Attention注意力机制:原理、实现与优化全解析
在深度学习处理序列数据(如文本、语音、时序信号)的过程中,传统循环神经网络(RNN)和卷积神经网络(CNN)存在明显局限:RNN难以并行计算且长序列下信息传递衰减,CNN则对长距离依赖捕捉能力较弱。Attention注意力机制的出现突破了这一瓶颈,其核心思想是让模型在处理序列时"有的放矢"------通过学习输入序列不同部分的重要性权重,对关键信息进行显式加权,从而高效聚焦与输出相关的内容。本文将从Attention的基础原理出发,逐步深入Transformer中的应用、计算复杂度优化、KV缓存技术,以及MHA、GQA、MLA等变体,最后介绍DCA、S2-Attention等长上下文优化方案。
1. Attention机制基础:核心思想与计算逻辑
1.1 核心思想:聚焦"重要信息"
Attention机制的本质是动态权重分配:在处理序列数据时,模型无需对所有输入token一视同仁,而是通过计算"相关性"(即注意力权重),让输出更依赖于对当前任务更重要的输入部分。例如,在机器翻译中,将"我爱中国"译为"I love China"时,模型应让"爱"的输出更关注输入的"爱",而非"我"或"中国"。
对比传统模型:
- RNN/GRU/LSTM:按顺序处理序列,每个时刻的隐藏态依赖前一时刻,长序列下易出现"梯度消失",且无法并行计算;
- CNN:通过卷积核捕捉局部特征,需堆叠多层才能覆盖长距离依赖,效率较低;
- Attention:直接计算序列中任意两个token的相关性,并行性强,且能显式建模长距离依赖。
1.2 Scaled Dot-Product Attention:标准计算范式
Transformer中最核心的Attention形式是Scaled Dot-Product Attention(缩放点积注意力),其计算公式与计算流程如下:
1.2.1 核心公式
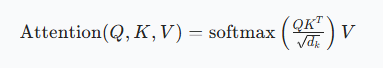
其中:
- (Q)(Query,查询):当前任务需要"寻找的信息"(如解码器生成某个token时的查询向量);
- (K)(Key,键):输入序列中"包含的信息"(如编码器每个token的特征向量);
- (V)(Value,值):需要被加权聚合的信息(通常与(K)来自同一序列,维度可与(K)不同);
- (d_k):(Q)和(K)的维度;
- (\sqrt{d_k}):缩放因子,用于解决维度增大时(QK^T)数值过大导致softmax梯度消失的问题。
1.2.2 计算流程
- 生成Q、K、V:通过线性层将输入序列的嵌入向量(含位置编码)分别映射为Q、K、V;
- 计算注意力分数 :对Q和(KT)做矩阵乘法,得到每个Query与所有Key的相关性分数((QKT));
- 缩放:将分数除以(\sqrt{d_k}),避免数值过大;
- 掩码(可选):对不需要关注的位置(如Decoder中的未来token)填充"-∞",确保模型不利用未来信息;
- 归一化:通过softmax将分数转化为0-1之间的注意力权重,确保权重和为1;
- 加权聚合:用权重对V进行加权求和,得到最终的Attention输出。
1.3 Query、Key、Value:形象化理解
可以用"图书馆找书"的例子理解三者的关系:
- Query:你想找的书的"关键词"(如"深度学习入门");
- Key:图书馆中每本书的"标签"(如每本书封面上的书名、分类);
- Value:每本书的"内容";
- 注意力权重:你的关键词与每本书标签的匹配度(匹配度越高,权重越大);
- Attention输出:根据匹配度,将高匹配度书籍的内容聚合起来,形成你需要的信息。
更技术化的描述:序列中某个token的Query,会与所有token的Key计算点积------若两者语义或位置相关(如同一指代、相邻位置),点积结果会更大,对应Key的Value会被赋予更高权重,最终聚合到该token的输出中。
1.4 为什么需要"缩放"(除以(\sqrt{d_k}))?
