
笔者链接:扑克中的黑桃A
专栏链接:论文精读
本文关键词 :知识图谱; 表示学习; 链接预测; 多元关系; 超关系
引
诸位技术同仁:
本系列将系统精读的方式,深入剖析计算机科学顶级期刊/会议论文,聚焦前沿突破的核心机理与工程实现。
通过严谨的学术剖析,解耦研究范式、技术方案及实证方法,揭示创新本质。我们重点关注理论-工程交汇点的技术跃迁,提炼可迁移的方法论锚点,助力诸位的技术实践与复杂问题攻坚,共推领域持续演进。

每日一句
所有的忧伤都是过往,
当时间慢慢沉淀,
你会发现,
自己的快乐比想象的多得多。

目录
[1.知识图谱:结构化的 "知识通讯录"](#1.知识图谱:结构化的 “知识通讯录”)
[2. 链接预测:补全 "知识地图" 的核心任务](#2. 链接预测:补全 “知识地图” 的核心任务)
[3. 表示学习:让计算机 "理解" 知识的桥梁](#3. 表示学习:让计算机 “理解” 知识的桥梁)
[二.知识表示形式:从简单到复杂的 "知识编码" 演进](#二.知识表示形式:从简单到复杂的 “知识编码” 演进)
[1. 二元关系:知识表示的 "基础句型"](#1. 二元关系:知识表示的 “基础句型”)
[2. 多元关系:表达复杂知识的 "长句型"](#2. 多元关系:表达复杂知识的 “长句型”)
[3. 超关系:主次分明的复杂知识表示](#3. 超关系:主次分明的复杂知识表示)
[三.面向二元关系的表示学习模型:四类经典 "建模方法"](#三.面向二元关系的表示学习模型:四类经典 “建模方法”)
[1. 平移距离模型:基于 "空间平移" 的语义建模](#1. 平移距离模型:基于 “空间平移” 的语义建模)
[(1) 经典模型:TransE](#(1) 经典模型:TransE)
[(2) 优化方向与衍生模型](#(2) 优化方向与衍生模型)
[2. 张量分解模型:基于 "矩阵分解" 的关联捕捉](#2. 张量分解模型:基于 “矩阵分解” 的关联捕捉)
[(1) 经典模型:RESCAL](#(1) 经典模型:RESCAL)
[(2) 优化方向与衍生模型](#(2) 优化方向与衍生模型)
[3. 传统神经网络模型:基于 "特征提取" 的非线性建模](#3. 传统神经网络模型:基于 “特征提取” 的非线性建模)
[(1) 卷积神经网络(CNN)](#(1) 卷积神经网络(CNN))
[(2) 其他神经网络模型](#(2) 其他神经网络模型)
[4. 图神经网络模型:基于 "信息传播" 的结构建模](#4. 图神经网络模型:基于 “信息传播” 的结构建模)
[(1) 核心思想](#(1) 核心思想)
[(2) 经典模型](#(2) 经典模型)
[(3) 与其他模型的区别](#(3) 与其他模型的区别)
[1. 多元关系的表示学习模型](#1. 多元关系的表示学习模型)
[(1) 平移距离模型的扩展](#(1) 平移距离模型的扩展)
[(2) 张量分解模型的扩展](#(2) 张量分解模型的扩展)
[(3) 传统神经网络模型的扩展](#(3) 传统神经网络模型的扩展)
[2. 超关系的表示学习模型](#2. 超关系的表示学习模型)
[(1) 传统神经网络模型的扩展](#(1) 传统神经网络模型的扩展)
[(2) 图神经网络模型的扩展](#(2) 图神经网络模型的扩展)
[五.实验对比与分析:不同模型的 "实战表现"](#五.实验对比与分析:不同模型的 “实战表现”)
[1. 常用数据集](#1. 常用数据集)
[(1) 二元关系数据集](#(1) 二元关系数据集)
[(2) 多元关系数据集](#(2) 多元关系数据集)
[(3) 超关系数据集](#(3) 超关系数据集)
[2. 评测指标](#2. 评测指标)
[3. 实验结果分析](#3. 实验结果分析)
[(1) 二元关系模型对比](#(1) 二元关系模型对比)
[(2) 多元关系模型对比](#(2) 多元关系模型对比)
[(3) 超关系模型对比](#(3) 超关系模型对比)
[(4) 关键结论](#(4) 关键结论)
[1. 模型优化:提升可解释性与可扩展性](#1. 模型优化:提升可解释性与可扩展性)
[2. 知识表示形式:融合更多结构与信息](#2. 知识表示形式:融合更多结构与信息)
[3. 问题作用域:针对特定场景定制模型](#3. 问题作用域:针对特定场景定制模型)
文献来源
杜雪盈, 刘名威, 沈立炜, 彭鑫. 面向链接预测的知识图谱表示学习方法综述.
DOI:10.13328/j.cnki.jos.006902
软件学报, 2024, 35(1): 87--117.
已标明出处,如有侵权请联系笔者。
在信息爆炸的时代,我们每天都会接触到海量数据,但这些数据大多以零散的文字、图片等形式存在,就像散落的拼图碎片。知识图谱(Knowledge Graph, KG)的出现,将这些碎片拼接成一张结构化的 "知识地图"------ 实体是地图上的城市,关系是连接城市的道路,让我们能清晰看到知识之间的关联。然而,这张 "地图" 却常常存在 "道路缺失" 的问题:全球知名的知识图谱 FreeBase 中,70% 的人物实体没有出生地信息,99% 缺失种族信息;Wikidata 虽覆盖更广,但仍有大量复杂关系未被记录。这种不完整性就像地图上关键路段的缺失,严重影响了知识的应用价值 ------ 在信息检索中,可能漏掉相关结果;在问答系统中,无法回答涉及未记录关系的问题
为了补全这张 "知识地图",链接预测(Link Prediction)技术应运而生。它能根据已有 "道路" 推测缺失的 "连接",比如根据 "(北京,是首都,中国)" 和 "(中国,位于,亚洲)",推测出 "(北京,位于,亚洲)" 这一缺失关系。而实现链接预测的核心,是知识图谱表示学习(Knowledge Graph Representation Learning)------ 将实体和关系从文字符号转换为计算机可计算的数值向量,就像把地图上的城市坐标化,让计算机能通过坐标计算距离和方向,从而推测未知的 "道路"
就像量子计算系统有 "应用→系统软件→体系结构→硬件" 的完整链条,知识图谱要从 "零散数据" 变成 "可用工具",也离不开 "构建图谱→发现缺失→补全链接" 的核心流程。咱们沿着 "是什么→缺什么→怎么补" 的思路,逐个拆解。
本文将系统解读面向链接预测的知识图谱表示学习方法,从知识图谱的基本构成与链接预测的核心目标出发,拆解二元关系、多元关系、超关系三种知识表示形式,详解平移距离、张量分解、传统神经网络、图神经网络四类表示学习模型的原理与演化,并通过实验对比揭示不同模型的性能差异,最后展望未来研究方向。通过本文,读者将全面掌握知识图谱补全的核心技术,理解计算机如何 "读懂" 知识并推测未知关联。
一.知识图谱与链接预测的基础认知
1.知识图谱:结构化的 "知识通讯录"
知识图谱本质是存 "谁与谁有啥关联" 的数据库,由实体 (图的节点)和关系(图的边)组成,比如 "(李白,创作,《静夜思》)""(《静夜思》,属于,诗歌)"。
- 经典类比:就像经典计算机里的 "关系型数据库",实体是 "数据表的行",关系是 "数据表的列",存的是结构化的 "实体 - 关系 - 实体" 三元组,而非杂乱的文本段落。
- 人话类比:就像你手机里的通讯录 ------"张三""李四" 是联系人(实体),"同事""大学同学""同住一个小区" 是关系,你能一眼看清谁和谁有关联,而不是把所有名字堆在无分类的备忘录里。
目前,学术界和工业界已构建了多个大规模知识图谱:
FreeBase
由谷歌构建的开放知识图谱,包含大量实体和关系,但存在严重的信息缺失,如前文所述的人物属性缺失问题。
Wikidata
维基百科支持的协作式知识图谱,数据更全面,且允许用户持续编辑补充,就像一张不断更新的 "活地图"。
DBpedia
从维基百科中抽取结构化知识形成的图谱,聚焦于实体的属性和分类,如 "(北京,首都,中国)""(北京,人口,2154 万)"。
YAGO
融合维基百科和 WordNet 的知识图谱,强调实体的时间和空间属性,如 "(爱因斯坦,出生于,1879 年)"。
但现有图谱都有 "通讯录备注不全" 的问题:
FreeBase 中 70% 的人物实体没 "出生地" 信息,99% 缺失 "种族" 信息;
连 "(鱼,生活在,水)" 这种常识,Wikidata 都可能漏记。
......
