前言
好像目前为止没怎么见到过真要求lca的题()
一、树上倍增
1.基本原理
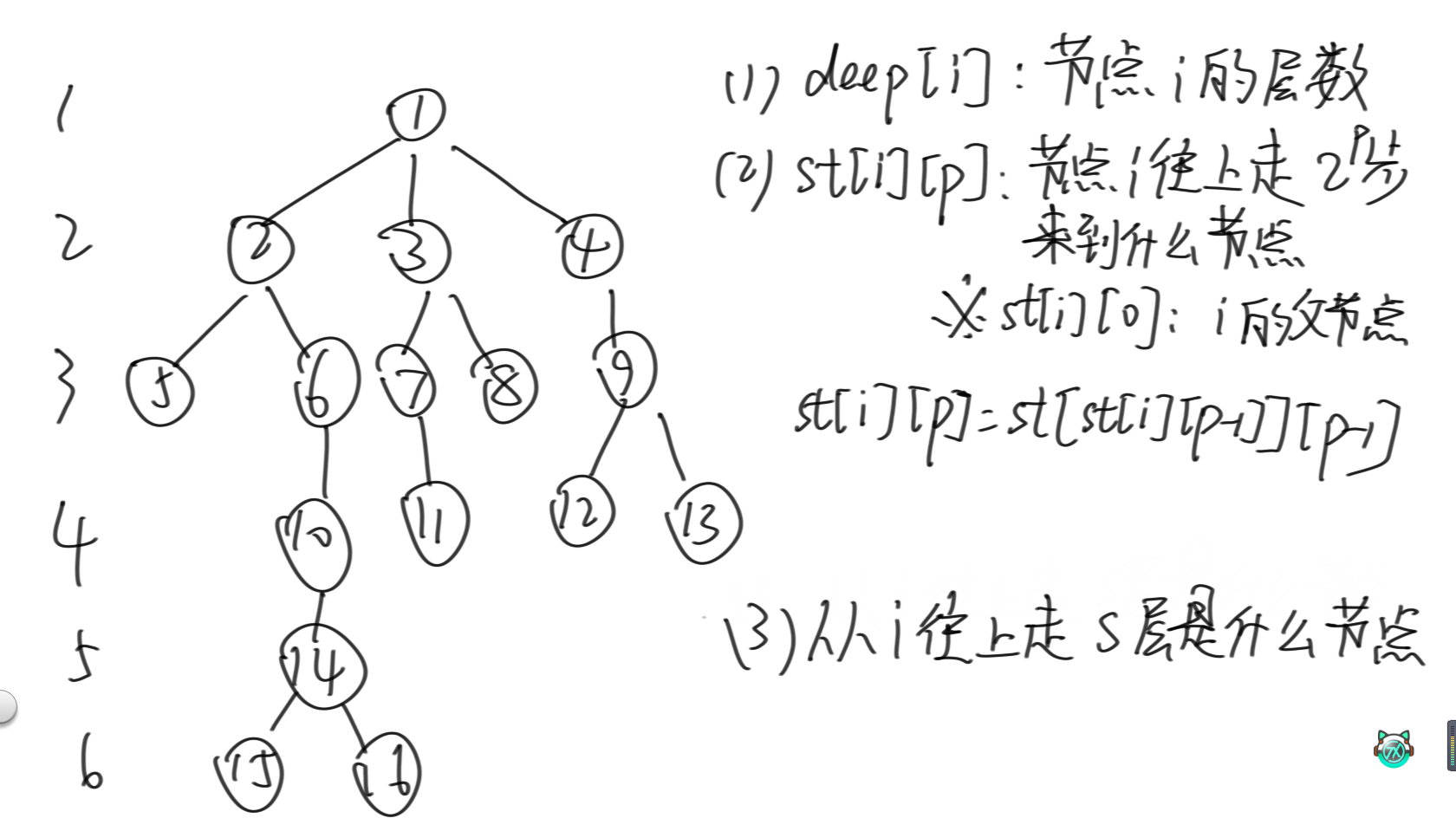
首先,对于每棵树,要先构建出一张deep表,deepi表示i节点的层数,定义根节点的层数为1。之后定义stip为从i节点开始往上走2的p次方步来到什么节点,那么很明显sti0就是i的父节点。那么和普通的st表类似,stip就等于stst\[ip-1]p-1,就是先往上跳2的p-1次方步,从这个节点再跳2的p-1次方步即可。那么有了这张表,就可以快速查询从i往上走s层是什么节点。
2.树节点的第 K 个祖先
cpp
class TreeAncestor {
public:
const int LIMIT=20;
int power;
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
void dfs(int u,int fa)
{
if(u==0)
{
deep[u]=1;
}
else
{
deep[u]=deep[fa]+1;
}
stjump[u][0]=fa;
for(int p=1;(1<<p)<=deep[u];p++)
{
stjump[u][p]=stjump[stjump[u][p-1]][p-1];
}
for(int v:g[u])
{
dfs(v,u);
}
}
//深度
vector<int>deep;
//st表
vector<vector<int>>stjump;
//图
vector<vector<int>>g;
TreeAncestor(int n, vector<int>& parent) {
deep.resize(n);
stjump.resize(n,vector<int>(LIMIT));
g.resize(n);
power=log2(n);
for(int i=1;i<parent.size();i++)
{
g[parent[i]].push_back(i);
}
dfs(0,0);
}
int getKthAncestor(int node, int k) {
//不够k步
if(deep[node]<=k)
{
return -1;
}
//想去的层数
int s=deep[node]-k;
for(int p=power;p>=0;p--)
{
//在s层以下
if(deep[stjump[node][p]]>=s)
{
node=stjump[node][p];
}
}
return node;
}
