本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
RAG的检索增强生成(Retrieval-Augmented Generation, RAG)技术,一直是不少人研究和优化的方向,RAG通过整合外部知识库来增强模型能力,特别适用于实时性、准确性和专业深度要求高的企业场景。但它也有一些固有的缺陷。今天我将深入解析RAG的检索增强生成优化核心技术,如果你在项目中也遇到了瓶颈,建议你仔细把文章看完。废话不多说,我将从问题背景到解决方案再到优化实践,确保详细覆盖技术细节。
一、RAG的背景:解决大语言模型的三大核心缺陷
大语言模型(如GPT系列)本质上是基于固定训练数据的概率生成器,这导致其在实际应用中存在三个关键矛盾:
1、知识的静态性与需求的实时性矛盾:
LLM的训练数据有明确截止点(例如GPT-4数据截止于2023年10月),无法获取后续信息(如2024年新品发布)。重新训练模型以更新知识成本高昂(数百万至数亿美元),且可能引发灾难性遗忘问题。RAG通过外接动态知识库(如公司文档系统或新闻API)来解决这一矛盾。当用户查询最新信息时,RAG先检索外部数据库中的实时内容,再让LLM基于检索结果生成答案,从而将LLM从静态记忆者转变为动态整合者。

2、生成的概率性与结果的准确性矛盾:
LLM的生成机制依赖词序概率预测,易产生幻觉(Hallucination),例如编造不存在的药物名称或财务数据。RAG通过引入事实边界约束来破局:要求LLM的答案严格基于检索到的权威文档(如年度报告或官方手册),并附带来源链接以确保可审计性。这在金融、医疗等合规敏感行业中至关重要。
3、通用知识与专业深度矛盾:
通用LLM缺乏企业或行业的内部知识(如公司SOP或工业设备故障手册)。RAG通过构建定制化知识基座解决这一问题:将企业内部文档或行业手册导入向量数据库,使通用LLM瞬间升级为领域专家。例如,导入机器人维护手册后,LLM能精确指导"电机轴承磨损"的故障排查步骤。
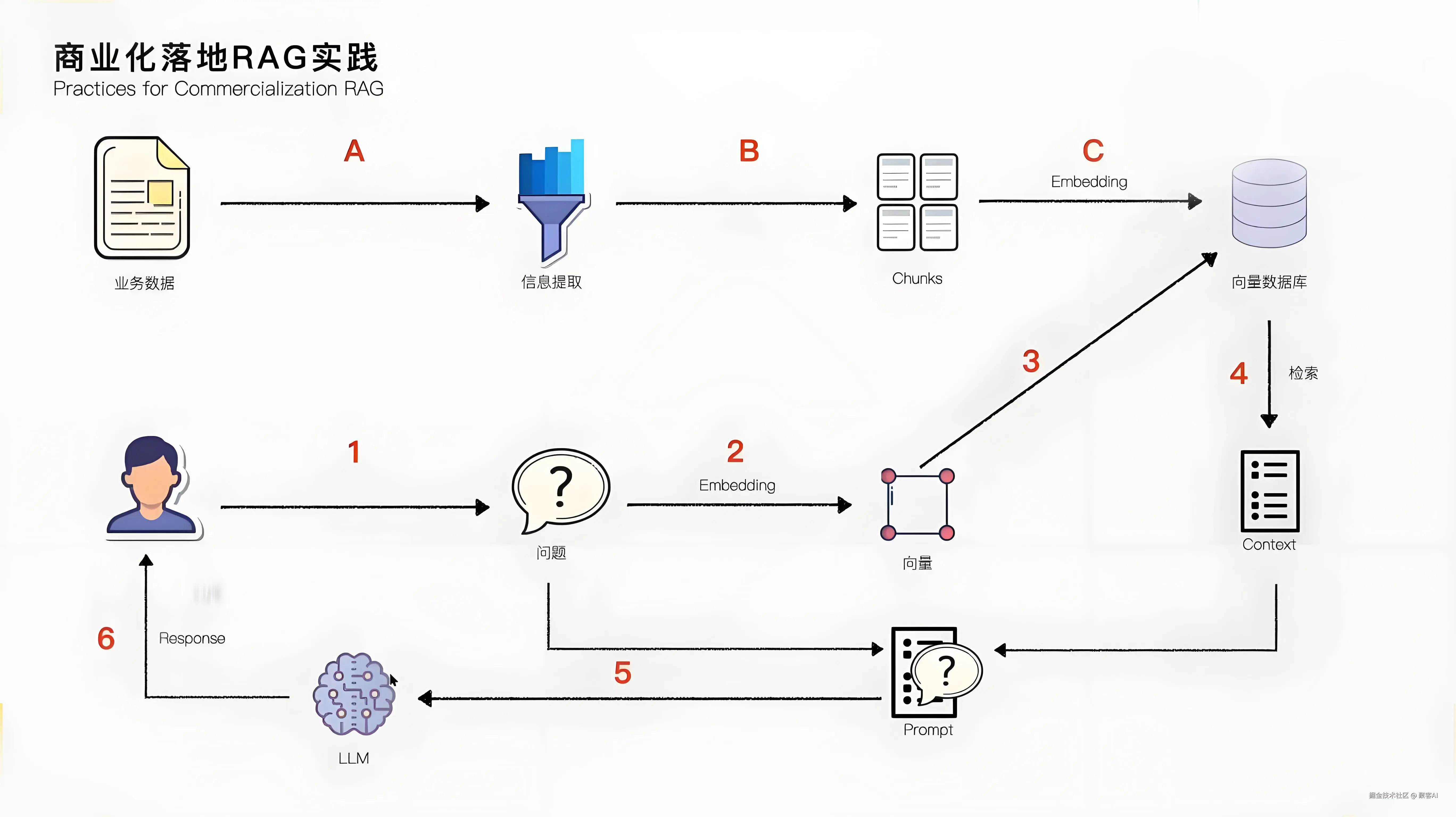
二、RAG的核心架构:离线索引与在线检索生成的闭环
RAG技术基于"用检索事实约束生成"的逻辑,实现分为两个阶段:离线索引(预处理知识库)和在线检索生成(实时响应查询)。这种架构确保高效性和可扩展性。
1、离线索引阶段:构建可检索的知识块
此阶段将非结构化文档(如PDF、Word或网页)转化为语义可计算的格式,包括以下步骤:
- 数据加载:从企业系统(如SharePoint)或公共源(如新闻API)收集文档,确保覆盖全业务场景(如客户服务SOP)。
- 分割分块:将长文档切成100-500字的语义块,以适配LLM的上下文窗口限制(例如GPT-4的8,192 token限制)。分割需按自然语义边界进行(如章节或段落),保持块内完整性。
- 向量化(Embedding):使用嵌入模型(如text-embedding-3-small或Sentence-BERT)将文本块转换为向量(数字数组),实现语义相似性计算(例如"猫"和"狗"向量相近)。
