精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
基于Python+Django的新能源汽车数据分析系统是一个专门针对新能源汽车市场分析和用户交流的综合性平台。该系统采用B/S架构设计,运用Python作为核心开发语言,结合Django强大的Web开发框架,构建了稳定高效的后端服务体系。前端采用Vue.js配合ElementUI组件库,为用户提供现代化、响应式的操作界面。系统数据存储依托MySQL数据库,确保数据的安全性和完整性。整个系统围绕新能源汽车数据展开,为管理员提供全面的后台管理功能,包括用户账户管理、汽车信息维护、用户评论监管、车辆配置管理、社区交流管理、用户反馈处理以及举报记录跟踪等模块。普通用户可以通过注册登录访问系统,浏览详细的新能源汽车信息,发表个人使用体验和评价,参与社区讨论交流,形成良性的用户互动生态。系统通过数据分析功能,能够对收集到的汽车信息、用户行为、评论内容等进行深度挖掘,为新能源汽车市场趋势分析提供数据支撑,帮助用户更好地了解新能源汽车产品特点和市场动态。
选题背景
随着全球环保意识的日益增强和国家新能源政策的大力推进,新能源汽车产业正经历着前所未有的快速发展阶段。新能源汽车作为传统燃油车的重要替代方案,其市场占有率持续攀升,产品种类日趋丰富,技术路线也愈发多样化。然而在这个快速发展的过程中,消费者面临着信息获取困难、产品选择复杂、用户体验参差不齐等诸多挑战。传统的汽车信息获取渠道往往存在信息更新滞后、用户反馈渠道单一、数据分析能力不足等问题。市场上虽然存在一些汽车信息平台,但大多侧重于传统燃油车,对新能源汽车的专业性覆盖还不够深入。同时,新能源汽车的技术参数、续航能力、充电便利性、使用成本等关键指标与传统汽车存在显著差异,需要更加专业和细致的信息展示与分析。在这样的市场背景下,构建一个专门针对新能源汽车的信息分析和交流平台,成为满足市场需求和用户期待的重要途径。
选题意义
从实用价值角度来看,基于Python+Django的新能源汽车数据分析系统能够为广大新能源汽车潜在购买者和现有用户提供一个相对完整的信息获取和交流平台。用户可以通过系统获得较为全面的车辆信息,了解不同品牌车型的技术特点和市场表现,同时通过其他用户的真实评价和使用体验,形成更为客观的购车参考。从技术实践意义来说,该系统整合了当前主流的Web开发技术栈,通过Python+Django的后端架构和Vue+ElementUI的前端框架,展示了现代Web应用开发的标准流程和技术要点。系统中的数据分析功能虽然相对基础,但体现了数据驱动决策的重要理念。从学习研究角度而言,该项目涵盖了数据库设计、后端API开发、前端界面构建、用户权限管理等多个技术领域,为计算机专业学生提供了较为全面的实践机会。通过项目实施过程,可以加深对Web开发全流程的理解,提升问题解决和系统设计能力。虽然作为毕业设计项目在规模和复杂度上相对有限,但其所体现的技术应用和实际问题解决思路具有一定的参考价值。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
三、视频展示
计算机毕业设计选题推荐:基于Python+Django的新能源汽车数据分析系统
四、项目展示
登录模块:
首页模块:
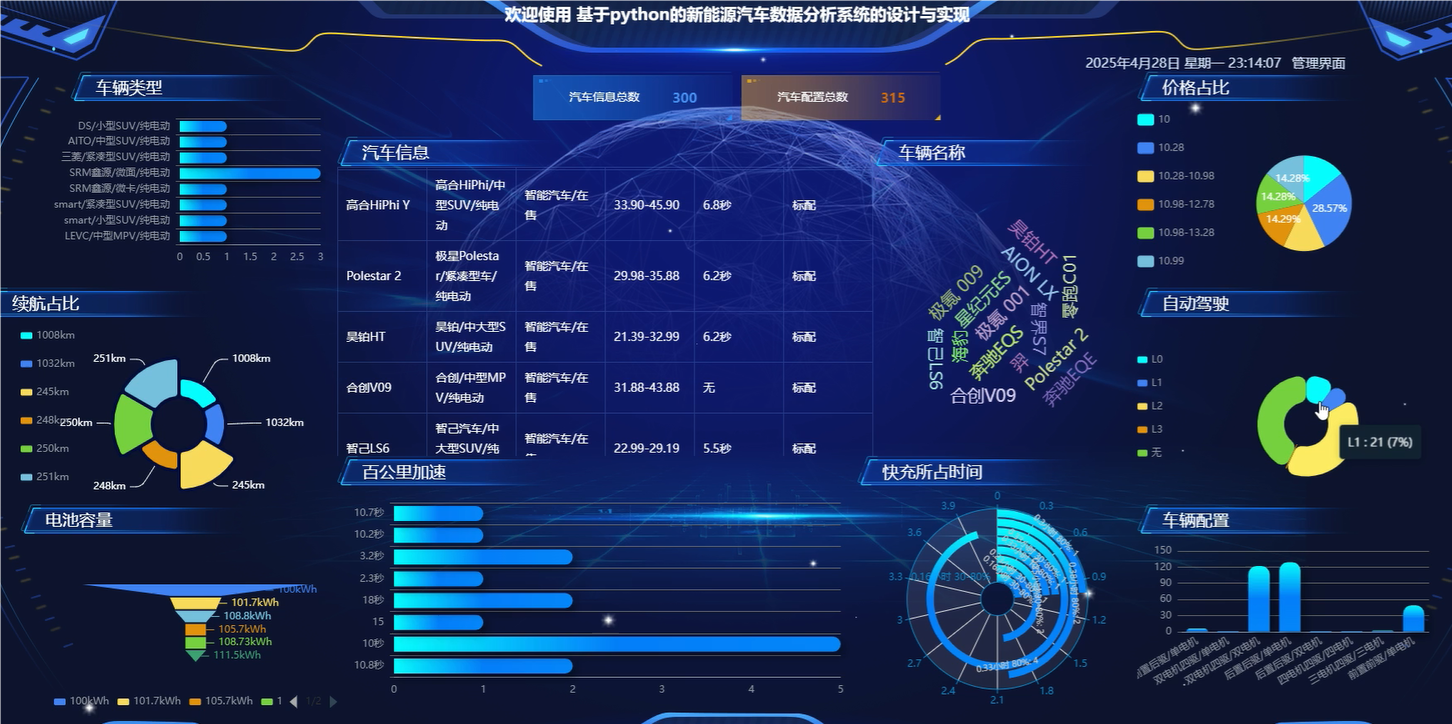
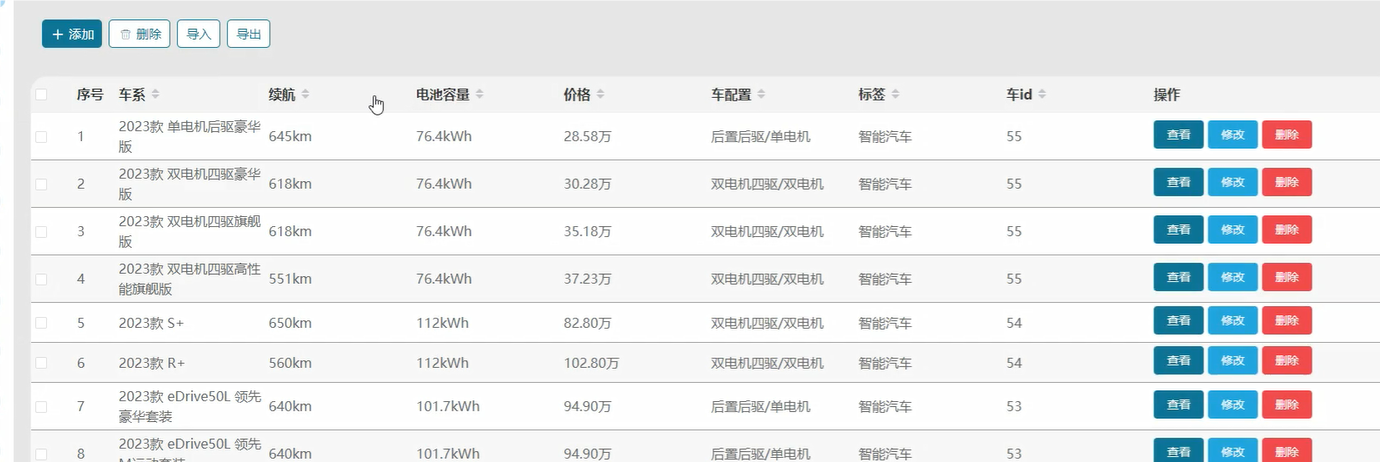
管理模块:

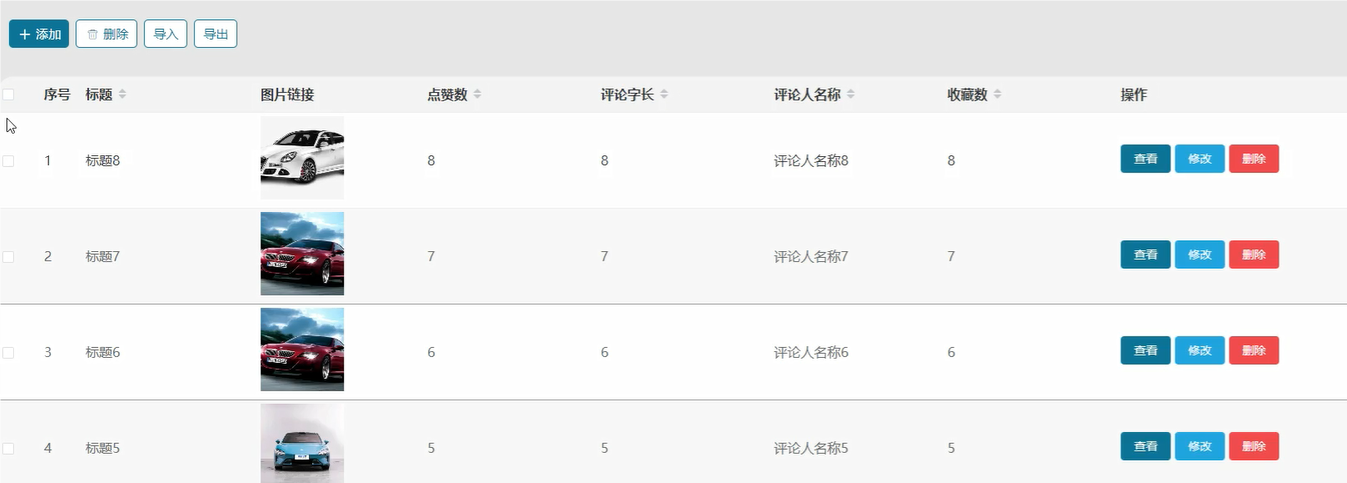
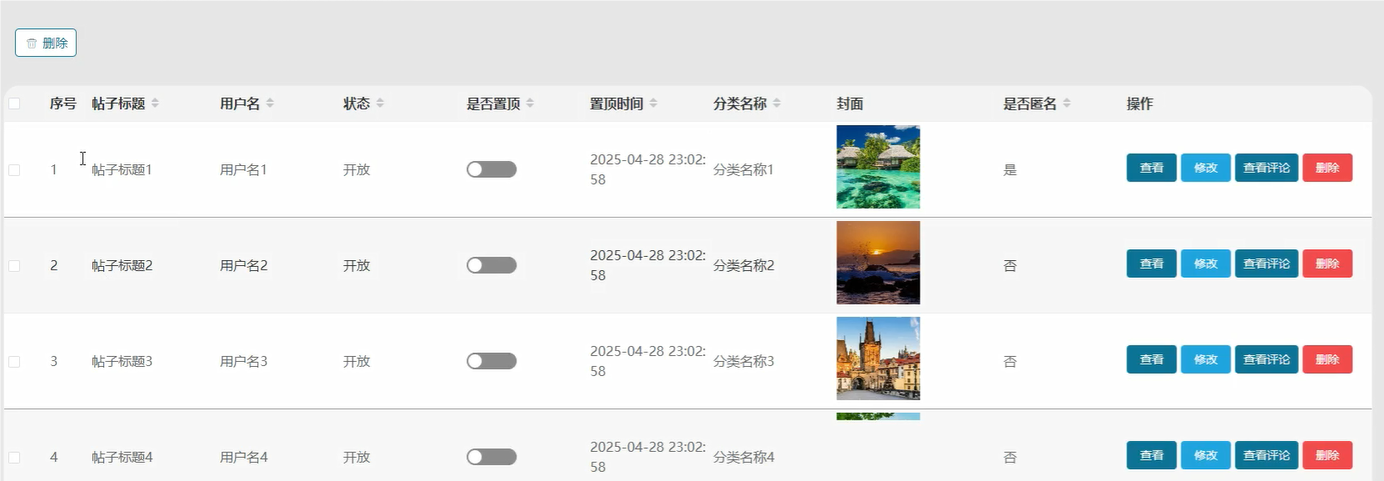
五、代码展示
bash
from pyspark.sql import SparkSession
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import json
from .models import Car, Comment, User
from django.core.paginator import Paginator
from django.db.models import Q, Avg, Count
import pandas as pd
def get_car_analysis_data(request):
spark = SparkSession.builder.appName("CarDataAnalysis").getOrCreate()
