AI IDE在大规模代码库中如何高效、低成本地定位相关上下文?从实际使用上来看,部分AI IDE(Claude Code、Gemini、Cline 等)倾向不做持久索引,而是以grep/read file等工具反复检索;而Cursor等产品采用 Codebase Indexing(代码切分 + 向量化 + 服务端索引),属于代码 RAG典型范式;经过翻阅了大量资料和实际使用体验之后,我得出结论:
-
在典型的"Bug 定位 / Issue 修复 / 跨文件跳转 / 语义相似片段检索"任务上,引入代码向量检索后,检索稳定性与对话 token 成本均显著改善。
-
纯
grep方案在精确性与时间/金钱成本(大量无关上下文读取)上存在系统性短板,但在确定性符号定位与超低延迟上仍有价值。 -
更优的方案是混合检索:BM25/关键词检索 + 语义ANN + 代码结构特征(AST)+ 轻量 rerank。
针对这种情况,我开发了一款MCP Server ,基于向量数据库并结合语义检索,搭配IDE内置的命令行工具,可以减少代码库索引时可能存在的token过度消耗和长时间等待,兼容常见的AI IDE,感兴趣的读者可以直接去项目地址(github.com/zishengwu/s...)进行下载使用。
1. 为什么选择RAG而非传统搜索(grep, glob)?
在使用AI编程助手时,我们主要面临三类任务:
- 根据需求实现新功能。
- 在指定文件中修改既有代码。
- 查找并修复Bug。
对于第二类任务,上下文是明确的。但对于第一和第三类任务,AI必须自主识别相关文件和代码片段作为上下文。如果仅仅依赖AI自身的能力或grep、glob等简单搜索工具,往往会导致巨大的等待时间和过度的Token消耗。例如,要找到某个特定函数的实现,可能需要大量的工具调用和反复尝试。
而这种场景刚好是RAG非常擅长的,通过为代码库创建一个语义索引,可以执行一次高效的搜索,直接检索到最相关的上下文,从而极大地降低延迟和成本。
2. 如何对代码块进行索引?
虽然可以使用RecursiveCharacterTextSplitter或正则表达式等传统文本切分方法,但对于代码而言,使用抽象语法树(Abstract Syntax Trees, AST)是一种更精确、更结构化的方法。
什么是AST?
AST是源代码语法结构的抽象树状表示。树中的每一个节点都代表代码中的一个构造。这能够将代码视为结构化实体,而非纯文本,从而精确地提取函数、类、方法等逻辑单元。
python
import ast
import inspect
import graphviz
from ast import NodeTransformer, fix_missing_locations, copy_location
# 1.要处理的源代码
source_code = """
def hello_world(name):
greeting = f"Hello, {name}!"
print(greeting)
return greeting
def calculate_sum(a, b):
result = a + b
print(f"The sum is: {result}")
return result
class MyClass:
def method1(self):
print("Method 1 called")
def method2(self, x):
return x * 2
"""
# 2.解析代码生成AST
def parse_and_visualize(code):
"""解析代码并可视化AST"""
try:
tree = ast.parse(code)
dot = ast_to_graphviz(tree)
dot.render('ast_tree', view=True, format='png')
return tree
except SyntaxError as e:
