【论文阅读】Deepseek-VL:走向现实世界的视觉语言理解
文章目录
发展过程 deepSeek LLM-MOE-Math-V2-V3-R1
在学习前,我们需要先了解MOE所带来的意义
MOE
混合专家模型 (MoE) 的引入使得训练具有数千亿甚至万亿参数的模型成为可能
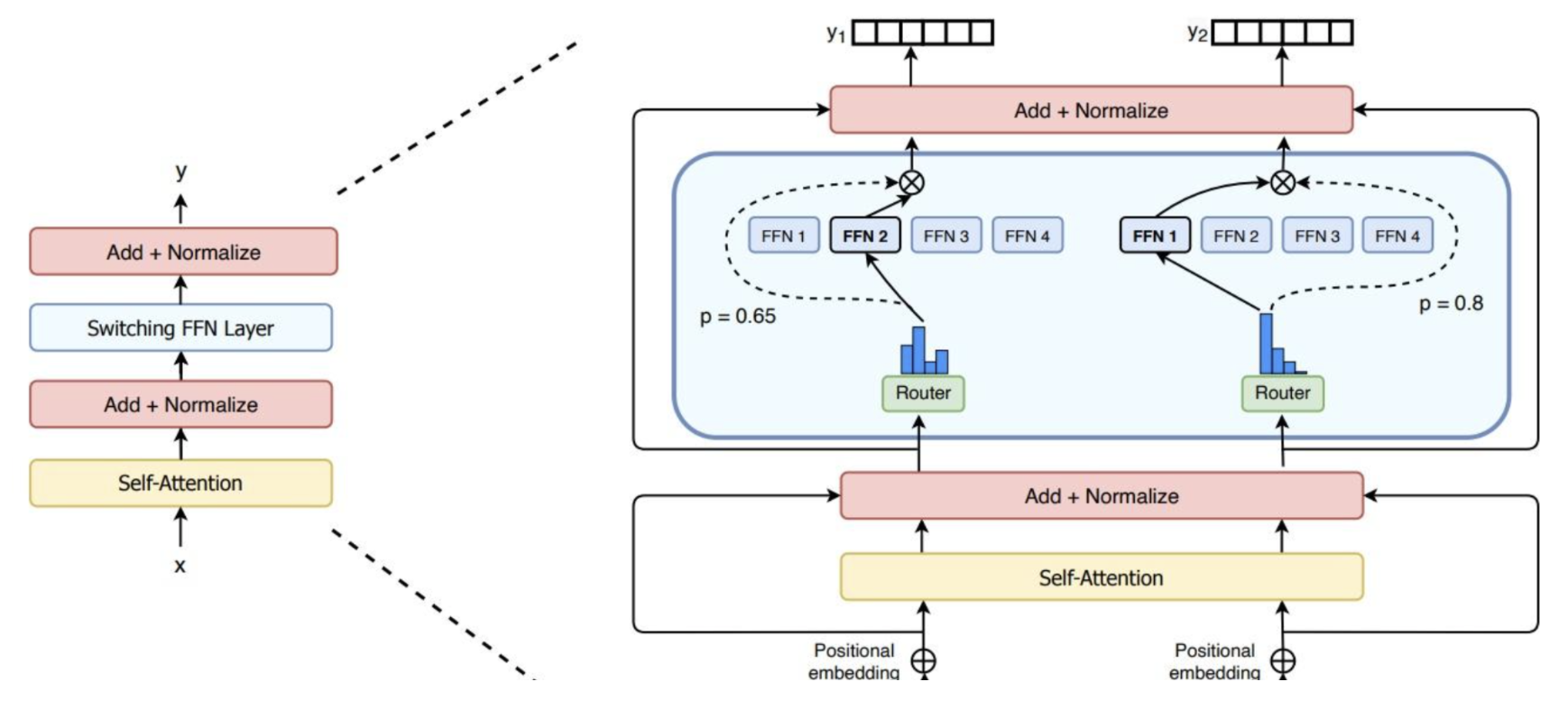
简单来说 就是将原有的FFN结构来进行替换为多个FFN(专家),他们之间的权重值是不同的
GShard 将在编码器和解码器中的每个前馈网络 (FFN) 层中的替换为使用 Top-2 门控的混合专家模型 (MoE) 层
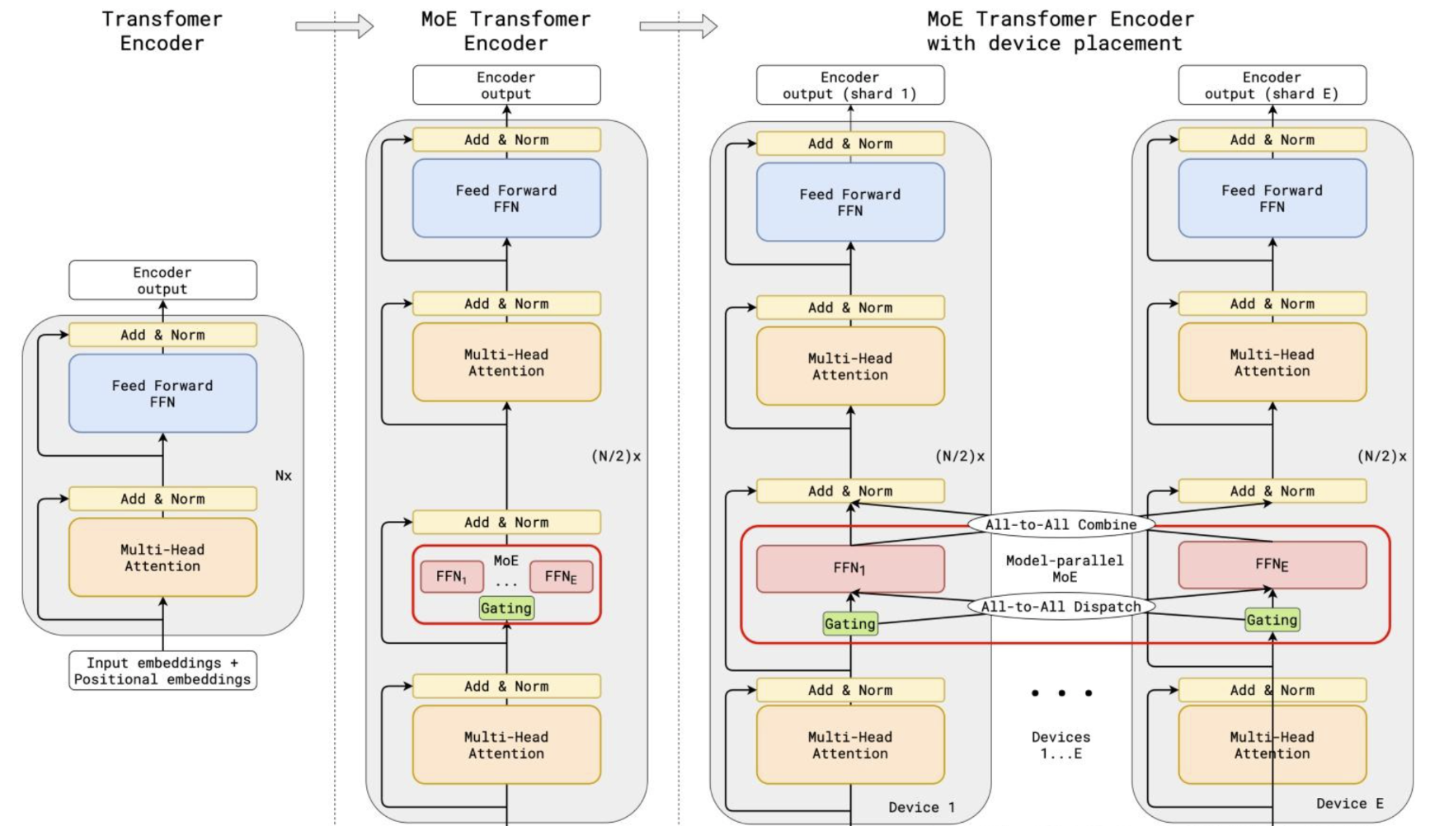
专家容量是 MoE 中最重要的概念之一 。为什么需要专家容量呢?因为所有张量的形状在编译时是静态确定的,无法提前知道多少Token会分配给每个专家,因此需要一个固定的容量因子。
专家学习特点
