Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
0. 前言
在本节中,我们将介绍如何微调 Transformer 语言模型用于多类别文本分类,使用土耳其语预训练模型 BERTurk,在自定义新闻分类数据集上完成七类别文本分类任务,涵盖了数据下载与预处理、标签映射与分布可视化、构建 Dataset 与 DataLoader、配置 Trainer 训练参数,定义宏平均 F1、精准率、召回率等评估指标。
1. 数据处理
在本节中,我们将微调土耳其语 BERT 模型 BERTurk,使用自定义数据集执行七类别分类任务。数据集来源于土耳其报纸,包含了七个类别,首先从Kaggle 网站下载数据集并解压缩。
(1) 加载数据:
python
import pandas as pd
data= pd.read_csv("TTC4900.csv")
data=data.sample(frac=1.0)(2) 使用 id2label 和 label2id 组织 ID 和标签,以便让模型能够识别 ID 与标签的对应关系。将标签数量 NUM_LABELS 传递给模型,以指定在 BERT 模型中的分类头的层大小:
python
labels=["teknoloji","ekonomi","saglik","siyaset","kultur","spor","dunya"]
NUM_LABELS= len(labels)
id2label={i:l for i,l in enumerate(labels)}
label2id={l:i for i,l in enumerate(labels)}
data["labels"]=data.category.map(lambda x: label2id[x.strip()])
data.head()输出结果如下所示:

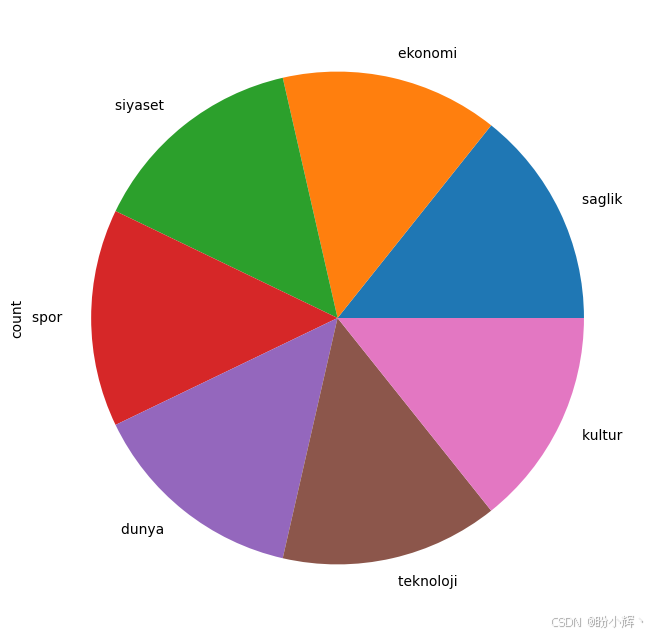
(3) 使用 pandas 对象来统计和绘制类别数量:
python
data.category.value_counts().plot(kind='pie', figsize=(8,8))如下图所示,数据集的类别分布较为均匀:
2. 模型实例化与训练
(1) 实例化一个序列分类模型,包含标签数量 (7)、标签 ID 映射关系以及 BERTurk 模型:
python
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("dbmdz/bert-base-turkish-uncased", max_length=512)
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("dbmdz/bert-base-turkish-uncased", num_labels=NUM_LABELS, id2label=id2label, label2id=label2id)
model.to(device)输出模型的简要信息,在本节中,我们主要关注最后一层:
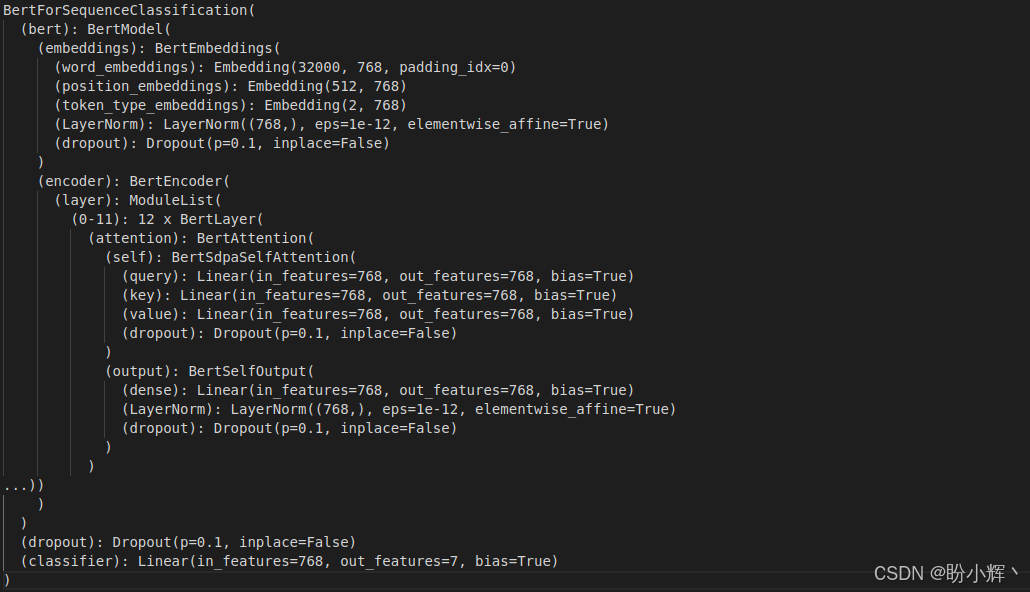
可以看到,我们并未选择 DistilBert,因为没有针对土耳其语的预训练无大小写 DistilBert模型。
(2) 准备训练集 (50%)、验证集 (25%) 和测试集 (25%):
python
SIZE= data.shape[0]
train_texts= list(data.text[:SIZE//2])
val_texts= list(data.text[SIZE//2:(3*SIZE)//4 ])
test_texts= list(data.text[(3*SIZE)//4:])
train_labels= list(data.labels[:SIZE//2])
val_labels= list(data.labels[SIZE//2:(3*SIZE)//4])
test_labels= list(data.labels[(3*SIZE)//4:])
len(train_texts), len(val_texts), len(test_texts)
# (2450, 1225, 1225)(3) 对三个数据集的句子进行分词,转换为整数 (input_ids),然后将它们输入到 BERT 模型中:
python
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)(4) 实现 MyDataset 类。该类继承自抽象的 Dataset 类,通过重写 __getitem__ 和 __len__() 方法,分别返回数据集的数据样本和数据集大小:
python
from torch.utils.data import Dataset
import torch
class MyDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = MyDataset(train_encodings, train_labels)
val_dataset = MyDataset(val_encodings, val_labels)
test_dataset = MyDataset(test_encodings, test_labels)(5) 设置批大小为 16:
python
from transformers import TrainingArguments, Trainer
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='macro')
acc = accuracy_score(labels, preds)
return {
'Accuracy': acc,
'F1': f1,
'Precision': precision,
'Recall': recall
}
training_args = TrainingArguments(
# The output directory where the model predictions and checkpoints will be written
output_dir='./TTC4900Model',
do_train=True,
do_eval=True,
# The number of epochs, defaults to 3.0
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
# Number of steps used for a linear warmup
warmup_steps=100,
weight_decay=0.01,
logging_strategy='steps',
# TensorBoard log directory
logging_dir='./multi-class-logs',
logging_steps=50,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
fp16=True,
load_best_model_at_end=True
)多类别文本分类和情感分析采用相同的评估指标------即宏平均 F1、精准率和召回率。
(6) 实例化 Trainer 对象:
python
trainer = Trainer(
# the pre-trained model that will be fine-tuned
model=model,
# training arguments that we defined above
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics= compute_metrics
)(7) 开始训练过程:
trainer.train()输出结果如下所示:

3. 模型评估
(1) 为了检查训练好的模型,我们在三个数据集划分上评估微调后的模型,最佳模型的验证损失为 0.311731:
python
q=[trainer.evaluate(eval_dataset=data) for data in [train_dataset, val_dataset, test_dataset]]
pd.DataFrame(q, index=["train","val","test"]).iloc[:,:5]输出结果如下所示:

分类准确率大约为 93.0%,宏平均 F1 大约为 92.99。在该土耳其语基准数据集上进行测试,TF-IDF 和线性分类器、word2vec 嵌入,或基于 LSTM 的分类器最佳 F1 值大约为 90.0。与这些方法相比,微调后的 BERT 模型的表现更好。
(2) 可以通过 TensorBoard 监测模型训练进展:
shell
%load_ext tensorboard
%tensorboard --logdir multi-class-logs/(3) 接下来,实现 predict 函数运行模型进行推理。如果希望得到实际标签而不是 ID,可以使用模型的 config 对象:
python
from transformers import DistilBertForSequenceClassification, DistilBertTokenizerFast
def predict(text):
inputs = tokenizer(text, padding=True, truncation=True, max_length=512, return_tensors="pt").to("cuda")
outputs = model(**inputs)
probs = outputs[0].softmax(1)
return probs, probs.argmax(),model.config.id2label[probs.argmax().item()](4) 调用 predict 函数进行文本分类推理:
python
text = "Fenerbahçeli futbolcular kısa paslarla hazırlık çalışması yaptılar"
predict(text)
# (tensor([[1.0262e-03, 1.9993e-03, 1.1139e-03, 2.0719e-03, 6.1755e-04, 9.9115e-01,
# 2.0249e-03]], device='cuda:0', grad_fn=<SoftmaxBackward0>),
# tensor(5, device='cuda:0'),
# 'spor')可以看到,模型正确地将输入句子预测为体育 (spor) 类别。
(5) 接下来,保存模型,并使用 from_pretrained() 函数重新加载:
python
model_path = "turkish-text-classification-model"
trainer.save_model(model_path)
tokenizer.save_pretrained(model_path)(6) 重新加载保存的模型,并借助 pipeline 类进行推理:
python
model_path = "turkish-text-classification-model"
from transformers import pipeline, BertForSequenceClassification, BertTokenizerFast
model = BertForSequenceClassification.from_pretrained(model_path)
tokenizer= BertTokenizerFast.from_pretrained(model_path)
nlp= pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)虽然任务名称是 sentiment-analysis (情感分析),但这个参数实际上会返回 TextClassificationPipeline (文本分类管道):
python
nlp("Sinemada hangi filmler oynuyor bugün")
# [{'label': 'kultur', 'score': 0.9874143004417419}]
nlp("Dolar ve Euro bugün yurtiçi piyasalarda yükseldi")
# [{'label': 'ekonomi', 'score': 0.9944096207618713}]
nlp("Bayern Münih ile Barcelona bugün karşı karşıya geliyor. Maçı İngiliz hakem James Watts yönetecek!")
# [{'label': 'spor', 'score': 0.9957844614982605}]可以看到,模型成功完成了预测。
小结
本节介绍了如何在少量样本下高效微调多分类 Transformer 模型,使用微调 BERTurk 模型在土耳其语新闻数据集上取得了约 93.0% 的测试准确率和 92.99% 的宏平均 F1 分数,详细介绍了数据划分、自定义 MyDataset 实现、训练循环与 Trainer 用法,以及如何使用 pipeline 快速进行推理。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型