前言
本系列前两篇文章:
- 深入浅出LangGraph AI Agent智能体开发教程(一)---全面认识LangGraph
- 深入浅出LangGraph AI Agent智能体开发教程(二)---LangGraph预构建图API快速创建Agent
通过前两篇文章的学习我们了解了LangGraph的核心原理和技术架构,利用LangGraph的预构建图高级API编写了ReAct图,并接入自定义的请求心知天气API工具函数,快速搭建了天气助手智能体。本期内容我们继续围绕LangGraph接入工具函数的案例进行讲解,让大家充分理解LangGraph接入自定义工具、接入LangChain内置工具、多工具并联串联调用和Agent工具调用次数限制等知识点,大家一起来学习吧~
本系列分享是笔者结合自己学习工作中使用LangChain&LangGraph经验倾心编写的,力求帮助大家体系化快速掌握LangChain&LangGraph AI Agent智能体开发的技能!笔者的LangChain系列教程暂时更完,后面也会实时补充工作实践中的额外知识点,建议大家在学习LangGraph分享前先学习LangChain的基本使用技巧。大家感兴趣可以关注笔者掘金账号和系列专栏。更可关注笔者同名微信公众号: 大模型真好玩 , 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。
一、LangGraph ReAct Agent 外部工具调用形式
上篇文章深入浅出LangGraph AI Agent智能体开发教程(二)---LangGraph预构建图API快速创建Agent我们直观感受到了LangGraph 预构建ReACT图 API create_react_agent的强大。本小节内容我们还会学习到借助LangGraph React Agent,无需任何额外设置,即可完成多工具串联和并联的调用。
1.1 添加多个工具函数
首先在上篇文章的代码中添加将指定内容写入本地文件的工具函数write_file, 该项目代码包含get_weather和write_file两个工具函数,分别用来查询天气和保存内容至文件。完整的项目代码如下:
python
import requests
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import create_react_agent
class WeatherQuery(BaseModel):
loc: str = Field(description="城市名称")
class WriteQuery(BaseModel):
content: str = Field(description="需要写入文档的具体内容")