这就像你通讯录里有人没填手机号、有人没标 "所属部门",真要联系或找人时,总会 "卡壳"。
这种缺失会导致知识图谱在应用中 "力不从心"------ 比如智能问答系统无法回答 "鱼生活在哪里?",推荐系统无法基于未记录的关系推荐相关内容。
2. 链接预测:补全 "知识地图" 的核心任务
链接预测是知识图谱补全(Knowledge Graph Completion)的核心任务,目标是根据知识图谱中已有的实体和关系,预测缺失的实体或关系。具体可分为两类子任务:
- 实体预测:已知关系和部分实体,预测缺失的实体。例如已知 "(?, 创作,《静夜思》)",预测头实体 "李白";已知 "(李白,创作,?)",预测尾实体 "《静夜思》"。这就像已知 "航线" 和 "终点",推测 "起点";或已知 "起点" 和 "航线",推测 "终点"。
- 关系预测:已知头实体和尾实体,预测它们之间的关系。例如已知 "(李白,?, 《静夜思》)",预测关系 "创作";已知 "(北京,?, 中国)",预测关系 "是首都"。这就像已知 "起点" 和 "终点",推测连接它们的 "航线类型"。
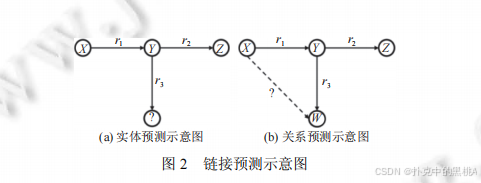
图2左侧展示实体预测场景(用 "?" 标记缺失的头实体),右侧展示关系预测场景(用 "?" 标记缺失的关系),通过具体案例(如 "(?,导演,《流浪地球》)" 预测 "郭帆")直观呈现两类任务的区别。
链接预测的实现依赖于对知识图谱中 "关系模式" 的挖掘。知识图谱中存在多种典型的关系模式,例如:
对称关系
若 "(A,朋友,B)" 成立,则 "(B,朋友,A)" 也成立,如 "朋友""同事"。
反对称关系
若 "(A,父亲,B)" 成立,则 "(B,父亲,A)" 一定不成立,如 "父子""上下级"。
传递关系
若 "(A,属于,B)" 和 "(B,属于,C)" 成立,则 "(A,属于,C)" 也成立,如 "国家 - 省份 - 城市" 的隶属关系。
表示学习模型通过捕捉这些模式,实现对缺失链接的预测。例如,对于传递关系,模型会学习到 "头实体向量 + 关系向量 1 + 关系向量 2 ≈ 尾实体向量" 的规律,从而推测多步关系。
3. 表示学习:让计算机 "理解" 知识的桥梁
知识图谱中的实体和关系以符号形式存在(如 "李白""创作"),而计算机无法直接处理符号之间的语义关联。表示学习的作用,就是将这些符号转换为低维稠密的数值向量(Embedding),让向量之间的运算能够反映语义关系,就像用经纬度表示城市位置,通过经纬度计算距离来反映城市间的实际距离。
表示学习的核心目标是:对于知识图谱中存在的三元组(h, r, t),其向量表示应满足某种 "合理性条件",而对于不存在的三元组,则不满足该条件。例如,TransE 模型要求 "h + r ≈ t",即头实体向量与关系向量的和应接近尾实体向量;ComplEx 模型则通过复数向量的运算捕捉实体与关系的交互。
表示学习与链接预测的关系密不可分:
- 表示学习是链接预测的基础:只有将实体和关系转换为向量,计算机才能通过数值计算推测缺失链接,就像只有将城市坐标化,才能通过坐标计算路线。
- 链接预测是表示学习的重要应用:表示学习的效果通常通过链接预测的准确率来评估,一个好的表示模型应能准确预测缺失的实体或关系,就像准确的坐标系统能帮助我们找到最短路线。
通过表示学习,知识图谱的符号化知识被转化为向量空间中的数值关系,为链接预测、知识推理、信息检索等任务提供了可计算的基础。
二.知识表示形式:从简单到复杂的 "知识编码" 演进
知识的复杂性决定了其表示形式的多样性。从最初的二元关系,到能表达复杂关联的多元关系和超关系,知识表示形式的演进反映了对现实世界知识的更精准刻画。
1. 二元关系:知识表示的 "基础句型"
二元关系是知识图谱中最基本、最常用的表示形式,用三元组(h, r, t)描述 "头实体 - 关系 - 尾实体" 的关联,就像语言中的 "主谓宾" 短句,结构简单且易于处理。例如:
- "(北京,是首都,中国)":头实体 "北京",关系 "是首都",尾实体 "中国"。
- "(爱因斯坦,提出,相对论)":头实体 "爱因斯坦",关系 "提出",尾实体 "相对论"。
数学建模
在二元关系中,链接预测的目标是补全不完整的三元组,具体分为三种情况:
- 头实体缺失:(?, r, t),需预测 h,如 "(?, 发明,电灯)"→"爱迪生"。
- 尾实体缺失:(h, r, ?),需预测 t,如 "(牛顿,发现,?)"→"万有引力"。
- 关系缺失:(h, ?, t),需预测 r,如 "(地球,?, 太阳系)"→"属于"。
模型通过学习实体和关系的向量表示,对所有可能的候选实体或关系进行评分,评分最高的即为预测结果。例如,对于(?, 发明,电灯),模型会计算每个实体 h 的向量与 "发明" 向量 r 的和,与 "电灯" 向量 t 的距离,距离最小的 h 即为预测答案。
优缺点分析
- 优点:结构简单,易于建模和计算,是目前知识图谱中最主流的表示形式。现有大多数表示学习模型都是基于二元关系设计的,如 TransE、DistMult 等。
- 缺点 :表达能力有限,无法刻画包含多个实体或关系的复杂知识。例如,"在 2023 年的电影《流浪地球 2》中,吴京饰演刘培强" 这一事实,包含实体 "吴京""《流浪地球 2》""2023 年""刘培强" 和关系 "参演""上映时间""饰演角色",若拆分为多个二元三元组:
- (吴京,参演,《流浪地球 2》)
- (《流浪地球 2》,上映时间,2023 年)
