循环神经网络------pytorch实现循环神经网络(RNN、GRU、LSTM)
本文将深入探讨循环神经网络的理论基础,并通过PyTorch深度学习框架来展示如何实现循环神经网络模型。我们将首先介绍循环神经网络的基本概念。通过PyTorch代码示例,我们将展示如何设计、训练和评估一个循环神经网络模型。
python
import torch
print("pytorch version:",torch.__version__)1. 循环神经网络(RNN)简介
想象一下:你读一句话时,会记住前面的词来理解后面的词(比如"我昨天__了苹果",你会根据"昨天"猜出是"吃"而不是"买")。循环神经网络(RNN)就是教AI做类似的事------它能记住序列中的历史信息,专门处理有"时间顺序"的数据 (如文本、语音、股票走势)。
传统神经网络(比如图像识别用的CNN)像"金鱼记忆",只看当前输入;而RNN像"人类大脑",会把上一步的思考结果传给下一步。
1.1 什么是序列数据?
-
通俗解释 :
序列数据就是按时间或顺序排列的一串信息。比如:
- 一句话:"我 爱 你" → 每个词是序列中的一个元素(顺序错了意思就全变!)。
- 一串股票价格:周一100元, 周二105元, 周三98元 → 明天价格取决于前几天走势。
RNN要解决的问题是:输入一串有顺序的东西,输出另一串有顺序的东西(比如输入中文句子,输出英文翻译)。
-
数学形式 :
一个长度为 TTT 的输入序列可以表示为:
x=(x(1),x(2),...,x(T)) \mathbf{x} = \left( \mathbf{x}^{(1)}, \mathbf{x}^{(2)}, \dots, \mathbf{x}^{(T)} \right) x=(x(1),x(2),...,x(T))其中 x(t)∈Rd\mathbf{x}^{(t)} \in \mathbb{R}^dx(t)∈Rd 表示第 ttt 个时间步的输入向量。
对于典型的序列建模,我们希望学习一个函数:
f:(x(1),x(2),...,x(T))↦(y(1),y(2),...,y(T)) f: (\mathbf{x}^{(1)}, \mathbf{x}^{(2)}, \dots, \mathbf{x}^{(T)}) \mapsto (\mathbf{y}^{(1)}, \mathbf{y}^{(2)}, \dots, \mathbf{y}^{(T)}) f:(x(1),x(2),...,x(T))↦(y(1),y(2),...,y(T))
这里 y(t)\mathbf{y}^{(t)}y(t) 是在第 ttt 个时间步的输出。
- 输入序列:
(x¹, x², ..., xᵀ)xᵗ表示第t个时间点的数据(比如t=1是第一个词"我")。- 它是个向量(可以理解为这个词的"数字特征",比如用100个数字描述"我"的含义)。
- 输出序列:
(y¹, y², ..., yᵀ)yᵗ是RNN在第t步的预测结果(比如翻译成英文的第t个词)。
核心目标 :RNN要学一个"翻译规则"------把输入序列(x¹, x², ..., xᵀ)映射成输出序列(y¹, y², ..., yᵀ)。
✅ 关键点 :顺序不能乱!RNN的特殊之处就在于它关心"前因后果",而普通神经网络只看当前输入。
1.2 RNN的核心:隐藏状态
RNN不像普通神经网络只算一步,它有个隐藏状态 hᵗ(可以理解为RNN的"大脑记忆"),每一步都更新这个记忆,用来记住之前发生了什么。
RNN 的核心思想是引入隐藏状态 h(t)\mathbf{h}^{(t)}h(t),它表示到时间步 ttt 时对序列历史信息的编码。递推关系为:
隐藏状态更新:
h(t)=σh(Wxhx(t)+Whhh(t−1)+bh) \mathbf{h}^{(t)} = \sigma_{h} \left( W_{xh} \mathbf{x}^{(t)} + W_{hh} \mathbf{h}^{(t-1)} + \mathbf{b}_h \right) h(t)=σh(Wxhx(t)+Whhh(t−1)+bh)
- Wxh∈Rm×dW_{xh}\in \mathbb{R}^{m \times d}Wxh∈Rm×d:输入到隐藏层权重
- Whh∈Rm×mW_{hh}\in \mathbb{R}^{m \times m}Whh∈Rm×m:隐藏层到隐藏层权重
- bh∈Rm\mathbf{b}_h \in \mathbb{R}^mbh∈Rm:偏置项
- σh\sigma_hσh:非线性函数(如 tanh\tanhtanh 或 ReLU)
其中,h(0)\mathbf{h}^{(0)}h(0) 通常初始化为零向量。
输出计算:
y(t)=σy(Whyh(t)+by) \mathbf{y}^{(t)} = \sigma_{y} \left( W_{hy} \mathbf{h}^{(t)} + \mathbf{b}_y \right) y(t)=σy(Whyh(t)+by)
- Why∈Rk×mW_{hy}\in \mathbb{R}^{k \times m}Why∈Rk×m:隐藏层到输出的权重
- by∈Rk\mathbf{b}_y \in \mathbb{R}^kby∈Rk:输出偏置
- σy\sigma_yσy:任务相关的输出激活函数(如分类可用Softmax)
如果将递推公式沿时间展开,可以表示为:
h(t)=σh(Wxhx(t)+Whh σh(Wxhx(t−1)+Whh σh(⋯ ))) \mathbf{h}^{(t)} = \sigma_h\left( W_{xh} \mathbf{x}^{(t)} + W_{hh} \; \sigma_h\left( W_{xh} \mathbf{x}^{(t-1)} + W_{hh} \; \sigma_h\left( \cdots \right) \right)\right) h(t)=σh(Wxhx(t)+Whhσh(Wxhx(t−1)+Whhσh(⋯)))
这就相当于在时间上共享参数的一个深度网络,每个时间步都使用相同的 Wxh,Whh,WhyW_{xh}, W_{hh}, W_{hy}Wxh,Whh,Why。
✅ 为什么需要非线性函数(tanh/softmax)?
如果没有它们,RNN只能做简单加减(像计算器),其函数形式再怎么复杂都能简化为线性回归,但加了之后就能学习复杂的非线性模式。
1.3 RNN能解决什么问题?------看输入输出的"配对方式"
RNN的强项是处理输入和输出有顺序依赖的任务。根据输入/输出序列的长度,分为4类(普通神经网络只能处理固定长度,而RNN灵活适应各种组合):
| 任务类型 | 输入 → 输出 | RNN为什么适合? | 真实例子 |
|---|---|---|---|
| 一对一 | 固定长度 → 固定长度 | ❌ RNN不必要!普通神经网络就能搞定 | 图像分类:输入一张猫图 → 输出"猫" |
| 一对多 | 1个输入 → 序列输出 | ✅ RNN用初始记忆生成序列 | 图像描述:输入一张图 → 输出"一只狗在跑"(5个词) |
| 多对一 | 序列输入 → 1个输出 | ✅ RNN用最后记忆总结全局信息 | 情感分析:输入"电影太烂了" → 输出"负面" |
| 多对多 | 序列输入 → 序列输出 | ✅ RNN每步更新记忆,实时生成对应输出 | 机器翻译:输入"我爱你" → 输出"I love you" |
2.RNN文本生成任务实战
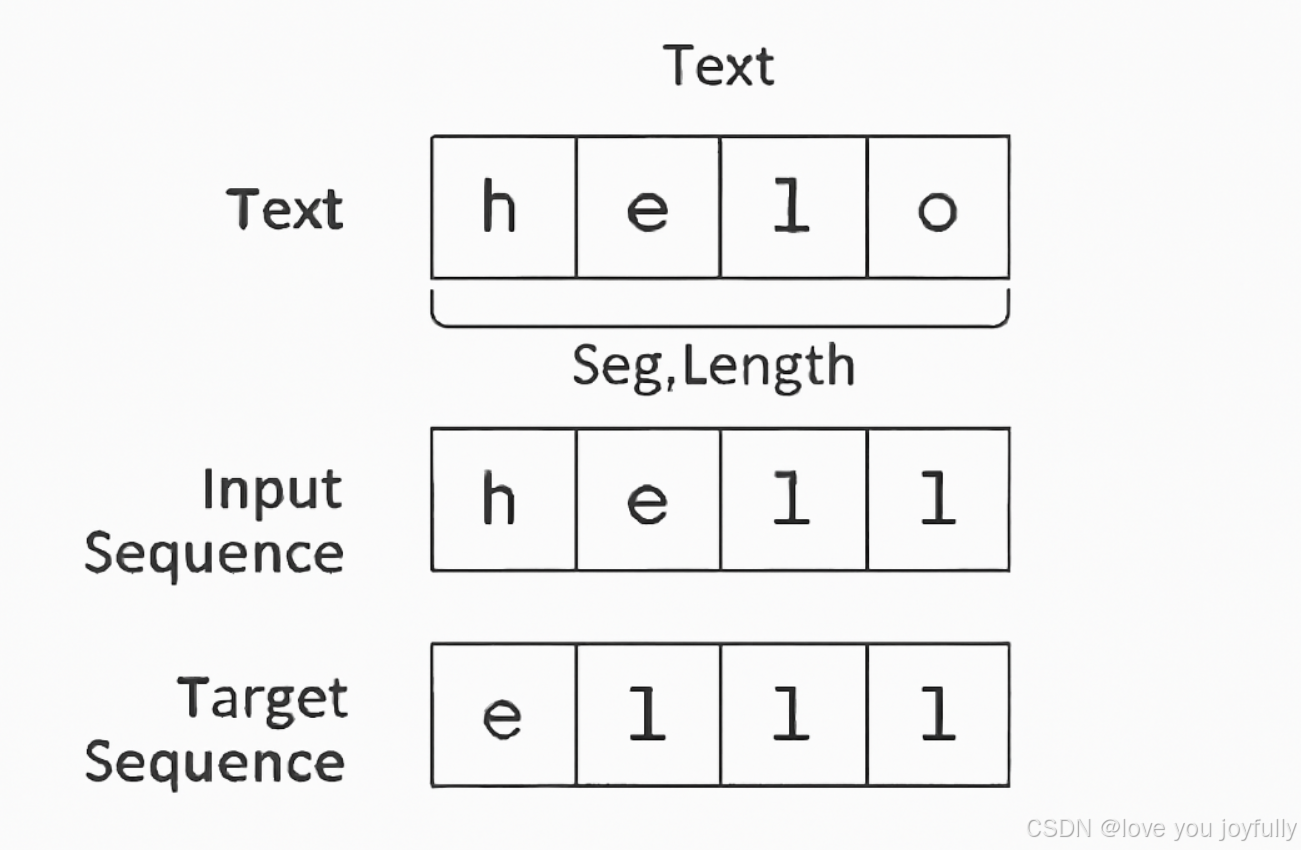
首先,我们需要定义一个名为 TextDataset 的自定义数据集类,用于将原始文本数据预处理成适合训练循环神经网络(RNN)的格式。
它的主要作用是:把一长段文本拆分成一个个有序的字符序列,并构建"输入-目标"样本对,让模型学会根据前一个字符预测下一个字符 。该类首先需要统计文本中所有唯一字符并建立字符与数字索引之间的映射关系,然后将整个文本转换为数字序列;在获取每个样本时,取长度为 seq_length 的字符序列作为输入,其后一个字符开始的相同长度序列作为目标输出(即预测下一个字符),从而形成序列预测任务。
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
import random
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
class TextDataset(Dataset):
"""
自定义文本数据集类
用于处理文本数据,将其转换为适合 RNN 训练的格式
"""
def __init__(self, text, seq_length):
"""
初始化数据集
Args:
text: 原始文本字符串
seq_length: 序列长度(每个训练样本的长度)
"""
self.seq_length = seq_length
# 获取所有唯一字符并创建字符-索引映射
self.chars = sorted(list(set(text)))
self.char_to_idx = {ch: i for i, ch in enumerate(self.chars)}
self.idx_to_char = {i: ch for i, ch in enumerate(self.chars)}
# 将文本转换为索引序列
self.data = [self.char_to_idx[ch] for ch in text]
print(f"数据集信息:")
print(f"- 文本长度: {len(text)}")
print(f"- 唯一字符数: {len(self.chars)}")
print(f"- 字符集: {''.join(self.chars)}")
print(f"- 序列长度: {seq_length}")
def __len__(self):
"""返回数据集大小"""
return len(self.data) - self.seq_length
def __getitem__(self, idx):
"""
获取一个训练样本
Returns:
input_seq: 输入序列 (seq_length,)
target_seq: 目标序列 (seq_length,) - 输入序列向右偏移一位
"""
input_seq = self.data[idx:idx + self.seq_length]
target_seq = self.data[idx + 1:idx + self.seq_length + 1]