当(d_k)(Q和K的维度)较大时,(QK^T)的数值会显著增大:
- 假设Q和K的元素服从均值为0、方差为1的正态分布,那么(QK^T)中每个元素的方差为(d_k),数值范围会随(d_k)增大而扩大;
- 数值过大会导致softmax函数的输入"两极分化":最大值对应的权重趋近于1,其余权重趋近于0,形成"one-hot"分布;
- 这种分布会导致梯度变小(softmax在极端值处梯度接近0),模型难以更新参数,学习效率下降。
缩放(除以(\sqrt{d_k}))能将(QK^T)的方差归一化为1,避免数值极端化,保证梯度正常传递,提升训练稳定性。
2. Transformer中的Attention:Self-Attention与Cross-Attention
Transformer的Encoder和Decoder均以Attention为核心组件,但根据Q、K、V的来源不同,分为Self-Attention(自注意力) 和Cross-Attention(交叉注意力)。
2.1 Self-Attention:关注自身序列内部依赖
Self-Attention的核心特点是Q、K、V来自同一输入序列,目的是捕捉序列内部的依赖关系(如文本中"他"与"小明"的指代关系、句子中主谓宾的关联)。
2.1.1 Encoder与Decoder中的Self-Attention差异
| 位置 | 核心限制 | 目的 |
|---|---|---|
| Encoder | 无掩码,可关注所有token | 捕捉输入序列的全局依赖(如文本语义) |
| Decoder | 有掩码(Masked Attention),仅关注当前及之前的token | 避免利用未来信息,保证自回归生成(如翻译时不提前看后面的词) |
Masked Attention(因果注意力) 的作用:在Decoder生成第t个token时,模型只能使用第1到第t个token的信息,不能使用第t+1到第n个token------通过在(QK^T)中对未来位置填充"-∞",使softmax后这些位置的权重为0,从而排除未来信息的干扰。
2.1.2 Self-Attention伪代码流程(简化版)
python
def self_attention(input_seq):
# 1. 输入嵌入+位置编码
x = embedding(input_seq) + positional_encoding(input_seq)
# 2. 线性映射生成Q、K、V
Q = linear_q(x)
K = linear_k(x)
V = linear_v(x)
# 3. 计算注意力分数并缩放
scores = torch.matmul(Q, K.T) / math.sqrt(Q.shape[-1])
# 4. Decoder中添加掩码(Encoder无此步)
if is_decoder:
scores = mask_future_tokens(scores)
# 5. 归一化与加权聚合
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output2.2 Cross-Attention:关联两个不同序列
Cross-Attention的核心特点是Q来自一个序列,K和V来自另一个序列,目的是建立两个序列之间的关联(如机器翻译中"源语言序列"与"目标语言序列"的对齐)。
2.2.1 应用场景:Decoder与Encoder的交互
在Transformer Decoder中,Cross-Attention通常作为第二层Attention(第一层为Masked Self-Attention):
- Q:Decoder当前生成的序列(目标语言,如英文);
- K、V:Encoder对输入序列的编码结果(源语言,如中文);
- 作用:让Decoder在生成每个token时,聚焦于源语言中与之对应的token(如生成"I"时关注"我",生成"love"时关注"爱")。
2.2.2 Cross-Attention伪代码流程(简化版)
python
def cross_attention(decoder_input, encoder_output):
# 1. Decoder输入嵌入+位置编码,Encoder输出直接作为K、V来源
x_dec = embedding(decoder_input) + positional_encoding(decoder_input)
# 2. 生成Q(来自Decoder)、K/V(来自Encoder)
Q = linear_q(x_dec)
K = linear_k(encoder_output)
V = linear_v(encoder_output)
# 3. 计算注意力分数并缩放(无需掩码,Encoder输出无未来信息)
scores = torch.matmul(Q, K.T) / math.sqrt(Q.shape[-1])
