基本信息
题目:HAC: Hash-grid Assisted Context for 3D Gaussian Splatting Compression
来源:ECCV 2024
学校:SJTU
摘要:3DGS压缩
三维高斯抛雪球( 3DGS )具有渲染速度快、保真度高等优点,是一种很有前途的新视点合成框架。然而,大量的高斯及其相关属性需要有效的压缩技术。尽管如此,高斯(或本文中的锚)点云的稀疏性和无组织性对压缩提出了挑战。为了解决这个问题,我们利用无组织锚点和结构化哈希网格之间的关系,利用它们的互信息进行上下文建模,并提出了一种哈希网格辅助的上下文( HAC )框架,用于高度紧凑的3DGS表示。我们的方法引入了二进制哈希网格来建立连续的空间一致性,允许我们通过精心设计的上下文模型来揭示锚点的内在空间关系。 为了便于熵编码,我们利用高斯分布来准确估计每个量化属性的概率,其中提出了一个自适应量化模块,以实现对这些属性的高精度量化,以提高保真度恢复。此外,我们还结合了一种自适应的掩码策略来消除无效的高斯和锚点。重要的是,我们的工作是探索基于上下文压缩的3DGS表示的先驱,与vanilla 3DGS相比,实现了超过75 ×的显著尺寸缩减,同时提高了保真度,并实现了超过11 ×的尺寸缩减。
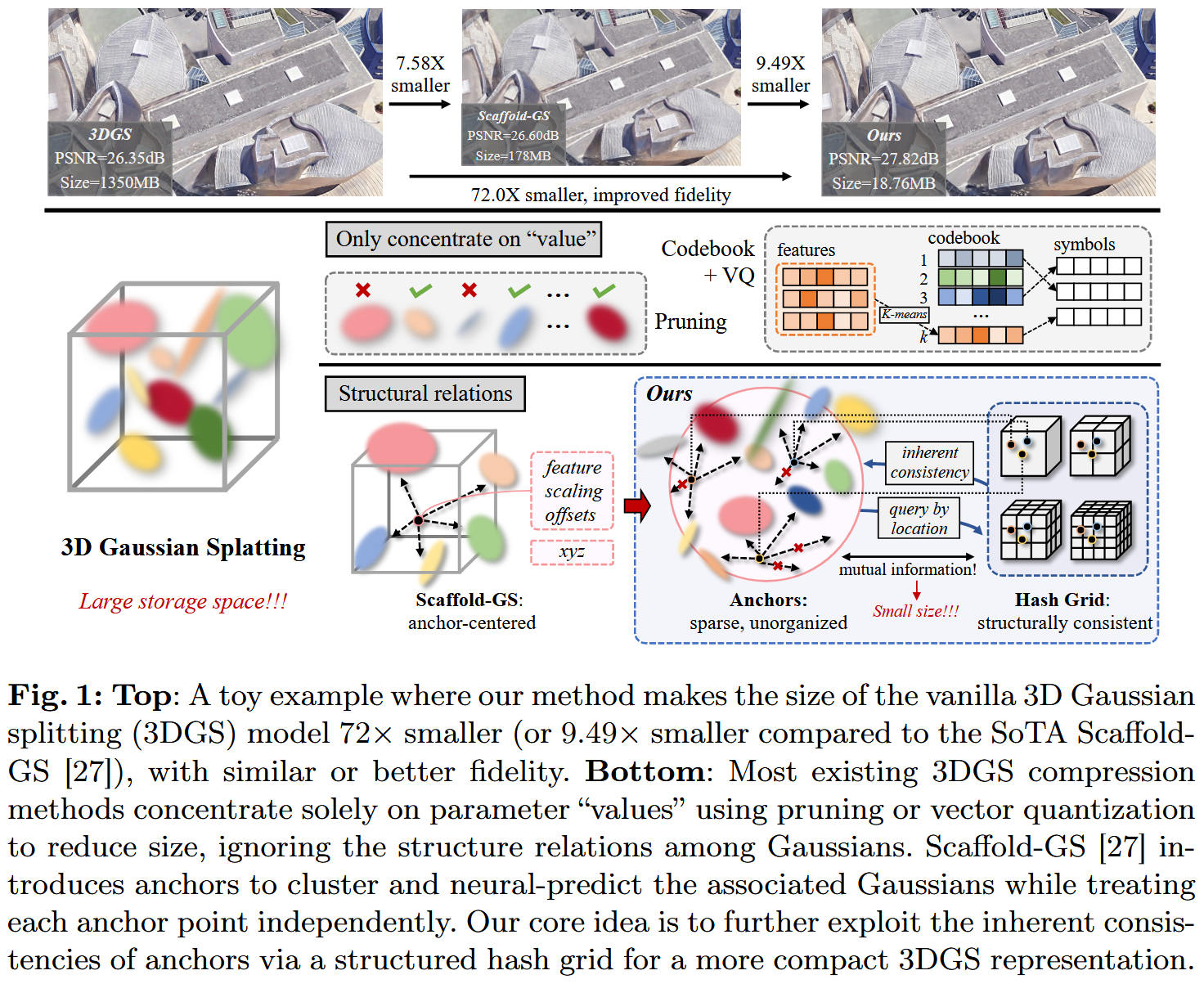
Introduction
论文首先回顾了近年来3D场景表示在新型视图合成(novel view synthesis)领域的进展。
- 背景技术演进 :
- Neural Radiance Field (NeRF):NeRF是一种隐式表示方法,使用多层感知机(MLP)沿采样射线积累RGB值来渲染颜色,实现照片级真实图像重建。但NeRF的瓶颈是需要大量射线点采样,导致训练和渲染速度慢。
- NeRF的改进 :引入特征网格(feature grids)来加速渲染,通过缩小MLP规模来提升速度。但这些方法仍需频繁采样射线点,渲染速度相对较慢。
- 3D Gaussian Splatting (3DGS) :一种新兴范式,使用可学习的3D高斯分布(Gaussians)显式表示3D空间。这些高斯分布从结构从运动(SfM)初始化,具有可学习的形状和外观参数。通过基于图块的光栅化(tile-based rasterization),可以快速、可微分地渲染到2D平面,避免了NeRF的体积渲染(volume rendering)。这使得渲染速度极快,并保持高照片真实度,因此迅速被广泛采用。
- 3DGS的缺点 :