return torch.tensor(input_seq, dtype=torch.long), torch.tensor(target_seq, dtype=torch.long)之后,我们定义一个基于 RNN 的文本生成模型 RNNTextGenerator。其作用是让机器学会根据前面的字符预测下一个字符,从而实现文本自动生成。它首先将输入的字符通过嵌入层转换为向量,然后利用多层RNN对序列进行处理,捕捉字符之间的时序依赖关系,最后通过全连接层将RNN的输出映射到词汇表上的概率分布。模型支持批次训练和dropout防止过拟合,并能初始化隐藏状态以保持序列记忆。
该模型包括以下几个部分:
- 词嵌入层:将字符索引转换为稠密向量。
- RNN 层:用于处理序列数据。
- Dropout 层:防止过拟合。
python
class RNNTextGenerator(nn.Module):
"""
基于 RNN 的文本生成模型
"""
def __init__(self, vocab_size, embedding_dim, hidden_size, num_layers, dropout=0.2):
"""
初始化 RNN 模型
Args:
vocab_size: 词汇表大小(字符数量)
embedding_dim: 词嵌入维度
hidden_size: RNN 隐藏层大小
num_layers: RNN 层数
dropout: Dropout 概率
"""
super(RNNTextGenerator, self).__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_layers = num_layers
# 词嵌入层:将字符索引转换为稠密向量
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# RNN 层:可以选择 RNN、LSTM 或 GRU
self.rnn = nn.RNN(
input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=dropout if num_layers > 1 else 0,
batch_first=True # 输入格式为 (batch, seq, feature)
)
# Dropout 层:防止过拟合
self.dropout = nn.Dropout(dropout)
# 输出层:将 RNN 输出映射到词汇表大小
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden=None):
"""
前向传播
Args:
x: 输入序列 (batch_size, seq_length)
hidden: 隐藏状态(可选)
Returns:
output: 输出logits (batch_size, seq_length, vocab_size)
hidden: 新的隐藏状态
"""
batch_size = x.size(0)
# 如果没有提供隐藏状态,则初始化为零
if hidden is None:
hidden = self.init_hidden(batch_size, x.device)
# 词嵌入
embedded = self.embedding(x) # (batch_size, seq_length, embedding_dim)
# RNN 前向传播
rnn_out, hidden = self.rnn(embedded, hidden) # (batch_size, seq_length, hidden_size)
# Dropout
rnn_out = self.dropout(rnn_out)
# 输出层
output = self.fc(rnn_out) # (batch_size, seq_length, vocab_size)
return output, hidden
def init_hidden(self, batch_size, device):
"""
初始化隐藏状态
"""
return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)之后我们定义好训练函数,文本生成函数以及测试函数。首先,通过 TextDataset 将原始文本转换为模型可读的序列样本(输入序列与对应的目标字符);然后,构建一个带有词嵌入层和多层RNN的生成模型 RNNTextGenerator,用于学习字符之间的时序依赖关系;在 train_model 函数中进行多轮训练,使用交叉熵损失和Adam优化器更新参数,同时每几个epoch生成一段文本以观察学习效果;训练完成后,generate_text 函数利用训练好的模型从给定起始字符串出发,逐字符预测并生成新文本(通过softmax采样引入随机性),实现文本生成;最后,test_model 在测试集上评估模型性能,计算平均损失和困惑度,并输出多个生成样例。
python
def train_model(model, dataset, dataloader, criterion, optimizer, device, num_epochs):
"""
训练模型
Args:
model: RNN 模型
dataset: 数据集对象
dataloader: 数据加载器
criterion: 损失函数
optimizer: 优化器
device: 设备(CPU 或 GPU)
num_epochs: 训练轮数
"""
train_losses = []
print("开始训练...")
print("-" * 50)
for epoch in range(num_epochs):
total_loss = 0
num_batches = 0
model.train() # 设置为训练模式
for batch_idx, (input_seq, target_seq) in enumerate(dataloader):
# 将数据移到指定设备
input_seq = input_seq.to(device)
target_seq = target_seq.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
output, _ = model(input_seq)
# 计算损失
# 需要重新调整维度:output (batch, seq, vocab) -> (batch*seq, vocab)
# target (batch, seq) -> (batch*seq)
loss = criterion(output.view(-1, model.vocab_size), target_seq.view(-1))
# 反向传播
loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 更新参数
optimizer.step()
total_loss += loss.item()
num_batches += 1
# 每100个batch打印一次进度
if (batch_idx + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Batch [{batch_idx+1}/{len(dataloader)}], Loss: {loss.item():.4f}')
# 计算平均损失
avg_loss = total_loss / num_batches
train_losses.append(avg_loss)
print(f'Epoch [{epoch+1}/{num_epochs}] 完成, 平均损失: {avg_loss:.4f}')
# 每个epoch结束后生成一些样本文本
if (epoch + 1) % 5 == 0:
sample_text = generate_text(model, dataset, device, "The ", length=50)
print(f'生成样本: {sample_text}')
print("-" * 50)
return train_losses
# ==================== 文本生成函数 ====================
def generate_text(model, dataset, device, start_string, length=100, temperature=1.0):
"""
使用训练好的模型生成文本
Args:
model: 训练好的 RNN 模型
dataset: 数据集对象(用于字符映射)
device: 设备
start_string: 起始字符串
length: 生成文本长度
temperature: 温度参数,控制生成的随机性
Returns:
generated_text: 生成的文本
"""
model.eval() # 设置为评估模式
with torch.no_grad():
# 将起始字符串转换为索引
input_seq = [dataset.char_to_idx[ch] for ch in start_string]
generated = start_string
# 初始化隐藏状态
hidden = model.init_hidden(1, device)
# 生成指定长度的文本
for _ in range(length):
# 准备输入
input_tensor = torch.tensor([input_seq], dtype=torch.long).to(device)
# 前向传播
output, hidden = model(input_tensor, hidden)
# 获取最后一个时间步的输出
last_output = output[0, -1, :] / temperature
# 应用 softmax 并采样
probabilities = torch.softmax(last_output, dim=0)
next_char_idx = torch.multinomial(probabilities, 1).item()
# 转换为字符并添加到结果
next_char = dataset.idx_to_char[next_char_idx]
generated += next_char
# 更新输入序列(滑动窗口)
input_seq = input_seq[1:] + [next_char_idx]
return generated
# ==================== 测试函数 ====================
def test_model(model, test_dataloader, criterion, device, dataset):
"""
测试模型性能
"""
model.eval()
total_loss = 0
num_batches = 0
print("开始测试...")
