大模型私有化部署
文章目录
-
- 大模型私有化部署
- 私有化大模型选择
-
- GLM发展历程总结与特点
- **ChatGLM3私有化本地部署**
- [# **步骤**](# 步骤)
-
- 0x01.**模型资源评估**
- 0x02.**GPU环境确认**
- 0x03.**Python环境准备**
- 0x04.**GPU版PyTorch安装**
- 0x05.**验证当前PyTorch与CUDA是否兼容**
- **0x06.获取工程**
- **0x07.**安装ChatGLM3项目依赖库
- [**0x08.** Demo验证](#0x08. Demo验证)
私有化大模型选择
- 支持中文的
- 开源的
- 可商用
- 性能好
- 低成本部署
- 建议考虑支持国产芯片
本节主要针对选择的 智谱GLM (智谱AI ) 成立2019年6月 清华大学计算机系知识工程实验室(KEG)的技术成功转换来的。支持国产芯片。
GLM发展历程总结与特点
| 时间 | 模型 | 参数量 | 主要贡献与特点 |
|---|---|---|---|
| 2021 | GLM-1 | - | 提出自回归空白填充范式,统一理解与生成 |
| 2022 | GLM-130B | 1300亿 | 对标GPT-3,开源 、双语 、高效量化,奠定地位 |
| 2023 | ChatGLM-6B | 60亿 | 现象级开源对话模型,极大降低大模型使用门槛 |
| 2023 | GLM-2 | 1B/10B | 系列化、商业化,满足不同规模部署需求 |
| 2024 | GLM-4 | 未知 | 全面对标GPT-4,支持多模态 、长上下文 、智能体 |
git 地址请参见 https://github.com/THUDM/
ChatGLM3私有化本地部署
模型参数精度的选择需要找到关键的权衡点。一方面使用更高精度的数据类型可以提供更高的数值精度,同时会占用更多的内存计算速度慢对设备的性能要求会更高,与此同时使用低精度的数据类型可以节省内存并加速计算,但会导致数值精度损失。在实际应用中,需要更具项目的需要,具体选择模型的精度和硬件设备和性能的搭配。
量化技术
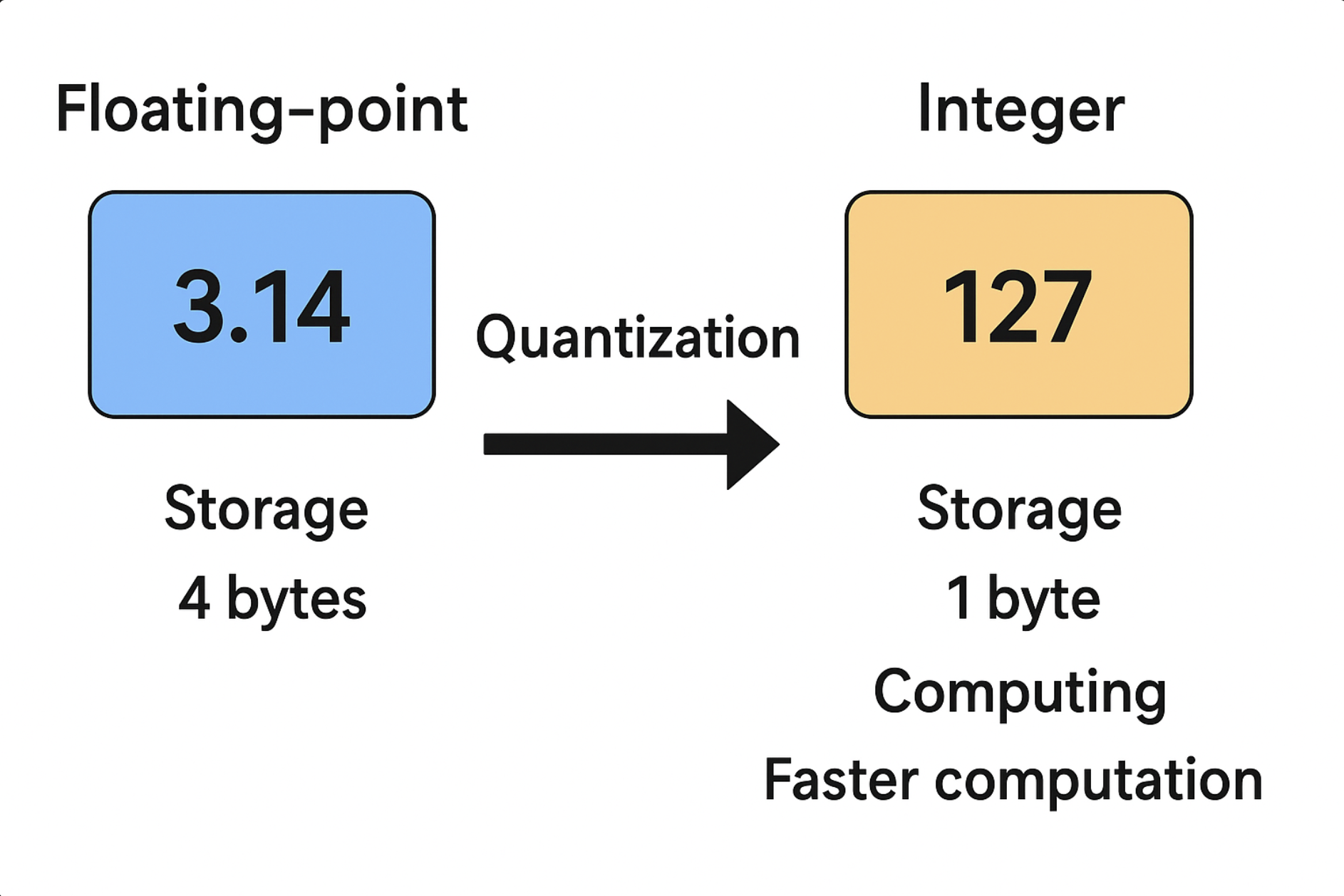
量化(Quantization)确实是一种 模型压缩与加速技术 ,它的核心思想就是:把模型中的 浮点数(通常是 FP32)参数和激活值 映射到 较低精度的整数表示(如 INT8、INT4)。这样一来:
-
存储成本降低
FP32 占 4 字节
INT8 只占 1 字节
模型体积可以缩小 约 4 倍
-
计算速度提升
在许多硬件(如 ARM CPU、GPU、TPU、NPU)上,低精度整数运算比浮点运算更快。特别是 INT8 矩阵乘法(GEMM)在移动设备和推理加速芯片上有硬件支持。
-
功耗降低
存储带宽减少,访存和运算的能耗也随之降低,更适合部署在边缘设备和移动端
# 步骤
0x01.模型资源评估