cars = Car.objects.all()
car_data = []
for car in cars:
car_data.append({
'id': car.id,
'name': car.name,
'brand': car.brand,
'price': float(car.price),
'battery_capacity': float(car.battery_capacity),
'range_km': int(car.range_km),
'energy_consumption': float(car.energy_consumption),
'charging_time': float(car.charging_time)
})
df = spark.createDataFrame(car_data)
price_stats = df.agg({'price': 'avg', 'price': 'max', 'price': 'min'}).collect()[0]
range_stats = df.agg({'range_km': 'avg', 'range_km': 'max', 'range_km': 'min'}).collect()[0]
battery_stats = df.agg({'battery_capacity': 'avg', 'battery_capacity': 'max', 'battery_capacity': 'min'}).collect()[0]
brand_count = df.groupBy('brand').count().collect()
brand_analysis = []
for row in brand_count:
brand_analysis.append({'brand': row['brand'], 'count': row['count']})
price_range_correlation = df.corr('price', 'range_km')
battery_range_correlation = df.corr('battery_capacity', 'range_km')
efficiency_df = df.withColumn('efficiency_score', df['range_km'] / df['energy_consumption'])
top_efficiency = efficiency_df.orderBy(efficiency_df['efficiency_score'].desc()).limit(10).collect()
efficiency_cars = []
for car in top_efficiency:
efficiency_cars.append({
'name': car['name'],
'efficiency_score': round(car['efficiency_score'], 2),
'range_km': car['range_km'],
'energy_consumption': car['energy_consumption']
})
spark.stop()
return JsonResponse({
'price_analysis': {
'average': round(price_stats['avg(price)'], 2),
'maximum': round(price_stats['max(price)'], 2),
'minimum': round(price_stats['min(price)'], 2)
},
'range_analysis': {
'average': round(range_stats['avg(range_km)'], 2),
'maximum': range_stats['max(range_km)'],
'minimum': range_stats['min(range_km)']
},
'battery_analysis': {
'average': round(battery_stats['avg(battery_capacity)'], 2),
'maximum': round(battery_stats['max(battery_capacity)'], 2),