with torch.no_grad():
for input_seq, target_seq in test_dataloader:
input_seq = input_seq.to(device)
target_seq = target_seq.to(device)
output, _ = model(input_seq)
loss = criterion(output.view(-1, model.vocab_size), target_seq.view(-1))
total_loss += loss.item()
num_batches += 1
avg_test_loss = total_loss / num_batches
perplexity = torch.exp(torch.tensor(avg_test_loss))
print(f"测试结果:")
print(f"- 平均损失: {avg_test_loss:.4f}")
print(f"- 困惑度 (Perplexity): {perplexity:.2f}")
# 生成一些测试样本
print("\n生成的测试样本:")
test_prompts = ["The ", "To be ", "in the "]
for prompt in test_prompts:
generated = generate_text(model, dataset, device, prompt, length=80)
print(f"'{prompt}' -> {generated}")
# ==================== 主函数 ====================
def main():
"""
主函数:完整的训练和测试流程
"""
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 准备示例数据(这里使用一个简单的文本,实际应用中可以使用更大的数据集)
sample_text = """
To be or not to be, that is the question:
Whether 'tis nobler in the mind to suffer
The slings and arrows of outrageous fortune,
Or to take arms against a sea of troubles
And by opposing end them. To die---to sleep,
No more; and by a sleep to say we end
The heart-ache and the thousand natural shocks
That flesh is heir to: 'tis a consummation
Devoutly to be wish'd. To die, to sleep;
To sleep, perchance to dream---ay, there's the rub:
For in that sleep of death what dreams may come,
When we have shuffled off this mortal coil,
Must give us pause---there's the respect
That makes calamity of so long life.
""" * 10 # 重复文本以增加数据量
# 超参数设置
seq_length = 50 # 序列长度
batch_size = 32 # 批次大小
embedding_dim = 128 # 词嵌入维度
hidden_size = 256 # 隐藏层大小
num_layers = 2 # RNN 层数
dropout = 0.3 # Dropout 概率
learning_rate = 0.001 # 学习率
num_epochs = 20 # 训练轮数
# 创建数据集
dataset = TextDataset(sample_text, seq_length)
# 划分训练集和测试集
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# 创建数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(f"训练集大小: {len(train_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
# 创建模型
model = RNNTextGenerator(
vocab_size=len(dataset.chars),
embedding_dim=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=dropout
).to(device)
print(f"\n模型参数数量: {sum(p.numel() for p in model.parameters()):,}")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
train_losses = train_model(model, dataset, train_dataloader, criterion, optimizer, device, num_epochs)
# 绘制训练损失曲线
plt.figure(figsize=(10, 6))
plt.plot(train_losses)
plt.title('training loss over epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()
# 测试模型
test_model(model, test_dataloader, criterion, device, dataset)
# 保存模型
torch.save({
'model_state_dict': model.state_dict(),
'char_to_idx': dataset.char_to_idx,
'idx_to_char': dataset.idx_to_char,
'model_config': {
'vocab_size': len(dataset.chars),
'embedding_dim': embedding_dim,
'hidden_size': hidden_size,
'num_layers': num_layers,
'dropout': dropout
}
}, 'rnn_text_generator.pth')
print("\n模型已保存为 'rnn_text_generator.pth'")
# ==================== 运行主函数 ====================
if __name__ == "__main__":
main()使用设备: cuda
数据集信息:
- 文本长度: 6630
- 唯一字符数: 40
- 字符集:
',-.:;ADFMNOTWabcdefghiklmnopqrstuvwy---
- 序列长度: 50
训练集大小: 5264
测试集大小: 1316
模型参数数量: 245,800
开始训练...
--------------------------------------------------
Epoch [1/20], Batch [100/165], Loss: 0.3160
Epoch [1/20] 完成, 平均损失: 0.8635
--------------------------------------------------
Epoch [2/20], Batch [100/165], Loss: 0.1180
Epoch [2/20] 完成, 平均损失: 0.1420
--------------------------------------------------
Epoch [3/20], Batch [100/165], Loss: 0.1275
Epoch [3/20] 完成, 平均损失: 0.1182
--------------------------------------------------
Epoch [4/20], Batch [100/165], Loss: 0.1040
Epoch [4/20] 完成, 平均损失: 0.1108
--------------------------------------------------
Epoch [5/20], Batch [100/165], Loss: 0.1064
Epoch [5/20] 完成, 平均损失: 0.1076
生成样本: The sling end armo die, to sleep, perchanr And by op
--------------------------------------------------
Epoch [6/20], Batch [100/165], Loss: 0.0999
Epoch [6/20] 完成, 平均损失: 0.1042
--------------------------------------------------
Epoch [7/20], Batch [100/165], Loss: 0.0945
Epoch [7/20] 完成, 平均损失: 0.1031
--------------------------------------------------
Epoch [8/20], Batch [100/165], Loss: 0.1130
Epoch [8/20] 完成, 平均损失: 0.1002
--------------------------------------------------
Epoch [9/20], Batch [100/165], Loss: 0.0985
Epoch [9/20] 完成, 平均损失: 0.0993
--------------------------------------------------
Epoch [10/20], Batch [100/165], Loss: 0.1018
Epoch [10/20] 完成, 平均损失: 0.0984
生成样本: The sting end arrows of so gave dity of outrageous for
--------------------------------------------------
Epoch [11/20], Batch [100/165], Loss: 0.0916
Epoch [11/20] 完成, 平均损失: 0.0967
--------------------------------------------------
Epoch [12/20], Batch [100/165], Loss: 0.1009
Epoch [12/20] 完成, 平均损失: 0.0968
--------------------------------------------------
Epoch [13/20], Batch [100/165], Loss: 0.0969
Epoch [13/20] 完成, 平均损失: 0.0962
--------------------------------------------------
Epoch [14/20], Batch [100/165], Loss: 0.0925
Epoch [14/20] 完成, 平均损失: 0.0951
--------------------------------------------------
Epoch [15/20], Batch [100/165], Loss: 0.0979
Epoch [15/20] 完成, 平均损失: 0.0937
生成样本: The heamind tral shor not to be oparows of outrageous
--------------------------------------------------
Epoch [16/20], Batch [100/165], Loss: 0.1060
Epoch [16/20] 完成, 平均损失: 0.0935
--------------------------------------------------
Epoch [17/20], Batch [100/165], Loss: 0.1054
Epoch [17/20] 完成, 平均损失: 0.0936
--------------------------------------------------
Epoch [18/20], Batch [100/165], Loss: 0.0884
Epoch [18/20] 完成, 平均损失: 0.0926
--------------------------------------------------
Epoch [19/20], Batch [100/165], Loss: 0.0933
Epoch [19/20] 完成, 平均损失: 0.0926
--------------------------------------------------
Epoch [20/20], Batch [100/165], Loss: 0.0964
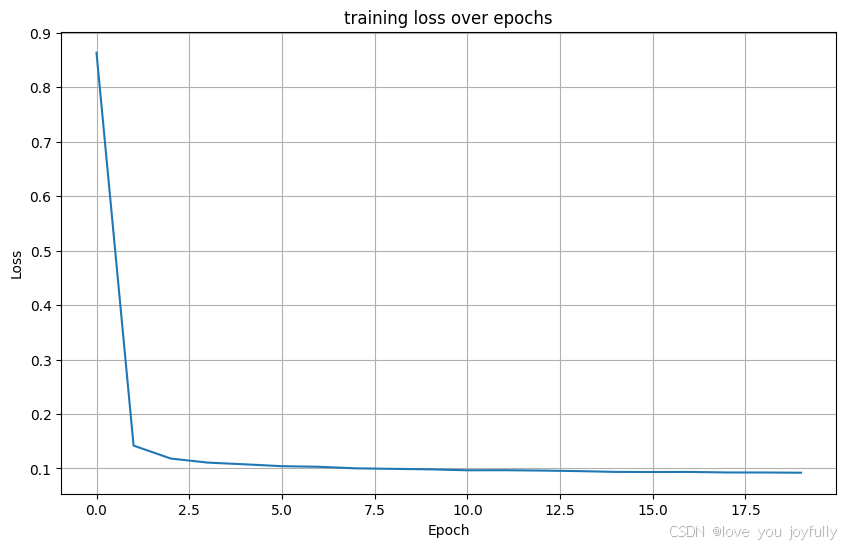
Epoch [20/20] 完成, 平均损失: 0.0922
生成样本: The sle---to sleep, perchance the rub:
Must give us
--------------------------------------------------
开始测试...
