以下是对论文《Visual Abstraction: A Plug-and-Play Approach for Text-Visual Retrieval》(VISA)的深度解析,从核心问题、方法创新到实验验证的系统性阐述:
一、问题背景:传统跨模态检索的瓶颈
语义冗余与粒度失配是文本-视觉检索的核心挑战:
- 视觉信号的低效性
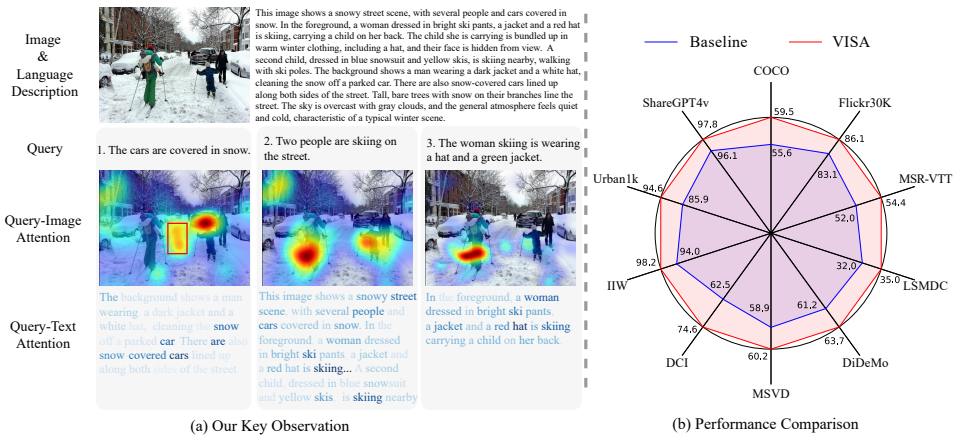
图像/视频包含大量低阶冗余信息(如纹理细节),而文本查询关注高阶语义(如"滑雪者"而非"雪地纹理")。传统视觉语言模型(如CLIP)的全局对比学习难以过滤噪声(图1a红框)。 - 描述-查询的粒度鸿沟
图像蕴含无限粒度信息,但配对文本描述通常简短(平均<20词)。当用户查询涉及细粒度属性(如"戴红帽的滑雪者")时,模型难以精准匹配(图1a Query 2-3)。
现有方案的局限:
- 目标检测方法(如UNITER)仅能捕捉有限物体,无法表示关系/动作。
- 基于大模型生成细粒度描述的方法(如DreamLIP)需从头训练VLMs,计算成本高昂。
二、VISA核心创新:视觉抽象化
2.1 核心思想
将跨模态检索转化为纯文本匹配:
- 视觉→文本转换:用现成大模型(LMM)将图像/视频转化为密集语义的文本描述
- QA驱动的粒度对齐:根据用户查询生成针对性问题,细化描述粒度
- 文本空间检索:在统一文本空间计算相似度,规避跨模态对齐偏差
2.2 技术框架
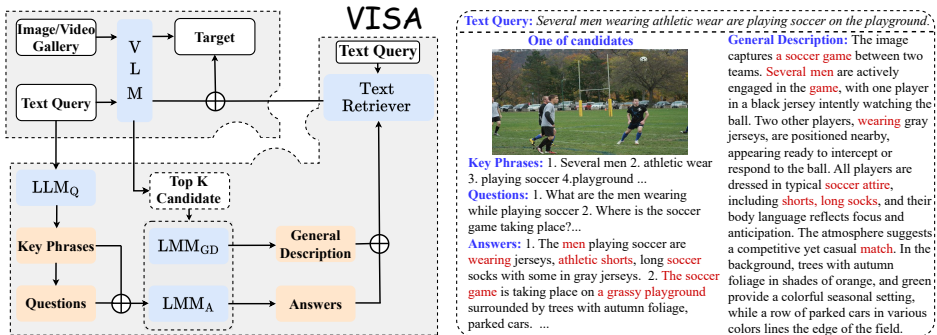
三阶段流程(图2):
-
通用描述生成(General Description)
- 使用LLaVA等LMM生成图像/视频的全局描述:
TiGD=LMMGD(PromptGD,Ii) - 作用:过滤低阶冗余(如背景纹理),保留核心语义(如人物动作、场景)
- 使用LLaVA等LMM生成图像/视频的全局描述:
-
QA精炼(QA-Based Refinement)
- 问题生成 :LLM解析查询关键词→生成3-5个针对性问题(表10)
Questions=LLMQ(PromptQ,key-phrases,q) - 答案生成 :LMM基于视觉内容回答问题:
TiA=LMMA(PromptA,key-phrases,Questions,Ii) - 关键设计 :
- 强制详细回答(禁止"Yes/No")
- 不确定时输出"Uncertain"(避免幻觉)
- 问题生成 :LLM解析查询关键词→生成3-5个针对性问题(表10)
-
混合检索(Hybrid Retrieval)
- 融合VLM原始分值与文本空间分值:
sfinal=norm(sVLM)+norm(sText-Retri) - 文本检索器(如gemma2)计算文本相似度:
s(Ti∣q)=Text-Retri(TiGD⊕TiA,q)
- 融合VLM原始分值与文本空间分值:
三、实验验证:多场景性能突破
3.1 数据集与指标
- 短文本图像检索:MS-COCO(5K图)、Flickr30K(1K图)
