
导论:从数字化世界到可计算世界
数字地图的演进,本质上是一场关于"世界可计算性"的持续探索。第一代地图的核心任务是数字化转录(Digital Transcription) ,它成功地将物理世界的静态元素------道路、建筑、兴趣点(POI)------抽象为数据库中可供计算机检索的结构化数据。这是一个伟大的成就,它让我们拥有了物理世界的数字镜像。然而,一个真正有用的导航服务所必须面对的,是一个充满动态、随机性和复杂交互的真实世界,其核心挑战便是交通。

交通系统是一个典型的复杂自适应系统(Complex Adaptive System),更接近于一个混沌系统。其宏观状态由亿万个独立决策主体(驾驶员)的微观行为、复杂的环境因素(天气、光照、道路设施)以及深刻的时空依赖性(上游的交通事故会在几分钟内引发数公里长的拥堵)共同涌现而成。对这样一个系统进行精确建模、可靠预测和最优决策,是现代导航技术皇冠上的明珠。
高德地图给出的答案,是系统性地、分层次地应用深度学习技术,构建了一个从底层数据处理到顶层人机交互的完整智能技术栈。这一架构的核心思想,是从"连接"物理世界的基本信息,跃迁至"理解"其内在运行规律,并最终实现"预测"和"决策"的智能闭环。这标志着地图服务的核心价值,正从信息提供(Information Provision) 转向 决策支持(Decision Support)乃至自主决策(Autonomous Decision-Making) 。
近年来,高德地图提出的全面AI化战略及其AI原生地图应用,是这一技术哲学演进的必然产物和集大成者。它标志着其内部的深度学习应用不再是服务于特定功能的、孤立的"优化补丁",而是被整合进一个统一的、具备感知、推理与行动能力的"空间智能体"(Spatial Agent)。这不仅是一次技术升级,更是一场产品范式的革命。

本文将以前所未有的深度,解构这一智能体系的四大关键层次,剖析深度学习模型如何在不同尺度上解决导航中的核心问题,并最终融为一体:
- 微观路线层(Microscopic Route Level):聚焦于单次导航任务。我们将深入探讨如何利用先进的序列模型(如LSTM),将ETA(预估到达时间)这一核心指标的预测精度推向物理极限,剖析其如何克服传统方法的根本性缺陷。
- 宏观路网层(Macroscopic Network Level):将视角提升至整个城市。我们将解析图神经网络(GNN)如何将复杂的城市路网抽象为数学上的"图",从而洞察并预测整个城市交通网络的宏观流动趋势与拥堵演化。
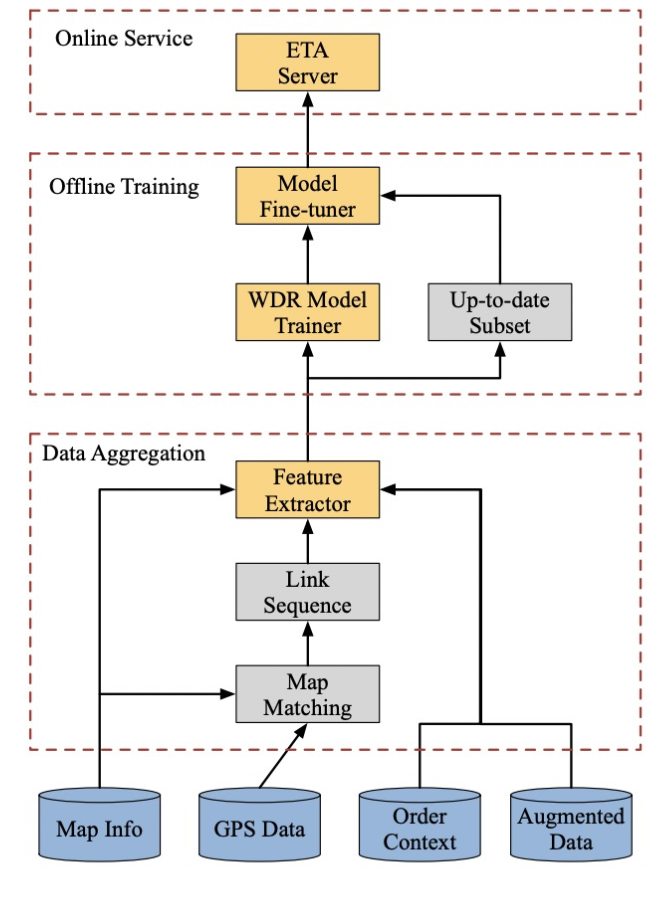
- Foundational 数据层(Foundational Data Layer):深入系统的基石。我们将揭示高德如何通过混合分类模型,从每日亿万级的原始轨迹数据中"去伪存真",确保输入上层模型的数据是纯净、可靠的,这是整个智能体系的"免疫系统"。