测试结果:
- 平均损失: 0.0797
- 困惑度 (Perplexity): 1.08
生成的测试样本:
'The ' -> The shuffled ortune,
To be or nobler ion
The rub:
No more; and arrows
'To be ' -> To be or not to be wr have shuffled off this mortal coil,
Most a sea of tris the r
'in the ' -> in the mind to suffer
The heart-ache and the thousand natural shocks
The heart-
模型已保存为 'rnn_text_generator.pth'3. LSTM、GRU模型
循环神经网络(RNN)在时间序列或序列数据中,通过隐藏状态 hth_tht 把前一时刻的信息传递到当前时刻。然而,普通 RNN 容易出现梯度消失/爆炸,导致难以处理长距离依赖。
LSTM 和 GRU 使用门控机制(gating mechanism) 来控制信息流动,从而缓解这一问题。
3.1 LSTM
LSTM 的核心是单元状态 ctc_tct 和 隐藏状态 hth_tht,通过三个门(遗忘、输入、输出)和候选单元状态组合完成状态更新。
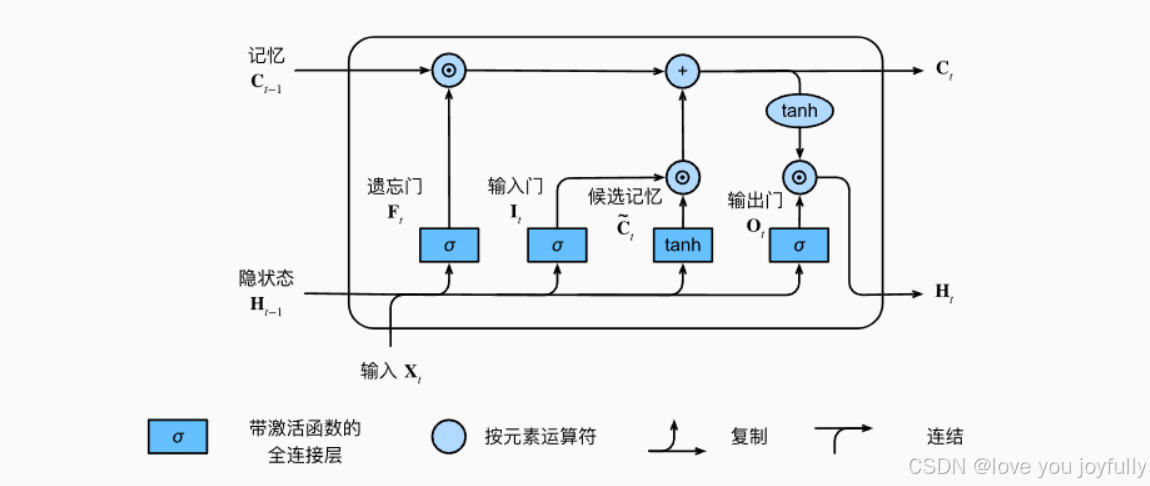
图像来自动手学深度强化学习,地址:https://zh-v2.d2l.ai/
假设当前输入 xt∈Rd\mathbf{x}t \in \mathbb{R}^dxt∈Rd,前一时刻隐藏状态 ht−1∈Rh\mathbf{h}{t-1} \in \mathbb{R}^hht−1∈Rh,单元状态 ct−1∈Rh\mathbf{c}_{t-1} \in \mathbb{R}^hct−1∈Rh。
遗忘门(forget gate)
ft=σ(Wfxt+Ufht−1+bf) \mathbf{f}_t = \sigma\left( \mathbf{W}_f \mathbf{x}_t + \mathbf{U}f \mathbf{h}{t-1} + \mathbf{b}_f \right) ft=σ(Wfxt+Ufht−1+bf)
σ(⋅)\sigma(\cdot)σ(⋅) 是 Sigmoid 函数,输出范围在 0,10,10,1。
输入门(input gate)
it=σ(Wixt+Uiht−1+bi) \mathbf{i}_t = \sigma\left( \mathbf{W}_i \mathbf{x}_t + \mathbf{U}i \mathbf{h}{t-1} + \mathbf{b}_i \right) it=σ(Wixt+Uiht−1+bi)
候选单元状态(cell candidate)
c~t=tanh(Wcxt+Ucht−1+bc) \tilde{\mathbf{c}}_t = \tanh\left( \mathbf{W}_c \mathbf{x}_t + \mathbf{U}c \mathbf{h}{t-1} + \mathbf{b}_c \right) c~t=tanh(Wcxt+Ucht−1+bc)
更新单元状态
ct=ft⊙ct−1+it⊙c~t \mathbf{c}_t = \mathbf{f}t \odot \mathbf{c}{t-1} + \mathbf{i}_t \odot \tilde{\mathbf{c}}_t ct=ft⊙ct−1+it⊙c~t
这里 ⊙\odot⊙ 表示逐元素乘法(Hadamard product)。
输出门(output gate)
ot=σ(Woxt+Uoht−1+bo) \mathbf{o}_t = \sigma\left( \mathbf{W}_o \mathbf{x}_t + \mathbf{U}o \mathbf{h}{t-1} + \mathbf{b}_o \right) ot=σ(Woxt+Uoht−1+bo)
隐藏状态更新
ht=ot⊙tanh(ct) \mathbf{h}_t = \mathbf{o}_t \odot \tanh(\mathbf{c}_t) ht=ot⊙tanh(ct)
LSTM 输入输出关系
- 输入 :xt,ht−1,ct−1\mathbf{x}t, \mathbf{h}{t-1}, \mathbf{c}_{t-1}xt,ht−1,ct−1
- 输出 :ht,ct\mathbf{h}_t, \mathbf{c}_tht,ct
LSTM 的优点是 ctc_tct 作为长期记忆通路,可以让信息跨较长时间传播。
3.2 GRU
GRU 没有显式的长时记忆单元 ct\mathbf{c}_tct,它将 LSTM 的遗忘门和输入门合并为一个更新门 ,并用重置门 控制候选状态的生成。GRU 参数更少,计算更快。
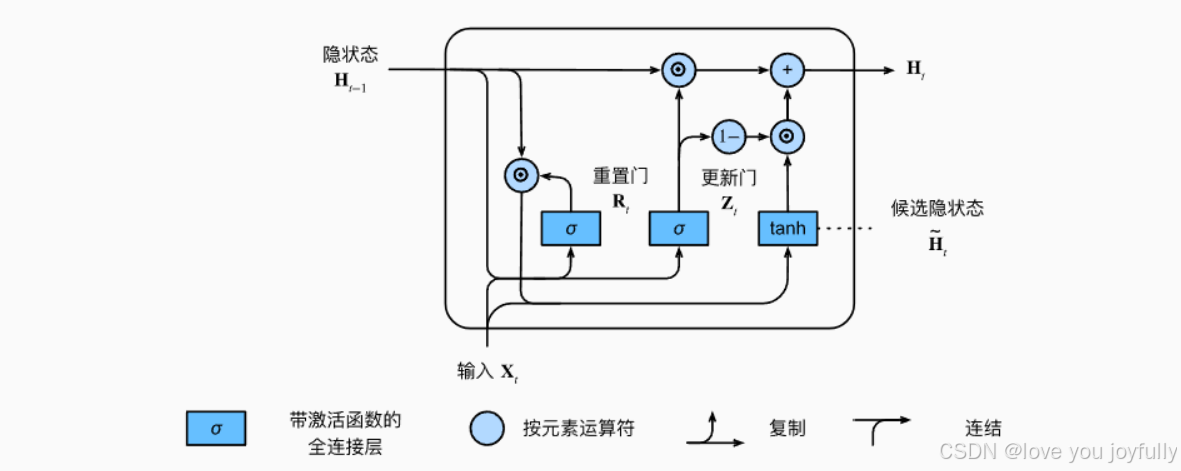
图像来自动手学深度强化学习,地址:https://zh-v2.d2l.ai/
假设:
- 当前输入:xt∈Rd\mathbf{x}_t \in \mathbb{R}^dxt∈Rd
- 前一隐藏状态:ht−1∈Rh\mathbf{h}_{t-1} \in \mathbb{R}^hht−1∈Rh
更新门(update gate)
zt=σ(Wzxt+Uzht−1+bz) \mathbf{z}_t = \sigma\left( \mathbf{W}_z \mathbf{x}_t + \mathbf{U}z \mathbf{h}{t-1} + \mathbf{b}_z \right) zt=σ(Wzxt+Uzht−1+bz)
控制保留多少上一时刻的信息。
重置门(reset gate)
rt=σ(Wrxt+Urht−1+br) \mathbf{r}_t = \sigma\left( \mathbf{W}_r \mathbf{x}_t + \mathbf{U}r \mathbf{h}{t-1} + \mathbf{b}_r \right) rt=σ(Wrxt+Urht−1+br)
控制在生成候选状态时,对过去信息的遗忘程度。
候选隐藏状态(candidate hidden state)
h~t=tanh(Whxt+Uh(rt⊙ht−1)+bh) \tilde{\mathbf{h}}_t = \tanh\left( \mathbf{W}_h \mathbf{x}_t + \mathbf{U}_h \left( \mathbf{r}t \odot \mathbf{h}{t-1} \right) + \mathbf{b}_h \right) h~t=tanh(Whxt+Uh(rt⊙ht−1)+bh)
隐藏状态更新
ht=(1−zt)⊙h~t+zt⊙ht−1 \mathbf{h}_t = (1 - \mathbf{z}_t) \odot \tilde{\mathbf{h}}_t + \mathbf{z}t \odot \mathbf{h}{t-1} ht=(1−zt)⊙h~t+zt⊙ht−1
- 输入 :xt,ht−1\mathbf{x}t, \mathbf{h}{t-1}xt,ht−1
- 输出 :ht\mathbf{h}_tht
GRU 结构更紧凑,更新门 zt\mathbf{z}_tzt 在功能上相当于 LSTM 的遗忘门 + 输入门的组合。
| 特性 | LSTM | GRU |
|---|---|---|
| 记忆单元 | ctc_tct | 无显式 ctc_tct |
| 门结构 | 遗忘门、输入门、输出门 | 更新门、重置门 |
| 参数量 | 较多 | 较少 |
| 表达能力 | 更强,适合复杂长依赖 | 更轻量,训练更快 |
| 隐藏状态更新 | 依赖 ctc_tct 与 hth_tht | 直接更新 hth_tht |
4.GRU网络机器翻译实战
Seq2Seq模型:
模型像一个"翻译官"。当它接收到一句中文(输入序列)时,它不会逐字翻译,而是先完整地阅读、理解整句话的含义,在脑海中形成一个"摘要"或"概念"(编码状态),然后基于这个"概念",再说出一句完整的英文(输出序列)。
这个过程被拆分成了两个部分:
- 编码器(Encoder) :负责"阅读和理解"。它将输入的变长序列(如一句话)处理后,压缩成一个固定长度的、包含了整个输入序列信息的数学表示------上下文向量(Context Vector)。这个向量可以被看作是模型对输入序列的"理解"或"摘要"。
- 解码器(Decoder):负责"表达和生成"。它接收编码器生成的上下文向量,然后一个词一个词地生成输出序列。
这种"先编码,后解码"的结构,就是编码器-解码器(Encoder-Decoder)架构。
图像来自动手学深度强化学习,地址:https://zh-v2.d2l.ai/
应用场景:
除了机器翻译,Seq2Seq模型还广泛应用于:
- 文本摘要:输入长篇文章,输出简短摘要。
- 对话系统(聊天机器人):输入一个问题或一句话,输出一句回答。
- 语音识别:输入一段音频的声学特征序列,输出对应的文字序列。
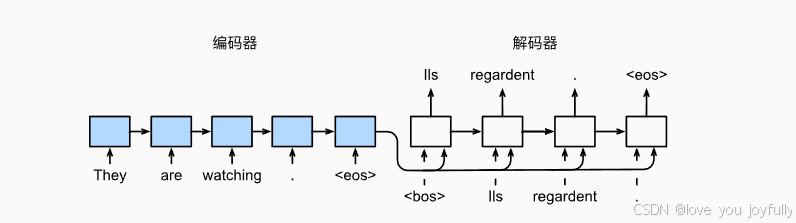
以循环神经网络(RNN)为例说明模型输入输出流程
现在,我们以最经典的RNN来实现一个Seq2Seq模型,来完成一个简单的机器翻译任务:将中文 "我 爱 你 " 翻译成英文 "I love you"。
第一步:准备工作
在输入神经网络之前,需要将文本信息转化为计算机可处理的数字形式。通常,这一步通过**词嵌入(Word Embedding)**实现,即每个字或词都对应唯一的向量。具体表示如下:
- "我" →\rightarrow→ v我\boldsymbol{v}_{\text{我}}v我
- "爱" →\rightarrow→ v爱\boldsymbol{v}_{\text{爱}}v爱
- "你" →\rightarrow→ v你\boldsymbol{v}_{\text{你}}v你
- 英文单词同理,例如 "I" →\rightarrow→ vI\boldsymbol{v}{\text{I}}vI,"love" →\rightarrow→ vlove\boldsymbol{v}{\text{love}}vlove,"you" →\rightarrow→ vyou\boldsymbol{v}_{\text{you}}vyou
第二步:编码器(Encoder)阶段
编码器的任务是接收输入序列 "我 爱 你",并将其转换为一个能够代表整体语义的上下文向量 C\boldsymbol{C}C。
具体流程如下:
-
时间步 t=1t=1t=1:
- 输入:第一个词的向量 v我\boldsymbol{v}_{\text{我}}v我,以及初始隐藏状态 h0\boldsymbol{h}_0h0(通常为零向量)。
- 处理:RNN单元接收 v我\boldsymbol{v}_{\text{我}}v我 和 h0\boldsymbol{h}_0h0,计算得到新的隐藏状态 h1\boldsymbol{h}_1h1,其既包含了"我"的信息,也作为下一步的记忆。
-
时间步 t=2t=2t=2:
- 输入:第二个词的向量 v爱\boldsymbol{v}_{\text{爱}}v爱 和前一步的隐藏状态 h1\boldsymbol{h}_1h1。
- 处理:RNN单元接收 v爱\boldsymbol{v}_{\text{爱}}v爱 和 h1\boldsymbol{h}_1h1,输出新的隐藏状态 h2\boldsymbol{h}_2h2,此时已融合了"我"和"爱"的语义。
-
时间步 t=3t=3t=3:
- 输入:第三个词的向量 v你\boldsymbol{v}_{\text{你}}v你 和前一步的隐藏状态 h2\boldsymbol{h}_2h2。
- 处理:RNN单元接收 v你\boldsymbol{v}_{\text{你}}v你 和 h2\boldsymbol{h}_2h2,计算得到最终隐藏状态 h3\boldsymbol{h}_3h3。
编码结束:
至此,所有输入词均已处理。最后一个隐藏状态 h3\boldsymbol{h}_3h3 蕴含了整个输入序列"我 爱 你"的语义信息。我们将其作为上下文向量:
C=h3 \boldsymbol{C} = \boldsymbol{h}_3 C=h3
编码器的输出即为该固定长度向量 C\boldsymbol{C}C。
第三步:解码器(Decoder)阶段
解码器的目标是接收上下文向量 C\boldsymbol{C}C,并逐步生成目标序列 "I love you"。该过程为自回归(auto-regressive),即每一步的输出依赖于前一步的结果。
具体流程如下:
-
时间步 t=1t=1t=1:
- 输入:
- 特殊起始符(Start-of-Sequence, ⟨SOS⟩\langle \text{SOS} \rangle⟨SOS⟩)的向量 v⟨SOS⟩\boldsymbol{v}_{\langle \text{SOS} \rangle}v⟨SOS⟩;
- 初始隐藏状态为编码器传递的上下文向量 C\boldsymbol{C}C。
- 处理:解码器RNN单元接收 v⟨SOS⟩\boldsymbol{v}_{\langle \text{SOS} \rangle}v⟨SOS⟩ 和 C\boldsymbol{C}C,计算后输出向量,经全连接层(如Softmax)预测概率最高的第一个目标词(假设为 "I"),同时更新隐藏状态为 s1\boldsymbol{s}_1s1。
- 输入:
-
时间步 t=2t=2t=2:
- 输入:上一步输出词 "I"的向量 vI\boldsymbol{v}_{\text{I}}vI 和隐藏状态 s1\boldsymbol{s}_1s1。
