简约而不简单:JustRL如何用最简RL方案实现1.5B模型突破性性能
当整个强化学习领域都在追求复杂化时,一篇来自清华大学的论文提出了一个颠覆性的问题:这些复杂性真的必要吗?JustRL以一种极简的单阶段训练方法,在两个1.5B参数的推理模型上实现了当前最佳性能,同时仅使用复杂方法一半的计算资源。这项研究不仅挑战了现有的RL训练范式,更为整个领域提供了一个经过验证的简单基线。
论文标题: JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
来源: arXiv:2512.16649v1 cs.CL | https://arxiv.org/abs/2512.16649
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
大型语言模型在数学推理和编程等挑战性任务上的成功很大程度上归功于大规模强化学习与可验证奖励(RLVR)的应用。然而,对于小型轻量模型,学术界和工业界却走向了不同的道路。领先企业更倾向于通过蒸馏(distillation)来提升小模型性能,即使用大型教师模型的输出进行监督微调。这种方法在短期内确实高效、稳定且能立即带来性能提升,Qwen3的强到弱蒸馏和DeepSeek-R1都证明了这一策略的有效性。
但蒸馏存在根本性局限:其性能上限受教师模型能力约束。当研究人员依赖蒸馏来改善小型模型性能时,他们遇到了一个天花板,特别是在教师模型更新不频繁的情况下。即使增加数据和延长训练时间,一旦教师模型性能达到平台期,进一步的性能提升变得非常困难。相比之下,当蒸馏过程达到饱和时,RL可以提供进一步的改进,使其成为此类场景下的关键方法。