- 交互与决策层(Interaction & Decision-Making Layer):探索智能的顶层表达。我们将分析大语言模型(LLM)如何扮演"中央大脑"的角色,将底层复杂的感知与预测能力,封装成可与用户进行自然语言交互、主动完成复杂任务规划的智能体。
通过对这四个层次的穿透式分析,我们将揭示一个世界领先的地图服务商,是如何通过深度学习,将其产品从一个静态的、被动响应的"信息浏览器",重构为一个动态的、主动思考的、具备深刻时空理解力的"计算引擎"。
一、 微观路线层:基于序列模型的ETA精准预测
预估到达时间(Estimated Time of Arrival, ETA)是导航服务与用户之间最直接、最核心的"契约"。一个可靠的ETA是信任的基石,而一个飘忽不定的ETA则是焦虑的源头。在深度学习介入之前,ETA的计算经历了从基于规则、基于历史统计到基于经典机器学习的漫长演进,但始终未能完美解决真实路况的高度动态性问题。
1.1 范式困境:孤立预测与特征工程的极限
传统方法的根本缺陷在于其**"静态"和"孤立"的视角**。
- 基于历史统计:这种方法假设"历史会重演",它会根据当前是周几、几点,去查询历史上此时此刻此路段的平均速度。这在路况平稳时勉强可用,但无法应对任何"意外",如一场突如其来的大雨、一次临时的交通管制或一起交通事故。
- 经典机器学习(如GBDT) :梯度提升决策树等模型将ETA预测看作一个回归问题。它们通过引入更多的人工特征(如天气、节假日、周边POI密度等)来提升精度。然而,它们仍面临两大无法逾越的障碍:
- 特征工程的极限:模型的上限被人类工程师的想象力所束缚。特征的设计过程耗时耗力,且永远无法穷尽所有影响交通的细微因素。更重要的是,特征之间的复杂交互关系(例如,下雨天在晚高峰对主干道的影响远大于对支路的影响)很难被手动捕捉。
- 时空依赖的缺失:这是最致命的缺陷。这些模型通常将一条路线拆解成N个独立的路段,对每个路段的通行时间进行孤立预测,最后简单求和。这种方法完全忽略了交通流的**"传导效应"(Propagation Effect)**。现实中,路段A的突发拥堵,不仅使其自身通行时间增加,更必然会延迟车辆进入后续路段B、C的时间。而路段B、C在新的、被延后的时间点上,其路况可能已经发生了翻天覆地的变化。这种"一步错,步步错"的连锁误差,是传统ETA模型在复杂路况下频繁"跳变"、失去准头的主要原因。
1.2 范式革新:将路线视为时间序列
深度学习,特别是循环神经网络(RNN)及其变体,为ETA预测带来了革命性的范式转变。其核心思想简洁而深刻:不再将一条路线视为一堆路段的无序集合,而是将其看作一个以空间为轴线、以路段为单位的、具有严格先后顺序的时间序列。 高德地图在此场景下深度应用了长短期记忆网络(LSTM)。
