🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到:
Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
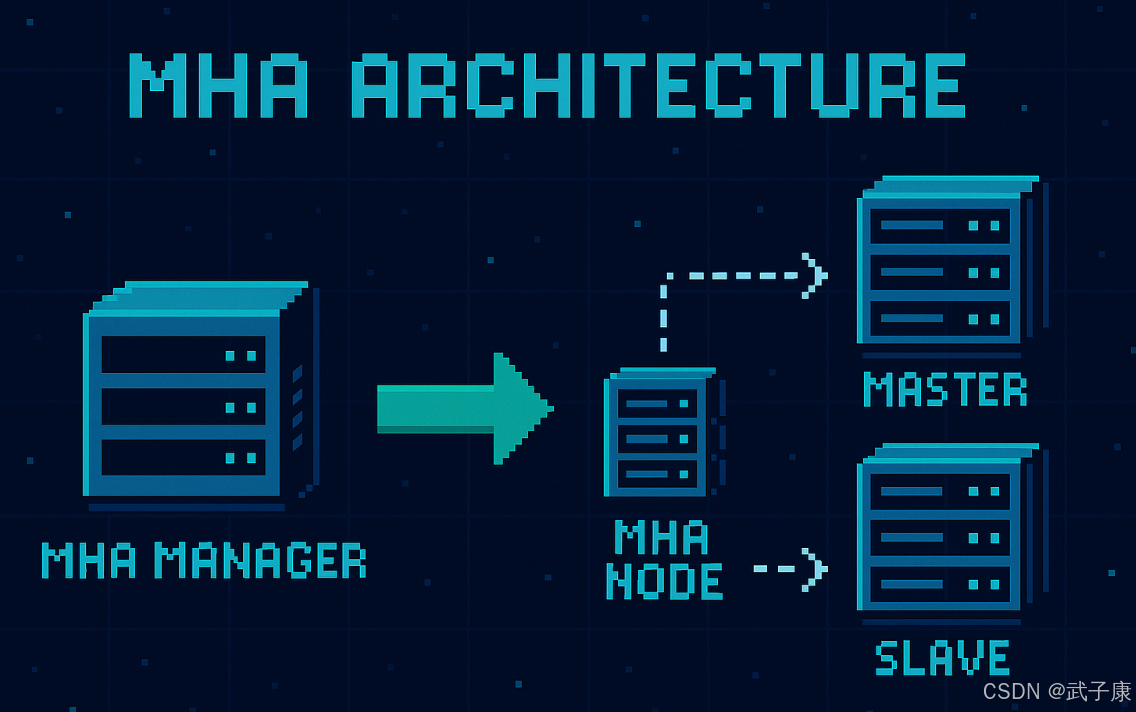
MHA架构详解
MHA基本概念
MHA(Master High Availability)是一套成熟的MySQL高可用解决方案,由日本DeNA公司的Yoshinori Matsunobu开发。它主要用于实现MySQL主从架构下的自动化故障转移和主从切换功能。
核心功能特性
-
快速故障转移:
- 能够在30秒内自动完成主库故障检测和从库提升
- 典型的故障转移时间在10-30秒之间,具体取决于网络环境和配置
- 支持手动触发的主库切换(计划内切换),通常仅需0.5-2秒
-
数据一致性保障:
- 通过对比各从库的relay log差异,确保数据一致性
- 支持自动从旧主库获取binlog进行数据修复
- 提供多种数据一致性检查机制
-
灵活的部署方式:
- 支持标准的主从复制架构
- 兼容基于GTID的复制模式
- 可与半同步复制配合使用增强数据安全性
典型应用场景
-
金融交易系统:
- 需要保证交易数据零丢失的支付系统
- 证券交易所的订单处理系统
-
电商平台:
- 大促时段的订单处理系统
- 商品库存管理系统
-
社交网络服务:
- 用户关系链存储系统
- 即时消息存储系统
工作原理
-
监控阶段:
- MHA Manager通过定期ping检查主库可用性
- 监控主库的复制线程状态
- 检查网络连通性
-
故障检测:
- 当主库不可达时,启动二次确认机制
- 通过多台服务器交叉验证故障情况
-
故障转移流程:
- 识别数据最接近主库的候选从库
- 应用差异relay log确保数据一致
- 提升新主库并重新配置其他从库
优势比较
相比于其他高可用方案(如DRBD、Heartbeat等),MHA具有以下优势:
- 不需要共享存储设备
- 不依赖特定的硬件配置
- 对应用完全透明,无需修改应用代码
- 支持标准的MySQL版本,无需特殊补丁
局限性
- 需要至少一个从库才能工作
- 故障转移期间会有短暂的写入中断