- (吴京,饰演角色,刘培强)
会丢失 "参演电影""上映时间""饰演角色" 之间的关联信息,就像把一个完整的长句拆成零散的短句,失去了上下文联系。
2. 多元关系:表达复杂知识的 "长句型"
为了表达包含 3 个及以上实体或多个关系的复杂知识,多元关系(N-ary Relations)表示形式应运而生。它用一组 "角色 - 键值对"(Role-Value Pairs)描述知识,其中 "角色" 对应关系,"键值" 对应实体,就像带多个修饰语的长句,能完整呈现知识的细节。例如,上述电影案例的多元关系表示为:
{演员:吴京,电影: 《流浪地球 2》, 上映时间: 2023 年,饰演角色:刘培强}
数学建模
多元关系的一般形式为 {r₁: v₁, r₂: v₂, ..., rₙ: vₙ},其中 n≥3(元数)。链接预测任务需补全缺失的角色或键值:
- 角色缺失:{r₁: v₁, ..., ?: vₙ},需预测缺失的角色 r,如 {演员:吴京,电影: 《流浪地球 2》, ?: 刘培强}→"饰演角色"。
- 键值缺失:{r₁: v₁, ..., rₙ: ?},需预测缺失的键值 v,如 {演员:吴京,电影: ?, 饰演角色:刘培强}→《流浪地球 2》。
多元关系的建模需考虑角色与键值之间的关联,以及不同角色 - 键值对之间的交互。例如,"演员" 和 "饰演角色" 的键值通常存在对应关系(特定演员在特定电影中饰演特定角色),模型需捕捉这种关联以提高预测准确率。
优缺点分析
- 优点:能完整表达复杂知识,保留多个实体和关系之间的关联信息,避免了二元关系拆分导致的语义丢失。
- 缺点:破坏了三元组的结构化形式,所有角色 - 键值对平行存储,缺少主次之分。例如,在 {演员:吴京,电影: 《流浪地球 2》, 上映时间: 2023 年} 中,"演员 - 电影" 是核心关系,"上映时间" 是辅助信息,但多元关系将它们平等对待,可能导致模型无法聚焦核心关联,就像长句中修饰语过多掩盖了主干意思。
3. 超关系:主次分明的复杂知识表示
超关系(Hyper-relations)是多元关系的优化形式,它保留一个主三元组(h, r, t)作为核心知识,其余信息作为 "限定词键值对"(Qualifier Pairs)附加在主三元组上,整体表示为(h, r, t, Q),其中 Q={(q₁: v₁), ..., (qₙ: vₙ)} 是辅助信息,就像 "主题句 + 注释" 的结构,主次分明。例如,上述电影案例的超关系表示为:
(吴京,参演,《流浪地球 2》,{上映时间: 2023 年,饰演角色:刘培强})
数学建模
超关系以主三元组为核心,限定词为辅助,链接预测主要针对主三元组的缺失进行补全,同时利用限定词信息提高预测精度:
- 头实体缺失:(?, r, t, Q),如(?, 参演,《流浪地球 2》, {饰演角色:刘培强})→"吴京"。
- 尾实体缺失:(h, r, ?, Q),如(吴京,参演,?, {上映时间: 2023 年})→《流浪地球 2》。
- 关系缺失:(h, ?, t, Q),如(吴京,?, 《流浪地球 2》, {饰演角色:刘培强})→"参演"。
限定词的作用是提供上下文约束,缩小预测范围。例如,预测 "(?, 参演,《流浪地球 2》)" 时,若已知限定词 "饰演角色:刘培强",模型可更精准地定位到 "吴京",而不是其他参演演员。
优缺点分析
- 优点:既保留了核心语义(主三元组),又包含了辅助信息(限定词),知识表示的准确性和完整性优于二元关系和多元关系。同时,主三元组的结构与现有二元关系模型兼容,便于模型扩展。
- 缺点:对模型的建模能力要求更高,需要区分主三元组与限定词的关联,以及不同限定词之间的交互。例如,模型需理解 "饰演角色" 限定词与主三元组 "参演" 关系的强关联性,而 "上映时间" 限定词的关联性较弱。

图三,以 "本尼迪克特・康伯巴奇在《模仿游戏》中饰演阿兰・图灵并获奥斯卡提名" 为例,分别展示二元关系(拆分为 3 个三元组)、多元关系(4 个角色 - 键值对)、超关系(主三元组 + 2 个限定词)的表示方式,直观呈现三者在语义保留和结构清晰度上的差异。
与知识超图的区别
超图(Hypergraph)中每条边可连接多个节点,知识超图用一条超边连接多元知识中的所有实体,但未区分主次关系,更接近多元关系的表示形式。而超关系通过主三元组明确核心关联,限定词辅助描述,在语义表达上更精准,因此更适合链接预测任务。
三.面向二元关系的表示学习模型:四类经典 "建模方法"
在深入剖析各类表示学习模型的细节前,我们先通过 "知识图谱表示学习技术划分框架",从时间线与模型类别两个角度,直观把握技术发展的整体脉络与分类逻辑。
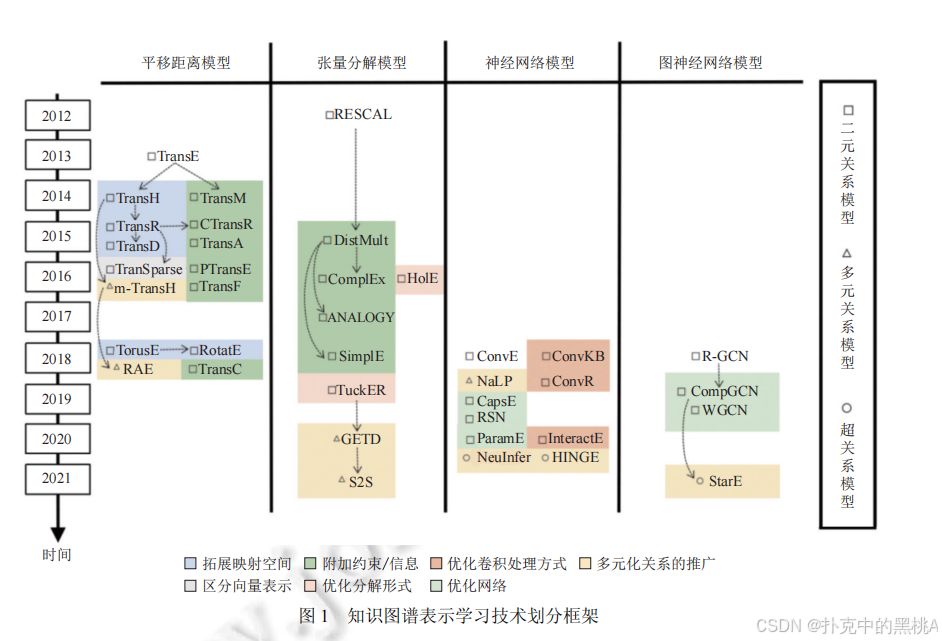
图 1横向划分 "平移距离模型""张量分解模型""神经网络模型""图神经网络模型" 四大类,纵向按年份(2012---2021)排列关键模型,并通过符号(方块、三角形、圆形)区分 "二元关系模型""多元关系模型""超关系模型",同时用颜色标注 "拓展映射空间""附加约束 / 信息""优化卷积处理方式" 等技术优化方向,为后续具体模型的讲解提供全局视角。
接下来,我们将依次详解这四类面向二元关系的表示学习模型的原理、优化与衍生。
二元关系是知识图谱的基础,针对二元关系的表示学习模型已形成四大类:平移距离模型、张量分解模型、传统神经网络模型和图神经网络模型。这些模型从不同角度建模实体与关系的关联,各有优劣。
1. 平移距离模型:基于 "空间平移" 的语义建模