};首先,还是先求出小于等于n的最接近的2的幂,然后去dfs同时构建deep表和st表。那么就是先构建出deep表,然后把stjumpi0设置成自己的父亲,然后从低位开始往上跳,注意这里要用deep限制一下跳的距离,最后再往下扎即可。那么在每次查询时,先求出想去的层数s,然后从高位往低位考虑,能跳就跳即可。
二、树上倍增求LCA
1.基本原理

如果要求节点a和节点b的lca,方法就是先让a和b根据stjump表来到同一层,然后一起往上走,过程中保证各自到达的节点不同,最后再往上走一步即可。
2.【模板】最近公共祖先(LCA)
cpp
#include <bits/stdc++.h>
using namespace std;
/* /\_/\
* (= ._.)
* / > \>
*/
typedef long long ll;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int MAXN=5e5+5;
const int LIMIT=20;
int deep[MAXN];
int stjump[MAXN][LIMIT];
vector<vector<int>>g(MAXN);
int power;
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
void dfs(int u,int fa)
{
deep[u]=deep[fa]+1;
stjump[u][0]=fa;
for(int p=1;(1<<p)<=deep[u];p++)
{
stjump[u][p]=stjump[stjump[u][p-1]][p-1];
}
for(int v:g[u])
{
if(v!=fa)
{
dfs(v,u);
}
}
}
int lca(int a,int b)
{
//让a是更深的节点
if(deep[a]<deep[b])
{
int t=a;
a=b;
b=t;
}
for(int p=power;p>=0;p--)
{
if(deep[stjump[a][p]]>=deep[b])
{
a=stjump[a][p];
}
}
if(a==b)
{
return a;
}
for(int p=power;p>=0;p--)
{
if(stjump[a][p]!=stjump[b][p])
{
a=stjump[a][p];
b=stjump[b][p];
}
}
return stjump[a][0];
}
void solve()
{
int n,m,s;
cin>>n>>m>>s;
power=log2(n);
for(int i=1,u,v;i<n;i++)
{
cin>>u>>v;
g[u].push_back(v);
g[v].push_back(u);
}
dfs(s,0);
int a,b;
while(m--)
{
