🔥 本文专栏:c++
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录 :
最大的风险是不敢冒险,最大的错误是不敢犯错
引入
我们知道我们编写的代码中,难免会出现错误,比如我要开辟一个动态数组,那么这里我可以调用malloc函数在堆上申请了一片连续的空间,但是如果我开辟的空间过大,而内存此时没有这么大的空闲的连续内存块,那么会返回一个空指针,而如果我没有对malloc的返回值进行检查,那么默认此时已经成功开辟了在堆上分配的动态数组,那么接着我解引用该指针去访问内存中的内容,那么此时就是空指针解引用,那么就会触发异常从而终止程序
而同理,如果我写了一个计算器程序,那么实现加减乘除4个模块的函数,那么此时用户要进行除法算术运算,那么接下来程序会接收用户的键盘输入,然后获取到被除数与除数的值,然后进行除法运算,那么如果用户输入的除数的值是0,那么由于除数是不能为0,那么一旦除数为0,那么此时就会引发除0的算术异常从而终止程序
而我们编写的程序会有着各种行为,比如访问内存或者进行算术运算,而这些行为底层其实就是对应着用户编写的一行行代码,那么其中程序中有些行为是不合法的,比如上文的访问内存的例子,那么我们访问内存中某块区域的内容,那么一般是通过指针保存的地址去访问内存中的某块空间,但是如果该指针是空指针或者未经初始化的野指针,那么此时解引用该指针来访问内存就是一个不合法的行为,而我们用户可能会事先知道代码中的某个位置可能会有不合法的行为的出现,比如调用malloc函数的那行代码,那么如果malloc函数调用失败,那么一旦返回空指针然后解引用就会触发异常,所以这行代码会有这引发异常的风险,同理我们进行被除数除以除数的这行代码,一旦除数为0,那么也会有引发异常的风险
所以这里我们就得对可能会触发异常的代码位置编写一个异常的检查机制,那么对于c语言来说,那么其有两种方式来检查异常,那么第一种方式就是断言,也就是调用assert函数,其接收一个参数,那么如果assert函数的参数是为true或者说非0,那么就可以继续执行assert函数之后的代码,而assert函数的参数为false或者为0,那么就会立刻终止程序
那么这种方式是一种暴力的检查方式,因为无论引发什么类型的错误,那么此时assert断言的处理方式都是终止程序,而如果在这样的场景下,也就是我们编写的代码是一个需要长期稳定运行的一个服务器或者应用程序,以微信为例
那么我们知道微信这个软件有着各种功能,比如发送信息以及接收信息和视屏聊天等,那么微信的这些功能我们都可以将其做成一个函数模块,那么微信这个软件上的各种行为或者说动作,比如发送信息以及加好友和视频通话,其实就是可以理解为调用某一个特定功能模块的函数,那么微信那么这些动作的触发也就是函数的调用都会被封装到一个while的死循环逻辑中,那么除非用户显示退出这个while循环,那么此时会一直执行while循环中的各个流程
那么如果我们此时在用微信发送一条消息,那么假设我们正处于隧道或者电梯这些信号不好的地方,由于信号不好,我们能够看到我们的发送的消息可能迟迟发布不出去甚至可能发送消息失败,但是以我们生活中的经验,我们知道微信肯定有某个消息发不出去的情况出现,但是微信从来不会因为某个消息发不出去从而导致程序突然闪退或者微信就崩了,那么我们通常是等到信号恢复或者稳定之后,再尝试重新发送该消息,然后消息成功发送到接收方,那么刚才所说的消息发送失败,其实在程序员的视角下,其实就是发送消息对应的函数调用失败或者是调用该函数得到了一个不符合预期的结果,那么该函数的调用失败或者调用函数得到一个错误的结果,由于函数中某个位置的代码出现了错误导致,但是该错误不是一个致命到需要让这个程序停止运行的错误,那么这里我们期望的解决方式就是在尝试重新调用该函数,然后得到一个符合预期的正确的结果即可