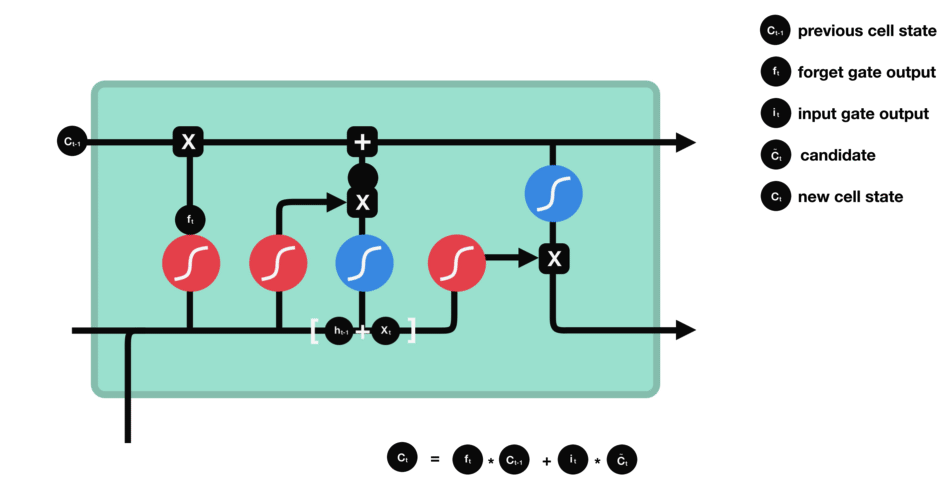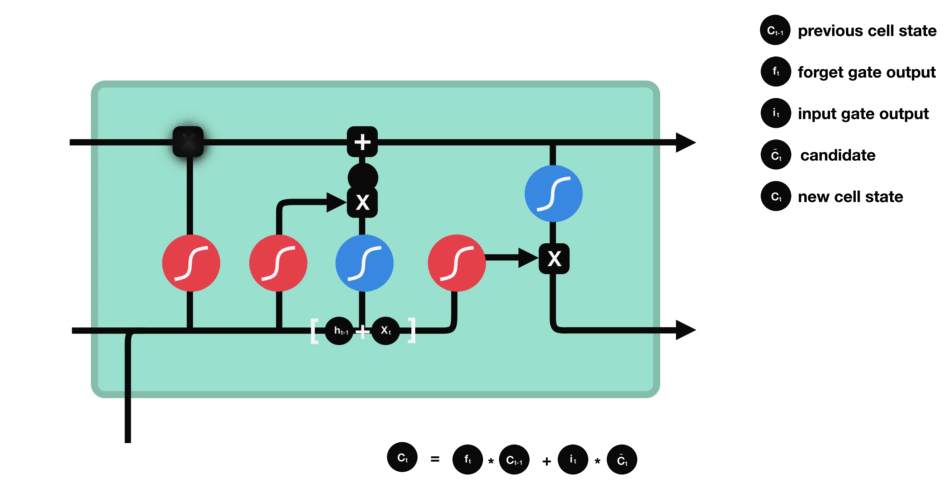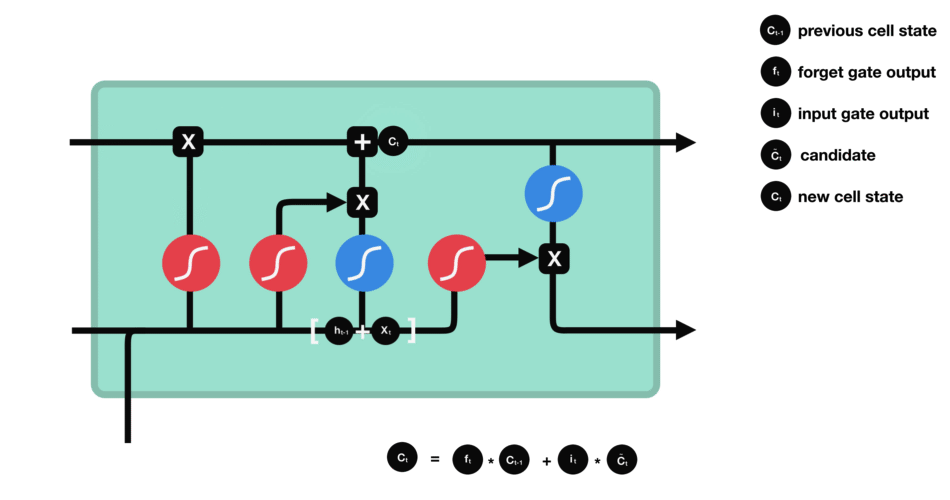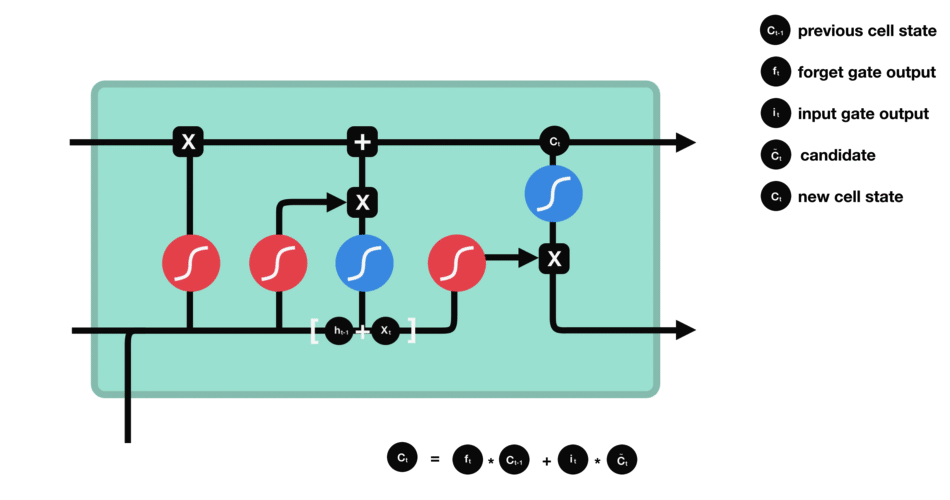
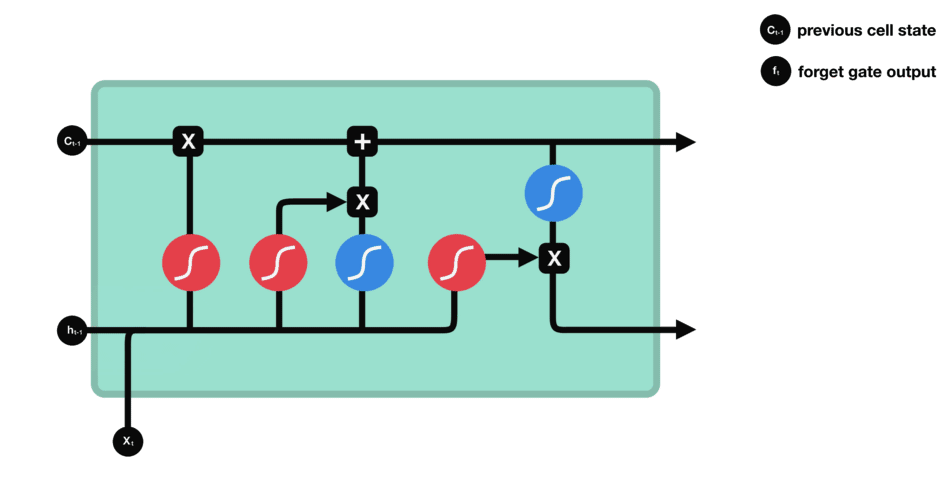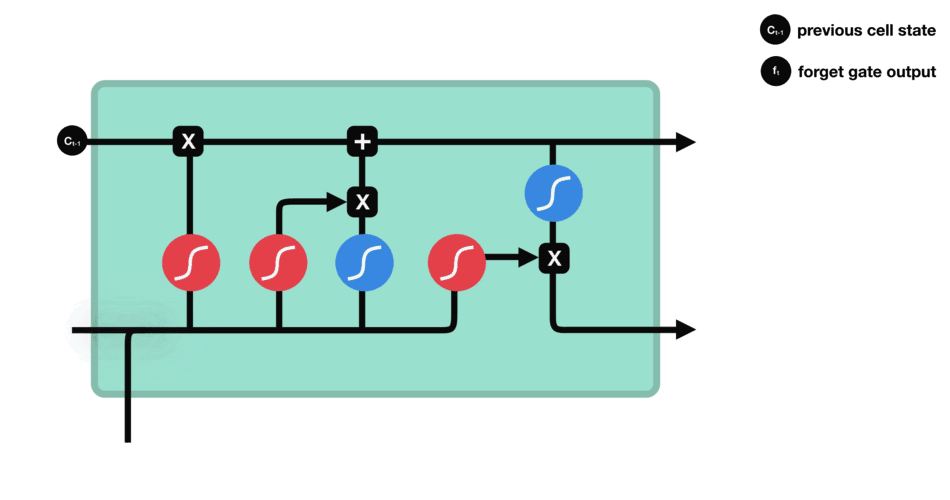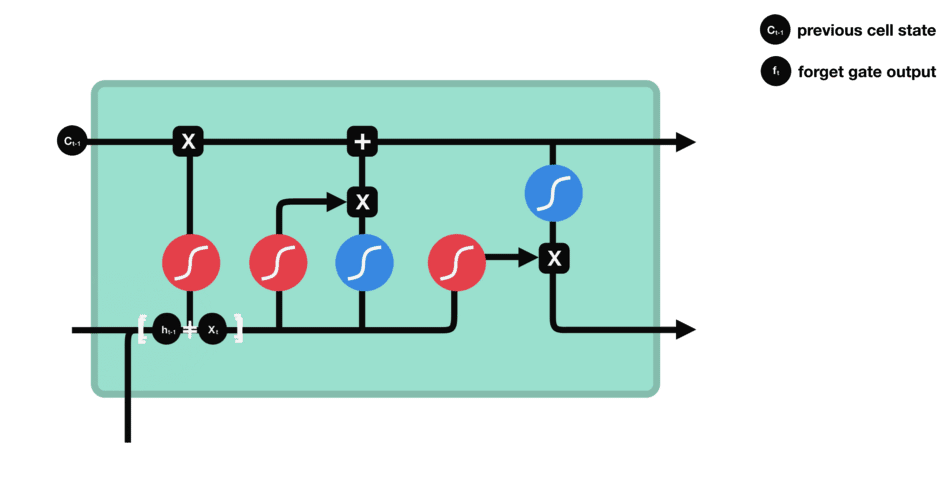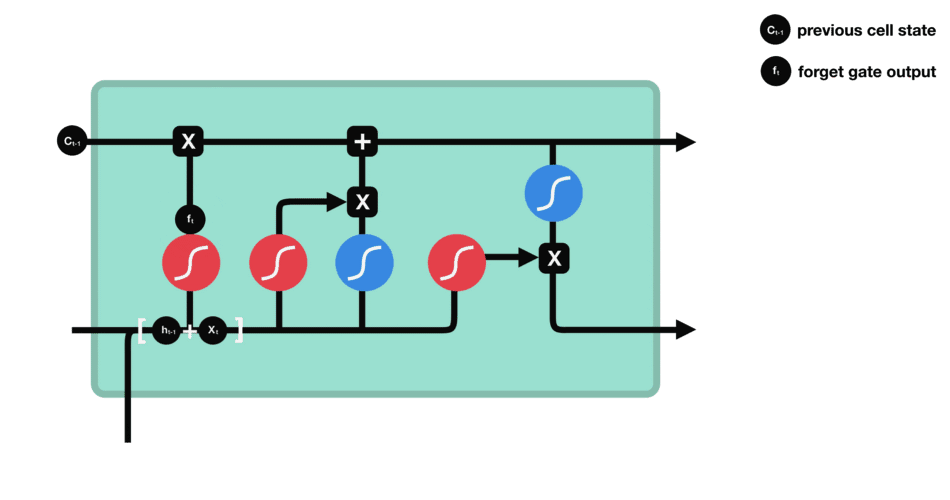
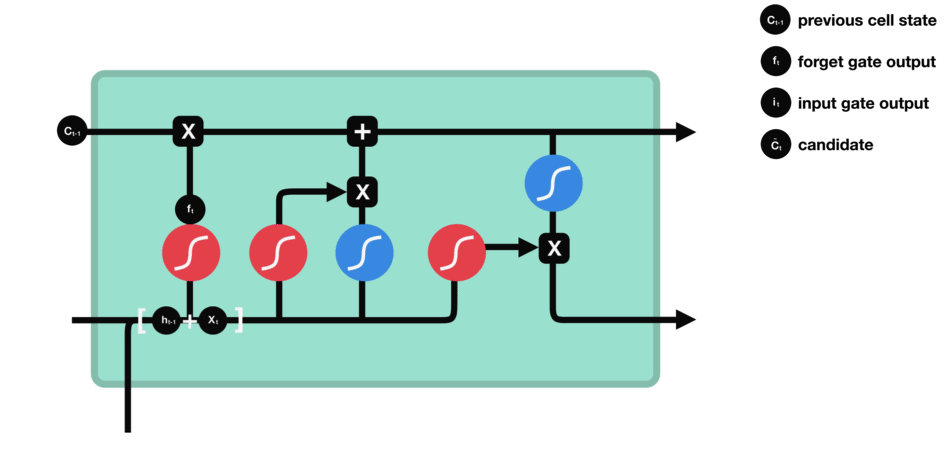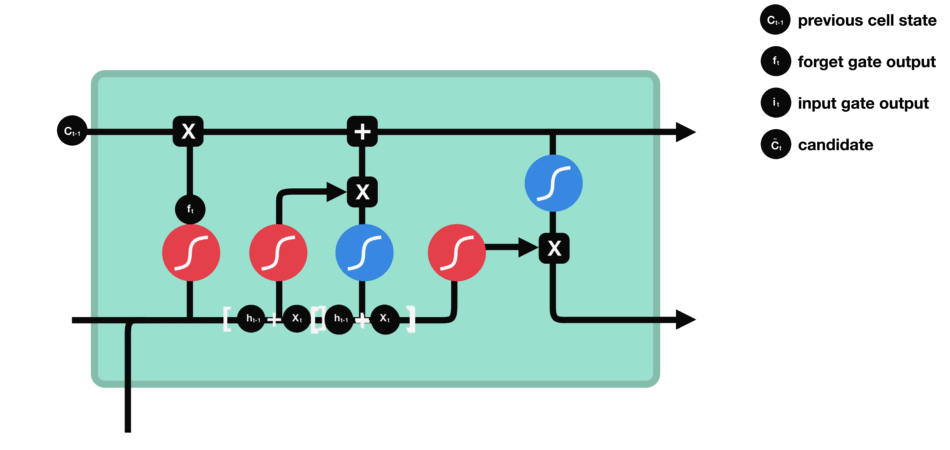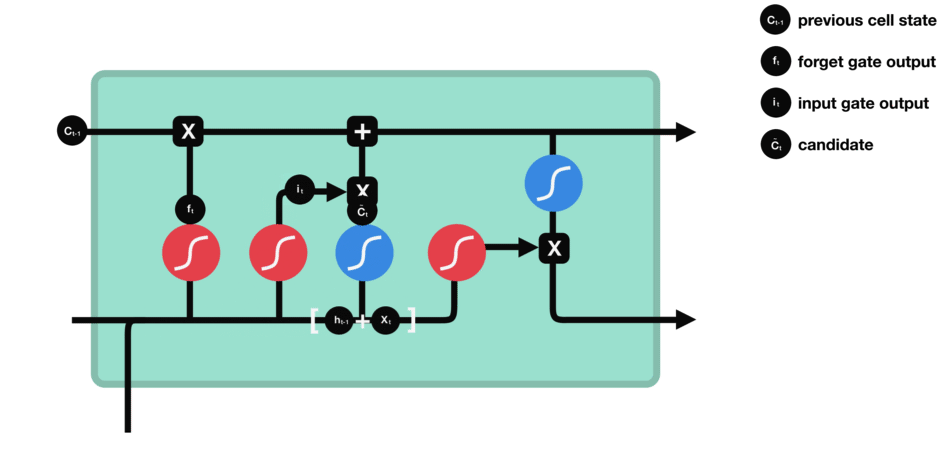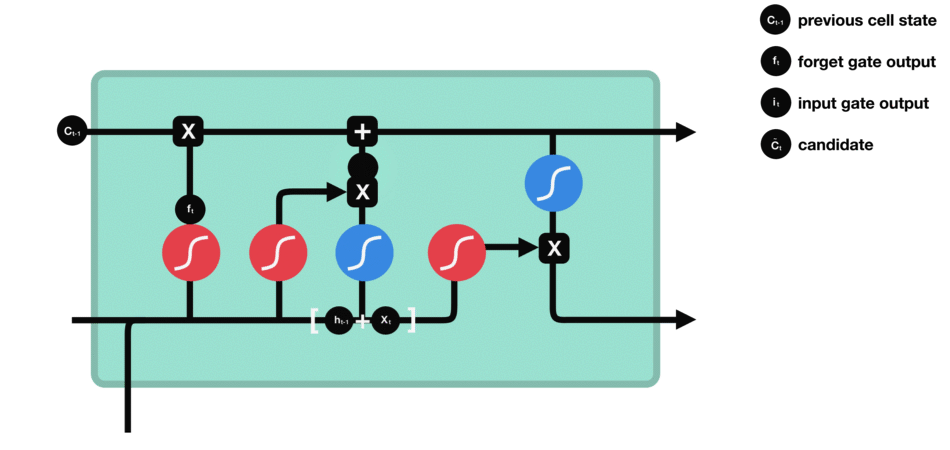
RNN的细胞结构图 如下:
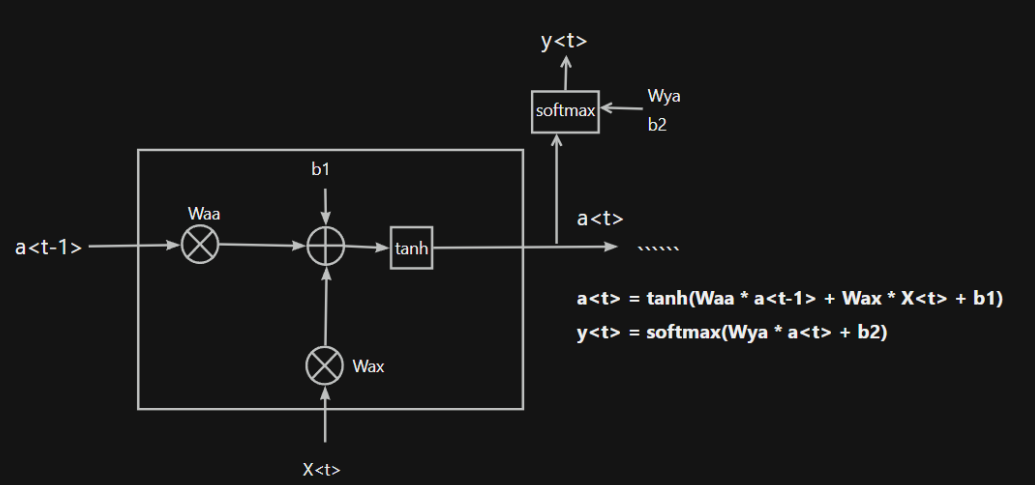
LSTM之所以能够胜任此任务,源于其为处理序列数据中长程依赖而生的精巧内部结构。一个LSTM单元包含三个关键的"门控"机制------遗忘门、输入门、输出门 ,以及一个贯穿始终的**"细胞状态"(Cell State)**,后者可以看作是模型的"长期记忆"。
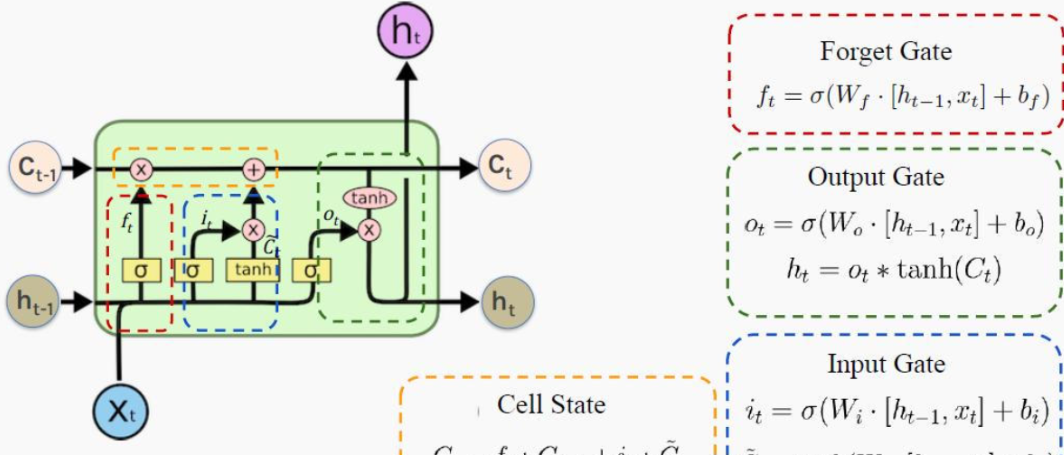
在ETA预测的语境下,这个工作流程可以被生动地解读:
-
细胞状态 :就像一条传送带,携带着路线已经过的部分的核心信息(比如"目前整体路况通畅"或"刚刚经历了一段严重拥堵")向前传递。
-
遗忘门 :当车辆从拥堵的市区主干道驶入通畅的高速公路时,遗忘门会决定"忘记"之前关于市区拥堵的细节信息,因为它对预测高速路段的通行时间已不再重要。
-
输入门 :当模型处理到一个新的路段时,输入门会判断这个路段的新信息(如实时路况显示为红色、限速60km/h)哪些是重要的,并决定将其更新到细胞状态中。
-
输出门 :基于当前的细胞状态(长期记忆)和当前路段的输入,输出门会计算出对当前路段通行时间的最佳预测,并更新传递给下一个时间步的"短期记忆"(隐藏状态)。
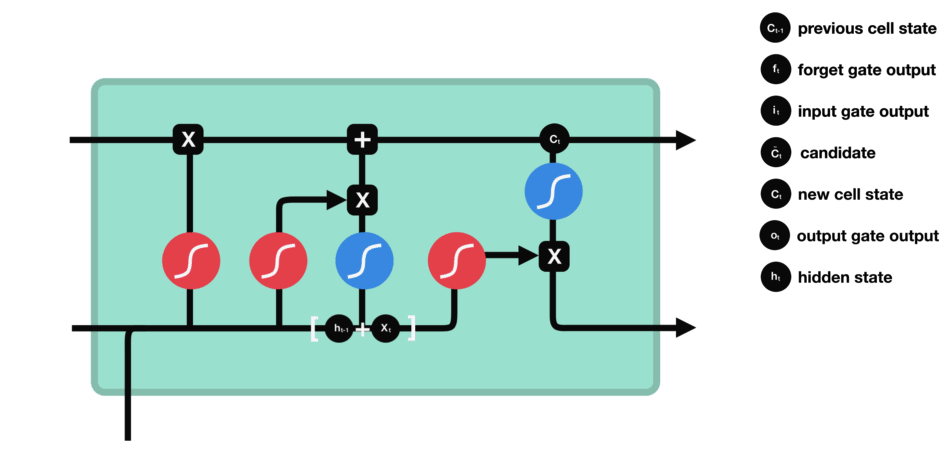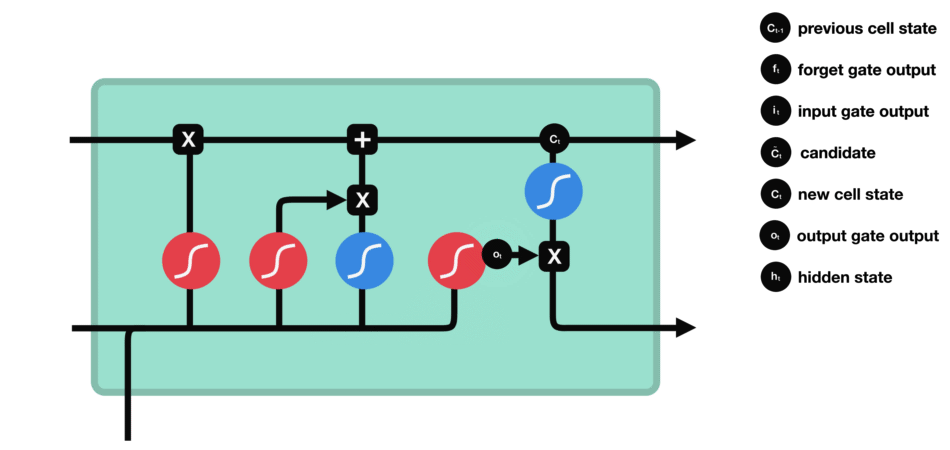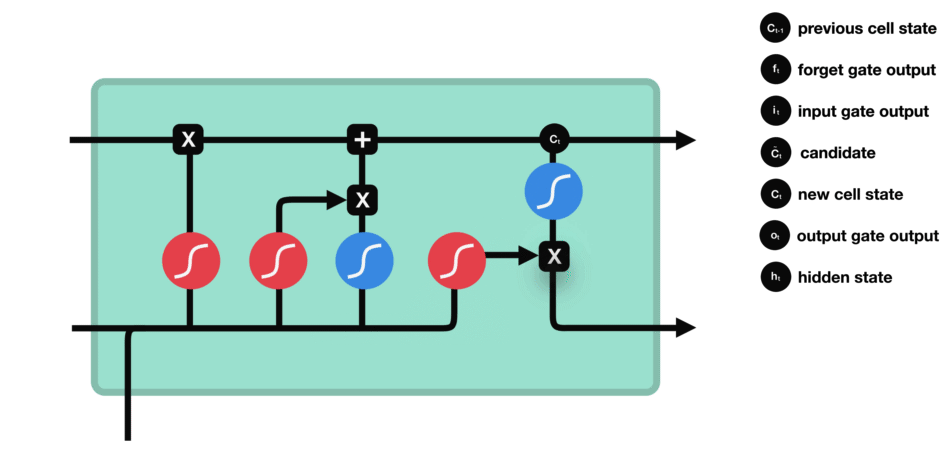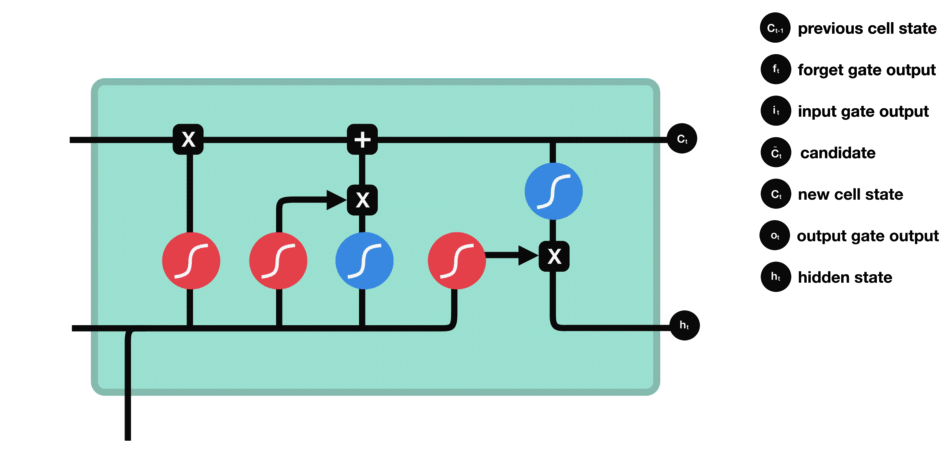