平移距离模型受词向量(Word2Vec)中 "平移不变性" 现象的启发,将关系视为头实体到尾实体的 "平移向量",核心思想是 "头实体向量 + 关系向量 ≈ 尾实体向量",就像在地图上,"起点坐标 + 路线向量 ≈ 终点坐标"。
(1) 经典模型:TransE
TransE 是 2013 年提出的首个平移距离模型,它将每个实体和关系映射到低维向量空间,对于三元组(h, r, t),要求 h + r ≈ t。其评分函数定义为:
f(h,r,t)=∣∣h+r−t∣∣L1/L2
其中,||・|| 表示 L₁或 L₂范数(距离),评分越低,三元组越合理。例如,对于 "(北京,到,上海)",TransE 学习到的向量应满足 "北京 + 到 ≈ 上海"。
TransE 的优点是简单高效,参数少,适合大规模知识图谱;但缺点是无法处理复杂关系,如 1-N(一个头实体对应多个尾实体,如 "母亲 - 子女")、N-1(多个头实体对应一个尾实体,如 "子女 - 父亲")和 N-N(多对多关系,如 "学生 - 老师")。例如,对于 "(小明,母亲,李华)" 和 "(小红,母亲,李华)",TransE 会要求 "小明 + 母亲 ≈ 李华" 和 "小红 + 母亲 ≈ 李华",导致 "小明 ≈ 小红",显然不合理。
(2) 优化方向与衍生模型
为解决 TransE 的缺陷,研究者从多个方向进行优化:
拓展映射空间
- TransH (2014):将实体和关系映射到关系专属的超平面上,头实体 h 和尾实体 t 在超平面上的投影 h⊥、t⊥满足 h⊥ + dᵣ ≈ t⊥(dᵣ是超平面上的平移向量)。超平面通过法线向量 wᵣ定义,投影计算为:
h⊥=h−wrTh⋅wr
t⊥=t−wrTt⋅wr
评分函数为:f(h,r,t)=∣∣h⊥+dr−t⊥∣∣22
TransH 通过超平面区分不同关系的映射空间,能更好处理 1-N 等复杂关系,就像为不同类型的路线(如公路、铁路)设置不同的平面地图。 - TransR (2015):进一步将实体空间与关系空间分离,每个关系 r 对应一个投影矩阵 Mᵣ,实体向量通过 Mᵣ投影到关系空间后再进行平移:
hr=h⋅Mr
tr=t⋅Mr
评分函数为:f(h,r,t)=∣∣hr+r−tr∣∣22
例如,"苹果" 作为水果和公司时,在 "属于 - 水果" 和 "属于 - 公司" 关系空间中的投影不同,避免了语义混淆。 - TransD (2015):针对 TransR 中头尾实体共享投影矩阵的问题,为头实体和尾实体分别设计投影矩阵 Mᵣₕ和 Mᵣₜ,提高建模灵活性:
hr=h⋅Mrh
tr=t⋅Mrt
评分函数与 TransR 类似。
改进映射方式
- TorusE(2018):将向量空间从欧氏空间改为环形曲面(Torus),利用环形空间的周期性解决长距离平移问题,评分函数考虑环形空间中的最短距离。
- RotatE(2019):将向量空间扩展到复数域,将关系视为旋转操作,即 h ⊙ r ≈ t(⊙为元素级乘法),其中 r 的模长为 1(旋转向量特性)。这种旋转操作能自然建模对称关系(旋转 0 度)、反对称关系(旋转 180 度)和逆关系(旋转相反角度),例如 "朋友" 关系是对称的(r 旋转 0 度,h⊙r = h ≈ t,t⊙r = t ≈ h),"父子" 关系是反对称的(r 旋转 180 度,h⊙r ≈ t 则 t⊙r ≈ -h ≠ h)。
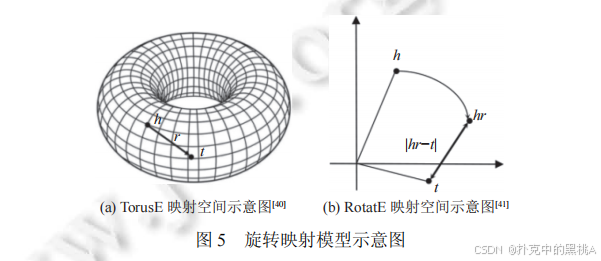
图 5 为 "旋转映射模型示意图",其中(a)是TorusE 的环形映射空间示意图 ,展示实体向量在圆环表面的分布与平移逻辑;(b)是RotatE 的复数域旋转示意图,直观呈现 "头实体向量h经关系r旋转后得到hr,且hr与尾实体向量t的距离越近,三元组越合理" 的核心思想。通过示意图,能更清晰理解 TorusE 的 "环形空间平移" 与 RotatE 的 "复数域旋转" 技术细节。
区分向量表示
- TranSparse(2016):针对关系的异质性(不同关系连接的实体对数差异大),用稀疏度不同的矩阵表示关系,复杂关系(连接实体多)用稠密矩阵,简单关系用稀疏矩阵,减少参数冗余。
附加约束信息
- CTransR(2015):将同一关系的实体对聚类,为每个聚类学习专属关系向量,增强对关系细分语义的建模。
- PTransE(2015):引入关系路径信息,例如 "h → r1 → e → r2 → t" 可推出 "h → r → t",通过路径约束增强预测准确性。
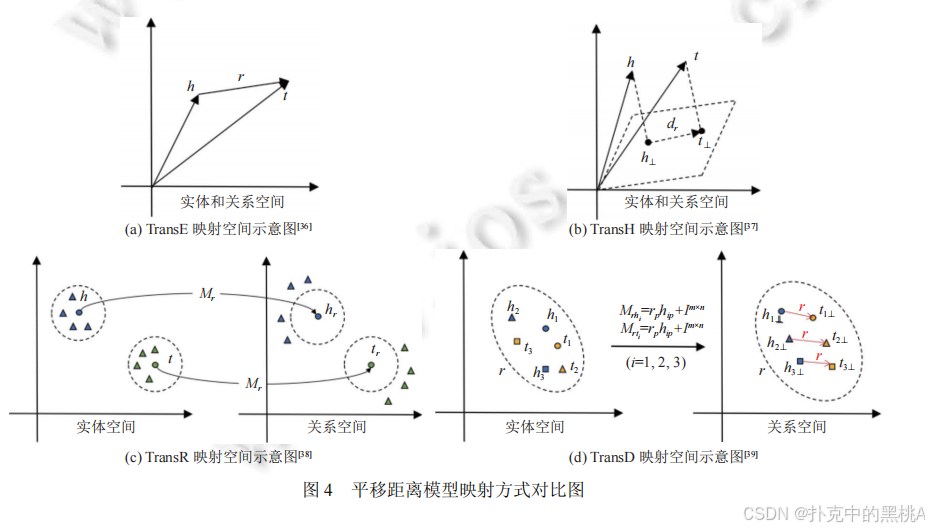
图 4直观展示 TransE(同一空间平移)、TransH(超平面投影)、TransR(实体 - 关系空间分离)、TransD(头尾实体分别投影)的空间映射差异,帮助理解模型的演进逻辑。
2. 张量分解模型:基于 "矩阵分解" 的关联捕捉
张量分解模型将知识图谱视为一个三维张量(实体 × 实体 × 关系),其中张量元素 T (h, r, t)=1 表示三元组(h, r, t)存在,T (h, r, t)=0 表示不存在。通过分解张量,得到实体和关系的低维向量表示,就像将一个复杂的魔方拆成小方块,通过小方块的组合还原魔方结构。
(1) 经典模型:RESCAL
RESCAL 是 2011 年提出的首个张量分解模型,它将三元组(h, r, t)表示为实体向量与关系矩阵的双线性乘积:
f(h,r,t)=hTMrt
其中,Mᵣ是关系 r 的 d×d 矩阵,h 和 t 是 d 维实体向量。该模型通过矩阵 Mᵣ捕捉实体 h 和 t 之间的交互强度,评分越高,三元组越合理。