cin>>a>>b;
cout<<lca(a,b)<<endl;
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int t=1;
//cin>>t;
while(t--)
{
solve();
}
return 0;
}一开始还是正常构建stjump表,之后对于查询,为了方便写代码,所以考虑让a节点固定是最深的节点。之后从高位到低位考虑,只要往上跳后层数还大于等于b节点,就往上跳即可。此时特判一下,若a已经等于b了,那么就直接返回即可。之后就是让a和b同时往上跳,最后再多跳一步即可。
三、tarjan算法解决LCA批量查询
这个算法真的牛逼orz
1.基本原理

首先,根据查询建图,同时存节点和编号,注意要建无向图,也就是一条查询对两个节点都连一条边。

之后去图上dfs,对于刚来到的节点u,先将visu设置为true,然后去节点u的子树。每棵子树遍历完回到节点u时,用并查集merge子树和节点u,并以节点u作为代表节点。当遍历完节点u的所有子树时,考虑所有和节点u有关的查询(u,x)。若x没来过,就先不处理这条查询,等到(x,u)再处理。若x来过,那么两节点的lca就是x集合的代表节点。
对于这个例子,先往下扎来到节点e,然后考虑所有和e相关的查询。此时因为节点f还没来过,那么就不处理这条查询了。之后回到节点b,用并查集merge节点b和节点e。

之后来到节点f,把考虑所有和f相关的查询,那么此时就可以处理查询(e,f)了,所以答案就是e所在集合的代表节点b。之后返回节点b,merge节点f和节点b。然后回到节点a,merge节点b和节点a。

之后一直往下扎到节点j,此时可以发现节点j的所有查询都查询不了。然后回到节点g,merge节点j和节点g。然后去节点k,此时可以发现查询(k,g)中节点g来过了,那么lca就是g集合的代表节点,就是g本身。

之后来到节点p时,查询(p,c)中节点c已经来过了,所以lca就是集合的代表元素c。然后查询(p,i)中节点i还没来过,所以不处理。最后查询(p,j)中节点j已经来过了,所以lca就是j所在集合的代表节点c。
之后回到节点h,查询(h,j)中节点j来过了,所以lca就是代表元素c。之后回到节点c,这里虽然这条查询已经处理过了,但再处理一遍也不会改变答案,所以再处理一遍也行。
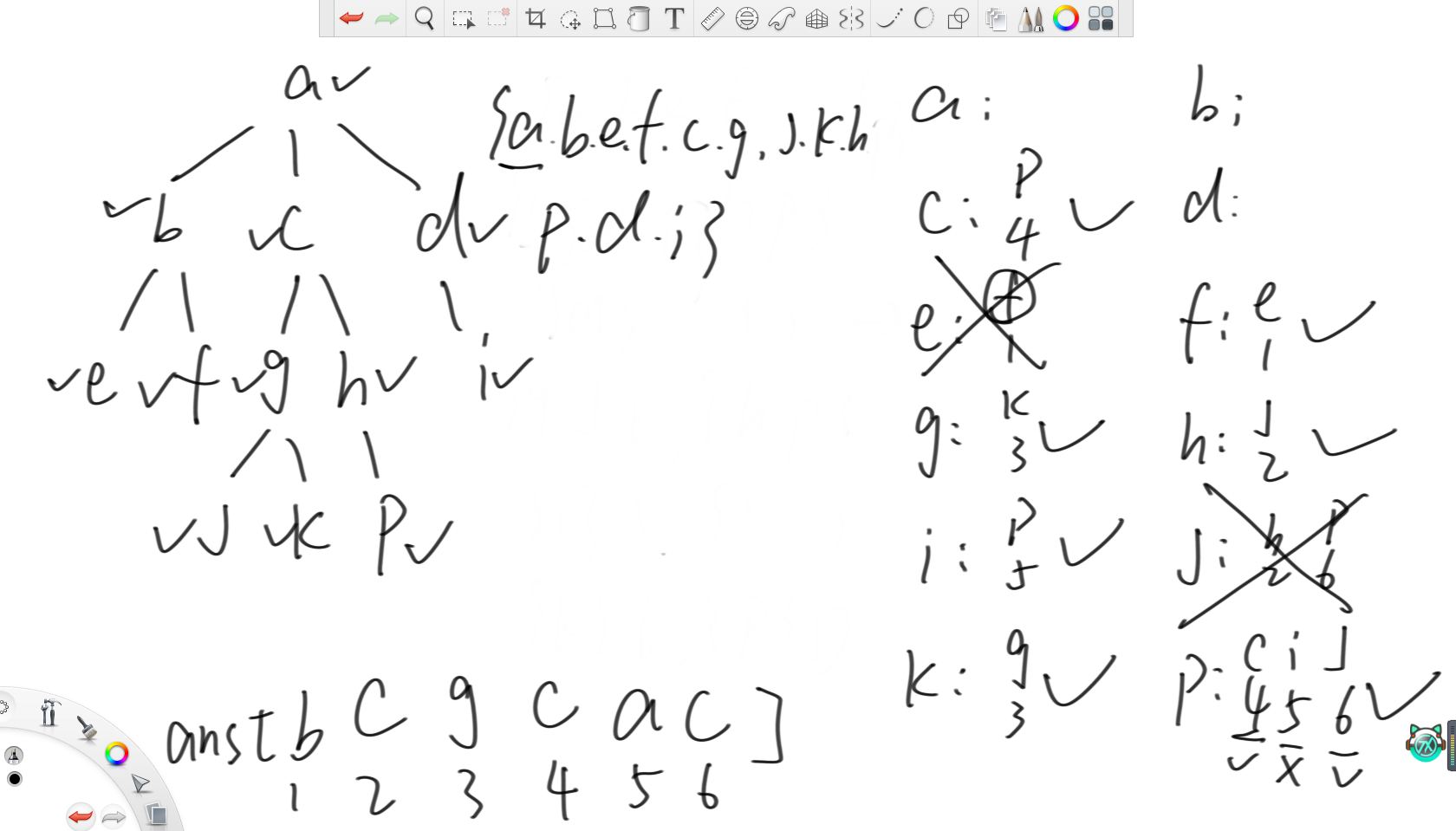
最后来到节点i时可以把和节点p的lca设置为p所在集合的代表元素,所以就是节点a。
2.【模板】最近公共祖先(LCA)
cpp
#include <bits/stdc++.h>
using namespace std;
/* /\_/\
* (= ._.)