所以我们可以看到由于信号问题,我们发送的消息前面会一直转圈,而上文我们就说过,微信程序的各种流程都会封装到一个while的死循环中,那么这里转圈其实就可以理解为:这里调用发送信息模块的函数失败,那么调用失败假设返回的错误码是-1,那么主流程会对该函数模块的返回值进行检查,如果返回值是-1,那么就continue再尝试调用这个函数,直到得到正确的结果之后,再执行后序的代码,而如果我们采取的是assert这种暴力的方式,那么程序中一旦出现这样非致命的错误,比如像这里发送信息的模块的函数调用失败,那么assert断言检查其函数返回值是-1,那么直接将整个程序就终止,那么这肯定是不合理的
并且assert函数只在debug模式下生效,那么在realse模式下是无法生效的,所以c语言的这种assert断言处理就是一刀斩乱麻,那么assert的应该场景一般就是检查一些致命的错误,比如我们编写一个需要长期稳定运行的服务器的代码,以买火车票的软件为例,其中该软件也会定义很多相关功能的函数模块,假设其中的数据库模块出现问题,导致很多买票人的身份信息丢失,这个问题一旦发生,那么程序就肯定不能再尝试正常运行,那么就需要assert来断言来立刻终止程序,然后修复该函数模块
由于上文的assert检查错误的方式过于暴力,那么c语言的第二种处理方式就是一种温柔的方式,那么就是返回错误码,所谓的返回错误码,其实我们利用函数的返回值,那么我们可以在用户层面上规定某些特定函数的返回值代表该函数调用失败或者出现错误,比如返回0代表函数调用成功且结果正确,而返回-1就代表函数调用失败或者结果不符合预期
那么比如上文我们提到的微信调用某个发送信息的函数出现失败,那么这里发生了一个非致命错误,那么我们就可以返回一个错误码,而不是立刻终止程序,那么我们可以根据返回的错误码的具体含义,比如1代表非致命错误,2代表致命错误,来决定是继续运行这个程序还是直接中终止程序,但是错误码的方式看似解决了assert断言的问题,但是该方式还是会存在一个缺陷,那么如果这里我们函数是嵌套的调用,也就是在main函数中调用了fun1函数,并且fun1中调用了fun2函数,而fun2又调用了fun3函数,那么假设fun3函数调用失败,而main函数是整个代码的主逻辑,那么内部肯定定义有检查函数的调用情况的代码逻辑,通过检查函数的返回值,如果函数的返回值是-2,那么说明调用失败,那么main函数在根据这里返回的错误码做相应的决策,那么如果这里fun3调用失败,要让外部的main函数知道,那么由于这里的函数调用链较深,那么它得先返回给fun2,那么意味着这里fun2内部要定义检查fun3的调用情况的代码逻辑,并且其还要将结果返回给fun1,最后再由fun1返回给main函数,那么这里沿着函数调用链从下往上依次返回,其中就会涉及到函数栈帧的销毁,那么会付出性能上的损耗
main() fun1() fun2() fun3() 正常调用链 调用 fun1() 调用 fun2() 调用 fun3() 错误发生点 返回错误码 -2 检查返回值 转发错误码 -2 检查返回值 转发错误码 -2 决策处理 (终止/重试/日志) main() fun1() fun2() fun3()
而这些执行特定功能或者特定任务的函数就相当于工厂中干活的工人,那么这些工人只需要干事即可,那么如果某个流水线上的工人发现了错误,那么我们希望他直接报告给工厂主管,而不是选择先报告给然组长,然后组长再报告给工头,最后工头再报给工厂主管,也就是不希望经过中间人来传达消息,那么工厂主管听到你报告的错误之后,然立马做出相应的反应与处理,而c++的处理异常的方式就正是这样
C++异常处理方式 传统错误处理方式 对比 对比 直接抛出异常 工人发现错误 异常直达主管 主管捕获并处理 报告给组长 工人发现错误 组长报告给工头 工头报告给主管 主管处理错误 工人: 函数执行任务 发现错误/异常 直接抛出异常 异常传播机制 检查调用链中的异常处理 跳过中间层级函数 直达能够处理异常的工厂主管 工厂主管: 顶层异常处理 捕获异常 分析异常类型 执行相应的错误处理 恢复程序正常流程 继续执行后续代码