- 需要大量3D高斯分布来表示大规模场景(如城市级场景需要数百万个高斯),每个高斯都有关联属性,导致存储空间巨大(几GB)。
- 高斯分布稀疏且无序,压缩困难。
- 现有压缩方法的局限 :
- 大多数方法只关注参数"值"(values),忽略结构关系(structural relations)。
- 示例:参数修剪(pruning)Lightgaussian, 22:删除值低于阈值的高斯。
- 向量量化(vector quantization)Lightgaussian, 22, Compact3d, 32:聚类相似值,只保留代表性参数。
- 这些方法无法消除结构冗余(structural redundancies),这是紧凑表示的关键。
- Scaffold-GS :引入锚点(anchors)来聚类附近的相关3D高斯,并从锚点属性神经预测高斯属性,实现存储节省。但锚点仍是稀疏、无序的点云形式,难以进一步压缩。
- 大多数方法只关注参数"值"(values),忽略结构关系(structural relations)。
- 论文的创新想法 :
- 受NeRF系列启发,考虑使用有序特征网格表示3D空间。
- 观察到Scaffold-GS中无序锚点属性与结构化哈希网格特征之间存在大量互信息(mutual information)。
- 提出Hash-grid Assisted Context (HAC)框架 :联合学习结构化的紧凑哈希网格(每个哈希参数二值化),用于锚点属性的上下文建模。
- 以Scaffold-GS作为基础模型,对于每个锚点,根据其位置查询哈希网格,得到插值哈希特征(interpolated hash feature)。
- 使用该特征预测锚点属性的值分布(value distributions),便于熵编码(如算术编码AE),实现高度紧凑的模型表示。
- 此外,引入Adaptive Quantization Module (AQM):动态调整不同锚点属性的量化步长(quantization step sizes),保留原始信息。
- 使用可学习掩码(learnable masks)删除无效高斯和锚点,进一步提升压缩比。
- 贡献总结 :
- 首次为3DGS压缩建模上下文,即使用结构化哈希网格挖掘无序3D高斯(或Scaffold-GS中的锚点)之间的内在一致性。
- 使用插值哈希特征神经预测锚点属性的值分布,并通过AQM神经预测量化步长细化;同时使用可学习掩码修剪无效元素。
