随着大数据与深度学习的发展,时间序列分析的建模能力显著提升,而掩码重建作为一种自监督学习范式,已成为提升序列表征能力的重要技术。该方法通过随机掩码部分数据并重建原始序列,迫使模型挖掘时序依赖性与潜在模式,在减少标注依赖的同时增强鲁棒性。近年来,相关研究聚焦于如何结合掩码策略优化特征提取、解决噪声与缺失值问题,并探索与非平稳性、多变量交互等复杂场景的适配性。
我整理了时间序列+掩码重建领域的前沿论文 ,涵盖不同掩码机制与Transformer、GAN等架构的融合创新,供大家学习与参考,有需要可以自取。
论文这里
一、An Experimental Reservoir-Augmented Foundation Model: 6G O-RAN Case Study
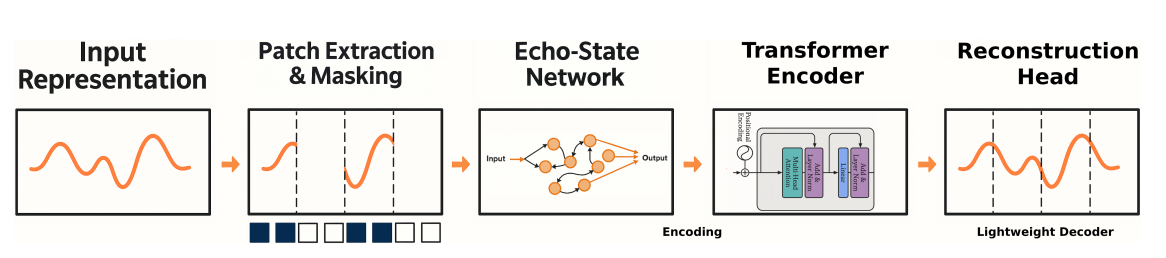
1. 方法
本文提出了一种新型的时间序列基础模型 RA-MAT,旨在处理6G开放无线接入网络(O-RAN)中生成的超高维、非平稳时间序列数据。RA-MAT结合了回声状态网络(ESN)计算与掩码自编码技术,以满足6G O-RAN测试对延迟、能效和可扩展性的严格要求。它通过固定的随机初始化ESN快速将每个时间片段投影到丰富的动态嵌入中,避免了时间反向传播的计算开销。
2. 创新点
-
融合ESN与Transformer的创新架构
将回声状态网络(ESN)与掩码自编码Transformer结合,通过固定随机初始化权重,快速将时间序列片段投影为动态嵌入,既保留时序非线性特征,又避免反向传播的高计算成本。
-
面向6G场景的工程优化
针对6G网络超高维、非平稳时序特性,模型通过ESN的动力学系统建模能力捕捉复杂模式,并结合Transformer的全局注意力机制增强跨片段关联分析,最终在O-RAN测试中实现MSE < 0.06的高精度预测,验证了其在实时性、鲁棒性方面的实用性。
论文链接:https://arxiv.org/abs/2508.07778v1
代码链接:https://github.com/frezazadeh/Time-Series-Foundation-Model
二、Spatial Imputation Drives Cross-Domain Alignment for EEG Classification
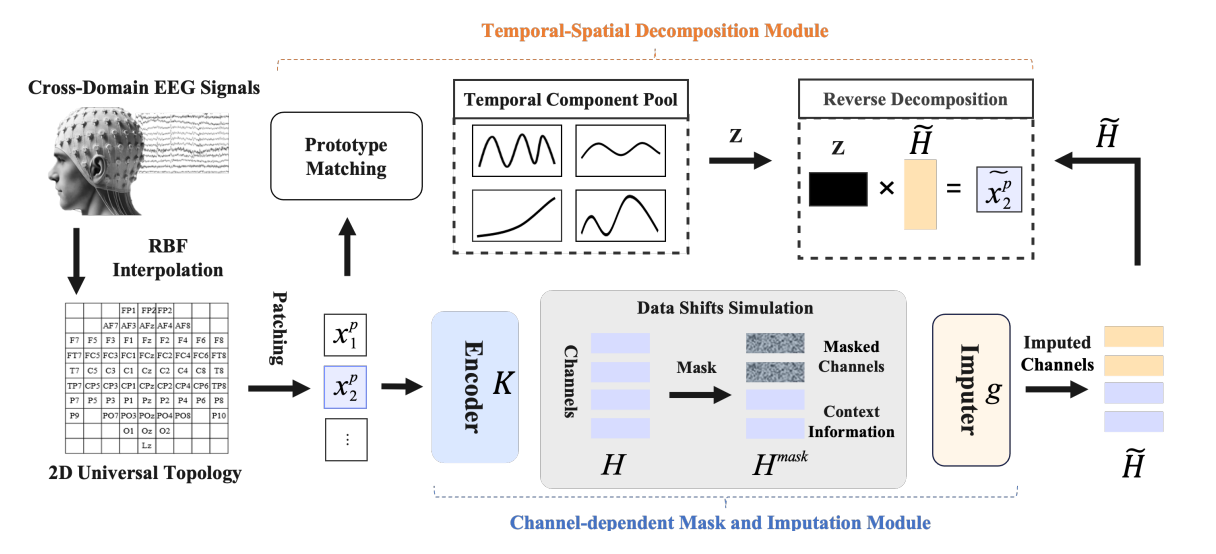
1.方法
