这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
一、概述
在机器学习的应用中,特别是在医疗诊断领域,准确评估分类模型的性能至关重要。然而,当面对罕见疾病的分类问题时,传统的性能评估指标,如总体准确率,可能无法充分反映模型在识别稀有事件方面的能力。这是因为在罕见疾病的背景下,数据集往往高度不平衡,即负类(无疾病)的样本数量远远超过正类(有疾病)的样本数量。
本文旨在探讨在这种不平衡数据集上,如何更有效地评估分类模型的性能。我们将通过一个具体的例子来说明,即使一个模型在测试集上达到了99%的高准确率,这也可能掩盖了它在识别罕见疾病方面的不足。这是因为在只有0.5%的患者实际患有疾病的情况下,一个总是预测"无疾病"的模型也能轻易达到高准确率。
为了解决这个问题,我们将引入两个更为精细的性能评估指标:精确度(Precision)和召回率(Recall)。精确度衡量的是在所有被预测为正类的样本中,实际为正类的比例;而召回率衡量的是在所有实际为正类的样本中,被正确预测为正类的比例。这两个指标能够更全面地反映模型在处理不平衡数据集时的性能,尤其是在识别罕见疾病方面的能力。
通过本文的分析,我们希望读者能够理解在罕见疾病分类中,为什么需要超越传统的准确率指标,并学会如何利用精确度和召回率来更准确地评估和改进分类模型。
二、罕见疾病的分类例子

这幅图展示了一个罕见疾病分类的例子,其中:
-
训练了一个分类器 fw ,b (x),用于预测疾病是否存在。
-
在测试集上,该分类器的错误率为1%,即99%的诊断是正确的。
-
然而,只有0.5%的患者实际上患有这种疾病。
-
如果分类器总是预测"y=0"(即没有疾病),其错误率会是0.5%。
-
图中强调了即使分类器有99.5%的准确率,仍然存在1%的错误率,这在罕见疾病分类中可能是不可接受的。
三、精确度与召回率的计算
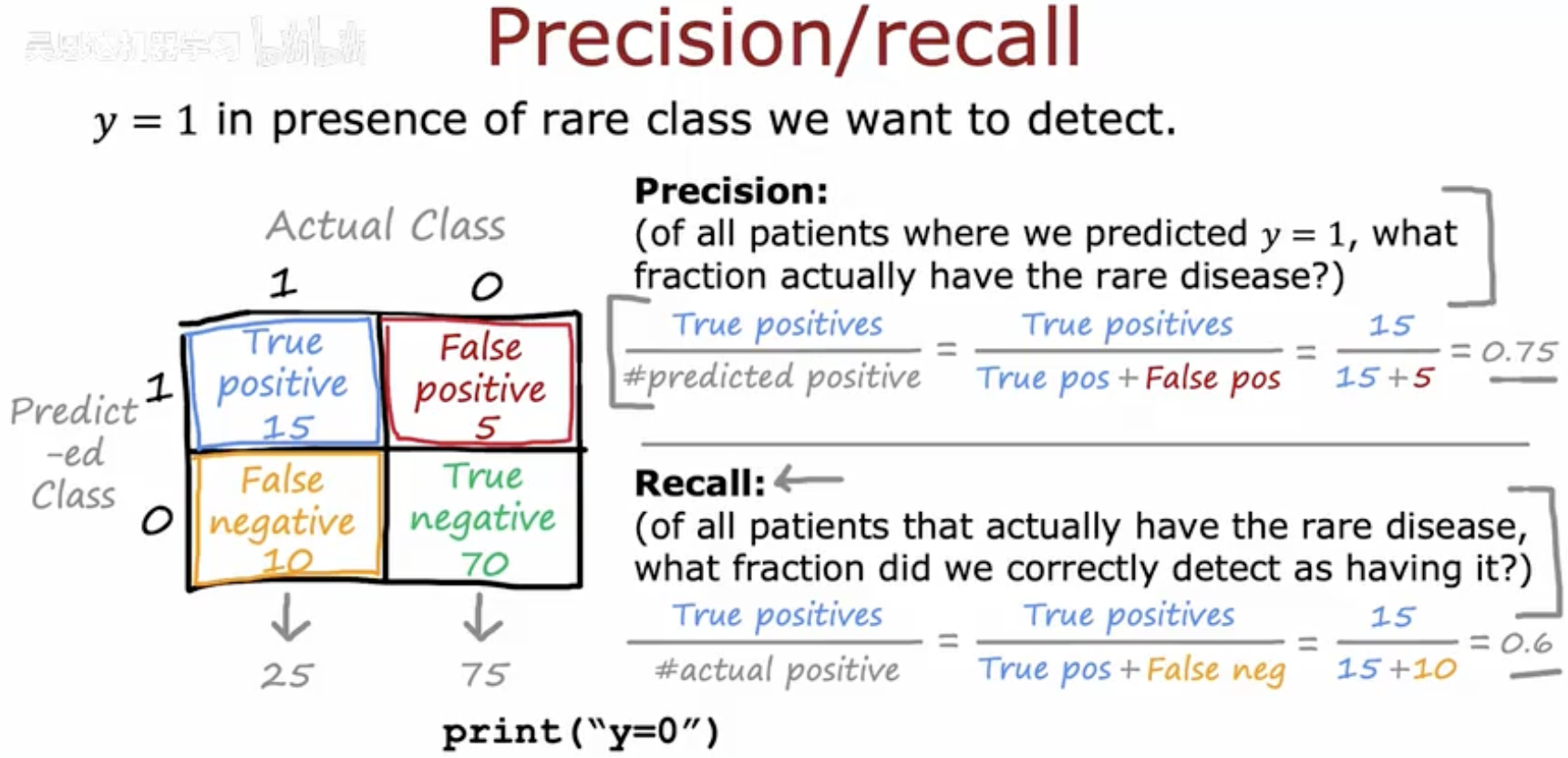
这幅图解释了精确度(Precision)和召回率(Recall)的概念,并通过一个混淆矩阵展示了这些指标的计算方法。
-
混淆矩阵:图中展示了一个2x2的矩阵,用于表示分类器的预测结果与实际结果的对比。
-