- 需要额外的Manager节点进行监控管理
目前MHA主要支持一主多从架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
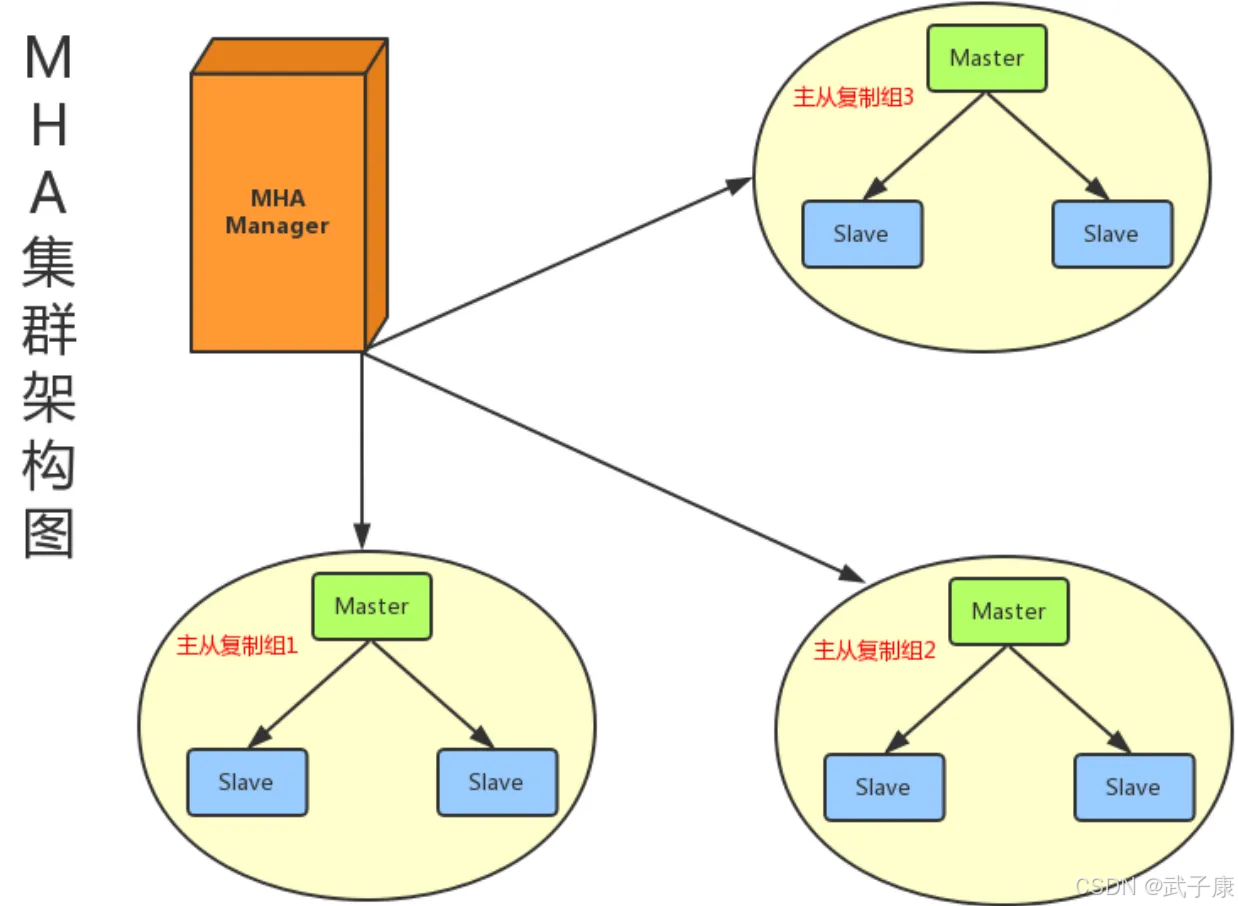
组成部分
MHA(Master High Availability)主要由两个核心组件构成,它们协同工作以实现MySQL的高可用性:
1. MHA Manager(管理节点)
MHA Manager是整个架构的控制中心,负责监控和管理整个MySQL主从复制集群。它具有以下特点和功能:
-
部署方式灵活:
- 可以独立部署在专用管理服务器上,同时监控多个Master-Slave集群
- 也可以部署在某台Slave节点上,节省硬件资源
-
主要职责:
- 持续监控Master节点的健康状态(通过定期ping检测)
- 在Master故障时自动触发并控制故障转移流程
- 实时检查MySQL复制状态和延迟情况
- 维护服务器配置信息和复制拓扑关系
- 提供管理接口支持手动故障转移操作
-
典型工作流程:
- 每3秒(可配置)检测一次Master可达性
- 当连续3次检测失败时判定Master故障
- 自动选择数据最新的Slave作为新Master
- 协调所有Node完成VIP切换和复制关系重建
2. MHA Node(数据节点)
MHA Node是运行在每个MySQL实例上的代理程序,无论该实例当前是Master还是Slave角色。它的主要功能包括:
-
核心功能:
- 在Master节点上:实时保存和传输二进制日志(binlog)
- 在Slave节点上:接收并应用中继日志(relay log)
- 精确识别各Slave间的日志差异点
- 将缺失的日志事件应用到落后的Slave
- 定期清理过期的中继日志文件
-
关键工作机制:
- 使用SSH协议与其他节点通信
- 实现精确的日志位置比对算法
- 支持并行应用差异日志以加快恢复速度
- 提供API供Manager调用来执行具体操作
-
典型应用场景:
- 当Master宕机时,Node会配合Manager完成:
- 从旧Master抢救未传输的binlog
- 将缺失的日志补全到新Master
- 修改其他Slave的复制指向