@tool(args_schema=WeatherQuery)
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
:return:心知天气 API查询即时天气的结果,具体URL请求地址为:"https://api.seniverse.com/v3/weather/now.json"
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
url = "https://api.seniverse.com/v3/weather/now.json"
params = {
"key": "你注册的心知天气api key",
"location": loc,
"language": "zh-Hans",
"unit": "c",
}
response = requests.get(url, params=params)
temperature = response.json()
return temperature['results'][0]['now']
@tool(args_schema=WriteQuery)
def write_file(content):
"""
将指定内容写入本地文件。
:param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。
:return:是否成功写入
"""
with open('res.txt', 'w', encoding='utf-8') as f:
f.write(content)
return "已成功写入本地文件。"
model = init_chat_model(
model='deepseek-chat',
model_provider='deepseek',
api_key='你注册的deepseek api key'
)
tools = [get_weather, write_file]
agent = create_react_agent(model=model, tools=tools)1.2 工具并联调用
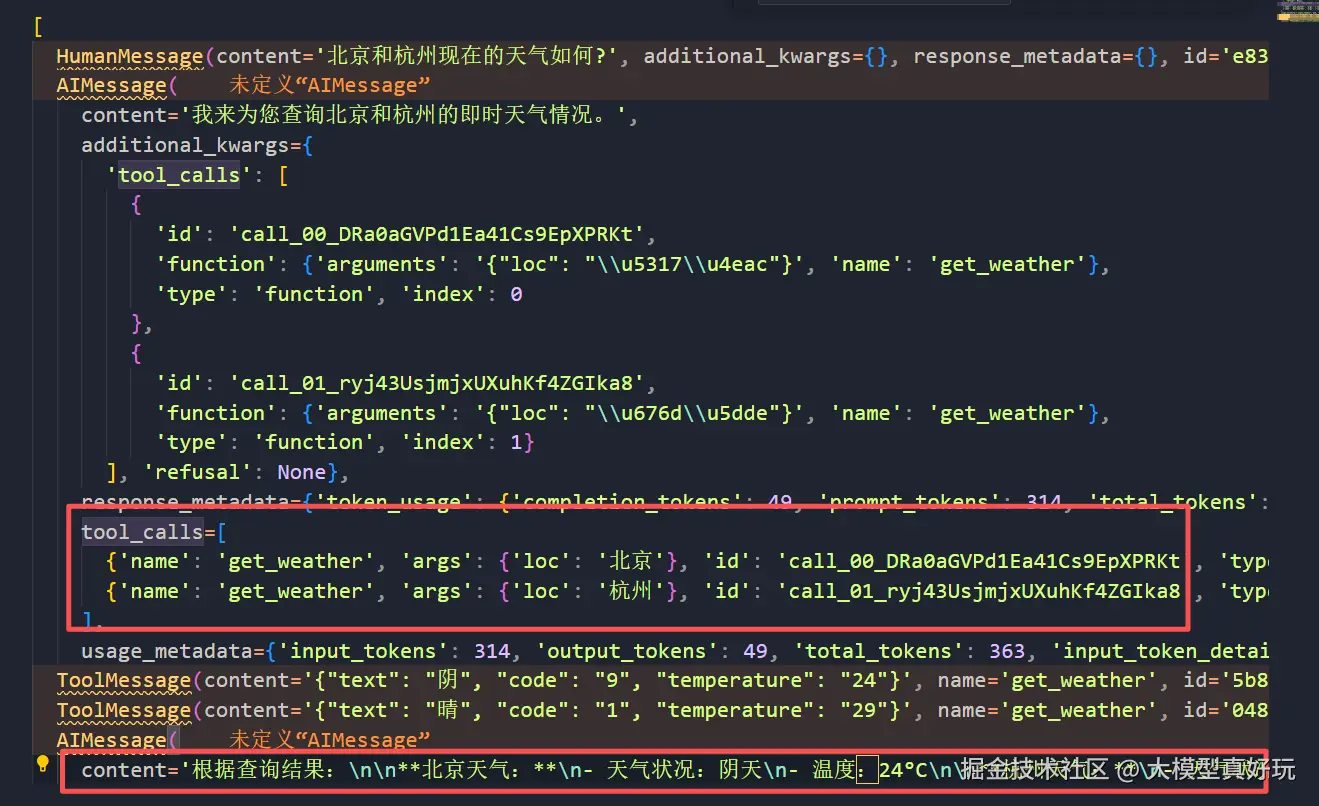
测试ReAct图智能体的工具并联调用,同时查询北京和杭州的天气。从执行结果看,ReAct图智能体同时调用了get_weather工具函数分别查询北京和杭州的天气状况,执行流程如下:
python
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "北京和杭州现在的天气如何?"
}
]
}
)
