模型介绍
Qwen3-Embedding-0.6B 是阿里巴巴通义千问团队基于Qwen3基础模型开发的文本嵌入模型,专门为文本表示、检索和重排序任务而设计。该模型在保持高效计算的同时,提供了卓越的多语言文本理解能力。
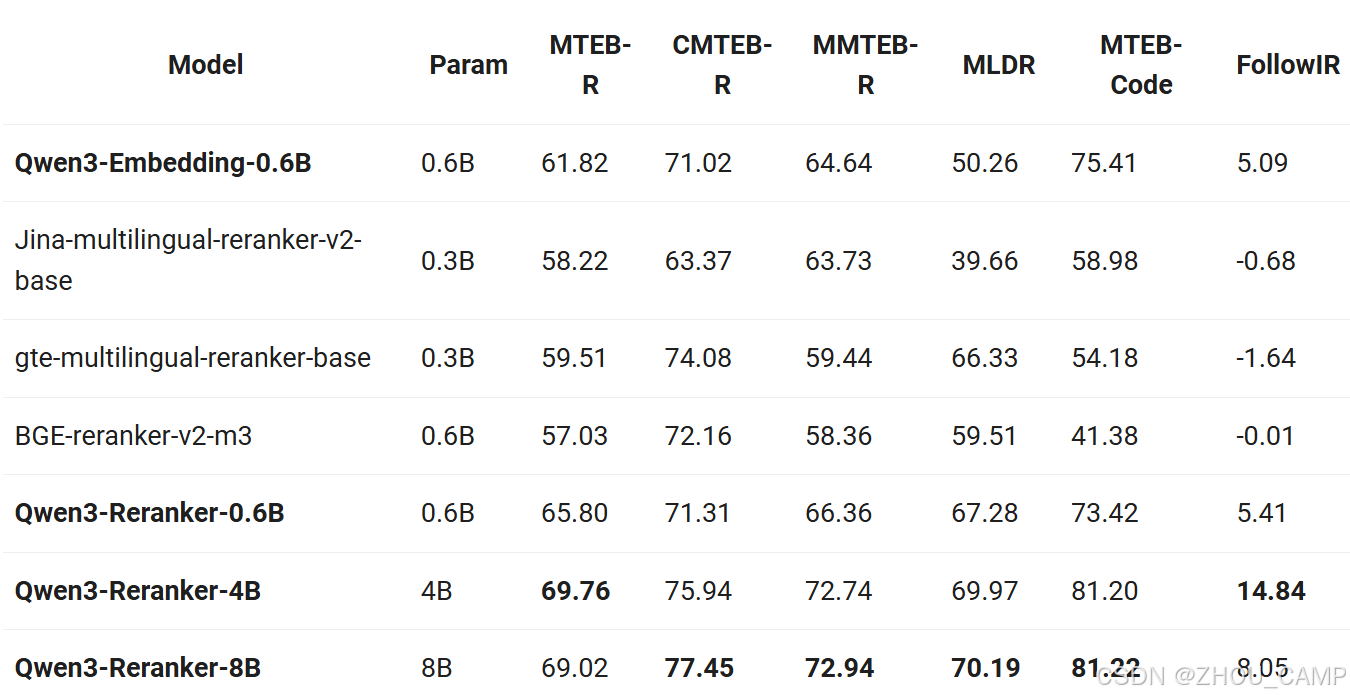
模型性能

模型加载
python
import torch
import torch.nn.functional as F
from torch import Tensor
from modelscope import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')模型结构
python
model Qwen3Model(
(embed_tokens): Embedding(151669, 1024)
(layers): ModuleList(
(0-27): 28 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): Linear(in_features=1024, out_features=2048, bias=False)
(k_proj): Linear(in_features=1024, out_features=1024, bias=False)
(v_proj): Linear(in_features=1024, out_features=1024, bias=False)
(o_proj): Linear(in_features=2048, out_features=1024, bias=False)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
)
(mlp): Qwen3MLP(
(gate_proj): Linear(in_features=1024, out_features=3072, bias=False)
(up_proj): Linear(in_features=1024, out_features=3072, bias=False)
(down_proj): Linear(in_features=3072, out_features=1024, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((1024,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((1024,), eps=1e-06)
)
)
(norm): Qwen3RMSNorm((1024,), eps=1e-06)
(rotary_emb): Qwen3RotaryEmbedding()
)模型配置
python
model.configQwen3Config {
"architectures": [
"Qwen3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151643,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 1024,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_types": [
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention",
"full_attention"
],
"max_position_embeddings": 32768,
"max_window_layers": 28,
"model_type": "qwen3",
"num_attention_heads": 16,
"num_hidden_layers": 28,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000,
"sliding_window": null,
"tie_word_embeddings": true,
"torch_dtype": "float32",
"transformers_version": "4.55.2",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151669
}模型使用
python
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())[[0.7645569443702698, 0.14142519235610962], [0.1354975402355194, 0.5999550819396973]]