* / > \>
*/
typedef long long ll;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int MAXN=5e5+5;
const int LIMIT=20;
int deep[MAXN];
int stjump[MAXN][LIMIT];
vector<vector<int>>g(MAXN);
int power;
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
void dfs(int u,int fa)
{
deep[u]=deep[fa]+1;
stjump[u][0]=fa;
for(int p=1;(1<<p)<=deep[u];p++)
{
stjump[u][p]=stjump[stjump[u][p-1]][p-1];
}
for(int v:g[u])
{
if(v!=fa)
{
dfs(v,u);
}
}
}
int lca(int a,int b)
{
//让a是更深的节点
if(deep[a]<deep[b])
{
int t=a;
a=b;
b=t;
}
for(int p=power;p>=0;p--)
{
if(deep[stjump[a][p]]>=deep[b])
{
a=stjump[a][p];
}
}
if(a==b)
{
return a;
}
for(int p=power;p>=0;p--)
{
if(stjump[a][p]!=stjump[b][p])
{
a=stjump[a][p];
b=stjump[b][p];
}
}
return stjump[a][0];
}
//树上倍增
void solve1()
{
int n,m,s;
cin>>n>>m>>s;
power=log2(n);
for(int i=1,u,v;i<n;i++)
{
cin>>u>>v;
g[u].push_back(v);
g[v].push_back(u);
}
dfs(s,0);
int a,b;
while(m--)
{
cin>>a>>b;
cout<<lca(a,b)<<endl;
}
}
//是否访问过
bool vis[MAXN];
//问题列表
vector<vector<pii>>ques(MAXN);
//答案
int ans[MAXN];
//并查集
int father[MAXN];
void build(int n)
{
for(int i=1;i<=n;i++)
{
father[i]=i;
}
}
int find(int i)
{
if(i!=father[i])
{
father[i]=find(father[i]);
}
return father[i];
}
//tarjan
void tarjan(int u,int fa)
{
vis[u]=true;
for(int v:g[u])
{
if(v!=fa)
{
tarjan(v,u);
//合并
father[v]=u;
}
}
//查问题列表答案
for(auto [v,idx]:ques[u])
{
if(vis[v])
{
ans[idx]=find(v);
}
}
}
//tarjan算法
void solve2()
{
int n,m,s;
cin>>n>>m>>s;
for(int i=1,u,v;i<n;i++)
{
cin>>u>>v;
g[u].push_back(v);
g[v].push_back(u);
}
build(n);
int a,b;
for(int i=1;i<=m;i++)
{
cin>>a>>b;
ques[a].push_back({b,i});
ques[b].push_back({a,i});
}
tarjan(s,0);
for(int i=1;i<=m;i++)
{
cout<<ans[i]<<endl;
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int t=1;
//cin>>t;
while(t--)
{
solve2();
}
return 0;
}代码其实还好,就是一个递归模拟上述过程。
四、题目
0.小结论
如果边的权值为正,假设节点a和节点b的最近公共祖先为节点c,那么a到b的路径长度就等于头节点到a的长度加上头节点到b的长度减去两倍的头节点到c的长度。
1.紧急集合 / 聚会
cpp
#include <bits/stdc++.h>
using namespace std;
/* /\_/\
* (= ._.)