- 在五个数据集上的实验显示,HAC在平均压缩比上比基础Scaffold-GS高11倍,比原始3DGS高75倍,同时保持相当或更好的保真度(fidelity)。
Lee, J.C., Rho, D., Sun, X., Ko, J.H., Park, E.: Compact 3d gaussian representation for radiance field. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Niedermayr, S., Stumpfegger, J., Westermann, R.: Compressed 3d gaussian splatting for accelerated novel view synthesis. arXiv preprint arXiv:2401.02436 (2023)
Related Works
这一节回顾了NeRF和3DGS的相关研究及其压缩技术,突显了论文的创新点。
- Neural Radiance Field (NeRF)及其压缩 :
- NeRF:使用隐式MLP沿射线积累RGB值生成视图,但采样点密集和大MLP导致渲染慢。
- 改进:Instant-NGP、TensoRF、K-planes、DVGO使用显式网格表示,缩小MLP,提升速度,但增加存储。
- 压缩技术:
- 值-based方法:修剪10, 25、码本(codebooks)25, 26、量化或熵约束(如BiRF37、SHACIRA15)。
- 结构关系-based方法:小波分解34、秩残差分解40、空间预测38,利用网格的有序结构消除空间冗余。CNC7充分利用结构信息,实现显著的率失真(RD)性能提升。
- 3D Gaussian Splatting (3DGS)及其压缩 :
- 3DGS19:使用可学习形状和外观属性的3D高斯表示场景,通过可微分溅射(splatting)和光栅化优化,解决NeRF的慢速问题。
- 压缩挑战:高斯稀疏、无序,难以建立结构关系。
- 现有方法主要关注参数"值":修剪Lightgaussian, 22、codebooks码本Lightgaussian, 22, 31, 32、熵约束14。
- 探索关系的方法:Scaffold-GS使用锚点中心特征减少参数;Morgenstern et al.29考虑维度折叠到有序2D空间。但这些对空间冗余的挖掘不足。
- 论文的灵感:图像压缩8, 16, 17和视频压缩23, 24, 36通过挖掘空间/时间关系消除结构冗余。论文以Scaffold-GS为基础,引入结构化哈希网格作为上下文,建模稀疏锚点的内在一致性,实现更紧凑表示。