- 更新应用连接使用的VIP地址
- 当Master宕机时,Node会配合Manager完成:
整个故障转移过程通常能在10-30秒内完成,且对应用程序完全透明,无需人工干预,确保了业务连续性。MHA还会自动发送邮件通知管理员故障转移的详细情况。
故障处理
MHA故障处理机制详解
MHA(Master High Availability)作为MySQL高可用解决方案,其故障处理机制主要包括以下完整步骤:
-
保存宕机主库的二进制日志
- 自动检测到Master宕机后,立即将Master服务器的binlog日志文件完整保存
- 通过SSH连接到原Master服务器,将未同步的binlog传输到管理节点
- 示例:如果Master在事务ID=100的位置宕机,会保存100之后的所有binlog事件
-
定位最新的从库
- 通过对比所有Slave的
SHOW SLAVE STATUS信息 - 根据
Exec_Master_Log_Pos和Relay_Log_Pos确定数据最接近Master的Slave - 优先选择启用半同步复制的Slave(如果配置了半同步)
- 通过对比所有Slave的
-
修复其他从库
- 从最新Slave获取relay log信息
- 使用
mysqlbinlog工具解析和重放relay log到其他落后Slave - 确保所有Slave达到相同的数据状态
-
恢复未同步的binlog
- 将第一步保存的Master binlog在新主库上应用
- 使用
mysqlbinlog --start-position=XXX指定精确位置恢复 - 完整性检查确保没有数据丢失
-
主从切换操作
- 在最新Slave执行
STOP SLAVE; RESET MASTER; - 修改my.cnf配置,启用log-bin等主库必需参数
- 通过
CHANGE MASTER TO命令提升为新的Master
- 在最新Slave执行
-
重建复制拓扑
- 在所有其他Slave执行:
sql
STOP SLAVE;
CHANGE MASTER TO MASTER_HOST='new_master_ip';
START SLAVE;- 验证
Seconds_Behind_Master是否为0 - 配置新的主从监控机制
应用场景:
- 硬件故障导致主库不可用
- 主库意外崩溃(如OOM kill)
- 网络分区导致主库不可达
- 计划内的主库维护窗口
异常处理:
- 如果binlog保存失败,会尝试从磁盘恢复
- 当多个Slave数据差异较大时,会触发一致性校验
- 网络问题会导致自动重试机制启动
MHA(Master High Availability)优点详解
1. 自动故障转移速度快
MHA能够在主库发生故障时,在10-30秒内自动完成故障检测和主从切换。相比人工干预需要数分钟甚至更长时间,MHA大大缩短了服务不可用时间。其快速故障转移的关键在于:
- 实时监控主库状态
- 预先配置好的故障检测机制
- 自动化的故障处理流程
2. 数据一致性保障
在主库崩溃的情况下,MHA通过以下机制确保数据一致性:
- 自动识别和应用最新binlog事件
- 从多个从库中选择数据最完整的作为新主库
- 确保所有从库都与新主库保持同步
这种方式避免了传统主从切换可能导致的"脑裂"问题。
3. 性能表现优异
MHA支持多种复制模式,可根据业务需求灵活配置:
- 半同步复制 :平衡数据安全性和性能
- 示例应用:金融交易系统
- 异步复制 :最大化性能
- 示例应用:高并发Web应用
- 可根据不同从库设置不同的复制模式
4. 集中式监控管理
单个MHA Manager节点可以同时监控和管理多个MySQL集群(通常可管理10-20个集群),具有以下优势:
- 降低管理成本
- 统一监控界面
- 集中告警机制
- 典型部署场景:
- 企业级多业务线数据库环境
- SaaS服务提供商的多租户架构
此外,MHA还支持自定义故障转移脚本,可以根据业务需求扩展功能,如:
- 故障转移前执行数据校验
- 切换后自动修改应用连接配置
- 发送详细的故障通知
主备切换
主备切换是指将备库转换为主库,原主库转换为备库的过程,这是数据库高可用架构中的核心机制。根据业务需求的不同,主要有两种切换策略:
-
可靠性优先策略:确保数据一致性为最高优先级
- 典型实现步骤:
a) 停止主库写入
b) 等待备库追上主库(Seconds_Behind_Master=0)
c) 提升备库为新主库
d) 开启新主库写入 - 适用场景:金融交易、订单系统等对数据一致性要求严格的业务
- 典型实现步骤:
-