True Positive (TP):预测为1且实际为1的数量是15。
-
False Positive (FP):预测为1但实际为0的数量是5。
-
True Negative (TN):预测为0且实际为0的数量是70。
-
False Negative (FN):预测为0但实际为1的数量是10。
-
-
精确度(Precision):计算公式为
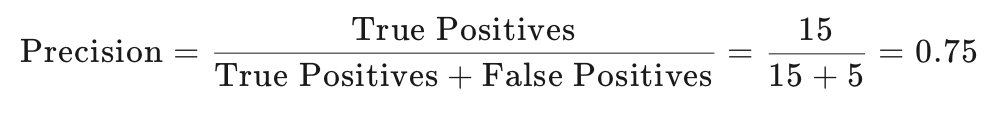
这表示在所有被预测为1的样本中,有75%实际上是1。
-
召回率(Recall):计算公式为
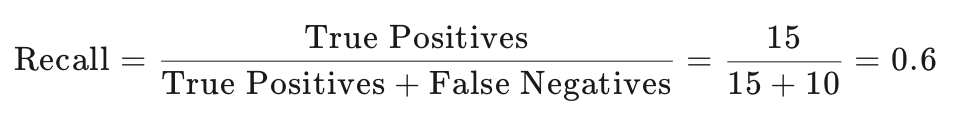
这表示在所有实际为1的样本中,有60%被正确预测为1。
图中还指出,如果分类器总是预测"y=0",则没有假阳性,但会有10个假阴性,这在某些情况下可能是不可接受的
四、精确度与召回率的解释与总结
精确度(Precision)解释
精确度是衡量模型预测为正类(如疾病存在)的样本中,实际为正类的比例。它关注的是预测的准确性。精确度的计算公式为:

在本例中,精确度为0.75,意味着在所有被预测为患有疾病的患者中,有75%实际上是患有疾病的。
召回率(Recall)解释
召回率是衡量实际为正类的样本中,被模型正确预测为正类的比例。它关注的是模型的覆盖能力,即模型能够识别出多少实际的正类样本。召回率的计算公式为:
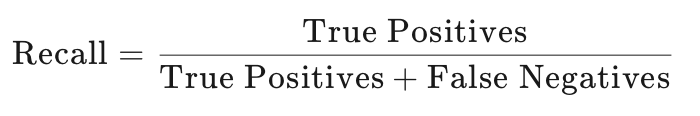
在本例中,召回率为0.6,意味着在所有实际患有疾病的患者中,有60%被模型正确识别出来。
总结
在处理罕见疾病分类问题时,精确度和召回率是两个非常重要的评估指标。精确度高意味着模型在预测为正类时的准确性高,而召回率高意味着模型能够识别出更多的实际正类样本。
在本例中,尽管模型的总体准确率为99%,但如果我们只关注准确率,可能会忽略模型在识别罕见疾病方面的不足。通过精确度和召回率的分析,我们可以更全面地了解模型在处理不平衡数据集时的性能,从而更好地评估和改进模型。这对于医疗诊断等关键应用尤为重要,因为在这些领域,漏诊或误诊可能带来严重后果。
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!