一、版本控制
1.什么是版本控制?
版本控制用于高效追踪和管理项目开发中的代码、配置及文档变更历史,确保团队成员始终使用正确版本,并支持版本回溯、差异比较和文件恢复。它能带来以下优势:通过历史记录保障数据安全与完整性;多分支开发机制提升团队协作效率;结合CI/CD工具实现自动化流程,简化复杂项目管理能力。
2.什么是版本控制系统?
版本控制工具用于管理代码变更,通过版本号或语义化标签标记不同开发阶段。它能完整记录文件修改历史,支持回退到任意历史版本。该工具允许多开发者协同工作,通过分支机制隔离不同功能开发,最终将所有变更合并至主分支。版本库是版本控制系统的核心。
3.什么是版本库?
版本库是版本控制系统的核心数据库,完整保存了项目文件及其变更历史,包括文件所有版本、元数据以及版本间的依赖关系。其核心特性包括:完整历史记录、分支与合并功能、分布式存储机制。
二、分布式版本控制Git
Git 是一款开源的分布式版本控制系统(DVCS),由 Linux 创始人 Linus Torvalds 在 2005 年开发。该系统能高效管理代码和文件变更历史,支持团队协作与并行开发。其分布式架构特性提供了强大的分支管理功能,可精准追踪每个版本的变化。
1.Git工作流
工作区(Workspace):存放从仓库中提取出来的文件的地方,供用户直接编辑。
暂存区(Index/Stage):文件变更暂存的区域,准备提交的文件信息。
仓库(Local Repository):存储所有版本数据和元信息的地方。
远程仓库(Remote Repository):托管在远程服务器上的共享仓库,供他人浏览、下载代码。
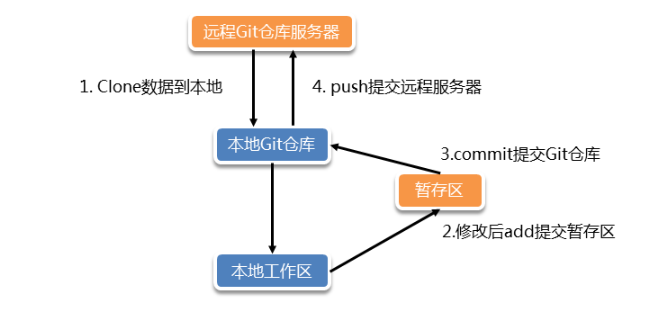
工作流程
2.Git版本库操作
# --local:仓库级(仓库目录下.git/config)
# --global:全局级(~/.gitconfig)
# --system:系统级(/etc/gitconfig)
git config --global user.name 用户名 #设置全局级用户名
git config --global init.defaultBranch 分支名 #设置全局默认分支名称
git config --list #查看已有的Git配置初始化版本库
git init 项目目录查看Git本地仓库状态
git status将文件信息添加到暂存区
git add 文件名将暂存区文件提交到本地仓库并附加提交信息
git commit -m "提交信息"查看本地Git版本库信息
git log #详细信息
git log --pretty=oneline #简略信息
git log --oneline #极简信息3.Git指针操作
还原到指定版本
git reset --hard 版本id获取指针移动轨迹
git reflog4.Git分支操作
查看分支信息
git branch -v创建分支
git branch 分支名切换分支
git checkout 分支名删除分支
git branch -d 分支名合并分支到master中
git merge 分支名5.Git标签管理
查看已有标签
git tag创建标签
git tag 标签名删除标签
git tag -d 标签名三、Git服务器
Git 服务器是用于集中存储和管理 Git 仓库的核心节点,主要负责维护代码版本历史、支持团队协作开发。它通过标准协议与本地仓库进行数据交互,通常部署在独立服务器上,开发者可通过网络远程访问服务器中的代码仓库。常用的Git服务器有GitHub、Gitee码云、GitLab。
1.GitLab
DevOps一体化平台,集成代码托管、CI/CD、项目管理、安全扫描等生命周期工具,支持端到端软件交付,提供多层安全防护、操作审计日志及符合国内法规的数据存储方案。
2.代码托管
git remote add origin GitLub仓库项目地址 #关联远程项目
git push -u origin --all #推送本地仓库所有分支
git push -u origin --tags #推送本地仓库所有标签http方式免密推送
git config --global credential.helper store #持久保存密码设置四、CI/CD
在DevOps理念推动下,持续集成(CI)、持续交付(CD)和持续部署(CD)等创新方法应运而生,显著提升了软件发布效率。CI的核心在于开发人员频繁提交代码至共享仓库,借助自动化构建和测试确保代码质量,有效规避集成问题。CD则更进一步,能够将验证通过的代码自动发布到存储库,实现生产环境的一键部署。而最高级别的持续部署则是全自动化流程,所有测试通过的代码将自动部署上线,完全无需人工参与。
1.DevOps流程
计划:项目初期,研讨业务需求,指定研发计划。
编码:开发团队基于项目需求编写业务代码,使用Git等工具进行版本控制。
构建:通过Maven,Docker等工具打包代码为可上线的产品。
测试:对产品进行自动化测试(如Jmeter)验证其功能和性能。
发布:生成通过测试后的稳定版本,准备进行部署。
部署:使用Ansible、Kubernetes等工具将产品自动发布到生产环境。
运营:运维团队监控产品在生产环境下的工作中状态,处理异常。
监控:使用Prometheus进行日志与指标的收集,反馈信息到计划阶段优化迭代。