# 4. 归一化与加权聚合
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output2.3 Multi-Head Attention:并行捕捉多维度依赖
为了让模型同时关注不同维度的信息(如语义、语法、位置),Transformer引入了Multi-Head Attention(多头注意力):将Q、K、V分别拆分为多个"头"(Head),每个头独立计算Scaled Dot-Product Attention,最后将所有头的输出拼接并通过线性层融合。
核心优势:
- 并行性:多个头可同时计算,提升效率;
- 多粒度关注:不同头可捕捉不同类型的依赖(如一个头关注语义关联,另一个头关注位置邻近性)。
计算流程:
- 将Q、K、V通过线性层映射为高维向量,拆分为h个独立的头(每个头维度为(d_k/h));
- 每个头独立计算Scaled Dot-Product Attention;
- 拼接所有头的输出;
- 通过线性层将拼接结果映射为最终输出。
3. Attention计算复杂度优化:从O(N²)到近似线性
标准Self-Attention的时间复杂度为(O(N^2d))(N为序列长度,d为Q/K/V维度),当N较大(如长文本、长视频序列)时,计算量和显存占用会急剧增加。为解决这一问题,研究者提出了Sparse Attention 和Linear Attention等优化方案。
3.1 Sparse Attention:稀疏化注意力矩阵
核心思想:只计算序列中"有意义"的局部或稀疏关联,忽略无关token的注意力计算,将复杂度从(O(N^2))降至(O(Nk))(k为每个token需关注的token数)。
3.1.1 实现原理:局部紧密+远程稀疏
结合"空洞注意力(Dilated Attention)"和"局部注意力(Local Attention)":
- 局部注意力:每个token仅关注其周围k个token(如窗口大小为5,关注前后2个token),捕捉局部依赖;
- 空洞注意力:每隔k个token关注一个远程token(如k=4,关注第1、5、9...个token),捕捉长距离依赖;
- 最终注意力矩阵中,仅局部和远程稀疏位置的权重非零,其余位置设为0。
3.1.2 不足与局限
- 人工设计依赖:需手动选择"局部窗口大小"和"远程间隔",缺乏自适应能力;
- 工程实现复杂:稀疏矩阵的存储和计算需特殊优化(如稀疏张量),难以推广到通用框架;
- 任务适应性有限:仅适用于"局部依赖为主、远程依赖稀疏"的任务(如文本),对需全局依赖的任务(如长文档摘要)效果较差。
3.1.3 窗口注意力示例(简化逻辑)
python
def sparse_attention(Q, K, V, window_size=3):
N = Q.shape[0] # 序列长度
scores = torch.matmul(Q, K.T) / math.sqrt(Q.shape[-1])
# 仅保留当前token前后window_size个位置的分数,其余设为-∞
for i in range(N):
start = max(0, i - window_size)
end = min(N, i + window_size + 1)
scores[i, :start] = -float('inf')
scores[i, end:] = -float('inf')
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output3.2 Linear Attention:去除softmax,降低复杂度
核心思想:去掉softmax归一化,通过矩阵运算顺序调整,将复杂度从(O(N2d))降至(O(Nd2))(d为Q/K/V维度,通常远小于N)。
3.2.1 原理:先算(K^T V),再与Q交互
标准Attention的计算顺序是"Q与(K^T)交互→softmax→与V交互",而Linear Attention调整为:
- 用非负激活函数(\phi)处理Q和K(替代softmax的非负权重作用);
- 先计算(K^T V)(全局聚合V的信息);
- 再用Q与聚合后的结果交互,得到最终输出。
核心公式(核函数形式):
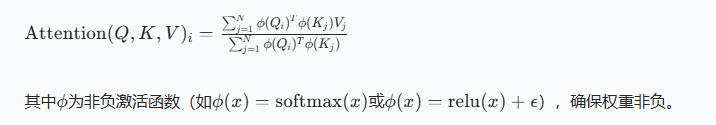
3.2.2 优势与应用
- 复杂度低 :当N远大于d时(如N=10000,d=512),(O(Nd2))远小于(O(N2d));
- 工程友好:无需稀疏优化,可直接用稠密矩阵计算;
- 跨领域适配:在CV(如图像分割)和NLP(如长文本分类)中均有应用,典型代表如A2-Nets、Linear Attention Transformer。
3.2.3 实现示例(简化版)
python
def linear_attention(Q, K, V):
# 非负激活处理Q和K
Q = torch.softmax(Q, dim=-1) # φ(Q) = softmax(Q)
K = torch.softmax(K, dim=-2) # φ(K) = softmax(K)(按序列维度归一化)