本文介绍了一种新颖的自监督学习框架IMAC,旨在解决跨域脑电图(EEG)分类中的数据偏移问题。IMAC通过引入通道依赖的掩码和插补机制,将跨域EEG数据的对齐问题视为空间时间序列插补任务。
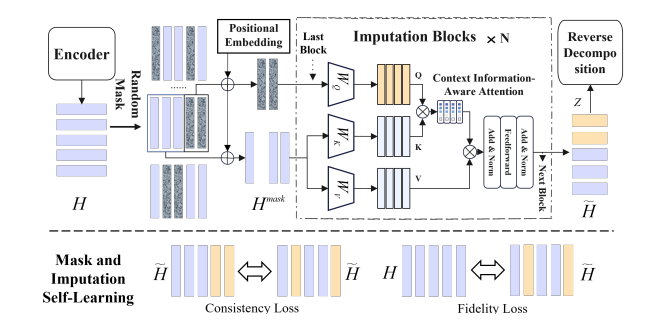
2. 创新点
-
跨域问题重构
首次提出将跨域脑电(EEG)分类中的数据偏移问题转化为时空信号插补任务,通过模拟通道缺失与重建对齐异构域分布。
-
动态通道掩码机制
设计通道依赖的自适应掩码策略,根据域间差异程度动态选择掩码位置。相比于随机掩码,该方法能更精准地模拟真实场景下的数据偏移模式,增强模型对未知域的泛化能力。
-
时间-空间解耦建模:
提出分解式时空表示模块,将EEG信号分离为独立的时间动态成分与空间依赖成分。通过双分支结构分别学习时间局部相关性与跨通道空间关系,避免跨域噪声干扰关键特征。
-
混合损失联合优化
结合插补损失(重建EEG信号)、对比损失(域不变特征学习)与分类损失(下游任务导向),多目标协同驱动模型平衡跨域对齐与分类性能,抑制过拟合特定域噪声的问题。
论文链接:https://arxiv.org/abs/2508.03437v1
三、IMTS is Worth Time Channel Patches: Visual Masked Autoencoders for Irregular Multivariate Time Series Prediction
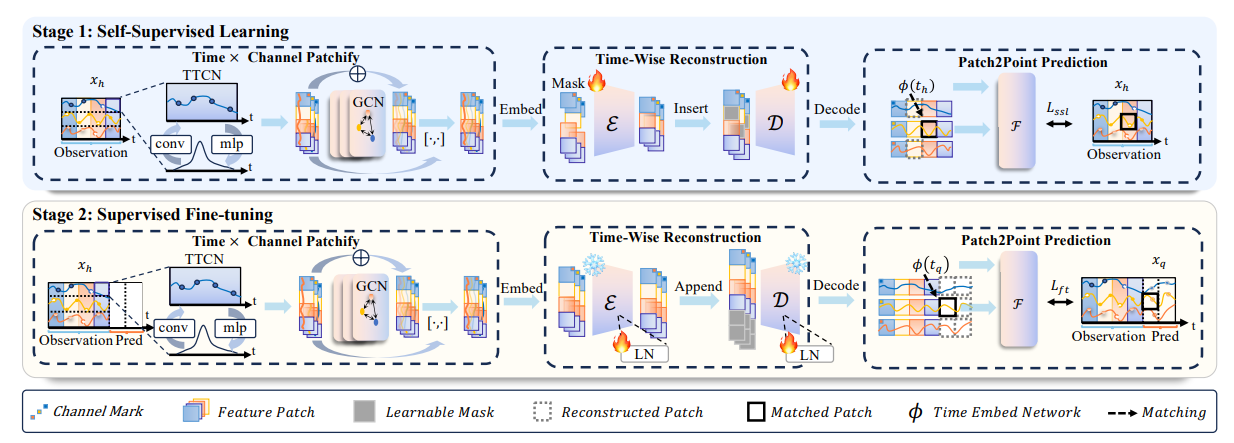
1. 方法
本文提出了一种新颖的框架VIMTS,旨在处理不规则多变量时间序列(IMTS)预测。该框架利用视觉预训练的掩码自编码器(MAE)来建模稀疏的多通道数据。解码过程中采用粗到细的策略,从补丁逐步生成精确的时间点预测。
2. 创新点
-
异构数据统一表征策略
提出时间对齐的特征补丁化编码方法,将多变量时间序列切割为跨通道的连续时间块,并引入通道相关性补偿层,动态融合不同传感器通道的关联信息,缓解缺失值导致的局部模式断裂问题。
-
粗到细渐进式解码机制
解码器采用分层重构策略,首先生成粗粒度的全局趋势预测,再通过残差细化网络逐步校正细节。该方法显著提升对长程依赖和局部突变的联合建模能力,避免一步预测的误差累积。
-
两阶段轻量化适配框架:
通过自监督预训练(掩码重建) + 监督微调两阶段策略,最大化利用无标注数据提取通用时序模式,同时减少下游任务对标注数据量的需求。