异常
那么接下来我们来看看c++是如何处理异常的,那么我们先来看c++的处理异常的语法是什么,而由于c++是一门面向对象的语言,那么c语言的处理异常方式是返回一个错误码,而c++出现异常则是抛出一个异常对象,那么该对象的类型可以是内置类型也可以是自定义类型
那么抛出异常对象的语法则是需要用到throw关键字,后面跟上抛出的异常对象,那么以上文的除法的算术运算为例,那么除法的算术运算可专门定义一个dive函数模块来实现,其中需要检查除数的情况,那么一旦除数是0,那么此时的除法运算就是不合法的,那么检测到除数是0之后,我们就可以直接抛出一个异常对象,那么这里我选择抛出的异常对象的类型string,其中记录了引发异常的信息
cpp
int div(int x,int y)
{
if(y==0)
{
string str="Division by zero exception ";
throw str;
}
return x/y;
}那异常对象抛出之后,那么就下来的动作便是异常对象的捕获,那么异常对象的捕获,则需要我们定义try catch语句块,那么try语句块中的内容就是包含抛出异常的代码片段或者抛出异常的函数调用处,而这里异常的捕获则是通过后面的catch语句块,那么catch语句块后面括号的内容,则是异常声明 ,里面定义了一个异常对象标识符,代表当前catch语句块要捕获的异常对象的类型,而catch语句块中的内容则是捕获之后,处理该异常的相应逻辑的代码,那么我们可以定义多个catch语句块,那么catch语句块匹配则是从上往下依次匹配,那么如果抛出的异常对象的类型匹配该catch块,那么就可以执行其catch语句块中的代码,然后执行完当前catch块中的代码之后,就会跳过之后的所有的catch块,再依次顺序执行之后的代码,那么类似于c语言的Switch case语句
cpp
try
{
//抛出异常的代码
}catch(类型 变量名)
{
//相应的异常的处理逻辑
}而这里如果我们不知道抛出异常对象的类型,那么我们可以在catch块后面声明一个省略号或者说通配符:...,那么这里catch块就会捕获任意类型的异常,那么上文说过,这里扫描catch语句块是从上往下依次扫描,那么一旦某个catch语句块捕获成功,那么这里就会跳过之后的catch块,所以这里建议将这个捕获任意类型的catch语句块放到最后
cpp
try{
}catch(type1 execpetion)
{
}catch(type2 execpetion)
{
}catch(...)
{
}要注意的是catch语句块捕获的异常对象类型的机制,那么有的读者会有这样的想法:如果我返回的异常对象的类型如果是char*类型的对象,但是当前catch块要捕获的异常对象的类型是string类型,那么string支持了接收char * 的c风格字符串的构造函数,那么意味着char 类型对象能够隐式类型转化为string类型,那么是否这里可以将抛出的char 异常对象给隐式类型转化为string,然后就可以被该catch块给捕获
又或者抛出的异常对象的类型是int,但int同样可以可以转为double类型,那么如果这里catch块接收的是double类型的异常对象,那么如果允许类型转化的,那么意味着当前catch块是否也够接收int类型的异常对象
那么实际出真知,那么我编写了两个代码来验证刚才的情况,如果成捕获,那么就会执行catch语句块中的内容,也就是打印string中的字符串内容:
cpp
//test1
#include<iostream>
#include<string>
using namespace std;
int Div(int x, int y)
{
if (y == 0)
{