- 存储:将向量和文本块存入向量数据库(如Chroma或Milvus),支持高效相似性搜索(百万级数据中快速返回Top-K结果)。
2、在线检索生成阶段:实时查询处理
用户查询时,RAG执行以下步骤生成答案:
- 查询向量化:用相同嵌入模型将用户问题(如"iPhone16发布时间")转换为向量,确保与数据库向量在同一语义空间。
- 相似性搜索:在向量数据库中查找Top-K相似块(例如Top-5),如查询"iPhone发布时间"时匹配到"苹果发布会新闻"块。
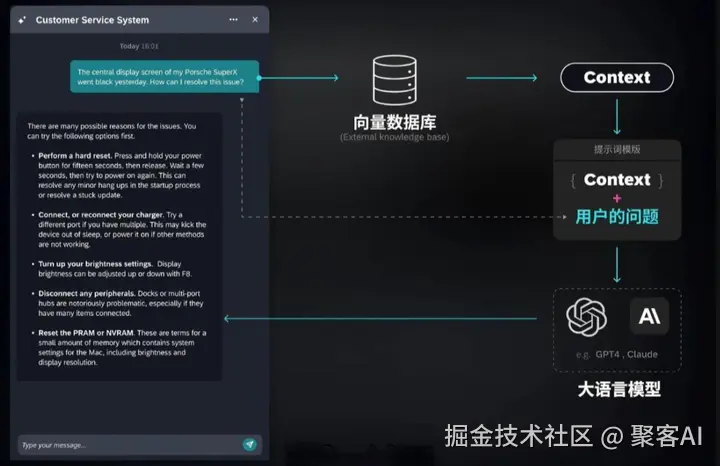
- 构造增强提示(Prompt):将检索块和问题拼接为指令
例如:"严格根据以下内容回答:内容1:2024年iPhone16于3月12日发布(来源:苹果官网);问题:iPhone16发布时间?"此步骤通过约束词("严格根据")防止LLM幻觉。
- 生成答案:LLM基于提示输出结果,如"iPhone16系列于2024年3月12日发布"。此时,LLM角色变为事实整合器,而非依赖静态记忆。
三、高级RAG优化:解决基础架构的瓶颈
基础RAG(Naive RAG)存在检索不准、上下文冗余和查询模糊等瓶颈。高级RAG通过三个优化方向提升性能:
1、查询优化:将模糊用户问题转化为精准检索指令:
- 查询重写:用LLM改写问题,例如将"苹果新品什么时候出"优化为"2024年苹果iPhone系列发布时间"。
- HyDE(假设文档嵌入):让LLM生成假设答案(如"解决客户投诉的步骤:1.倾听;2.道歉"),再用于检索,提升相关性。
- 多轮查询:拆分复杂问题,例如"某公司2023年净利润及增长率"分解为子问题分别检索。
2、检索优化:结合语义与关键词以提高覆盖率:
- 混合搜索:融合稠密向量检索(语义相似)和稀疏检索(如BM25关键词匹配),例如查询"BM25算法"时同时搜索语义块和关键词块。
- 重排序:用交叉编码器对Top-K块打分,筛选最相关块(如仅输入得分>8的块)。
3、后处理:精炼检索结果:
- 上下文压缩:用LLM压缩冗余块,例如将"iPhone16发布会细节"简化为核心发布时间。
- 冗余过滤:基于向量相似性去重。
ps:关于RAG检索增强生成的技术优化,其实之前我也写过很多,这里就不再过多展示,我这里把之前的一些技术文档整理给粉丝朋友,点个小红心自行领取:《检索增强生成(RAG)》
总结
RAG并非替代LLM,而是通过动态知识库、事实约束和专业知识植入来弥补其短板。在实际应用中,RAG已证明价值。例如:制造行业用于设备维护助手(基于故障手册生成维修步骤)、零售行业用于智能导购(整合产品参数和用户评价)。未来,随着向量数据库和嵌入模型的优化,RAG将继续成为企业级AI的核心支柱,其核心逻辑------以检索事实约束生成------将确保AI从演示工具进化为生产力引擎。好了,今天的分享就到这里,点个小红心,我们下期再见。