print(response['messages'])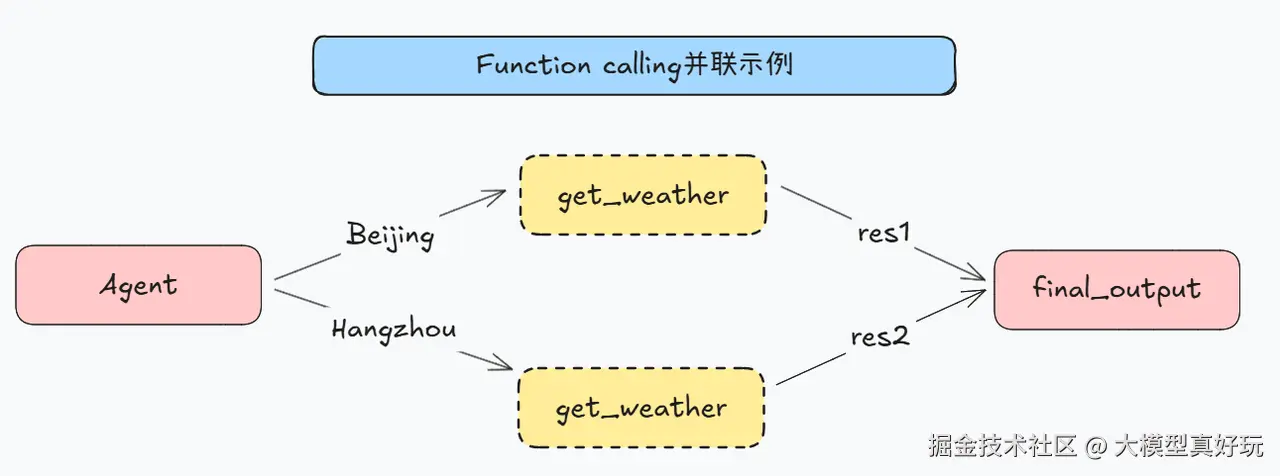
1.3 工具串联调用
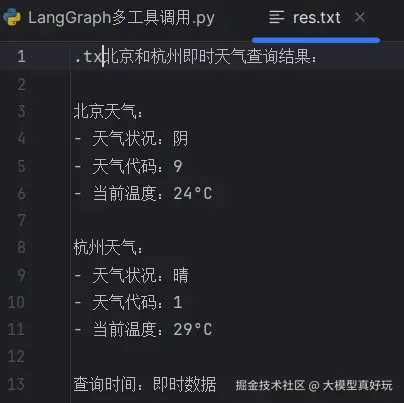
测试ReAct图智能体的工具串联调用(实则是串并联调用)。在查询北京杭州天气的基础上,将查询结果写入文件中。从执行结果看,ReAct图智能体首先调用get_weather函数查询北京和杭州的天气情况,然后调用write_file函数将内容写入res.txt文件中。执行流程如下:
python
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "北京和杭州现在的天气如何?并把查询结果写入文件中"
}
]
}
)
print(response['messages'])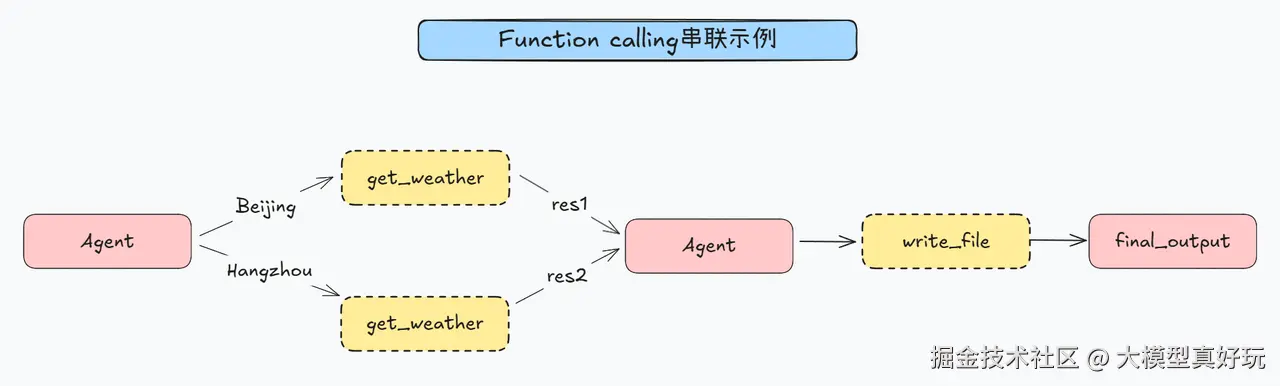

二、LangGraph ReAct 限制工具调用次数
2.1 限制调用次数的配置
对于任何全自动代理,合理控制调用次数都是至关重要的一环,对于LangGraph ReAct Agent来说,我们只需要在Agent运行时设置{"recursion_limit": X},即可限制智能体自主执行任务的步数。
python
try:
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "北京现在的天气如何"
}
],
},
{
"recursion_limit": 4
},
)
print(response['messages'][-1].content)
except GraphRecursionError:
print('智能体由于超过最多调用次数而停止')上述代码的执行结果如下,可以看到ReAct成功执行并返回了结果:
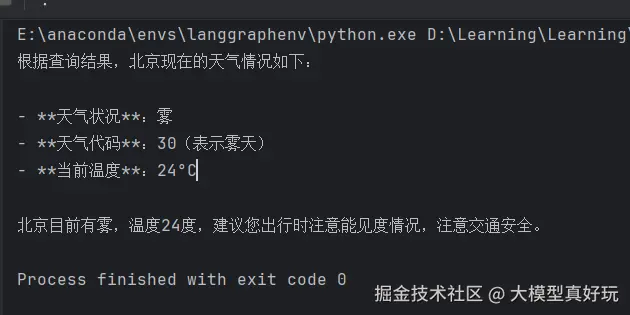
但如果我们将参数recursion_limit改为2,执行结果就会报错:
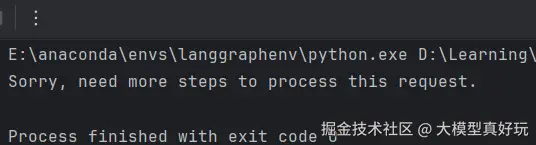
这是为什么呢?原理其实非常简单,
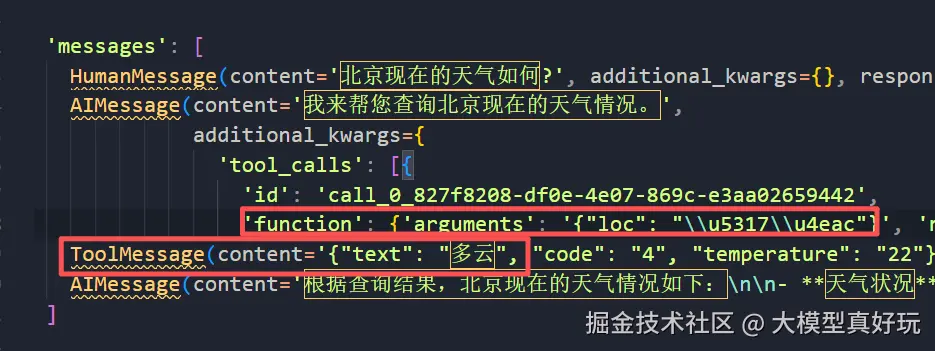
当我们询问"北京现在的天气如何"问题后,智能体执行流程如下,共需要经过:
HumanMessage收集用户提示词AIMessage调用大模型确定执行逻辑ToolMessage执行查询天气函数并得到结果AIMessage总结函数调用结果并生成回答
可以看到完整的流程至少需要4步,设置recursion_limit为2肯定无法完整执行。
三、LangGraph ReAct智能体内部工具调用
3.1 LangChain内置工具