Rho, D., Lee, B., Nam, S., Lee, J.C., Ko, J.H., Park, E.: Masked wavelet representation for compact neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20680--20690 (2023)
Song, Z., Duan, W., Zhang, Y., Wang, S., Ma, S., Gao, W.: Spc-nerf: Spatial predictive compression for voxel based radiance field. arXiv preprint arXiv:2402.16366 (2024)
Tang, J., Chen, X., Wang, J., Zeng, G.: Compressible-composable nerf via rankresidual decomposition. Advances in Neural Information Processing Systems 35, 14798--14809 (2022)
Chen, Y., Wu, Q., Harandi, M., Cai, J.: How far can we compress instant-ngpbased nerf? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Deng, C.L., Tartaglione, E.: Compressing explicit voxel grid representations: fast nerfs become also small. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1236--1245 (2023)
Cheng, Z., Sun, H., Takeuchi, M., Katto, J.: Learned image compression with discretized gaussian mixture likelihoods and attention modules. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 79397948 (2020)
He, D., Zheng, Y., Sun, B., Wang, Y., Qin, H.: Checkerboard context model for efficient learned image compression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14771--14780 (2021)
Girish, S., Shrivastava, A., Gupta, K.: Shacira: Scalable hash-grid compression for implicit neural representations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17513--17524 (2023)
Li, L., Shen, Z., Wang, Z., Shen, L., Bo, L.: Compressing volumetric radiance fields to 1 mb. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4222--4231 (2023)
Li, L., Wang, Z., Shen, Z., Shen, L., Tan, P.: Compact real-time radiance fields with neural codebook. In: ICME (2023)
Morgenstern, W., Barthel, F., Hilsmann, A., Eisert, P.: Compact 3d scene representation via self-organizing gaussian grids. arXiv preprint arXiv:2312.13299 (2023)
Shin, S., Park, J.: Binary radiance fields. Advances in neural information processing systems (2023)
Method
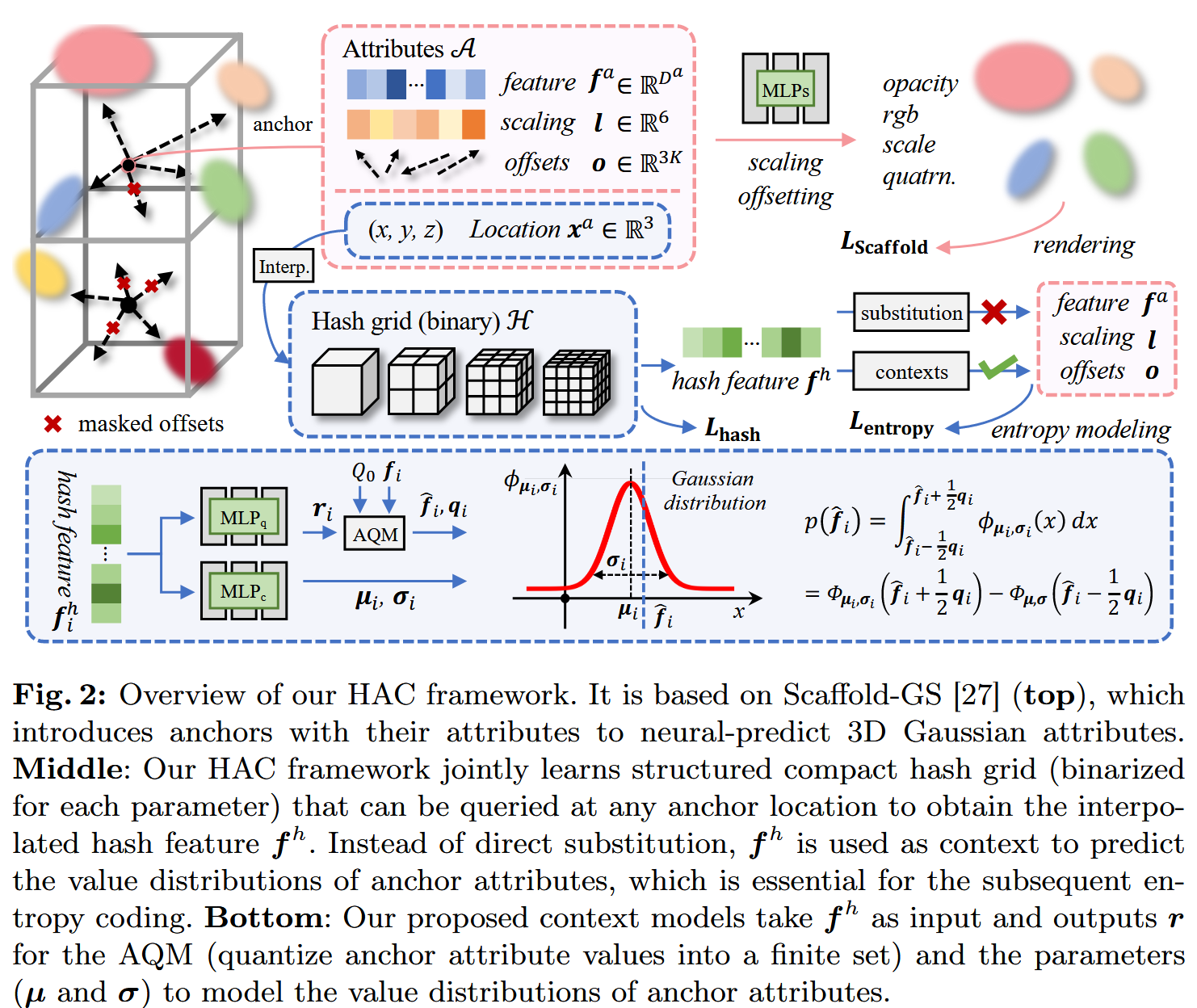
论文在图2中概念化了HAC框架。HAC以Scaffold-GS27(图2上部)为基础,后者引入锚点及其属性A(包括特征、缩放和偏移)来聚类和神经预测3D高斯属性(不透明度、RGB、缩放、四元数)。HAC的核心是联合学习结构化的紧凑哈希网格(每个参数二值化),通过锚点位置查询网格得到插值哈希特征 (图2中部)。