* / > \>
*/
typedef long long ll;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int MAXN=5e5+5;
const int LIMIT=20;
vector<int>deep(MAXN);
int power;
vector<vector<int>>stjump(MAXN,vector<int>(LIMIT));
vector<vector<int>>g(MAXN);
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
void dfs(int u,int father)
{
deep[u]=deep[father]+1;
stjump[u][0]=father;
for(int p=1;(1<<p)<=deep[u];p++)
{
stjump[u][p]=stjump[stjump[u][p-1]][p-1];
}
for(int &v:g[u])
{
if(v!=father)
{
dfs(v,u);
}
}
}
int lca(int a,int b)
{
if(deep[a]<deep[b])
{
int t=a;
a=b;
b=t;
}
for(int p=power;p>=0;p--)
{
if(deep[stjump[a][p]]>=deep[b])
{
a=stjump[a][p];
}
}
if(a==b)
{
return a;
}
for(int p=power;p>=0;p--)
{
if(stjump[a][p]!=stjump[b][p])
{
a=stjump[a][p];
b=stjump[b][p];
}
}
return stjump[a][0];
}
void solve()
{
int n,q;
cin>>n>>q;
for(int i=0,u,v;i<n-1;i++)
{
cin>>u>>v;
g[u].push_back(v);
g[v].push_back(u);
}
//a,b,c三个点要么lca都是同一个节点
//要么两个点先汇聚到一个lca,再一起和另一个点汇聚到另一个lca上
//对于情况一,路程就是从头节点到三个点的距离,减去三倍的从头节点到lca的距离
//对于情况二,肯定是汇聚到两个点的lca上,否则两个点会多走一段距离
power=log2(n);
dfs(1,0);
int x,y,z;
while(q--)
{
cin>>x>>y>>z;
int l1=lca(x,y);
int l2=lca(x,z);
int l3=lca(y,z);
//若x和y的lca等于x和z的lca,那么要么三者的lca相同,要么x和y的更高
int high=l1!=l2?(deep[l1]<deep[l2]?l1:l2):l1;
int low=l1!=l2?(deep[l1]<deep[l2]?l2:l1):l3;
cout<<low<<" "<<1ll*(deep[x]+deep[y]+deep[z]-deep[low]-2*deep[high])<<endl;
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int t=1;
//cin>>t;
while(t--)
{
solve();
}
return 0;
}对于三个点,肯定要么三个点的lca都是同一个节点,要么两个点先走到这两个点的lca,再和第三个点一起汇聚到另一个lca上。对于第一种情况,距离就是头节点到三个点的距离,减去三倍的头节点到lca的距离。对于第二种情况,肯定是汇聚到两个点的lca上,否则这两个点就需要多走一段距离。
所以代码就是每次查一下三个点相互的lca,然后找出层数最高和最低的lca。那么若x和y的lca和x和z的lca不同,那么最高的lca一定出自这两个,那么用deep表比较一下即可。若相同,那么要么三者lca相同,要么x和y的更高。最低节点的判断类似。所以之后就是让三者汇聚到最低的lca上,然后距离就是头节点到三者的距离,减去头节点到汇聚点的距离,再减去两倍的到最高点的距离。
2.货车运输
cpp
#include <bits/stdc++.h>
using namespace std;
/* /\_/\
* (= ._.)