return None比如上述Python代码中的函数可以被解析成如下的语法树: 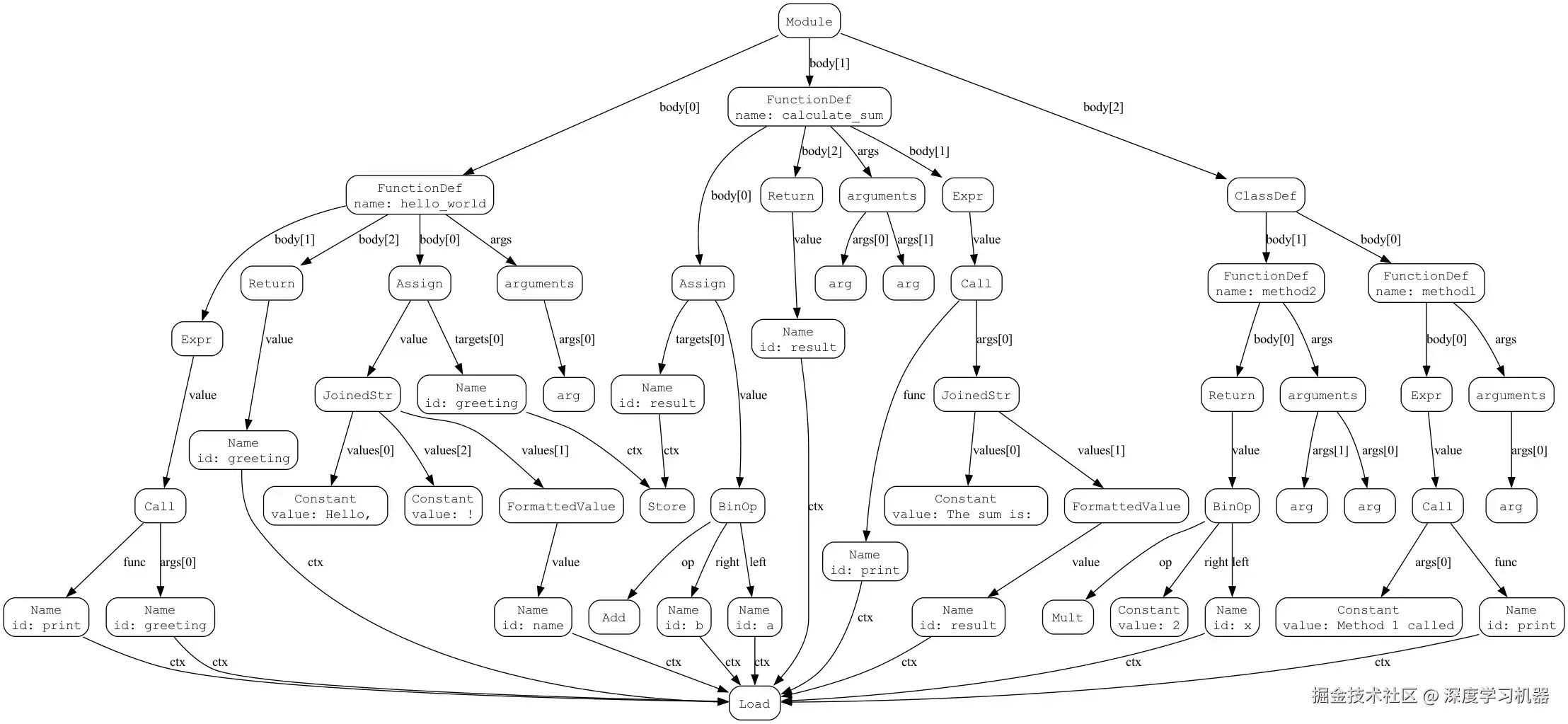
系统使用SmartASTParser类,它利用了内置的ast模块解析Python代码,其他语言,如Java、C++、JavaScript、TypeScript等,则使用了tree-sitter库进行解析。
以下是ast_parser.py中解析Python代码的片段:
python
# 来源: ast_parser.py
@staticmethod
def _extract_python(file_path: Path, content: str) -> List[Dict]:
try:
tree = ast.parse(content)
except SyntaxError as e:
print(f"文件 {file_path} 存在语法错误: {e}")
return []
blocks: List[Dict] = []
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef, ast.ClassDef)):
block_info = SmartASTParser._parse_python_node(node, content, file_path)
blocks.append(block_info)
return blocks该方法遍历AST,提取出对应函数和类的节点,并为每个代码块创建结构化数据。
3. 如何保持索引更新?
一个索引只有在保持最新时才有用。我探索了以下几种变更追踪策略。
策略一:全量重新索引
最简单但效率最低的方法。每当需要更新时,它会从头开始重新索引整个代码库。这种方法的计算成本极高,不具备可扩展性。
策略二:追踪文件修改时间
一个稍好的方法是检查文件的最后修改时间戳。但是,如果文件在没有实际内容变更的情况下被保存,或者被恢复到原始状态,这仍可能导致不必要的重复索引。
策略三:哈希文件内容
该方法通过计算每个文件内容的哈希值(FileHash = H(file_content))来改进时间戳方法。只有当新哈希值与旧哈希值不同时,才认为发生了变更。这种方法克服了策略二容易引起重复索引的缺点,但仍然需要遍历所有的文件才能定位出哪个文件进行了修改。
策略四:分层Merkle树
为了实现精确高效的更新,本系统实现了一种基于Merkle树 的变更追踪机制。这种数据结构使我们能够验证大型数据集的完整性,并快速定位变更点。 
CodeChangeTracker类实现了这一策略:
- 文件哈希收集: 首先,它为项目中的每个源文件计算SHA-256哈希值。
- Merkle树构建 : 这些文件哈希成为Merkle树的"叶子节点"。通过递归地对节点对进行哈希,最终构建出一棵树,其唯一的
ProjectRoot(项目根)哈希代表了整个代码库当前状态的指纹。 - 变更检测 : 要检测变更,只需计算新的
ProjectRoot并将其与前一次索引运行时存储的根哈希进行比较。-
如果根哈希相同,代码库未发生变化。
-
如果不同,可以从根节点向下遍历树,在每一层比较节点哈希,从而以O(log n)的时间复杂度高效地定位到具体是哪些文件被添加、修改或删除了。相比策略三,实现时间复杂度从O(n)降低到了O(log n)。
-
以下是code_change_tracker.py中构建树的核心逻辑:
python
# 来源: code_change_tracker.py
@staticmethod
def _build_merkle_tree(file_hashes: Dict[str, str]) -> Optional[MerkleNode]:
"""构建Merkle树"""
if not file_hashes:
return None
sorted_files = sorted(file_hashes.items())