- 处理:RNN单元接收 vI\boldsymbol{v}_{\text{I}}vI 和 s1\boldsymbol{s}_1s1,计算并预测下一个词(假设为 "love"),隐藏状态更新为 s2\boldsymbol{s}_2s2。
-
时间步 t=3t=3t=3:
- 输入:上一步输出词 "love"的向量 vlove\boldsymbol{v}_{\text{love}}vlove 和隐藏状态 s2\boldsymbol{s}_2s2。
- 处理:RNN单元接收 vlove\boldsymbol{v}_{\text{love}}vlove 和 s2\boldsymbol{s}_2s2,计算并预测下一个词(假设为 "you"),隐藏状态更新为 s3\boldsymbol{s}_3s3。
-
结束生成:
- 下一步,模型可能预测出特殊结束符(End-of-Sequence, ⟨EOS⟩\langle \text{EOS} \rangle⟨EOS⟩)。当生成 ⟨EOS⟩\langle \text{EOS} \rangle⟨EOS⟩ 时,解码过程终止。
解码完成:
解码器依次输出 "I"、 "love"、 "you",最终合成完整的目标序列。
补充
- 信息瓶颈问题 :在基础的Seq2Seq模型中,编码器必须把源序列的所有信息都压缩进一个固定长度的上下文向量
C中。如果输入序列很长,这个向量很难记住所有细节,导致信息丢失,这就是所谓的"信息瓶颈"。 - 注意力机制(Attention Mechanism) :为了解决信息瓶颈问题,后来引入了注意力机制 。它允许解码器在生成每个词的时候,不仅依赖于那个固定的上下文向量
C,还可以"回头看"输入序列的每一个部分,并对当前生成任务最重要的部分给予更多的"关注"。这极大地提升了Seq2Seq模型(尤其是长序列任务)的性能。
接下来,我们将通过一个简单的例子,来展示如何使用PyTorch实现一个基本的Seq2Seq模型,并进行训练和测试。
首先,我们设计一个词汇表类,用于将文本转换为数字表示,以及将数字表示转换回文本。设计两个文本预处理函数,分别用于处理英文和中文文本。
python
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import numpy as np
import random
import jieba
import re
from collections import defaultdict
import matplotlib.pyplot as plt
# 设置随机种子保证结果可重现
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
set_seed(42)
# 词汇表类
class Vocabulary:
def __init__(self, name):
self.name = name
self.word2index = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "<UNK>": 3}
self.index2word = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
self.word2count = {}
self.n_words = 4
def add_sentence(self, sentence):
for word in sentence:
self.add_word(word)
def add_word(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.index2word[self.n_words] = word
self.word2count[word] = 1
self.n_words += 1
else:
self.word2count[word] += 1
# 文本预处理函数
def normalize_english(s):
"""英文预处理"""
s = s.lower().strip()
# 保留字母、数字和基本标点
s = re.sub(r"[^a-zA-Z0-9.!?]+", " ", s)
s = re.sub(r"\.+", ".", s)
s = re.sub(r"\!+", "!", s)
s = re.sub(r"\?+", "?", s)
return s.split()
def normalize_chinese(s):
"""中文预处理"""
s = s.strip()
# 移除英文字符和数字,保留中文和基本标点
s = re.sub(r"[a-zA-Z0-9]+", "", s)
# 使用jieba分词
words = jieba.cut(s)
return [word for word in words if word.strip()]接下来,我们设计一个数据集类和collate函数,其中,数据集类用于加载和处理数据,collate函数用于将一批数据整理成模型可以接受的格式。
python
# 数据集类
class TranslationDataset(Dataset):
def __init__(self, pairs, input_vocab, output_vocab, max_length=20):
self.pairs = pairs
self.input_vocab = input_vocab
self.output_vocab = output_vocab
self.max_length = max_length
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
pair = self.pairs[idx]
input_sentence = pair[0]
output_sentence = pair[1]
# 转换为索引序列
input_indices = self.sentence_to_indices(input_sentence, self.input_vocab, add_eos=True)
output_indices = self.sentence_to_indices(output_sentence, self.output_vocab, add_sos=True, add_eos=True)
return input_indices, output_indices
def sentence_to_indices(self, sentence, vocab, add_sos=False, add_eos=False):
indices = []
if add_sos:
indices.append(vocab.word2index["<SOS>"])
for word in sentence[:self.max_length-2]: # 为SOS和EOS留出空间
indices.append(vocab.word2index.get(word, vocab.word2index["<UNK>"]))
if add_eos:
indices.append(vocab.word2index["<EOS>"])
return indices
# 自定义collate函数
def collate_fn(batch):
input_seqs, target_seqs = zip(*batch)
# 找出最大长度
max_input_len = max(len(seq) for seq in input_seqs)
max_target_len = max(len(seq) for seq in target_seqs)
# 填充序列
padded_input = []
padded_target = []
for seq in input_seqs:
padded = seq + [0] * (max_input_len - len(seq)) # 用0填充(PAD token)
padded_input.append(padded)
for seq in target_seqs:
padded = seq + [0] * (max_target_len - len(seq)) # 用0填充(PAD token)
padded_target.append(padded)
return torch.tensor(padded_input, dtype=torch.long), torch.tensor(padded_target, dtype=torch.long)接着,我们定义了编码器,解码器和Seq2Seq模型。其中,编码器负责将输入序列编码为上下文向量,解码器负责根据上下文向量生成目标序列,Seq2Seq模型将编码器和解码器组合在一起,形成完整的序列到序列模型。
python
# 编码器
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1, dropout=0.1):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 嵌入层
self.embedding = nn.Embedding(input_size, hidden_size, padding_idx=0)
# GRU层
self.gru = nn.GRU(hidden_size, hidden_size, num_layers,
batch_first=True, dropout=dropout if num_layers > 1 else 0)
def forward(self, input_seq, hidden=None):
# input_seq: (batch_size, seq_len)
batch_size = input_seq.size(0)
if hidden is None:
hidden = self.init_hidden(batch_size, input_seq.device)
embedded = self.embedding(input_seq) # (batch_size, seq_len, hidden_size)
output, hidden = self.gru(embedded, hidden)
return output, hidden
def init_hidden(self, batch_size, device):
return torch.zeros(self.num_layers, batch_size, self.hidden_size, device=device)
# 解码器
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size, num_layers=1, dropout=0.1):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
# 嵌入层
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=0)
# GRU层
self.gru = nn.GRU(hidden_size, hidden_size, num_layers,
batch_first=True, dropout=dropout if num_layers > 1 else 0)
# 输出层
self.out = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input_step, hidden):
# input_step: (batch_size, 1)
# hidden: (num_layers, batch_size, hidden_size)
embedded = self.embedding(input_step) # (batch_size, 1, hidden_size)
embedded = self.dropout(embedded)
output, hidden = self.gru(embedded, hidden)
output = self.out(output) # (batch_size, 1, output_size)
return output, hidden
# 编码器-解码器模型
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2SeqModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, input_tensor, target_tensor, teacher_forcing_ratio=0.5):
batch_size = input_tensor.size(0)
target_length = target_tensor.size(1)
vocab_size = self.decoder.output_size
# 存储解码器输出
decoder_outputs = torch.zeros(batch_size, target_length, vocab_size, device=self.device)
# 编码器前向传播
encoder_outputs, encoder_hidden = self.encoder(input_tensor)
# 解码器初始化
decoder_hidden = encoder_hidden
decoder_input = target_tensor[:, 0].unsqueeze(1) # SOS token: (batch_size, 1)
# 解码器前向传播
for t in range(1, target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
