MovieNet是由香港中文大学等机构联合构建的、面向 holistic 电影理解的综合性多模态数据集。针对现有数据集在规模和多模态标注上的局限,MovieNet以其海量数据与丰富标注,为从低层视觉到高层语义的电影理解研究提供了坚实基础。
该数据集核心包含1,100部完整电影、3.9M张图片、60K条预告片以及海量剧本、字幕、剧情梗概和元数据。更重要的是,MovieNet提供了全方位的人工标注:包括110万个人物边界框与身份、4.2万个场景边界、6.5万个动作/场景标签以及9.2万个电影风格标签,并首次手动关联了电影片段与剧情梗概段落。
基于此,MovieNet设立了五大基准任务:类型分析、电影风格预测、人物识别、场景分析和故事理解。基线实验表明,这些任务极具挑战性,例如,融合多模态信息的模型在场景分割和故事理解任务上表现更优,凸显了跨模态学习的重要性。与AVA等数据集相比,MovieNet不再局限于原子动作识别,而是致力于支持从艺术风格分析到故事情节理解的完整研究链路。
综上所述,MovieNet通过其系统性的数据构建、全面的标注体系和多维度的基准任务,为推进基于故事的复杂长视频理解研究提供了不可或缺的资源与评测平台。
文章目录
-
-
- [1. 前言](#1. 前言)
- [2. 思维导图(mindmap)](#2. 思维导图(mindmap))
- [3. 详细总结](#3. 详细总结)
-
- 一、项目背景与核心目标
- 二、数据集核心构成
- 三、五大基准任务与实验结果
-
- [(1)类型分析(Genre Analysis)](#(1)类型分析(Genre Analysis))
- [(2)电影风格预测(Cinematic Style Prediction)](#(2)电影风格预测(Cinematic Style Prediction))
- [(3)人物识别(Character Recognition)](#(3)人物识别(Character Recognition))
- [(4)场景分析(Scene Analysis)](#(4)场景分析(Scene Analysis))
- [(5)故事理解(Story Understanding)](#(5)故事理解(Story Understanding))
- 四、未来工作与发布信息
- [4. 关键问题与答案](#4. 关键问题与答案)
- [5. MovieNet数据集](#5. MovieNet数据集)
-
1. 前言
MovieNet是由香港中文大学-商汤联合实验室构建的面向电影理解的综合性数据集 ,包含1,100部电影 及多模态数据(如3K小时视频、3.9M张照片、10M句文本、7M条元信息等),提供了丰富的人工标注(含1.1M人物边界框与身份标注 、42K场景边界 、65K动作/场景标签 、92K电影风格标签 等);基于该数据集,研究者构建了五大基准任务(类型分析、电影风格预测、人物识别、场景分析、故事理解)并进行实验,揭示了现有方法的不足;相较于现有数据集,MovieNet在规模、多模态覆盖、标注完整性上具有显著优势,旨在推动基于故事的长视频理解研究,将依规发布于https://movienet.github.io。
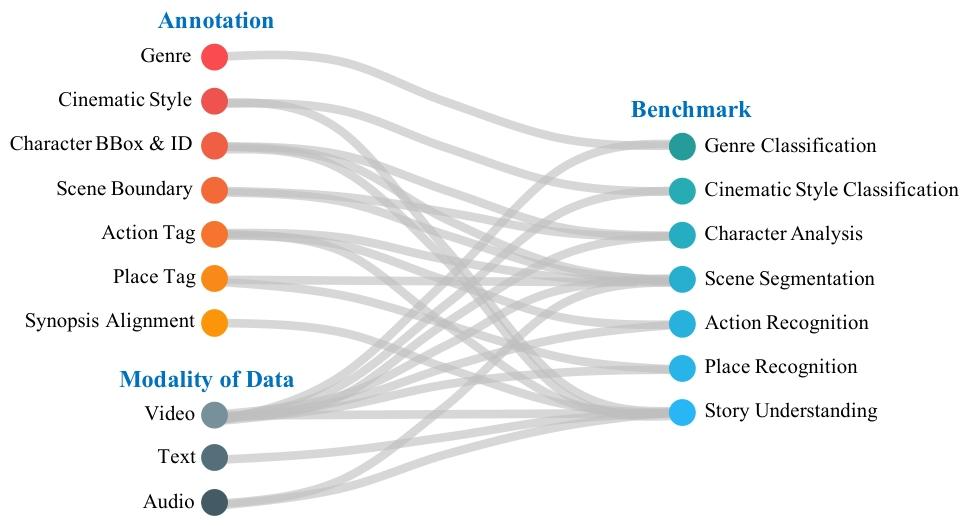
图 1:MovieNet 中的数据、标注、基准任务及其相互关系,这些元素共同构建了一个用于全面电影理解的综合性数据集。

图 2:MovieNet 是一个用于电影理解的综合性数据集,包含海量来自不同模态的数据以及多维度的高质量标注。图中展示了 MovieNet 中电影《泰坦尼克号》(Titanic)的部分数据(蓝色标注)与标注信息(绿色标注)。
2. 思维导图(mindmap)
3. 详细总结
一、项目背景与核心目标
-
电影理解的重要性
电影作为反映现实世界的故事性长视频,兼具娱乐、教育价值,其理解不仅对人类认知重要,更是AI高阶视觉智能的关键场景(复杂度高、与现实关联紧密)。相较于网络图像(如ImageNet)和短视频(如ActivityNet),电影含更丰富的多模态信息,是深度学习模型的优质数据来源。
-
现有数据集的局限
现有电影理解数据集存在两大核心问题:
- 规模有限:如MovieGraphs仅含51部电影,AVA仅含430个15分钟片段;
| # movie | trailer | photo | meta | script | synop. | subtitle | plot | AD | |
|---|---|---|---|---|---|---|---|---|---|