# 先算K^T V(全局聚合)
context = torch.einsum('bhnd,bhne->bhde', K, V) # K: (b,h,n,d), V: (b,h,n,e)
# 再与Q交互
output = torch.einsum('bhnd,bhde->bhne', Q, context)
return output.reshape(*Q.shape)4. KV Cache:自回归生成的"显存与速度优化神器"
在Transformer Decoder的自回归生成 (如文本生成、代码生成)中,每次生成新token时,都需要用当前token的Q与"所有历史token的K、V"计算Attention------若每次都重新计算历史K、V,会造成大量重复计算。KV Cache(键值缓存) 正是为解决这一问题而生:缓存历史token的K和V,避免重复计算,显著提升推理速度并降低显存占用。
4.1 核心原理:缓存历史,复用计算
自回归生成的特点是"生成第t个token时,仅依赖第1到第t-1个token的信息",且历史token的K、V一旦生成,就不会再变化。因此:
- 生成第1个token时:计算第1个token的K1、V1,缓存K1、V1;
- 生成第2个token时:计算第2个token的K2、V2,将K2拼接在K1后(K=K1,K2),V2拼接在V1后(V=V1,V2),直接复用缓存的K1、V1;
- 后续token以此类推,每次仅需计算当前token的K、V,再与历史缓存拼接。
4.2 示例:"唱跳篮球"生成过程对比
以生成"唱跳篮球"为例,对比"无KV Cache"和"有KV Cache"的计算差异:
4.2.1 无KV Cache:重复计算历史KV
- 生成"唱"(第1步):计算Q1与K1、V1的Attention,输出"唱";
- 生成"跳"(第2步):重新计算Q2与K1、K2的Attention(K1、V1重复计算),输出"跳";
- 生成"篮"(第3步):重新计算Q3与K1、K2、K3的Attention(K1、K2、V1、V2重复计算),输出"篮";
- 生成"球"(第4步):重新计算Q4与K1-K4的Attention(大量重复计算),输出"球"。
4.2.2 有KV Cache:复用历史KV
- 生成"唱"(第1步):计算K1、V1,缓存K1、V1,Q1与K1、V1交互,输出"唱";
- 生成"跳"(第2步):计算K2、V2,缓存更新为K1,K2、V1,V2,Q2与K1,K2、V1,V2交互(复用K1、V1),输出"跳";
- 生成"篮"(第3步):计算K3、V3,缓存更新为K1,K2,K3、V1,V2,V3,Q3与缓存交互(复用K1-K2、V1-V2),输出"篮";
- 生成"球"(第4步):计算K4、V4,缓存更新为K1-K4、V1-V4,Q4与缓存交互(复用K1-K3、V1-V3),输出"球"。
可见,KV Cache完全避免了历史KV的重复计算,生成速度随序列长度增加而提升更明显。
4.3 工程实现:Hugging Face示例
Hugging Face Transformers库中,KV Cache的核心逻辑是"拼接历史KV与当前KV",关键代码如下:
python
def forward(hidden_states, past_key_value=None, use_cache=True):
# 1. 生成当前token的Q、K、V
Q = self.q_proj(hidden_states)
K = self.k_proj(hidden_states)
V = self.v_proj(hidden_states)
# 2. 若有历史缓存,拼接历史KV与当前KV
if past_key_value is not None:
past_K, past_V = past_key_value
K = torch.cat((past_K, K), dim=-2) # 按序列维度拼接
V = torch.cat((past_V, V), dim=-2)
# 3. 决定是否保存当前KV为缓存(供下一次生成使用)
present = (K, V) if use_cache else None
# 4. 计算Attention(使用拼接后的KV)
scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(Q.shape[-1])
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output, present4.4 显存占用分析
KV Cache的显存占用与"序列长度""头数""头维度"" batch大小"相关,公式如下(以FP16精度为例):
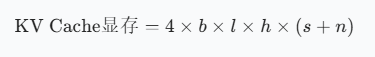
其中:
- (b):batch大小;
- (l):Transformer层数;
- (h):每个头的维度(head_dim);
