高分。
ROUGE
- ROUGE主要用于评估自动文本摘要的质量,它可以评估生成的摘要与一组参考摘要之间的相似度。
- ROUGE有多个变体,包括ROUGE-N(评估n-gram的重叠)、ROUGE-L(最长公共子序列的重叠)和ROUGE-S(skip-gram的重叠)等,注:skip-gram(连续m个词,中间空n个词)。
- ROUGE的分数也是越高越好,表示生成的摘要与参考摘要的相似度越高。
这两种指标都是基于召回率(recall)的,即它们更关注机器生成的文本中包含了多少参考文本(也就是标签)信息。
在批量推理的过程中,模型的BLEU和ROUGE分数会被自动计算并保存,您也可以通过此方法评估模型。
环境准备
使用自动化的bleu和rouge等常用的文本生成指标来做评估。指标计算会使用如下3个库,请先做一下pip安装:
bash
pip install jieba # 中文文本分词
pip install rouge-chinese
pip install nltk # 自然语言处理工具包(Natural Language Toolkit)