| MovieQA 68 | 140 | √ | √ | ||||||
| LSMDC 57 | 200 | √ | √ | ||||||
| MovieGraphs 71 | 51 | ||||||||
| AVA 28 | 430 | ||||||||
| MovieNet | 1,100 | √ | √ | √ | √ | √ | √ | √ |
- 标注单一:多聚焦单一元素(如MovieQA仅支持问答,AVA仅标注原子动作),无法支撑从"中层实体(人物、场景)"到"高层故事"的完整理解。
| # character | # scene | # cine. tag | # aligned sent. | # action/place tag | |
|---|---|---|---|---|---|
| MovieQA 68 | - | - | - | 15K | - |
| LSMDC 57 | - | - | - | 128K | - |
| MovieGraphs 71 | 22K | - | - | 21K | 23K |
| AVA 28 | 116K | - | - | - | 360K |
| MovieNet | 1.1M | 42K | 92K | 25K | 65K |
- MovieNet的核心目标
构建一个**"数据-标注-基准"三位一体的综合性数据集**,覆盖电影理解的全链路需求,推动基于故事的长视频理解研究。
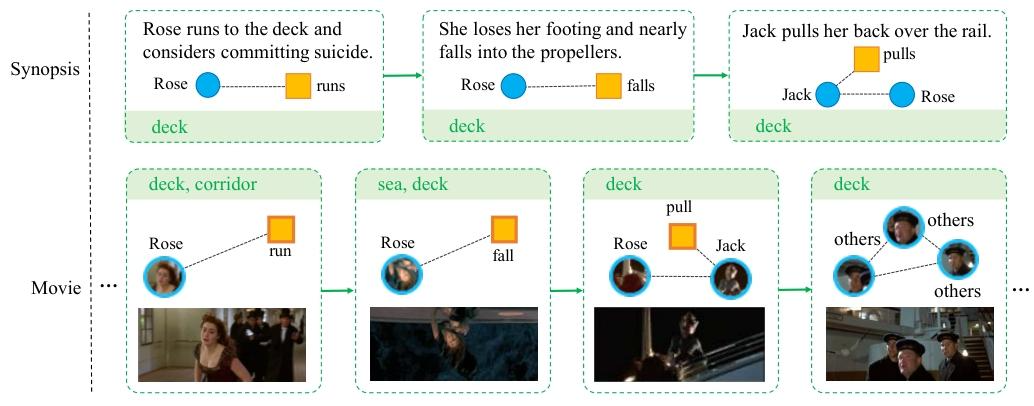
图 5:MovieNet-MSR(MovieNet 电影片段检索任务)中的剧情梗概段落与电影片段示例。该图展示了电影和剧情梗概中故事的时空结构。我们还可以发现,人物、动作和场景是故事理解的关键要素。
二、数据集核心构成
MovieNet的核心优势在于多模态数据覆盖 与全方位人工标注,具体细节如下:
(1)多模态数据详情
| 数据类型 | 具体内容 | 数量规模 |
|---|---|---|
| 视频数据 | 1,100部电影(筛选标准:彩色、时长>1小时、覆盖28类类型/多国/多年份) | 3K小时 |
| 预告片 | 从YouTube下载(基于IMDb/TMDb链接,确保准确性) | 60K条(33K部电影) |
| 图像数据 | 海报、剧照、宣传图、幕后照等7类 | 3.9M张 |
| 文本数据 | 字幕(人工对齐)、剧本(2K部,与字幕匹配)、剧情梗概(11K条,>50句/条) | 10M句 |
| 元数据 | 类型、演员(含角色名)、导演、评分、IMDb/TMDb/豆瓣ID等 | 375K条 |
(2)全方位人工标注(五大类)
| 标注类型 | 具体内容 | 数量规模 | 核心价值 |
|---|---|---|---|
| 人物边界框与身份 | 标注top10主演(IMDb排序)+"其他"角色,含四步流程(选帧→训练检测器→清洗→标身份) | 1.1M实例 | 支撑人物检测与身份识别任务 |
| 场景边界 | 基于镜头分割(镜头为最小视觉单元,场景为语义关联镜头序列)手动标注 | 42K个场景 | 支撑场景分割任务 |
| 动作/场景标签 | 按场景分割片段标注,排除"站立""交谈"等低信息标签,最终保留80类动作+90类场景 | 65K个标签 | 支撑事件理解任务 |
| 剧情描述对齐 | 3位标注者通过"粗对齐→精对齐"流程,关联剧情段落与电影片段 | 4,208对(段落-片段) | 支撑故事理解与片段检索任务 |
| 电影风格标签 | 标注镜头视角尺度(5类:远景→极近景)与相机运动(4类:静态→缩放) | 92K个标签 | 支撑电影艺术风格分析任务 |
(3)与现有数据集的关键对比
- 数据规模对比(表1:多模态数据覆盖)
| 数据集 | 电影数量 | 预告片 | 照片 | 剧本 | 剧情梗概 | 字幕 |
|---|---|---|---|---|---|---|
| MovieQA68 | 408 | 140 | - | - | ✔️ | ✔️ |
| LSMDC57 | 200 | 200 | - | ✔️ | - | - |
| MovieGraphs71 | 51 | - | - | - | - | - |
| AVA28 | 430(片段) | - | - | - | - | - |
| MovieNet | 1,100 | 60K | 3.9M | 2K | 11K | ✔️ |
- 标注规模对比(表2:标注完整性)