'minimum': round(battery_stats['min(battery_capacity)'], 2)
},
'brand_distribution': brand_analysis,
'correlations': {
'price_range': round(price_range_correlation, 3),
'battery_range': round(battery_range_correlation, 3)
},
'efficiency_ranking': efficiency_cars
})
@csrf_exempt
def manage_car_comments(request):
if request.method == 'GET':
page = request.GET.get('page', 1)
car_id = request.GET.get('car_id', '')
status = request.GET.get('status', '')
keyword = request.GET.get('keyword', '')
comments_query = Comment.objects.select_related('user', 'car').all()
if car_id:
comments_query = comments_query.filter(car_id=car_id)
if status:
comments_query = comments_query.filter(status=status)
if keyword:
comments_query = comments_query.filter(
Q(content__icontains=keyword) |
Q(user__username__icontains=keyword) |
Q(car__name__icontains=keyword)
)
comments_query = comments_query.order_by('-created_time')
paginator = Paginator(comments_query, 20)
comments_page = paginator.get_page(page)
comments_data = []
for comment in comments_page:
comments_data.append({
'id': comment.id,
'content': comment.content,
'rating': comment.rating,
'status': comment.status,
'user_name': comment.user.username,
'car_name': comment.car.name,
'created_time': comment.created_time.strftime('%Y-%m-%d %H:%M:%S'),
'reply_count': comment.replies.count() if hasattr(comment, 'replies') else 0
})
return JsonResponse({
'comments': comments_data,
'total_pages': paginator.num_pages,
'current_page': comments_page.number,
'total_count': paginator.count,
'has_next': comments_page.has_next(),
'has_previous': comments_page.has_previous()
})
elif request.method == 'POST':
data = json.loads(request.body)
action = data.get('action', '')
comment_ids = data.get('comment_ids', [])
if action == 'batch_approve':
Comment.objects.filter(id__in=comment_ids).update(status='approved')
affected_count = len(comment_ids)
elif action == 'batch_reject':