RESCAL 的优点是表达能力强,能建模多种关系类型;但缺点是参数多(每个关系有 d² 个参数),计算复杂度高,难以应用于大规模知识图谱。
(2) 优化方向与衍生模型
为降低复杂度并增强建模能力,研究者提出了多种优化模型:
施加矩阵约束
- DistMult (2015):简化 Mᵣ为对角矩阵(Mᵣ=diag (r)),评分函数变为:
f(h,r,t)=hTdiag(r)t=∑i=1dhiriti
参数数量从 d² 减少到 d,计算效率大幅提升。但对角矩阵的对称性导致模型只能处理对称关系(h^T diag (r) t = t^T diag (r) h),无法建模反对称关系(如 "父子")。 - ComplEx (2016):引入复数向量解决 DistMult 的对称性问题,实体和关系向量为复数域向量,评分函数为:
f(h,r,t)=Re(hTdiag(r)tˉ)
其中,tˉ是 t 的共轭复数,Re (・) 表示取实部。复数运算打破了对称性(h^T diag (r) tˉ ≠ t^T diag(r) hˉ),使模型能处理反对称关系。 - ANALOGY(2017):要求关系矩阵 Mᵣ是正规矩阵(MᵣMᵣᵀ = MᵣᵀMᵣ),并满足关系组合的可交换性,增强对类比推理的支持,例如 "国王 - 男人 = 女王 - 女人" 的类比关系。
优化分解形式
- HolE (2016):用循环关联运算(Circular Correlation)压缩实体交互,h * t 的结果与关系向量 r 做点积:
f(h,r,t)=(h∗t)Tr
循环关联运算可视为矩阵乘法的压缩形式,参数数量少且表达能力接近 RESCAL。 - SimplE (2018):为每个实体 e 设置头嵌入 eₕ和尾嵌入 eₜ,每个关系 r 设置正向嵌入 r 和逆向嵌入 r⁻¹,评分函数为正向和逆向三元组的平均:
f(h,r,t)=21(hhTdiag(r)tt+htTdiag(r−1)th)
通过区分头 / 尾嵌入和正 / 逆向关系,在低参数复杂度下实现对非对称关系的建模。 - TuckER (2019):引入核心张量 W,将三元组表示为多线性乘积:
f(h,r,t)=W×1h×2r×3t
其中 ×ₖ表示第 k 维的张量乘积。核心张量 W 是共享参数,实体和关系向量维度可独立设置,灵活性高且表达能力强。
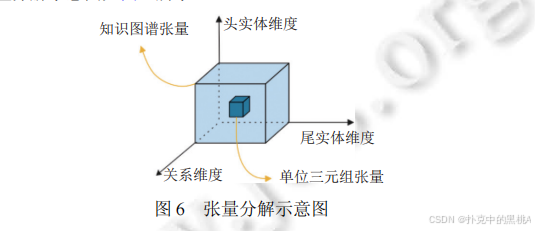
图 6展示三维知识图谱张量如何分解为头实体向量、关系矩阵 / 向量、尾实体向量,直观呈现 "整体分解为局部" 的过程,帮助理解张量分解的核心思想。
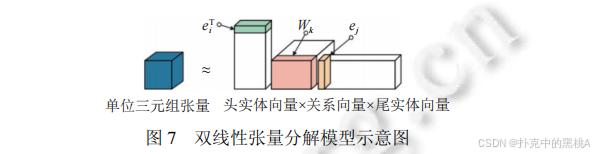
图 7 直观展示 "头实体向量 × 关系向量 × 尾实体向量" 的双线性交互,与 RESCAL、DistMult 等双线性张量分解模型的核心思想(通过矩阵 / 张量乘积捕捉实体 - 关系关联)高度匹配,辅助解释这类模型的 "双线性关联" 本质。
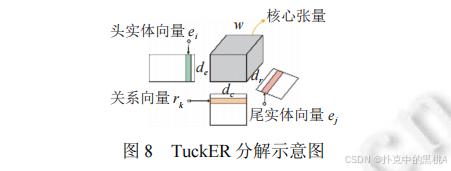
在图8中,TuckER 通过 "核心张量 + 多线性乘积" 增强表示能力,图 8 清晰展示头实体、关系、尾实体向量与核心张量的交互方式,能直观解释 TuckER "用共享核心张量建模多维度关联" 的创新点。
3. 传统神经网络模型:基于 "特征提取" 的非线性建模
传统神经网络模型通过非线性变换提取三元组的深层特征,捕捉实体与关系的复杂关联,就像用高精度扫描仪提取 "实体 - 关系" 图案的细节特征,再通过特征匹配进行预测。
(1) 卷积神经网络(CNN)
卷积神经网络擅长提取局部特征,在知识图谱表示学习中,通过卷积层捕捉实体与关系向量的局部交互模式:
- ConvE (2018):将头实体 h 和关系 r 的向量拼接后重塑为二维矩阵(如 d×k),用多个卷积核提取特征,经全连接层转换后与尾实体 t 的向量做点积:
f(h,r,t)=g(W⋅g(h;r∘ω)+b)⋅t
其中 h; r 是向量拼接,∘是卷积运算,g 是激活函数。ConvE 首次将 CNN 用于链接预测,通过二维卷积捕捉局部特征,效果优于传统平移和张量模型。 - ConvKB (2018):直接拼接头实体 h、关系 r、尾实体 t 的向量为 d×3 矩阵,用卷积层提取三者的整体关联特征,避免 ConvE 仅关注 h 和 r 的缺陷:
f(h,r,t)=g(W⋅g(h;r;t∘ω)+b) - ConvR (2019):将关系 r 的向量作为卷积核,对头实体 h 的向量进行卷积,增强 h 和 r 的交互:
f(h,r,t)=g(W⋅g(h∘ωr)+b)⋅t - InteractE(2020):优化向量拼接方式,通过循环交替、元素交叉等方式增强 h 和 r 的交互,并使用循环卷积进一步提取特征,提升特征利用率。
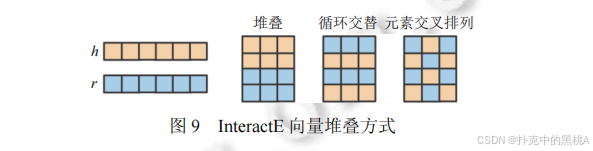
InteractE 的核心优化点是 "增强实体与关系的向量交互",图 9 对比了不同的向量堆叠策略(堆叠、循环交替、元素交叉),能辅助解释该模型如何通过更精细的向量排列,提升卷积层对特征的提取能力。
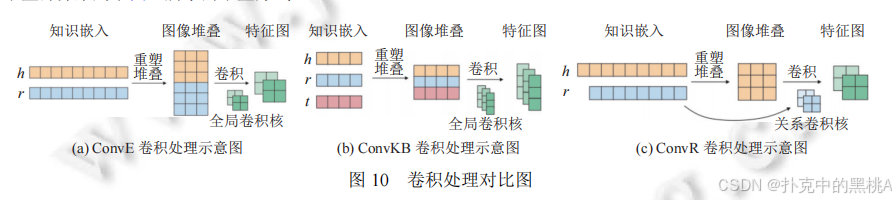
图 10展示 ConvE(h 和 r 拼接卷积)、ConvKB(h、r、t 拼接卷积)、ConvR(用 r 作为卷积核)的不同卷积操作,直观呈现特征提取方式的演进。
(2) 其他神经网络模型