与此同时,针对小模型的RL训练却以不稳定和困难而闻名,需要越来越复杂的技术才能可靠工作。过去一年中,我们看到了大量方法试图稳定和改善小模型的RL训练:多阶段训练管道、动态超参数调度、自适应温度控制、响应长度惩罚,以及各种形式的数据策划和过滤。这种技术的激增引发了一个重要问题:这种复杂性真的必要吗?
研究问题
当前小模型RL训练面临的具体挑战包括:
- 训练不稳定性:许多近期工作将训练不稳定性(如奖励崩溃、熵漂移和长度爆炸)作为其复杂技术的动机,但这些技术往往建立在已经复杂的基线之上,使得无法确定新方法是提供真正的好处还是仅仅补偿了先前复杂性引入的问题。
- 累积复杂性:当不同工作结合不同方法子集并报告不同结果时,很难确定真正驱动性能的因素。更令人担忧的是,累积的"最佳实践"可能在相互对抗,而不是解决RL的基本挑战。
- 性能上限约束:蒸馏方法虽然稳定,但受教师模型能力限制,当达到蒸馏极限时,缺乏进一步的提升路径。
主要贡献
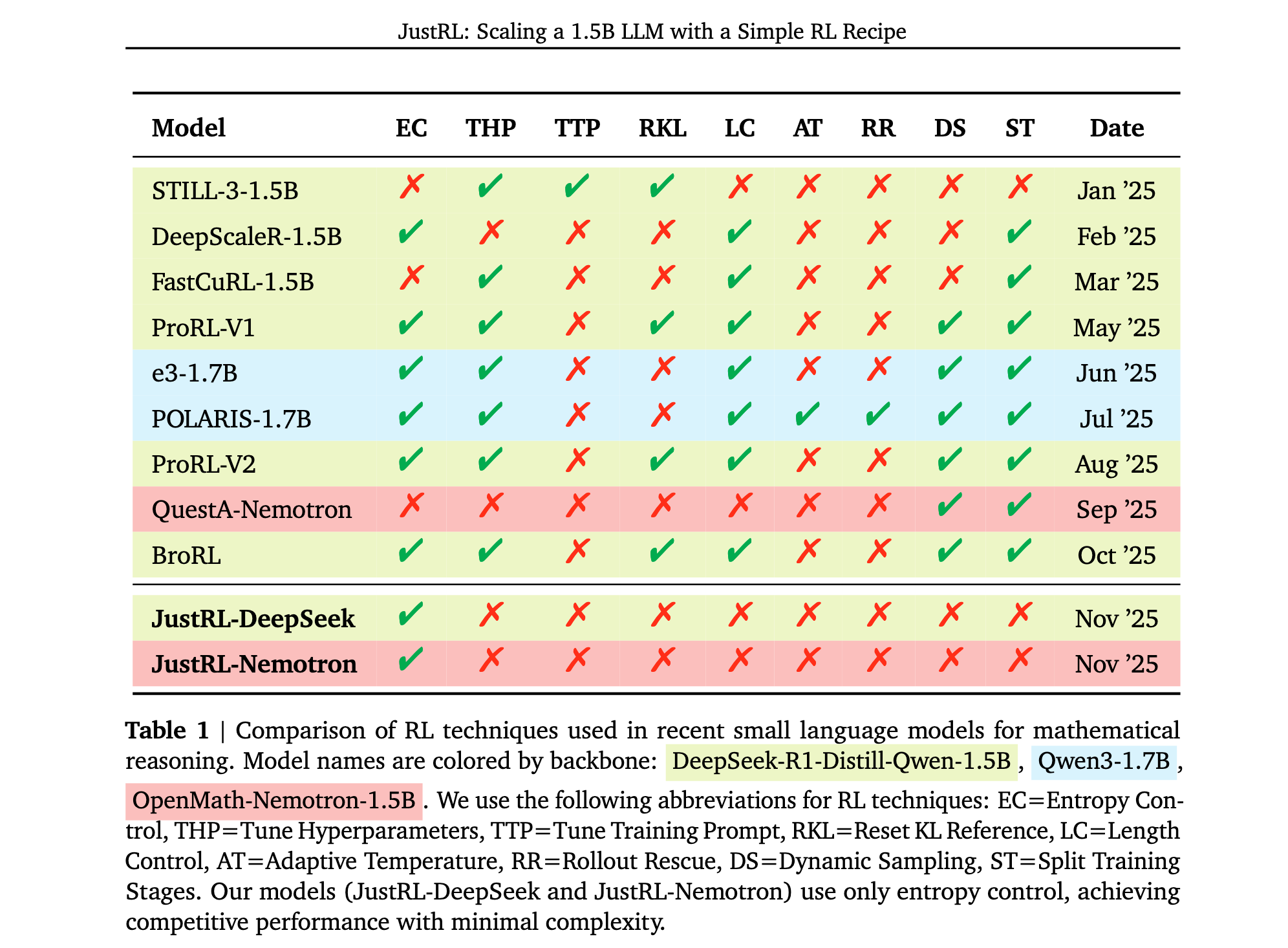
- 极简训练方案:提出了一个极简的单阶段训练方法,使用固定超参数,在两个1.5B推理模型上实现了最先进的性能(九个数学基准测试中平均准确率达到54.9%和64.3%),同时仅使用复杂方法一半的计算量。
- 跨模型通用性:相同的超参数在两个不同模型间无需调整即可迁移,训练过程展现出超过4000步的平滑单调改进,没有通常需要干预的崩溃或平台期。