Comment.objects.filter(id__in=comment_ids).update(status='rejected')
affected_count = len(comment_ids)
elif action == 'batch_delete':
affected_count = Comment.objects.filter(id__in=comment_ids).count()
Comment.objects.filter(id__in=comment_ids).delete()
elif action == 'single_update':
comment_id = data.get('comment_id')
new_status = data.get('status')
Comment.objects.filter(id=comment_id).update(status=new_status)
affected_count = 1
else:
return JsonResponse({'success': False, 'message': '操作类型无效'})
return JsonResponse({
'success': True,
'message': f'成功处理{affected_count}条评论',
'affected_count': affected_count
})
def get_user_interaction_analysis(request):
spark = SparkSession.builder.appName("UserInteractionAnalysis").getOrCreate()
users = User.objects.all()
user_stats = []
for user in users:
comment_count = Comment.objects.filter(user=user).count()
avg_rating = Comment.objects.filter(user=user).aggregate(Avg('rating'))['rating__avg'] or 0
latest_comment = Comment.objects.filter(user=user).order_by('-created_time').first()
user_stats.append({
'user_id': user.id,
'username': user.username,
'comment_count': comment_count,
'avg_rating': float(avg_rating),
'registration_date': user.date_joined.strftime('%Y-%m-%d'),
'last_activity': latest_comment.created_time.strftime('%Y-%m-%d') if latest_comment else user.date_joined.strftime('%Y-%m-%d'),
'is_active': user.is_active
})
df = spark.createDataFrame(user_stats)
active_users = df.filter(df.comment_count > 0).count()
total_users = df.count()
activity_rate = (active_users / total_users) * 100 if total_users > 0 else 0
comment_distribution = df.groupBy('comment_count').count().orderBy('comment_count').collect()
rating_distribution = df.filter(df.avg_rating > 0).groupBy('avg_rating').count().collect()
top_active_users = df.orderBy(df.comment_count.desc()).limit(10).collect()
monthly_activity = Comment.objects.extra(
select={'month': "DATE_FORMAT(created_time, '%%Y-%%m')"}