- CapsE (2019):引入胶囊网络(Capsule Network),用向量输出的胶囊代替传统神经元的标量输出,更好捕捉特征的空间关系和层次结构,评分函数基于胶囊网络的输出向量 norm:
f(h,r,t)=∣∣capsnet(g(h,r,t∗ω))∣∣ - RSN (2019):结合循环神经网络(RNN)和残差学习,捕捉知识图谱中的长路径依赖,通过多步关系路径的上下文信息辅助预测:
f(h,r,t)=σ(rsn(h,p,r)⋅t)
其中 p 是关系路径,rsn 是循环残差网络模块。
4. 图神经网络模型:基于 "信息传播" 的结构建模
图神经网络(GNN)专为图结构数据设计,通过 "信息传播" 机制聚合邻居节点的信息,更新节点表示,能有效捕捉知识图谱的局部结构特征,就像一个人通过朋友的反馈和评价,不断完善对另一个人的认识。
(1) 核心思想
GNN 的核心是迭代更新实体向量:每个实体通过聚合其邻居实体(与该实体有直接关系的实体)的信息,更新自身向量。对于知识图谱,邻居信息不仅包括实体,还包括连接它们的关系,因此模型需同时建模实体和关系的交互。
(2) 经典模型
- R-GCN (2017):首个用于知识图谱的图卷积网络,为每个关系 r 设计转换矩阵 Wᵣ,实体向量更新公式为:
hv(k)=f(∑(u,r)∈N(v)Wr(k)hu(k−1)+W0(k)hv(k−1))
其中 N (v) 是实体 v 的邻居,W₀是自环矩阵(保留自身信息)。R-GCN 通过关系转换矩阵建模关系信息,但关系数量增多时会导致参数爆炸。 - CompGCN (2020):优化 R-GCN 的参数问题,用基向量组合表示关系转换矩阵,并通过减法、乘法等组合函数 φ(hᵤ, r) 聚合邻居信息:
hv(k)=f(∑(u,r)∈N(v)Wλ(r)(k)ϕ(hu(k−1),hr(k−1)))
其中 λ(r) 是关系 r 的基向量索引,φ 是实体 - 关系组合函数。CompGCN 参数更少且表达能力更强。 - WGCN(2019):引入关系权重,为不同关系的邻居分配不同聚合权重,权重由关系类型决定,增强对重要关系的关注。
- KBGAT(2019):结合图注意力机制(GAT),通过注意力层计算邻居的权重,重要邻居(对当前实体影响大的邻居)的信息权重更高,就像在朋友评价中,更重视亲密朋友的意见。
(3) 与其他模型的区别
图神经网络模型采用 "编码 - 解码" 结构:编码阶段通过信息传播学习实体向量,解码阶段用评分函数(如 TransE、DistMult)进行链接预测。这种分离架构使 GNN 的表示学习更灵活,可适配不同的预测任务,而平移距离、张量分解等模型的表示学习与预测过程通过同一评分函数绑定。

表 1像 "二元关系模型对比表",汇总四类模型的代表模型、评分函数、优化方向和核心优缺点,例如 TransE 的评分函数为 L₁/L₂范数,优化方向是拓展映射空间,优点是简单高效,缺点是无法处理复杂关系。
四.面向多元化关系的表示学习模型:从二元到多元的扩展
现实世界的知识往往包含多个实体和关系,因此需要将二元关系模型扩展到多元关系和超关系场景。这种扩展不仅是表示形式的变化,更需要调整建模逻辑以捕捉复杂关联。
1. 多元关系的表示学习模型
多元关系用角色 - 键值对表示,模型需处理多个实体和关系的交互,其核心挑战是如何聚合多个角色 - 键值对的信息,并保持它们之间的关联。
(1) 平移距离模型的扩展
- m-TransH (2016):将 TransH 扩展到多元关系,为每个角色 - 键值对(rᵢ, vᵢ)定义超平面,实体 vᵢ在超平面上的投影与角色向量 rᵢ满足平移约束。通过元关系(Meta-relation)聚合所有角色 - 键值对的信息,整体评分函数为:
f(r,t)=∑ρ∈M(Rr)ar(ρ)Pnr(t(ρ))+br2
其中 M (Rᵣ) 是角色集合,aᵣ(ρ) 是权重,P 是投影函数。m-TransH 是首个多元关系模型,但严格的位置约束导致信息丢失,且无法预测关系。 - RAE(2018):在 m-TransH 中引入多层感知器(MLP)建模实体相关性,将实体向量输入 MLP 得到关联特征,再融入评分函数。RAE 支持多实体缺失预测,但仍局限于实体预测,无法处理关系缺失。
(2) 张量分解模型的扩展
- GETD (2020):将 TuckER 的三阶张量扩展为(N+1)阶张量(N 为元数),用张量环分解(Tensor Ring Decomposition)简化核心张量,降低计算复杂度。例如,三元关系(N=3)的评分函数为:
f(ir,i1,...,in)=W^×1rir×2ei1×3...×n+1ein
GETD 需为不同元数的知识单独训练模型,泛化性差。 - S2S(2021):将实体和关系向量分割为 N 个片段(N 为最大元数),不同元数的知识共享片段,通过稀疏核心张量聚合信息。例如,实体 e 的向量为 e₁, e₂, ..., eₙ,元数为 k 的知识使用前 k 个片段。S2S 支持混合元数训练,但无法区分核心与辅助关系。
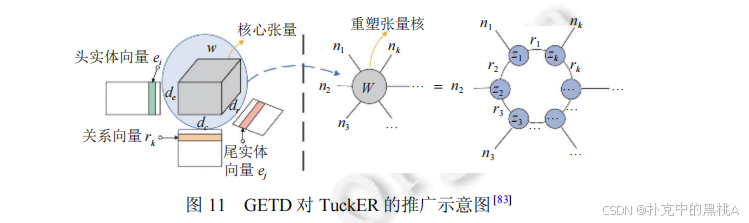
GETD 是针对多元关系的张量分解扩展,核心是将 TuckER 的 "三阶张量" 推广到 "N+1 阶张量"(N 为多元关系元数)。图 11 展示了 GETD 如何基于 TuckER 的核心张量进行扩展,辅助解释 "多元关系下的张量分解逻辑"。
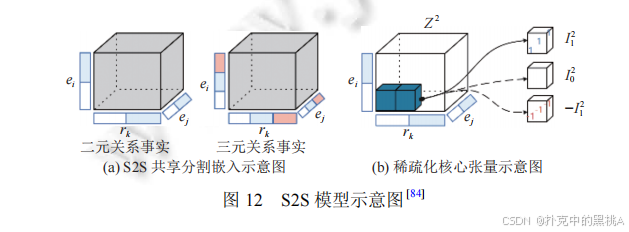