ST-MoE 的研究者们发现,编码器中不同的专家倾向于专注于特定类型的Token或浅层概念
特性:
- 某些专家可能专门处理标点符
- 而其他专家则专注于专有名词等
- 解码器中的专家通常具有较低的专业化程度
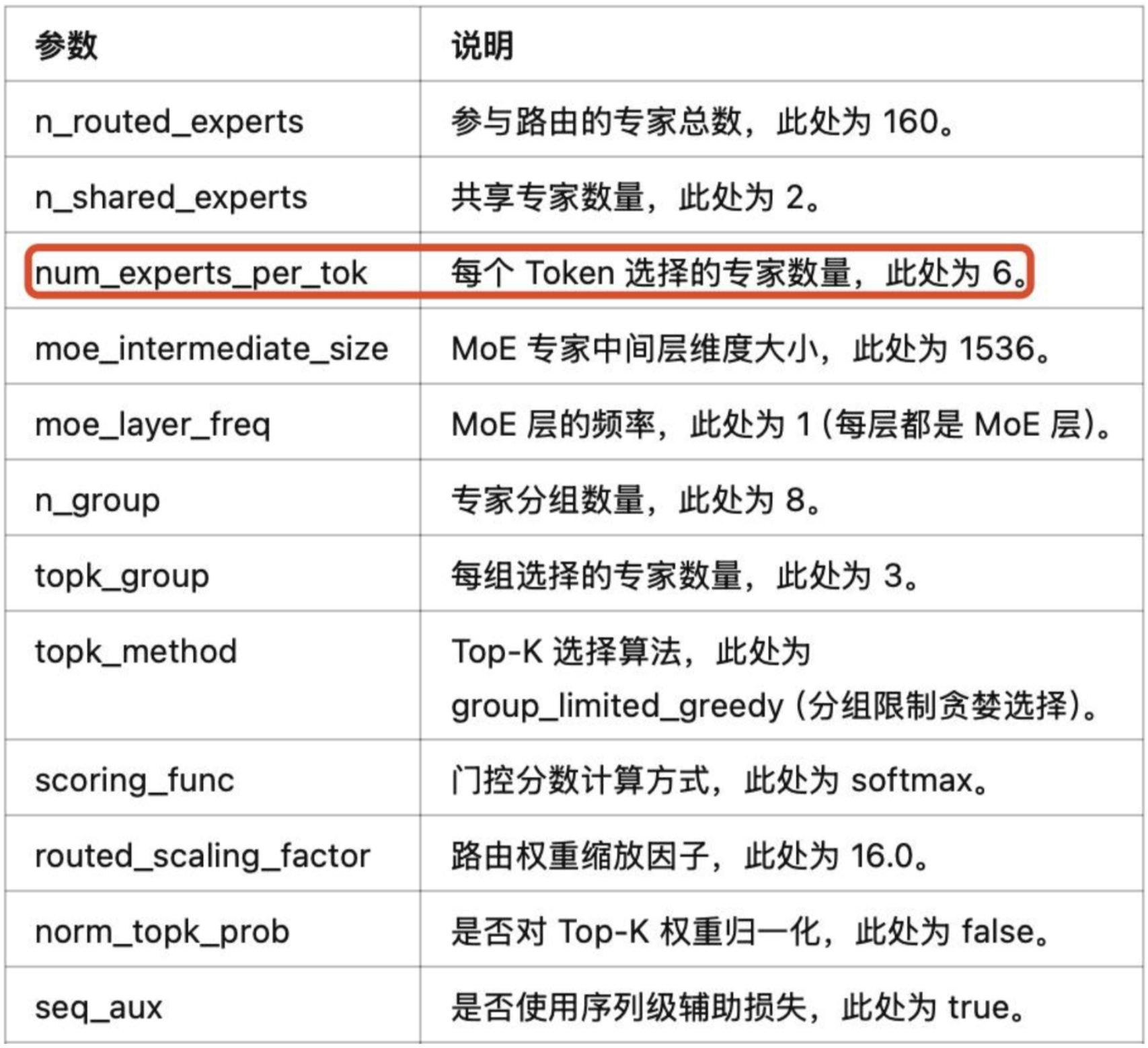
我们预计使用deepseek v2模型 MOE具体参数如下
python
{
// 部分参数省略
"hidden_act": "silu",
"hidden_size": 5120,
"initializer_range": 0.02,
"intermediate_size": 12288,
"model_type": "deepseek_v2",
"moe_intermediate_size": 1536,
"moe_layer_freq": 1,
"n_group": 8,
"n_routed_experts": 160,
"n_shared_experts": 2,
"norm_topk_prob": false,