这种机制使得信息能够在整个路线序列中智能地流动。模型在预测第N个路段时,是基于前面所有N-1个路段的综合信息动态做出的,从而完美地捕捉了交通的传导效应。
代码示例:简化的LSTM模型预测下一路段通行时间
为了直观地展示这一思想,下面的代码使用TensorFlow/Keras构建了一个极其简化的LSTM模型。它演示了模型如何学习序列模式,即根据前两个路段的通行时间,来预测第三个路段的通行时间。在真实系统中,输入特征会是包含数十个维度的高维向量。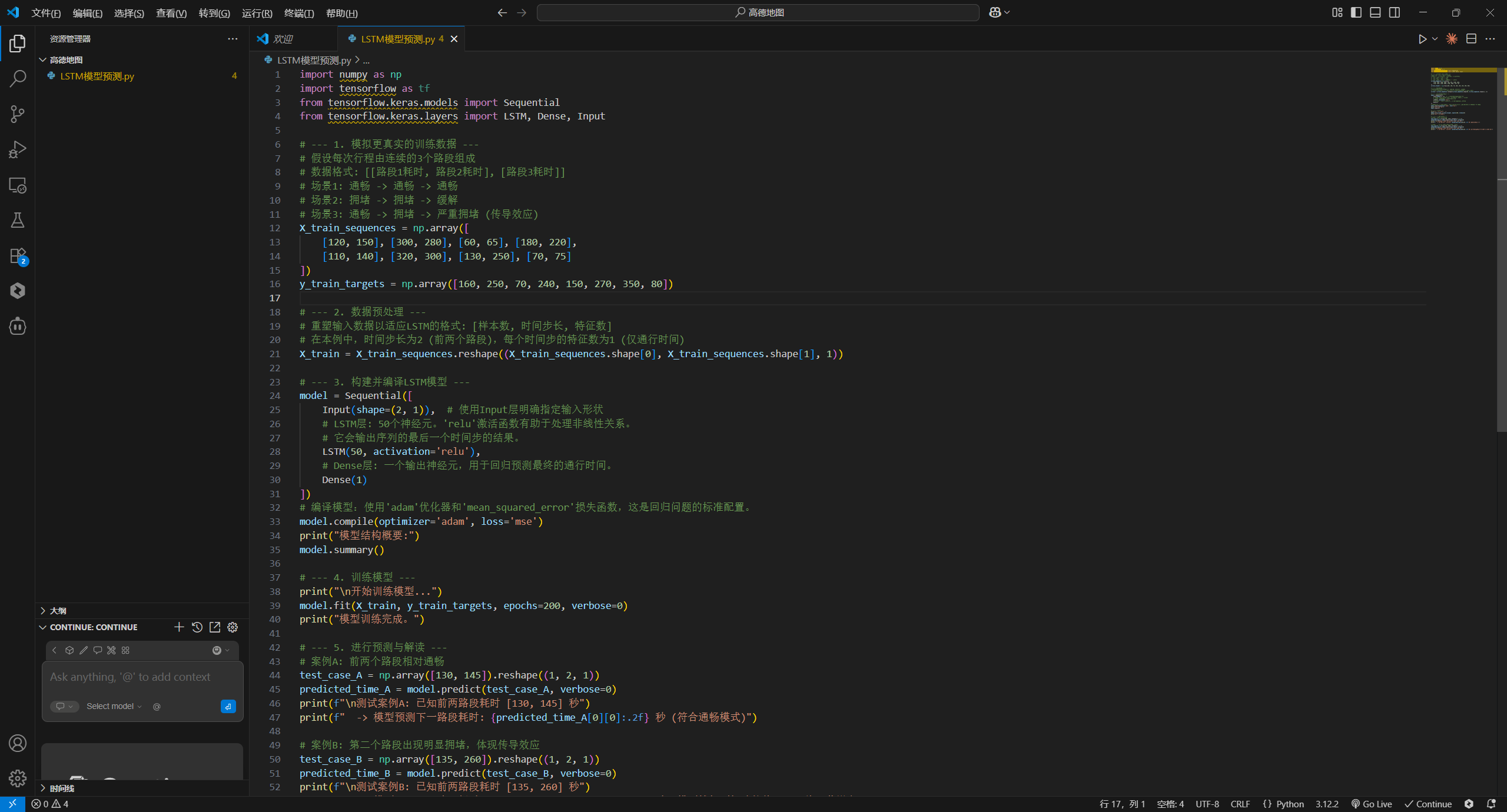
python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Input
# --- 1. 模拟更真实的训练数据 ---
# 假设每次行程由连续的3个路段组成
# 数据格式: [[路段1耗时, 路段2耗时], [路段3耗时]]
# 场景1: 通畅 -> 通畅 -> 通畅
# 场景2: 拥堵 -> 拥堵 -> 缓解
# 场景3: 通畅 -> 拥堵 -> 严重拥堵 (传导效应)
X_train_sequences = np.array([
[120, 150], [300, 280], [60, 65], [180, 220],
[110, 140], [320, 300], [130, 250], [70, 75]
])
y_train_targets = np.array([160, 250, 70, 240, 150, 270, 350, 80])
# --- 2. 数据预处理 ---
# 重塑输入数据以适应LSTM的格式: [样本数, 时间步长, 特征数]
# 在本例中,时间步长为2 (前两个路段),每个时间步的特征数为1 (仅通行时间)
X_train = X_train_sequences.reshape((X_train_sequences.shape[0], X_train_sequences.shape[1], 1))
# --- 3. 构建并编译LSTM模型 ---
model = Sequential([
Input(shape=(2, 1)), # 使用Input层明确指定输入形状
# LSTM层: 50个神经元。'relu'激活函数有助于处理非线性关系。
# 它会输出序列的最后一个时间步的结果。
LSTM(50, activation='relu'),
# Dense层: 一个输出神经元,用于回归预测最终的通行时间。
Dense(1)
])
# 编译模型:使用'adam'优化器和'mean_squared_error'损失函数,这是回归问题的标准配置。
model.compile(optimizer='adam', loss='mse')
print("模型结构概要:")
model.summary()
# --- 4. 训练模型 ---
print("\n开始训练模型...")