S2S 的创新点是 "共享嵌入片段 + 稀疏核心张量",支持混合元数的多元关系建模。图 12(a)展示二元 / 三元关系的 "共享分割嵌入",图 12(b)展示 "稀疏化核心张量",能直观解释 S2S 如何在多元场景下优化参数与提升泛化性。
(3) 传统神经网络模型的扩展
- NaLP(2019):将角色 - 键值对的向量拼接后输入卷积层,提取特征后用全连接层输出评分。NaLP 首次将 CNN 用于多元关系,但平等对待所有角色 - 键值对,忽略核心关联。
- NaLP-Fix(2020):在 NaLP 基础上优化负采样策略,提高模型稳定性,但未解决核心关联缺失问题。
- HypE(2021):为不同元数设计专用卷积核,增强对特定元数知识的建模,但灵活性不足,无法处理可变元数。
2. 超关系的表示学习模型
超关系保留主三元组和限定词,模型需区分核心与辅助信息,其核心挑战是如何有效融合主三元组与限定词的关联。
(1) 传统神经网络模型的扩展
- NeuInfer (2020):分别计算主三元组的有效性得分和主三元组与限定词的兼容性得分,加权求和得到总评分:
f(h,r,t,Q)=α⋅fmain(h,r,t)+(1−α)⋅fcomp(h,r,t,Q)
其中 fₘₐᵢₙ是主三元组评分,fₒₘₚ是兼容性评分(主三元组与每个限定词的交互得分)。NeuInfer 首次建模超关系,但特征提取较简单。 - HINGE (2020):将主三元组(h, r, t)与每个限定词(qₙ, qᵥ)拼接为五元组(h, r, qₙ, qᵥ, t),用卷积层提取特征后进行最小池化,聚合所有限定词的信息:
f(h,r,t,Q)=minq∈Qfconv(h,r,qn,qv,t)
HINGE 通过卷积捕捉主三元组与限定词的交互,但卷积操作和顺序训练导致时间复杂度高,难以应用于大规模图谱。
(2) 图神经网络模型的扩展
- StarE (2021):扩展 CompGCN,将限定词信息纳入实体向量更新过程,实体 v 的向量更新公式为:
hv=f(∑(u,r)∈N(v)Wλ(r)ϕr(hu,γ(hr,hq)vu))
其中 γ(hᵣ, h_q) 融合关系和限定词向量,φᵣ是组合函数。StarE 在解码阶段可搭配 ConvE、Transformer 等模型,在超关系预测中效果最佳,证明了 GNN 对复杂结构的建模能力。
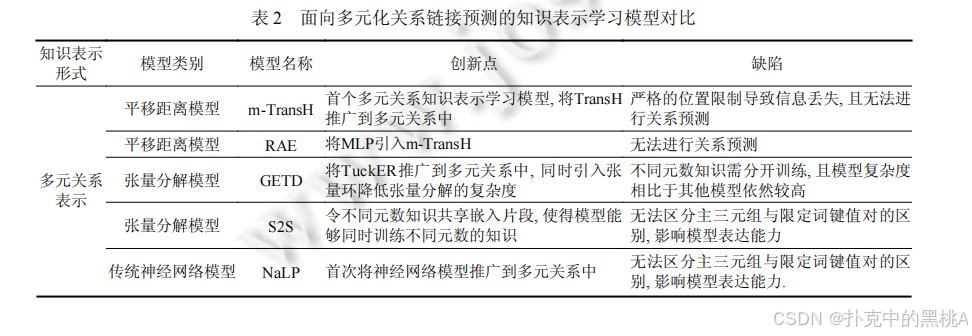
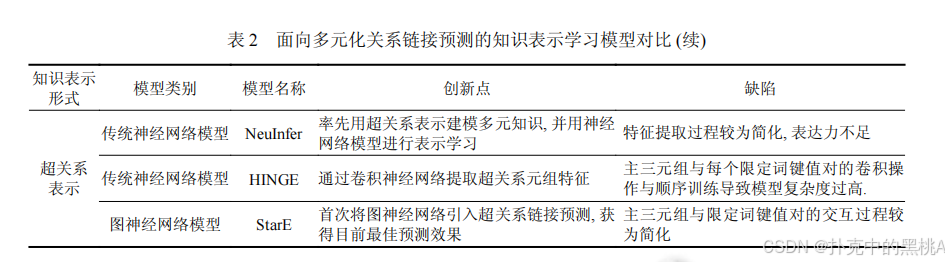
表 2这张表像 "多元化关系模型对比表",汇总多元和超关系模型的知识表示形式、模型类别、创新点和缺陷,例如 StarE 的创新点是引入 GNN 处理超关系,缺陷是主三元组与限定词的交互较简单。
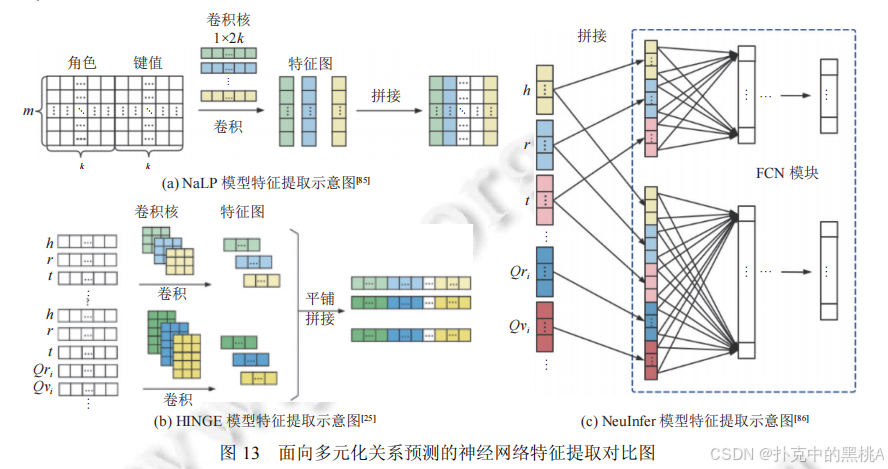
图 13这张图像 "多元化模型特征提取对比图",展示 NaLP(多元关系平等处理)、NeuInfer(主三元组 + 兼容性评分)、HINGE(主三元组与限定词卷积)的特征提取流程,直观呈现从多元到超关系的建模升级。
五.实验对比与分析:不同模型的 "实战表现"
为客观评估模型性能,需在标准数据集上进行实验,通过统一指标对比不同模型的链接预测效果。本节将介绍常用数据集、评测指标,并分析实验结果。
1. 常用数据集
(1) 二元关系数据集
- FB15k:从 FreeBase 抽取,包含 14951 个实体、1245 个关系,训练集 483142 个三元组。存在数据泄露(测试集含训练集的逆向三元组)。
- WN18:从 WordNet 抽取,包含 40943 个实体、18 个关系,聚焦词汇语义关系。同样存在数据泄露。
- FB15k-237:FB15k 的优化版,删除 237 个核心关系外的冗余关系,解决数据泄露问题。
- WN18RR:WN18 的优化版,删除冗余关系,保留 11 个关系,难度更高。
- YAGO3-10:从 YAGO3 抽取,包含 123182 个实体、37 个关系,实体数多且含文本属性,数据泄露少。
(2) 多元关系数据集
- JF17K:从 FreeBase 抽取,包含 28645 个实体、322 个关系,多元知识占比 45.9%,但存在严重数据泄露(测试集 44.5% 主三元组在训练集)。
- Wikipeople:从 Wikidata 抽取,聚焦人物相关知识,多元知识占比仅 2.6%,测试不充分。
(3) 超关系数据集
- WD50K:从 Wikidata 抽取,包含 47156 个实体、532 个关系,超关系知识占比 13.6%,删除泄露数据,更具挑战性。其子集 WD50K (33)、WD50K (66)、WD50K (100) 的超关系占比分别为 31.2%、64.5%、100%,用于测试模型对超关系比例的适应性。
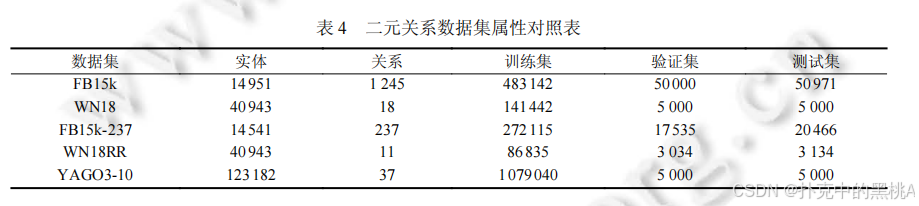
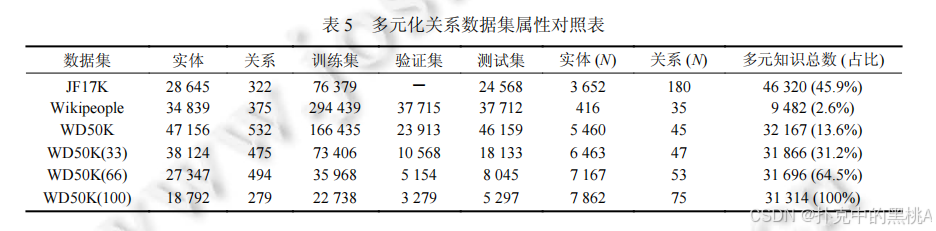
表 4、表 5:这两张表像 "数据集属性表",汇总二元关系数据集(表 4)和多元化关系数据集(表 5)的实体数、关系数、训练 / 验证 / 测试集规模等关键属性,方便对比数据集特点。
2. 评测指标
链接预测的核心是对候选实体或关系排序,常用指标包括:
- 平均秩(Mean Rank, MR):正确答案在预测结果中的平均排名,值越小越好。但对异常值敏感,例如一个排名 1000 的结果会大幅拉高平均值。
- 平均倒数秩(Mean Reciprocal Rank, MRR):正确答案排名倒数的平均值,值越大越好。MRR = (1/|Q|)Σ(1/rank (q)),对异常值更稳健。
