引言
在动画制作领域,传统流程复杂且劳动强度大,涵盖剧本创作、分镜设计、角色与场景设计、动画制作、配音以及最终剪辑等多个创作阶段。这一过程不仅需要大量专业人员参与,还要求不同团队间紧密协作,导致成本高昂、制作周期漫长。
近年来,生成式人工智能取得了显著进展,例如用于动画生成的 AniSora 等基础模型,在特定任务中展现出了令人印象深刻的能力。然而,这些方法在特定领域各有优劣,在智能体驱动的视频生成中,难以维持一致性且精细可控性欠佳。因此,开发一个全自动的长篇动画生成系统仍是一项亟待解决的挑战,尤其是在选择合适的控制条件以及确保跨阶段内容一致性方面。
为此,我们提出 AniME,一种导演驱动的多智能体框架。该框架通过引入定制化模型选择MCP机制,为不同环节的专用智能体配置定制化工具箱,实现了任务分解、跨阶段一致性控制以及迭代式反馈优化。AniME 借鉴真实动画工作室的生产流程,强调全局调度与质量控制,使长篇动画的自动化生成成为可能。
All In One模型AniSora V3开源
在介绍AniME工作流前,先介绍一下团队近期开源的动画视频生成模型AniSora V3. 此前AniSora已经发布了2个版本的模型,在国内外社区中获得了比较好的口碑和反馈。本次,V3版本有了比较大的升级,量化版本支持单卡4090推理,单台4卡4090生成5秒360p视频仅需30秒,单台8卡A800仅需8秒。
V3版本除了在动态性、画面美感、指令遵从等方面进行了增强外,还结合动画制作实际流程中的相关诉求,增加了多种模态的交互能力,更加贴合动画制作流程本身,为长视频创作提供了有力支撑。
角色单张正面立绘生成360度视频



任意帧引导
该功能在V1版本中已经支持,V3版本中该功能的指令遵从性得到了进一步增强
可以通过首帧、尾帧或任意中间帧,根据剧情生成视频
风格转绘
输入视频 |
|---|
线稿提取 |
风格化 |
多模态引导
| 首帧+多模态输入 |
|---|
  The boy in red and the girl in red are fencing in the scene. The boy in red and the girl in red are fencing in the scene. |
| 输出视频 |
 |
| 首帧+多模态输入 |
  A worn-out red robot flings its arm away, only to have it fly back and reassemble with a new arm holding a sword. A worn-out red robot flings its arm away, only to have it fly back and reassemble with a new arm holding a sword. |
| 输出视频 |
 |
| 首帧+audio |
 |
| 输出视频 |
| 详见:mp.weixin.qq.com/s/S8pJ_CeQg... |
极低分辨率超分
支持90p到720p/1080p的超分,可以用更少的抽卡时间,生成细节更丰富的视频:
详见:mp.weixin.qq.com/s/S8pJ_CeQg...
AniSora为动画视频创作提供了多种交互功能,但它只能生成单个镜头。我们通过AniME组织整体工作流程,实现长视频的创作。
AniME 架构
AniME 将从故事到视频的任务分解为多个层级阶段,由导演智能体(Director Agent)统筹调度,多个专用智能体(Specialized Agents)协同完成,系统架构如图1所示。每个智能体 Ai 都有明确的输入类型 Ii 、输出类型 Oi 以及本地的模型上下文协议(MCP)工具箱 ,智能体之间通过结构化 JSON 消息进行交互。