model.fit(X_train, y_train_targets, epochs=200, verbose=0)
print("模型训练完成。")
# --- 5. 进行预测与解读 ---
# 案例A: 前两个路段相对通畅
test_case_A = np.array([130, 145]).reshape((1, 2, 1))
predicted_time_A = model.predict(test_case_A, verbose=0)
print(f"\n测试案例A: 已知前两路段耗时 [130, 145] 秒")
print(f" -> 模型预测下一路段耗时: {predicted_time_A[0][0]:.2f} 秒 (符合通畅模式)")
# 案例B: 第二个路段出现明显拥堵,体现传导效应
test_case_B = np.array([135, 260]).reshape((1, 2, 1))
predicted_time_B = model.predict(test_case_B, verbose=0)
print(f"\n测试案例B: 已知前两路段耗时 [135, 260] 秒")
print(f" -> 模型预测下一路段耗时: {predicted_time_B[0][0]:.2f} 秒 (模型捕捉到拥堵趋势,预测值显著增高)")这个简单的例子揭示了核心思想:模型的预测结果不仅仅是基于输入值的简单平均或线性外推,而是基于它在训练数据中学到的序列模式。案例B的预测值远高于案例A,正是因为模型识别出了一个"拥堵正在加剧"的序列模式。在真实世界中,高德的ETA模型会融合路线的全局静态特征(如总长度、红绿灯总数)与LSTM对路段序列的动态预测,形成一个端到端的、高度精确的预测系统。
二、 宏观路网层:基于图神经网络的城市交通预测
单次ETA的精准预测解决了"点到点"的微观问题。然而,要实现真正意义上的智能交通,例如为全城用户进行最优的拥堵规避,甚至辅助交通管理部门进行信号灯优化和交通疏导,地图服务就必须具备对整个城市交通网络进行宏观预测的能力。城市路网是一种典型的图(Graph)结构 数据------路口是节点,道路是边。这种数据的拓扑关系复杂且不规则,是典型的非欧几里得空间数据,这超出了传统CNN等擅长处理规则网格数据(如图像)的模型的"能力圈"。
2.1 范式困境:从网格到图的挑战
在GNN兴起之前,宏观交通预测的一些尝试会将城市地图强行划分为规则的地理网格,然后统计每个网格内的车辆密度或平均速度,最后用CNN来预测未来每个网格的状态。这种方法的缺陷是显而易见的:
- 拓扑信息丢失:它完全破坏了道路网络内在的连通性。模型无法知道网格A和网格B之间是否有一条高容量的快速路,或者只是一条无法通行的小巷。
- 空间分辨率与计算成本的矛盾:网格划分得太粗,会丢失大量细节;划分得太细,则会导致数据极度稀疏和计算量爆炸。
2.2 范式革新:时空图卷积网络(STGCN)
图神经网络(Graph Neural Network, GNN) ,特别是图卷积网络(Graph Convolutional Network, GCN),为直接在图结构数据上进行深度学习提供了强大的数学工具。高德地图等行业先驱,将先进的**时空图卷积网络(Spatio-Temporal Graph Convolutional Network, STGCN)**应用于此领域,将交通预测问题置于其最自然的数学表达之上。
STGCN模型的核心是时空一体化建模,它通过精巧设计的网络层,同时捕捉两种相互交织的依赖关系:
-
空间依赖性(Spatial Dependency) :这是通过图卷积 实现的。图卷积的核心思想是**"消息传递"(Message Passing)或"邻居聚合"(Neighbor Aggregation)**。对于图中的每一个节点(路口),其新一层的特征表示,是通过聚合其所有邻居节点(与之直接相连的路口)的当前特征,并结合自身特征计算得出的。这个过程完美地模拟了物理世界的交通规律:一个路口的拥堵状况,正是由其所有相邻路口的车流汇入和流出情况共同决定的。通过堆叠多层图卷积,一个节点可以感知到其二阶、三阶乃至更远邻居的状态,从而学习到拥堵在复杂路网中的全局扩散模式。
-
时间依赖性(Temporal Dependency) :交通数据在时间维度上具有强烈的模式,如周期性(早晚高峰)、趋势性(节假日出城潮)。STGCN通过在图卷积层之间穿插时间卷积模块来捕捉这些模式。这些模块通常采用带门控机制的一维卷积(Gated Temporal Convolution)或GRU等循环单元。模型将过去一段时间(例如,过去60分钟,每5分钟一个快照)内所有节点的交通状态序列作为输入,时间卷积层能够学习到交通流量随时间演变的动态规律。
STGCN网络整体架构:
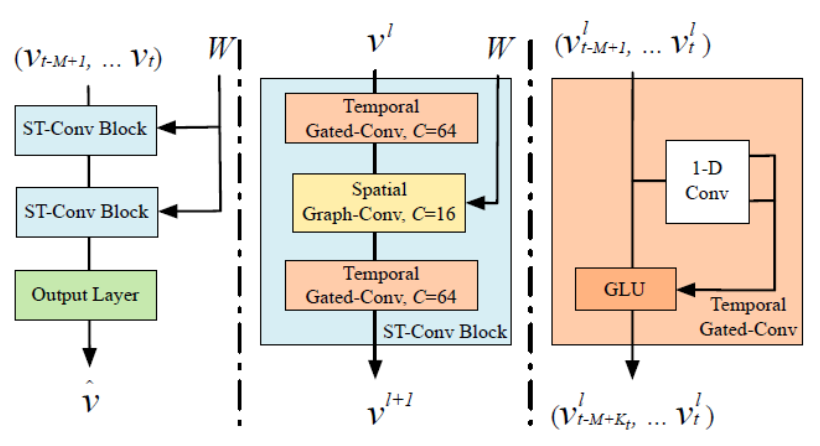
STGCN通过将"时空卷积块"(一个空间图卷积层 + 一个时间卷积层)作为基本单元进行堆叠,构建出能够同时理解"在哪个路口"和"在什么时间"发生的变化将如何影响整个路网未来的时空模型。
尤为关键的是,高德地图在其模型中引入了一个极具价值的、其他竞争者难以获得的专有数据维度:基于海量用户实时导航请求计算出的"未来意图流量"。系统能够通过分析当前所有正在使用高德导航的车辆规划的路径,提前预判在未来5分钟、10分钟、15分钟后,将有多少车辆计划汇集到某条特定道路上。将这一具有"上帝视角"的预见性特征,与STGCN强大的时空建模能力相结合,使得高德能够"预见"拥堵的形成,从而更早地为用户规划出能够真正"躲避未来拥堵"的路线,实现了从"被动响应当前拥堵"到"主动预测并规避未来拥堵"的智能化飞跃。
代码示例:使用NetworkX构建城市路网图结构
在应用GNN之前,首要任务是将路网数据结构化为图。下面的代码使用流行的networkx库,演示了这一基础但至关重要的一步。真实的路网图将包含数百万个节点和边。
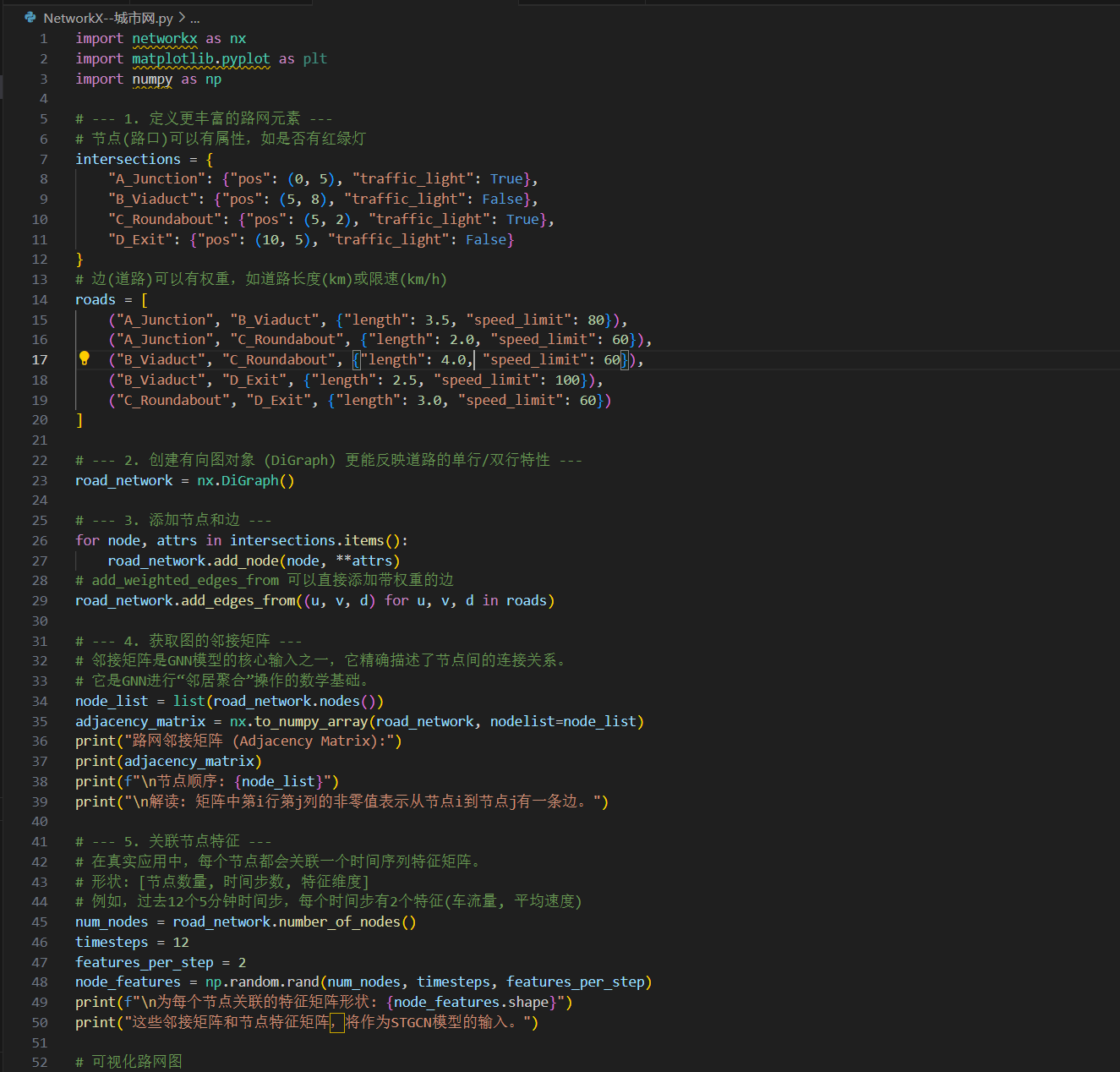
python
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
# --- 1. 定义更丰富的路网元素 ---
# 节点(路口)可以有属性,如是否有红绿灯
intersections = {
"A_Junction": {"pos": (0, 5), "traffic_light": True},
"B_Viaduct": {"pos": (5, 8), "traffic_light": False},
"C_Roundabout": {"pos": (5, 2), "traffic_light": True},
"D_Exit": {"pos": (10, 5), "traffic_light": False}
}
# 边(道路)可以有权重,如道路长度(km)或限速(km/h)
roads = [
("A_Junction", "B_Viaduct", {"length": 3.5, "speed_limit": 80}),
("A_Junction", "C_Roundabout", {"length": 2.0, "speed_limit": 60}),
("B_Viaduct", "C_Roundabout", {"length": 4.0, "speed_limit": 60}),