- (s):输入序列长度;
- (n):输出序列长度;
- 系数4:K和V各占2字节(FP16),共4字节。
示例:GPT-3(175B)的KV Cache显存
- GPT-3参数:层数(l=96),头数=96,头维度(h=128),FP16参数显存=350GB;
- 若(b=1),(s=100),(n=1000):KV Cache显存=4×1×96×128×(100+1000)≈5.3GB,仅为参数显存的1.5%,显存占用极低。
4.5 KV Cache优化方案
当序列长度极长(如10万token)时,KV Cache的显存占用仍会增加,需进一步优化:
4.1 共用KV:MQA/GQA(见第5章)
通过"多个Query头共享一组KV",减少KV的数量,直接降低缓存占用。
4.2 窗口优化:滑动窗口与重计算
- 固定窗口(如Longformer):仅缓存最近k个token的KV,超出窗口的KV丢弃,复杂度(O(Tk))(T为总长度),但精度可能下降;
- KV重计算:丢弃窗口外的KV,需时重新计算,精度高但性能损失大;
- 箭型窗口(如StreamingLLM):保留少量"注意力锚点"(Attention Sink),结合滑动窗口,平衡精度与性能。
4.3 量化与稀疏
- 量化:将KV从FP16量化为FP8或INT4,显存占用降低4-8倍(如lmdeploy框架支持KV量化);
- 稀疏:对KV进行稀疏化(如仅保留重要维度),进一步减少存储。
4.4 存储与计算优化
- PagedAttention(vLLM):将KV拆分为"页",存储在非连续内存中,避免内存碎片,提升显存利用率;
- FlashDecoding:基于FlashAttention,将KV分成小chunk并行计算,再聚合结果,提升长序列推理速度。
5. 缓存与效果的取舍:从MHA到MLA的演进
在自回归模型中,"注意力效果"与"KV Cache显存占用"存在天然权衡:效果越好的Attention(如MHA),通常需要更多的KV缓存;而缓存更省的Attention(如MQA),效果可能下降。研究者通过设计MHA→GQA→MQA→MLA的变体,逐步平衡这一矛盾。
5.1 三种经典Attention:MHA、GQA、MQA对比
| Attention类型 | 核心设计 | KV Cache per Token(元素数) | 效果 | 适用场景 |
|---|---|---|---|---|
| Multi-Head Attention(MHA) | 每个Query头独立对应一组KV | (2n_h d_h l) | 强 | 对效果要求高,显存充足(如GPT-3、LLaMA 2) |
| Grouped-Query Attention(GQA) | Query头分组,每组共享一组KV | (2n_g d_h l) | 中等 | 平衡效果与缓存(如GPT-4、Qwen-7B) |
| Multi-Query Attention(MQA) | 所有Query头共享一组KV | (2d_h l) | 弱 | 显存受限,对效果要求不高(如T5、部分轻量模型) |
注:(n_h)为总Query头数,(n_g)为分组数((n_g < n_h)),(d_h)为头维度,(l)为层数。
5.1.1 Multi-Head Attention(MHA):效果最优,缓存最高
MHA是Transformer的标准配置,每个Query头都有独立的K和V:
- 优势:多个头可捕捉不同维度的依赖,效果最强;
- 劣势:KV数量与头数成正比,缓存占用高(如128个头的模型,KV数量是MQA的128倍)。
5.1.2 Multi-Query Attention(MQA):缓存最省,效果最弱
MQA为所有Query头共享一组K和V:
- 优势:KV数量仅1组,缓存占用极低(是MHA的1/(n_h));
- 劣势:所有头共享同一KV,难以捕捉多维度依赖,效果明显下降(如长文本生成时语义连贯性差)。
5.1.3 Grouped-Query Attention(GQA):平衡之选
GQA将Query头分成若干组,每组共享一组KV(如128个头分成8组,每组16个头共享1组KV):
- 优势:KV数量为分组数(n_g),缓存占用介于MHA和MQA之间,效果接近MHA(GPT-4测试显示,GQA与MHA的效果差距小于1%);
- 劣势:分组数需手动调整(如8组、16组),需在效果和缓存间权衡。
5.2 MLA(Multi-head Latent Attention):Deepseek-V2的创新方案
为解决"MHA缓存高、MQA效果差"的问题,Deepseek-V2提出了MLA(多头 latent 注意力),核心是通过"低秩压缩KV",在降低缓存的同时保持甚至提升效果。
5.2.1 核心原理:低秩压缩与解耦RoPE
MLA的关键设计是将KV压缩为低维的"latent向量",仅缓存latent向量,而非原始KV:
- KV低秩压缩 :通过线性层将输入隐藏态映射为低维的(c_t^{KV})(latent KV向量,(d_c << n_h d_h)),仅缓存(c_t{KV});推理时再通过线性层将(c_t{KV})恢复为原始维度的KV;
- Query低秩压缩:对Query也进行低秩压缩,减少训练时的激活显存占用;
- 解耦RoPE:RoPE(旋转位置编码)与低秩压缩存在兼容性问题,MLA通过"额外多头Query+共享Key"的设计,单独处理RoPE,确保位置信息不丢失。
5.2.2 训练与推理差异
- 训练阶段:MLA保持多头结构,每个头有独立的压缩/恢复线性层,确保效果;
- 推理阶段 :MLA转为MQA形式,仅缓存低维的(c_t^{KV})和少量RoPE相关的Key,缓存占用仅为((d_c + d_hR)l)((d_hR)为RoPE相关维度),远低于MHA,且效果更强。
5.2.3 效果与缓存优势
根据Deepseek-V2论文测试:
- 缓存占用:MLA的KV Cache元素数约为(4.5d_h l),仅为MHA的(4.5/n_h)(如(n_h=128)时,缓存是MHA的3.5%),接近MQA;
- 效果:MLA在长文本理解(如128k token)和生成任务上,效果超过MHA和GQA,尤其在长距离依赖捕捉上表现更优。
6. 长上下文Attention优化:DCA与S2-Attention
当序列长度超过1万甚至10万时(如长文档分析、代码库理解),即使有KV Cache和MLA,传统Attention的复杂度仍难以承受。研究者提出了DCA(双块注意力) 和S2-Attention(移位稀疏注意力) 等方案,专门优化长上下文任务。
6.1 DCA(Dual Chunk Attention):分块计算,全局交互
DCA的核心思想是"将长文本分块,先算块内注意力,再算块间注意力",既减少计算量,又保证全局信息交互。
6.1.1 计算步骤
- 分块:将长序列按固定大小分成若干块(如2000词分4块,每块500词);
- 块内注意力:对每个块单独计算Self-Attention,捕捉块内局部依赖(复杂度(O(C^2d)),C为块大小);
- 块间注意力:将每个块视为一个"超级token",计算块与块之间的Attention,捕捉全局依赖(复杂度(O(M^2Cd)),M为块数);
- 融合输出:将块内和块间Attention的结果加权融合,通过线性层输出。
6.1.2 优势与应用
- 复杂度低:总复杂度为(O(M C^2d + M^2 C d)),当M较小时(如M=20,C=500),远低于(O(N^2d))(N=10000);
- 全局信息保留:块间注意力确保模型不丢失长距离依赖;
- 适用场景:长文档摘要、法律文本分析、代码库理解等超长篇序列任务。
6.2 S2-Attention(Shifted Sparse Attention):移位分组,高效微调
S2-Attention是LongLoRA(长上下文微调框架)提出的方案,核心是"分组+移位",在微调长上下文模型时大幅降低计算量。
6.2.1 核心设计
- 分组:将序列按固定大小分成若干组(如8192个token分成4组,每组2048个token);
- 移位:将一半头的token按"半组大小"移位(如第2组的token移位1024个位置),确保相邻组之间的信息流动;
- 组内计算:注意力仅在组内计算,避免跨组的大量计算;
- 掩码优化:通过微调注意力掩码,避免移位导致的信息泄漏。
6.2.2 优势与应用
- 微调效率高:仅需计算组内注意力,微调长上下文模型(如将LLaMA 2的上下文从4k扩展到128k)时,计算量仅为标准Attention的1/16;
- 效果稳定:移位设计确保组间信息不丢失,微调后模型在长上下文任务上的效果接近全量微调;
- 适用场景:长上下文模型的高效微调(如LongLoRA、LoRA-Long)。
7. 总结:Attention机制的演进与趋势
Attention机制自2017年Transformer论文提出以来,经历了从"标准MHA"到"高效变体"的演进,核心趋势是在"效果""速度""显存"三者间寻找最优平衡:
- 早期:以MHA为核心,追求效果最优,忽视计算与显存成本;
- 中期:通过Sparse Attention、Linear Attention降低复杂度,通过KV Cache优化推理速度;
- 近期:通过GQA、MLA平衡效果与缓存,通过DCA、S2-Attention解决超长篇序列问题。
未来,Attention机制的发展方向可能包括:
- 自适应稀疏:无需人工设计,模型自动学习该关注哪些token;
- 更高效的低秩压缩:如结合Transformer-XL的记忆机制,进一步降低缓存;
- 跨模态适配:将文本领域的Attention优化推广到图像、视频等长序列跨模态任务。
对于开发者而言,选择Attention变体时需根据任务需求权衡:
- 效果优先(如GPT-4):选择MHA或GQA;
- 显存优先(如边缘设备):选择MQA或MLA;
- 长上下文优先(如长文档分析):选择DCA或S2-Attention+KV Cache。