- 复杂性批判:通过消融实验揭示,添加"标准技巧"如显式长度惩罚和鲁棒验证器可能通过崩溃探索而降低性能,表明领域可能正在增加复杂性来解决在稳定、规模化基线中消失的问题。
- 方法论启示:为社区建立了一个简单、经过验证的基线,倡导方法论转变:从简单开始,扩大规模,只有当简单、稳健的基线明显失败时才增加复杂性。
方法论精要
JustRL的核心方法论是刻意简化的,研究者将自己约束在RL的基础要素上,避免了近期工作中常见的多阶段管道、动态调度和专门技术。
核心算法设置
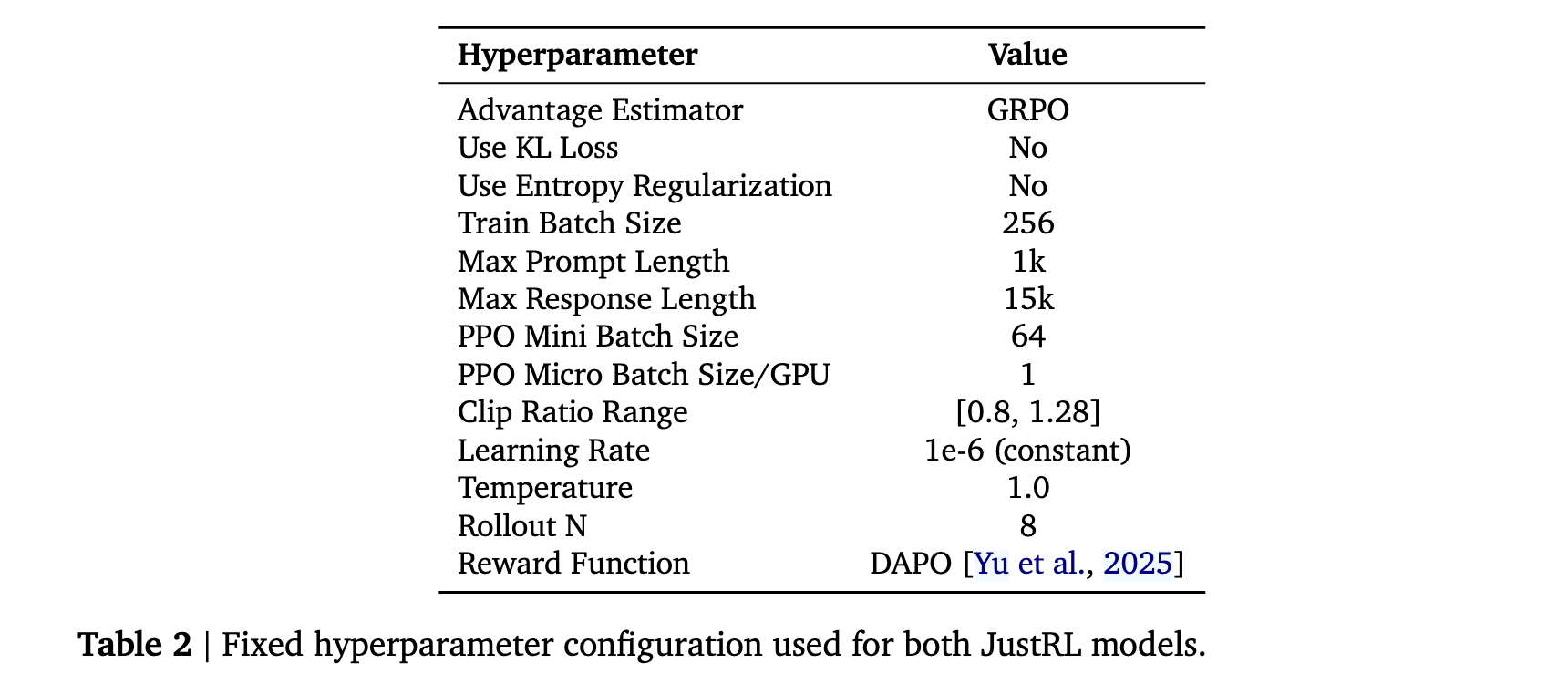
JustRL使用veRL框架中GRPO(Generalized Relative Policy Optimization)的默认实现,采用二元结果奖励。奖励信号来自DAPO的轻量级基于规则的验证器,没有使用SymPy等可能增加计算开销的符号数学库。
简化的关键要素:
- 单阶段训练:没有渐进式上下文长度扩展,没有课程切换,没有阶段转换。从开始到结束连续训练。
- 固定超参数:没有自适应温度调度,没有动态批量大小调整,没有训练中期的参考模型重置。
- 标准数据:在DAPO-Math-17k数据集上训练,没有离线难度过滤或在线动态采样策略。
- 基础提示:简单的后缀提示,无需调优:"Please reason step by step, and put your final answer within \boxed{}."