| 数据集 | 人物标注(实例) | 场景边界 | 电影风格标签 | 剧情对齐句 | 动作/场景标签 |
|---|---|---|---|---|---|
| MovieQA68 | - | - | - | 15K | - |
| LSMDC57 | - | - | - | 128K | - |
| MovieGraphs71 | 22K | - | - | 21K | 23K |
| AVA28 | 116K | - | - | - | 360K |
| MovieNet | 1.1M | 42K | 92K | 2.5K | 65K |
三、五大基准任务与实验结果
基于数据与标注,MovieNet设计了覆盖"艺术风格-中层实体-高层故事"的五大基准任务,以下为核心细节:
(1)类型分析(Genre Analysis)
- 任务目标:解决长视频类型分类(现有方法仅支持图像/预告片),应对长尾分布(如"剧情片"数量是"体育片"40倍)与高语义依赖挑战。
- 数据规模:1.6M张照片(海报、剧照等4类)、68K条预告片。
- 基线模型与结果(表3:类型分类结果)
| 数据类型 | 模型 | Recall@0.5 | Precision@0.5 | mAP |
|---|---|---|---|---|
| 照片 | VGG16 | 27.32 | 66.28 | 32.12 |
| 照片 | ResNet50 | 34.58 | 72.28 | 46.88 |
| 预告片 | TSN-r50 | 17.95 | 78.31 | 43.70 |
| 预告片 | TRN-r50 | 21.74 | 77.63 | 45.23 |
- 关键发现:ResNet50在照片上表现最优,TRN-r50在预告片上优于TSN,且数据集规模扩大后性能下降,凸显长尾与高语义挑战。
(2)电影风格预测(Cinematic Style Prediction)
- 任务目标:识别镜头的"视角尺度"(5类)与"相机运动"(4类),助力电影艺术分析与视频编辑。
- 数据规模:46,857个镜头(来自电影与预告片)。
- 基线模型与结果(表4:风格预测结果)
| 模型 | 视角尺度准确率 | 相机运动准确率 |
|---|---|---|
| I3D | 76.79 | 78.45 |
| TSN | 84.08 | 70.46 |
| TSN+R³Net(引入显著性) | 87.50 | 80.65 |
- 关键发现:引入主体显著性(R³Net)可提升性能,说明"主体占比"对风格判断至关重要。
(3)人物识别(Character Recognition)
- 任务拆分:人物检测(定位人物)+人物身份识别(匹配角色)。
- 数据规模:1.1M人物实例(3,087个身份)。
- 基线模型与结果
- 人物检测:Cascade R-CNN在MovieNet上训练达95.17% mAP,远超COCO(81.50%)与CalTech(5.67%),证明域适配的重要性;
- 人物身份识别:融合"身体+面部"线索的PPCC模型达75.95% mAP,远超仅用身体线索的模型(32.81%),凸显多线索融合价值。
(4)场景分析(Scene Analysis)
- 任务拆分:场景分割(检测场景边界)+动作/场景标签(标注事件元素)。
- 场景分割结果 :MS-LSTM模型(融合音频、人物、动作、场景多模态)达0.465 AP,远超传统方法(如Grouping模型0.336 AP);
- 动作/场景标签结果 :SlowFast模型在动作识别上达23.52% mAP ,TSN在场景识别上达8.33% mAP,反映事件标注的高挑战性。
(5)故事理解(Story Understanding)
- 任务目标:基于剧情梗概检索对应电影片段(语义级匹配)。
- 数据规模:4,208对"剧情段落-电影片段"。
- 基线模型与结果 :引入"中层实体(人物/动作)+时空图结构"的MovieSynAssociation模型达Recall@10=63.00%,远超仅用全局特征的模型(18.72%),证明中层实体与结构建模的重要性。
四、未来工作与发布信息
-
未来工作方向
- 扩展标注:增加更多电影数量,补充光照、色彩等电影风格标注;
- 方法探索:优化现有任务模型,探索预告片生成、电影修复等实用方向。
-
发布信息
MovieNet将依规发布于官网:https://movienet.github.io,同步提供数据处理工具包(爬虫、预处理、数据生成器等)。
4. 关键问题与答案
问题1:MovieNet相较于现有电影理解数据集,最核心的竞争优势是什么?