const char* str = "Division by zero exception ";
throw str;
}
return x / y;
}
int main()
{
int x, y,z;
cin >> x >> y;
try
{
z = Div(x, y);
cout << z << endl;
}
catch (string exc)
{
cout << exc << endl;
}
return 0;
}
//test2
#include<iostream>
#include<string>
using namespace std;
int Div(int x, int y)
{
if (y == 0)
{
int k = -1;
throw k;
}
return x / y;
}
int main()
{
int x, y,z;
cin >> x >> y;
try
{
z = Div(x, y);
cout << z << endl;
}
catch (double exc)
{
cout << exc << endl;
}
return 0;
}test1:
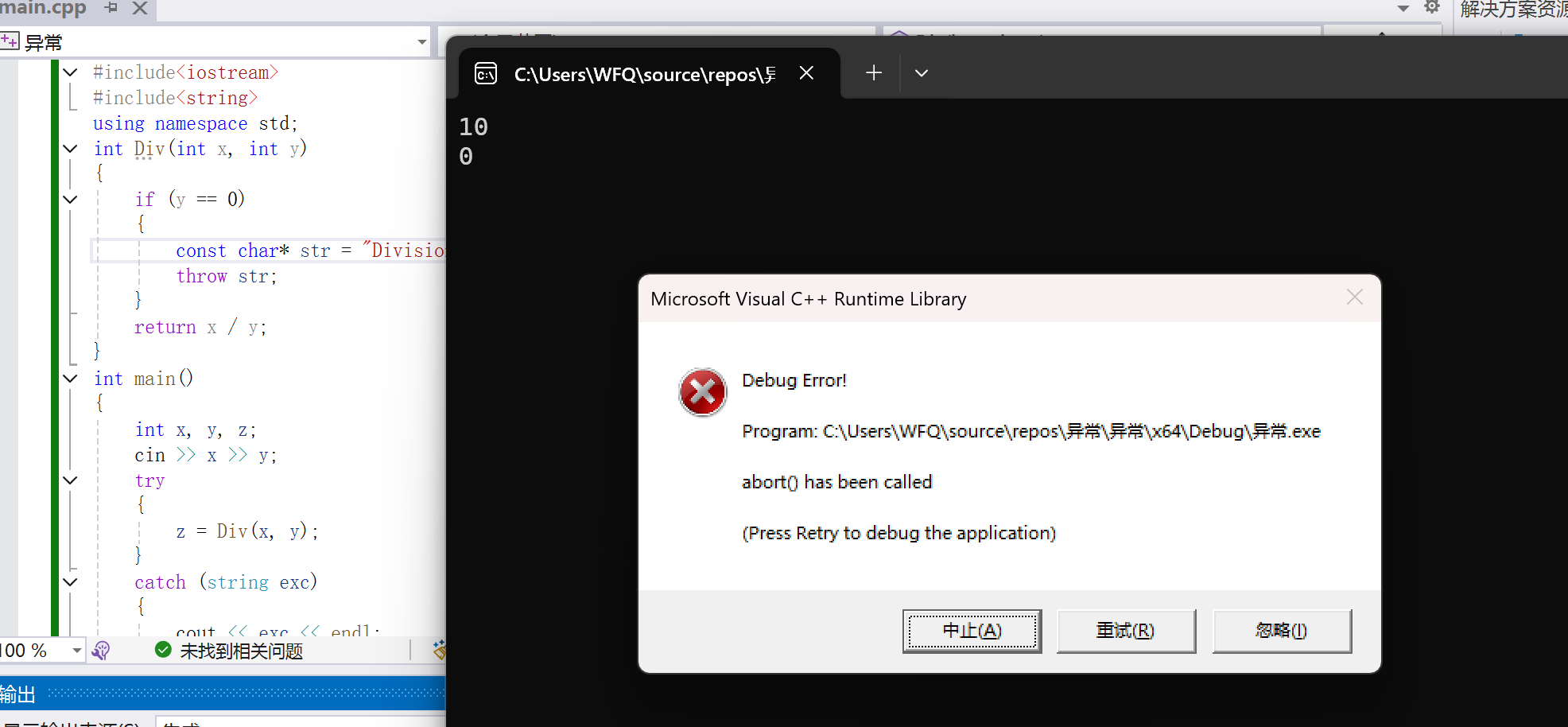
test.2:
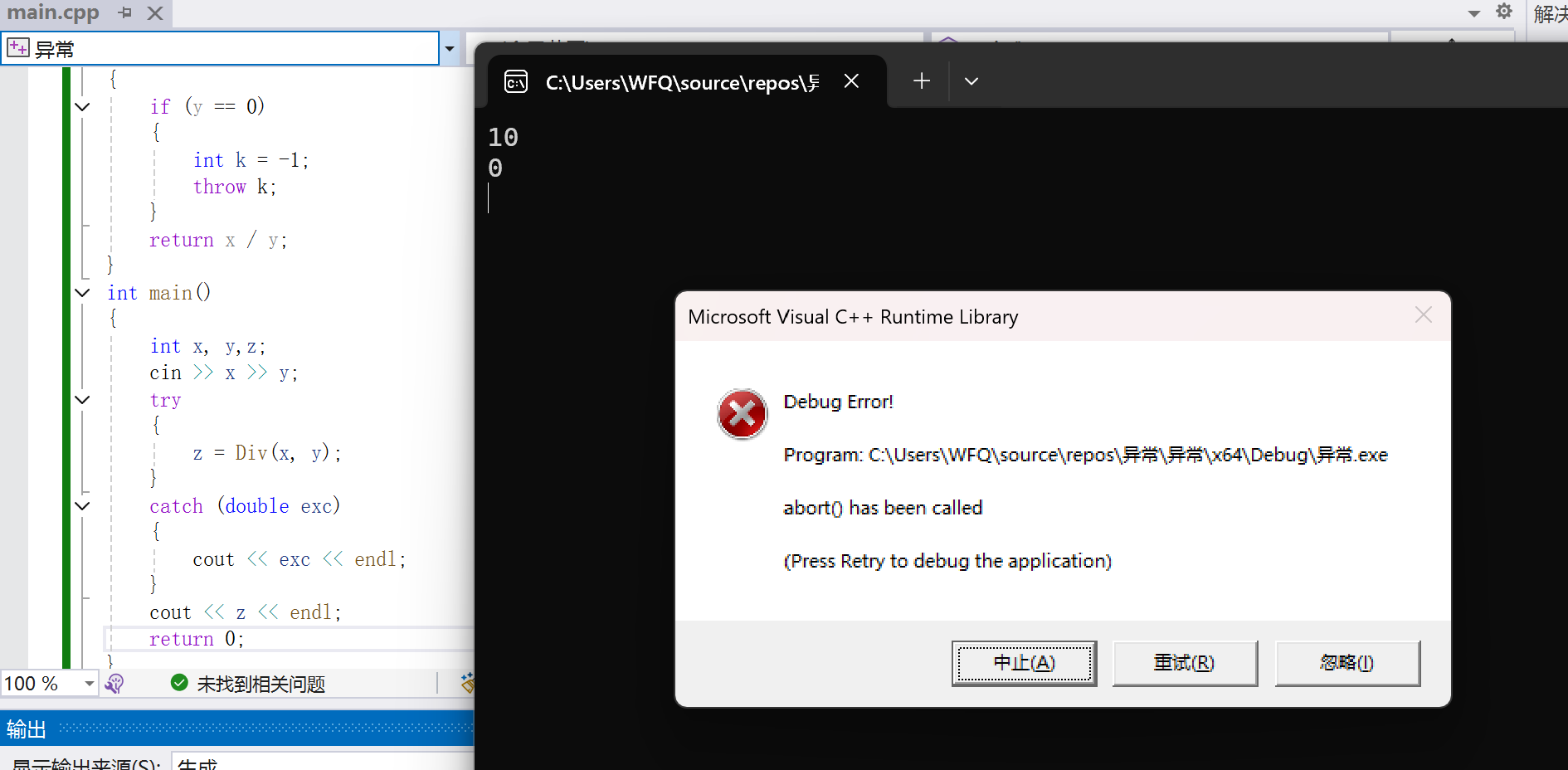
那么根据代码的运行结果,我们就知道这里catch的捕获机制就是精准匹配异常对象的数据类型,不会存在隐式类型转化,但是有一个例外,那么就是如果抛出的异常对象的类型是一个继承父类的子类类型,也就是允许除继承关系外的隐式类型转换。然后catch块如果是捕获父类对象,那么此时catch块能够捕获到子类类型的异常对象
cpp
#include<iostream>
#include<string>
using namespace std;
class base
{
public:
int member1;
};
class derive :public base
{
public:
int member2;
};
int Div(int x, int y)
{
if (y == 0)
{
derive d;
d.member1= 10;
throw d;
}
return x / y;
}
int main()
{
int x, y, z;
cin >> x >> y;
try
{
z = Div(x, y);
cout << z << endl;
}
catch (base exc)
{
cout << exc.member1 << endl;
}
return 0;
}那么这里的代码逻辑就是我定义了一个父类和继承该父类的子类,并且父类定义了一个成员变量member1,那么这里一旦div函数内检查到除数是0,那么就会抛出一个子类类型的异常对象,但是在抛出之前,我给子类对象的父类成员变量给了一个初始值为10,然后用父类对象接收,那么如果catch块能够捕获该子类对象,那么就会执行catch语句块中的内容,也就就是打印子类对象的父类成员变量
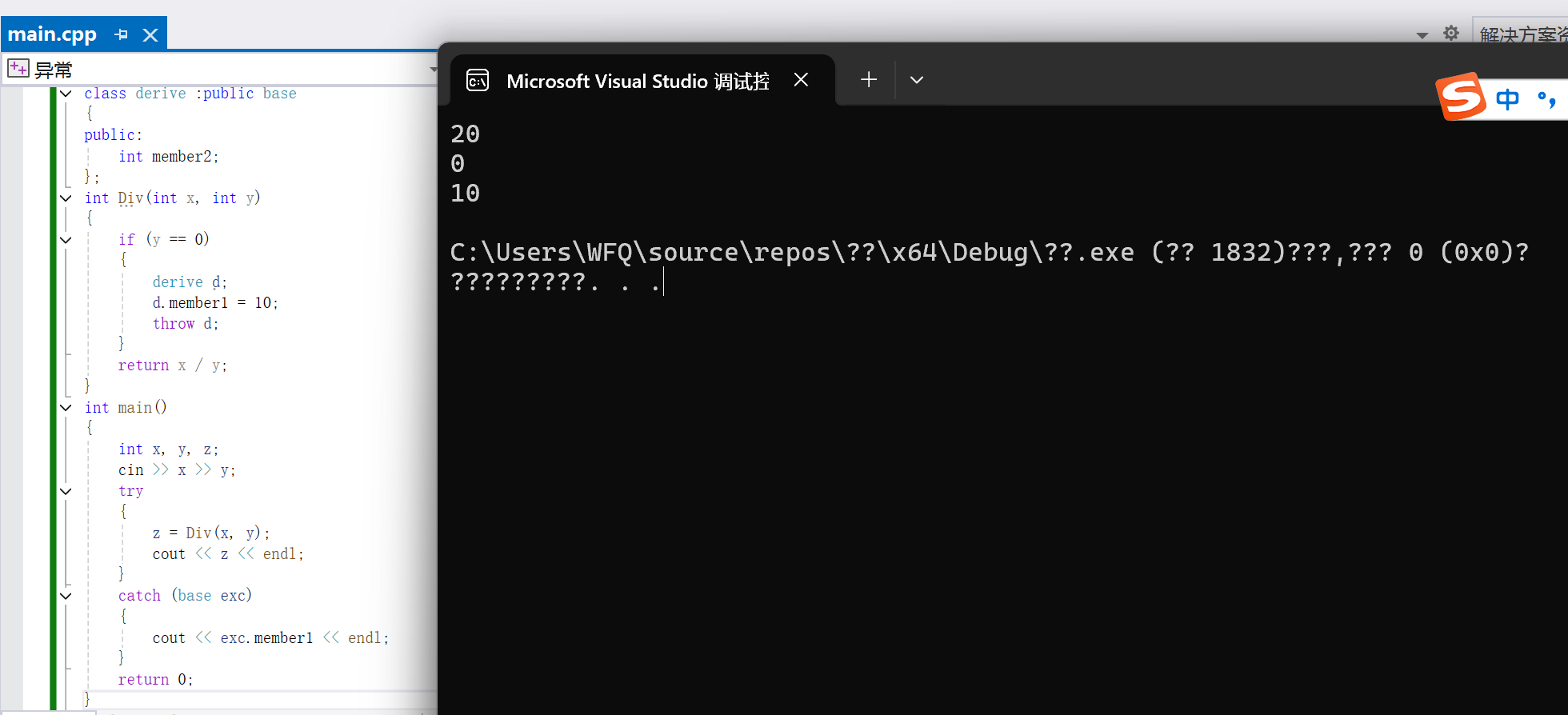
那么根据运行结果,我们能够验证到,catch能够用用父类的对象来捕获一个抛出的子类类型的异常对象
那么这里为什么会有这个特例以及怎么运用,那么这里我先买一个伏笔,那么下文会解释
那么其次注意的一个点就是这里throw抛出了一个异常对象,那么该异常对象一定要被捕获,也就是要有对应的try catch语句,所谓的'对应",意思是即使我们在代码中定义了try catch语句块,但是当前定义的所有的catch语句块要捕获的异常对象的类型与当前抛出的异常对象的类型是不匹配的,比如在上文中谈到的例子中,抛出的是char * 但是要捕获的是string又或者抛出的是int但要捕获的是double,那么这里会导致该异常对象抛出后一直没有对应匹配的catch语句来捕获的话,那么程序就会自动强行终止