"num_experts_per_tok": 6,
"num_hidden_layers": 60,
"num_key_value_heads": 128,
"topk_group": 3,
"topk_method": "group_limited_greedy",
}
专家其实就是参数量更少的 FFN/MLP 结构,和 llama 中结构一样,只是参数量和计算量更少了
Deepseek-VL
关键方面构建:
- Data Construction
- Model Architecture
- Training Strategy
我们在开发模型时追求在真实世界场景中的熟练性能,包括广泛的预训练,基于用例分类的仔细数据策展,高分辨率处理的模型架构设计,以及一个平衡多模态的训练策略
可以引导模型从1B扩展到7B
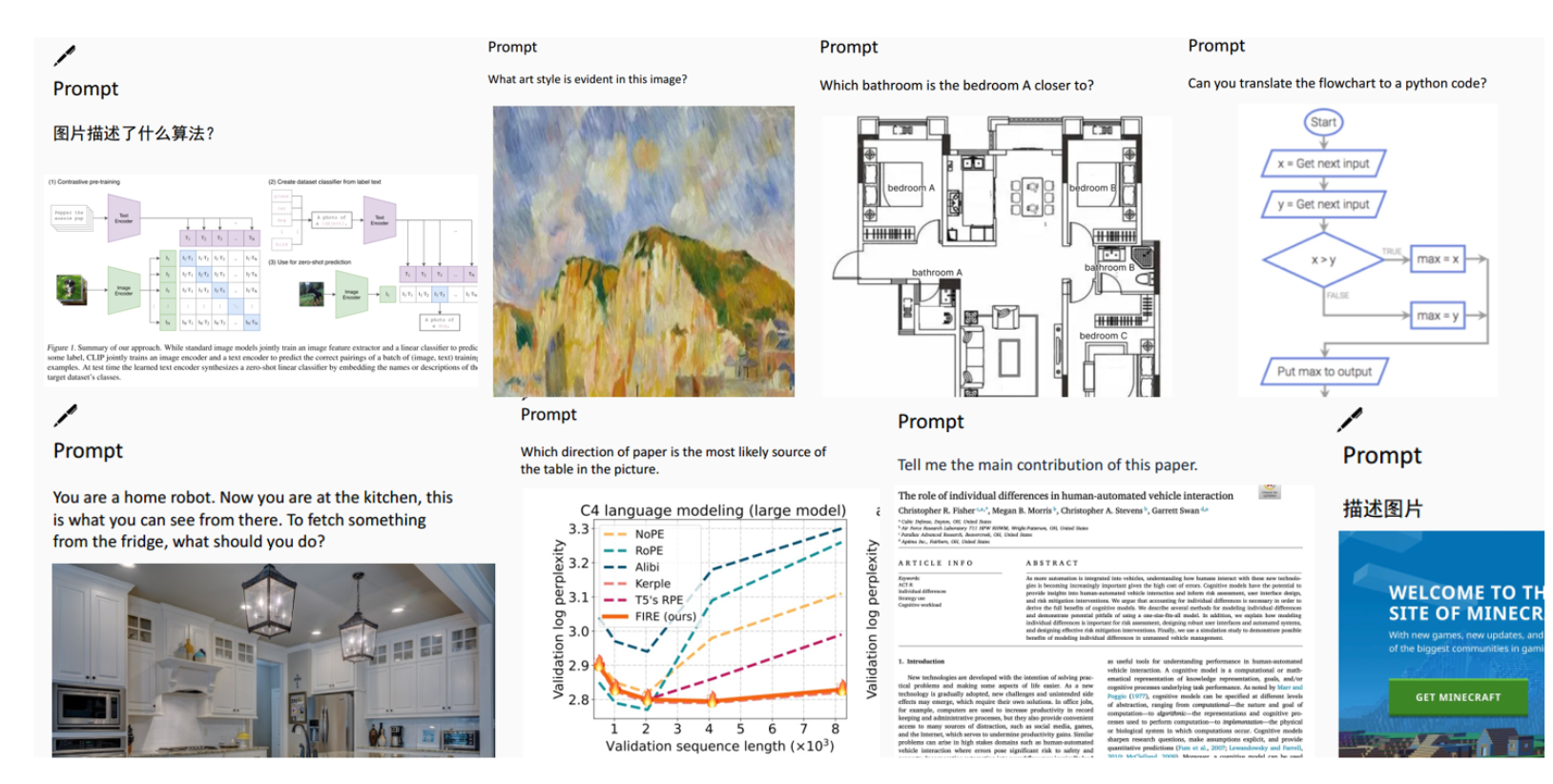
体现了deepseek-VL的多种理解和处理能力