* / > \>
*/
typedef long long ll;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int MAXN=1e4+5;
const int MAXM=5e4+5;
const int LIMIT=21;
int power;
//边
vector<vector<int>>edges(MAXM,vector<int>(3));
//判断节点是否访问过
vector<bool>vis(MAXN);
//并查集
vector<int>father(MAXN);
//最大生成树建图
vector<vector<pii>>g(MAXN);
//ST表
vector<int>deep(MAXN);
vector<vector<int>>stjump(MAXN,vector<int>(LIMIT));
vector<vector<int>>stmin(MAXN,vector<int>(LIMIT));
int find(int i)
{
if(i!=father[i])
{
father[i]=find(father[i]);
}
return father[i];
}
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
void kruskal(int n,int m)
{
sort(edges.begin()+1,edges.begin()+m+1,[](vector<int>&x,vector<int>&y)
{
return x[2]>y[2];
});
for(int i=1,u,v,w,fu,fv;i<=m;i++)
{
u=edges[i][0];
v=edges[i][1];
w=edges[i][2];
fu=find(u);
fv=find(v);
if(fu!=fv)
{
father[fu]=fv;
g[u].push_back({v,w});
g[v].push_back({u,w});
}
}
}
void dfs(int u,int w,int fa)
{
vis[u]=true;
//第一个节点
if(fa==0)
{
deep[u]=1;
stjump[u][0]=u;
stmin[u][0]=1e9;
}
else
{
deep[u]=deep[fa]+1;
stjump[u][0]=fa;
stmin[u][0]=w;
}
for(int p=1;(1<<p)<=deep[u];p++)
{
stjump[u][p]=stjump[stjump[u][p-1]][p-1];
stmin[u][p]=min(stmin[u][p-1],stmin[stjump[u][p-1]][p-1]);
}
for(auto &[v,vw]:g[u])
{
if(!vis[v])
{
dfs(v,vw,u);
}
}
}
int lca(int a,int b)
{
//不连通
if(find(a)!=find(b))
{
return -1;
}
if(deep[a]<deep[b])
{
int t=a;
a=b;
b=t;
}
int ans=1e9;
for(int p=power;p>=0;p--)
{
if(deep[stjump[a][p]]>=deep[b])
{
ans=min(ans,stmin[a][p]);
a=stjump[a][p];
}
}
if(a==b)
{
return ans;
}
for(int p=power;p>=0;p--)
{
if(stjump[a][p]!=stjump[b][p])
{
ans=min(ans,min(stmin[a][p],stmin[b][p]));
a=stjump[a][p];
b=stjump[b][p];
}
}
ans=min(ans,min(stmin[a][0],stmin[b][0]));
return ans;
}
void solve()
{
int n,m;
cin>>n>>m;
for(int i=1;i<=m;i++)
{
cin>>edges[i][0]>>edges[i][1]>>edges[i][2];
}
//如果要让运量最大,可以考虑对每一个连通块求最大生成树
//之后可以考虑用st表维护最小值
power=log2(n);
for(int i=1;i<=n;i++)
{
father[i]=i;
}
kruskal(n,m);
//对每个连通块构建ST表
for(int i=1;i<=n;i++)
{
if(!vis[i])
{
dfs(i,0,0);
}
}
int q;
cin>>q;
int x,y;
while(q--)
{
cin>>x>>y;
cout<<lca(x,y)<<endl;
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int t=1;
//cin>>t;
while(t--)
{
solve();
}
return 0;
}这个题最难的是转化......
如果要让运量最大,那么肯定是要让路径上的边权最小值最大,所以每条边肯定是越大越好,所以可以去每个连通块里构建最大生成树。证明是,假如存在一条u到v的路径,使得这条路径上的最小边权比最大生成树上u到v的最小边权,设这条路径上的最小边权为a,树上的最小边权为b,那么就有a大于b。而又因为最大生成树是边权从大到小排序,所以a肯定是先于b被考虑的,而又因为a没有被考虑进最大生成树,那么就说明此时有其他更大的边使得u和v连通,所以不成立。
在构建完最大生成树后,就可以考虑用st表维护最小值,然后每次求lca时跟着求出最小值即可。
3.边权重均等查询
cpp
class Solution {
public:
typedef pair<int,int> pii;
const int MAXN=1e4+5;
const int MAXM=2e4+5;
const int MAXW=26;
//建图
vector<vector<pii>>g;
//weightCnt[i][w]:从头节点到i的路径中,权值为w的边有几条
vector<vector<int>>weightCnt;
//tarjan算法
vector<vector<pii>>ques;
vector<bool>vis;
//并查集
vector<int>father;
//lca
vector<int>lca;
void build(int n,int m)
{