那么在刚才的所举的例子中,我们的try catch语句块都是定义在main函数中,然后main函数中调用的函数抛出了异常,那么此时我在引入一个这样的场景,也就是异常的抛出的位置是由连续调用的某个函数抛出,比如main函数调用了fun1,然后fun1调用了fun2,最后fun2调用了fun3,如果异常是在fun3函数中抛出,但是此时我的try catch语句块还是定义在main函数中,那么此时我们fun3一旦抛出了一个string类型的异常对象,那么此时位于main函数中的try catch语句块能否捕获到fun3函数抛出的异常对象呢,那么我们写一个代码来查看现象:
cpp
#include<iostream>
#include<string>
using namespace std;
void fun3()
{
string str = "give a exception";
throw str;
}
void fun2()
{
fun3();
}
void fun1()
{
fun2();
}
int main()
{
try
{
fun1();
}
catch (string exc)
{
cout << exc << endl;
}
return 0;
}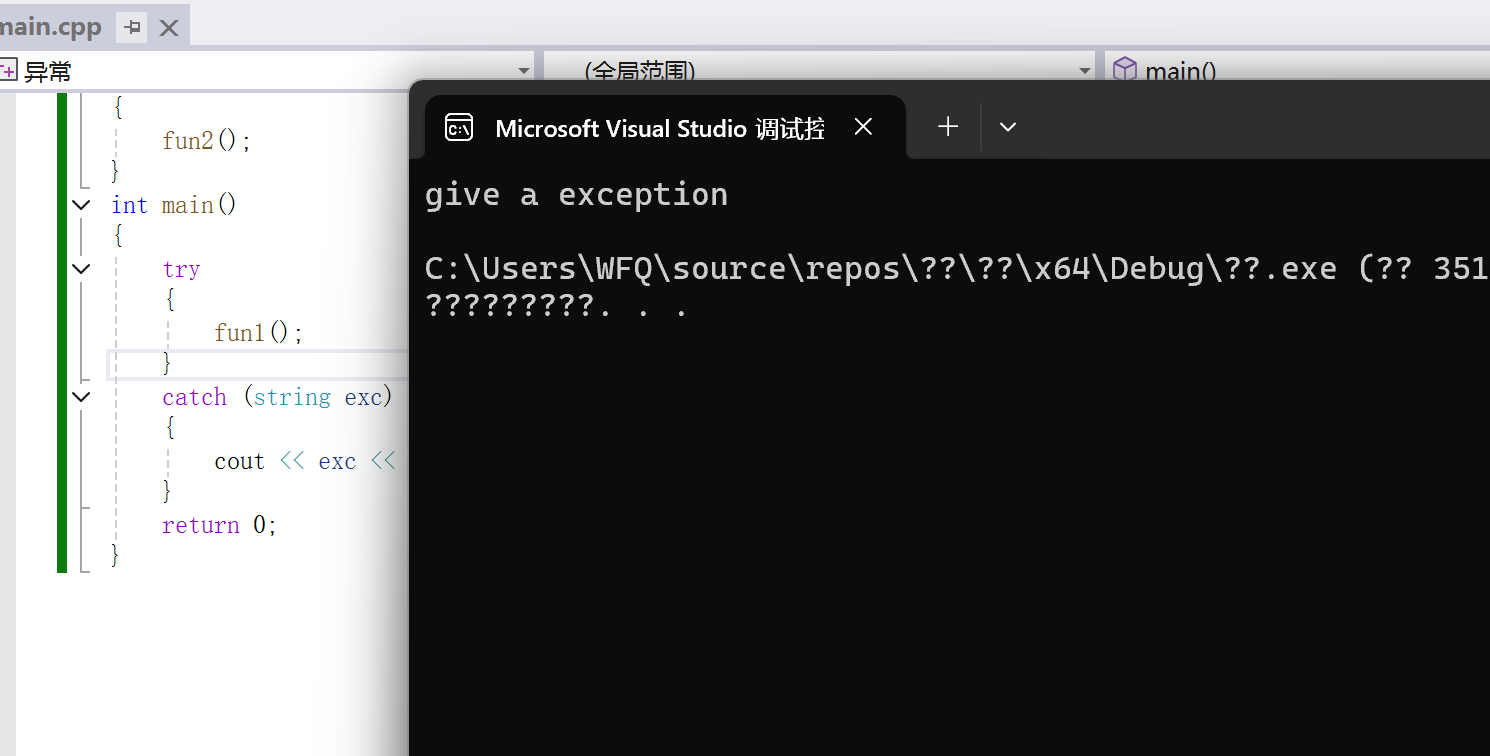
那么这里我们可以观察到此时成功执行了main函数中的try catch语句,那么这个结果其实是符合我们的预期的,因为try catch语句块是定义在main函数中,那么这里异常抛出,那么只能被main函数中的try catch语句块给捕获
那么如果此时我们在刚才的基础上再进行一个变化,那么如果这里我们在fun2以及fun1中也定义能够捕获string类型异常的try catch语句块,但是其中fun2中的catch块要捕获的异常对象的类型是double类型,那么此时我再来执行该代码,并且这里我特意还在每一个函数的末尾添加了一个打印语句,那么我们来看看运行结果是什么:
cpp
#include<iostream>
#include<string>
using namespace std;
void fun3()
{
string str = "give a exception";
throw str;
cout<<"I am fun3"<<endl;
}
void fun2()
{
try {
fun3();
}
catch (double exc)
{
cout <<"fun2: "<< exc << endl;
}
cout<<"I am fun2"<<endl;
}
void fun1()
{
try {
fun2();
}
catch (string exc)
{
cout << "fun1: " << exc << endl;
}
cout<<"I am fun1"<<endl;
}
int main()
{
try
{
fun1();
}
catch (string exc)
{
cout <<"main: "<< exc << endl;
}
cout<<"I am main"<<endl;
return 0;
}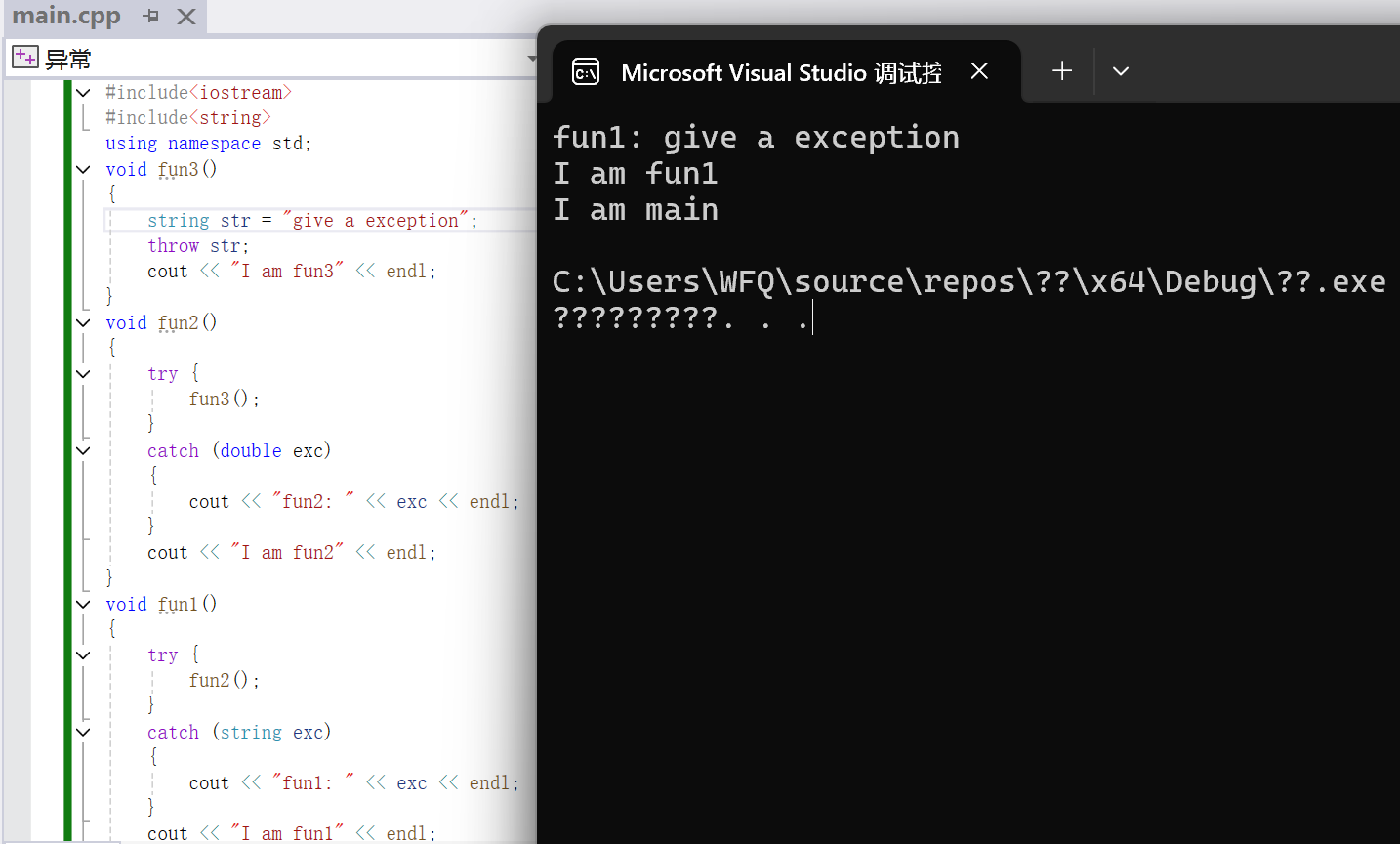
那么根据运行结果,我们可以看到是fun1捕获了异常,那么即使位于函数调用链最顶层的main函数也定义了try catch语句块,并且其也能捕获string类型的异常对象,但是这里由于抛出的string类型的异常对象已经被fun1中定义的try catch语句块的代码捕获,那么就不会在被之后的main函数中定义的catch块捕获,并且这里我们发现这里只打印了fun1以及main函数后面的语句,所以这里异常的抛出还会改变程序的执行流,那么执行流直接到捕获该异常对象的catch语句块中,然后再依次顺序执行catch语句块之后的内容