- 视频检索:MSR-VTT(1K视频)、DiDeMo(1K视频)
- 长文本检索:DCI(170+词/描述)、Urban1k(空间关系)
- 核心指标:召回率@1/5/10(R@1/R@5/R@10)
3.2 关键结果
-
图像检索性能跃升(表1)
- SigLIP + VISA:COCO的R@1提升 +3.0%(54.2%→57.2%)
- EVA-CLIP + VISA:Flickr30K的R@1提升 +3.0%(83.1%→86.1%)
-
视频检索全面领先(表2)
- InternVideo2-G + VISA:MSR-VTT的R@1提升 +2.4%(52.0%→54.4%)
- DiDeMo上的最大提升达 +8.9%(45.9%→54.8%)
-
长文本检索突破(表3)
- LoTLIP + VISA:DCI的R@1提升 +12.1%(62.5%→74.6%)
- 证明对复杂语义(空间关系、多属性)的捕捉能力
四、技术优势解析
4.1 效率与兼容性
- 零训练开销:直接集成现成LMM(LLaVA/Qwen)
- 在线延迟仅1秒/查询:QA精炼与文本检索可并行(表7)
- 模型无关性:提升CLIP/SigLIP/BLIP-2等各类VLMs(表6)
4.2 模块化设计价值
- 通用描述的必要性 :移除后Urban1k的R@1下降 4.3%(表5)
- QA精炼的粒度适配:3-5个问题达到最优平衡(表4b)
- 文本检索器选择:轻量模型stella-435M延迟仅0.0005秒(表4d)
4.3 可视化案例
- 细粒度修正(图3):通用描述误判"黑色夹克"→QA修正为"黑色外套"
- 关键属性捕捉(图4):通过QA精炼准确捕获"倒计时3秒"的细节
- 语义消歧(图5):区分"Windows操作系统"与"窗户"的歧义

五、应用前景与局限
5.1 产业落地场景
- 安防监控:快速检索特定衣着特征的行人
- 电商搜索:匹配"红裙+蕾丝边+收腰"等复合需求
- 医疗影像:精准定位"左下肺叶毛玻璃结节"
5.2 技术局限
- LMM描述偏差:可能引入性别/种族偏见(需人工审核)
- 隐私风险:个人图像转化为文本时存在信息泄露可能
- 计算成本:离线生成描述需GPU资源(LLaVA-34B处理Flickr30K需437秒)
5.3 未来方向
- 自适应QA机制:动态调整问题数量(非固定3-5个)
- 多模态混合检索:融合文本描述与视觉特征
- 低资源部署:蒸馏小型QA生成模型(<1B参数)
六、结论
VISA通过视觉抽象化重构跨模态检索范式:
- 本质创新:将图像/视频转化为语义密集的文本描述,规避视觉信号噪声
- 技术突破:QA精炼实现查询自适应的粒度对齐,R@1最高提升12.1%
- 部署优势:即插即用、零训练成本,兼容现有检索系统
开源生态:
- 代码:
- 多粒度测试集(16.5K文档+1.6K查询)
VISA为跨模态任务提供新范式,可扩展至视频定位(Video Grounding)、组合图像检索(Composed Image Retrieval)等场景,推动多模态理解进入"文本中心化"时代。