混合方法有效地将1024×1024分辨率的图像(在大多数用例中已经足够)压缩为576个token
Data Construction:
- 视觉语言预训练数据
- 视觉语言监督微调数据
完整数据集的详细分类,分为以下几类:
- 交错的图像
- 表格和图表数据
- Web Code数据
- 文档光学字符识别(OCR)数据
- Text-only corpus
系统包含三个模块:
- 一个混合视觉编码器
- 一个视觉适配器
- 一个语言模型
混合视觉编码器
采用SigLIP作为视觉编码器,从视觉输入中提取高级语义特征表示
CLIP系列模型受到其相对低分辨率输入的限制
妨碍了他们处理需要更详细的低级功能
混合视觉编码器结合了SAM-B和SigLIP-L编码器,高效地编码高分辨率1024 x 1024图像,同时保留语义和详细信息
这些视觉令牌具有增强高级语义视觉识别和低级语义视觉识别的巨大能力水平的视觉基础任务
视觉语言适配器
两层混合MLP来桥接视觉编码器和LLM
不同的单层MLP分别用于处理高分辨率特征和低分辨率特征。随后,这些特征沿其维度沿着,然后通过另一层MLP转换到LLM的输入空间。
语言模型
语言模型建立在DeepSeek LLM
一系列DeepSeek-VL模型。鉴于目标是使用多模态和语言进行联合预训练,从DeepSeek的预训练模型中选择一个中间检查点继续预训练
训练阶段
我们在三个连续的阶段训练我们的DeepSeek-VL:
- 视觉语言Adaptor预热
- 联合视觉语言预训练
- 监督微调
Stage 1: Training Vision-Language Adaptor
这一阶段的主要目标是在嵌入空间内建立视觉和语言元素之间的概念联系,从而促进通过大语言模型(LLM)对图像中所描绘的实体的全面理解。
其中视觉编码器和LLM在此阶段保持冻结,同时只允许视觉语言适配器内的可训练参数
利用包括从ShareGPT 4V获得的125万个图像-文本配对字幕的数据集,沿着250万个文档OCR渲染对来训练VL适配器
Stage 2: Joint Vision-Language pretraining