所以这里我们就能知道异常的一个捕获流程了,那么当函数调用链中的某个位置的函数抛出了异常,那么此时捕获异常,那么这里首先会检查当前抛出异常的源头函数能否捕获,也就是需要扫描该函数中是否定义了try catch语句块,那么没定义,那么意味着当前函数无法捕获异常,那么就沿着函数调用链往上检查上一个函数,而如果定义了try catch语句块,那么在再检查try语句块中的内容是否包含了异常抛出的代码片段或者包含是否调用了被异常传播的函数调用,如果有就可以扫描后面紧跟着的catch语句块来确认是否有配当前异常对象的catch语句块的类型,如果没有那么则还是同样回溯到上层的函数,那么在回溯之前,会销毁当前函数的栈帧,接着在重复之前的步骤检查上层的函数能否捕获
那么这里要解释上文说道的被异传播的函数调用这个概念,那么有的读者不理解这里这里所谓被异常传播的函数,那么我来解释一下,那么如果在函数的调用链中,抛出异常的源头函数,以及沿着函数调用链往上的且没有捕获抛出的异常对象的函数,那么从抛出异常的源头函数沿着函数调用链往上的没有捕获的函数其会被视作传播异常对象的函数,在上文的例子中,那么fun3是抛出异常的源头函数,fun3本身没有捕获异常,那么会往上回溯到fun2,但同时fun2也没有捕获抛出的异常,那么此时fun2继续往上传播该异常对象,然后在回到fun1,那么fun1的try语句块中调用了fun2,那么虽然异常对象是fun3抛出的,但是由于fun2没有捕获异常,但是由于异常对象是fun2传播的,那么此时还是会扫描fun1函数的try后面的catch语句块,那么想强调的是:不一定try语句块中一定是调用抛出异常的源头函数才会检查后面的catch语句块的内容
无 有 否 是 否 是 函数抛出异常 检查当前函数
是否有try-catch语句块 销毁当前函数栈帧 回溯到上层调用函数 检查try语句块
是否包含异常代码 检查catch语句块
是否匹配异常类型 捕获并处理异常 异常处理完成
而是只要包含传播异常的函数调用就能够检查后面的catch语句块,所以try catch的函数捕获机制如果要用4个字来概括的话,那么就是就近捕获,一旦捕获成功,那么执行流就从当前捕获位置往后依次顺序执行
那么这里探讨完了异常的捕获流程之后,那么有的读者知道了如果在一个函数调用链中较深的某个位置抛出异常,那么会从当前位置开始的函数沿着函数调用链往上来依次寻找能够捕获的try catch函数,没有的话,那么当前函数栈帧会被销毁,再回溯到上一层的函数中
那么这里之所以叫异常的捕获,那么就是因为这里我们可以在catch语句块访问到抛出的异常对象,那么在上文的场景中,我们抛出的异常对象是string类型,那么我们捕获到异常后,可以访问到抛出的异常对象中的内容也就是打印string字符串,但是我们知道这里如果try catch块不在抛出异常的源头函数中,而是被该源头函数所在的函数调用链上方的函数捕获,那么等到上方的函数捕获到异常对象的时候,那么此时抛出异常的源头函数栈帧早已经被销毁了,其中在该函数中定义的各种局部变量其中包括异常对象也会被销毁,那么这里却还能访问到的原因是什么呢?
那么这里写了一段代码来进行实验,那么代码的逻辑很简答,那么就是fun1函数抛出了一个异常对象,然后main函数在try语句块中调用fun1函数,然后捕获其抛出的异常对象,但是这里fun1函数在抛出异常对象之前,我先打印了一下抛出的异常对象的地址,然后我又再main函数中的catch语句块也打印定义的异常对象标识符的地址,来进行一个对比:
cpp
#include<string>
using namespace std;
void fun1()
{
int x = 10;
cout <<"x:" <<& x << endl;
throw x;
}
int main()
{
try
{
fun1();
}
catch (int exc)
{
cout <<"exec:"<< & exc << endl;