decoder_outputs[:, t] = decoder_output.squeeze(1)
# Teacher forcing
use_teacher_forcing = random.random() < teacher_forcing_ratio
if use_teacher_forcing:
decoder_input = target_tensor[:, t].unsqueeze(1)
else:
decoder_input = decoder_output.argmax(dim=2)
return decoder_outputs最后,我们设计了一个训练测试的过程。整个过程首先准备了一批中英文对照的语句数据,并通过重复扩展来增加训练样本的数量。接着为英文和中文分别构建词汇表,将词语映射为数字索引,以便模型处理。
随后,数据被组织成批次形式,送入一个由编码器和解码器组成的神经网络模型进行训练。在训练过程中,模型读取英文句子,由编码器将其压缩为中间语义表示,再由解码器逐步生成对应的中文翻译。每次训练都会计算翻译结果与真实翻译之间的误差,并据此调整模型参数,同时使用梯度裁剪防止训练不稳定。每完成若干轮训练,模型就会尝试翻译几个新句子,以直观展示学习效果。
训练完成后,模型会被保存下来,以便后续使用。之后程序加载该模型,对一组新的英文句子进行翻译测试,输出对应的中文结果,验证其翻译能力。整个流程涵盖数据处理、模型训练、效果评估和结果可视化的完整链条,最终实现了一个能够将英文短句翻译成中文的简单机器翻译系统。
python
# 训练函数
def train(model, dataloader, optimizer, criterion, device, clip=1.0):
model.train()
total_loss = 0
for batch_idx, (input_tensor, target_tensor) in enumerate(dataloader):
input_tensor = input_tensor.to(device)
target_tensor = target_tensor.to(device)
optimizer.zero_grad()
# 前向传播
decoder_outputs = model(input_tensor, target_tensor)
# 计算损失(忽略填充和SOS标记)
# 重新整理输出和目标以计算损失
output = decoder_outputs[:, 1:].contiguous().view(-1, decoder_outputs.size(-1))
target = target_tensor[:, 1:].contiguous().view(-1)
loss = criterion(output, target)
# 反向传播
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
total_loss += loss.item()
if batch_idx % 50 == 0:
print(f'Batch {batch_idx}, Loss: {loss.item():.4f}')
return total_loss / len(dataloader)
# 评估函数
def evaluate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for input_tensor, target_tensor in dataloader:
input_tensor = input_tensor.to(device)
target_tensor = target_tensor.to(device)
decoder_outputs = model(input_tensor, target_tensor, teacher_forcing_ratio=0)
output = decoder_outputs[:, 1:].contiguous().view(-1, decoder_outputs.size(-1))
target = target_tensor[:, 1:].contiguous().view(-1)
loss = criterion(output, target)
total_loss += loss.item()
return total_loss / len(dataloader)
# 翻译函数
def translate_sentence(model, sentence, input_vocab, output_vocab, device, max_length=20):
model.eval()
with torch.no_grad():
# 预处理输入句子
if isinstance(sentence, str):
# 假设是英文输入
words = normalize_english(sentence)
else:
words = sentence
# 转换为索引
input_indices = []
for word in words:
input_indices.append(input_vocab.word2index.get(word, input_vocab.word2index["<UNK>"]))
input_indices.append(input_vocab.word2index["<EOS>"])
input_tensor = torch.tensor([input_indices], dtype=torch.long).to(device) # (1, seq_len)
# 编码
encoder_outputs, encoder_hidden = model.encoder(input_tensor)
# 解码
decoder_hidden = encoder_hidden
decoder_input = torch.tensor([[output_vocab.word2index["<SOS>"]]], dtype=torch.long).to(device)
decoded_words = []
for _ in range(max_length):
decoder_output, decoder_hidden = model.decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.topk(1)
# 修复:需要保持decoder_input为2D张量 (batch_size, 1)
decoder_input = topi.squeeze(-1).detach() # 从(batch_size, 1, 1)变成(batch_size, 1)
word_idx = topi.item()
if word_idx == output_vocab.word2index["<EOS>"]:
break
elif word_idx != output_vocab.word2index["<PAD>"]:
decoded_words.append(output_vocab.index2word[word_idx])
return decoded_words
# 加载模型函数
def load_model(model_path, device):
"""加载保存的模型"""
checkpoint = torch.load(model_path, map_location=device)
input_vocab = checkpoint['input_vocab']
output_vocab = checkpoint['output_vocab']
hidden_size = checkpoint['hidden_size']
num_layers = checkpoint['num_layers']
dropout = checkpoint.get('dropout', 0.1)
encoder = Encoder(input_vocab.n_words, hidden_size, num_layers, dropout)
decoder = Decoder(hidden_size, output_vocab.n_words, num_layers, dropout)
model = Seq2SeqModel(encoder, decoder, device).to(device)
model.load_state_dict(checkpoint['model_state_dict'])
return model, input_vocab, output_vocab
if __name__ == "__main__":
# 运行主程序
# 设备设置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用设备: {device}')
# 准备示例数据
pairs = [
(["hello"], ["你好"]),
(["good", "morning"], ["早上", "好"]),
(["how", "are", "you"], ["你", "好", "吗"]),
(["thank", "you"], ["谢谢"]),
(["goodbye"], ["再见"]),
(["i", "love", "you"], ["我", "爱", "你"]),
(["what", "is", "your", "name"], ["你", "的", "名字", "是", "什么"]),
(["nice", "to", "meet", "you"], ["很", "高兴", "认识", "你"]),
(["how", "much"], ["多少", "钱"]),
(["where", "are", "you", "from"], ["你", "是", "哪里", "人"]),
(["i", "am", "fine"], ["我", "很", "好"]),
(["see", "you", "tomorrow"], ["明天", "见"]),
(["good", "night"], ["晚安"]),
(["excuse", "me"], ["不好意思"]),
(["sorry"], ["对不起"]),
(["hi"], ["嗨"]),
(["good", "afternoon"], ["下午", "好"]),
(["good", "evening"], ["晚上", "好"]),
(["how", "do", "you", "do"], ["你好"]),
(["pleased", "to", "meet", "you"], ["很高兴", "认识", "你"]),
(["my", "name", "is", "john"], ["我的", "名字", "是", "约翰"]),
(["where", "are", "you", "from"], ["你", "是", "哪里", "人"]),
(["i", "am", "from", "china"], ["我", "是", "中国", "人"]),
(["how", "are", "you", "today"], ["你", "今天", "好", "吗"]),
(["i", "am", "fine", "thank", "you"], ["我", "很好", "谢谢"]),
(["and", "you"], ["你", "呢"]),
(["see", "you", "later"], ["待会", "见"]),
(["see", "you", "soon"], ["稍后", "见"]),
(["good", "luck"], ["祝", "好运"]),
(["have", "a", "good", "day"], ["祝", "你", "有", "个", "好", "日子"]),
(["have", "a", "nice", "weekend"], ["祝", "你", "有", "个", "愉快", "的", "周末"]),
(["welcome"], ["欢迎"]),
(["you", "are", "welcome"], ["不", "客气"]),
(["good", "morning", "sir"], ["早上", "好", "先生"]),
(["good", "morning", "madam"], ["早上", "好", "女士"]),
(["how", "is", "everything"], ["一切", "都", "好吗"]),
(["long", "time", "no", "see"], ["好久", "不见"]),
(["it", "is", "nice", "to", "see", "you", "again"], ["很", "高兴", "再次", "见到", "你"]),
(["how", "is", "your", "family"], ["你", "家人", "好", "吗"]),
(["i", "am", "glad", "to", "meet", "you"], ["很", "高兴", "认识", "你"]),
(["let", "me", "introduce", "myself"], ["让我", "自我", "介绍", "一下"]),
(["what", "is", "your", "nationality"], ["你", "是", "哪", "国", "人"]),
(["i", "am", "american"], ["我", "是", "美国", "人"]),
(["where", "is", "the", "bank"], ["银行", "在", "哪里"]),
(["where", "is", "the", "hospital"], ["医院", "在", "哪里"]),