g.resize(n);
weightCnt.resize(n,vector<int>(MAXW+1));
ques.resize(n);
vis.resize(n);
father.resize(n);
lca.resize(m);
for(int i=0;i<n;i++)
{
father[i]=i;
}
}
vector<int> minOperationsQueries(int n, vector<vector<int>>& edges, vector<vector<int>>& queries) {
int m=queries.size();
//因为w的范围很小,所以可以每次暴力求出现次数最多的边
//在a->lca->b中,w出现的次数就是
//头->a中w的次数+头->b中w的次数减去两倍的头->lca中W的次数
build(n,m);
for(int i=0,u,v,w;i<n-1;i++)
{
u=edges[i][0];
v=edges[i][1];
w=edges[i][2];
g[u].push_back({v,w});
g[v].push_back({u,w});
}
for(int i=0;i<m;i++)
{
ques[queries[i][0]].push_back({queries[i][1],i});
ques[queries[i][1]].push_back({queries[i][0],i});
}
tarjan(0,0,0);
vector<int>ans(m);
for(int i=0,a,b,c;i<m;i++)
{
a=queries[i][0];
b=queries[i][1];
c=lca[i];
//所有权值的边的次数
int allCnt=0;
//出现次数最多的权值的次数
int maxCnt=0;
for(int w=1;w<=MAXW;w++)
{
//a->c->b中该权值的边的数量
int wcnt=weightCnt[a][w]+weightCnt[b][w]-2*weightCnt[c][w];
maxCnt=max(maxCnt,wcnt);
allCnt+=wcnt;
}
ans[i]=allCnt-maxCnt;
}
return ans;
}
//tarjan算法+dfs统计词频
void tarjan(int u,int w,int fa)
{
//抄一遍父亲
for(int i=1;i<=MAXW;i++)
{
weightCnt[u][i]=weightCnt[fa][i];
}
weightCnt[u][w]++;
vis[u]=true;
for(auto &[v,nw]:g[u])
{
if(v!=fa)
{
tarjan(v,nw,u);
father[v]=u;
}
}
for(auto &[v,i]:ques[u])
{
if(vis[v])
{
lca[i]=find(v);
}
}
}
int find(int i)
{
if(i!=father[i])
{
father[i]=find(father[i]);
}
return father[i];
}
};这个题首先可以观察到,因为w的范围很小,所以每次可以暴力求出现次数最多的边,那么最小操作次数肯定就是把所有边都改成和出现次数最多的边一样。那么在a到lca再到b的路径中,w出现的次数就是从头节点到a中的次数加上头节点到b的次数再减去两倍的头节点到lca的次数。所以可以考虑用tarjan算法一遍求出所有查询的lca,同时求出头节点到每个节点路径上每个w的词频即可。
4.在传球游戏中最大化函数值
原来在力扣里可以这么写!
cpp
typedef long long ll;
const int MAXN=1e5+5;
const int LIMIT=34;
int power;
//给定k的二进制上1的个数
int m;
//bits[i]:从高到低第i个为1的位的位置
vector<int>bits(LIMIT);
//ST表
vector<vector<int>>stjump(MAXN,vector<int>(LIMIT));
vector<vector<ll>>stsum(MAXN,vector<ll>(LIMIT));
class Solution {
public:
void build(ll k)
{
power=0;
while((1ll<<power)<=(k>>1))
{
power++;
}
m=0;
for(int p=power;p>=0;p--)
{
if((1ll<<p)<=k)
{
bits[m++]=p;
k-=1ll<<p;
}
}
}
ll getMaxFunctionValue(vector<int>& receiver, ll k) {
int n=receiver.size();
//根据k建立stjump和stsum
//后续就可以在logk的时间里求出传到的位置和累加和
//之后枚举从每个人开始传即可
build(k);
for(int i=0;i<n;i++)
{
stjump[i][0]=receiver[i];
stsum[i][0]=receiver[i];
}
for(int p=1;p<=power;p++)
{
for(int i=0;i<n;i++)
{
stjump[i][p]=stjump[stjump[i][p-1]][p-1];
stsum[i][p]=stsum[i][p-1]+stsum[stjump[i][p-1]][p-1];
}
}
ll ans=0;
for(int i=0;i<n;i++)
{
//当前位置
int cur=i;
ll sum=i;
//枚举每个k的二进制为1的位
for(int j=0;j<m;j++)
{
sum+=stsum[cur][bits[j]];
cur=stjump[cur][bits[j]];
}
ans=max(ans,sum);
}
return ans;
}
};这个题就和树没啥关系了,属于是st表题。
因为k是固定的,所以可以考虑根据k建立stjump和stsum表,那么就可以在O(logk)的时间里求出传到的位置和总和,那么之后去枚举从每个人开始传即可。这里可以先预处理出k的每一个二进制状态是1的位,后续就不用遍历每一位了。
5.Bingbong的回文路径
经典小白月赛最后一道超难题......
cpp
#include <bits/stdc++.h>
using namespace std;
/* /\_/\
* (= ._.)