答案:MovieNet的核心优势体现在"三维度领先":
- 规模维度 :覆盖1,100部电影(远超MovieQA的408部、LSMDC的200部),多模态数据量达"3K小时视频+3.9M张照片+10M句文本",满足深度学习模型的数据需求;
- 多模态维度:唯一同时包含电影、预告片、照片、剧本、剧情梗概、元数据的数据集,可支撑跨模态任务(如文本-视频检索);
- 标注维度:首次实现"人物-场景-动作-风格-剧情"的全链路标注(如1.1M人物标注、42K场景边界、92K风格标签),可支撑从"中层实体分析"到"高层故事理解"的完整研究,而现有数据集(如AVA仅标注动作、MovieQA仅支持问答)均无法覆盖该链路。
问题2:在MovieNet的人物识别基准任务中,现有方法面临的主要挑战是什么?如何缓解这些挑战?
答案:主要挑战与缓解方案如下:
- 域差距挑战 :现有人物重识别(ReID)数据集(如Market-1501、CUHK03)基于监控场景,与电影场景(光影复杂、视角多变)存在显著域差距,导致模型泛化性差(如在Market上训练的模型在MovieNet上仅达4.62% mAP);
- 缓解:使用MovieNet自身的1.1M电影人物数据训练模型,域适配后仅用身体线索的模型mAP提升至32.81%;
- 多线索融合挑战 :电影中人物常存在遮挡、姿态变化,单一身体线索不足以支撑身份识别;
- 缓解:融合"身体+面部"双线索,如PPCC模型通过竞争性共识机制整合双线索,将mAP提升至75.95%,远超单一线索模型。
问题3:MovieNet与AVA(原子视觉动作数据集)在定位和功能上的关键区别是什么?
答案:两者定位与功能差异显著,核心区别如下:
| 对比维度 | AVA | MovieNet |
|---|---|---|
| 核心定位 | 聚焦"原子动作识别"(如"站立""交谈"),服务于基础动作检测任务 | 聚焦"电影全链路理解",服务于从艺术风格到故事语义的综合研究 |
| 数据构成 | 430个15分钟电影片段,无多模态数据(如预告片、剧本) | 1,100部完整电影+多模态数据(60K预告片、3.9M照片等),数据更完整 |
| 标注内容 | 仅标注80类原子动作(含大量低信息动作如"站立"),无人物身份、场景等标注 | 标注80类高语义动作(排除低信息动作)+人物身份、场景、风格等全链路标注 |
| 支持任务 | 仅支撑原子动作识别单一任务 | 支撑类型分析、风格预测、人物识别、场景分析、故事理解五大任务 |
| 研究价值 | 推动基础动作检测技术发展 | 推动基于故事的长视频理解,更贴近真实电影分析需求 |
5. MovieNet数据集
数据集中的数据:可以参考MovieNet(A holistic dataset for movie understanding) :面向电影理解的多模态综合数据集与工具链
图 A11:MovieNet 中剧情梗概语料库的词云图。
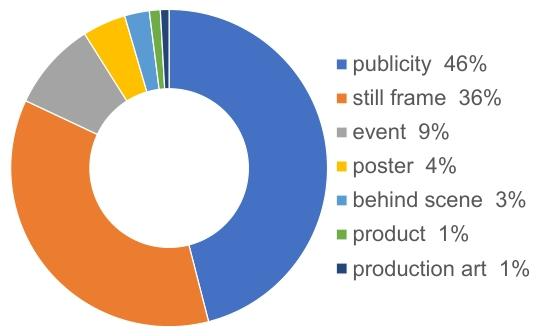
图 A12:MovieNet 中不同类型照片的占比。

图 A13:MovieNet 中不同类型照片的示例。