见我的大模型基础知识。
0x02.GPU环境确认
Mac用户:打开"终端",输入以下命令:system_profiler SPDisplaysDataType
0x03.Python环境准备
建议安装anaconda(https://www.anaconda.com/download),网站会自动识别安装什么版本
0x04.GPU版PyTorch安装
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看
作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
确认是否已经安装2.0版本及以上的GPU版本的PyTorch,ChatGLM3-6B运行过程需要借助PyTorch来完成
相关计算。
python
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
---
PyTorch version: 2.8.0
CUDA available: False0x05.验证当前PyTorch与CUDA是否兼容
编程模型
-
CUDA 提供了一套扩展 C/C++/Fortran 的 API,开发者可以像写普通 C 程序一样编写 GPU 代码。
-
代码分为 主机端(Host,运行在 CPU) 和 设备端(Device,运行在 GPU)。
-
GPU 程序以 核函数(Kernel Function) 的形式运行,可以由成千上万的线程并行执行。
python
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}") # 在 macOS 上应为 False
print(f"MPS available: {torch.backends.mps.is_available()}") # 在 Apple Silicon 上应为 True
# 检查设备
if torch.backends.mps.is_available():
device = torch.device("mps")
print(f"Using device: {device}")
else:
device = torch.device("cpu")
print("MPS not available, using CPU")0x06.获取工程
首先需要下载本仓库:
shell
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3**0x07.**安装ChatGLM3项目依赖库
pip install -r requirements.txt
安装过程若出现typing-extensions或fastapi等库不兼容性报错,并不会影响最终模型运行,不用进行额外处理。完成了相关依赖库的安装之后,即可尝试进行模型调用了。
0x08. Demo验证
python cli_demo.py