(["where", "is", "the", "post", "office"], ["邮局", "在", "哪里"]),
(["where", "is", "the", "police", "station"], ["警察", "局", "在", "哪里"]),
(["where", "is", "the", "train", "station"], ["火车", "站", "在", "哪里"]),
(["where", "is", "the", "bus", "stop"], ["公交", "车站", "在", "哪里"]),
(["where", "is", "the", "subway", "station"], ["地铁", "站", "在", "哪里"]),
(["where", "is", "the", "restaurant"], ["餐厅", "在", "哪里"]),
(["where", "is", "the", "hotel"], ["酒店", "在", "哪里"]),
(["where", "is", "the", "museum"], ["博物", "馆", "在", "哪里"]),
(["how", "do", "i", "get", "to", "the", "station"], ["怎么", "去", "车站"]),
(["which", "way", "to", "the", "airport"], ["哪", "条", "路", "去", "机场"]),
(["is", "there", "a", "map", "nearby"], ["附近", "有", "地图", "吗"]),
(["can", "you", "show", "me", "on", "the", "map"], ["你", "能", "在", "地图", "上", "指", "给我", "看", "吗"]),
(["go", "straight", "ahead"], ["直", "走"]),
(["turn", "left"], ["左", "转"]),
(["turn", "right"], ["右", "转"]),
(["it", "is", "on", "your", "left"], ["在", "你", "的", "左", "边"]),
(["it", "is", "on", "your", "right"], ["在", "你", "的", "右", "边"]),
(["it", "is", "just", "around", "the", "corner"], ["就", "在", "拐", "角", "处"]),
(["it", "is", "about", "two", "blocks", "away"], ["大约", "两", "个", "街区", "远"]),
(["cross", "the", "street"], ["穿", "过", "马路"]),
(["go", "past", "the", "park"], ["经", "过", "公园"]),
(["take", "the", "second", "left"], ["第", "二", "个", "左", "转"]),
(["take", "the", "first", "right"], ["第", "一", "个", "右", "转"]),
(["how", "far", "is", "it"], ["有", "多", "远"]),
(["is", "it", "walkable"], ["可以", "走", "过去", "吗"]),
(["can", "i", "take", "a", "taxi"], ["我", "可以", "打", "车", "吗"]),
(["how", "long", "does", "it", "take", "to", "get", "there"], ["到", "那里", "需要", "多", "长", "时间"]),
(["is", "there", "a", "shortcut"], ["有", "近", "路", "吗"]),
(["how", "much", "is", "this"], ["这", "个", "多少", "钱"]),
(["what", "is", "the", "price"], ["价格", "是", "多少"]),
(["can", "i", "try", "it", "on"], ["我", "可以", "试", "一下", "吗"]),
(["do", "you", "have", "this", "in", "a", "larger", "size"], ["有", "没有", "大", "一点", "的", "尺", "码"]),
(["do", "you", "have", "this", "in", "a", "smaller", "size"], ["有", "没有", "小", "一点", "的", "尺", "码"]),
(["what", "colors", "do", "you", "have"], ["有", "什么", "颜色"]),
(["can", "i", "see", "another", "one"], ["我", "可以", "看看", "其他", "的", "吗"]),
(["is", "it", "on", "sale"], ["这", "个", "打折", "吗"]),
(["can", "you", "give", "me", "a", "discount"], ["可以", "给", "我", "打折", "吗"]),
(["do", "you", "accept", "credit", "cards"], ["接受", "信用", "卡", "吗"]),
(["do", "you", "take", "alipay", "or", "wechat"], ["接受", "支付", "宝", "或", "微信", "吗"]),
(["where", "is", "the", "changing", "room"], ["试", "衣", "间", "在", "哪里"]),
(["i", "will", "take", "it"], ["我", "要", "了"]),
(["can", "i", "return", "this"], ["可以", "退货", "吗"]),
(["do", "you", "have", "a", "warranty"], ["有", "保修", "吗"]),
(["how", "long", "is", "the", "return", "policy"], ["退货", "政策", "有", "多", "长", "时间"]),
(["is", "this", "new"], ["这", "是", "新", "的", "吗"]),
(["is", "this", "genuine"], ["这", "是", "正品", "吗"]),
(["do", "you", "have", "this", "in", "stock"], ["这", "个", "有", "货", "吗"]),
(["when", "will", "it", "be", "back", "in", "stock"], ["什么", "时候", "会", "补", "货"]),
(["can", "i", "reserve", "this"], ["我", "可以", "预订", "吗"]),
(["do", "you", "ship", "overseas"], ["可以", "国际", "邮寄", "吗"]),
(["how", "much", "is", "the", "shipping"], ["运费", "多少", "钱"]),
(["what", "is", "your", "return", "policy"], ["你", "们", "的", "退货", "政策", "是", "什么"]),
(["can", "i", "pay", "later"], ["可以", "后", "付款", "吗"]),
(["do", "you", "have", "a", "receipt"], ["有", "收", "据", "吗"]),
(["can", "i", "get", "a", "bag"], ["可以", "给", "我", "个", "袋", "子", "吗"]),
(["is", "tax", "included"], ["价格", "包含", "税", "吗"]),
(["the", "price", "tag", "is", "wrong"], ["价", "签", "价格", "不", "对"]),
(["i", "found", "a", "better", "price", "online"], ["我", "在", "网", "上", "找", "到", "了", "更", "便", "宜", "的"]),
(["can", "i", "see", "the", "menu"], ["可以", "看", "菜单", "吗"]),
(["what", "do", "you", "recommend"], ["你", "们", "有", "什么", "推荐"]),
(["i", "would", "like", "to", "order"], ["我", "想", "点", "餐"]),
(["can", "i", "have", "a", "table", "for", "two"], ["可以", "订", "一", "个", "两", "人", "桌", "吗"]),
(["is", "this", "table", "free"], ["这", "个", "桌", "子", "空", "着", "吗"]),
(["can", "i", "have", "some", "water"], ["可以", "给", "我", "一", "些", "水", "吗"]),
(["what", "is", "today", "special"], ["今", "天", "的", "特", "色", "菜", "是", "什么"]),
(["i", "am", "vegetarian"], ["我", "是", "素食", "者"]),
(["does", "this", "have", "meat"], ["这", "道", "菜", "有", "肉", "吗"]),
(["is", "this", "spicy"], ["这", "道", "菜", "辣", "吗"]),
(["can", "i", "get", "it", "less", "spicy"], ["可以", "做", "得", "不", "那", "么", "辣", "吗"]),
(["i", "would", "like", "the", "bill"], ["请", "给", "我", "账", "单"]),
(["can", "we", "split", "the", "bill"], ["可以", "分", "开", "付", "账", "吗"]),
(["do", "you", "accept", "credit", "cards"], ["接受", "信用", "卡", "吗"]),
(["what", "time", "do", "you", "close"], ["你", "们", "什么", "时间", "打", "烊"]),
(["can", "i", "make", "a", "reservation"], ["可以", "预订", "位", "子", "吗"]),
(["for", "when", "and", "what", "time"], ["预", "订", "什么", "时间", "的"])
]
# 扩展数据集用于训练
training_pairs = pairs * 10 # 重复数据以增加训练样本
# 创建词汇表
input_vocab = Vocabulary("english")
output_vocab = Vocabulary("chinese")
# 构建词汇表
print("构建词汇表...")
for pair in training_pairs:
input_vocab.add_sentence(pair[0])
output_vocab.add_sentence(pair[1])
print(f"英文词汇量: {input_vocab.n_words}")
print(f"中文词汇量: {output_vocab.n_words}")
# 创建数据集
dataset = TranslationDataset(training_pairs, input_vocab, output_vocab, max_length=15)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True, collate_fn=collate_fn)
# 模型参数
hidden_size = 256
num_layers = 2
dropout = 0.1
# 创建模型
encoder = Encoder(input_vocab.n_words, hidden_size, num_layers, dropout)
decoder = Decoder(hidden_size, output_vocab.n_words, num_layers, dropout)
model = Seq2SeqModel(encoder, decoder, device).to(device)
# 优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充标记
# 训练
print("\n开始训练...")