("B_Viaduct", "D_Exit", {"length": 2.5, "speed_limit": 100}),
("C_Roundabout", "D_Exit", {"length": 3.0, "speed_limit": 60})
]
# --- 2. 创建有向图对象 (DiGraph) 更能反映道路的单行/双行特性 ---
road_network = nx.DiGraph()
# --- 3. 添加节点和边 ---
for node, attrs in intersections.items():
road_network.add_node(node, **attrs)
# add_weighted_edges_from 可以直接添加带权重的边
road_network.add_edges_from((u, v, d) for u, v, d in roads)
# --- 4. 获取图的邻接矩阵 ---
# 邻接矩阵是GNN模型的核心输入之一,它精确描述了节点间的连接关系。
# 它是GNN进行"邻居聚合"操作的数学基础。
node_list = list(road_network.nodes())
adjacency_matrix = nx.to_numpy_array(road_network, nodelist=node_list)
print("路网邻接矩阵 (Adjacency Matrix):")
print(adjacency_matrix)
print(f"\n节点顺序: {node_list}")
print("\n解读: 矩阵中第i行第j列的非零值表示从节点i到节点j有一条边。")
# --- 5. 关联节点特征 ---
# 在真实应用中,每个节点都会关联一个时间序列特征矩阵。
# 形状: [节点数量, 时间步数, 特征维度]
# 例如,过去12个5分钟时间步,每个时间步有2个特征(车流量, 平均速度)
num_nodes = road_network.number_of_nodes()
timesteps = 12
features_per_step = 2
node_features = np.random.rand(num_nodes, timesteps, features_per_step)
print(f"\n为每个节点关联的特征矩阵形状: {node_features.shape}")
print("这些邻接矩阵和节点特征矩阵,将作为STGCN模型的输入。")
# 可视化路网图
# positions = nx.get_node_attributes(road_network, 'pos')
# edge_labels = {(u, v): d['length'] for u, v, d in road_network.edges(data=True)}
# nx.draw(road_network, positions, with_labels=True, node_color='skyblue', node_size=2500, font_weight='bold')
# nx.draw_networkx_edge_labels(road_network, positions, edge_labels=edge_labels)
# plt.title("More Detailed Urban Road Network Graph")
# plt.show()```
---三、 Foundational 数据层:基于混合分类模型的轨迹提纯
所有上层智能模型------无论是微观的ETA预测,还是宏观的交通预测------都建立在一个共同的、不容动摇的基础之上:高质量、纯净的输入数据。高德地图每日处理的轨迹数据规模已达亿万级别,这些由用户设备上传的GPS点构成了整个智能体系的"血液"。然而,原始的轨迹数据是混杂的、充满噪声的。它不仅包含了驾车用户的轨迹,还大量混入了步行、骑行、跑步,甚至是地铁、公交等多种模式的轨迹。如果不能对这些数据进行精确的清洗和分类,将会导致严重的**"数据污染"(Data Pollution)**。
这种污染的后果是灾难性的。试想一个场景:某条主干道因举办马拉松比赛而对机动车临时封闭。此时,成千上万的参赛者和观众会在这条路上产生密集的步行轨迹。如果系统无法区分这些轨迹的交通方式,它会错误地认为这条路"人声鼎沸、交通繁忙",甚至可能因为平均速度低而将其判断为"拥堵",从而继续向驾车用户推荐这条根本无法通行的路线。因此,准确的轨迹分类,是保证所有上层应用真实可靠的生命线,是整个智能体系的"免疫系统"。
3.1 挑战:标签稀疏与模式复杂性
轨迹分类面临两大核心技术挑战:
- 真值标签的极度稀疏:系统在收到一条轨迹时,几乎无法100%确定其真实的出行方式。虽然可以将用户的导航模式(如选择了"驾车导航")作为一种"弱标签"或"伪标签",但用户行为具有极大的不确定性。一个用户可能开着驾车导航步行去取车,或者在到达目的地后忘记关闭导航。依赖这种噪声巨大的标签来训练模型,效果可想而知。
- 出行模式的特征重叠:不同出行模式在某些场景下,其特征会高度相似。例如,在极度拥堵路段蠕行的汽车,其平均速度可能与步行无异;而高速行驶的电动自行车,其速度又可能与在市区低速行驶的汽车相当。外卖骑手在商圈内的复杂穿梭轨迹,在空间形态上也与寻找停车位的汽车轨迹有相似之处。
3.2 范式革新:统计学习与表示学习的互补"组合拳"
为了应对这些严峻的挑战,高德地图的算法工程师们并未押注于单一模型,而是采用了一套结合了传统统计学习和前沿深度学习优势的、互为补充的"组合拳"策略。
3.2.1 基于概率图模型的贝叶斯分类器
在模型构建的早期探索阶段,工程师们首先回归统计学本质,从轨迹中提取了横跨五大类的数百维人工统计特征,包括:
- 轨迹概况特征:总时长、总长度、首末点直线距离与轨迹长度比(弯曲度)等。
- 速度特征:最大速度、平均速度、速度标准差、各速度区间的时长占比等。
- 时间特征:推测的红灯等待总时长、掉头耗时等。
- 行为特征:掉头次数、急转弯次数等。
- 空间特征:轨迹点的空间聚集度(Gini系数)等。
在这些高维特征的基础上,利用高斯朴素贝叶斯(Gaussian Naive Bayes)分类器进行分类。贝叶斯方法的优势在于其明确的统计学意义和良好的可解释性。例如,通过分析特征的概率密度函数,可以清晰地看到,汽车轨迹的"最大速度"特征通常服从一个均值较高(如80km/h)的正态分布,而步行轨迹则服从一个均值极低(如8km/h)的正态分布。
然而,朴素贝叶斯有一个过强的"特征条件独立"假设(即认为平均速度和停顿比例之间没有关联),这与事实不符。为了解决这个问题,工程师们还通过构建更复杂的**贝叶斯网络(Bayesian Network)**来优化模型。贝叶斯网络允许定义特征之间的依赖关系,通过学习联合概率分布来建模,这有效解决了诸如"长距离骑行轨迹因总时长和总长度与驾车相似而被误判"的棘手问题。
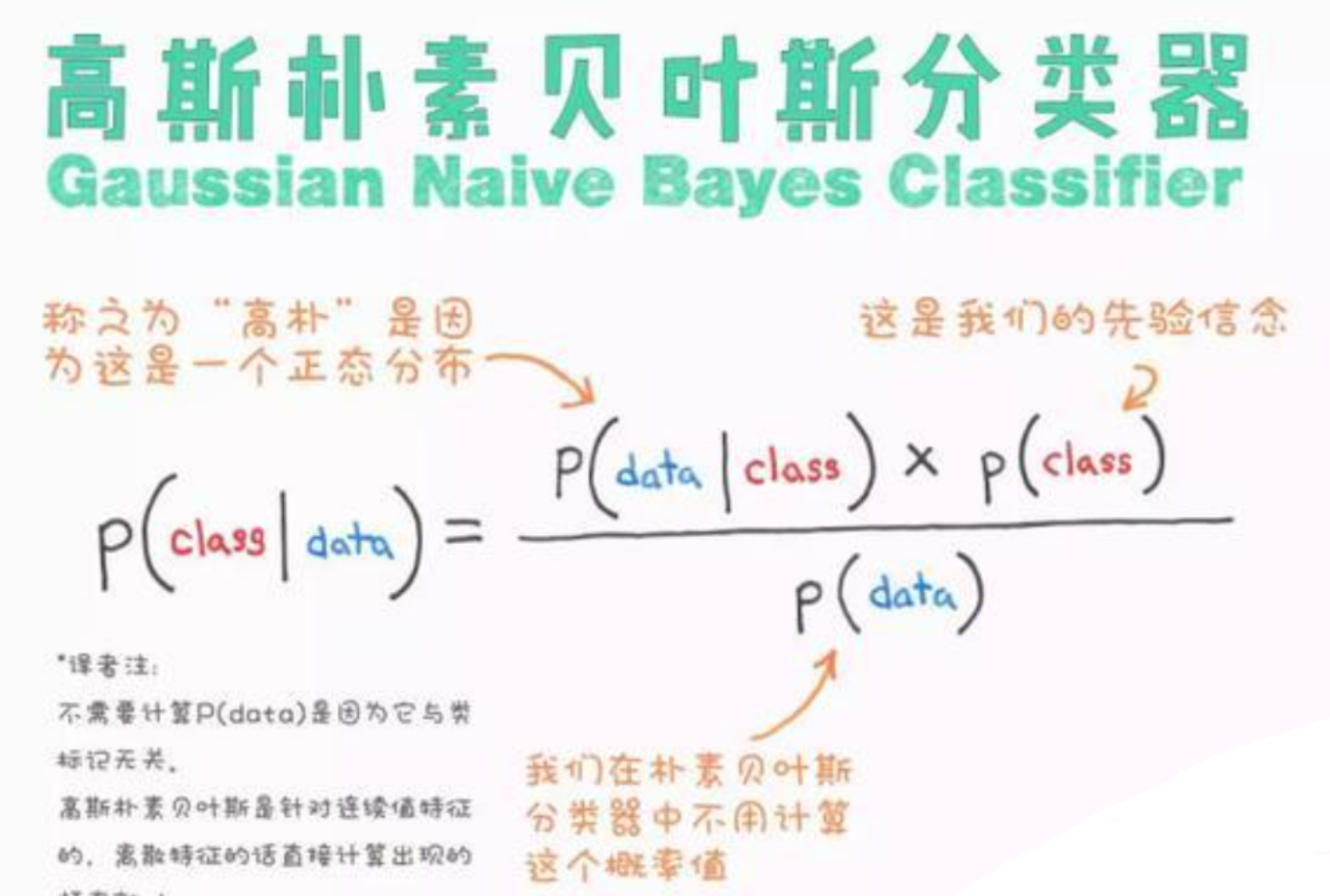
代码示例1:基于统计特征的贝叶斯分类器
此代码使用Scikit-learn,演示了如何基于轨迹的宏观统计特征来训练一个高斯朴素贝叶斯分类器,这是一个快速且有效的基线模型。
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