- 长度控制:简单地将最大上下文长度设置为16K tokens,而不是使用显式长度惩罚项。
唯一保留的技术:
研究者采用了"clip higher"技术,这是长期视野RL训练中稳定性的既定实践。他们将其视为基线的一部分而非附加技术。
超参数配置
JustRL在两个1.5B推理模型上使用veRL训练此方案:DeepSeek-R1-Distill-Qwen-1.5B和OpenMath-Nemotron-1.5B,每个模型使用32个A800-80GB GPU训练约15天。相同的超参数对两个模型都有效,无需针对模型调优,并在整个训练过程中保持固定。
评估协议
为了确保公平比较,JustRL采用了POLARIS的可重现评估脚本,评估九个具有挑战性的数学推理任务:
基准测试: AIME2024、AIME2025、AMC2023、MATH-500、Minerva Math、OlympiadBench、HMMT Feb 2025、CMIMC 2025和BRUMO 2025。
评估协议: 报告Pass@1准确率,对每个问题平均N个采样响应(MATH-500、Minerva Math和OlympiadBench使用N=4;其他使用N=32)。使用温度0.7、top-p 0.9,并允许最多32K tokens用于生成。使用CompassVerifier-3B轻量级基于模型的验证器来增强现有系统,解决基于规则的验证器的假阴性问题。
训练动态分析
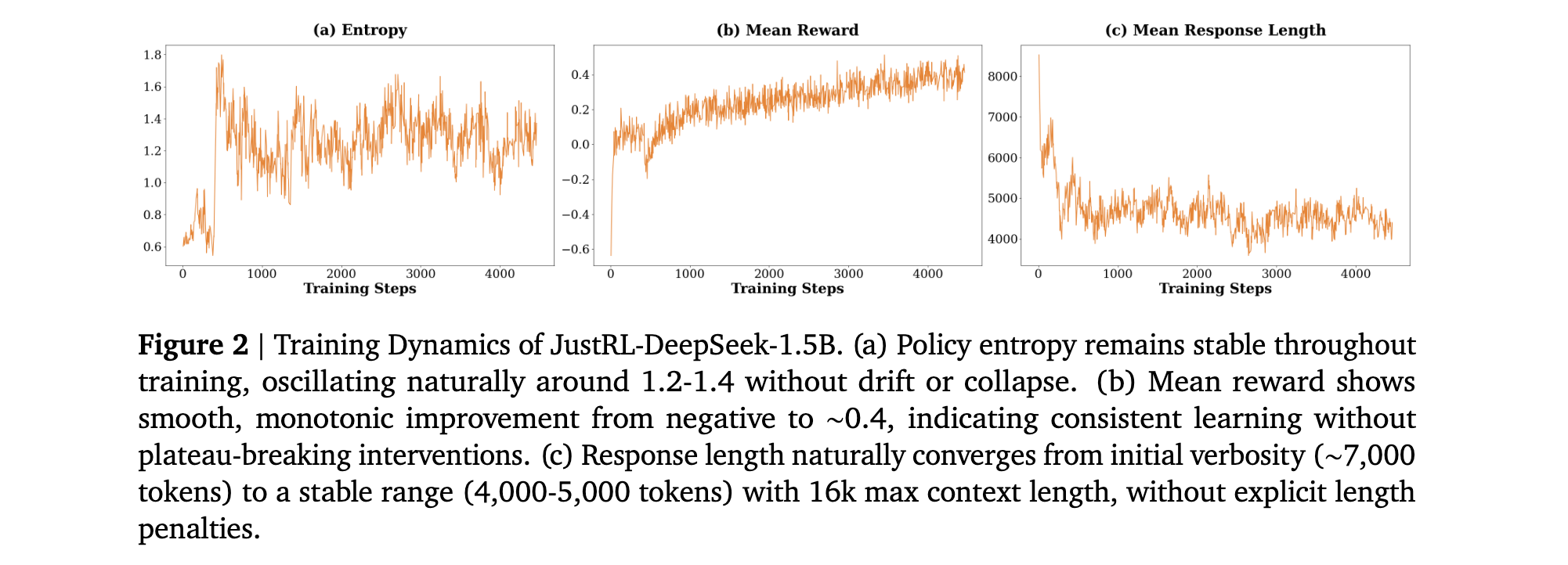