}
return 0;
}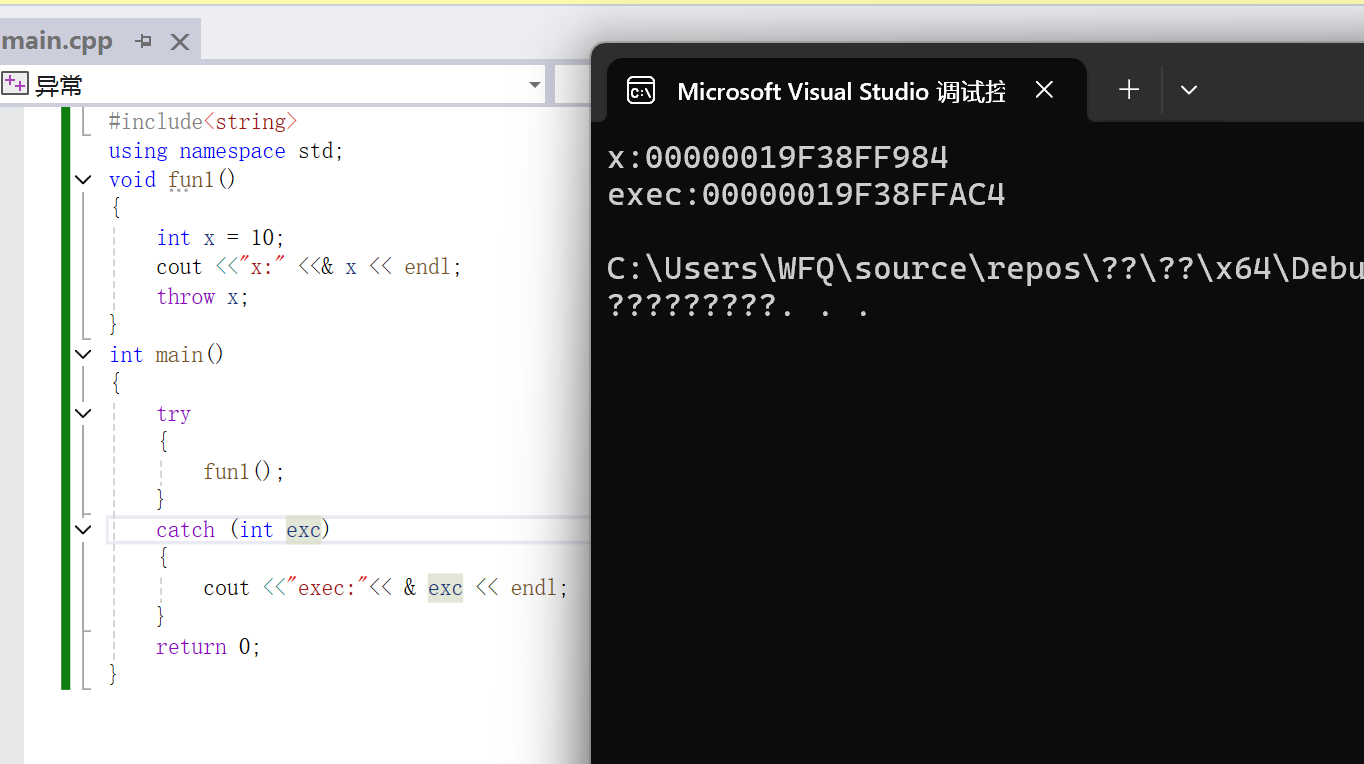
那么这里打印的地址是不一样的,那么这里符合预期,因为抛出的异常对象是位于fun1函数栈帧中,而异常对象标识符是位于main函数栈帧中,所以地址肯定不同,但是还没完,如果这我将异常对象标识符给设置成引用,再来分别打印打印异常对象标识符和位于fun1中抛出的异常对象的地址
cpp
#include<string>
using namespace std;
void fun1()
{
int x = 10;
cout <<"x:" <<& x << endl;
throw x;
}
int main()
{
try
{
fun1();
}
catch (int& exc)
{
cout <<"exec:"<< & exc << endl;
}
return 0;
}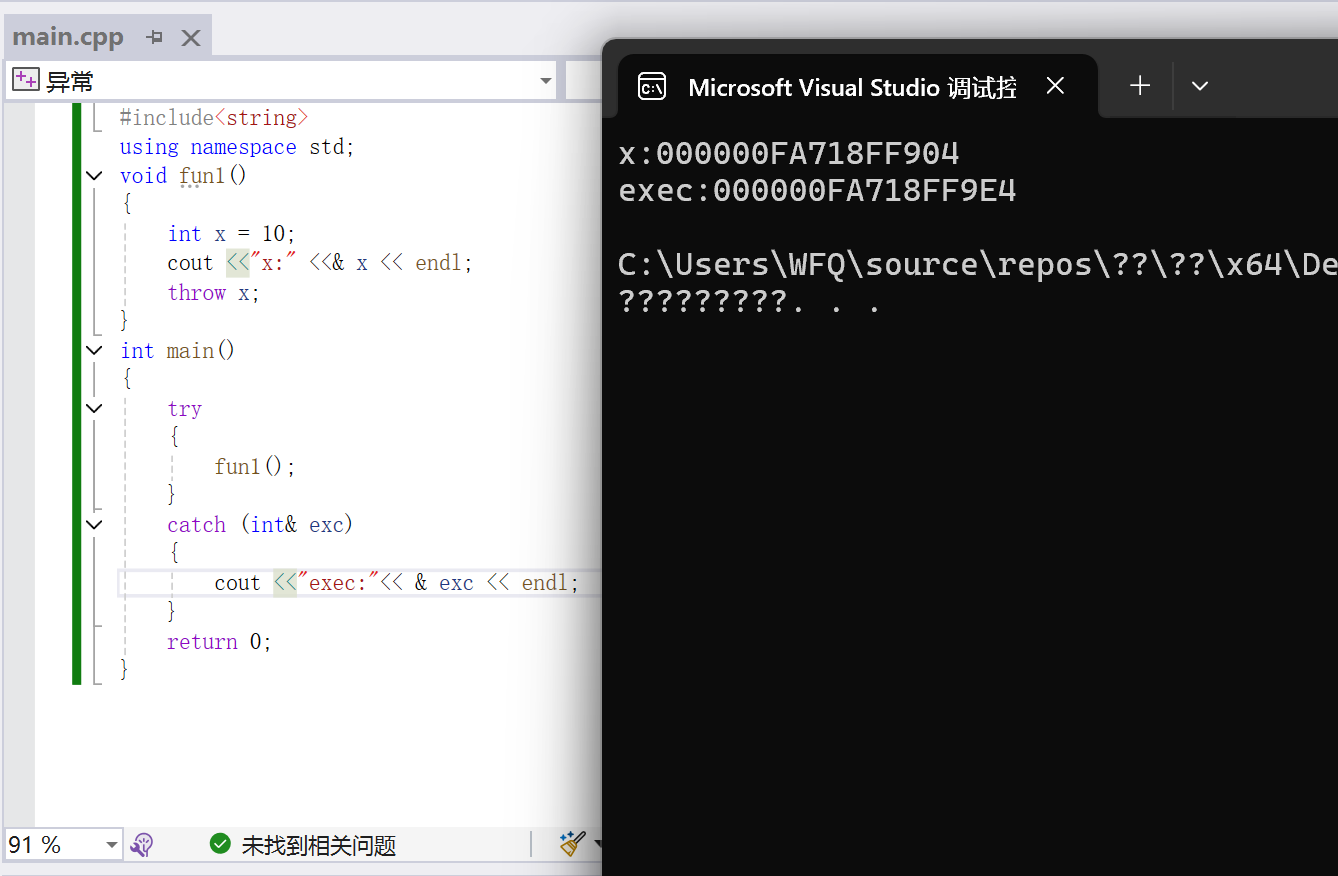
那么这里我将其改成引用,那么我们知道引用就是其指向对象的别名,而我们发现这里引用所绑定的对象的地址和抛出的异常对象的地址是不同的,那么说明这里抛出的异常对象在被函数栈帧被销毁之前,那么系统会在独立于函数调用栈的内存区域会构建一个中间的临时变量,也就是异常对象的副本,将值拷贝给这个副本,然后再通过这个副本拷贝给异常对象标识符,那么就能够验证为什么抛出对象的函数栈帧被销毁了,但是外部的函数却依然能够访问该抛出的异常对象
而我们上文就说过,那么我们异常对象标识符可以定义成一个父类的对象或者引用,来捕获子类对象,那么这里我们围绕这点来谈谈如何利用这个特性
那么我们在以后写一个大型的项目的时候,比如一个需要长期稳定运行的软件,那么这个软件的主流程会封装到一个while的死循环中,那么这个软件涉及到的各个模块比如网络模块以及数据模块,那么通常是定义成一个函数,那么这些函数通常是交给一个小组去维护,那么每一个模块难免会出现错误,所以每一个模块都会抛出异常,然后异常抛出之后,那么外部的主流程的while死循环会捕获异常,并且将该异常记录进日志,那么通过日志来找到程序错误的模块以及导致错误的原因以及谁负责该模块,那么这里我们可以通过设置一个异常编号,那么通过异常编号来定位抛出异常的模块,比如1到10之间的异常编号代表的就是网路模块,然后11到20则代表的是数据库模块,那而导致错误的原因则是可以用一个string类型的字符串来记录,而这里异常编号以及记录导致异常的原因的string字符串,那么都可以封装到一个类中,但是每一个模块的内容是不同的,意味着其抛出的异常也是不同的,所以除了异常编号以及导致异常的原因至海外,其中应该还应该携带该模块的额外信息,比如网络模块应该还得记录比如是什么协议出错,而数据块模块应该还额外携带包括哪句SQL语句出错
那么这样就意味着每一个模块抛出的异常对象是不同的,那么我们就得在while循环中定义多个catch分支来捕获这些不同类型的异常,就如同你定义一长串的if和else if语句,理论上确实是可以,但是这样会导致代码的可读性降低,那么我们更希望能够减少catch语句块的数量,所以这里我们可以定义一个基类,那么其中封装这些不同模块都应该有的内容,比如异常编号以及记录导致异常的信息的string字符串,然后其中再定义一个打印错误导致异常信息的成员函数并且将该成员函数设置为虚函数,接着我们可以在定义一个派生类继承该基类,然后重写该虚函数,然后子类的虚函数中就饿可以添加一些针对该模块的一些额外信息,比如出错的SQL语句以及网络协议等等
然后catch块捕获到异常之后,那么由于异常对象标识符是父类的指针或者引用,那么其捕获的实子类的异常对象,也就是父类的指针或者引用指向的是子类对象,那么此时通过父类的指针或者引用去调用虚函数,就会触发多态,从而调用子类自己的虚函数,那么这样就可以用来打印各个模块的一些额外的个性化的信息,而不用每一个模块自己定义一个独立的异常对象,然后再定义多个catch语句块来接收不同模块抛出的不同类型的异常对象