可用性优先策略:保证服务可用性为最高优先级
- 典型实现步骤:
a) 直接提升备库为新主库
b) 允许新主库立即接受写入
c) 原主库追赶数据 - 适用场景:社交网络、内容平台等更注重服务连续性的业务
- 典型实现步骤:
主备延迟
主备延迟是由主从数据库同步延迟导致的性能指标,它反映了备库数据相对于主库的滞后程度。与数据同步有关的关键时间点主要包含以下三个:
-
T1时刻:主库A完成事务执行并写入binlog文件
- 例如:14:00:00完成订单支付事务写入
-
T2时刻:备库B完全接收到该binlog
- 例如:14:00:02收到binlog(网络传输耗时2秒)
-
T3时刻:备库B执行完该binlog中的事务
- 例如:14:00:05完成事务执行(执行耗时3秒)
主备延迟的计算公式为:延迟时间 = T3 - T1。在上例中,延迟时间为5秒。
在MySQL中,可以通过执行SHOW SLAVE STATUS命令获取复制状态信息。其中重要的字段包括:
Seconds_Behind_Master:表示当前备库延迟秒数Relay_Log_Pos:备库当前执行的binlog位置Master_Log_File:备库正在读取的主库binlog文件
延迟的常见原因包括:
- 网络带宽不足导致binlog传输延迟
- 备库服务器性能不足导致SQL线程执行缓慢
- 大事务或DDL操作阻塞复制进程
- 备库承担读负载导致资源竞争
延迟原因
备库机器性能问题
- 硬件配置不足:备库服务器可能使用较老的CPU、内存不足或存储性能较差,特别是使用机械硬盘而非SSD的情况
- 资源过载:常见情况是一台机器同时作为多个主库的备库(例如1台备库服务3-5个主库),导致IO、CPU、网络等资源被过度分摊
- 网络瓶颈:主备库之间的网络带宽不足或延迟较高,影响binlog传输速度
分工问题
- 读操作负载:备库承担了应用的大量读请求(如报表查询、数据分析等),典型的"读写分离"场景下,读压力过大会直接影响复制线程性能
- 后台任务干扰 :例如:
- 定时执行的统计计算任务
- 大数据量的备份操作
- 定期维护任务(如optimize table)
- 资源分配不当:未对复制线程设置资源优先级,导致其与业务查询争抢CPU和IO资源
大事务操作
- 典型场景 :