JustRL的训练动态分析揭示了其稳定性的本质。通过对JustRL-DeepSeek-1.5B在4000训练步骤中的三个关键动态跟踪:平均训练奖励、策略熵和平均响应长度,研究者发现:
- 策略熵稳定性:策略熵在后期训练步骤中在1.0到1.6之间振荡,没有系统性向上(探索崩溃)或向下(过早收敛)漂移,表明简单的"clip higher"技术在大规模RL中表现良好。
- 奖励单调改进:平均奖励从约-0.6上升到+0.4。曲线虽然嘈杂,但趋势明显向上。更重要的是,没有扩展的平台期或突然下降,这些通常会在多阶段方法中触发干预。
- 响应长度自然收敛:模型开始时较为冗长,生成平均约8000 tokens的响应。在没有任何显式长度惩罚的情况下,到第1000步时自然压缩到4000-5000 tokens并维持这个范围。这种有机压缩可能比显式惩罚更稳健,后者可能产生模型学会博弈的对抗性压力。
与传统RL方法的对比
JustRL的训练动态与典型RL形成鲜明对比。许多近期工作明确将训练不稳定性作为其技术的动机:
- ProRL-v2在观察到长度漂移后引入调度长度惩罚
- BroRL在达到平台期后将推演增加到数百个
- 多个工作在KL散度过大时应用KL正则化和重置参考模型,这限制了训练上限
JustRL的训练没有表现出这些需要干预的病理现象。虽然研究者无法进行广泛的受控比较,但文献提供了背景:当许多近期方法明确引用训练不稳定性作为其技术动机时,JustRL的最小配方产生的训练动态根本不需要已成为标准实践的干预。
实验洞察