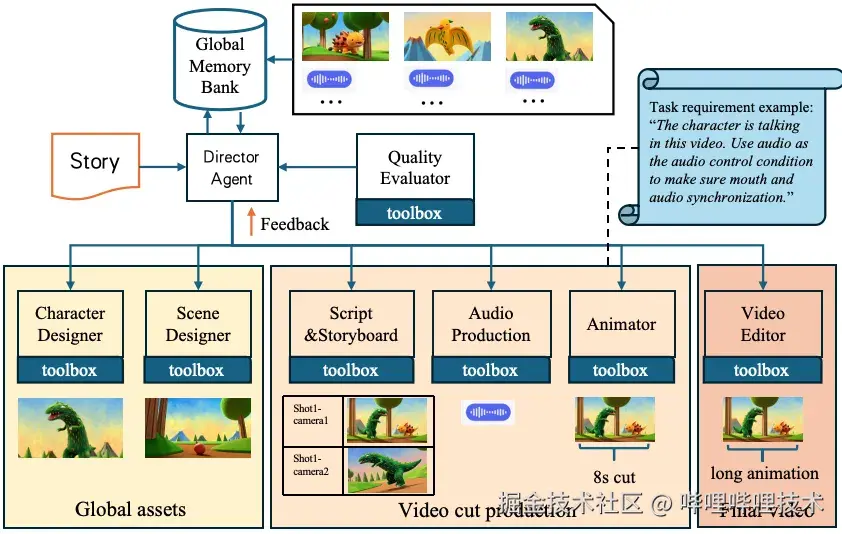
图片 1 AniME架构图
导演智能体与多智能体协作流程
导演智能体是 AniME 框架的中央控制器,负责管理全局工作流程和质量保证。它将输入的故事分解为任务工作流,为各个智能体分配子任务,检查每个专业智能体的工作质量,并维护一个全局资产记忆库(Asset Memory Bank)存储统一的角色、场景、风格等资产,保证跨镜头一致性。
- 导演工作流程:给定一个长篇故事 R,导演通过分割过程将其按层级分解为场景和镜头,并确定视觉风格 Sv 和声学设置风格 Sa 。随后,利用链式思维提示生成初始任务列表 T,每个任务都按照下游智能体的格式明确规定了输入 / 输出规格。导演还维护着一个工作流图 W=(N,E),其中每个节点 n∈N对应一个制作任务,边 E则编码了明确的依赖关系。 具体算法流程如图2所示

图片 2 AniME多智能体协作算法流程图
- 资产记忆管理:资产记忆库存储经过导演审批后的资产,确保整个流程中的一致性和可重用性。每个表格都可查询、有版本控制,能够通过语义相似性进行检索。角色表格不仅存储参考图像,还存储参考风格和声音样例,以确保动画保持视觉保真度。 为防止偏差,导演保持对全局资产的单一写入权限,同时允许下游专家智能体进行读取访问。
专业智能体与模型选择MCP 机制
AniME 参考真实动画制作流程,对应一个创作阶段设计了专业智能体。每个专业智能体都利用专用的 MCP模型工具箱,可以根据任务需求自适应地选择模型。
专业智能体
剧本和分镜智能体(Script and Storyboard Agent):该智能体将叙事文本转换为时间序列的镜头,主要执行三个关键步骤:一是利用LLM解析将文本分割为场景和镜头;二是进行相机规划,包括镜头类型、轨迹和过渡方式;三是进行参考素材检索,通过一系列条件生图模型生成关键帧。该智能体可根据需求在多种工具中自适应选择。其中文本到图像工具适用于空的定场镜头,虽简单快速但布局控制有限;参考图像生成工具能维持角色身份一致性,适用于以对话为中心的面板,但无法生成空的定场镜头;布局引导生成工具则适用于精确的多角色或物体密集型面板,构图准确但计算成本较高。此外,基于大型语言模型(LLM)的分割、相机规划和布局规划模块负责协调镜头级别的结构。
角色智能体(Character Designer):从文本描述和风格向量出发,通过文生图模型生成角色的多视角图像。角色参考图包括多个视角,确保侧面和背面轮廓与标准正面视图匹配。 在工具选择上,该智能体主要利用参考图像生成来确保一致的角色身份,多视角合成和超分模块则用于确保多角度一致性和图像清晰度。
场景智能体(Scene Designer):负责生成故事拍摄环境和背景,其输出包括可在多个场景中重用的分层资产。 工具选择方面,场景智能体优先采用布局引导生成来实现精确的物体放置,采用深度引导图像生成来创建空间连贯的场景,采用重新照明模型来维持时间上的照明一致性。文本到图像工具可选择性地生成广泛的定场镜头,但对构图的控制较少。
动画师(Animator):从关键帧、姿势和相机轨迹合成运动序列,主要使用关键帧 / 音频 / 姿势 / 相机条件视频生成模型。对于语音驱动的情景,该智能体将关键帧条件视频扩散与音频驱动的嘴唇同步相结合。为了维持时间连贯性,可以使用光流引导和运动插值。 对于无语音场景,该智能体主要通过首、尾帧驱动的视频生成模型来生成片段。
音频制作智能体(Audio Production Agent):管理对话、音效和音乐。它采用说话人条件的文本转语音(TTS)生成特定角色的声音。背景音乐通过文本到音乐生成来创作,然后由音频混合器平衡语音、音乐和音效。 此智能体在说话人条件的 TTS、文本到音乐生成和音频混合器程序中进行选择。