leaves = [MerkleNode(hash=file_hash, file_path=file_path, is_leaf=True) for file_path, file_hash in sorted_files]
if len(leaves) == 1:
return leaves[0]
current_level = leaves
while len(current_level) > 1:
next_level = []
for i in range(0, len(current_level), 2):
left = current_level[i]
right = current_level[i + 1] if i + 1 < len(current_level) else left # 如果节点数为奇数,则复制最后一个节点
parent_hash = CodeChangeTracker._hash_pair(left.hash, right.hash)
parent = MerkleNode(hash=parent_hash, left=left, right=right)
next_level.append(parent)
current_level = next_level
return current_level[0] if current_level else None这种更新方法确保了索引成本与变更的大小成正比,而不是与项目的大小成正比。
4. 系统架构
该系统由几个关键模块协同工作,提供了一个健壮的代码索引和检索服务。
4.1 组件概览
fast_mcp_server.py
功能: 提供 FastMCP 服务,暴露用于代码索引和查询的端点。
-
核心组件
VectorDBManager: 管理 ChromaDB 实例IncrementalCodeIndexer: 协调增量索引过程BackgroundIndexer: 后台任务管理器(自动化全量 + 增量索引)
-
暴露的工具
工具函数 说明 full_index(project_path)触发对指定项目的全量索引 status(project_path)获取项目的索引状态 query(project_path, text, top_k)对项目进行语义搜索
code_indexer.py
功能: 索引过程的"大脑",负责调度检测、解析、嵌入、存储。
-
关键方法
方法 功能 run_incremental_indexing检测并处理已变更的文件 full_index扫描并索引所有源文件 _process_filesAST 解析、代码块切分、调用外部 API 生成嵌入、更新向量数据库
code_change_tracker.py
功能: 基于 Merkle 树的变更检测。
- 在项目内
.code_index目录维护文件哈希状态 - 用于判断哪些文件需要增量更新
ast_parser.py
功能: 使用 AST 将源代码解析为结构化的代码块。
vector_db.py
功能: 数据访问层,封装与 ChromaDB 的交互。
-
关键特性
功能 说明 集合管理 每个项目单独维护一个集合 数据操作 upsert(插入或更新)、delete语义搜索 query_by_embedding备份/恢复 save_all_data_to_json,load_all_data_from_json
4.2 架构图
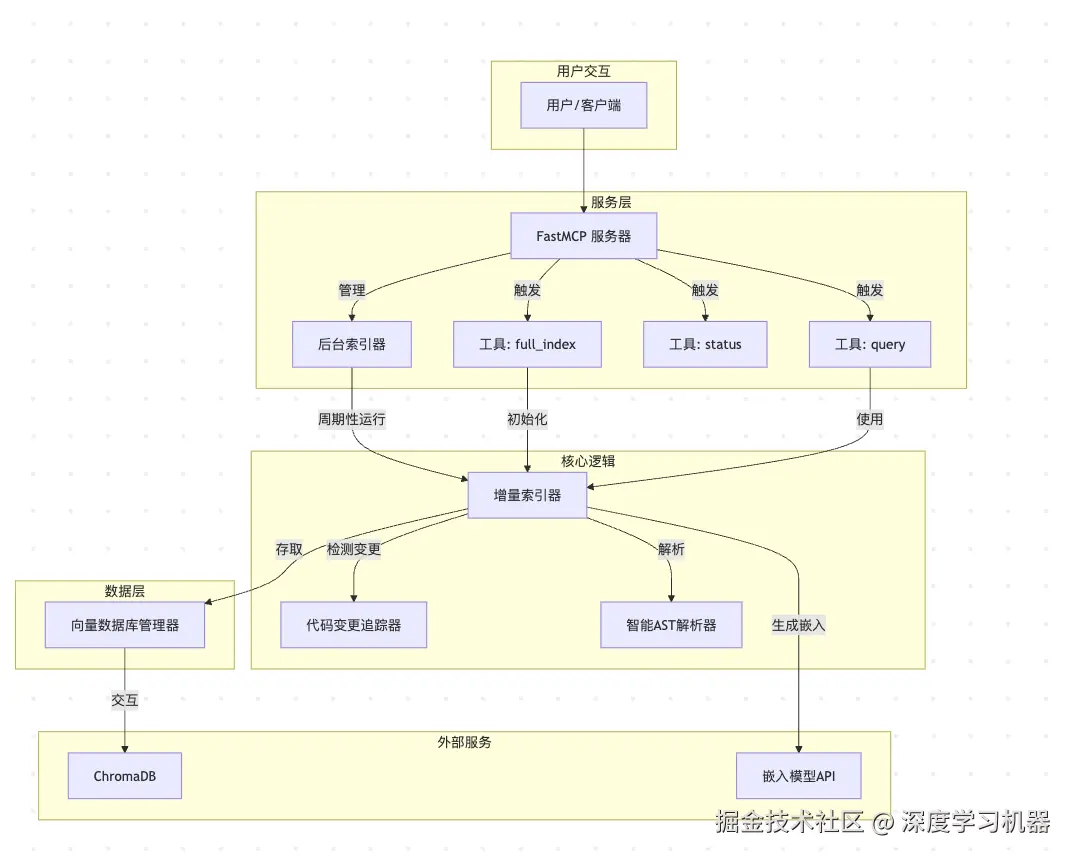
4.3 详细工作流程
4.3.1 初始索引流程
- 触发 : 用户首次为项目调用
full_index工具。 - 后台任务 :
BackgroundIndexer启动一个后台线程来执行全量索引,避免阻塞服务器。 - 文件扫描 :
IncrementalCodeIndexer.full_index扫描项目目录以查找所有支持的源文件。 - AST解析 : 对每个文件,调用