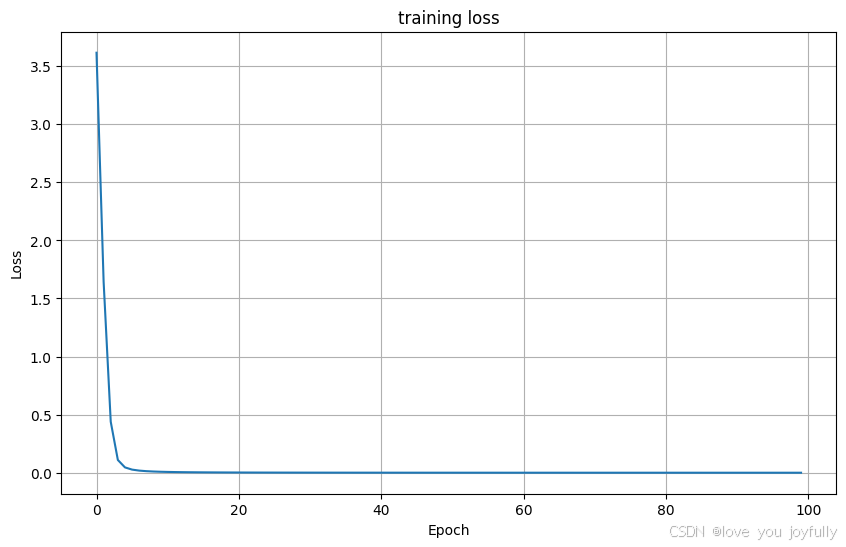
num_epochs = 100
train_losses = []
for epoch in range(num_epochs):
train_loss = train(model, dataloader, optimizer, criterion, device)
train_losses.append(train_loss)
if epoch % 10 == 0:
print(f'Epoch [{epoch}/{num_epochs}], Loss: {train_loss:.4f}')
# 测试翻译效果,随机选择几个句子进行测试
test_sentences = random.sample(pairs, 5)
test_sentences = [pair[0] for pair in test_sentences] # 只测试英文句子
# 将测试句子转换为字符串形式
test_sentences = [' '.join(sentence) for sentence in test_sentences]
print("翻译测试:")
for sentence in test_sentences:
translation = translate_sentence(model, sentence, input_vocab, output_vocab, device)
print(f" {sentence} -> {''.join(translation)}")
print()
# 保存模型
torch.save({
'model_state_dict': model.state_dict(),
'input_vocab': input_vocab,
'output_vocab': output_vocab,
'hidden_size': hidden_size,
'num_layers': num_layers,
'dropout': dropout
}, 'translation_model.pth')
print("模型已保存到 translation_model.pth")
# 最终测试
print("\n=== 最终翻译测试 ===")
test_sentences = [
"hello",
"good morning",
"thank you",
"how are you",
"goodbye",
"i love you",
"what is your name",
"nice to meet you"
]
for sentence in test_sentences:
translation = translate_sentence(model, sentence, input_vocab, output_vocab, device)
print(f"英文: {sentence}")
print(f"中文: {''.join(translation)}")
print("-" * 30)
# 绘制训练损失
plt.figure(figsize=(10, 6))
plt.plot(train_losses)
plt.title('training loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()使用设备: cuda
构建词汇表...
英文词汇量: 180
中文词汇量: 217
开始训练...
Epoch [0/100], Loss: 3.6157
翻译测试:
i am vegetarian -> 我我是
it is on your right -> 你是是
sorry -> 可以个吗
i would like to order -> 我我点
how much -> 这个吗
Epoch [10/100], Loss: 0.0069
翻译测试:
do you have this in a larger size -> 有没有大一点的尺码
you are welcome -> 不客气
is this table free -> 这个桌子空着吗
do you have a warranty -> 有保修吗
where is the bus stop -> 公交车站在哪里
Epoch [20/100], Loss: 0.0019
翻译测试:
can i pay later -> 可以后付款吗
how much is the shipping -> 运费多少钱
good evening -> 晚上好
do you take alipay or wechat -> 接受支付宝或微信吗
the price tag is wrong -> 价签价格不对
Epoch [30/100], Loss: 0.0008
翻译测试:
i am vegetarian -> 我是素食者
i am american -> 我是美国人
where is the post office -> 邮局在哪里
good morning -> 早上好
let me introduce myself -> 让我自我介绍一下
Epoch [40/100], Loss: 0.0005
翻译测试:
i will take it -> 我要了
i am vegetarian -> 我是素食者
it is nice to see you again -> 很高兴再次见到你
go straight ahead -> 直走
pleased to meet you -> 很高兴认识你
Epoch [50/100], Loss: 0.0003
翻译测试:
i am fine thank you -> 我很好谢谢
where is the restaurant -> 餐厅在哪里
you are welcome -> 不客气
is this spicy -> 这道菜辣吗
see you soon -> 稍后见
Epoch [60/100], Loss: 0.0002
翻译测试:
can i have some water -> 可以给我一些水吗
where is the post office -> 邮局在哪里
go straight ahead -> 直走
what is today special -> 今天的特色菜是什么
can i make a reservation -> 可以预订位子吗
Epoch [70/100], Loss: 0.0001
翻译测试:
can you show me on the map -> 你能在地图上指给我看吗
where is the subway station -> 地铁站在哪里
how much is this -> 这个多少钱
what is the price -> 价格是多少
is it on sale -> 这个打折吗
Epoch [80/100], Loss: 0.0001
翻译测试:
is there a shortcut -> 有近路吗
can i see the menu -> 可以看菜单吗
where is the police station -> 警察局在哪里
can i make a reservation -> 可以预订位子吗
let me introduce myself -> 让我自我介绍一下
Epoch [90/100], Loss: 0.0000
翻译测试:
can i get a bag -> 可以给我个袋子吗
i am vegetarian -> 我是素食者
can i pay later -> 可以后付款吗
hello -> 你好
goodbye -> 再见
模型已保存到 translation_model.pth
=== 最终翻译测试 ===
英文: hello
中文: 你好
------------------------------
英文: good morning
中文: 早上好
------------------------------
英文: thank you
中文: 谢谢
------------------------------
英文: how are you
中文: 你好吗
------------------------------
英文: goodbye
中文: 再见
------------------------------
英文: i love you
中文: 我爱你
------------------------------
英文: what is your name
中文: 你的名字是什么
------------------------------
英文: nice to meet you
中文: 很高兴认识你
------------------------------
从上方例子可以看到,基于GRU的Seq2Seq模型已经能够实现基本的机器翻译功能。
循环神经网络(RNN)的发展可追溯至20世纪80年代末,当时研究人员开始探索如何让神经网络处理序列数据。早期的Elman网络和Jordan网络首次引入了"隐藏状态"的概念,使网络能够记住之前的信息。然而,真正让RNN在序列建模领域崭露头角的是1997年Hochreiter和Schmidhuber提出的长短期记忆网络(LSTM),它通过精心设计的门控机制有效缓解了梯度消失问题,使网络能够学习长期依赖关系。随后在2014年,GRU(门控循环单元)作为LSTM的简化版本被提出,在保持类似性能的同时减少了计算复杂度。整个2010年代中期,RNN及其变体成为自然语言处理、语音识别等序列任务的主流方法,推动了机器翻译、文本生成等应用的快速发展。
如今,RNN及其变体仍在多个领域发挥重要作用,包括语音识别系统中的声学建模、金融领域的时间序列预测、医疗健康中的生理信号分析,以及工业场景中的异常检测等。在一些计算资源有限或序列长度较短的应用中,RNN因其结构简单、参数量相对较少而仍具优势。然而,RNN存在几个根本性缺陷:首先,其顺序处理机制导致难以并行计算,训练效率低下;其次,尽管LSTM和GRU改善了长期依赖问题,但随着序列长度增加,它们仍难以有效捕捉远距离依赖关系;再者,RNN的固定维度隐藏状态形成了"信息瓶颈",限制了模型对长文本的表示能力。
正是这些局限性催生了注意力机制的广泛应用。2014年,Bahdanau等人在机器翻译任务中首次将注意力机制与RNN结合,使模型能够"关注"输入序列中与当前输出最相关的部分,显著提升了翻译质量。这一思想在2017年被Google的研究团队发扬光大,他们提出了完全基于注意力机制的Transformer模型,在论文《Attention is All You Need》中摒弃了传统的循环结构,采用自注意力机制实现序列元素间的直接交互。Transformer不仅解决了RNN的并行化难题,还通过多头注意力机制捕获更丰富的上下文关系,迅速成为自然语言处理领域的新范式。此后,BERT、GPT等基于Transformer的大规模预训练模型相继涌现,将人工智能的语言理解与生成能力推向了新的高度,标志着序列建模进入了"注意力时代"。