# --- 1. 模拟更丰富的轨迹统计特征数据 ---
data = {
'avg_speed_kmh': [45.2, 5.1, 60.5, 8.3, 30.1, 4.5, 25.8, 55.0, 15.3, 4.8, 18.2],
'stop_ratio': [0.1, 0.5, 0.05, 0.6, 0.2, 0.45, 0.25, 0.1, 0.3, 0.55, 0.28],
'straightness': [0.95, 0.8, 0.98, 0.7, 0.9, 0.75, 0.92, 0.96, 0.85, 0.65, 0.88], # 轨迹弯曲度
'mode': ['driving','walking','driving','walking','driving','walking','driving','driving','cycling','walking','cycling']
}
df = pd.DataFrame(data)
# --- 2. 准备特征(X)和标签(y) ---
X = df[['avg_speed_kmh', 'stop_ratio', 'straightness']]
y = df['mode']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# --- 3. 训练高斯朴素贝叶斯模型 ---
# 该模型对每个类别,独立地估计每个特征的均值和方差,然后使用贝叶斯定理进行预测。
model = GaussianNB()
model.fit(X_train, y_train)
# --- 4. 评估模型性能 ---
y_pred = model.predict(X_test)
print("模型分类报告:")
print(classification_report(y_test, y_pred))
# --- 5. 预测新轨迹 ---
new_trajectory = [[28.5, 0.22, 0.91]] # 特征介于driving和cycling之间
predicted_mode = model.predict(new_trajectory)[0]
predicted_proba = model.predict_proba(new_trajectory)
print(f"\n新轨迹 {new_trajectory} 被预测为: {predicted_mode}")
print(f"预测的概率分布: {list(zip(model.classes_, predicted_proba[0]))}")3.2.2 基于表示学习的CNN分类器
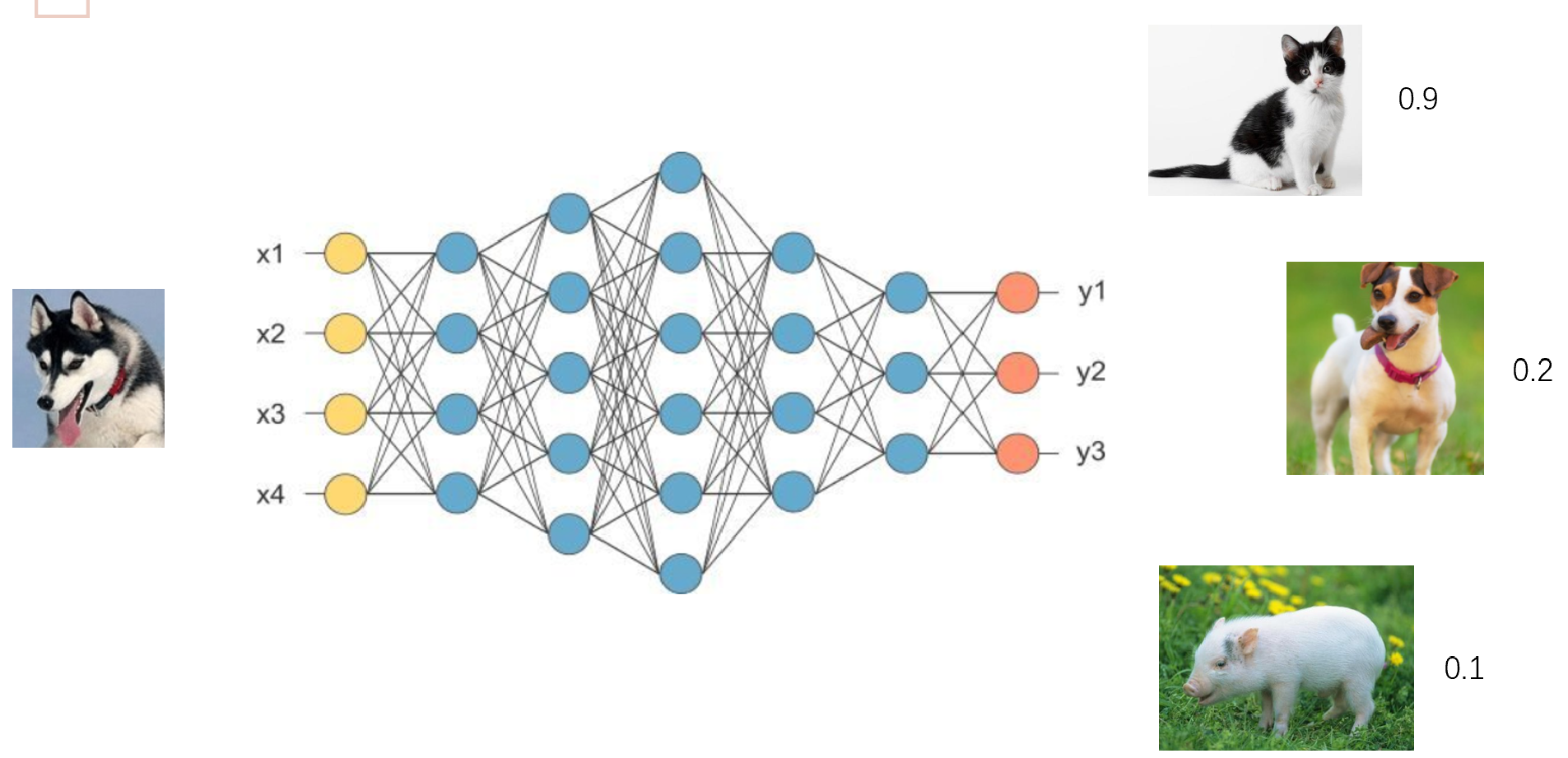
为了突破人工特征的天花板,充分发挥深度学习自动提取层次化特征的强大能力,高德的工程师们提出了一种极具创意的 "轨迹图像化"(Trajectory-as-an-Image) 方法。该方法的核心思想是将一个本质上是一维时序数据的轨迹,巧妙地 "升维"**并转换为一张二维图像,从而将轨迹分类问题转化为一个计算机视觉领域已经研究得非常透彻的图像分类问题。
这个转换过程大致如下:
- 空间投影:将轨迹的所有GPS点(经纬度坐标)进行归一化处理后,投影到一个固定大小的二维画布(例如64x64像素)上,形成轨迹的黑白空间形态骨架。
- 动态信息编码:将轨迹的动态属性,如每个点的瞬时速度、加速度、方向角(bearing)等,进行归一化,并将这些值编码为像素的颜色和亮度。例如,可以使用图像的RGB三个通道,分别编码速度、加速度和方向角。这样,一个高速行驶的直线轨迹点可能显示为亮红色,一个低速转弯的点可能显示为暗蓝色。
通过这种变换,一条轨迹就从一串枯燥的坐标数字,变成了一张蕴含丰富时空信息的"指纹图"。高速、平滑的驾车轨迹在图上可能呈现为一条色彩渐变均匀的平滑曲线;而外卖骑手在商圈内的轨迹则可能呈现为一个色彩斑驳、路径交错的复杂色块。
接下来,便可以利用在图像识别领域取得巨大成功的卷积神经网络(CNN) (如ResNet, VGG等)来对这些轨迹图进行分类。CNN的多层卷积核能够自动、分层次地学习和捕捉轨迹在空间分布上的各种模式:浅层卷积核可能学习到"直线"、"转角"等基本元素,深层卷积核则能学习到"沿主干道行驶"、"在小范围内穿梭"等更高级的语义模式。这种端到端的"表示学习"(Representation Learning)方法,完全摆脱了对人工特征的依赖,能够发现更多人类难以察觉的、隐藏在数据中的分类依据,作为对贝叶斯模型的有力补充和交叉验证。
代码示例2:轨迹图像化方法的概念
下面的伪代码描述了将轨迹转换为图像,以便使用CNN处理的根本思路,展示了信息编码的核心逻辑。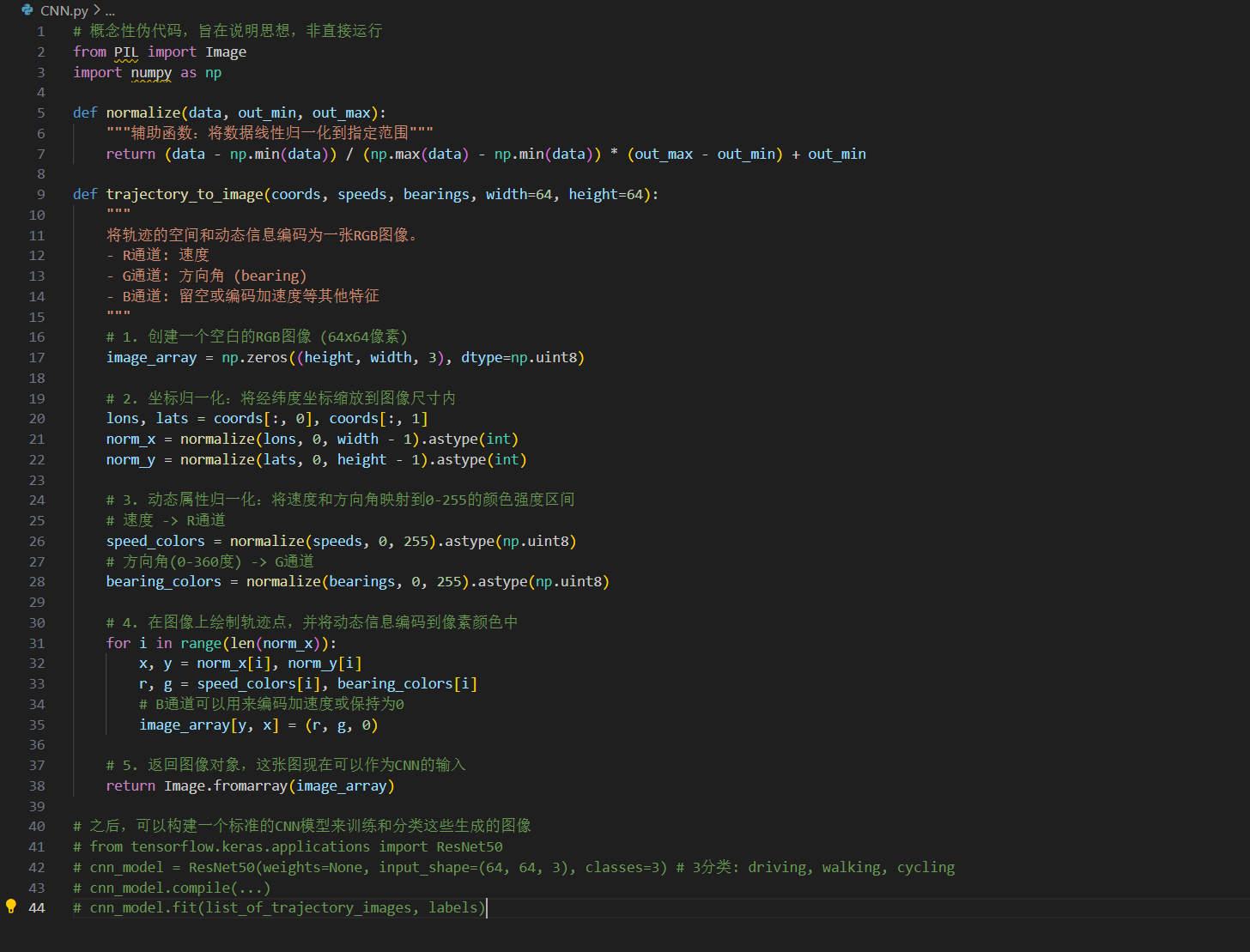
python
# 概念性伪代码,旨在说明思想,非直接运行
from PIL import Image
import numpy as np
def normalize(data, out_min, out_max):
"""辅助函数:将数据线性归一化到指定范围"""
return (data - np.min(data)) / (np.max(data) - np.min(data)) * (out_max - out_min) + out_min
def trajectory_to_image(coords, speeds, bearings, width=64, height=64):
"""
将轨迹的空间和动态信息编码为一张RGB图像。
- R通道: 速度
- G通道: 方向角 (bearing)
- B通道: 留空或编码加速度等其他特征
"""
# 1. 创建一个空白的RGB图像 (64x64像素)
image_array = np.zeros((height, width, 3), dtype=np.uint8)
# 2. 坐标归一化:将经纬度坐标缩放到图像尺寸内
lons, lats = coords[:, 0], coords[:, 1]
norm_x = normalize(lons, 0, width - 1).astype(int)
norm_y = normalize(lats, 0, height - 1).astype(int)
# 3. 动态属性归一化:将速度和方向角映射到0-255的颜色强度区间
# 速度 -> R通道
speed_colors = normalize(speeds, 0, 255).astype(np.uint8)
# 方向角(0-360度) -> G通道
bearing_colors = normalize(bearings, 0, 255).astype(np.uint8)
# 4. 在图像上绘制轨迹点,并将动态信息编码到像素颜色中
for i in range(len(norm_x)):
x, y = norm_x[i], norm_y[i]
r, g = speed_colors[i], bearing_colors[i]
# B通道可以用来编码加速度或保持为0
image_array[y, x] = (r, g, 0)
# 5. 返回图像对象,这张图现在可以作为CNN的输入
return Image.fromarray(image_array)