视频编辑智能体(Video Editor Agent):将所有资产整合为连贯的最终视频。自动化编辑工具会设计剪辑和过渡效果,通过 FFmpeg 的多遍编码生成最终视频。在此阶段支持人机交互式操作,以进行精细调整。
质量评估智能体(Quality Evaluator Agent):运用多种多模态评分模型对各个环节的效果进行打分。文本到视频相似性评分、身份验证、视听内容对齐,使用视觉语言模型(VLM)进行叙事一致性评估,并且对视频进行抽帧,进行身份验证以防止ID偏移。确保生成的序列符合预期的故事情节。导演智能体会根据评估分数决定下游智能体的任务是否需要重新进行。
模型选择MCP机制
在 AniME 中,模型上下文协议(MCP)使专业智能体能够根据导演提供的上下文自主选择和调用最适合其任务的工具。例如,当导演向分镜智能体发送场景描述后,剧本和分镜智能体首先生成分镜描述并选择图像生成工具,为每个镜头生成包含所选工具、提示、参考和注释的结构化 JSON 输出。通过 MCP,分镜智能体能够根据任务需求和场景上下文调整其工具选择,无需人工干预即可高效、高质量地生成分镜。导演的作用仍然是提供高级别的场景上下文,而 MCP 则管理专业智能体如何在内部协调其工具。 表1展示了对于导演智能体切分的场景片段,Script & Storyboard 智能体创作各个分镜时的生图工具选择过程。其生成条件的选择由场景的构图、一致性需求进行决策。
| a) scene_YX01_shot_01 |
|---|
 |
| {"shot_id":"scene_YX01_shot_01","tool":"reference_image_generation","prompt": "Ye holding a blue-and-white porcelain cup, tilting head to drink","reference_images":"assets/char_YX_front.png"} |
| b) scene_YX01_shot_02 |
 |
| {"shot_id":"scene_YX01_shot_02","tool":"layout_guided_generation","prompt":"System AI angrily stopping Ye","layout_bboxes":{"object":"Ye Xuan","bbox":\[100,300,400,900},{"object":"System AI","bbox":600,350,900,850,}]} |
| c) scene_YX01_shot_03 |
 |
| {"shot_id":"scene_YX01_shot_03","tool":"reference_image_generation","prompt":"Close-up of Ye's facial expression reacting to AI",reference_images":"assets/char_YX_front.png" } |
表格 1 StoryBoard Agent的自动分镜示例:"在玄夜的修炼室里,他双手捧起青花瓷杯仰头欲饮,人工智能气急败坏地阻止他,叫他快停下。 "
借助这一机制以及各智能体的协同工作,AniME 能够顺利完成从故事脚本到最终视频的生成流程,各环节衔接紧密,有效保障了生成内容的质量与一致性。
效果
AniME的多智能体协作已经用于内部的端到端动漫内容生成。例如对于小说片段:"一位算命先生曾说我生日那天会走大运,一飞冲天。可没想到,那天我居然被车撞了......然后直接被吸进了一个超级吞噬系统。在这个系统里,我叫玄夜,是个气海被毁的倒霉蛋,而且马上就要被天元宗圣女休夫了。 " AniME各模块的工作流程及输出如示意图2所示。通过各智能体协作,该片段可以自动化转换为长动画视频片段。