对于LangGraph智能体来说,除了能够灵活自如自定义工具,还能够接入LangChain丰富的内置工具快速完成智能体的开发。
在 LangChain 框架中,工具是实现语言模型与外部世界交互的关键机制。LangChain提供了大量内置与可扩展的工具接口,使得智能体能够执行函数调用、访问 API、查询搜索引擎、调用数据库等任务,从而超越纯语言生成的能力,真正实现"能行动的智能体"。LangChain 官方文档将这些工具按照其用途进行了模块化划分,涵盖了以下主要类别:
| 功能类别 | 工具名称 | 简要说明 |
|---|---|---|
| 🔎 搜索工具 | TavilySearchResults |
快速搜索实时网络信息 |
SerpAPIWrapper |
基于 SerpAPI 的搜索结果工具 | |
GoogleSearchAPIWrapper |
调用 Google 可编程搜索引擎 | |
| 🧠 计算工具 | PythonREPLTool |
执行 Python 表达式并返回结果 |
LLMMathTool |
结合 LLM 和数学推理能力 | |
WolframAlphaQueryRun |
基于 Wolfram Alpha 的计算引擎 | |
| 🗂 数据工具 | SQLDatabaseToolkit |
构建 SQL 数据库查询工具集 |
PandasDataframeTool |
用于在 Agent 中操作表格数据 | |
| 🌐 网络/API | RequestsGetTool / RequestsPostTool |
执行 HTTP 请求 |
BrowserTool / PlaywrightBrowserToolkit |
自动化网页浏览与抓取 | |
| 💾 文件处理 | ReadFileTool |
读取本地文件内容 |
WriteFileTool |
写入文本到指定文件中 | |
| 📚 检索工具 | FAISSRetriever |
基于向量的文档检索工具 |
ChromaRetriever |
使用 ChromaDB 的检索器 | |
ContextualCompressionRetriever |
上下文压缩检索器,适合长文档 | |
| 🧠 LLM 工具 | ChatOpenAI / OpenAIFunctionsTool |
使用 OpenAI 模型作为工具调用 |
ChatAnthropic |
Anthropic Claude 模型封装工具 | |
| 🔧 自定义工具 | @tool 装饰器 |
任意函数可封装为 Agent 可调用工具 |
Tool 类继承 |
自定义更复杂逻辑的工具实现 |
更具体的工具大家可参考官网python.langchain.com/docs/integr...