不直接替换锚点特征,而是作为上下文预测锚点属性的值分布,用于后续熵编码(如算术编码AE)。
上下文模型(图2下部)是一个简单的MLP,输入,输出用于自适应量化模块(AQM)的r(量化锚点属性值到有限集),以及高斯参数(μ和σ)来建模锚点属性的值分布,从而计算每个量化属性的概率用于AE。图2中画了两个MLP(MLPq和MLPc),但它们实际共享MLP层,只是输出维度不同。此外,引入自适应偏移掩码模块(图2左上)来修剪冗余高斯和锚点。
HAC的关键创新是利用哈希网格挖掘锚点间的空间一致性(inherent consistencies),实现比特消耗最小化,而不影响渲染速度和保真度上限。
3.1 Preliminaries

3.2 Bridging Anchors and Hash Grid

3.3 HAC: Hash-Grid Assisted Context Framework



3.4 Training and Coding Process

实验
硬件平台
在单个NVIDIA RTX 4090 GPU上训练。
数据集
- 遵循Scaffold-GS,选择多个数据集:
- 小规模:Synthetic-NeRF 28(合成数据集,用于初步验证)。
- 大规模真实场景:BungeeNeRF 42、DeepBlending 18、Mip-NeRF360 2(评估全部9个场景)、Tanks&Temples 20。
- 这些数据集覆盖多样场景(合成 vs. 真实,小 vs. 大规模),确保评估的全面性。例如,BungeeNeRF是城市级大规模,挑战性高;Mip-NeRF360包括室内外多视图。
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99--106 (2021)
Xiangli, Y., Xu, L., Pan, X., Zhao, N., Rao, A., Theobalt, C., Dai, B., Lin, D.: Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering. In: European conference on computer vision. pp. 106--122. Springer (2022)
Hedman, P., Philip, J., Price, T., Frahm, J.M., Drettakis, G., Brostow, G.: Deep blending for free-viewpoint image-based rendering. ACM Transactions on Graphics (ToG) 37(6), 1--15 (2018)