JustRL在两个流行的1.5B推理模型上应用,展示了其最小配方如何以显著稳定的训练动态实现竞争性能。
缩放较弱基座:JustRL-DeepSeek-1.5B
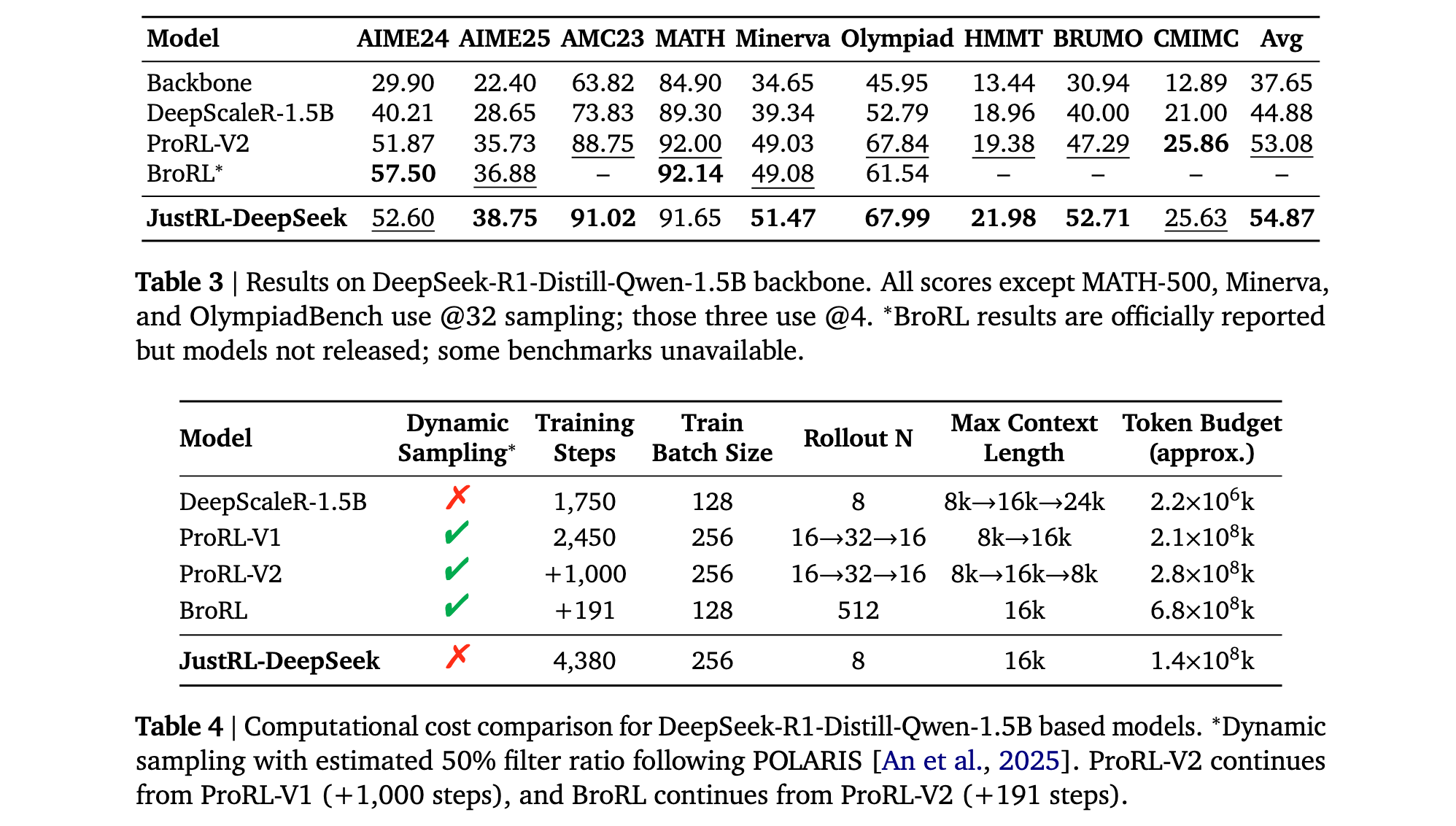
核心发现1: 从DeepSeek-R1-Distill-Qwen-1.5B开始,通过单阶段训练和固定超参数获得更好结果,在使用2倍较少计算的情况下超越更复杂的方法。训练曲线显示超过4000步的稳定改进,无需干预,表明足够规模与简单方法的结合可以超越复杂技术。
研究者使用简单的单阶段配方训练DeepSeek-R1-Distill-Qwen-1.5B共4380步。在九个数学基准测试中的avg@32结果报告显示,JustRL-DeepSeek-1.5B实现了54.87%的平均准确率,超过了ProRL-V2的53.08%,尽管ProRL-V2采用了九阶段训练管道和动态超参数及更复杂的技术。JustRL在九个基准中的六个上领先,展示了广泛改进而非对单一任务的过拟合。
计算效率: 真正的问题是简单性是否带来计算成本。答案是否定的。JustRL匹配了ProRL-V2一半的计算预算,同时使用单阶段配方和固定超参数。BroRL通过将每个例子的推演增加到512个需要4.9倍更多的计算,基本上是穷尽探索解决方案空间。JustRL的方法在没有这种计算开销的情况下实现了竞争性能。
缩放较强基座:JustRL-Nemotron-1.5B
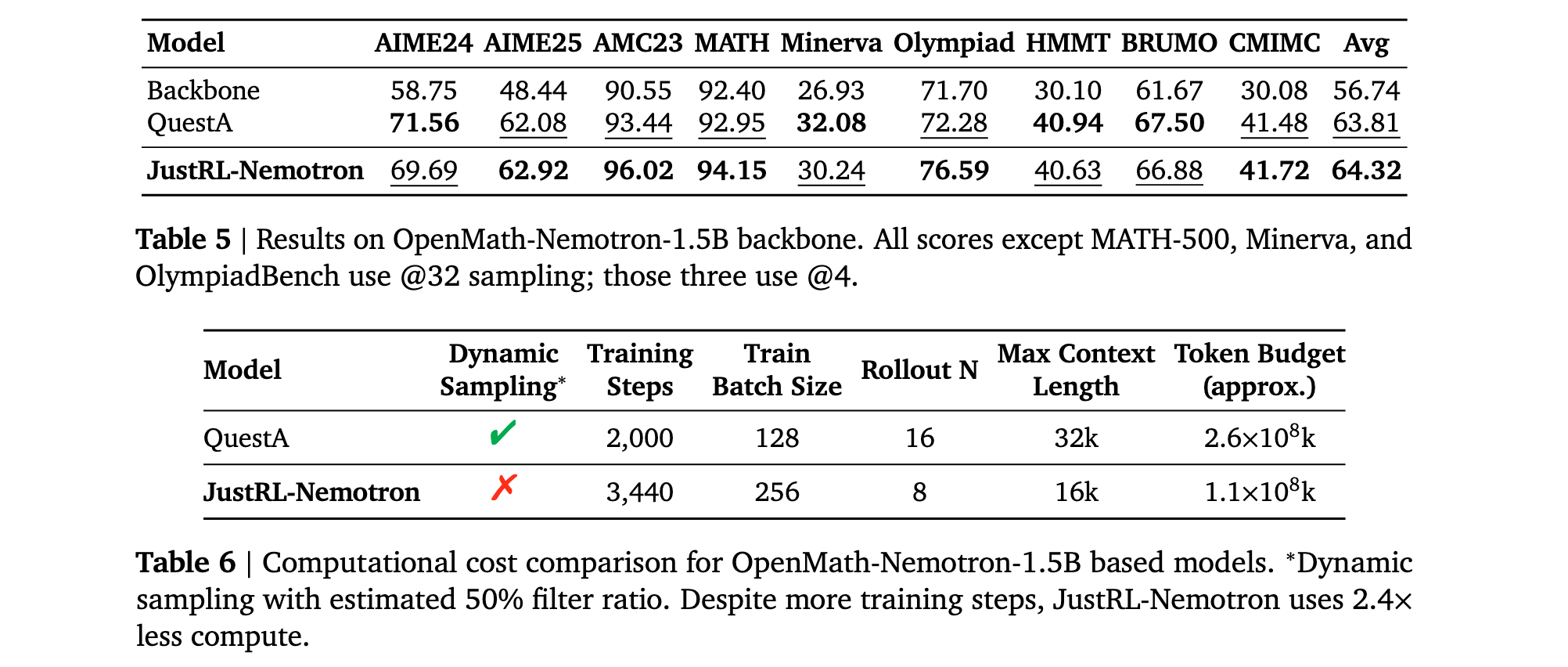