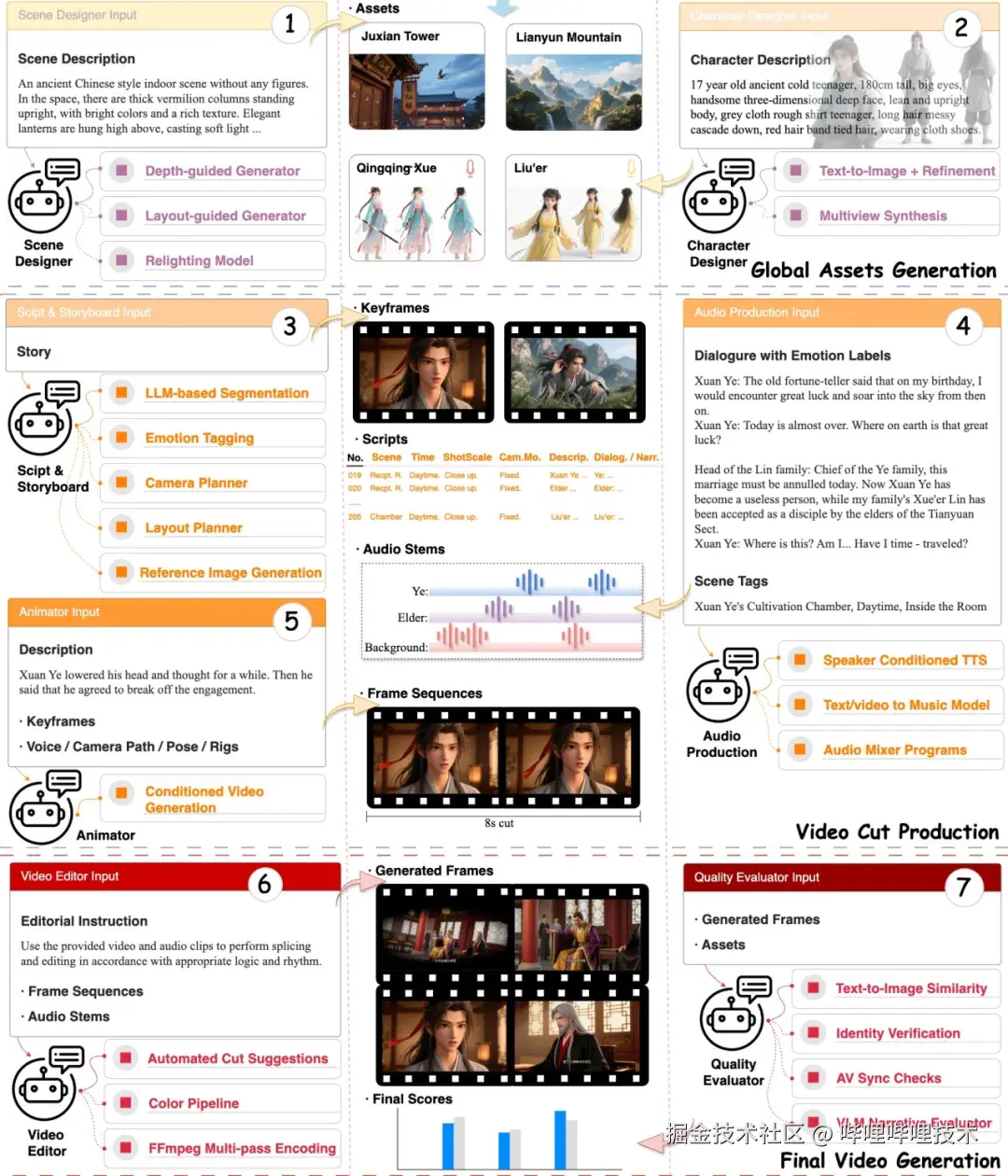
图片 2 Story驱动的AniME全流程视频生成效果演示
最终视频效果如下:
www.bilibili.com/video/BV1ip...
总结
本文提出了 AniME,一个导演驱动的多智能体长篇动画生成框架。通过引入模型选择MCP 机制,使不同智能体能够自主选择最优生成方式,实现了从文本故事到最终视频的全流程自动化。AniME 在保证风格一致性、角色身份保持和跨场景叙事连贯性方面展现出强大能力,推动了生成式 AI 在长篇动画制作中的落地。
ha t
1. Anthropic. 2024. Introducing the Model Context Protocol. Retrieved Aug 18, 2024 from www.anthropic.com/news/model-...
2. Chenpeng Du, Yiwei Guo, Hankun Wang, et al . 2025. Vall-t: Decoder-only generative transducer for robust and decoding-controllable text-to-speech. In ICASSP.
3. Yudong Jiang, Baohan Xu, Siqian Yang, et al . 2024. Anisora: Exploring the frontiers of animation video generation in the sora era. arXiv:2412.10255 (2024).
4. Yunxin Li, Haoyuan Shi, Baotian Hu, et al . 2024. Anim-director: A large multimodal model powered agent for controllable animation video generation. In SIGGRAPH Asia.
5. Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, et al . 2024. Tango 2: Aligning-based text-to-audio generations through direct preference optimization. In ACM MM.
6. Haoyuan Shi, Yunxin Li, Xinyu Chen, et al. 2025. AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation. arXiv:2506.10540 (2025).
7. Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. 2025. Automated movie generation via multi-agent cot planning. arXiv:2503.07314 (2025).
8. Haotian Xia, Hao Peng, Yunjia Qi, et al. 2025. StoryWriter: A Multi-Agent Framework for Long Story Generation. arXiv:2506.16445 (2025).
9. Ling Yang, Zhaochen Yu, Chenlin Meng, et al. 2024. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. In ICML.
-End-
作者丨太白金星、高树、HarryJ