- 命中比率(Hits@K):排名≤K 的正确答案比例,值越大越好。常用 K=1、3、5、10,Hits@1 更关注 top1 准确性。
例如,若预测结果中正确答案的排名为 3,则其倒数秩为 1/3,Hits@1=0,Hits@3=1。MRR 和 Hits@K 是目前最常用的指标,能较全面反映模型性能。
3. 实验结果分析
(1) 二元关系模型对比
- 平移距离模型:RotatE 表现最佳,在 FB15k-237 的 Hits@1 达 0.426,MRR 达 0.336,旋转操作使其能处理多种关系类型;TransE 因无法处理复杂关系,效果较差。
- 张量分解模型:ComplEx 和 TuckER 效果突出,TuckER 在 YAGO3-10 的 MRR 达 0.544,共享核心张量增强了表达能力;DistMult 因对称性限制,在非对称关系数据集上效果较差。
- 传统神经网络模型:ConvR 在多个数据集表现优异,ConvE 次之,ConvKB 因简单卷积效果较差;CapsE 和 RSN 效果不稳定,仍需优化。
- 图神经网络模型:CompGCN 在复杂数据集上优势明显,证明信息传播机制能有效捕捉图结构特征。
(2) 多元关系模型对比
- S2S 效果最佳,在 JF17K 的 MRR 达 0.528,共享嵌入片段解决了元数限制;GETD 在特定元数上表现好,但泛化性差;NaLP 因平等处理角色 - 键值对,效果最差。
(3) 超关系模型对比
- StarE(+Transformer)效果最优,在 WD50K (100) 的 Hits@1 达 0.588,MRR 达 0.654,超关系占比越高,优势越明显;HINGE 次之,但复杂度高;NaLP-Fix 因未区分主次关系,效果最差。
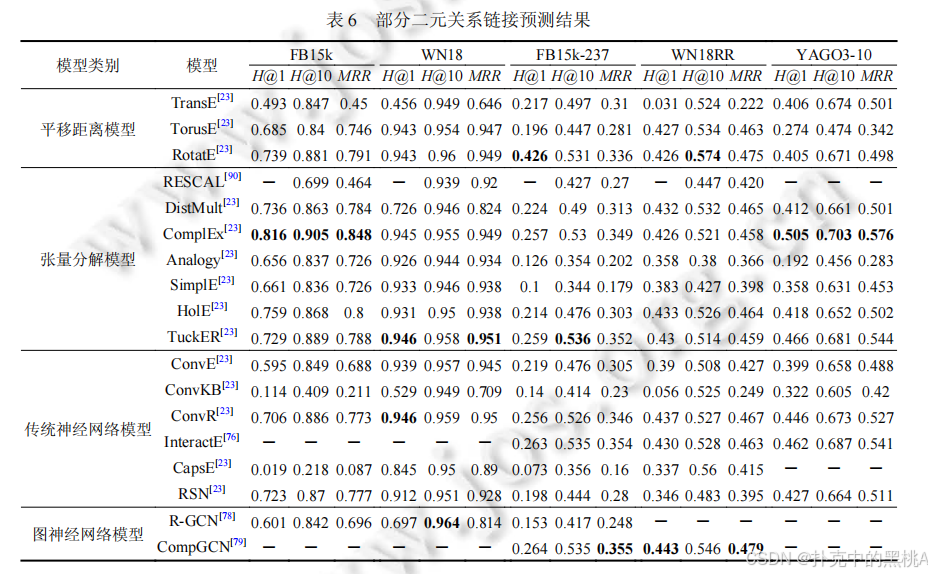
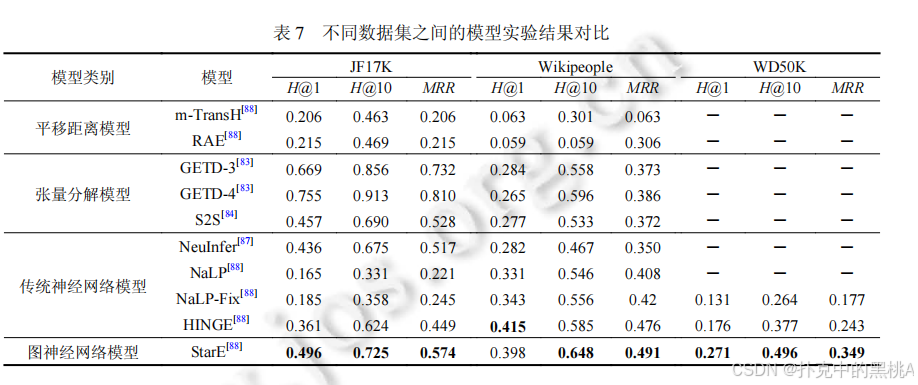
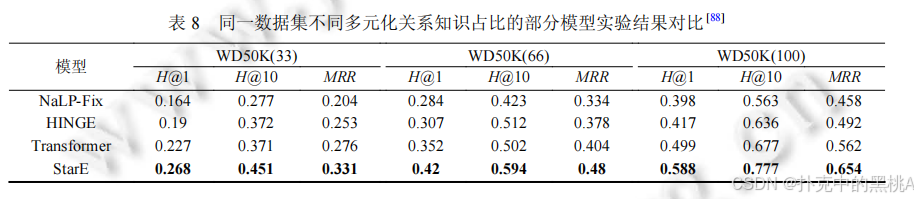
表 6、表 7、表 8:这些表像 "实验结果对比表",汇总不同模型在各数据集上的 MRR、Hits@1、Hits@10 指标,加粗数据为最优结果,直观呈现模型性能差异。
(4) 关键结论
- 模型表达能力:图神经网络 > 传统神经网络 > 张量分解 > 平移距离(整体趋势,具体因数据集而异)。
- 知识表示形式:超关系 > 多元关系 > 二元关系,更精准的知识表示能提升预测效果。
- 效率与效果平衡:平移距离模型效率最高,适合大规模图谱;图神经网络效果最佳,但计算复杂度高。
六.未来研究方向:挑战与机遇
尽管知识图谱表示学习已取得显著进展,但仍面临诸多挑战,未来可从以下方向突破:
1. 模型优化:提升可解释性与可扩展性
(1) 增强可解释性 :现有神经网络模型多为 "黑箱",预测结果难以解释。未来需结合逻辑规则(如将路径约束融入 GNN),或设计可解释的注意力机制,让模型 "说明" 预测依据,就像导航软件不仅给出路线,还解释选择理由。
(2) 提高可扩展性:大规模知识图谱(实体数超百万)对模型效率要求高。需研究稀疏参数化(如稀疏张量分解)、分布式训练(如分块处理实体)、在线学习(动态更新模型)等技术,降低计算复杂度。
2. 知识表示形式:融合更多结构与信息
(1) 融合层次与路径信息 :知识图谱中的层次结构(如 "动物→哺乳动物→猫")和关系路径(如 "朋友的朋友")蕴含丰富语义,未来需设计新表示形式整合这些信息,例如将层次约束作为正则项融入模型。
(2) 引入多模态信息:实体的文本描述、图像等多模态信息可辅助关系预测,需设计跨模态表示学习模型,实现 "文本 - 图像 - 知识" 的联合建模。
3. 问题作用域:针对特定场景定制模型
(1) 低资源场景 :小众领域知识图谱数据稀疏,需开发少样本 / 零样本学习模型,利用迁移学习(如从通用图谱迁移知识)或元学习(快速适应新关系)提高预测效果。
(2) 动态知识图谱 :实体和关系随时间变化(如 "总统" 关系的更替),需设计时序表示学习模型,捕捉知识的动态演化,就像实时更新的导航地图。
(3) 跨语言知识图谱:多语言知识图谱的链接预测需解决语言差异,需设计跨语言表示模型,实现不同语言实体的对齐与关联预测。
七.总结
知识图谱表示学习是链接预测的核心技术,通过将实体和关系转换为向量,实现了知识的可计算性。本文从知识表示形式和建模方法两个维度,系统解读了面向链接预测的表示学习方法:
- 知识表示形式:从二元关系到多元关系再到超关系,演进趋势是更精准地刻画复杂知识,保留更多语义关联。
- 建模方法:平移距离模型基于空间平移,张量分解模型基于矩阵分解,传统神经网络模型基于特征提取,图神经网络模型基于信息传播,四类模型各有优劣,图神经网络在复杂场景中表现最佳。
实验结果表明,超关系表示形式结合图神经网络模型能取得最优预测效果,但模型的可解释性和可扩展性仍需提升。未来,随着技术的发展,知识图谱表示学习将在低资源、动态、跨模态等场景中发挥更大作用,为智能系统提供更完整、更可靠的知识支撑。
通过不断优化模型、丰富知识表示形式、拓展应用场景,知识图谱这张 "知识地图" 将越来越完善,为人工智能的认知智能发展奠定坚实基础。
尾
本期技术解构至此。
论文揭示的方法论范式对跨领域技术实践具有普适参考价值。下期将聚焦其他前沿成果,深入剖析其的突破路径。敬请持续关注,共同深挖工程实现脉络,淬炼创新底层逻辑,在学术与工程融合中洞见技术演进规律,推动领域范式持续进化。