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics (ToG) 36(4), 1--13 (2017)
Benchmark
- 比较对象包括现有3DGS压缩方法:
- 11, 22, 31, 32:主要采用码本-based(codebook-based)或参数修剪(pruning)策略。这些是"值-based"方法,忽略结构冗余。
- Scaffold-GS 27:探索高斯关系,实现紧凑表示,是HAC的基础模型。
- EAGLES 14:使用非上下文熵约束(noncontextual entropy constraints)。
- Morgenstern et al. 29:采用维度折叠(dimension collapse)技术。
- 这些基线代表了从简单值压缩到初步结构探索的多样性。HAC的创新在于上下文建模,预期在压缩率上优于它们。
metric
- 重点评估率失真(RD)性能:计算在相似保真度下,HAC相对于其他方法的相对率(大小)变化。
- 注:无法计算BD-rate 4(Bjøntegaard Delta rate,一种标准RD指标),因为其他方法通常只输出单一率点,而BD-rate需至少四个率点。
- 隐含使用保真度指标如PSNR、SSIM、LPIPS(从补充材料推断,常见于NeRF/3DGS评估)。
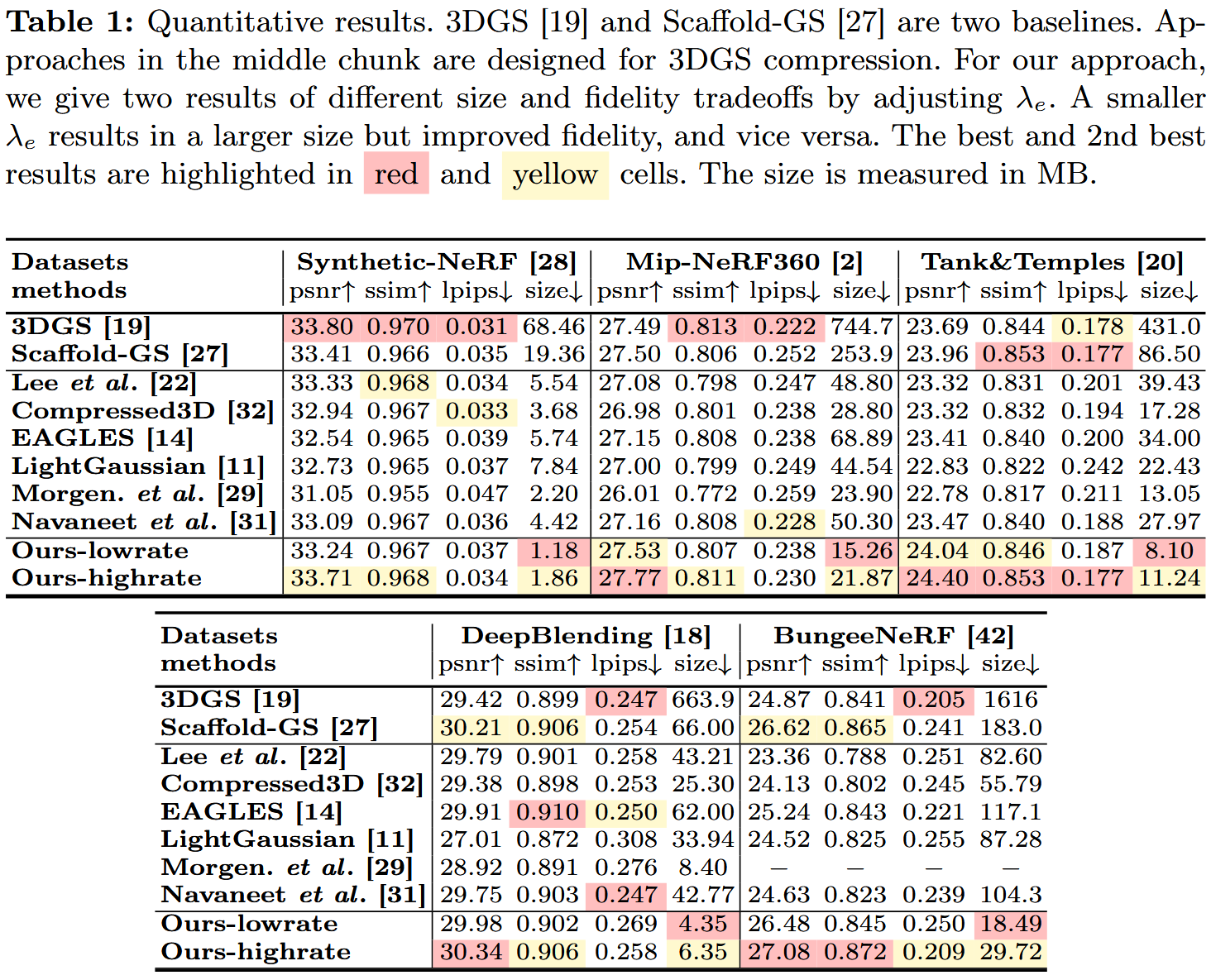
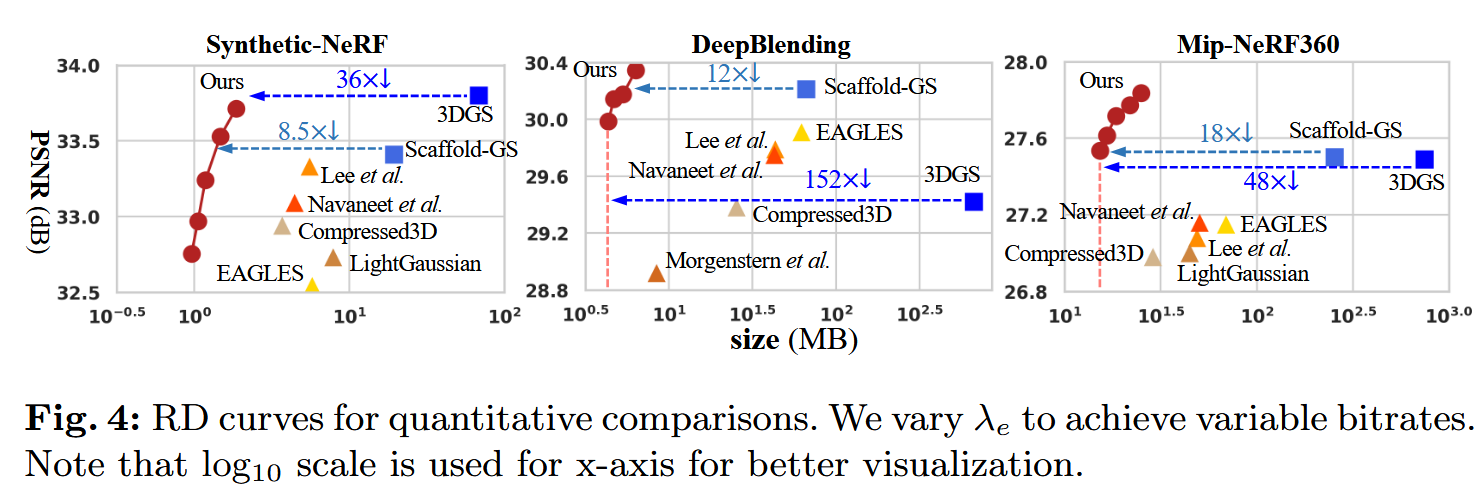

- 定量结果 :见表1和图4(补充C节有每个场景细节)。
- HAC比原始3DGS 19压缩超过75×,且保真度甚至改善。
- 比基础Scaffold-GS 27压缩超过11×。
- 最高保真度超过Scaffold-GS,主要原因:1) 熵损失正则化防止过拟合;2) 增加锚点特征维度到50,提升模型容量。
- 与其他压缩方法(中间组)比较:它们通过修剪和码本减少大小,但仍有显著空间冗余。Morgenstern 29大小小,但因维度折叠显著牺牲保真度。
- 定性结果:图5显示视觉输出,HAC在细节保留上优越。
- 分析:这些结果证明HAC的有效性。75×压缩意味着从几GB降到几十MB,实用性强。改善保真度表明上下文建模不仅是压缩工具,还能优化表示。
初体验
TODO