- 单次删除大量数据(如
DELETE FROM logs WHERE create_time < '2020-01-01') - 大表结构变更(如为千万级表添加索引)
- 批量导入数据(如通过load data导入GB级数据)
- 单次删除大量数据(如
- 影响机制 :
- 主库执行完成后才会将整个事务写入binlog
- 备库必须单线程应用这些大型事务
- 期间产生的锁竞争会阻塞后续复制事件
- 特殊案例 :长时间运行的显式事务(如未及时提交的
BEGIN...COMMIT)也会产生同样问题
可靠性优先
主备切换过程一般由专门的HA高可用组件完成,但是切换过程中会存在短时间不可用,因为在切换过程中某一时间主库A和从库B都是只读状态,如下图所示:
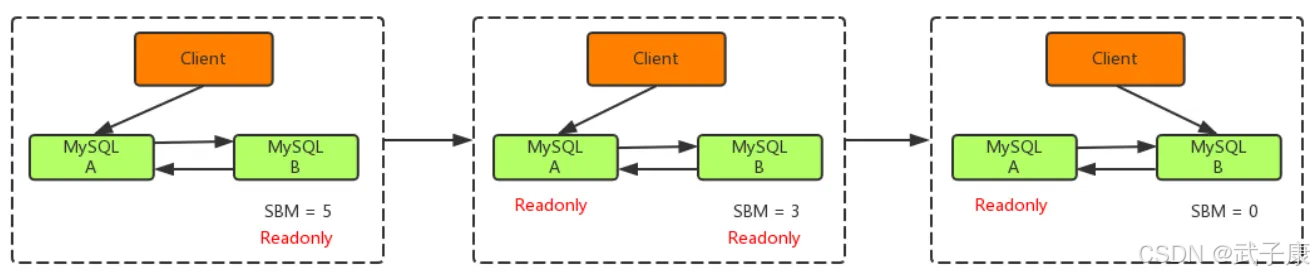
主库由A切换为B,切换的具体流程如下:
● 判断从库B的 seconds_behind_master 值,当小于某个值才能继续下一步
● 把主库A改为只读状态(readonly=true)
● 等待从库B的 seconds_behind_master 值降为0
● 把从库B改为可读状态(readonly=false)
● 把业务请求切换至从库B
可用性优先
不等主从同步我那成,直接把业务请求切换至从库B,并且让从库B可读写,这样几乎不存在不可用时间,但是会使数据不一致。
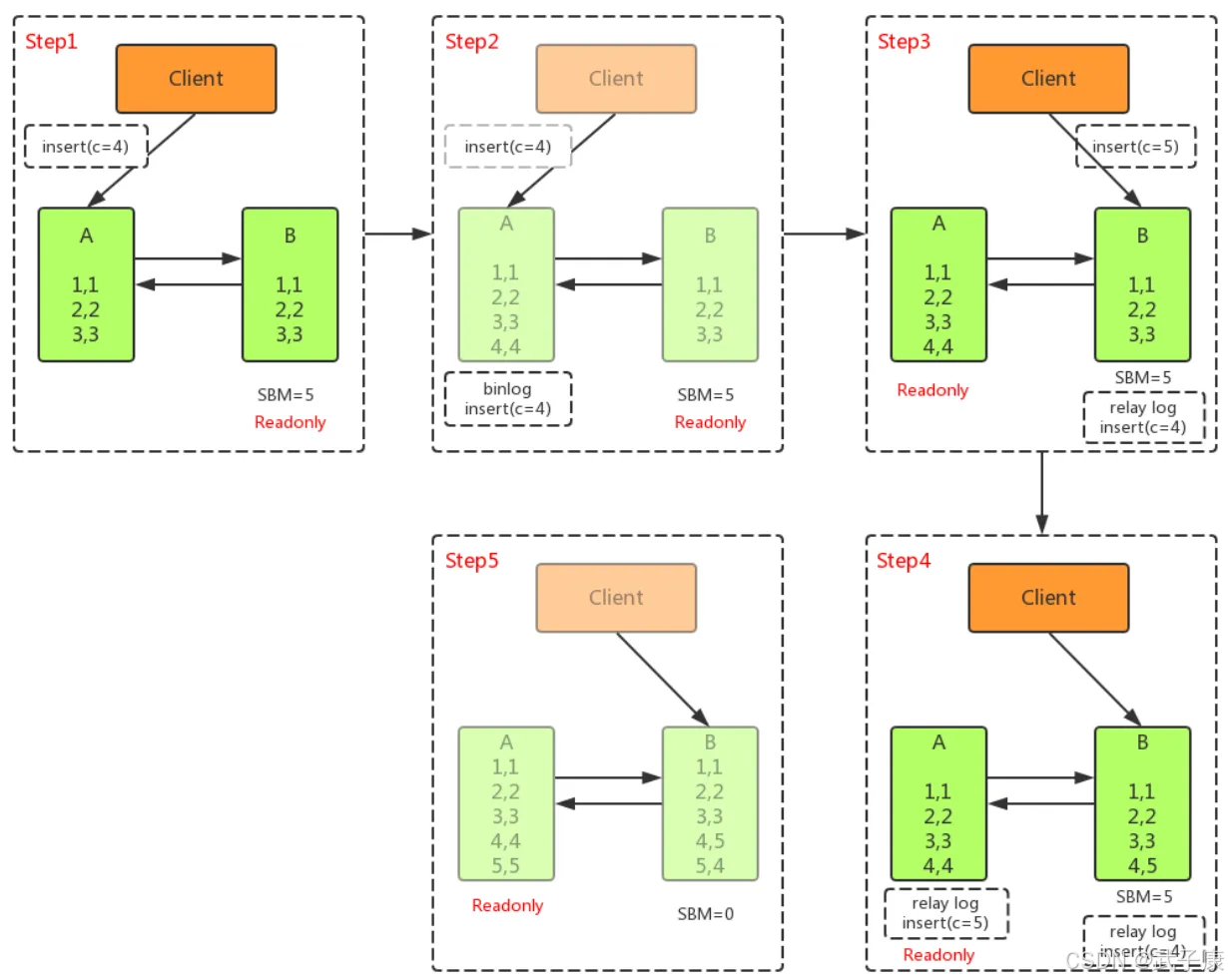
如上图所示,在A切换到B的过程中,执行了两个 INSERT 操作,过程如下:
● 主库A执行完 INSERT c=4,得到 (4,4),然后开始执行主从切换
● 主从之间有5S的同步延迟,从库B会先执行INSERT c=5,得到(4,5)
● 从库B执行主库A传过来的 binlog日志 INSERT c=4,得到(5,4)
● 主库A执行从库B传过来的binlog日志,INSERT c=5,得到(5,5)
● 此时主库A和从库B会有两行不一致的数据
通过上面介绍了解到,主备切换采用可用性优先策略,由于可能会导致数据不一致,所以多数情况下,优先选择可靠性优先战略,在满足数据可靠性的前提下,MySQL的可用性依赖于同步延时的大小,同步延时越小,可靠性就越高。