核心发现2: 相同的配方将OpenMath-Nemotron-1.5B缩放到当前最佳数学推理性能,无需任何超参数调整,匹配使用课程学习和问题增强的最先进结果。在两个不同起点上的竞争性能表明该方法是稳健的,而非针对特定条件的仔细调优。
研究者使用相同配方训练OpenMath-Nemotron-1.5B共3440步,无需超参数更改。在九个具有挑战性的数学基准上的评估结果显示,JustRL实现了64.32%的平均准确率,略微超过QuestA的63.81%,并在九个基准中的五个上领先。
差距很小,这很合理。两种方法都在推动1.5B规模可实现性的边界。关键区别在于如何达到那里。QuestA引入了创新的课程学习方法,通过用部分CoT解决方案增强问题作为提示,通过不同难度的分阶段训练提供更丰富的学习信号。这不仅需要真实答案,还需要大型模型生成的完整推理轨迹来构建课程,具有额外的数据需求和工程复杂性。JustRL仅使用标准的问题-答案对,无需增强或课程设计。
计算效率: 在实现略好平均性能的同时,JustRL使用了2倍较少的计算,而没有设计QuestA中使用的复杂课程。
消融研究
为了验证简单方法的有效性,研究者进行了两个消融研究,从JustRL-DeepSeek-1.5B的基础配方开始,都训练3000+步:
- 添加过长惩罚:添加对最后4k tokens的显式长度惩罚项(如DAPO中使用)
- 添加过长惩罚+鲁棒验证器:进一步添加DeepScaleR的更复杂验证器以减少假阴性
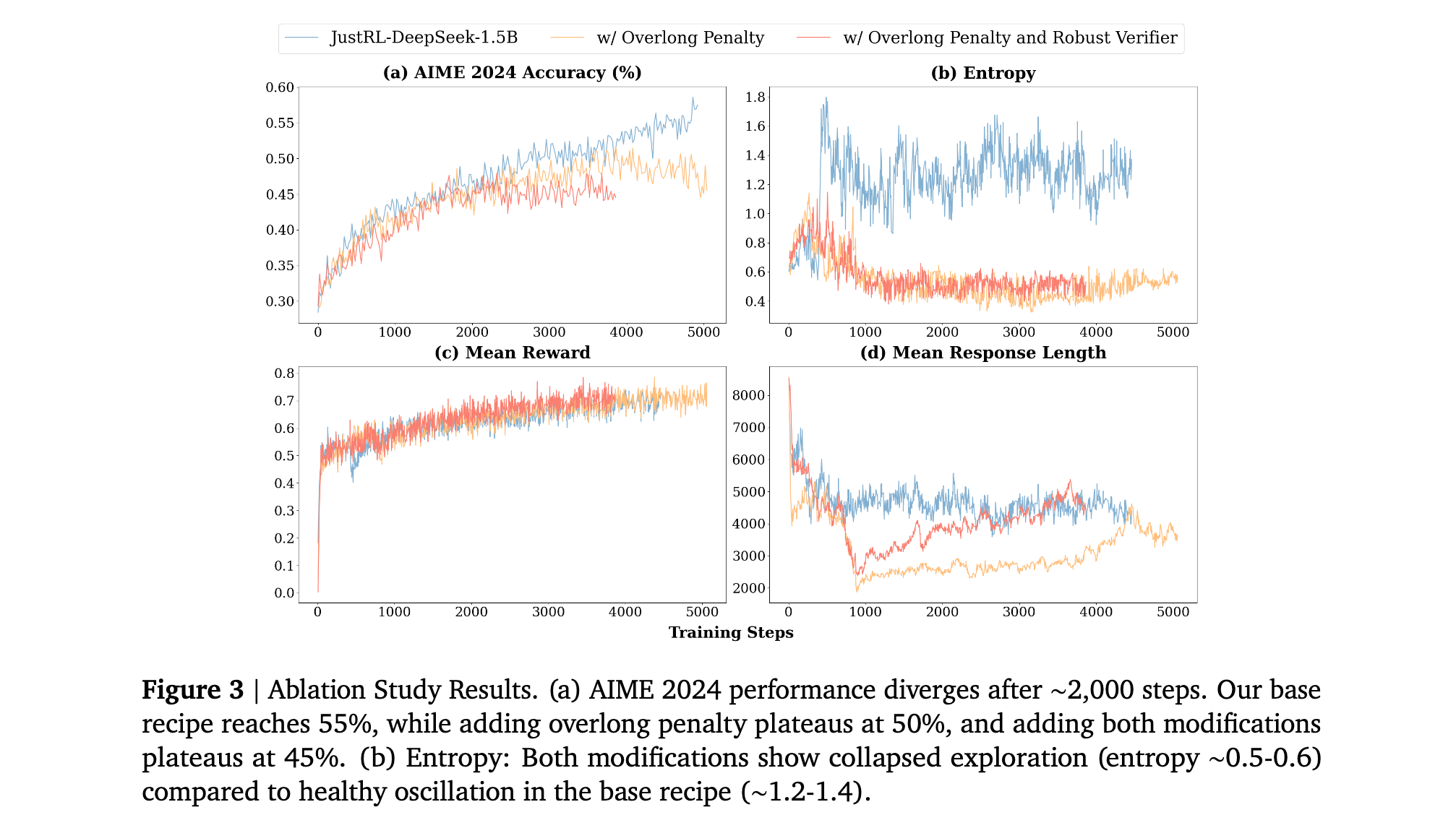