).values('month').annotate(
comment_count=Count('id'),
user_count=Count('user_id', distinct=True)
).order_by('month')
activity_trends = []
for item in monthly_activity:
activity_trends.append({
'month': item['month'],
'comments': item['comment_count'],
'active_users': item['user_count']
})
user_engagement_scores = []
for user_data in user_stats:
if user_data['comment_count'] > 0:
engagement_score = (user_data['comment_count'] * 0.6 + user_data['avg_rating'] * 0.4) * (1 if user_data['is_active'] else 0.5)
user_engagement_scores.append({
'username': user_data['username'],
'engagement_score': round(engagement_score, 2),
'comment_count': user_data['comment_count'],
'avg_rating': round(user_data['avg_rating'], 2)
})
user_engagement_scores.sort(key=lambda x: x['engagement_score'], reverse=True)
spark.stop()
return JsonResponse({
'user_activity_overview': {
'total_users': total_users,
'active_users': active_users,
'activity_rate': round(activity_rate, 2)
},
'comment_distribution': [{'comment_count': row['comment_count'], 'user_count': row['count']} for row in comment_distribution],
'top_active_users': [{'username': row['username'], 'comment_count': row['comment_count'], 'avg_rating': round(row['avg_rating'], 2)} for row in top_active_users],
'monthly_trends': activity_trends,
'user_engagement_ranking': user_engagement_scores[:20]
})六、项目文档展示

七、总结
基于Python+Django的新能源汽车数据分析系统作为一个综合性的毕业设计项目,成功地将现代Web开发技术与新能源汽车领域的实际需求相结合,构建了一个功能相对完整的信息管理和数据分析平台。该系统通过采用Python作为核心开发语言,结合Django框架的强大功能,实现了用户管理、汽车信息维护、评论互动、数据分析等多个核心模块。前端采用Vue.js配合ElementUI的技术方案,为用户提供了直观友好的操作界面,增强了整体的用户体验。系统的数据分析功能虽然在复杂度上符合本科毕业设计的要求,但通过集成Spark等大数据处理技术,展现了对汽车信息、用户行为、评论数据等多维度信息的处理能力。从技术实现角度来看,项目涵盖了数据库设计、后端API开发、前端界面构建、用户权限控制等Web开发的关键环节,为计算机专业学生提供了较为全面的实践锻炼机会。通过该项目的完成,不仅加深了对现代Web开发技术栈的理解和应用,也体现了将技术手段运用于解决特定领域问题的能力。虽然作为学生项目在规模和功能深度上还有进一步优化的空间,但其基本的架构设计和功能实现已经能够满足新能源汽车信息管理的基础需求,具备了一定的实用价值和技术参考意义。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