cpp
#include<iostream>
#include<string>
using namespace std;
class Execption
{
public:
int num;
string str;
virtual void what()
{
cout << str << endl;
}
};
class database :public Execption
{
public:
string sql;
void what()
{
str = str + sql;
cout << str << endl;
}
};
void data()
{
//关于data模块的代码逻辑
if (1)//这里为了方便演示,假设这里引发了异常
{
database a;
a.num = 1;
a.str = "base give a exception:";
a.sql = " SELECT";
throw a;
}
}
int main()
{
while(1){
try
{
//各个模块的调用
data();
}
catch (Execption& exc)
{
exc.what();
break;
}
}
return 0;
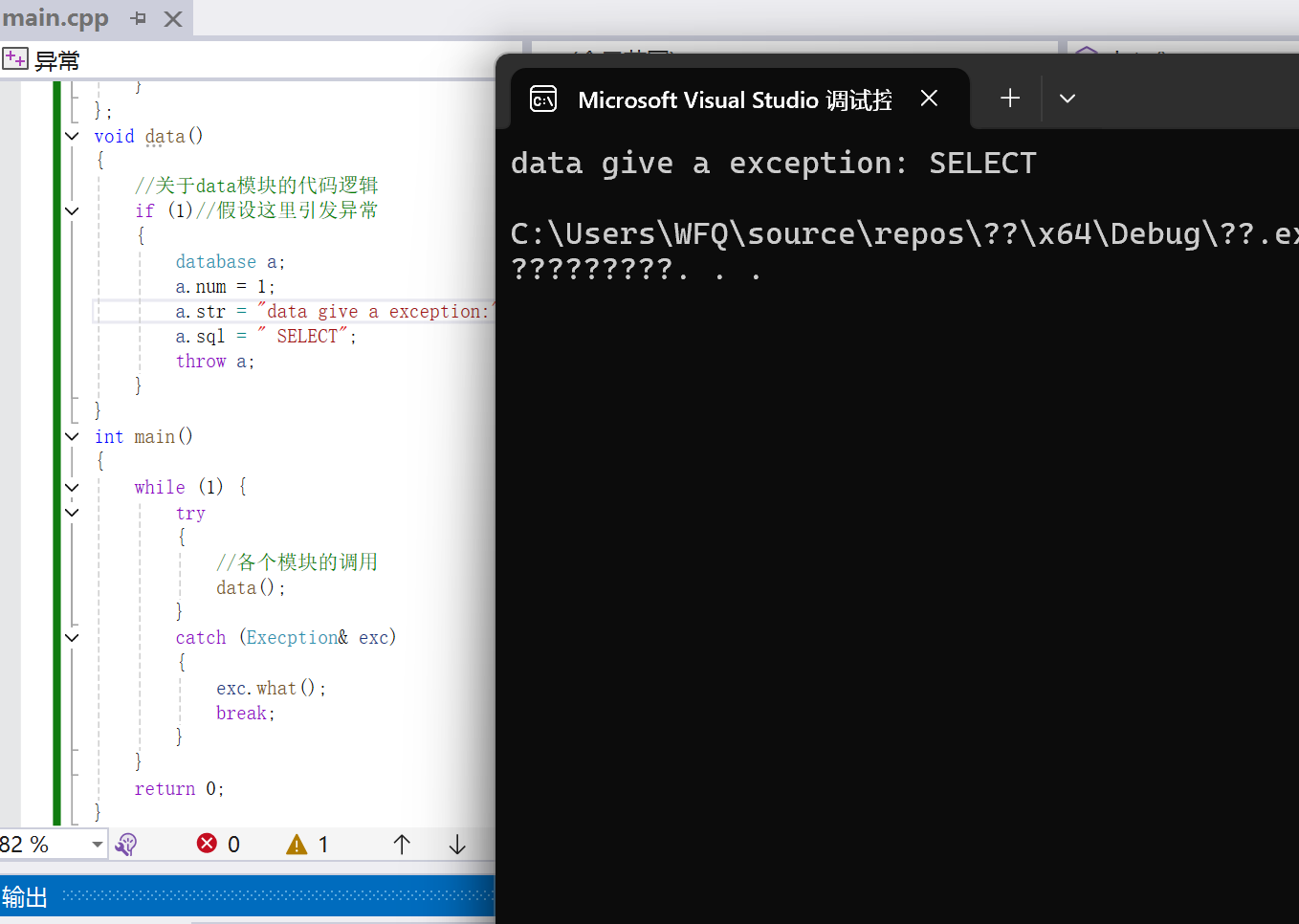
}
评价
那么文章的最后,我们就来评价一下c++处理异常的方式,那么我们知道对于c语言来说,那么其处理异常采取的方式就是断言或者返回错误码,那么而断言的方式则是一种暴力的处理方式,不管是什么类型的异常,即使是某些非致命不至于程序终止的异常,那么采取断言的话,也都采取终止程序的处理方式,所以断言一般是搭配错误码使用,那么在可能会引发致命或者严重的错误的代码位置,那么就可以定义断言的检查逻辑,其他引发非致命错误的位置则返回错误码,那么通过上文的讲述,我们也知道了,这种方式,如果是遇到一个处于函数调用链很深的某个位置的函数出错,那么往上返回错误码,那么首先,从该位置开始逐层往上返回,其中会伴随着函数栈帧的销毁,那么这里返回错误码的主要问题其实不在于函数栈帧销毁带来的性能影响,而是我们整个函数调用链上的所有函数内部都得定义一个检查其调用函数的错误码的逻辑
而上文我就说过,对于一些长期稳定运行的应用软件,那么我们通常会把该应用相应的一些功能专门定义成一个特定模块的函数,那么使用这些功能就是调用对应的函数,而这些函数的调用处则是位于main函数并且封装到一个while的死循环当中,那么对于这些特定模块的函数的调用是否成功的检查逻辑应该位于外部的main函数中,那么这些特定功能的模块的核心逻辑就是处理任务,一旦中间的某个步骤出是出现问题然后抛出了异常
那么它直接将该问题报告给外部的main函数,而不需在依次通知调用链往上的函数,那么主函数捕获到异常之后,立马进行相应的处理以及决策,那么c++的这种处理方式很好实现了业务逻辑与错误处理的分离
并且通过上文用父类的指针和引用来接收子类的异常对象,还可以利用多态,来打印不同的模块的一些个性化的信息
但是c++的这种抛出异常的方式的缺点也很明显,那么一旦代码中某个位置抛出异常,那么该异常必须得被捕获,那么如果异常是在一个较深的函数调用链中的某个函数或者抛出的,那么它会沿着函数调用链往上寻找能够捕获的catch语句,然后执行catch语句块中的内容,那么接着再依次顺序执行整个catch语句块之后的代码,那么这种方式就会打乱代码的执行流,那么会导致代码的执行流混乱,所以建议一般定义try catch语句块的时候,尽量在同一个位置集中定义,不要在不同位置定义
那么这里c++的异常的处理方式,总的来说还是利大于弊
结语
那么这就是本文关于异常的全部讲解,那么下一期博客我会更新AVL树,那么我会持续更新,希望你能多多关注,如果本文有帮助到你的话,还请三连加关注哦,你的支持就是我创作的最大动力