* / > \>
*/
typedef long long ll;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int MAXN=1e5+5;
const int LIMIT=17;
int power;
int log2(int n)
{
int ans=0;
while((1<<ans)<=(n>>1))
{
ans++;
}
return ans;
}
//节点数字
vector<int>s(MAXN);
//图
vector<vector<int>>g(MAXN);
//高度
vector<int>deep(MAXN);
vector<vector<int>>jump(MAXN,vector<int>(LIMIT));
const ll k=499;
//k的若干次方
vector<ll>kpow(MAXN);
//stup[u][p]:从u节点出发,往上跳2的p次方的字符串哈希值
vector<vector<ll>>stup(MAXN,vector<ll>(LIMIT));
//stdown[u][p]:从某个父亲节点出发,往下走2的p次方到u节点的字符串哈希值
vector<vector<ll>>stdown(MAXN,vector<ll>(LIMIT));
void build(int n)
{
power=log2(n);
kpow[0]=1;
for(int i=1;i<=n;i++)
{
kpow[i]=kpow[i-1]*k;
}
}
void dfs(int u,int fa)
{
deep[u]=deep[fa]+1;
jump[u][0]=fa;
stup[u][0]=stdown[u][0]=s[fa];
for(int p=1,v;(1<<p)<=deep[u];p++)
{
v=jump[u][p-1];
jump[u][p]=jump[v][p-1];
//从u往上跳2的p-1次方步的哈希值是高位,要乘以k的p-1次方左移
stup[u][p]=stup[u][p-1]*kpow[1<<(p-1)]+stup[v][p-1];
//从v往下走2的p-1次方步的哈希值是高位,要乘以k的p-1次方左移
stdown[u][p]=stdown[v][p-1]*kpow[1<<(p-1)]+stdown[u][p-1];
}
for(auto v:g[u])
{
if(v!=fa)
{
dfs(v,u);
}
}
}
int lca(int a,int b)
{
if(deep[a]<deep[b])
{
int t=a;
a=b;
b=t;
}
for(int p=power;p>=0;p--)
{
if(deep[jump[a][p]]>=deep[b])
{
a=jump[a][p];
}
}
if(a==b)
{
return a;
}
for(int p=power;p>=0;p--)
{
if(jump[a][p]!=jump[b][p])
{
a=jump[a][p];
b=jump[b][p];
}
}
return jump[a][0];
}
//从from走到mid,再从mid下方的节点走到to
ll Hash(int from,int mid,int to)
{
//往上爬的哈希值
ll up=s[from];
//往上爬
for(int p=power;p>=0;p--)
{
if(deep[jump[from][p]]>=deep[mid])
{
up=up*kpow[1<<p]+stup[from][p];
from=jump[from][p];
}
}
if(to==mid)
{
return up;
}
ll down=s[to];
//目前下扎的高度
int height=1;
for(int p=power;p>=0;p--)
{
if(deep[jump[to][p]]>deep[mid])
{
//往下扎的部分为高位
down=stdown[to][p]*kpow[height]+down;
height+=1<<p;
to=jump[to][p];
}
}
return up*kpow[height]+down;
}
//考虑用字符串哈希快速判断是否回文
bool isPalindrome(int a,int b)
{
int c=lca(a,b);
ll hash1=Hash(a,c,b);
ll hash2=Hash(b,c,a);
return hash1==hash2;
}
void solve()
{
int n;
cin>>n;
char c;
for(int i=1;i<=n;i++)
{
cin>>c;
//注意!!字符串哈希要从1开始!!
s[i]=c-'a'+1;
}
for(int i=1,fa;i<=n;i++)
{
cin>>fa;
g[i].push_back(fa);
g[fa].push_back(i);
}
build(n);
dfs(1,0);
int q;
cin>>q;
int u,v;
while(q--)
{
cin>>u>>v;
cout<<(isPalindrome(u,v)?"YES":"NO")<<endl;
}
}
int main()
{
ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);
int t=1;
//cin>>t;
while(t--)
{
solve();
}
return 0;
}因为涉及到回文,所以考虑用字符串哈希快速判断回文。因为对于一条路径,需要获取正序和逆序两种字符串哈希,所以就可以用st表去维护字符串哈希值。又因为从u到lca是往上跳,从lca到v是往下扎,所以要同时维护往上走和往下扎的st表。其中stup表好理解,就是从u往上走2的p次方步的字符串哈希值,但重点是stdown表,就是从u往上走2的p次方步的节点开始走到u的字符串哈希值。需要注意的是,整合时up和down高位和低位不同,以及求整条路径的哈希值时,往下扎时每一步需要乘以k的当前走过的高度height次方。
总结
加油加油!!