# 之后,可以构建一个标准的CNN模型来训练和分类这些生成的图像
# from tensorflow.keras.applications import ResNet50
# cnn_model = ResNet50(weights=None, input_shape=(64, 64, 3), classes=3) # 3分类: driving, walking, cycling
# cnn_model.compile(...)
# cnn_model.fit(list_of_trajectory_images, labels)通过这套"传统+现代"、"统计+表示"的混合分类系统,高德地图建立起了一道坚固的数据防火墙。它如同一个高精度的、多级串联的过滤器,确保了流入上层ETA和交通预测模型的数据是纯净可靠的,为整个宏伟的智能体系的稳定性与准确性提供了最坚实的Foundational保障。
四、 交互与决策层:基于大语言模型的空间智能体
在前三个层次,深度学习为高德地图构建了强大的对物理世界交通系统的 "感知" (通过轨迹分类)和 ** "预测" (通过ETA和交通预测)能力。然而,如何将这些强大但深藏于后台的能力,以一种更自然、更强大、更符合人类认知习惯的方式提供给用户,是通往真正"智能"的最后一公里。随着以GPT为代表的大语言模型(LLM)技术的成熟,人机交互的范式正在经历一场从图形界面(GUI)的点击操作,到自然语言对话式交互的根本性革命。高德地图敏锐地捕捉到了这一历史性机遇,将其AI战略推向了一个全新的高度:构建"空间智能体"(Spatial Agent)**。
4.1 范式困境:从执行指令到理解意图
传统的地图应用,无论功能多么强大,其本质上仍然是一个被动的**"工具"。它忠实地执行用户通过点击和输入框下达的、结构化的、明确的指令(例如,"导航去北京南站")。但它无法理解用户更复杂、更模糊、更接近人类日常交流的真实"意图"**。例如,一个用户心中模糊的想法可能是:"这个周末天气不错,我想在北京找个地方,能让老人轻松地散散步,又能让孩子玩得开心,最好人别太多,开车过去一个小时内能到。"
对于传统地图,用户必须自己将这个复杂的意图"翻译"成一连串的、独立的、机械的操作:
- 搜索"公园",在结果中逐个查看评价和图片。
- 搜索"亲子乐园",再进行一轮筛选。
- 将几个备选地点分别设为目的地,查看导航时间。
- 在多个APP之间切换,查询天气、开放时间等。
这个过程是繁琐、低效且充满心智负担的。
4.2 范式革新:以LLM为核心的"理解-推理-行动"循环
高德推出的业内首个专精出行生活的智能体"小高老师",其核心是一个经过海量出行领域数据和指令精调(Instruction Fine-Tuning)的大语言模型。它扮演的不再是被动的工具,而是一个能够进行复杂任务规划的**"决策大脑"或"行动中枢"。其工作流程遵循一个在AI Agent领域经典的 "理解-推理-行动"(Understand-Reason-Act)**循环。
-
理解(Understand) :当接收到用户用自然语言提出的模糊请求时,智能体的第一步是利用LLM强大的自然语言理解(NLU)和意图识别能力,将这段话分解为一系列结构化的、可执行的约束条件和子任务。例如,从"周末带老人小孩去北京玩,清净点,车程1小时内",LLM会解析出:
时间=本周末,地点=北京,人群=老人, 小孩,偏好=清净,交通约束=驾车时长<60分钟。 -
推理与工具调用(Reason & Act) :这是智能体的核心所在。LLM本身并不直接存储或计算实时路况、POI信息等事实性数据,这样做会使其信息迅速过时且容易"幻觉"。相反,它被训练成一个卓越的**"推理引擎"和 "任务编排器"。它会根据上一步分解出的子任务,智能地选择并调用高德后台封装好的各种原子能力,这些能力被称为"工具"(Tools)或API**。
- 这个"工具箱"里应有尽有,其中就包括了前文述及的ETA预测模型、实时路况预测服务、POI检索引擎、路线规划引擎,还包括天气查询、酒店/门票预订、用户评价分析等近百种服务。
- 推理过程是多轮的、动态的。例如,LLM可能会先调用
find_pois(city="北京", keywords=["公园", "亲子", "人少"]),得到一个候选列表。然后,它会对列表中的每个地点,循环调用plan_route(origin="用户当前位置", destination="候选地点", mode="driving")来获取预估的ETA。如果发现某个地点的ETA超过了60分钟,它会在内部的"思考"链条中将其剔除。它甚至可以进一步调用get_poi_reviews(poi_name, keyword="老人")来分析用户评价,确认该地是否真的适合老年人。
-
行动与生成(Act & Generate):在经过可能的多轮、复杂的工具调用和内部推理之后,智能体已经收集并筛选了所有必要的信息。最后一步,它会利用LLM强大的自然语言生成(NLG)能力,将所有这些碎片化的、结构化的数据,重新组织、润色,并以一种逻辑清晰、图文并茂、极富亲和力的多模态方式,向用户呈现一个完整的、可执行的解决方案。这可能是一个包含每日行程安排、多个备选方案、路线概览卡片和温馨提示的完整页面。
至此,智能体完成了从理解用户模糊意图,到规划复杂任务,再到交付最终行动方案的完整闭环。
代码示例:空间智能体工作流程的简化模拟
以下Python代码通过一个面向对象的框架,更清晰地模拟了智能体接收用户请求后,如何进行思考、选择工具、执行并最终生成回复的完整流程。
python
import numpy as np
import json
# --- 1. 模拟后端工具箱 (APIs) ---
class ToolBox:
def find_pois(self, city, keywords, user_preference):
print(f" [工具调用 find_pois] 参数: city='{city}', keywords='{keywords}', pref='{user_preference}'")
# 模拟数据库查询
all_pois = {
"世纪公园": {"tags": ["公园", "亲子"], "crowd_level": 8, "suitable_for": ["老人", "小孩"]},
"森林公园": {"tags": ["公园", "自然"], "crowd_level": 5, "suitable_for": ["老人"]},
"欢乐谷": {"tags": ["乐园", "亲子"], "crowd_level": 9, "suitable_for": ["小孩"]}
}
results = []
for name, data in all_pois.items():
if all(k in data["tags"] for k in keywords) and data["crowd_level"] < (6 if user_preference == "清净" else 10):
results.append({"name": name, "data": data})
return json.dumps(results)
def plan_route(self, origin, destination, mode="driving"):
print(f" [工具调用 plan_route] 参数: origin='{origin}', dest='{destination}'")
# 模拟调用底层的ETA预测模型
eta_minutes = np.random.randint(20, 90)
return json.dumps({"route_summary": f"从{origin}到{destination}的推荐路线", "eta_minutes": eta_minutes})
# --- 2. 智能体核心逻辑 ---
class SpatialAgent:
def __init__(self):
self.toolbox = ToolBox()
# 在真实场景中,这里会是一个与大语言模型交互的客户端
print("空间智能体已初始化。")
def llm_reasoning_and_tool_use(self, prompt):
# 这是对LLM"思考"过程的高度简化模拟
# Step 1: LLM解析意图
thought = "用户想在北京找个适合老人和小孩的、人少的公园,且车程要在1小时内。我需要先找POI,再检查路程。"
print(f"[智能体思考] {thought}")
# Step 2: LLM决定调用第一个工具
tool_call_1 = {"tool_name": "find_pois", "parameters": {"city": "北京", "keywords": ["公园", "亲子"], "user_preference": "清净"}}
print(f"[智能体决策] 准备调用工具: {tool_call_1}")
poi_results_str = getattr(self.toolbox, tool_call_1["tool_name"])(**tool_call_1["parameters"])
poi_results = json.loads(poi_results_str)
# Step 3: LLM分析工具返回结果,并进行下一步决策
thought = f"find_pois返回了{len(poi_results)}个结果: {[p['name'] for p in poi_results]}。现在我需要逐个检查它们的车程。"
print(f"[智能体思考] {thought}")
final_candidates = []
for poi in poi_results:
tool_call_2 = {"tool_name": "plan_route", "parameters": {"origin": "用户当前位置", "destination": poi["name"]}}
print(f"[智能体决策] 准备调用工具: {tool_call_2}")
route_info_str = getattr(self.toolbox, tool_call_2["tool_name"])(**tool_call_2["parameters"])
route_info = json.loads(route_info_str)
if route_info["eta_minutes"] <= 60:
thought = f"'{poi['name']}'的车程是{route_info['eta_minutes']}分钟,符合要求,加入候选列表。"
print(f"[智能体思考] {thought}")
final_candidates.append({"poi": poi, "route": route_info})
else:
thought = f"'{poi['name']}'的车程是{route_info['eta_minutes']}分钟,超过1小时,排除。"
print(f"[智能体思考] {thought}")
return final_candidates
def generate_final_response(self, candidates):
# Step 4: LLM基于最终信息,生成自然语言回复
if not candidates:
return "非常抱歉,根据您的要求(特别是车程1小时内且人少),暂时没有找到完全匹配的地点。或许放宽一些条件可以有更多选择哦。"
best_choice = candidates[0]
response = f"为您精心规划了周末出行方案!\n\n" \
f"🌟 **首选推荐:{best_choice['poi']['name']}**\n" \
f" - **特点**: {', '.join(best_choice['poi']['data']['tags'])}. 特别适合{', '.join(best_choice['poi']['data']['suitable_for'])}。\n" \
f" - **拥挤度**: 相对较低,可以享受一个宁静的周末。\n" \
f" - **交通**: 从您当前位置出发,预计驾车 **{best_choice['route']['eta_minutes']}分钟** 即可到达。\n\n" \
f"我已经为您准备好了导航路线,随时可以出发!"
return response
def run(self, user_prompt):
print(f"\n--- 开始处理新请求 ---")
print(f"用户请求: '{user_prompt}'")
# 核心:调用LLM进行推理和工具使用
candidates = self.llm_reasoning_and_tool_use(user_prompt)
# 生成最终回复
final_response = self.generate_final_response(candidates)
print("\n--- 智能体最终回复 ---")
print(final_response)
print("--- 请求处理完毕 ---\n")
# 运行智能体
agent = SpatialAgent()
agent.run("周末想在北京找个适合带老人和小孩玩的公园,要清净点,开车别超过一小时")结论:一个面向未来的整合式智能系统
通过对高德地图深度学习架构的四个层次的穿透式解构,我们可以清晰地看到一条从数据智能 到感知智能 ,再到认知智能的清晰演进路径。这四个层次并非孤立的技术模块,而是一个高度耦合、相互依存、层层递进的整合式智能系统:
- Foundational 数据层是基石,其轨迹分类的准确性直接决定了上层模型的输入质量。
- 微观与宏观预测层是系统的核心感知引擎,它们利用序列模型和图模型,分别在个体和群体尺度上,赋予了地图理解和预测物理世界交通状态的能力。
- 交互与决策层是智能的最终出口,它利用大语言模型作为"中央大脑",将底层强大的、但对用户不可见的感知与预测能力,转化为能够理解人类意图、主动规划复杂任务并与之进行自然语言对话的、富有智慧的认知能力。
深度学习已经不再是散落在高德地图各个功能点上的"优化插件",而是已经成为重构整个导航服务之核的、无处不在的底层操作系统 。它不仅在技术层面解决了诸多传统方法难以逾越的难题,更在产品哲学上推动了一场深刻的变革------地图服务的目标,不再仅仅是满足用户已经明确的出行需求,而是开始主动预测、引导并创造更美好、更便捷、更高效的出行与生活体验。
未来的地图,将不再是一个我们低头查看的、冰冷的二维工具。它将是一个我们与之对话、能够主动理解我们所处的复杂时空环境、并为我们提供最优决策的认知伙伴(Cognitive Companion)。高德地图通过其系统性的深度学习架构实践,不仅为我们展示了这一未来图景的清晰样貌,更在坚实地铺就通往这一未来的道路。