理解多模态输入。我们保持视觉编码器冻结,并优化语言模型和VL适配器。
设计了一种简单而有效的联合语言-多模态训练策略。在训练过程中,我们不仅进行多模态数据训练,还将大部分语言数据纳入训练。
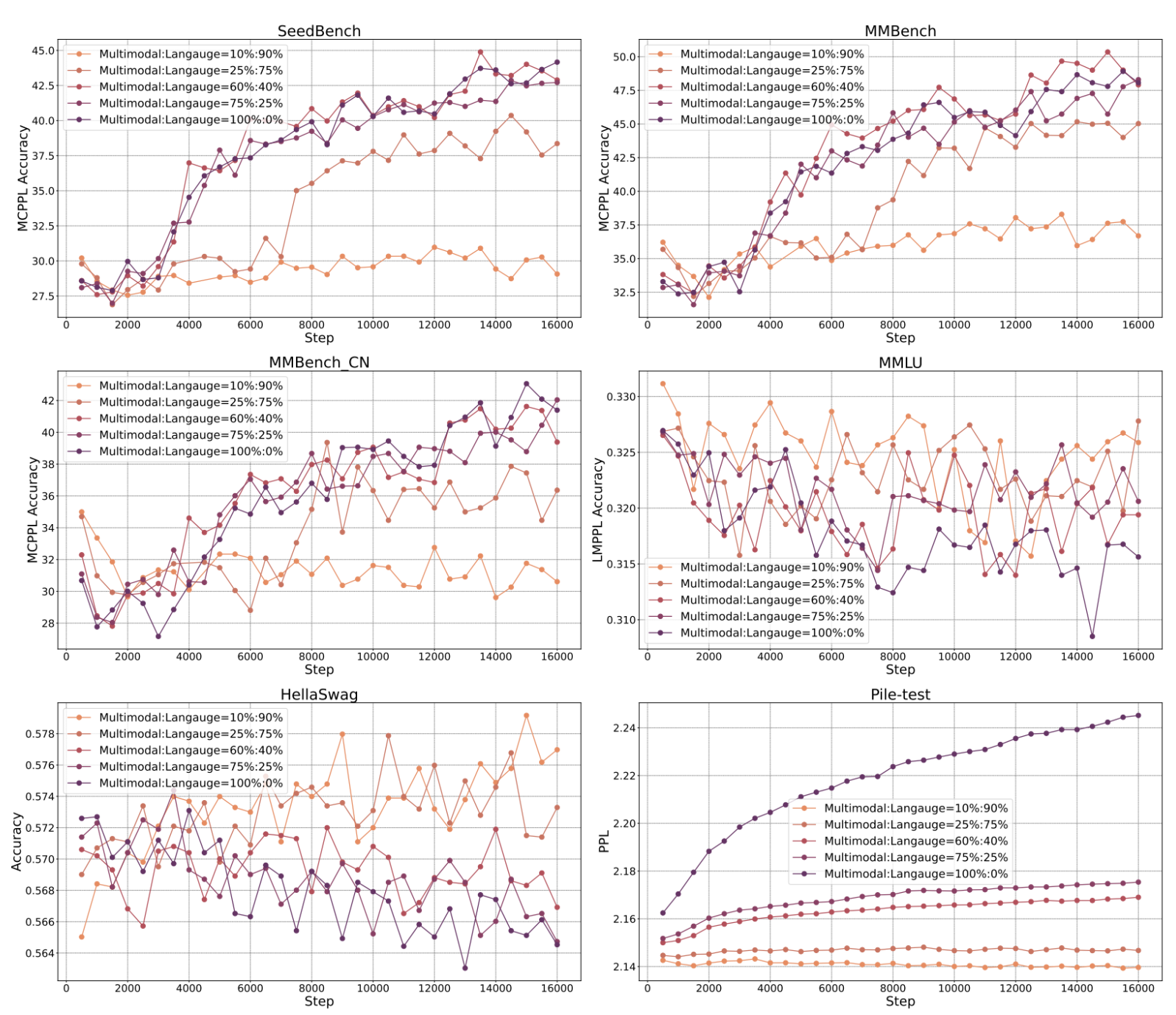
尝试找出最优的多模态和语言比例 最后固定在了7:3
Stage 3: Supervised Fine-tuning
使用基于警告的微调来微调预训练的DeepSeek-VL模型
超参数与超结构
使用HAI-LLM训练和评估我们的DeepSeek-VL
DeepSeek-LLM中的重叠计算和通信(DeepSeek-AI,2024). DeepSeek-VL 7 B在64个节点的集群上消耗了5天,每个节点包括8个Nvidia A100 GPU,而DeepSeek-VL-1B在涉及16个节点的设置上花费了7天
DeepSeek-VL致力于实现在应对这些挑战的同时最大限度地减少语言能力下降的目标