SmartASTParser来提取所有逻辑代码块(函数、类)。 - 向量化 : 准备代码块以进行嵌入。长代码块使用
RecursiveCharacterTextSplitter进行切分。然后将文本发送到嵌入模型API,转换为高维向量。 - 数据库存储 :
VectorDBManager.upsert_blocks将代码块的唯一ID、向量和元数据(文件路径、行号等)存储到项目的专用ChromaDB集合中。 - 状态更新 :
CodeChangeTracker根据所有已索引文件的哈希构建一个Merkle树,并将其树结构和根哈希保存到磁盘。这为未来的增量更新提供了基线。
4.3.2 增量索引流程
- 触发 :
BackgroundIndexer的计时器触发(例如,每5分钟一次)。 - 变更检测 : 调用
CodeChangeTracker.detect_changes。它计算当前文件的哈希,构建一个新的Merkle树,并将其根与存储的根进行比较。通过遍历树,它能高效地识别出added(新增)、modified(修改)和deleted(删除)的文件。 - 处理删除 : 对于
deleted列表中的每个文件,VectorDBManager.delete_blocks_by_file会从ChromaDB中移除其所有相关条目。 - 处理新增/修改 : 对于
added和modified列表中的文件,系统首先删除任何旧索引(针对修改的文件),然后执行与全量索引相同的解析、向量化和存储流程。 - 状态更新: 构建并保存一个新的Merkle树,以反映代码库的最新状态。
4.3.3 查询流程
- 触发 : 用户使用自然语言查询调用
query工具。 - 查询向量化 : 查询文本被发送到
嵌入模型API,转换为一个搜索向量。 - 数据库搜索 :
VectorDBManager.query_by_embedding在项目的ChromaDB集合中执行相似性搜索,以找到与查询向量最相关的top_k个代码块。 - 返回结果: 结果,包括代码、文件路径、行号和相关性分数,被返回给用户。
有些AI IDE,如Cursor,会在代码库首次打开的时候进行索引的创建,但这是 IDE 的行为,MCP协议无法独立做到这样,因此索引的创建仍然需要用户第一次主动调用
full_index工具进行创建。
5 使用方法
下载项目代码到本地
bash
git clone https://github.com/zishengwu/semantic-context-mcp配置MCP JSON文件:
json
{
"mcpServers": {
"Semantic Context MCP Server": {
"command": "fastmcp",
"args": [
"run",
"your_code_base/semantic-context-mcp/vector_search/fast_mcp_server.py:mcp"
],
"env": {
"OPENAI_API_KEY": "your_api_key",
"OPENAI_BASE_URL": "your_api_base_url",
"OPENAI_MODEL_NAME": "your_embedding_model_name"
}
}
}
}6 写在最后
从2024年开始,互联网上关于RAG技术会不会被取代的争论就一直没有停下。然而,最流行的AI IDE也没有完全抛弃这种经典的思路,可以说,RAG不会消亡,只会不断以新的形态存在,比如现在流行的Context Engineering,其核心关注点也就还是那些。
本项目采用了经典的RAG架构进行开发,基于向量数据库并结合语义检索,搭配IDE内置的命令行工具,可以减少代码库索引时可能存在的token过度消耗和长时间等待,兼容常见的AI IDE,感兴趣的读者可以直接去项目地址(github.com/zishengwu/s...)下载,也欢迎提出修改意见或贡献代码。>