3.2 创建带搜索功能的Agent
这里我们尝试借助LangChain内置的Tavily搜索引擎工具,搭建能够进行网络搜索的智能体。
- 首先需要在tavily官网进行注册并获取API-KEY:www.tavily.com/ (注意: 需要科学上网)

- 在我们创建的名为
langgraphenv的anaconda虚拟环境下执行pip install langchain-tavily命令安装内置工具的依赖包。
- 编写代码,导入
TavilySearch并快速将其封装为LangGraph智能体工具,原理也是使用create_react_agentapi快速创建智能体。
python
from langchain_tavily import TavilySearch
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import create_react_agent
search_tool = TavilySearch(
max_results=5,
topic="general",
tavily_api_key='你注册的TavilySearch api key'
)
tools = [search_tool]
model = init_chat_model(
model='deepseek-chat',
model_provider='deepseek',
api_key='你注册的DeepSeek api key'
)
search_agent = create_react_agent(model=model, tools=tools)
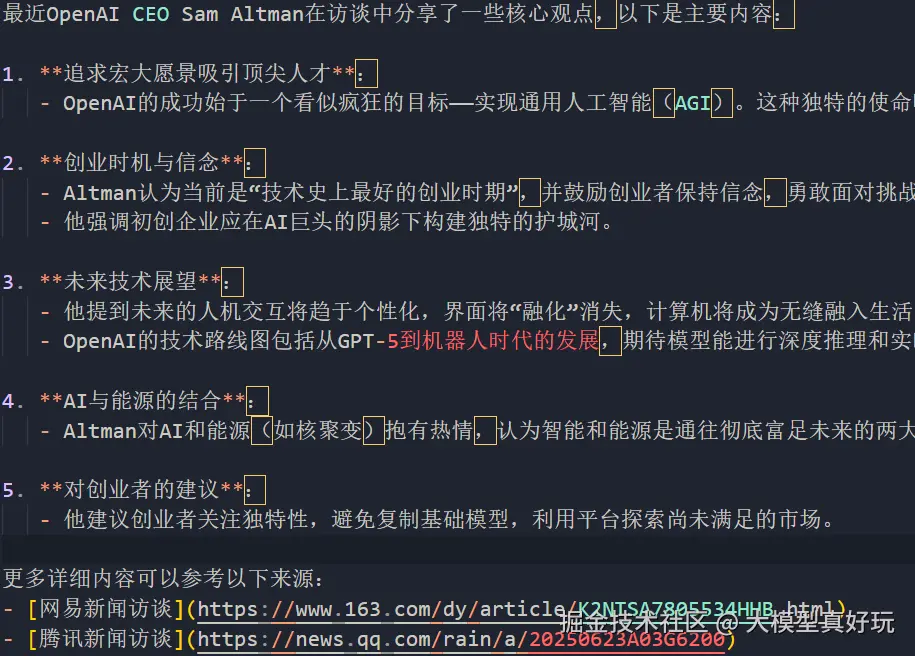
response = search_agent.invoke({"messages": [{"role": "user", "content": "请帮我搜索最近OpenAI CEO在访谈中的核心观点。"}]})
print(response["messages"][-1].content)执行结果如下,可以看到ReAct智能体成功调用了搜索引擎搜索到我们需要的内容:
四、总结
本期内容分享了LangGraph ReAct智能体接入内部工具函数和自定义工具函数的方法,深入研究了LangGraph多工具的执行模式,并可通过配置项限制LangGraph 智能体的调用次数。大家有在评论区私信笔者:"感觉最近分享的LangGraph create_react_agent和以前LangChain系列分享中的create_tool_calling_agent很相似,有没有一些LangGraph特别的技能技巧分享?", 笔者分享create_react_agent的初衷是希望大家更快上手LangGraph的使用,也帮助没有看过我们LangChain系列分享的小伙伴能快速学习智能体搭建流程,不过下一期我们要分享一波硬核内容:LangGraph智能体上线部署实战,涉及到LangSmith、LangGraph Sudio、LangGraph cli等全生态应用,大家期待一下吧~ (笔者主打一个听劝)
本系列分享预计会有20节左右的规模,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩 , 本系列分享的全部代码均可在微信公众号私信笔者: LangChain智能体开发 免费获得。