结果显示两种修改都降低了性能:添加过长惩罚在AIME 2024上平台期达到50%(对比基线55%),添加两种修改平台期达到45%。
过长惩罚的影响: 研究者假设显式惩罚冗长响应可能通过更快推动模型向简洁性来提高训练效率。相反,性能显著降低。熵图揭示了原因:显式惩罚崩溃了探索,将熵降低到0.5-0.6,对比基础方法的1.2-1.4范围。显式惩罚似乎创造了与学习目标冲突的压力,迫使过早收敛到较短响应,在模型探索真正有效的方法之前。
鲁棒验证器的影响: 研究者进一步假设减少假阴性(正确解被标记错误)将提供更清晰的学习信号。然而,即使在归一化奖励尺度后,其使用导致更差的最终性能,在AIME 2024上平台期达到45%。
研究者提供了两种可能解释:首先,更严格的基础验证器通过减少"完美"分数创建更丰富的学习信号谱,而鲁棒验证器的宽松性提供较少的细致指导。其次,严格验证器对精确格式的依赖可能压力模型发展更稳健的内部计算,当验证器外部纠正错误时这种激励就丢失了。因此,宽容的验证器可能无法鼓励最优泛化所需的精确性。
方法论启示
这些结果揭示了两个重要教训:
- 并非所有"标准技巧"都能跨情境转移:过长惩罚在DAPO的设置中有效,但在JustRL的设置中降低性能,展示了技术以复杂且有时不可预测的方式与其他设计选择相互作用。
- 简单方法并非总是更容易改进:研究者测试了两个看似合理的修改,都使情况变糟,表明基础配方达到了微妙平衡,容易被附加干预破坏。
研究者的观点不是附加技术永远没有帮助,而是它们应该经验验证而非假设有益。