2.Jenkins
Jenkins 是一款开源的 **持续集成/持续交付(CI/CD)** 自动化工具,基于 Java 开发,广泛应用于软件构建、测试和部署流程。支持Maven、Gradle等构建工具,能实现自定化编译与测试,监控Git的变更,触发预设的构建流程,快速测试代码质量,通过流水线(Pipeline)将构建好的产品部署到测试或生产环境。
五、Elasticsearch
Elasticsearch 是一个基于 Lucene 构建的开源分布式搜索引擎,专为全文检索、日志分析、复杂查询等高性能场景设计。具备分布式存储与计算的功能,实现数据自动分片并支持副本,提升可靠性与查询并行度,通过粉刺、标准化的词项映射,实现高效率全文检索,数据写入之后秒级可查,适用于日志监控等实时性要求较高的场景。
1.Elasticsearch服务配置
# vim /etc/elasticsearch/elasticsearch.yml
node.name: Services #23行,ES节点名称
path.data: /var/lib/elasticsearch #33行,ES数据存储路径
path.logs: /var/log/elasticsearch #37行,ES日志存储路径
network.host: 0.0.0.0 #55行,监听地址
http.port: 9200 #59行,HTTP端口
http.cors.enabled: true #60行,开启HTTP跨域访问支持
http.cors.allow-origin: "*" #61行,允许跨域的访问范围启动Elasticsearch服务,设置服务开机自启动systemctl enable elasticsearch --now2.测试Ik分词器
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/_analyze?pretty -d '
{
"analyzer": "standard",
"text": "需要分析的文本内容"
}'3.HEAD插件
导入ES-HEAD插件
podman load -i Elasticsearch/elasticsearch-head.tar启动HEAD容器
podman run -d --name es-head --hostname es-head -p 9100:9100 localhost/elasticsearch-head:latest 配置ES-HEAD跨域
#sed -n '59,61p' /etc/elasticsearch/elasticsearch.yml
http.port: 9200
http.cors.enabled: true #开启http跨域支持
http.cors.allow-origin: "*" #允许跨域的访问范围六、消息队列
消息队列是一种进程之间通信机制,用于在不同进程或服务之间以异步、解藕的方式传递数据。其核心思想是将消息暂存与队列当中,由生产者和消费者按需处理,广泛应用于分布式系统和高并发场景。
1.消息队列特点
异步处理:生产者发送消息后无需等待消费者处理,提升系统响应速度。
应用解藕:生产者和消费者通过队列交互,降低模块间直接依赖。
流量削峰:缓存突发请求,避免系统因瞬间高并发崩溃。
2.RabbitMQ
RabbitMQ 是一款基于 AMQP(高级消息队列协议)的开源消息中间件,专为分布式系统设计,可实现高效可靠的消息传递。它支持多语言客户端接入,提供直观的可视化管理界面,并具备灵活的消息分发机制,同时支持集群部署和持久化存储。
3.工作模式
简单模式(Simple):生产者直接发送消息到对列,消费者从队列中消费,一对一通信。
工作队列模式(Work Queues):多个消费者共享一个队列,消息通过轮询或者权重分配。
发布/订阅模式(Fanout):交换机将消息广播到所有绑定的队列,无路由键匹配。
路由模式(Direct):交换机根据Routing Key精确匹配队列的Binding Key,实现点对点通信。
主题模式(Topic):通过通配符实现模糊匹配。
4.RabbitMQ部署
安装Erlang
dnf -y install erlang-25.2-1.el8.x86_64.rpm安装RabbitMQ
dnf -y install rabbitmq-server-3.11.5-1.el8.noarch.rpm启动网页管理插件
rabbitmq-plugins enable rabbitmq_management创建用户
rabbitmqctl add_user 用户名列出已有用户
rabbitmqctl list_users为用户添加标签
abbitmqctl set_user_tags 用户名 标签
#超级管理员(administrator) 监控者(monitoring) 策略制定者(policymaker) 普通管理者(management) 其他(guest)列出已有虚拟主机
rabbitmqctl list_vhosts 创建虚拟机
rabbitmqctl add_vhost /虚拟机名设置用户对虚拟主机的所有权限
rabbitmqctl set_permissions -p /主机名 用户名查看用户权限
rabbitmqctl list_user_permissions 用户名